Measuring the impact:

Stephen Merity
Smerity @ Common Crawl
- Continuing the crawl
- Documenting best practices
- Guides for newcomers to Common Crawl + big data
- Reference for seasoned veterans
- Spending many hours blessing and/or cursing Hadoop
Before:
University of Sydney '11, Harvard '14
Google Sydney, Freelancer.com, Grok Learning
University of Sydney '11, Harvard '14
Google Sydney, Freelancer.com, Grok Learning
banned@slashdot.org
I was hoping on creating a tool that will automatically extract some of the most common memes ("But does it run Linux?" and "In Soviet Russia..." style jokes etc) and I needed a corpus - I wrote a primitive (threaded :S) web crawler and started it before I considered robots.txt. I do intensely apologise.
-- Past Smerity (16/12/2007)
Where did all the HTTP referrers go?

Referrers: leaking browsing history
If you click from
http://www.reddit.com/r/sanfrancisco
to
http://www.sfbike.org/news/
protected-bikeways-planned-for-the-embarcadero/
http://www.reddit.com/r/sanfrancisco
to
http://www.sfbike.org/news/
protected-bikeways-planned-for-the-embarcadero/
then SFBike knows you came from Reddit
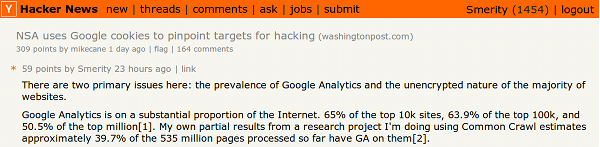
1) How many websites is Google Analytics (GA) on?
2) How much of a user's browsing history does GA capture?
Top 10k domains:
65.7%
65.7%
Top 100k domains:
64.2%
64.2%
Top million domains:
50.8%
50.8%
It keeps dropping off, but by how much..?
Estimate of captured browsing history...
?
Referrers allow easy web tracking
when done at Google's scale!
No information
!GA → !GA
Full information
!GA → GA
GA → !GA → GA
GA → !GA → GA → !GA → GA → !GA → GA → !GA → GA
GA → !GA → GA → !GA → GA → !GA → GA → !GA → GA
Key insight: leaked browsing history
Google only needs one in every two links to have GA in order to have your full browsing path*
*possibly less if link graph + click timing + machine learning used
Estimating leaked browser history
for each link = {page A} → {page B}:
total_links += 1
if {page A} or {page B} has GA:
total_leaked += 1
Estimate of leaked browser history is simply:
total_leaked / total_links

Joint project with Chad Hornbaker* at Harvard IACS
*Best full name ever: Captain Charles Lafforest Hornbaker II
The task
Google Analytics count: ".google-analytics.com/ga.js"
www.winradio.net.au NoGA 1
www.winrar.com.cn GA 6
www.winratzart.com GA 1
www.winrenner.ch GA 244
Generate link graph
domainA.com -> domainB.com <total times>
cnet-cnec-driver.softutopia.com -> www.softutopia.com 24
Merge link graph & GA count
www.winradio.net.au NoGA 1 www.winrar.com.cn GA 6 www.winratzart.com GA 1 www.winrenner.ch GA 244
domainA.com -> domainB.com <total times>
cnet-cnec-driver.softutopia.com -> www.softutopia.com 24
Exciting age of open data
Open data
+
Open tools
+
Cloud computing
+
Open tools
+
Cloud computing
WARC
raw web data
WAT
metadata (links, title, ...) for each page
WET
extracted text
raw web data
WAT
metadata (links, title, ...) for each page
WET
WARC = GA usage
raw web data
WAT = hyperlink graph
metadata (links, title, ...) for each page
raw web data
WAT = hyperlink graph
metadata (links, title, ...) for each page
Estimating the task's size
Web Data Commons Hyperlink Graph
Page level (http://en.wikipedia.org/wiki/Sunny_16_rule):
3.5 billion nodes, 128 billion edges, 331GB compressed
101 million nodes, 2 billion edges, 9.2GB compressed
Decided on using subdomains instead of page level
Engineering for scale
✓ Use the framework that matches best
✓ Debug locally
✓ Standard Hadoop optimizations
(combiner, compression, re-use JVMs...)
(combiner, compression, re-use JVMs...)
✓ Many small jobs ≫ one big job
✓ Ganglia for metrics & monitoring
Hadoop :'(
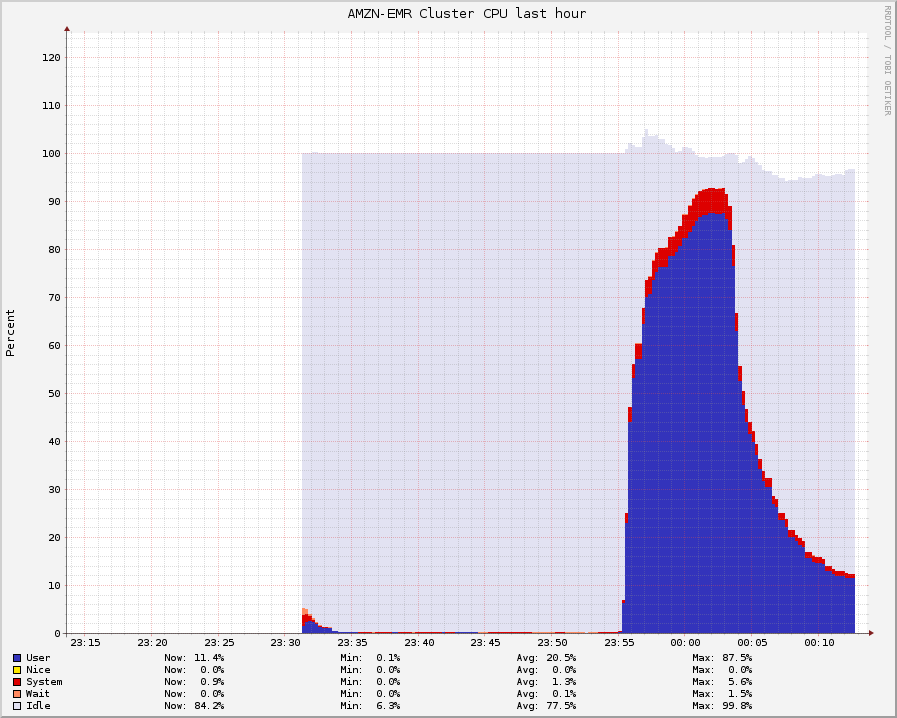
Hadoop :'(

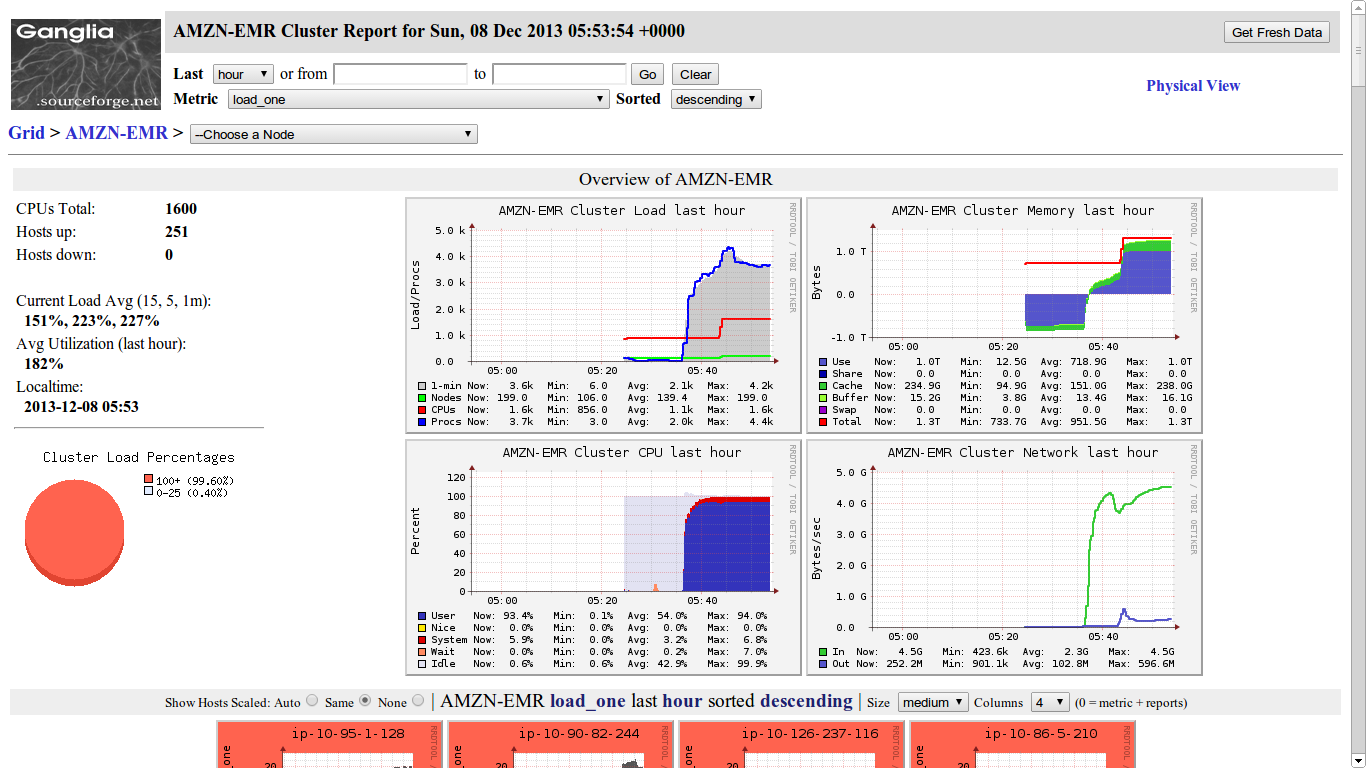
Monitoring & metrics with Ganglia
Engineering for cost
✓ Avoid Hadoop if it's simple enough
✓ Use spot instances everywhere*
✖ Use EMR if highly cost sensitive
(Elastic MapReduce = hosted Hadoop)
(Elastic MapReduce = hosted Hadoop)
*Everywhere but the master node!
Juggling spot instances
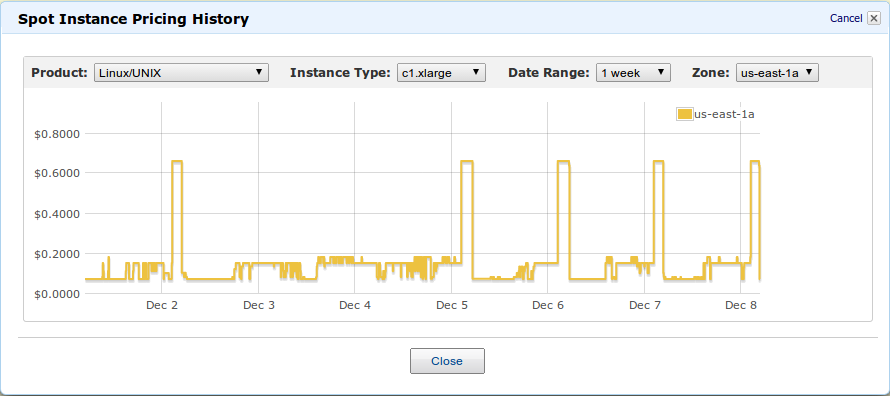
c1.xlarge goes from $0.58 p/h to $0.064 p/h
EMR: The good, the bad, the ugly
Good:
significantly easier, one click setup
significantly easier, one click setup
Bad:
price is insane when using spot instances
(spot = $0.075 with EMR = $0.12)
price is insane when using spot instances
(spot = $0.075 with EMR = $0.12)
Ugly:
Guess how many log files for a 100 node cluster?
Guess how many log files for a 100 node cluster?
584,764+ log files.
Ouch.
Cost projection
Best optimized small Hadoop job:
-
1/177th the dataset in 23 minutes
(12 c1.xlarge machines + Hadoop master)
Estimated full dataset job:
-
~210TB for web data + ~90TB for link data
- ~$60 in EC2 costs (177 hours of spot instances)
- ~$100 in EMR costs (avoid EMR for cost!)
Final results
29.96% of 48 million domains have GA
(top million domains was 50.8%)
48.96% of 42 billion hyperlinks leaked info to GA
That means that
one in every two hyperlinks will leak information to Google
The wider impact

Want Big Open Data?
Web Data
Covers everything at scale!
Languages...
Topics...
Demographics...
Processing the web is feasible
Downloading it is a pain!
Common Crawl does that for you
Processing it is scary!
Big data frameworks exist and are (relatively) painless
These experiments are too expensive!
Cloud computing means experiments can be just a few dollars
Get started now..!
Want raw web data?
CommonCrawl.org
CommonCrawl.org
Want hyperlink graph / web tables / RDFa?
Want example code to get you started?
Measuring the impact:
Full write-up: http://smerity.com/cs205_ga/
Stephen Merity
Measuring the impact: Google Analytics
By smerity




