New Methods for
Memory, Attention, and Efficiency in Neural Networks
Stephen Merity
@smerity

Joint works with colleagues from
Salesforce Research
Deep learning has saved us from feature engineering*
This is true - to some degree ...
Word vectors have replaced much of the manual work that WordNet was intended for
Machine translation no longer needs the training data to have manual alignments
Speech recognition no longer uses manual features / constructions like phonemes
Deep learning has saved us from feature engineering*

European Economic Area
aligned with
zone economique europeenne
* Architecture engineering is the new feature engineering

Model Architectures
The building blocks may be shared but
very little beyond that
For each task, there's a newly formed variation of the architecture just for it
This is especially true when hunting for the mythical state of the art numbers
(small percentage point gains can justify
very odd and very short term modifications)
Model Architectures (Vision)
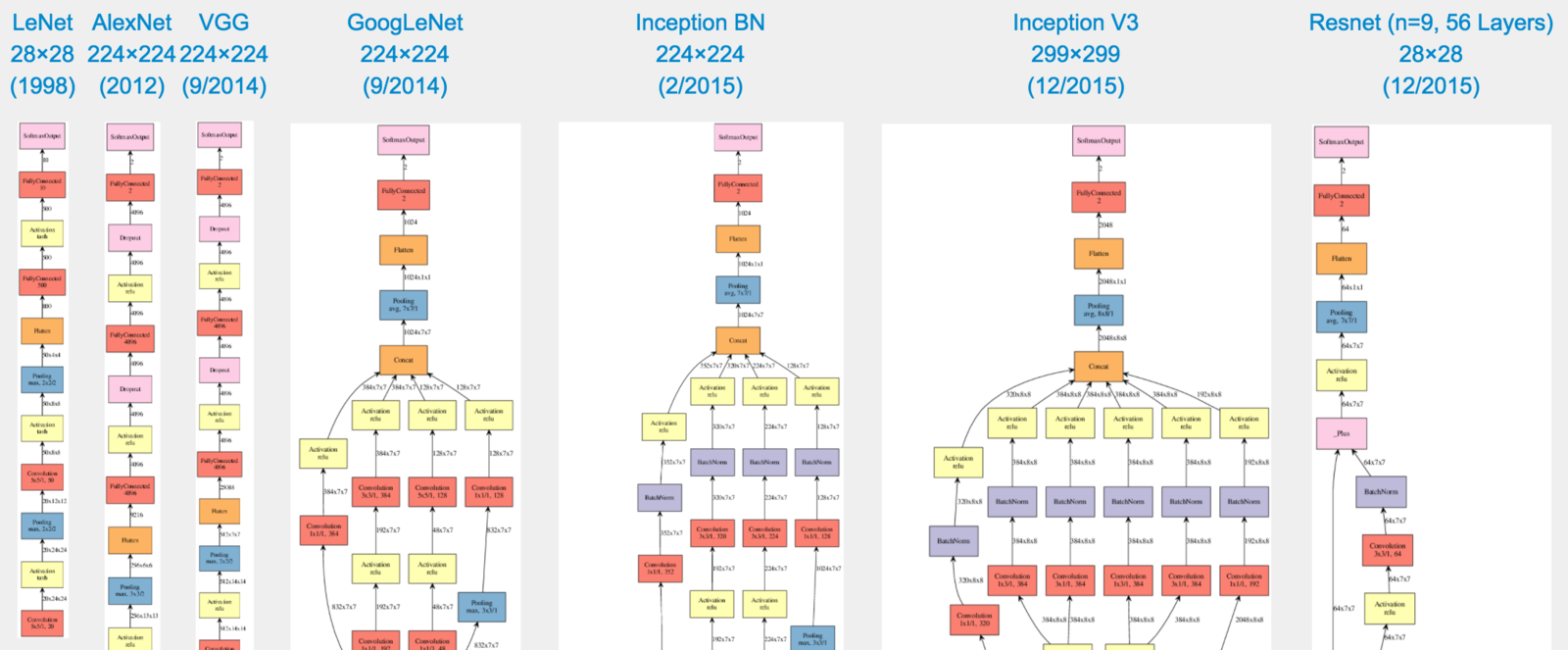
Image from Joseph Paul Cohen
All of these are variations for the task of image classification - not even more tailored tasks such as visual question answering
Model Architectures (Text)
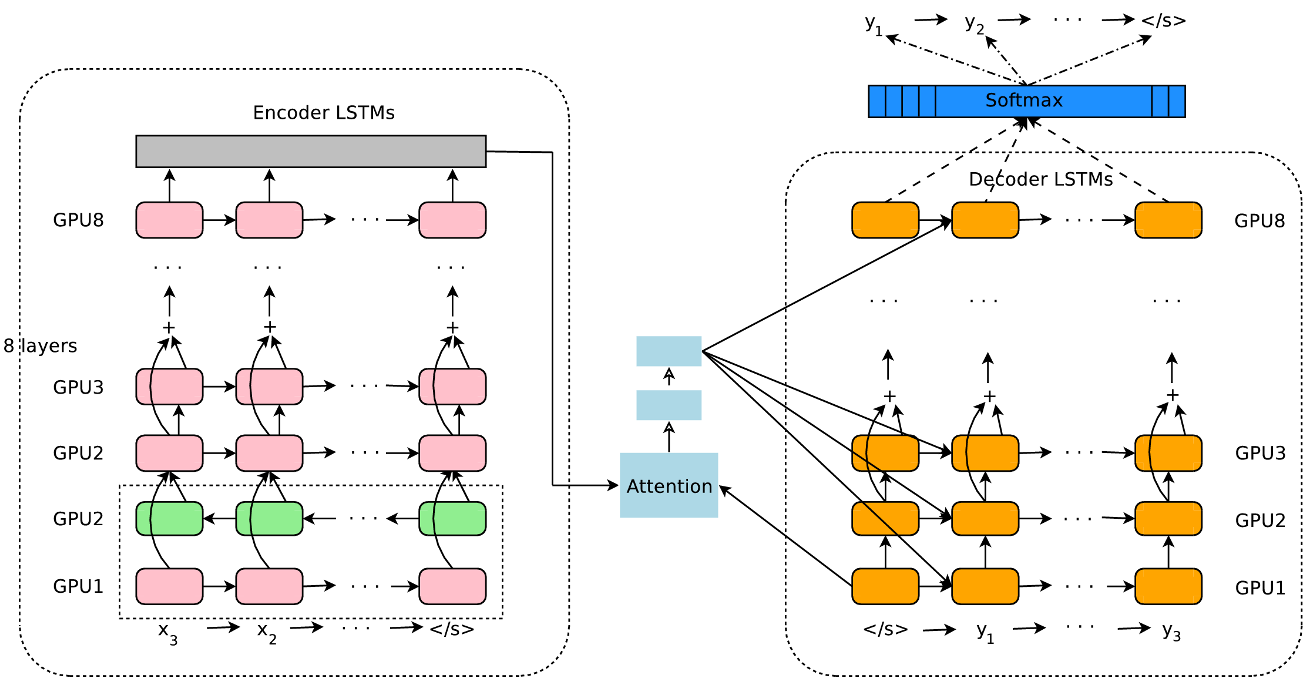
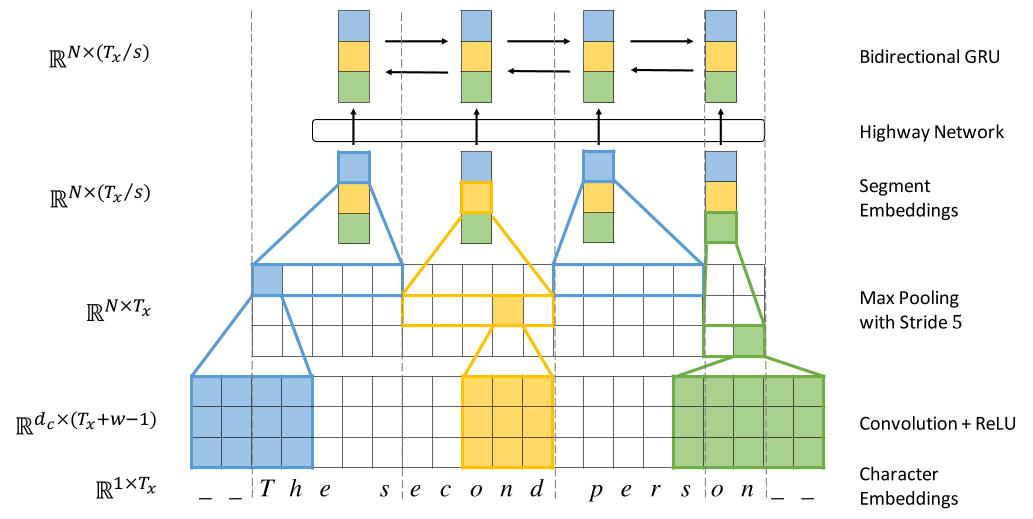
Encoder for Char-level Neural MT
(Lee et al. 2016):
convolutions and pooling for speed,
highway network for more processing
Google's Neural Machine Translation architecture (GNMT):
close to standard encoder-decoder but eight (!) layers + residual connections
Model Architectures
Specialized architectures aren't wrong by themselves
but they do pose some strong limitations
+ Transfer learning between tasks is difficult if the architectures for each task are different
+ Improvements found for one architecture may not be applicable (or tested) on another
+ This thinking encourages going back to the drawing board every time we get a new task
Model Architectures
Our largest interest is in transfer learning:
two related tasks should help each other
We already have primitive transfer learning:
Pretrained word vectors
(word2vec, GloVe, ...)
Pretrained ImageNet weights
(AlexNet, VGG, Inception, ResNet, ...)
Both leverage large datasets to provide an aspect of world knowledge to the model
Both are quite limited in scope however
Potential paths for improvement
Improve the shared building blocks that all architectures use:
better methods and components (regularization for RNNs / LSTM),
introducing new concepts (residual connections),
etc ...
More heretical: try to solve multiple tasks using
a single shared architecture
(though this is surprisingly difficult, especially while keeping SotA!)
The path to shared architectures
Modularity
Tasks do have different requirements, so construct the architectures with that in mind (i.e. swappable input module)
[vectors and joint training give us our "shared language"]
Remove information bottlenecks
Different tasks require processing different amounts of information and potentially different amounts of computation
Make reasoning mechanisms more generic
If the underlying reasoning mechanism can't solve certain subproblems it can't be used on tasks involving that subproblem
Think in terms of
Information Bottlenecks
Where is your model forced to use a compressed representation?
Most importantly,
is that a good thing?
Thinking of
Neural Networks
in terms of
Compression
Question Answering
1 Mary moved to the bathroom. 2 John went to the hallway. 3 Where is Mary? bathroom 1 4 Daniel went back to the hallway. 5 Sandra moved to the garden. 6 Where is Daniel? hallway 4 7 John moved to the office. 8 Sandra journeyed to the bathroom. 9 Where is Daniel? hallway 4 10 Mary moved to the hallway. 11 Daniel travelled to the office. 12 Where is Daniel? office 11 13 John went back to the garden. 14 John moved to the bedroom. 15 Where is Sandra? bathroom 8 1 Sandra travelled to the office. 2 Sandra went to the bathroom. 3 Where is Sandra? bathroom 2
Extract from the Facebook bAbI Dataset
Question Answering

Visual Genome: http://visualgenome.org/
Beyond classification ...

VQA dataset: http://visualqa.org/
Beyond classification ...

* TIL Lassi = popular, traditional, yogurt based drink from the Indian Subcontinent
Human Question Answering
Imagine I gave you an article or an image, asked you to memorize it, took it away, then asked you various questions.
Even as intelligent as you are,
you're going to get a failing grade :(
Why?
- You can't store everything in working memory
- Without a question to direct your attention,
you waste focus on unimportant details
Optimal: give you the input data, give you the question, allow as many glances as possible
Question Answering

Visual Genome: http://visualgenome.org/
Neural Machine Translation
Figure from Chris Olah's Visualizing Representations
Figure from Bahdanau et al's
Neural Machine Translation by Jointly Learning to Align and Translate

Neural Machine Translation

Results from Bahdanau et al's
Neural Machine Translation by Jointly Learning to Align and Translate
European Economic Area <=> zone economique europeenne
Attention and Memory in QA
When we know the question being asked
we can extract only the relevant information
This means that we don't compute or store unnecessary information
More efficient and helps avoid the
information bottleneck
QA for Dynamic Memory Networks
- A modular and flexible DL framework for question answering
- Capable of tackling wide range of tasks and input formats
- Can even been used for general NLP tasks (i.e. non QA)
(PoS, NER, sentiment, translation, ...)
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing (Kumar et al., 2015)
Dynamic Memory Networks for Visual and Textual Question Answering (Xiong et al., 2016)
For full details:
Related Attention/Memory Work
- Sequence to Sequence (Sutskever et al. 2014)
- Neural Turing Machines (Graves et al. 2014)
- Teaching Machines to Read and Comprehend
(Hermann et al. 2015) - Learning to Transduce with Unbounded Memory (Grefenstette 2015)
- Structured Memory for Neural Turing Machines
(Wei Zhang 2015)
- Memory Networks (Weston et al. 2015)
- End to end memory networks (Sukhbaatar et al. 2015)
DMN Overview

Original input module:
a simple uni-directional GRU
QA for Dynamic Memory Networks

- A modular and flexible DL framework for question answering
- Capable of tackling wide range of tasks and input formats
- Can even been used for general NLP tasks (i.e. non QA)
(PoS, NER, sentiment, translation, ...)
Input Modules

+ The module produces an ordered list of facts from the input
+ We can increase the number or dimensionality of these facts
+ Input fusion layer (bidirectional GRU) injects positional information and allows interactions between facts
Episodic Memory Module
Composed of three parts with potentially multiple passes:
- Computing attention gates
- Attention mechanism
- Memory update

Computing Attention Gates
Each fact receives an attention gate value from [0, 1]
The value is produced by analyzing [fact, query, episode memory]
Optionally enforce sparsity by using softmax over attention values

Soft Attention Mechanism
c = \sum^N_{i=1} g_i f_i
If the gate values were passed through softmax,
the context vector is a weighted summation of the input facts
Given the attention gates, we now want to extract a context vector from the input facts
Issue: summation loses positional and ordering information
Attention GRU Mechanism
If we modify the GRU, we can inject information from the attention gates.
Attention GRU Mechanism
If we modify the GRU, we can inject information from the attention gates.
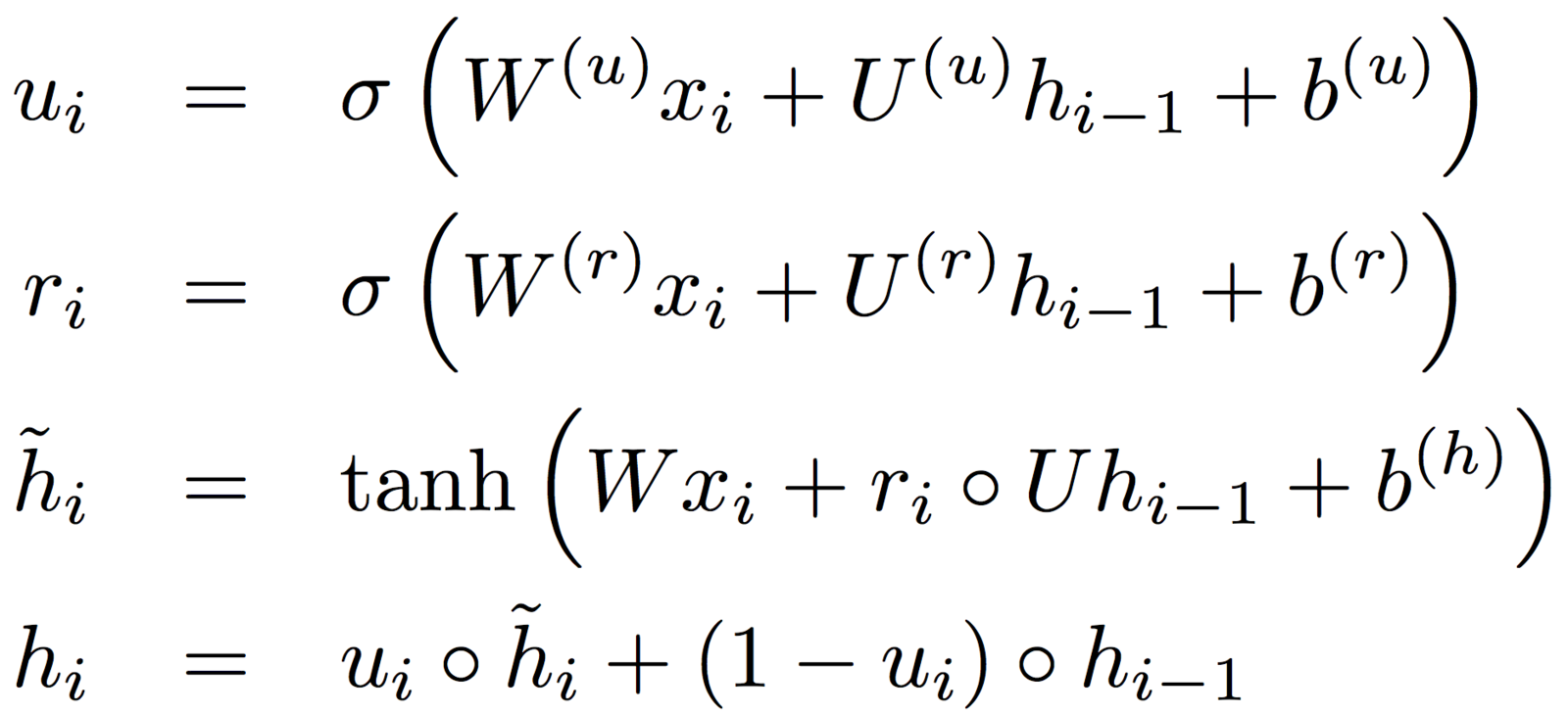
By replacing the update gate u with the activation gate g,
the update gate can make use of the question and memory

Results
Focus on three experimental domains:
Vision
Text
Attention visualization
Accuracy: Text QA (bAbI 10k)

bAbI is a set of 20 different tasks by Facebook that represent near "unit tests" of logical reasoning
Accuracy: Sentiment Analysis
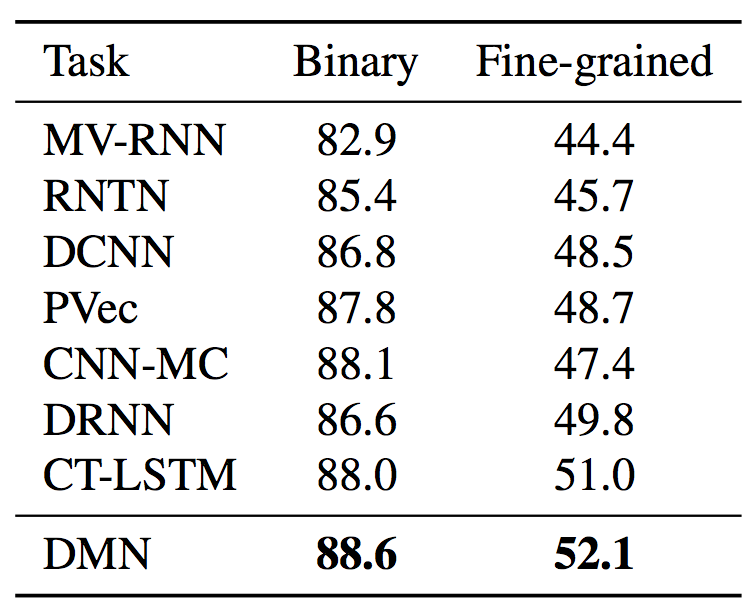
Experiments over the Stanford Sentiment Treebank
Test accuracies:
• MV-RNN and RNTN:
Socher et al. (2013)
• DCNN:
Kalchbrenner et al. (2014)
• PVec: Le & Mikolov. (2014)
• CNN-MC: Kim (2014)
• DRNN: Irsoy & Cardie (2015)
• CT-LSTM: Tai et al. (2015)
Accuracy related to attention passes
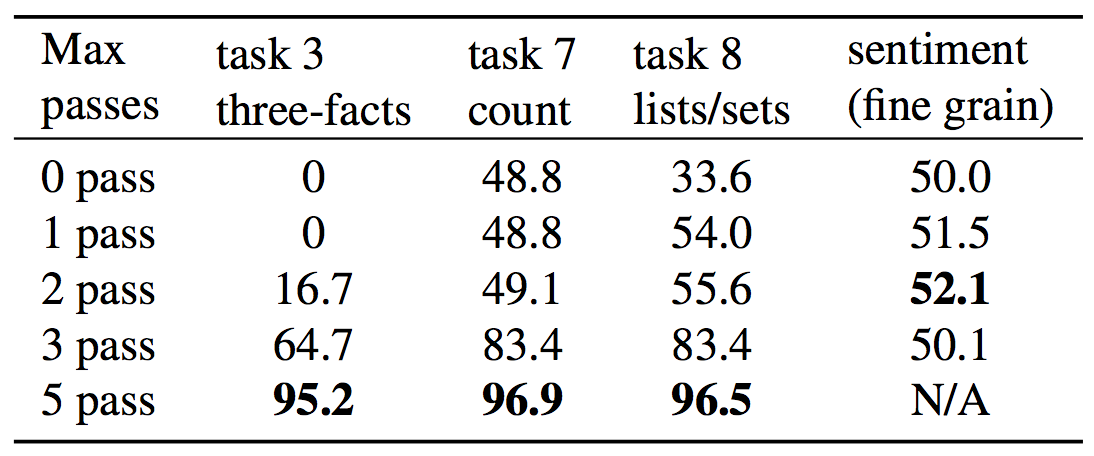
The results of the model generally improve with more passes,
especially for tasks requiring transitive reasoning
bAbi tasks (three-facts in particular) are constructed to require transitive reasoning
Accuracy related to attention passes
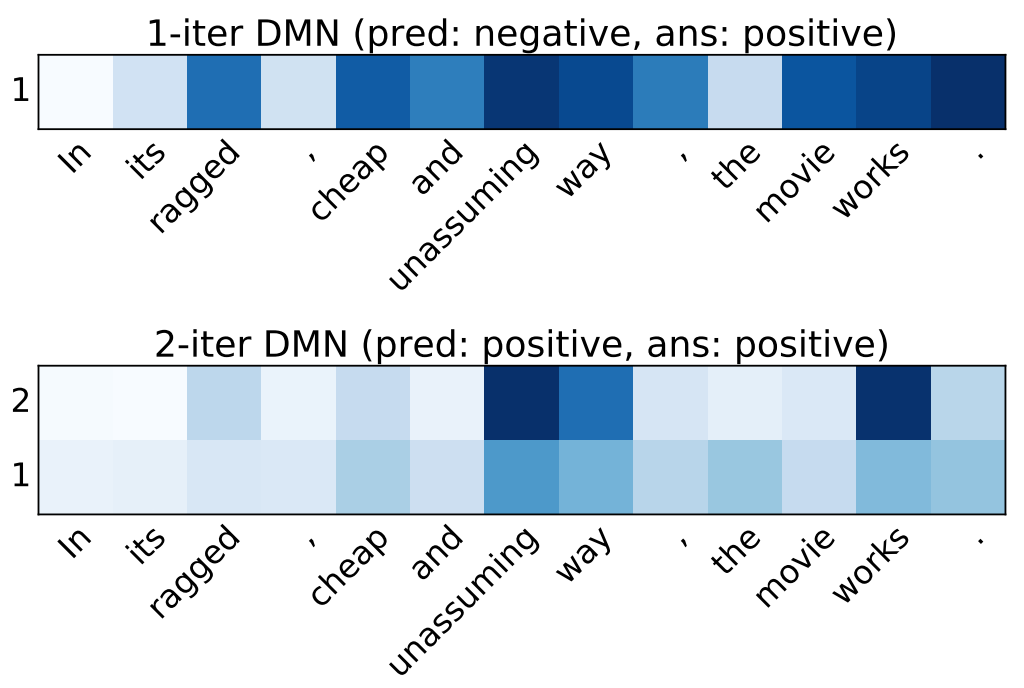
For sentiment analysis, two passes is shown to provide the best results. Both examples are incorrect with one pass.
In its ragged, cheap and unassuming way, the move works.
Accuracy related to attention passes
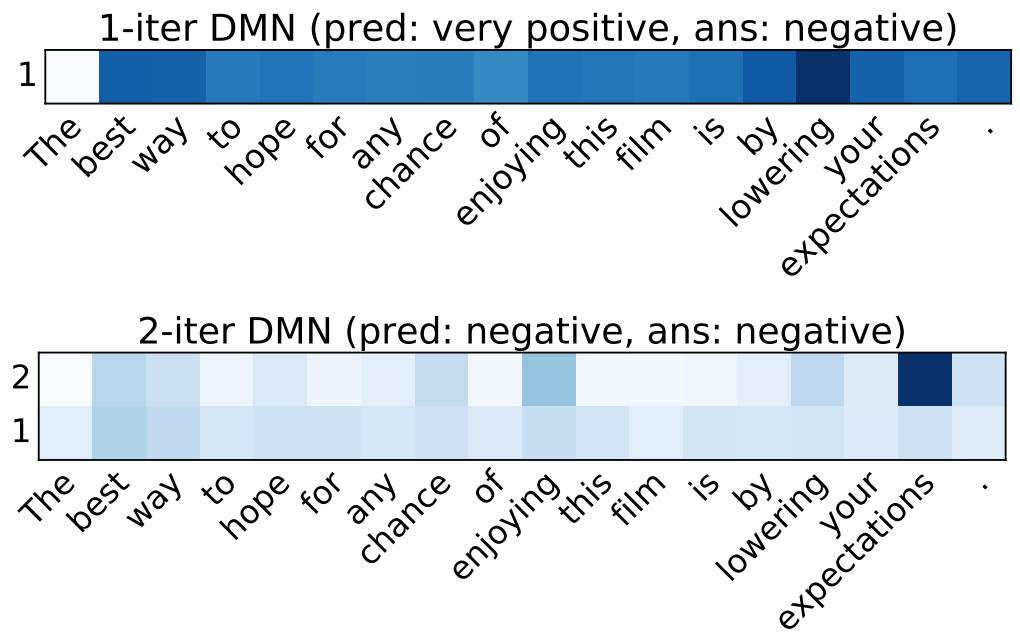
For sentiment analysis, two passes is shown to provide the best results. Both examples are incorrect with one pass.
The best way to hope for any chance of enjoying this film is by lowering your expectations.
Accuracy: Visual Question Answering

Accuracy: Visual Question Answering

Accuracy: Visual Question Answering

Accuracy: Visual Question Answering

Shared architectures can work,
what about jointly training tasks?
We noted earlier primitive transfer learning:
Pretrained word vectors
(word2vec, GloVe, ...)
Pretrained ImageNet weights
(AlexNet, VGG, Inception, ResNet, ...)
Once we have these weights, we don't touch the original data anymore ...
In the optimal world we should continue consulting these datasets if they're useful!
Upgraded word representations
For each word, we want both
word level and char level knowledge
Cat = [word(Cat); char(Cat)]
word(Cat) is standard Skipgram word vector
char(Cat) trains n-grams with Skipgram,
C, a, t
^C Ca at t$
^Ca Cat at$
then averages the resulting vectors of the unique character n-grams
Levels of our Joint Many Task model
The JMT model is composed of:
(Word level) POS
(Word level) Chunking
(Syntactic level) Dependency
(Semantic level) Relatedness
(Semantic level) Entailment
Each layer feeds in to the next layer, building a progressively enriched representation
Work by Kazuma Hashimoto, Caiming Xiong,
Yoshimasa Tsuruoka & Richard Socher
(Hashimoto (intern) and Tsuruoka from University of Tokyo)
(Semantic level) Entailment
(Semantic level) Relatedness
Each layer feeds in to the next layer, building a progressively enriched representation
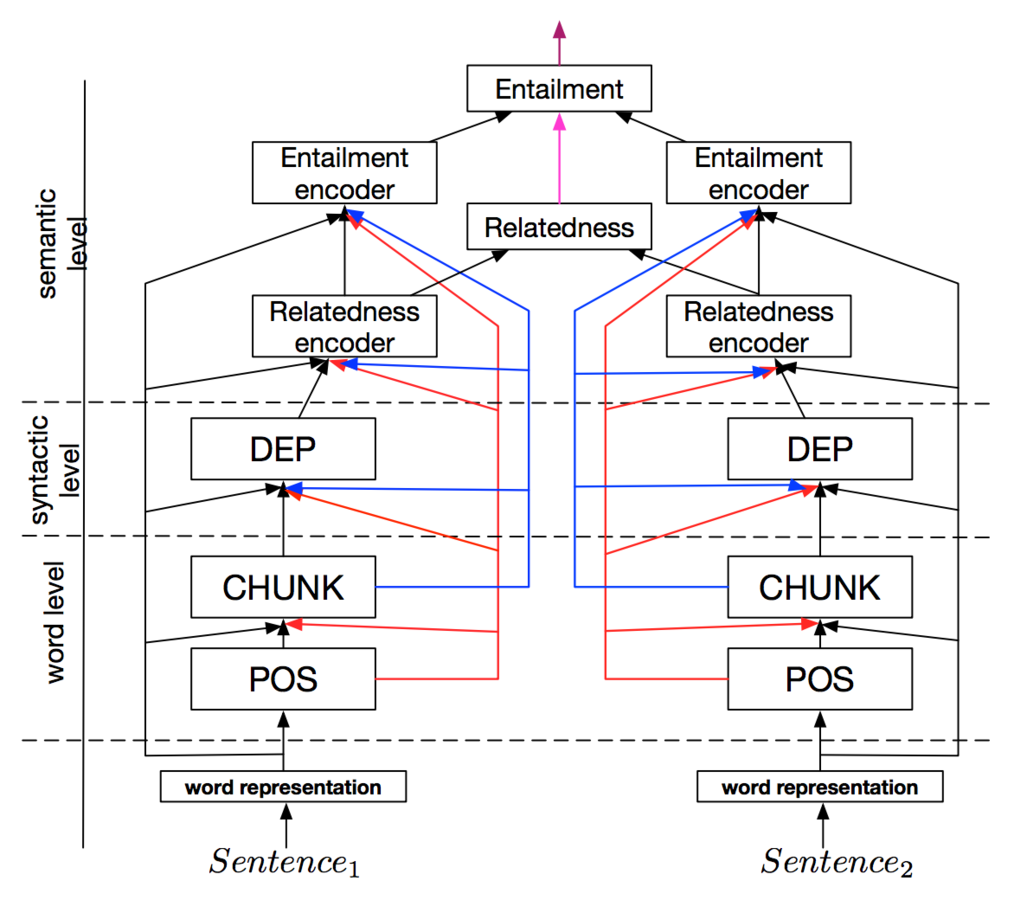
(Syntactic level) Dependency
(Word level) Chunking
(Word level) POS
Levels of our Joint Many Task model
The model is trained jointly.
To prevent the potential for
catastrophic interference
we penalize modifications to the lower level weights.
(Uses L2 regularization)
Training moves from the lowest dataset to the highest.
(i.e. POS ⇒ chunk ⇒ dep ⇒ ...)
Levels of our Joint Many Task model
Training moves from the lowest dataset to the highest.
(i.e. POS ⇒ chunk ⇒ dep ⇒ ...)
Training the Joint Many Task model
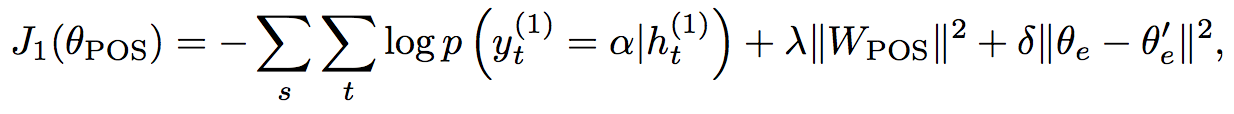
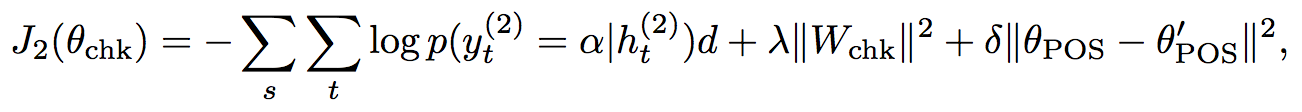
Loss = Cross Entropy + L2 Regularization + Successive Regularization
The training regime and successive regularization are important:
Joint Many Task Results
Achieves state of the art on
4 out of 5
of the tasks
(everything except POS)
Joint training substantially helps the majority of tasks
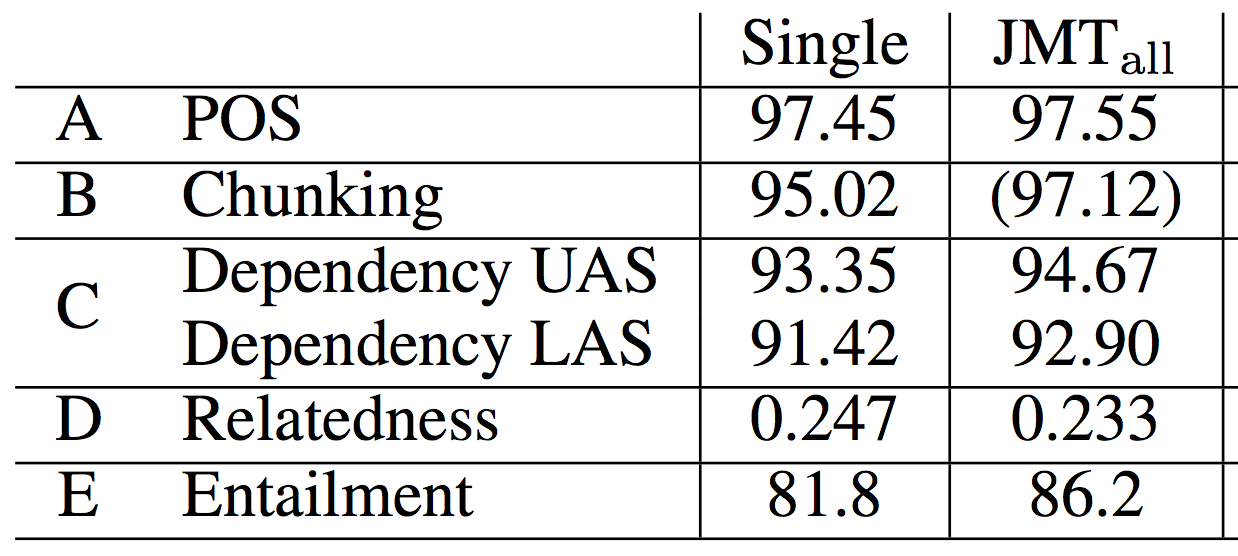
Higher is better for all tasks
except relatedness
Joint Many Task SotA
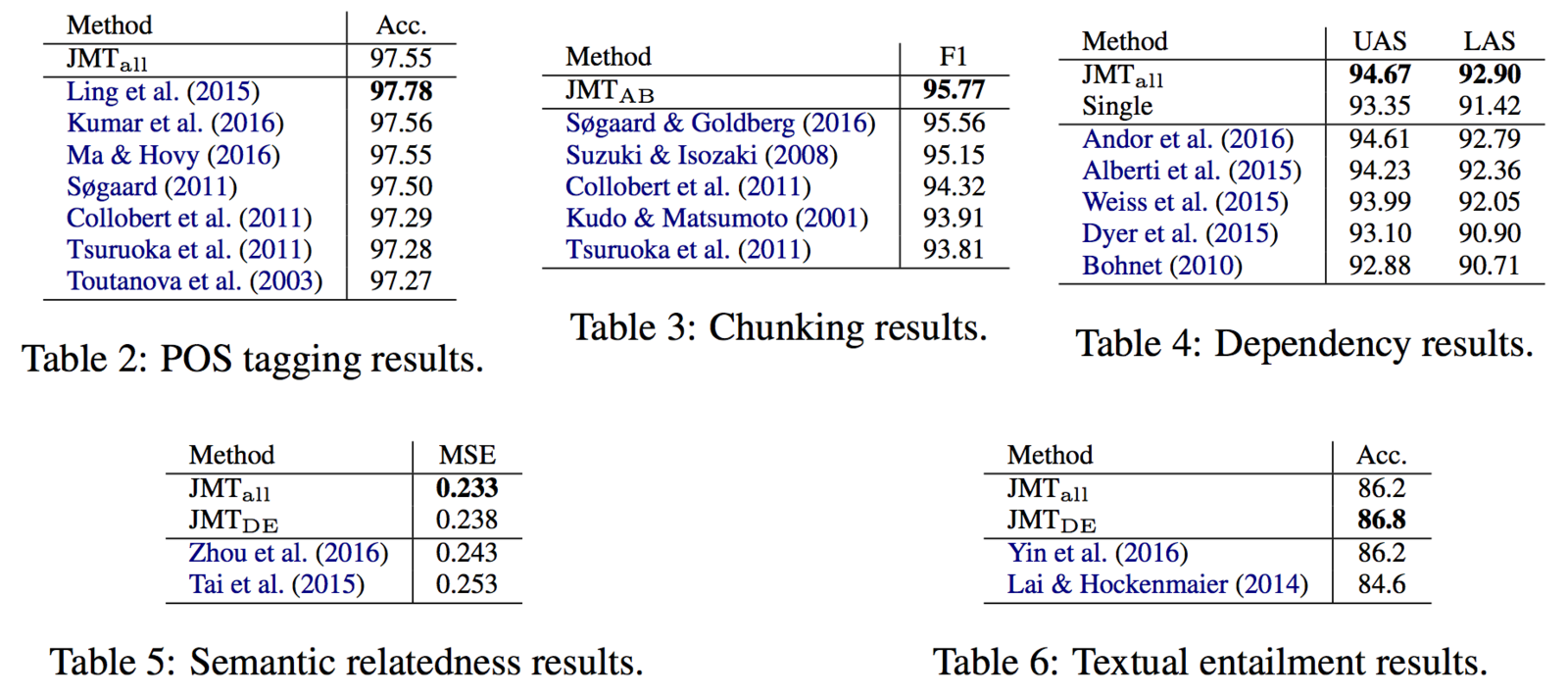
State of the art on 4 of the 5 highly competitive tasks
we experimented over
Why is JMT important?
Now we can leverage the pretrained set of weights and knowledge
(Word level) POS
(Word level) Chunking
(Syntactic level) Dependency
(Semantic level) Relatedness
(Semantic level) Entailment
(New level) Your task
New tasks can be slotted in to the existing architecture and take advantage of the
progressively enriched representation
Improving single architecture and building blocks
Shared architectures and joint many task models have many advantages but are slow and temperamental (for now)
Pushing state of the art with specific architectures is important - helps lay the groundwork for later joint models
We're also highly interested in extending the building blocks
Extending QA attention passes w/ Dynamic Coattention Network
DMN and other attention mechanisms show the potential for multiple passes to perform complex reasoning
Particularly useful for tasks where transitive reasoning is required or where answers can be progressively refined
Can this be extended to full documents?
Note: work from my amazing colleague -
Caiming Xiong, Victor Zhong, and Richard Socher
Extending QA attention passes w/ Dynamic Coattention Network
Stanford Question Answering Dataset (SQuAD) uses Wikipedia articles for question answering over textual spans


Dynamic Coattention Network
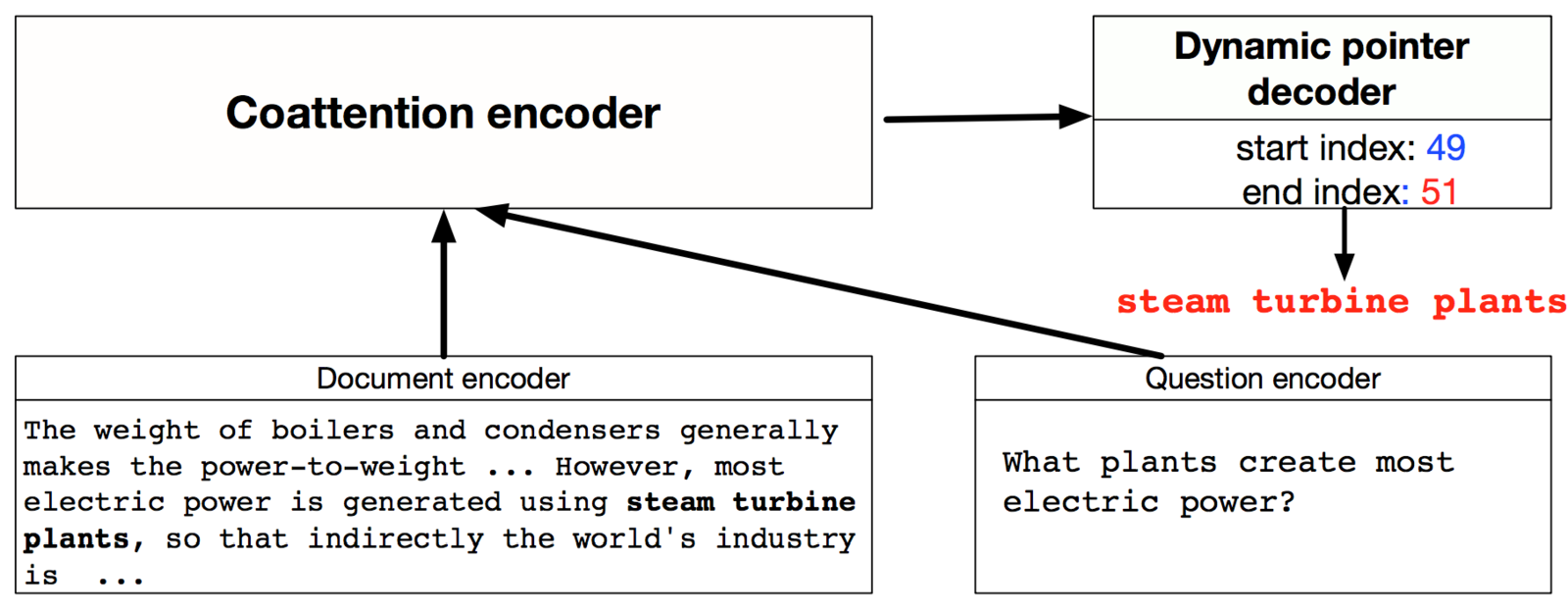
The overarching concept is relatively simple:
Dynamic Coattention Network
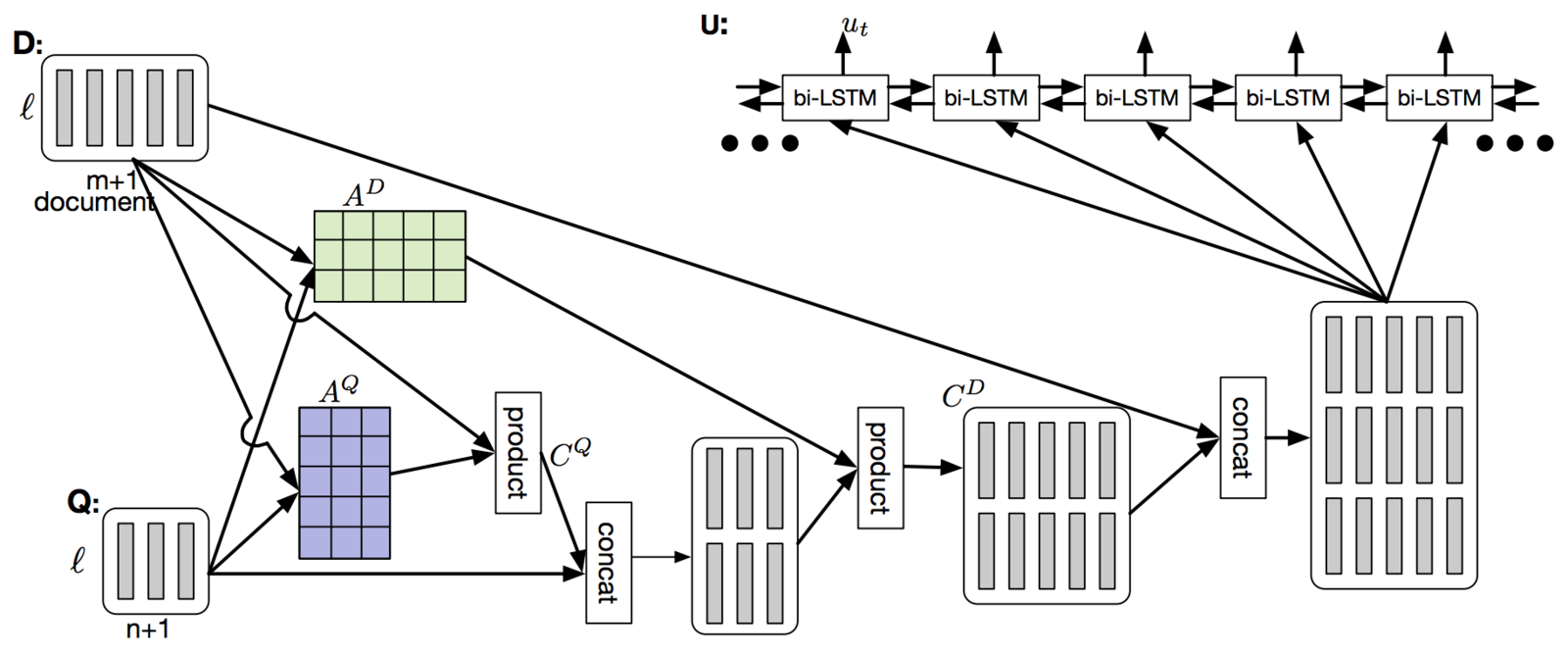
Encoder for the Dynamic Coattention Network
It's the specific implementation that kills you ;)
Dynamic Coattention Network

Explaining the architecture fully is complicated but intuitively:
Iteratively improve the start and end points of the answer
as we perform more passes on the data
Dynamic Coattention Network
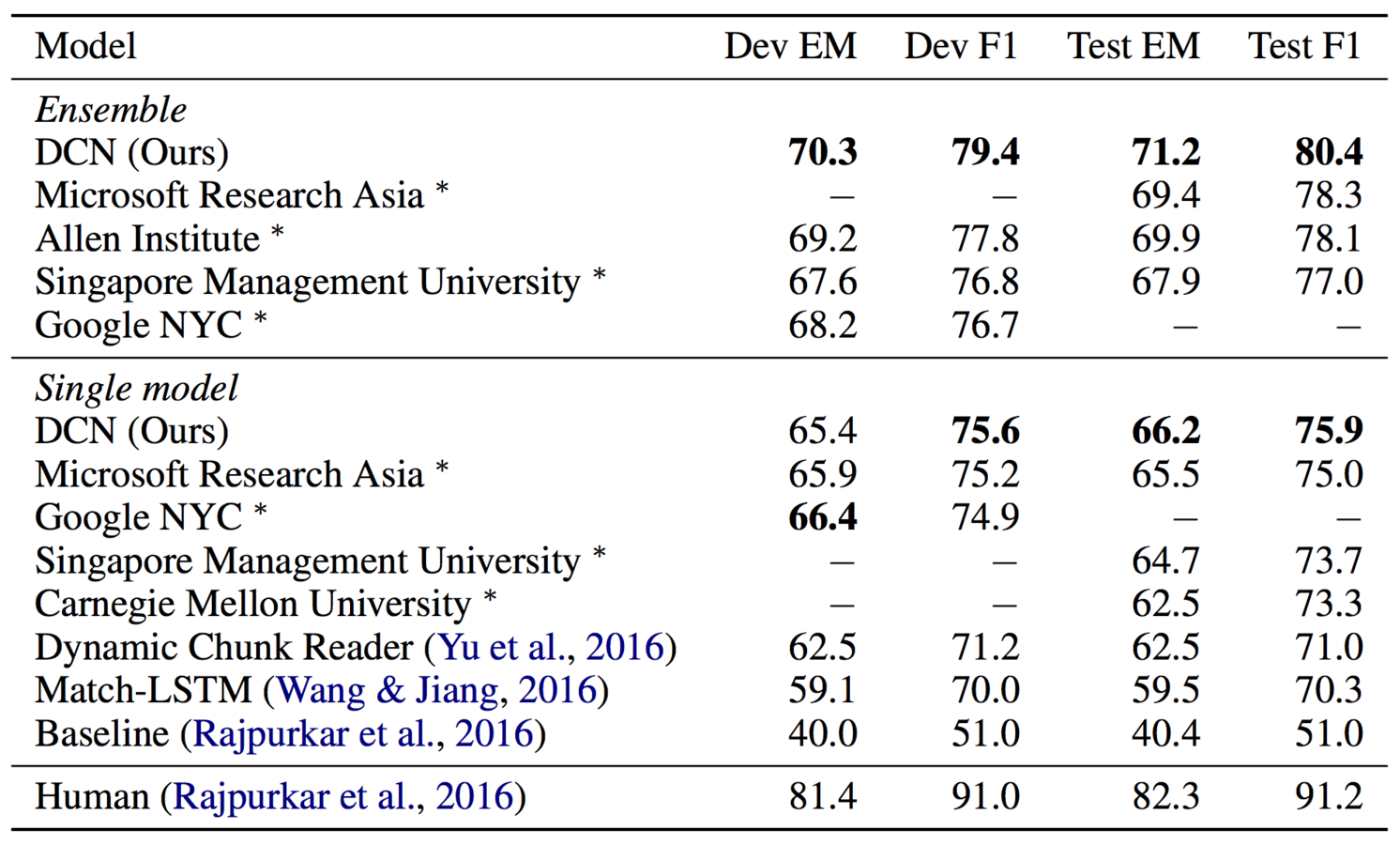
Improving building blocks: RNNs
For our work, recurrent neural networks are a core tool
though they do have fundamental limitations
Overfitting is a major problem
Slow for both training and prediction

Regularizing RNNs
RNNs can overfit strongly on the recurrent connections
Dropout on recurrent connections does not work by default -
the dropout is applied too many times, killing RNN's memory
Regularizing RNNs
Variational LSTM (Gal et al. 2015)
I informally refer to it as "locked dropout":
you lock the dropout mask once it's used
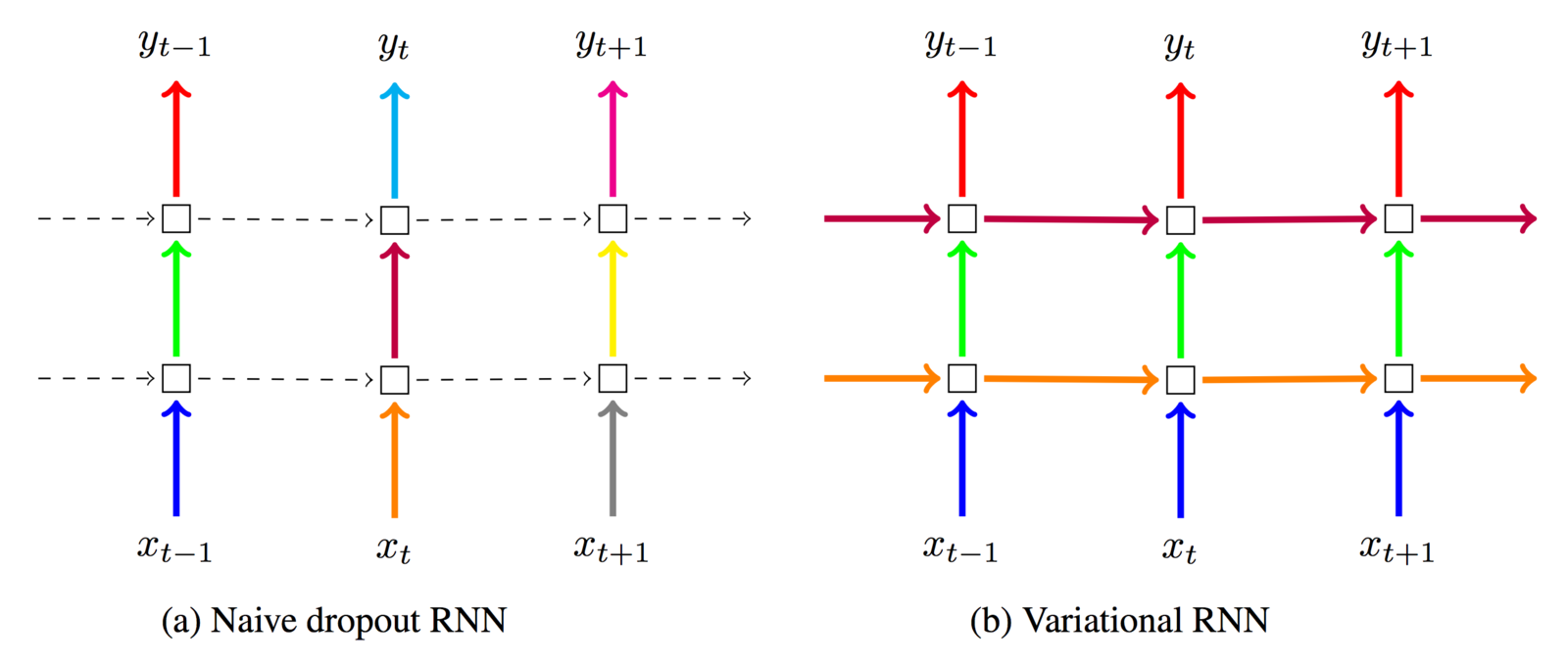
Regularizing RNNs
Variational LSTM (Gal et al. 2015)
Gives major improvement over standard LSTM, simplifies the prevention of overfitting immensely
Regularizing RNNs
IMHO, though Gal et al. used it for LM, best for
recurrent connections on short sequences
(portions of the hidden state h are blacked out until the dropout mask is reset)
Regularizing RNNs
Zoneout (Krueger et al. 2016)
Stochastically forces some of the recurrent units in h to maintain their previous values
Imagine a faulty update mechanism:
where delta is the update and m the dropout mask
h_t = h_{t-1} + m \odot \delta_t
Regularizing RNNs
Zoneout (Krueger et al. 2016)
Offers two main advantages over "locked" dropout
+ "Locked" dropout means |h| x p of the hidden units are not usable (dropped out)
+ With zoneout, all of h remains usable
(important for lengthy stateful RNNs in LM)
+ Zoneout can be considered related to stochastic depth which might help train deep networks
Improving building blocks: RNNs
For our work, recurrent neural networks are a core tool
though they do have fundamental limitations
Overfitting is a major problem
Slow for both training and prediction
Improving RNN speed via QRNNs
James Bradbury and I created quasi-recurrent neural networks (QRNNs) to maximize RNN speed without losing accuracy
For standard RNNs, matrix multiplications at each timestep depend on the output of the previous timestep
This forces us into a sequential process that doesn't use the GPU well

Red signifies convolutions or matrix multiplications
Blue signifies parametersless functions
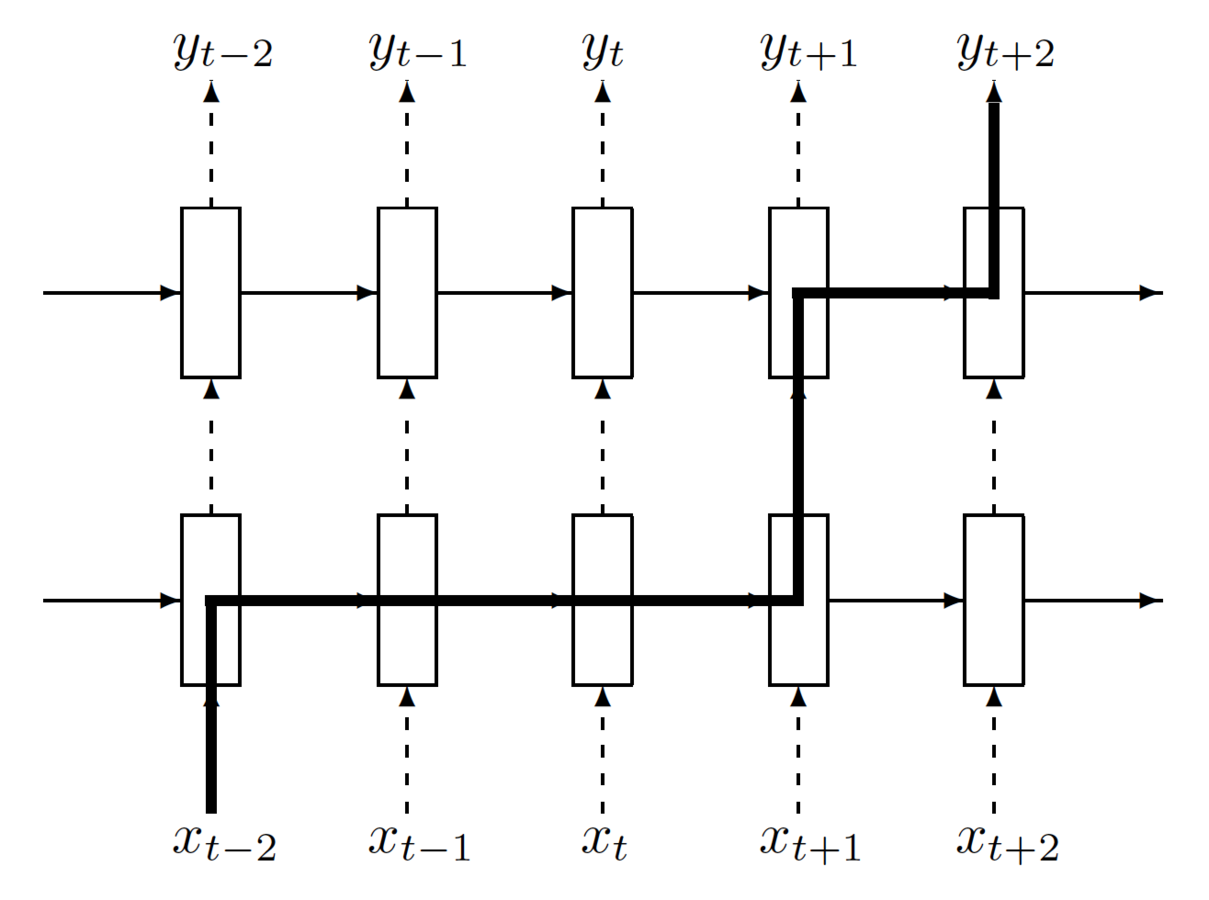
Improving RNN speed via QRNNs
Key ideas:
take inspiration from CNNs in only allowing fully parallel operations,
make the recurrent function (which is sequential by necessity)
as minimal and efficient as possible
Red signifies convolutions or matrix multiplications
Blue signifies parametersless functions
Improving RNN speed via QRNNs
Looking at the equations for a minimal LSTM (no input gate),
the use of the previous hidden state is the bottleneck
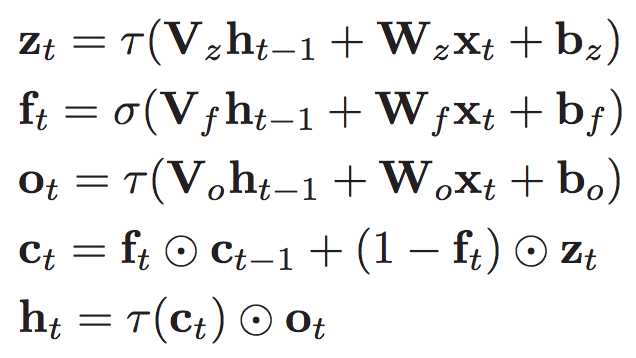
By replacing h with a convolution over the input x,
we may lose some computational capacity but we can be far more parallel
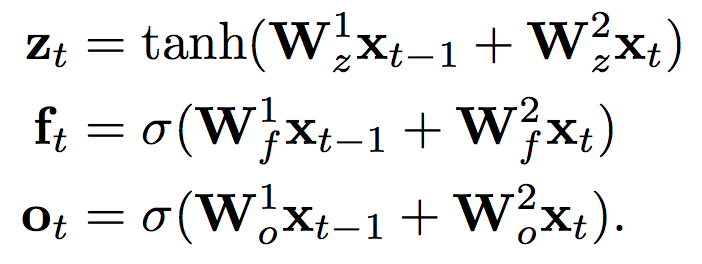
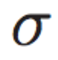
Improving RNN speed via QRNNs
This results in the output of c being "dynamic average pooling",
where the average pooling is controlled by the gates f
Here we show an example for a convolutional filter width of 2,
though there is no limitation over the filter width
The only recurrent connection is in blue and the computation is efficient on GPUs
QRNN results: IMDb
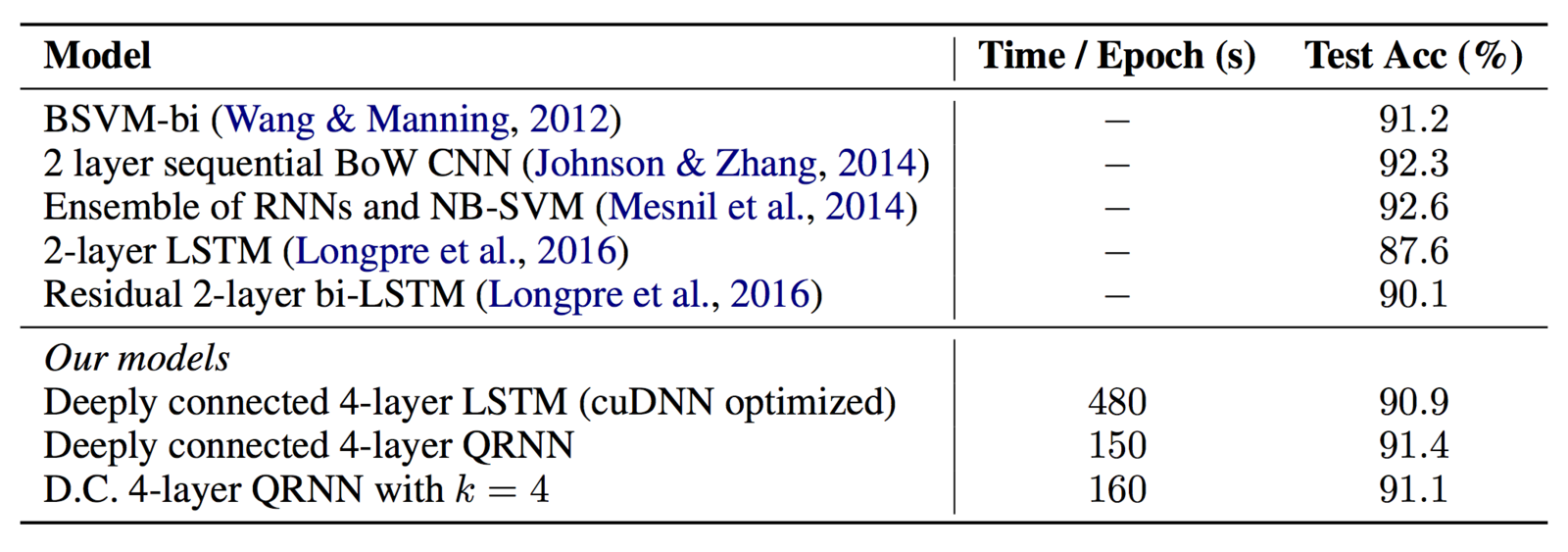
The IMDb dataset is near worst case for LSTMs due to long documents
(a) very slow for LSTMs and (b) gradient disappears quickly
Achieves better than previous LSTM approaches and is over 3x faster
(note: compared to highly optimized Nvidia cuDNN library)
QRNN results: language modeling
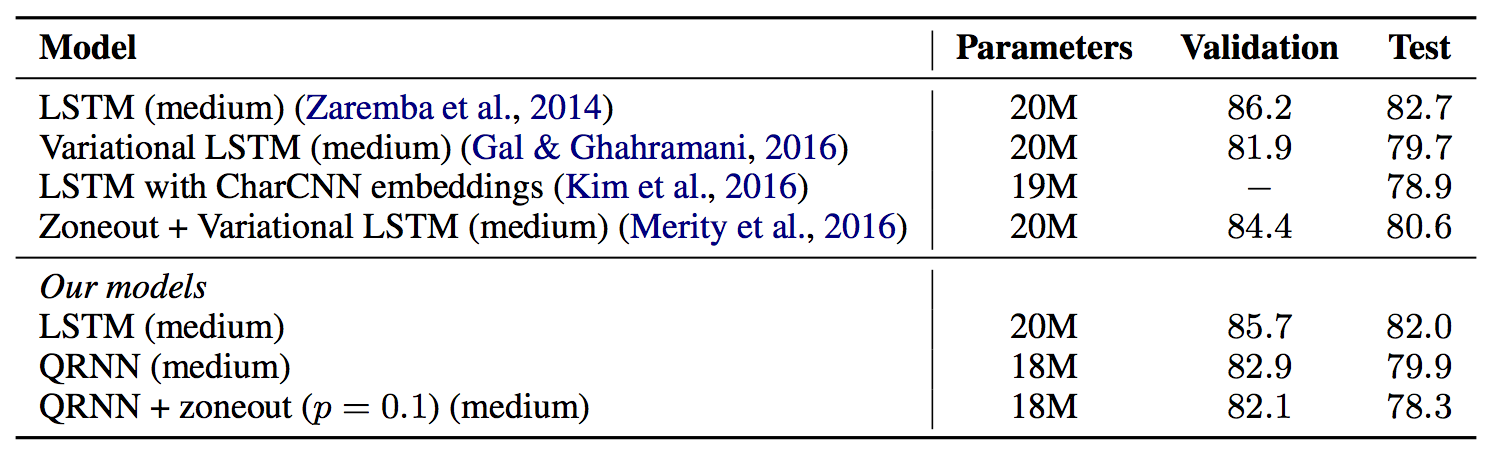
Language modeling is a standard task for RNNs and frequently used to test recurrent regularization techniques
The QRNN achieves similar results as strongly regularized LSTMs
(How? The recurrent capacity is limited - minimal need to regularize)
QRNN results: character level MT

Character level machine translation holds great promise for morphologically rich languages like German
(only recently have they achieved similar accuracy to word level)
QRNNs with convolutional window of 6 (i.e. look at the last six characters) achieves better results and are over 4x faster than comparable LSTMs
QRNN speed breakdown
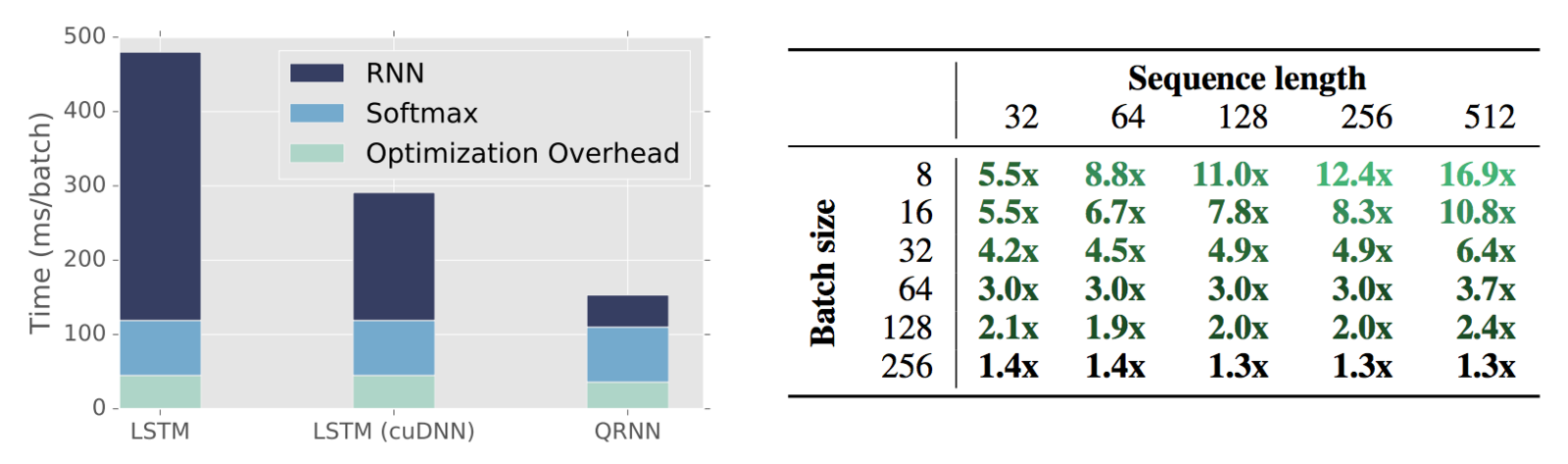
Forward + backward times for a single batch in language modeling
(note: RNN used to be the dominant component, for QRNN it's softmax)
Inference speed advantage of
QRNN compared to cuDNN LSTM
(note: longer sequences is better!)
Summary
- Attention and memory can improve logical reasoning and avoid the information bottlenecks prevalent in architectures
- While complex, joint many task models can leverage multiple datasets to achieve better results via transfer learning
- If you're using LSTMs, make sure you perform recurrent dropout! QRNN is also an interesting avenue of exploration ;)
- This is still early days!
Extra content!
(if reading online, the majority of the following slides require you to navigate downwards, not just sideways)
Improving building blocks: RNNs
For our work, recurrent neural networks are a fundamental tool
Hidden state is limited in capacity
Vanishing gradient still hinders learning
Encoding / decoding rare words is problematic
Pointer Networks
What if you're in a foreign country and you're ordering dinner ....?
You see what you want on the menu but
can't pronounce it :'(
Pointer Networks!
(Vinyals et al. 2015)
Pointer Networks
What if you're in a foreign country and you're ordering dinner ....?
You see what you want on the menu but
can't pronounce it :'(
Pointer Networks help tackle the
out of vocabulary problem
(most models are limited to a pre-built vocabulary)
Pointer Networks

Convex Hull
Delaunay Triangulation
The challenge: we don't have a "vocabulary" to refer to our points (i.e. P1 = [42, 19.5])
We need to reproduce the exact point
Pointer Networks

Notice: pointing to input!
Pointer Networks


Attention Sum (Kadlec et al. 2016)

Pointer Networks
Pointer networks avoid storing the identity of the word to be produced.
Why is this important?
In many tasks, the name is a placeholder.
In many tasks, the documents are insanely long.
(you'll never have enough working memory!)
Pointer networks avoid storing redundant data :)
Pointer Networks
Big issue:
What if the correct answer isn't in our input..?
... then the pointer network can never be correct!
We could use an RNN - it has a vocabulary - but then we lose the out of vocabulary words that the pointer network would get ...
Joining the RNN and pointer
General concept is to combine two vocabularies:
vocabulary softmax (RNN) and positional softmax (ptr)
There are multiple ways to combine these models...
Gulcehre et al. 2016 use a "switch" that decides between vocabulary and pointer for NMT and summarization
(only selects the maximum, doesn't do mixing)
Pointer Sentinel (Merity et al. 2016)

Use the pointer to determine how to mix the vocabulary and pointer softmax together
Pointer Sentinel (Merity et al. 2016)
Any probability mass the pointer gives to the sentinel is passed to the vocabulary softmax
Pointer Sentinel (Merity et al. 2016)

Pointer Sentinel (Merity et al. 2016)
The pointer decides when to back off to the vocab softmax
This is important as the RNN hidden state has limited capacity and can't accurately recall what's in the pointer
The longer the pointer's window becomes,
the more true this is
"Degrades" to a straight up mixture model
If g = 1, only vocabulary - If g = 0, only pointer
The pointer helps the RNN's gradients
The pointer sentinel mixture model changes the gradient flow
The pointer helps the RNN as the gradient doesn't need to traverse many previous timesteps
The pointer helps the RNN's gradients
For the pointer to point to the correct output,
the RNN is encouraged to make the hidden states at the two locations (end and input target) similar
Pointer sentinel really helps rare words
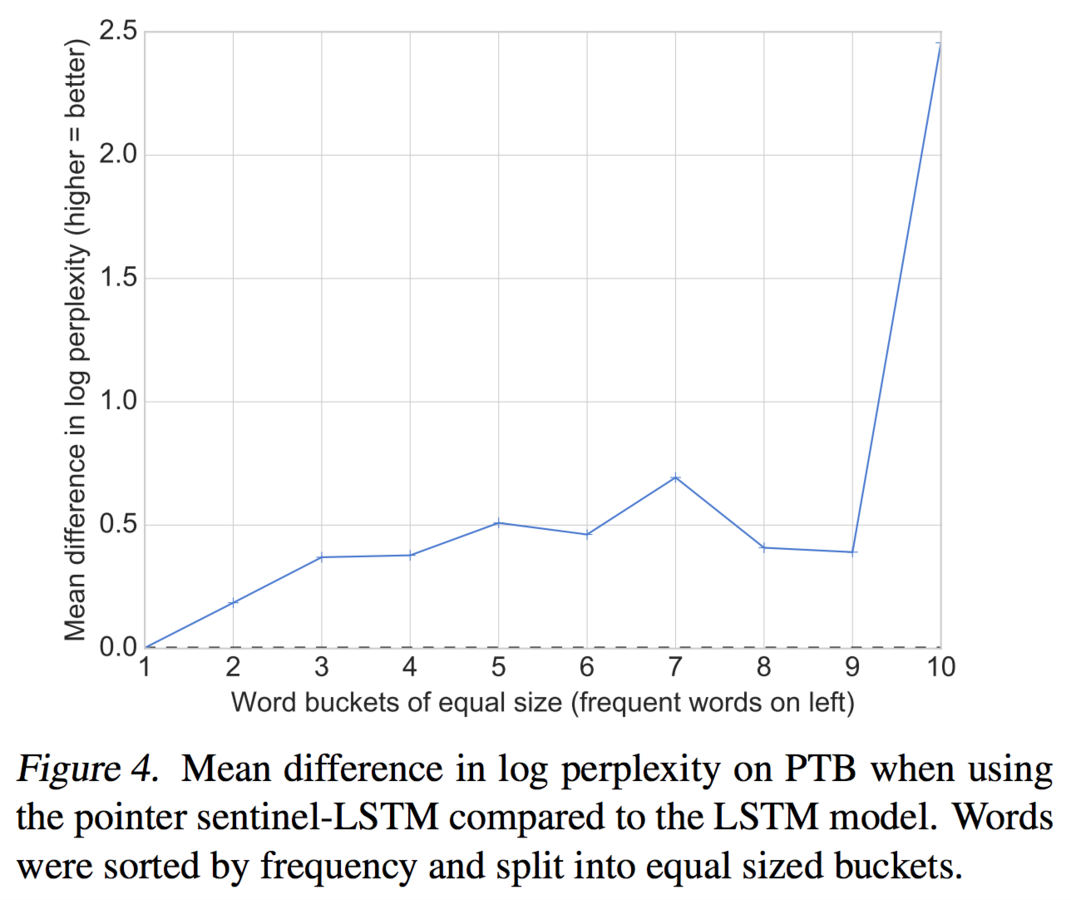
Pointer Sentinel-LSTM

State of the art results on language modeling
(generating language and/or autocompleting a sentence)

Hierarchical Attentive Memory
(Andrychowicz and Kurach, 2016)

Hierarchical Attentive Memory
Tree structured memory = O(log n) lookup
Hierarchical Attentive Memory
Tree structured memory = O(log n) lookup
HAM can learn to sort in O(n log n)
Netflix - New Methods for Memory, Attention, and Efficiency in Neural Networks
By smerity



