Stephen Merity, Caiming Xiong,
James Bradbury, Richard Socher
MetaMind - A Salesforce Company
@smerity

Stanford Deep Learning Reading Group
What I want you to learn
-
Many RNN encoder-decoder models need to (poorly) relearn one-to-one token mappings
-
Recurrent dropout - use it (Gal or zoneout)
-
Pointer networks are really promising + interesting
(pointer sentinel helps pull off joint learning) -
Ensembles can do better via joint learning
-
Mikolov PTB has issues - know what they are
-
LM + BPTT training has issues
By accurately assigning probability to a natural sequence, you can improve many tasks:
Machine Translation
p(strong tea) > p(powerful tea)
Speech Recognition
p(speech recognition) > p(speech wreck ignition)
Question Answering / Summarization
p(President X attended ...) is higher for X=Obama
Query Completion
p(Michael Jordan Berkeley) > p(Michael Jordan basketball)
Natural sequence ⇒ probability
p(S) = p(w_1, w_2, w_3, \ldots, w_n)
Break this down to probability of next word via chain rule of probability
p(w_n|w_1, w_2, w_3, \ldots, w_{n-1})
Given a sequence - in our case S is a sentence composed of the words W = [w1, w2, ..., wn]
Progression of language models
h_t, y_t = \text{RNN}(x_t, h_{t-1})
N-grams used to be all the rage
RNN variants, although computationally intensive, now hold the state of the art

Progression of language models
h_t, y_t = \text{RNN}(x_t, h_{t-1})
Encode previous relevant context from x,
store it for many time steps in h,
decode relevant context to y when appropriate
Regularizing RNN LMs
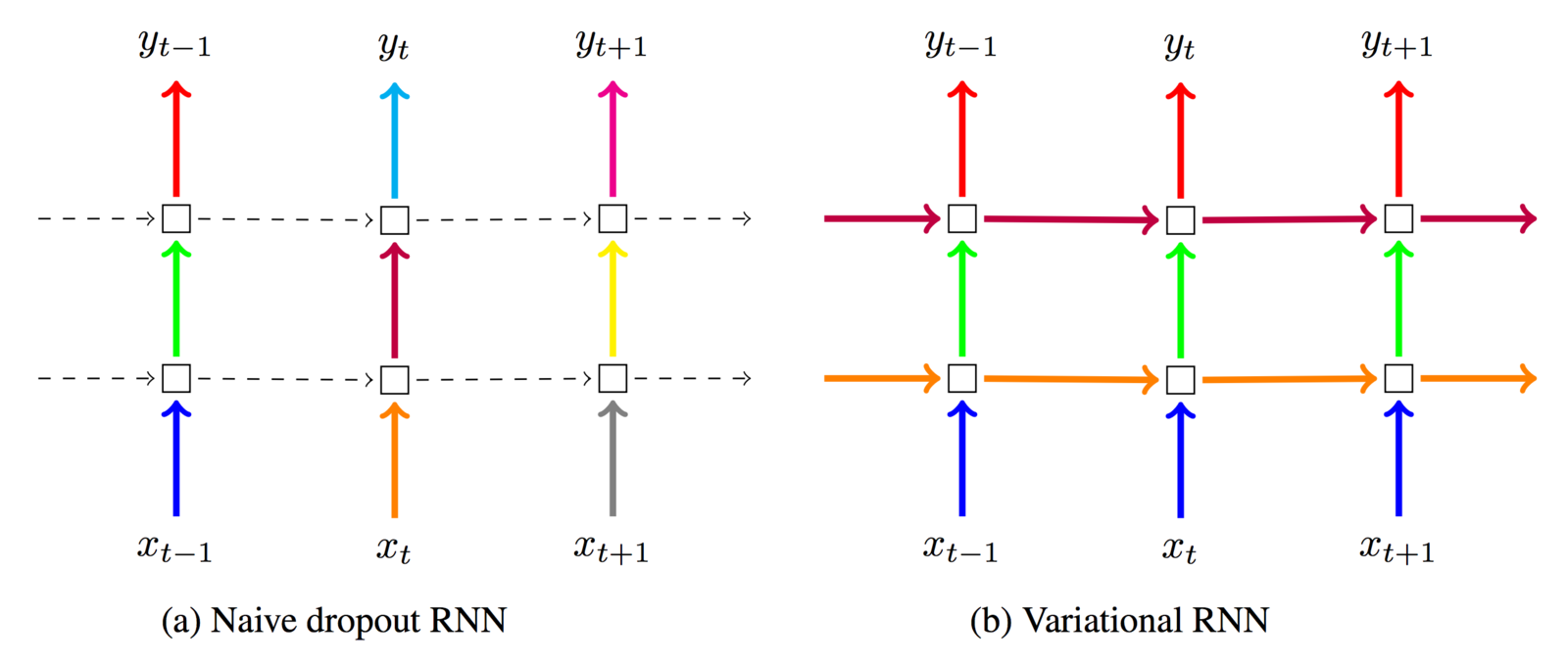
Variational LSTM (Gal et al. 2015)
I informally refer to it as "locked dropout":
you lock the dropout mask once it's used
Regularizing RNN LMs
Variational LSTM (Gal et al. 2015)
Gives major improvement over standard LSTM, simplifies the prevention of overfitting immensely
Regularizing RNN LMs
IMHO, though Gal et al. did it for LM, best for
recurrent connections on short sequences
(portions of the hidden state h are blacked out until the dropout mask is reset)
Regularizing RNN LMs
Zoneout (Krueger et al. 2016)
Stochastically forces some of the recurrent units in h to maintain their previous values
Imagine a faulty update mechanism:
where delta is the update and m the dropout mask
h_t = h_{t-1} + m \odot \delta_t
Regularizing RNN LMs
Zoneout (Krueger et al. 2016)
Offers two main advantages over "locked" dropout
+ "Locked" dropout means |h| x p of the hidden units are not usable (dropped out)
+ With zoneout, all of h remains usable
(important for lengthy stateful RNNs in LM)
+ Zoneout can be considered related to stochastic depth which might help train deep networks
Issues with RNNs for LM
Hidden state is limited in capacity
Vanishing gradient still hinders learning
Encoding / decoding rare words is problematic
Issues with RNNs for LM
Hidden state is limited in capacity
RNNs for LM do best with large hidden states
... but parameters increase quadratically with h
(attention tries to help with this but attention hasn't been highly effective for LM)
Issues with RNNs for LM
Vanishing gradient still hinders learning
"LSTMs capture long term dependencies"
... yet we only train BPTT for 35 timesteps?
Issues with RNNs for LM
Encoding / decoding rare words is problematic
+ The word vectors need to get in sync with the softmax weights (learn a one-to-one mapping)
+ The RNN needs to learn to encode the word and then decode it when appropriate
Pointer Networks (Vinyals et al. 2015)

Convex Hull
Delaunay Triangulation
The challenge: we don't have a "vocabulary" to refer to our points (i.e. P1 = [42, 19.5])
We need to reproduce the exact point
Pointer Networks (Vinyals et al. 2015)

Pointer Networks (Vinyals et al. 2015)


Pointer Networks
Pointer networks avoid needing to learn to store the identity of the word to be produced
(works well on limited data!)
Why is this important?
Helps solve the rare / OoV words problem
... but only if the word is in the input
Pointer Networks
Pointer networks also provide direct supervision
The pointer is directed to attend to any words in the input that are the correct answer
(explicitly instructed re: one-to-one mapping)
Vaguely similar to attention except attention mechanisms need to learn this alignment themselves
Attention Sum (Kadlec et al. 2016)

Pointer Networks
Big issue:
What if the correct answer isn't in our input..?
... then the pointer network can never be correct!
We could use an RNN - it has a vocabulary - but then we lose the out of vocabulary words that the pointer network would get ...
Joining RNN and Pointer
General concept is to combine two vocabularies:
vocabulary softmax (RNN) and positional softmax (ptr)
There are multiple ways to combine these models...
Gulcehre et al. 2016 use a "switch" that decides between vocabulary and pointer for NMT and summarization
(only selects the maximum, doesn't do mixing)
Pointer Sentinel

Use the pointer to determine how to mix the vocabulary and pointer softmax together
Pointer Sentinel
Any probability mass the pointer gives to the sentinel is passed to the vocabulary softmax
Pointer Sentinel

Why is the sentinel important?
The pointer decides when to back off to the vocab softmax
This is important as the RNN hidden state has limited capacity and can't accurately recall what's in the pointer
The longer the pointer's window becomes,
the more true this is
Why is the sentinel important?
"Degrades" to a straight up mixture model
If g = 1, only vocabulary
If g = 0, only pointer
Training the pointer sentinel model
RNN LMs by default use short windows for BPTT
(the default is only 35 timesteps!)
The pointer network wants as large a window as possible - it's not constrained by storing information in a hidden state
(the stored RNN outputs are essentially a memory network)
We keep saying LSTMs do well for long term dependencies but ...
we train them with BPTT
for only 35 timesteps
Training the pointer sentinel model
A relatively undiscussed issue with training RNN LMs ...
BPTT(35) means backprop for 35 ts, leap 35 ts, repeat...
When you use BPTT for 35 timesteps,
the majority of words have far less history
The word at the start of the window
only backprops into the word vector
(exacerbated by not shuffling batch splits in LM data)
Training the pointer sentinel model
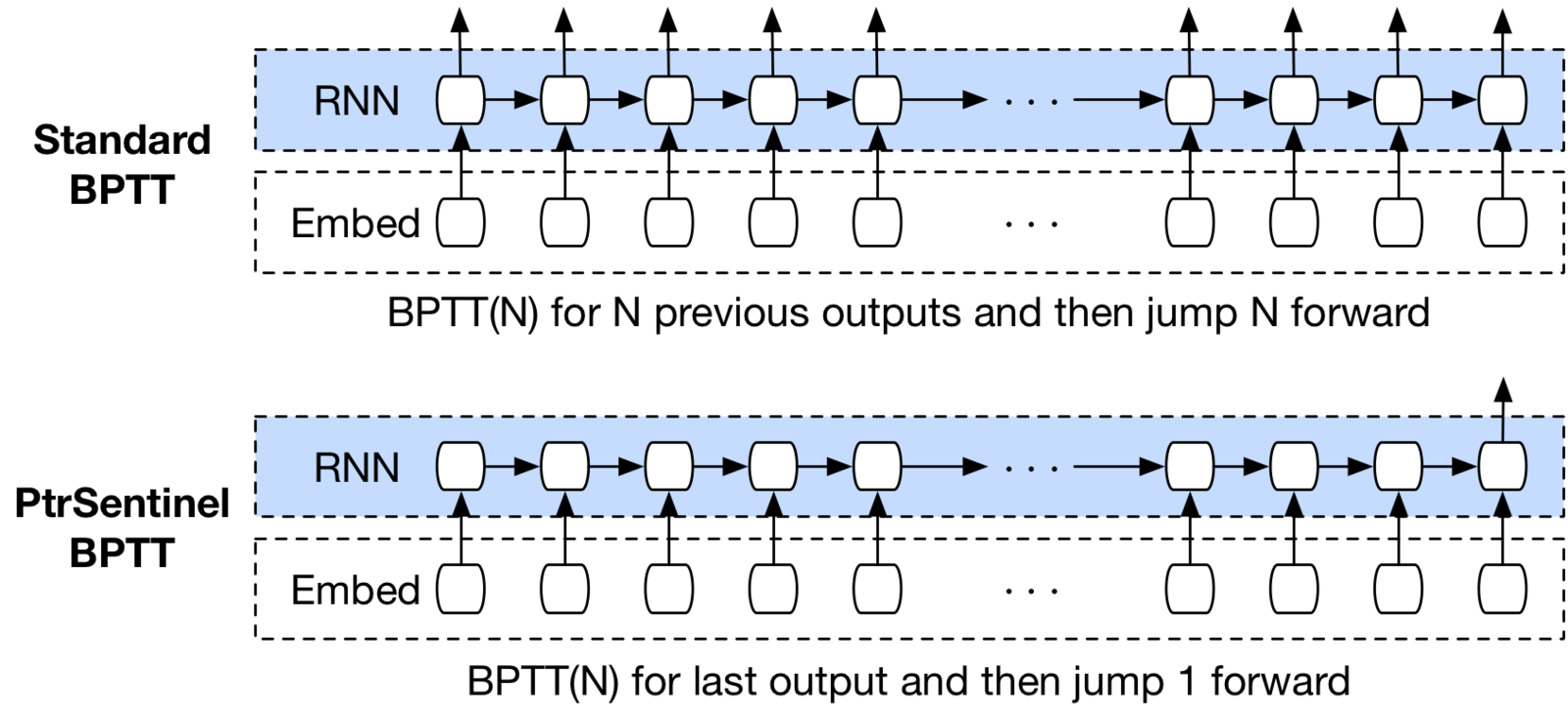
Training the pointer sentinel model
BPTT(100) for last output and then jump one forward
Training the pointer sentinel model
+ Safest tactic is just to regenerate all stale outputs
... but regenerating RNN outputs for last 100 words is slow
(working with stale outputs / gradients may be interesting ..?)
+ Aggressive gradient clipping is important early
(100 steps before any error signal ⇒ gradient explosion)
+ Plain SGD works better than ADAM etc (rarely discussed)
(GNMT for example starts with ADAM then uses SGD)
The pointer helps the RNN's gradients
The pointer sentinel mixture model changes the gradient flow
The pointer helps the RNN as the gradient doesn't need to traverse many previous timesteps
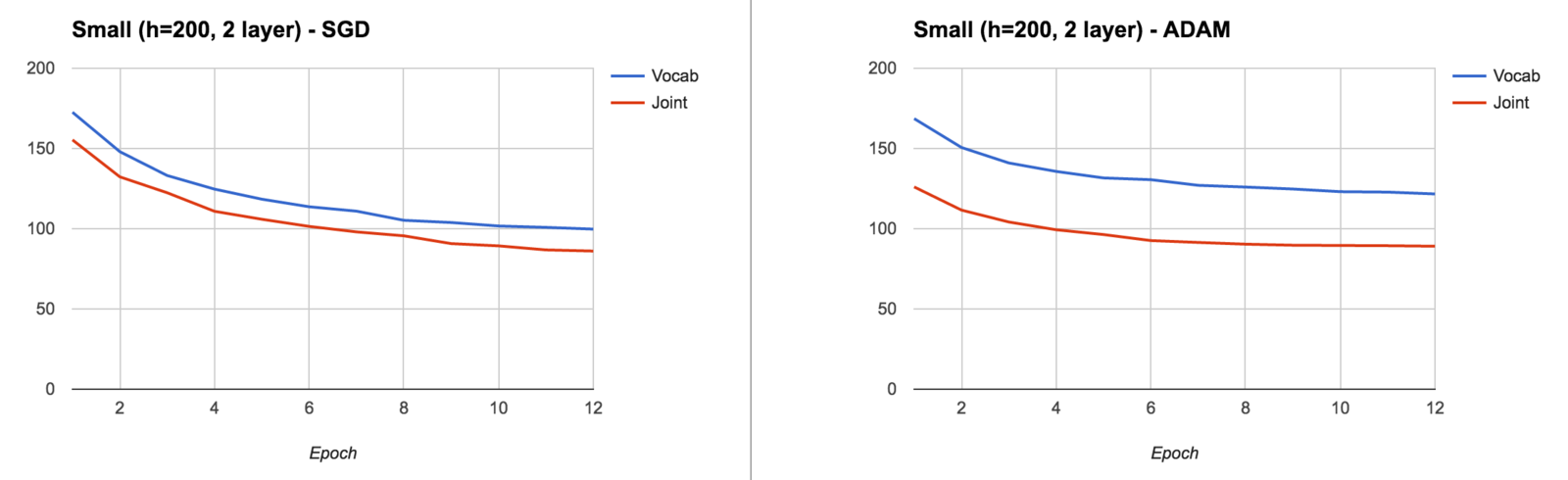
The pointer helps the RNN's gradients
For the pointer to point to the correct output,
the RNN is encouraged to make the hidden states at the two locations (end and input target) similar
Slower to train, similar predict
Important to note that, while pointer sentinel mixture models are slower to train, their run time is very similar
Previous RNN outputs are fully cached
Total additional computation is minimal compared to standard RNN LM
(especially when factoring in h required for similar perplexity)
Mikolov Penn Treebank (PTB)
+ Only 10k vocabulary
+ All lowercase
+ No punctuation
+ Numbers replaced with N

Mikolov Penn Treebank (PTB)

Aside: character level Mikolov PTB is ... odd ...
Literally the word level dataset in character form
+ Larger vocabulary (unk'ing freq <3)
+ Numbers, caps, punctuation are retained

Dataset comparison

+ WikiText-2 and PTB are of similar size
+ WikiText-2 has a more realistic vocab long tail
+ WikiText-103 is over 1/10th One Billion LM
(this makes working with it non-trivial)
Results (PTB)
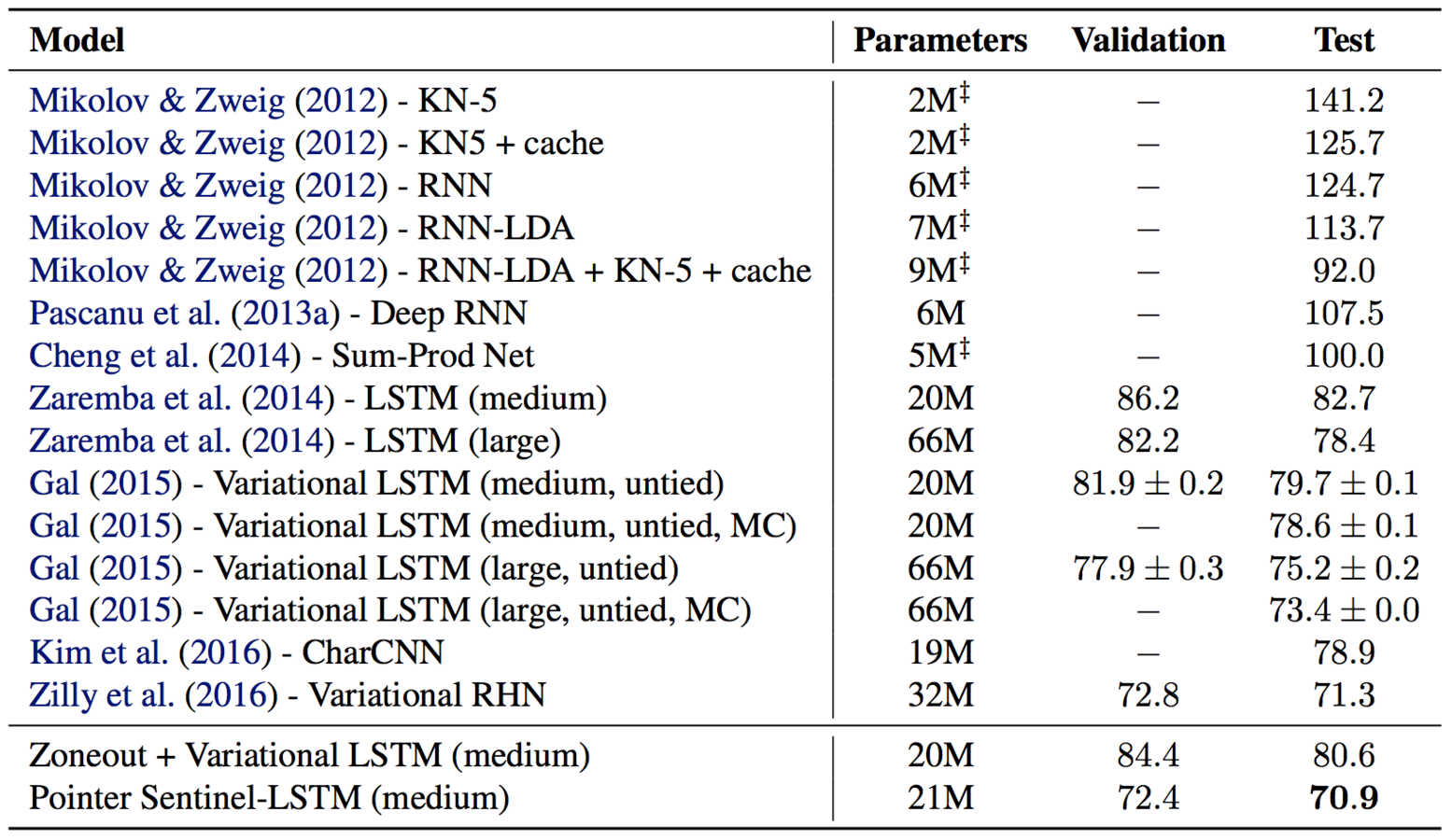
Results (PTB)
Results (WikiText-2)

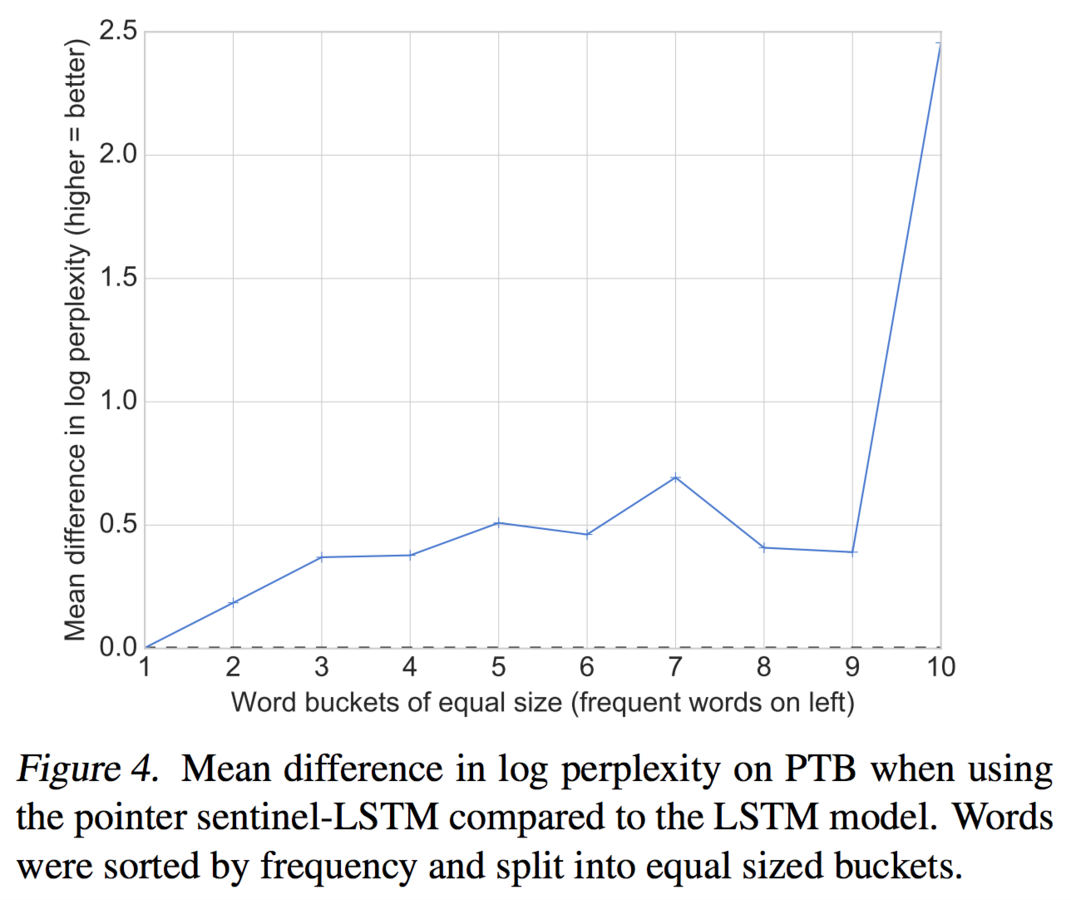
Pointer sentinel really helps rare words
Examples
federal researchers said lung-cancer mortality rates for people under N years of age have begun to decline particularly for white males <eos>
the national cancer institute also projected that overall u.s. ???

Examples
a merc spokesman said the plan has n't made much difference in liquidity in the pit <eos>
it 's too soon to tell but people do n't seem to be unhappy with it he ???

Examples
the fha alone lost $ N billion in fiscal N the government 's equity in the agency essentially its reserve fund fell to minus $ N billion <eos>
the federal government has had to pump in $ N ???

Examples
gen. douglas <unk> demanded and got in addition to his u.n. command
...
<unk> 's ghost sometimes runs through the e ring dressed like gen. ???

Examples
the pricing will become more realistic which should help management said bruce rosenthal a new york investment banker
...
they assumed there would be major gains in both probability and sales mr. ???

Examples
the sales force is viewed as a critical asset in integrated 's attempt to sell its core companies <eos>
<unk> cited concerns about how long integrated would be able to hold together the sales force as one reason its talks with integrated failed <eos>
in composite trading on the new york stock exchange yesterday ???

Conclusion
-
Find and fix information / gradient flow bottlenecks
-
Help your RNN encoder-decoder models relearn
one-to-one token mappings -
Recurrent dropout - use it! (locked, zoneout, ...)
-
Pointer networks are really promising + interesting for OoV
-
Try joint learning of models that may usually be ensembles
(pointer sentinel helps pull off joint learning) -
Mikolov PTB has issues - at least know what they are
-
Standard LM + BPTT training is likely not optimal
Stanford - Pointer Sentinel Mixture Models
By smerity



