Fernanda Mora
fernanda-mora.com
Intro a análisis de redes sociales


Contenido
- Introducción
- Qué podemos hacer con Twitter
Introducción
Redes sociales en internet
- Individuos, grupos y comunidades que se forman dentro del contexto de internet
- Facebook (1.2) , Whatsapp (1.3), Twitter (328), Instragram (1.8), LinkedIn
- Diversos temas
- Twitter es una red social abierta en la que cualquier persona, aun sin tener cuenta, puede tener acceso a los timelines de los usuarios.
- Todas las cuentas son iguales
- Red social de microblogging: usuarios publican mensajes cortos de hasta 280 caracteres continuamente en el tiempo
Qué se puede hacer
Imagen tomada de Bengio et al., 2016
¿Qué tipo de modelos podemos usar?
- Conteos de palabras

¿Qué tipo de modelos podemos usar?
- Conteo de RTs
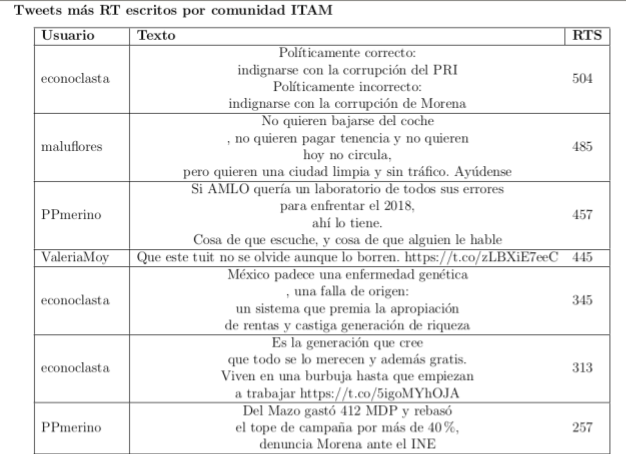
Tesis Maestría, Mauricio González
¿Qué tipo de modelos podemos usar?
- Interacciones en Twitter: seguidores -> Grafos
- Grafo: nodos (personas) y aristas (amistad entre personas)
- Maria es amigo de Pepe si Maria es seguidor de Pepe.

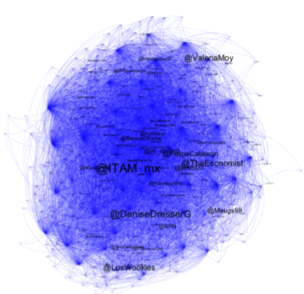
Tesis Maestría, Mauricio González
¿Qué tipo de modelos podemos usar?
- Queries sobre grafos (Neo4j)
- Hashtags más utilizados por una comunidad:
MATCH(u:User)-->(t:Tweet)<-[r:TAGS]-(h:Hashtag)
where not t.text contains "RT"
RETURN u.username, t.text, h.name, count(r) as cuenta
order by cuenta desc
limit 10
Tesis Maestría, Mauricio González
Imagen tomada de Bengio et al., 2016
¿Qué tipo de modelos podemos usar?
- Mensajes en Twitter: analizar contenido -> Procesamiento de lenguaje natural

Imagen tomada de Bengio et al., 2016
¿Cómo podemos descargar los tweets ?
- Streaming
- En batch
- Twitter search API: permite hacer queries sobre tweets y sobre info del usuario dentro de 7 días anteriores.
- Streaming API: sí puedes recopilar todos
Imagen tomada de Bengio et al., 2016
Ejemplo procesamiento tweets
- Una vez bajando los tweets, se pueden leer en Python 3
- with io.open(’/tweets.json’,encoding=’unicode-escape’) as f:
mi_json=json.loads(f.read().lower())
tweets=mi_json[’json_agg’]
documents=[tweet[’text’] for tweet in tweets if tweet[’text’]] - Se pueden tokenizar:
- tokenizer = RegexpTokenizer(r’\w+’)
documents = [ tokenizer.tokenize(doc.lower()) for doc in documents ] - Se pueden quitar las stopwords con el paquete NLTK
- documents = [[token for token in doc if token not in stoplist]
for doc in documents] - Se puede lematizar, en español es difícil
- documents=[[lemmatize(i) for i in document] for document in documents]
Imagen tomada de Bengio et al., 2016
Ejemplo procesamiento tweets
- TF-IDF: mide la importancia de una palabra relativo a un conjunto de documentos
- tfidf =gensim.models.TfidfModel(corpus,normalize=True)
- tfidf_corpus=tfidf[corpus]
- Modelo LDA se aplica al corpus
- lda_model = gensim.models.ldamodel.LdaModel(tfidf_corpus,
id2word=dictionary,
num_topics=K,
passes=N)
Imagen tomada de Bengio et al., 2016
Ejemplo procesamiento tweets
Desarrollo
Resultados
¿Preguntas?
fernanda-mora.com
fernandamoralba@gmail.com
Redes_sociales
By Sophie Germain



