Data Products
Or how to get models into production
PyData track at PyCon Italy
Friday 17th of April 2015
All opinions my own
Who am I?
I work as a Data Scientist for a large Telecommunications Company
- Masters in Mathematics
- Specialized in Statistics and Machine Learning
- Interned at Amazon
- Was a consultant for a while
- I've been an analytics product architect on one product
- Occasional contributor to Pandas and other projects
- @springcoil

We can't agree what data science is
I think a data scientist is someone with enough programming ability to leverage their mathematical skills and domain specific knowledge to turn data into solutions.
The solution should ideally be a product
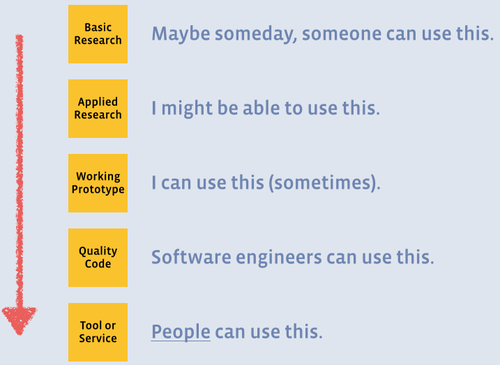

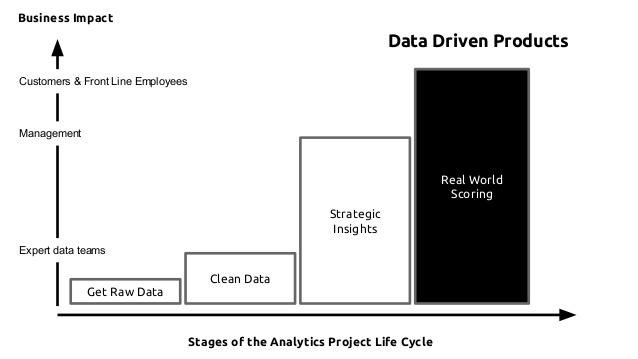
To help the business most
- I believe that data science offers the most value when the models are in production.
- Some of us call this a 'Data Product'
- In this talk I will explain how to use ScienceOps from Yhat to build a model in production
- Why should Amazon or Google get all the fun? Or competitive advantage?
The last mile problem
Sean Taylor at Facebook calls this the 'last mile problem'.
Or how do you translate the insight into something people use?
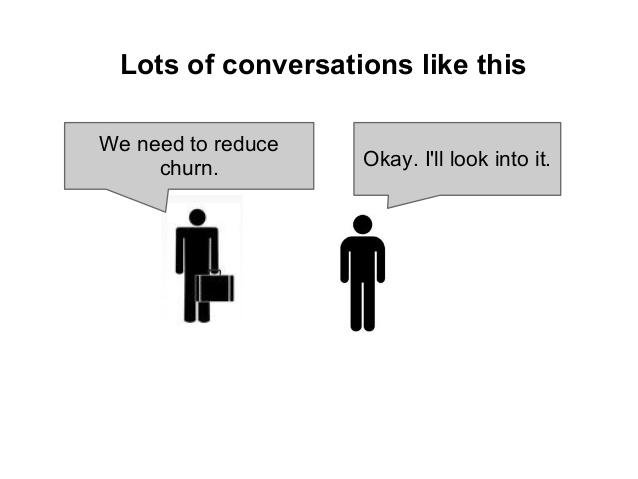
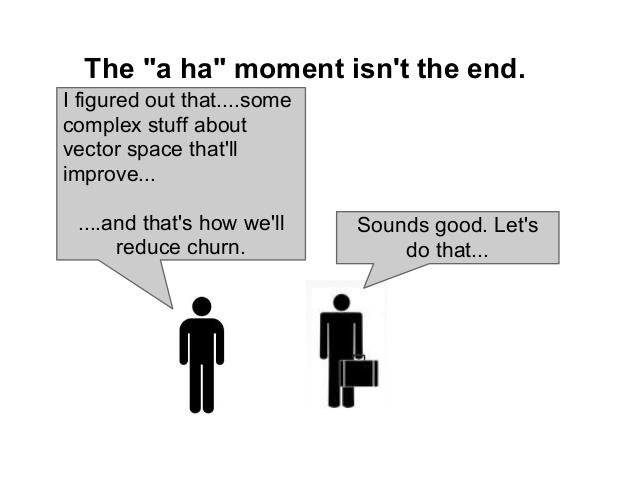
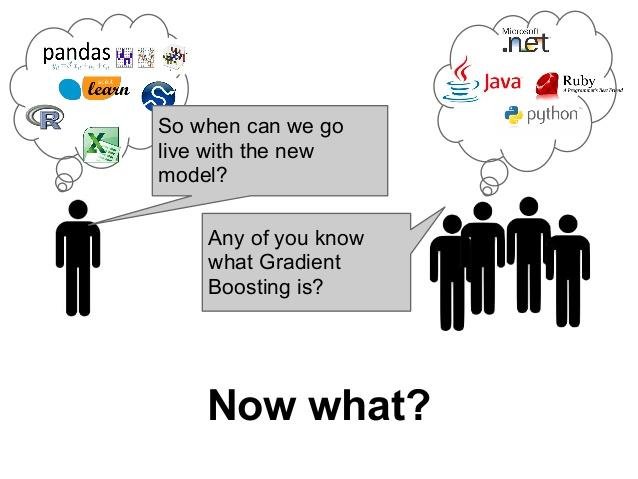
It is hard to incorporate
data into day to
day operations.
Data scientists are not software engineers
Although it is not acknowledged by some!
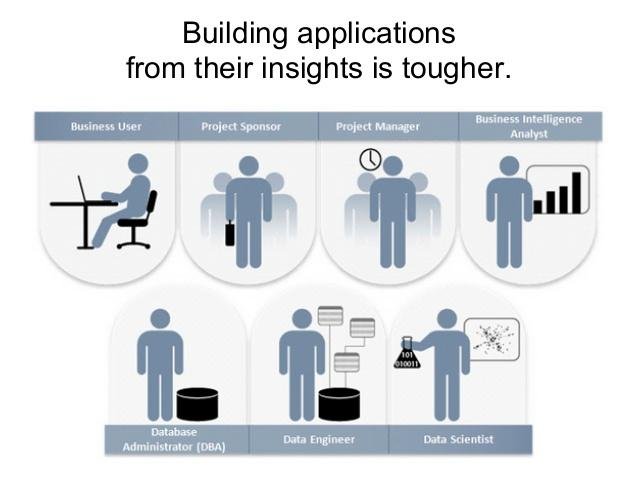
Producing models in code is not the same as producing a good web application, you need domain specific knowledge of model building and the challenges that presents.
R and D != Engineering
Many software engineers think that data science is just an engineering problem.
However, the scoping of a model building task is hard, you never quite know how to scope it effectively.
Takeaway: Make sure your stakeholders are ready for such high risk and high reward projects
Hiring data scientists is hard...
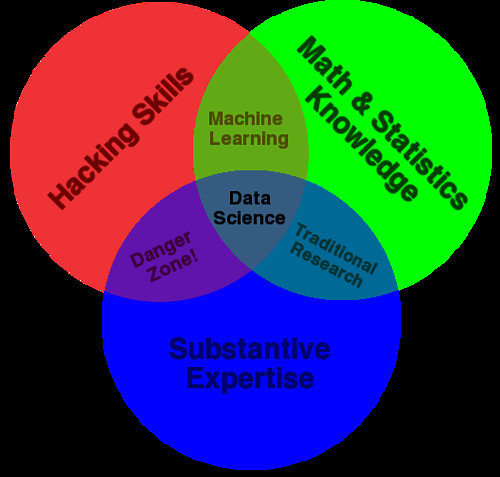
Why?
The data science process involves something like OSEMIC
Obtain
Scrub
Explore
Model
Interpret
Communicate
Building the model involved porting code from Matlab and understanding a new domain specific problem.
The API data sources were messy and hard to understand
Case study: Problem description
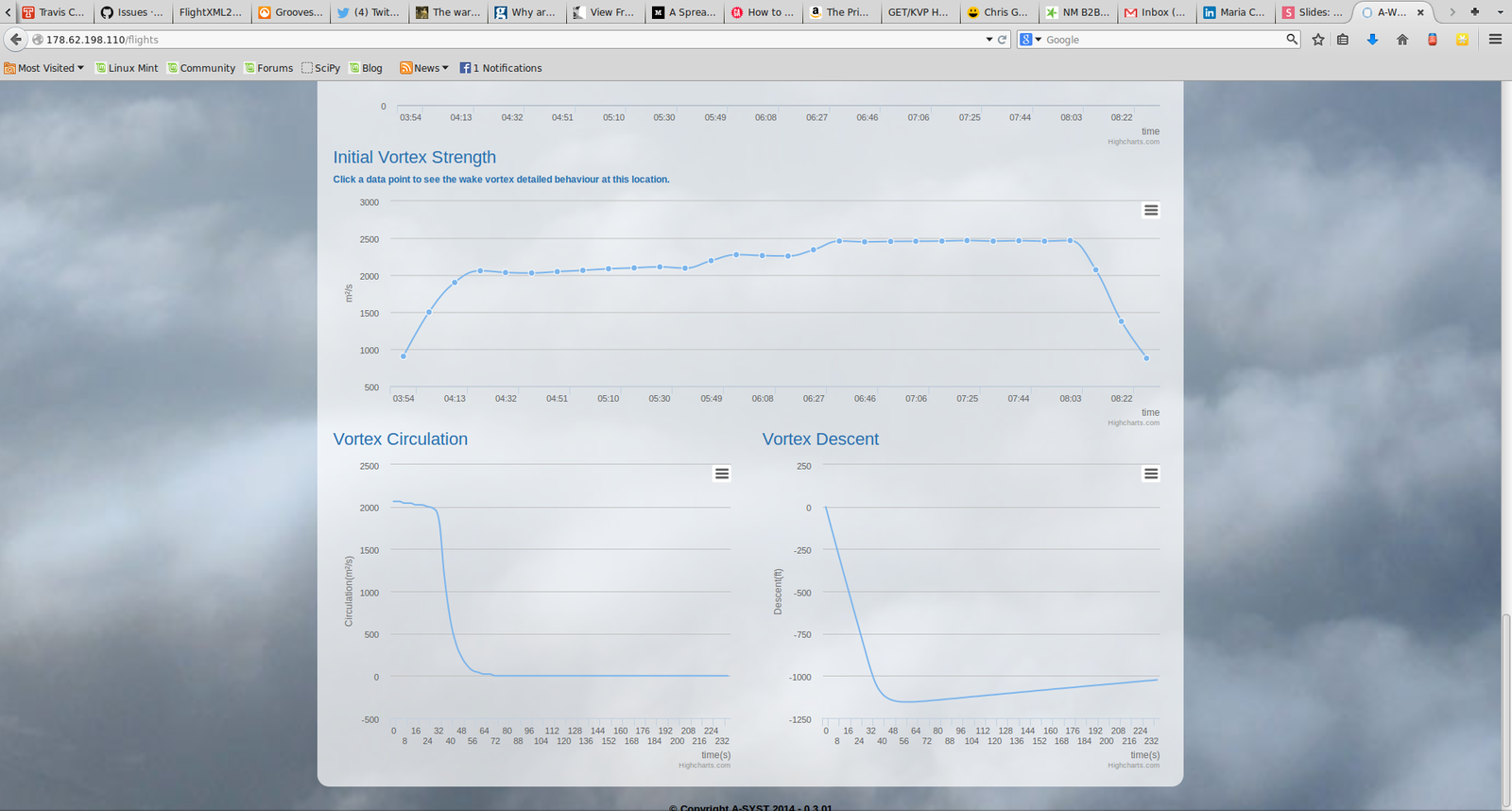
A client was working on a visualization tool and needed to provide the results of a differential equation in a usable form to users.
The research problem was already done - so after code was prototyped in Python - what next?
One key ingredient was that the results of the 'mathematical engine' had to be incorporated quickly into a Ruby on Rails/ Javascript based product.
The challenge therefore is one of interoperability
Possible Solutions (and their problems)
Port code to Java -----> Cross language validation
PMML ----> Doesn't have great language support
Batch Jobs -------> High maintenance and config
More tools, more work, more time
My first solution
Teach Math....



So I did what all data scientists do when stuck...

I found these guys

I could use stuff from YHatHQ to build a model as a service...

This is a much better solution!
I used Science Ops from YHatHQ
Key Tenets
1. Work with the tools you already know
2. Iterate quickly
3. Low touch
4. No rewriting code

Code!
What are the key takeaways?
1. The 'magic quickly' problem
2. Lack of a shared language between software engineers and data scientists - but investing in the right tooling by using open standards allows success.
3. To help data scientists and analysts succeed your business needs to be prepared to invest in tooling
Magic quickly

https://xkcd.com/1425/
Research is not engineering!

Lack of a shared language
Statisticians and software engineers don't necessarily have a shared language.
Services like Science Ops help bridge the gap.
"Watch for high skew and kurtosis"
Think about your team balance in your projects. Math folk versus coders.
Invest in tooling
- For your analysts and data scientists to succeed you need to invest in infrastructure to empower them.
- Think carefully how you want your company to spend its innovation tokens and take advantage of the excellent tools available like ScienceOps and AWS.
- I think there is great scope for entrepreneurs to take advantage of this arbitrage opportunity and build good tooling to empower data scientists by building platforms.
- Contribute to Open Source Software such as the PyData stack!
Alternatives to YhatHQ
(that I know of)



Lessons learned
- I can write a model in Python and have it deployed!
-
Software Engineers aren't data scientists and shouldn't be expected to write models in code.
- Models only provide value when they are in production
- Getting information from stakeholders is really valuable in improving models.
Successes
- Within a few months it was possible to have an analytics product in production, using information consumed from a variety of API's.
- I have no idea how else - maybe using PMML that I could deploy models.
- Total development time took 3 months, with 5 people. Only two (including myself) were working fulltime on this project.
- That development time includes time for us to learn the domain specific knowledge like models, API sources, etc.
Other kinds of data science Products
- Credit risk modelling
- Customer attrition modelling
- Recommendation engines
- Airline delay analysis
- The list goes on....
Wanna learn more?
www.yhathq.com
peadarcoyle@googlemail.com

Models in Production
By springcoil
Models in Production
How to create a Data Product on a budget :)



