Apache Spark
for dummies

Yegor Bondar
KEY NOTES
- Big Data, MapReduce, Hadoop, Distributed computing and other buzz words
- Where Apache Spark comes from?
- Apache Spark model & core concepts
- Scala, Python and Java
- Real world use cases
- All right.. I want to start working with Apache Spark!
- Conclusions
Buzz TErms that make hype

- How to collect the "big" data?
- How to store the "big" data?
- How to process "big" data?
- How to make the data "big" useful?
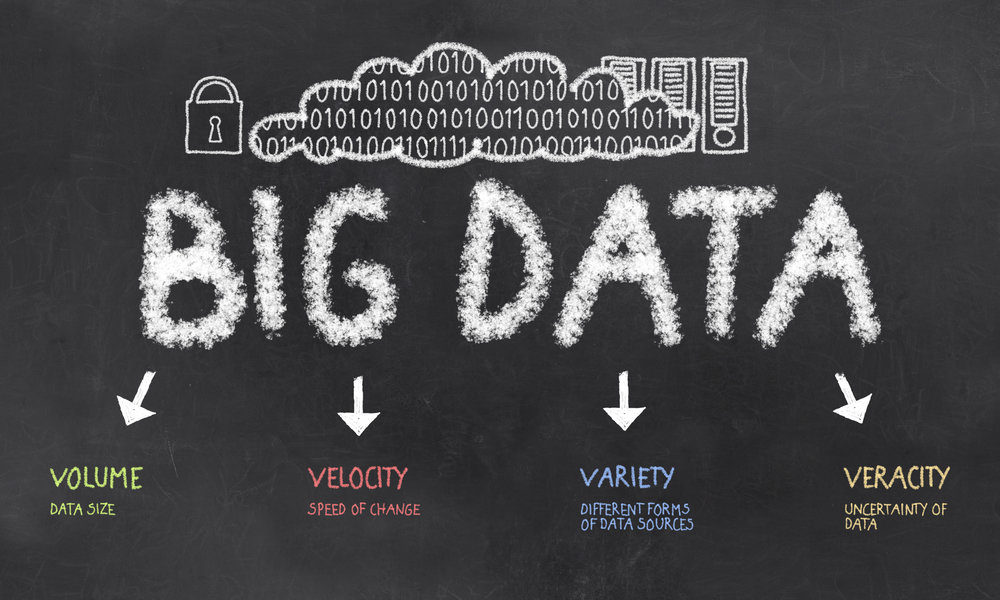
The main Big Data challenges:

5 Vs
Use cases
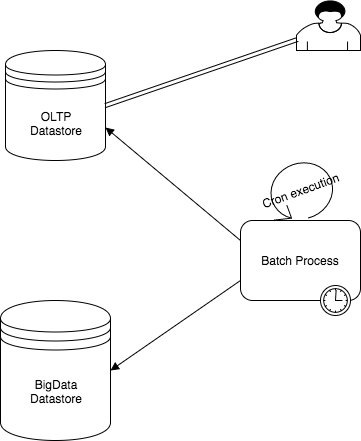
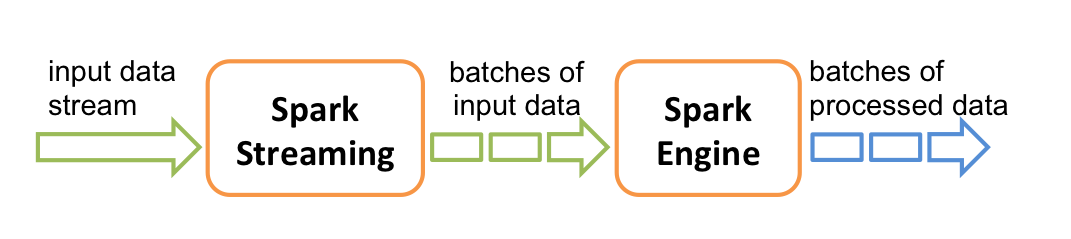
Batch processing
Use cases
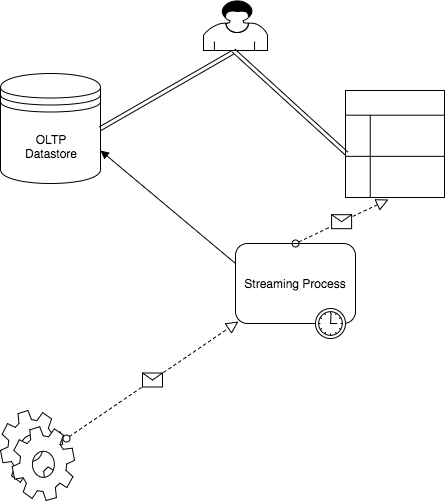
Real Time Processing
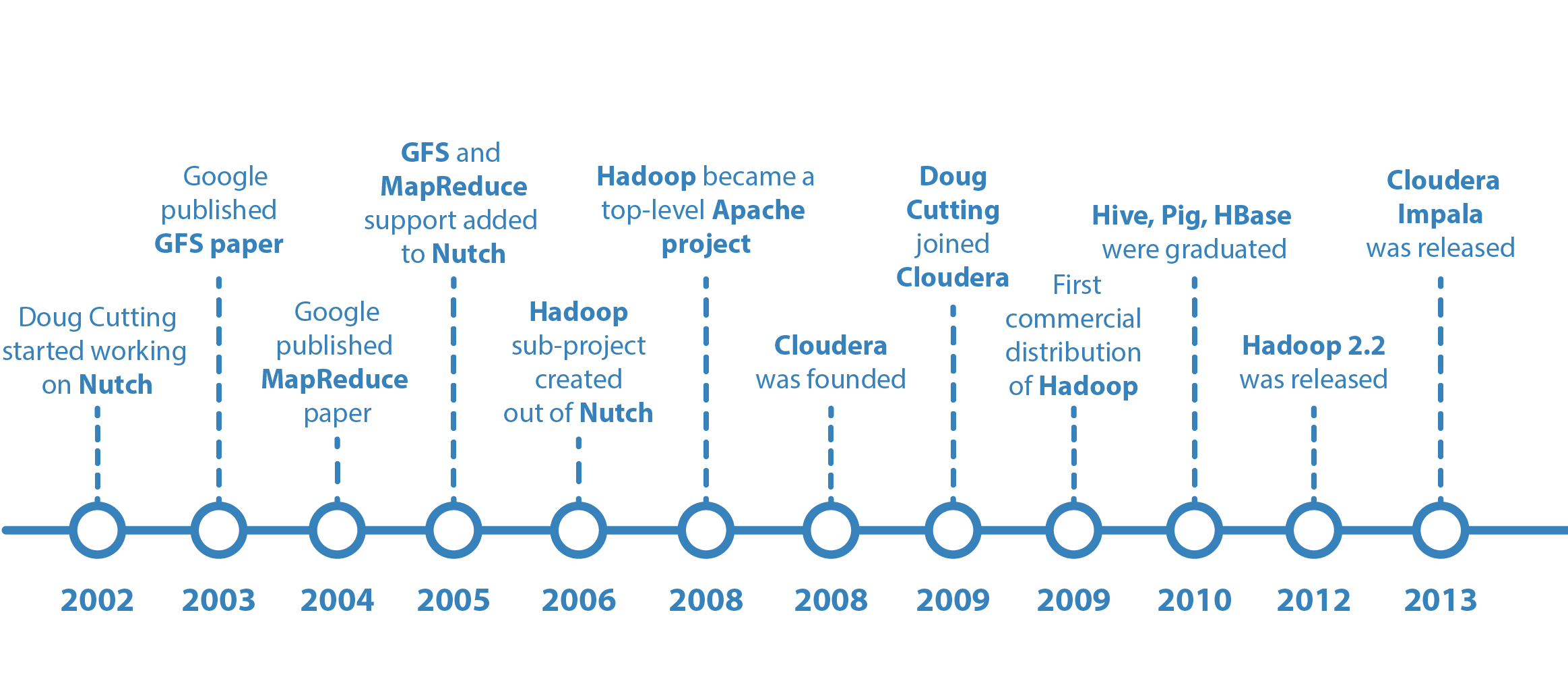
Big Data History
Map-Reduce

Map-Reduce Alternative
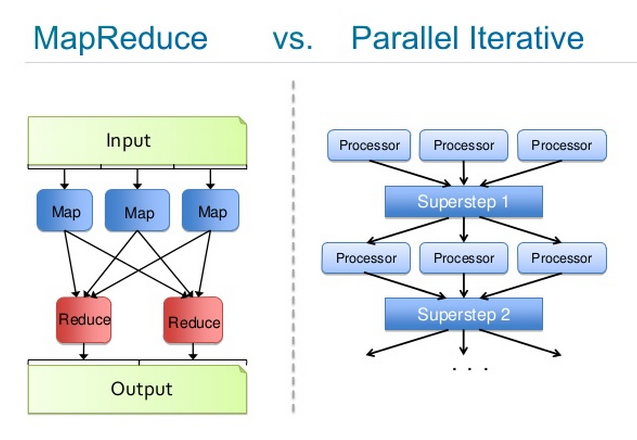
Map-Reduce in Cluster
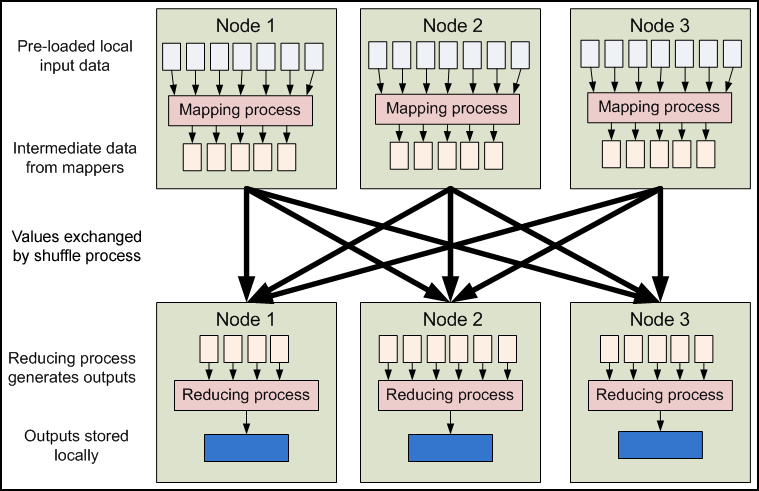
Apache Hadoop
an open-source software framework used for distributed storage and processing of dataset of big data using the MapReduce programming model. It consists of computer clusters built from commodity hardware.

Ecosystem
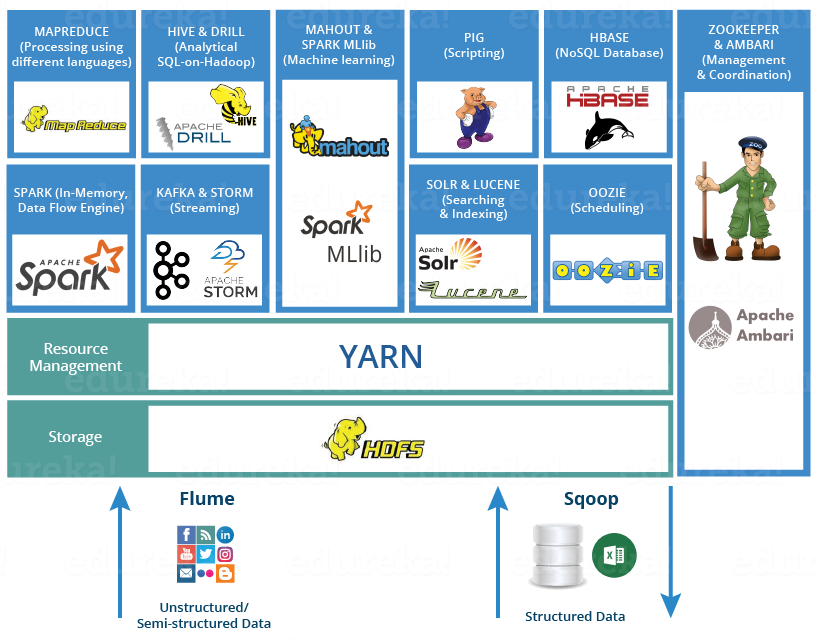
Spark vs hadoop
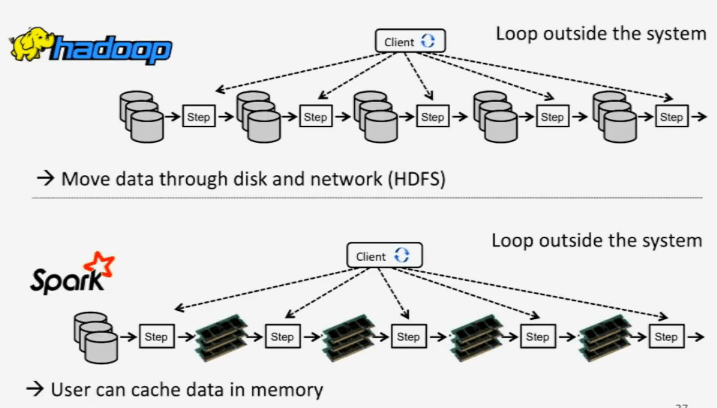
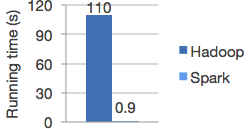
Apache Spark
Lightning-fast cluster computing
Main release year : 2014
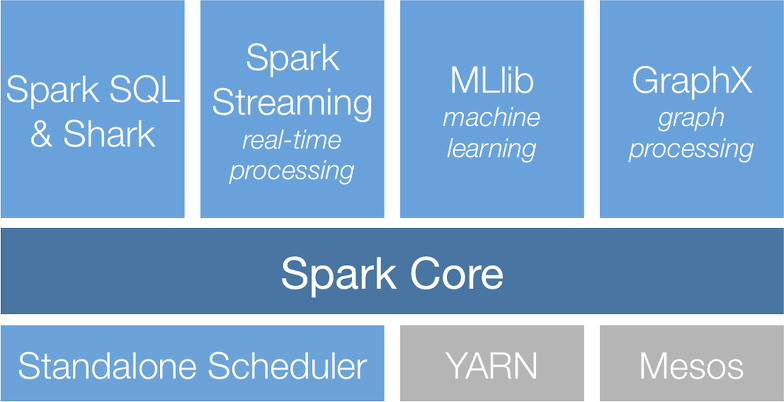
Apache Spark - Core Concepts
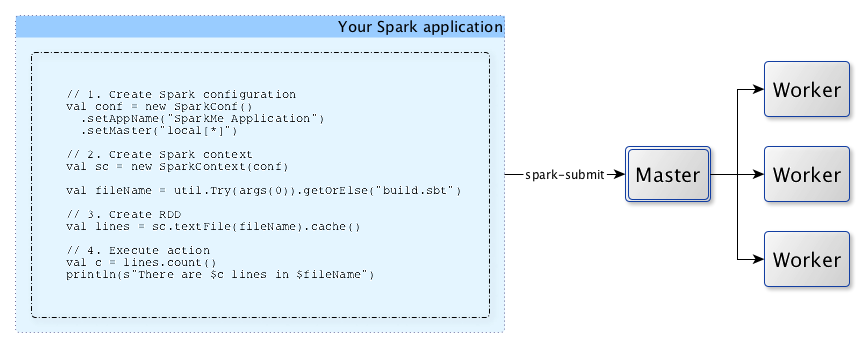
// Create Spark Configuration
val conf = new SparkConf()
.setAppName("Spark App")
.setMaster("local[*]")
// Create Spark Context
val sc = new SparkContext(conf)
// Read all lines from file
val lines = sc.textFile(filePath).cache()
// Apply transformations
val modifiedLines = lines.map(_.split("_"))
// Apply action
println(modifiedLine.count())Rdd[T]
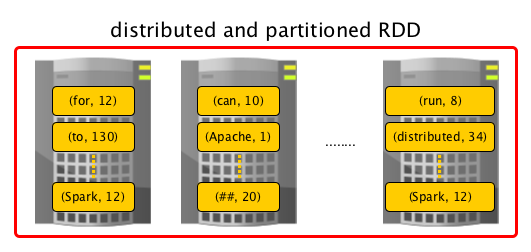
Resilient Distributed Dataset (aka RDD) is the primary data abstraction in Apache Spark and the core of Spark
- Resilient, i.e. fault-tolerant with the help of RDD lineage graph and so able to recompute missing or damaged partitions due to node failures.
- Distributed with data residing on multiple nodes in a cluster.
- Dataset is a collection of partitioned data with primitive values or values of values, e.g. tuples or other objects (that represent records of the data you work with).
Rdd[T]
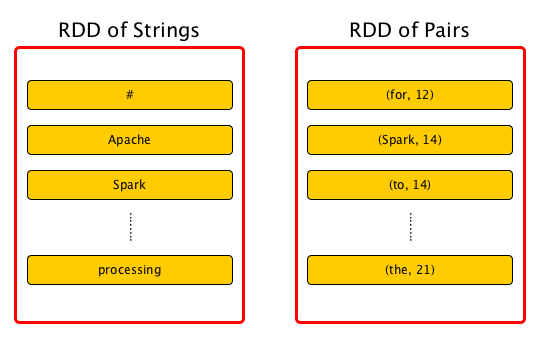
RDD[String]
RDD[(String, Int)]
RDD Transformations
transformation: RDD => RDD
transformation: RDD => Seq[RDD]Transformations are lazy operations on a RDD that create one or many new RDDs, e.g. map, filter, reduceByKey, join, cogroup, randomSplit.
immutable Rdd nature
val r00 = sc.parallelize(0 to 9)
val r01 = sc.parallelize(0 to 90 by 10)
val r10 = r00 cartesian r01
val r11 = r00.map(n => (n, n))
val r12 = r00 zip r01
val r13 = r01.keyBy(_ / 20)
val r20 = Seq(r11, r12, r13).foldLeft(r10)(_ union _)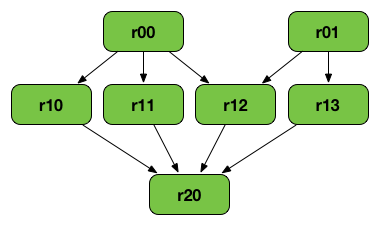
RDD ACTIONS
action: RDD => a valueActions are RDD operations that produce non-RDD values. They materialize a value in a Spark program.
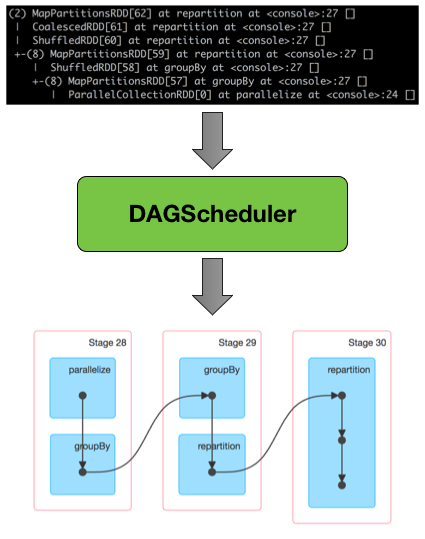
DAG Scheduler
DAG(Direct Acyclic Graph) is the scheduling layer of Apache Spark that implements stage-oriented scheduling. It transforms a logical execution plan (i.e. RDD lineage of dependencies built using RDD transformations) to a physical execution plan
Word count - Hadoop
public class WordCount extends Configured implements Tool {
public static void main(String args[]) throws Exception {
int res = ToolRunner.run(new WordCount(), args);
System.exit(res);
}
public int run(String[] args) throws Exception {
//configuration stuff ....
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value,
Mapper.Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
}Word count - Spark
JavaRDD<String> textFile = sc.textFile("hdfs://...");
JavaPairRDD<String, Integer> counts = textFile
.flatMap(s -> Arrays.asList(s.split(" ")).iterator())
.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey((a, b) -> a + b);
counts.saveAsTextFile("hdfs://...");val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")Real world use cases
- Distributed processing of the large file sets
- Process streaming data for different telecom network topologies
- Running calculations on different datasets based on external meta configuration.
Distributed processing
Input
- Set of binary data files stored in HDFS
- Files have custom format
- Data can be parallelized
Challenges
- Parse custom data format
- Calculate different aggregation values
- Store result as JSON back to HDFS
Desired output
JSON objects which represents the average signal value for certain Web Mercator Grid zoom.
{
"9#91#206" : {
"(1468,3300,13)" : -96.65605103479673,
"(1460,3302,13)" : -107.21621616908482,
"(1464,3307,13)" : -97.89720813468034
},
"9#90#206" : {
"(1447,3310,13)" : -113.03223673502605,
"(1441,3301,13)" : -108.92957834879557
},
"9#90#207" : {
"(1449,3314,13)" : -112.97138977050781,
"(1444,3314,13)" : -115.83310953776042,
"(1440,3313,13)" : -109.2352180480957
}
}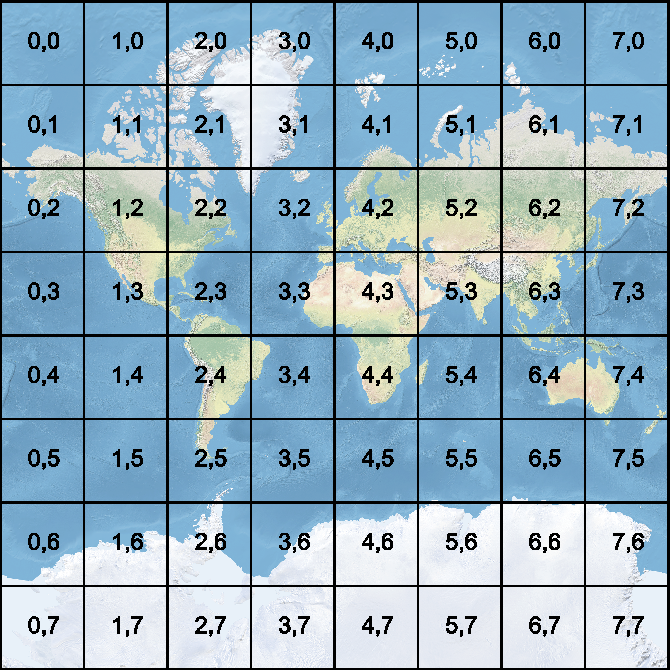
Data Parallelizm
Implementation
def prepareDataset(inputHolder: InputHolder,
processingCandidates: List[Info])(implicit sc: SparkContext): RDD[(Tile, GenSeq[GrdPointState])] = {
sc.binaryFiles(inputHolder.getPath.getOrElse("hdfs://path/to/files"), partitions = 4).filter {
case (grdPath, _) => processingCandidates.exists(inf => grdPath.contains(inf.path))
}.flatMap {
case (path, bytes) =>
log(s"CoverageParser.prepareDataset - Loading dataset for $path")
val grdInMemory = GdalGrdParser.gdal.allocateFile(bytes.toArray())
val infOpt = GdalGrdParser.gdal.info(grdInMemory)
val tileToPoints = ... // collect points from files on each node
tileToPoints
}.reduceByKey(_ ++ _).mapValues(points => AveragedCollector.collect(Seq(points)))
}
def aggregateAndPersistTiles(inputHolder: InputHolder,
dataSet: RDD[(Tile, GenSeq[GrdPointState])])(implicit rootPath: String): Unit = {
dataSet.mapPartitions { it =>
it.toSeq.map {
case (_, avgPoints) => ZoomedCollector.collectGrd(level.aggZoom)(avgPoints)
}.iterator
}.map { tileStates =>
ZoomedCollector.collectTiles(level.groupZoom)(tileStates)
}.map {
tileStates =>
tileStates.seq.toMap.asJson.noSpaces
}.saveAsTextFile(s"$rootPath/tiles_result_${System.currentTimeMillis()}")
}Results
| Dataset | Single JVM implementation | Spark Implementation (Local cluster) |
|---|---|---|
| 14 M points | 7 minutes & 2G Heap | 1 minute |
| 25 M points | 12 minutes & 2G Heap | 1.5 minute |
Pros
- Built in parallelism
- Ways to improve performance
Cons
- You should install 3rd party tool on each node to parse binary files
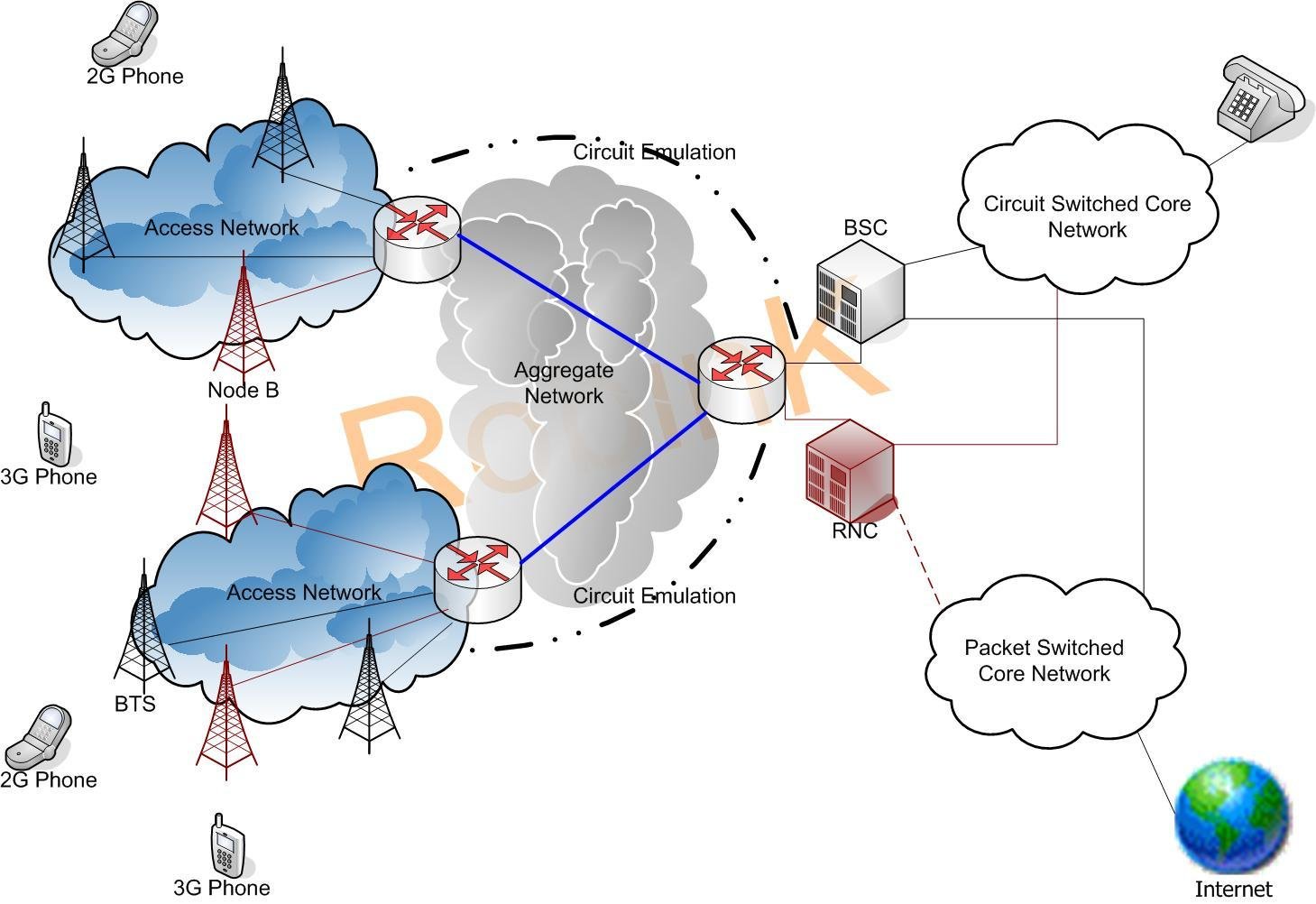
Data Stream Processing
Input
- JSON messages from Apache Kafka topics
- Each message represents the data from network topology element (cell, controller)
- Aggregated JSON object should be persisted to either Kafka topic or HBase
Challenges
- Aggregate different messages to build the final object
- Process Kafka topics in efficient manner
- Ensure reliability
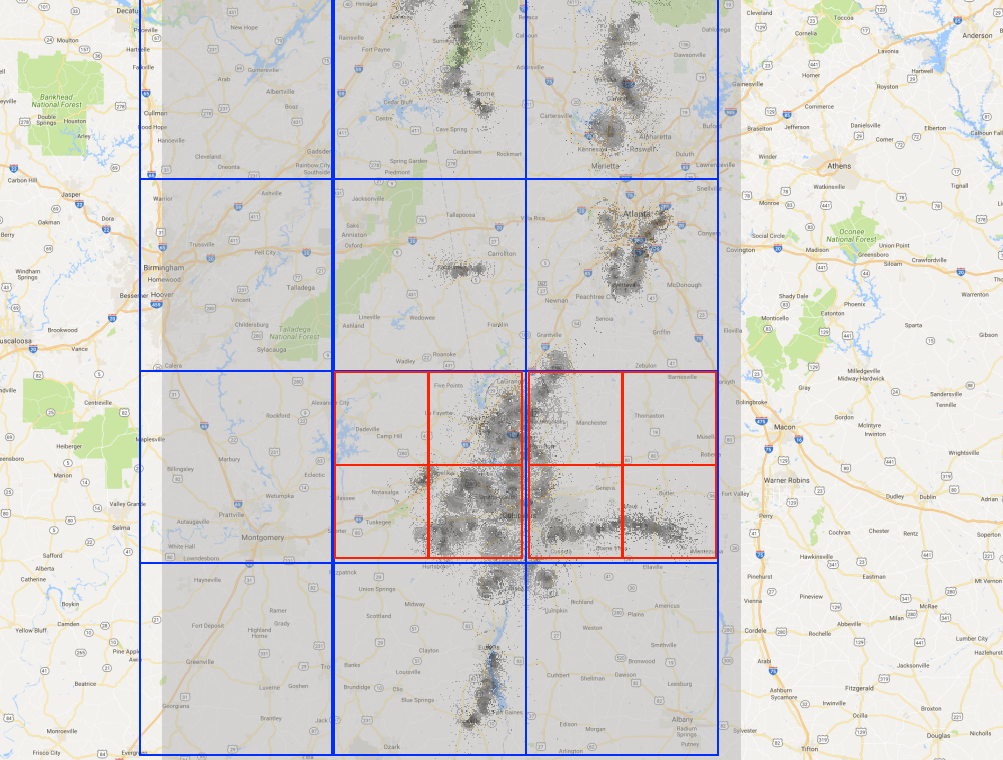
Network Topology
{
"technology" : "2g",
"cell_id" : "10051",
"site_id" : "UK1835",
"cell_name" : "KA1051A",
"latitude" : "49.14",
"longitude" : "35.87777777777778",
"antennaheight" : "49",
"azimuth" : "35",
"antennagain" : "17.5",
"lac" : "56134",
"Site name" : "UK1854"
}{
"SDCCH_NBR" : "23",
"bts_id" : "5",
"site_id" : "18043",
"cell_id" : "10051",
"bsc_id" : "1311",
"technology" : "2G",
"MCC" : "255",
"element-meta" : "BTSID",
"date" : "2016-10-31 03:03",
"bcc" : "2",
"SERVERID" : "259089846018",
"HO_MSMT_PROC_MD" : "0",
"element_type" : "BTS",
"vendor" : "ZTE",
"ncc" : "1",
"cell_name" : "KA1051A"
}Composed Key:
2G#KS#KHA#1311#18043#KA1051A
Composed Value:
Join of Input Jsons
BTS
BSC
Spark Streaming Design

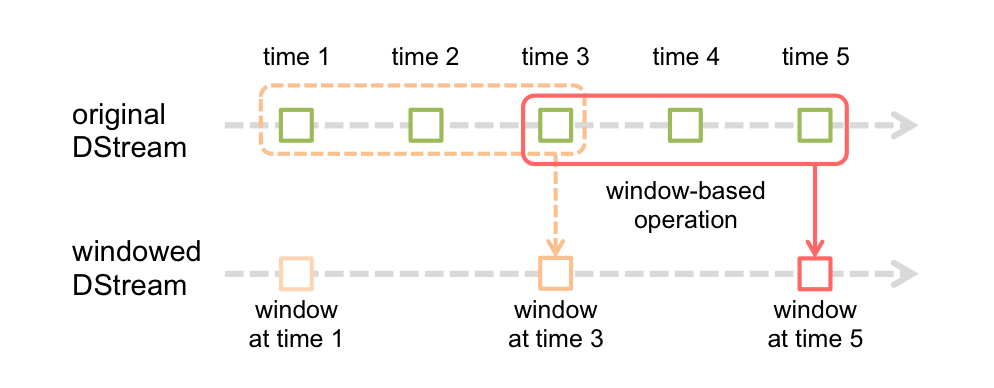
Conclusion
- Spark provides built-in Kafka support;
- Spark provides built-in storage for caching messages;
- It is easy to build re-try logic;
- Easy to join different streams.
Meta Calculations
Input
- Abstract dataset
- User should be able to configure the flow how to process the dataset
Challenges
- Apply custom function to transform the data
- Apply different transformations based on the configuration
- The engine should be flexible
Spark SQL
Spark SQL — Batch and Streaming Queries Over Structured Data on Massive Scale
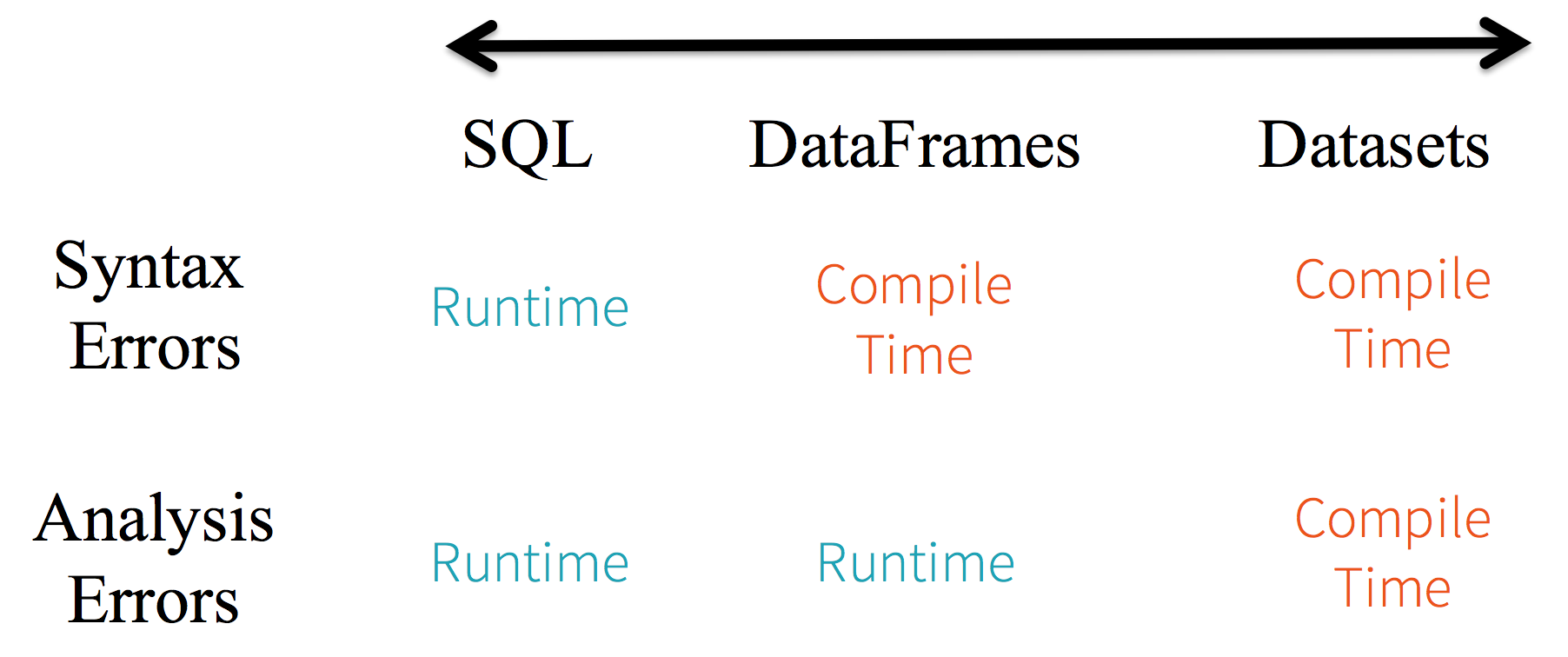
Spark SQL performance

Implementation of SQL Queries
@tailrec
def applyStages(stages: List[KpiTransformationStage],
inputTableAlias: String, stage: Int, df: DataFrame): DataFrame = {
stages match {
case section :: xs =>
val query = addFromClause(section.toSqlQuery, inputTableAlias)
val outputRes = sqlContext.sql(query)
outputRes.registerTempTable(s"Stage${stage}Output")
applyStages(xs, s"Stage${stage}Output", stage + 1, outputRes)
case Nil =>
df
}
}
// ...
registerUdfs(params)(sqlContext)
// ...
dataFrame.registerTempTable("Input"){
"transformations": [
{
"name": "TOPOLOGY_KPI_MESH50_TOTAL_section",
"stages": [
{
"sql": [
"select rowkey, nr_cells, nr_urban_cells, nr_total_cells,",
"getA(nr_small_cells, nr_total_cells) as aHealth,",
"getB(nr_dense_urban_cells, nr_total_cells) as bHealth"
]
}
]
}
]
}Conlusions
- Immutable nature of DataFrames/DataSets gives a lot of functionality;
- You work in terms of 2D tables: Rows, Columns and Cells;
- DataFrames performance is better than RDD;
- UDF(User Defined Function) is powerful feature for custom transformations.
Starter Kit
Apache Spark can be used locally without any complex setup.
- Add Spark library as a dependency
- Run it in local[*] mode
val conf: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("TestApp")
val sc: SparkContext = new SparkContext(conf)
...
val lines = sc.textFile("src/main/resources/data/data.csv")Starter Kit
Apache Jupiter, Apache Zeppelin
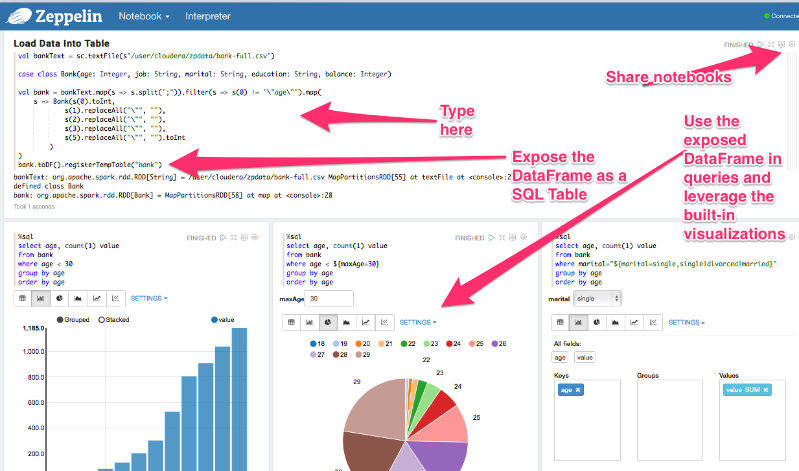
Conclusions
- Big Data != Big amount of data;
- Apache Spark is the replacement for Apache Hadoop in MapR frameworks;
- Different use cases can be covered using built-in Apache Spark functionality.
Useful resources

apache-spark
By Yegor Bondar
apache-spark
Apache Spark for Dummies



