Spark architecture
In local installation, cores serve as master & slaves

Hardware organization
spatial software organization
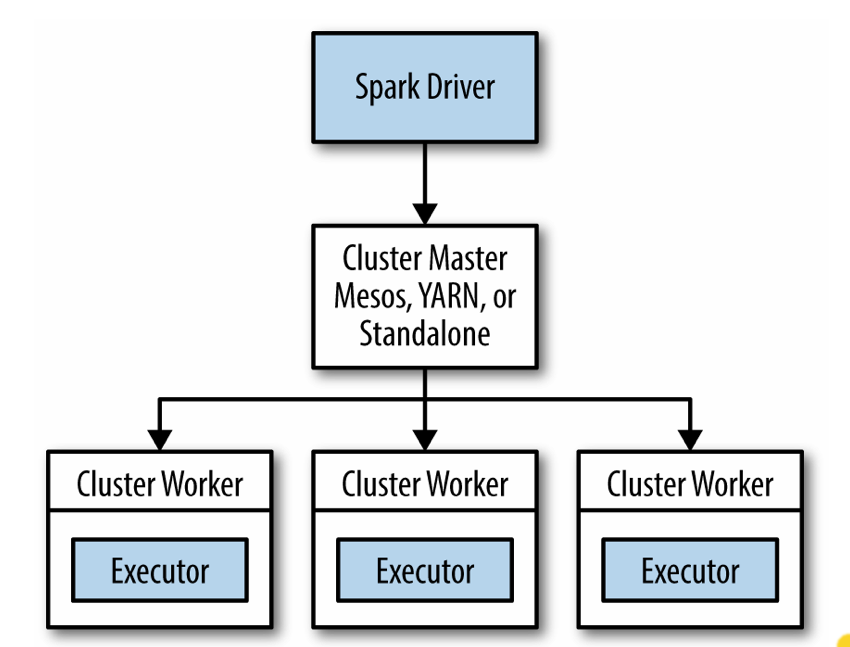
- The driver runs on the master
- It executes the "main()" code of your program.
- The Cluster Master manages the computation resources.
- The each worker manages a single core.
- Each RDD is partitioned among the workers,
- Workers manage partitions and Executors
- Executors execute tasks on their partition, are myopic.
spatial organization (more detail)
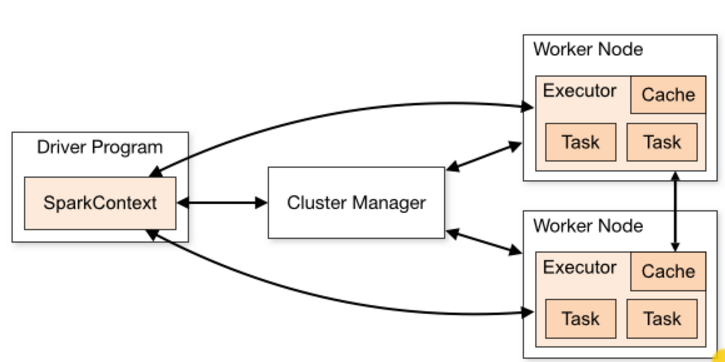
- SparkContext (sc) is the abstraction that encapsulates the cluster for the driver node (and the programmer).
- Worker nodes manage resources in a single slave machine.
- Worker nodes communicate with the cluster manager.
- Executors are the processes that can perform tasks.
- Cache refers to the local memory on the slave machine.
materialization
- Consider RDD1
-> Map (x: x*x) -> RDD2
->Reduce (x,y:x+y)-> float (in head node)
- RDD1 -> RDD2 is a lineage
- RDD2 can be consumed as it is being generated.
- Does not have to be materialized = stored in memory
RDD Processing
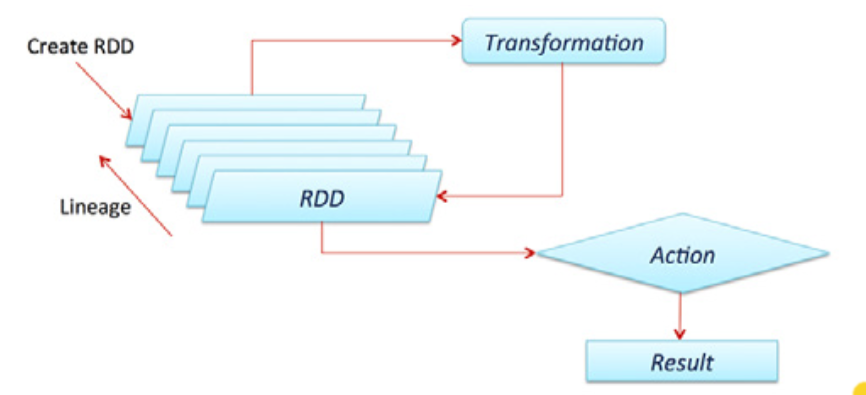
- RDDs, by default, are not materialized
- They do materialize if cached or otherwise persisted.
Temporal organization
RDD Graph and Physical plan
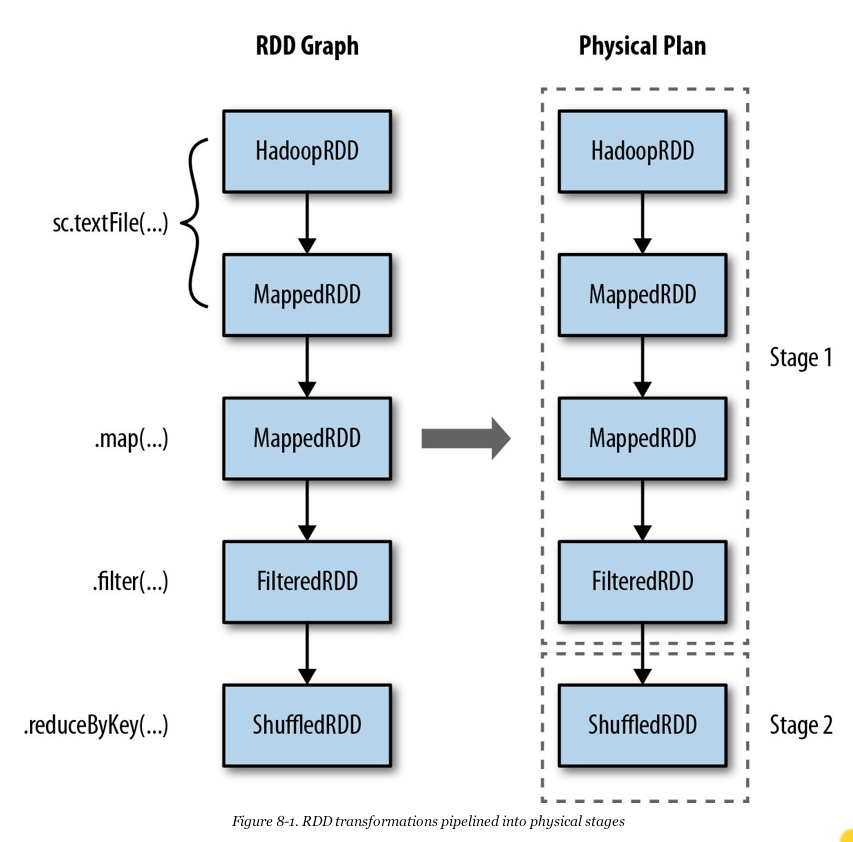
Recall Spatial
organization
A stage ends
when the RDD needs
to be materialized
Terms and concepts of execution
- RDDs are partitioned across workers.
- RDD graph defines the Lineage of the RDDs.
- SparkContext divides the RDD graph into stages which define the execution plan (or physical plan)
- A task corresponds to the to one stage,
restricted to one partition. - An executor is a process that performs tasks.
Summary
- Spark computation is broken into tasks
- Spatial organization: different data
partitions on different machine - Temporal organization: Computation
is broken into stages. a sequence of stages. - Next: persistence and checkpointing
Persistance
and Checkpointing
Levels of persistance
- Caching is useful for retaining intermediate results
- On the other hand, caching can consume a lot of memory
- If memory is exhausted, caches can be eliminated, spilled to disk etc.
- If needed again, cache is recomputed or read from disk.
- The generalization of .cache() is called .persist() which has many options.
Storage Levels

.cache() same as .persist(MEMORY_ONLY)
http://spark.apache.org/docs/latest/programming-guide.html#rdd-persistence
Checkpointing
- Spark is fault tolerant. If a slave machine crashes, it's RDD's will be recomputed.
- If hours of computation have been completed before the crash, all the computation needs to be redone.
- Checkpointing reduces this problem by storing the materialized RDD on a remote disk.
- On Recovery, the RDD will be recovered from the disk.
- It is recommended to cache an RDD before checkpointing it.
http://takwatanabe.me/pyspark/generated/generated/pyspark.RDD.checkpoint.html
Checkpoint vs. Persist to disk
- Cache materializes the RDD and keeps it in memory (and/or disk). But the lineage(computing chain)of RDD (that is, seq of operations that generated the RDD) will be remembered, so that if there are node failures and parts of the cached RDDs are lost, they can be regenerated.
- Checkpoint saves the RDD to an HDFS file and actually forgets the lineage completely. This allows long lineages to be truncated and the data to be saved reliably in HDFS, which is naturally fault-tolerant by replication.
- https://github.com/JerryLead/SparkInternals/blob/master/markdown/english/6-CacheAndCheckpoint.md
Spark Architecture
By Yoav Freund



