Streaming
운영과 회고
0. Streaming 101
1. Latency & Throughput
2. Offeset Management ( with Kafka source )
3. Process Fail Over
4. Monitoring
5. Detect Outliars & Alerting
- Next ....
Streaming 101
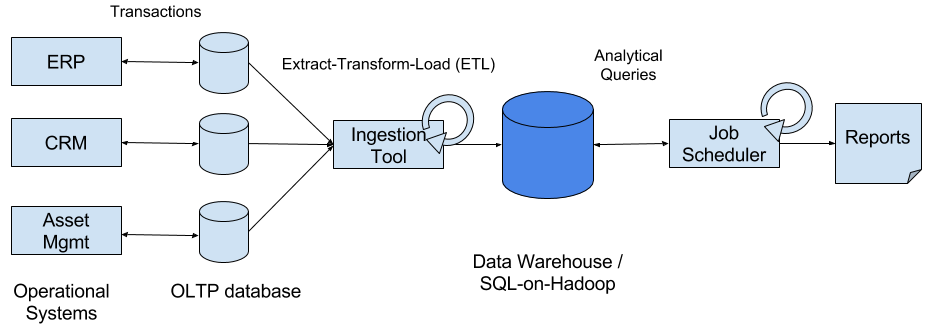
A traditional data warehouse architecture for data analytics
Batch Architecture Sketch
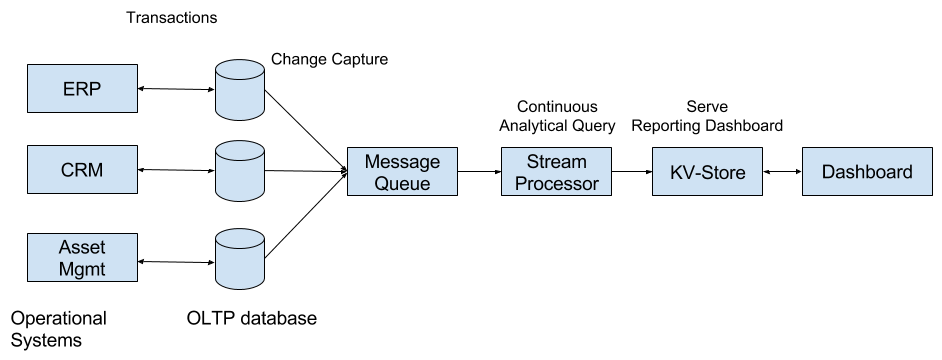
Streaming Architecture sketch
Architecture sketch of a streaming analytics system
출처 : Safari book's Streaming processing with Apache Flink
Time
출처 : Safari book's Streaming processing with Apache Flink

Processing Time
출처 : Safari book's Streaming processing with Apache Flink
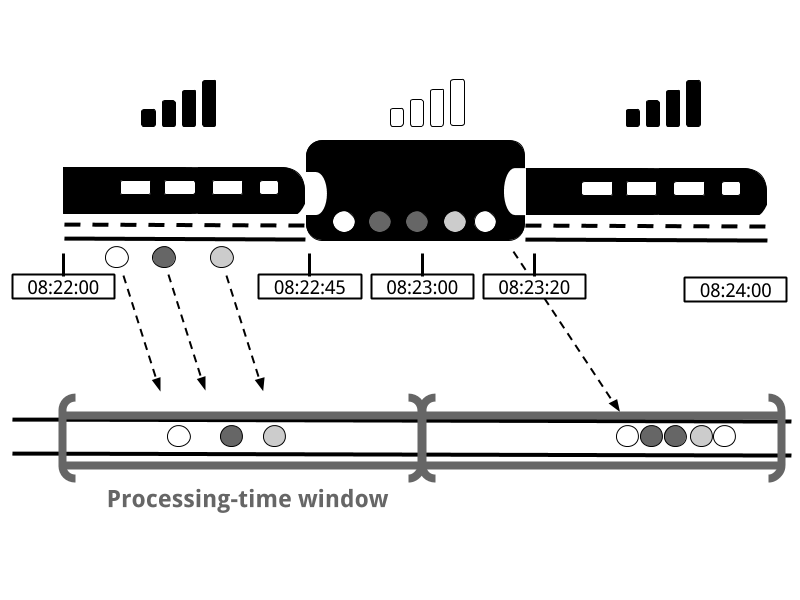
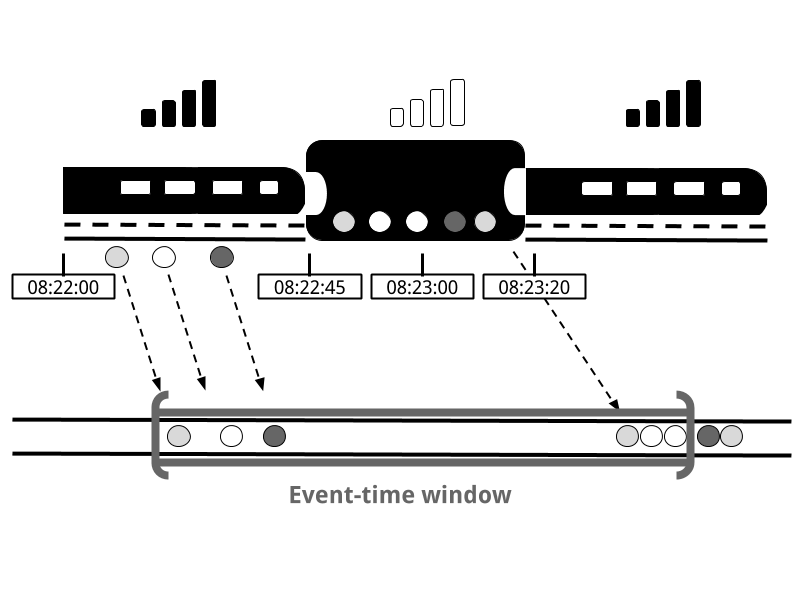
Event Time
출처 : Safari book's Streaming processing with Apache Flink
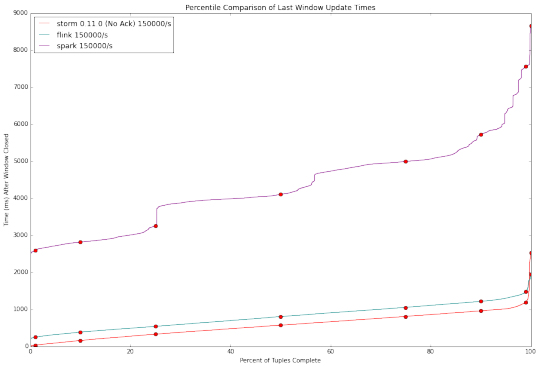
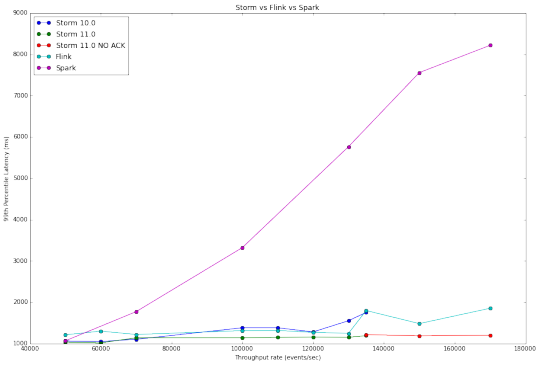
Latency & Throughput
출처 : Safari book's Streaming processing with Apache Flink
Latency : how long it takes for an event to be processed
Throughput : events or operations per time unit
Latency & Throughput

여러분들의 서비스에서도
Spark Streaming이
그렇게 느리던가요..?

출처 : https://www.slideshare.net/BrandonOBrien/spark-streaming-kafka-best-practices-w-brandon-obrien
Stand alone best
Offeset Management
( with Kafka source )
-
Checkpoints
-
Kafka itself
-
Your own data store
출처 : http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html
Using Check point
- 최종 결과를 저장했음에도 불구하고 offset을 checkpoint에 저장하지 못하고 장애가 발생하는 경우가 발생할 수 있습니다.
- checkpoint에 저장된 메타 데이터를 읽을 수 없으면, 재시작을 하더라도 마지막 처리된 이후부터 처리할 수 없습니다.
- checkpoint 정보는 직렬화(serialized)된 객체를 저장하는데, 역직렬화(deserialize)할 때 클래스가 바뀌면 에러가 발생하며 실패합니다.
- 어플리케이션이 시스템 장애로 재시작하면 코드 변화가 없기 때문에 역직렬화 문제가 발생하지 않습니다.
- 하지만 스트림 처리를 재시작하는 경우는 대부분 어플리케이션이 데이터를 잘못 처리해서 죽어버리거나 잠재적인 오류를 수정하여 어플리케이션을 재배포하는 경우이기 때문에, 어플리케이션 코드가 동일한 경우가 별로 없습니다. 따라서 checkpoint를 믿고 사용하기에는 불안정한 요소가 많습니다.
- window 연산은 checkpoint를 사용할 수 밖에 없는데, 어플리케이션 코드 변경에 취약하다는 점을 알고 사용해야 합니다.
Using Check point
- 최종 결과를 저장했음에도 불구하고 offset을 checkpoint에 저장하지 못하고 장애가 발생하는 경우가 발생할 수 있습니다.
- checkpoint에 저장된 메타 데이터를 읽을 수 없으면, 재시작을 하더라도 마지막 처리된 이후부터 처리할 수 없습니다.
- checkpoint 정보는 직렬화(serialized)된 객체를 저장하는데, 역직렬화(deserialize)할 때 클래스가 바뀌면 에러가 발생하며 실패합니다.
- 어플리케이션이 시스템 장애로 재시작하면 코드 변화가 없기 때문에 역직렬화 문제가 발생하지 않습니다.
- 하지만 스트림 처리를 재시작하는 경우는 대부분 어플리케이션이 데이터를 잘못 처리해서 죽어버리거나 잠재적인 오류를 수정하여 어플리케이션을 재배포하는 경우이기 때문에, 어플리케이션 코드가 동일한 경우가 별로 없습니다. 따라서 checkpoint를 믿고 사용하기에는 불안정한 요소가 많습니다.
- window 연산은 checkpoint를 사용할 수 밖에 없는데, 어플리케이션 코드 변경에 취약하다는 점을 알고 사용해야 합니다.
자세한 얘기는 (전) SK Planet 엄태욱님의 글을 읽어보세요 :)
Spark Streaming으로 유실 없는 스트림 처리 인프라 구축하기
( http://readme.skplanet.com/?p=12465 )
Kafka itself
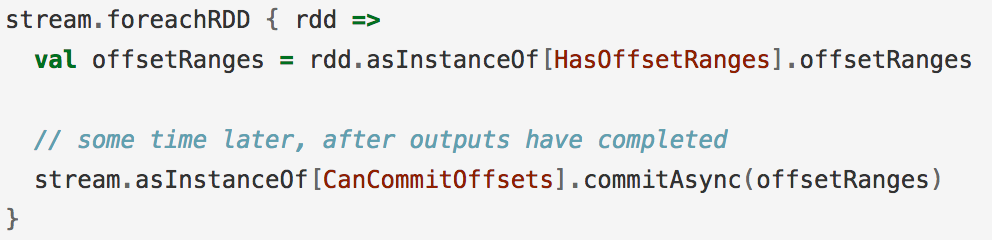
Your own data store
External Store
- HBase
- Zookeeper
- Redis
Internal Store
- Local File
참고 링크
- http://blog.cloudera.com/blog/2017/06/offset-management-for-apache-kafka-with-apache-spark-streaming/
Exactly Once 를 반드시 보장해야 되는것이 아니라면...
- Kafka Itself :)
Process Fail Over
- Reids Cluster 가 문제가 생겼을 때
- Kafka Broker 에 문제가 생겼을 때
- Yarn 에 문제가 생겼을 때
- Master Node 에 문제가 생겼을 때...
- 기타 등등
=> 자동으로 Process 를 Restart 할 수 있어야 한다.
( PM2, systemd, service ... )
그래도 피할 수 없는 SPOF 문제 ㅠㅠ

그렇다고 이건 너무 오바;;

Hadoop 3 에서 해결해주길..
Monitoring
장애 리스트
- Yarn Cluster 에 Batch Query 가 말도 안되게 큰게 실행되어 Network 장애가 발생
- Kafka Broker Controller 가 죽은 경우
- Kafka Broker NIC 가 노후되어 Consumer 이 밀리는 경우
- Kafka Broker NIC 가 노후되어 Producing 이 밀리는 경우
- Kafka Partition 정보가 바뀐 경우
- HBase region server process 가 밀리는 경우
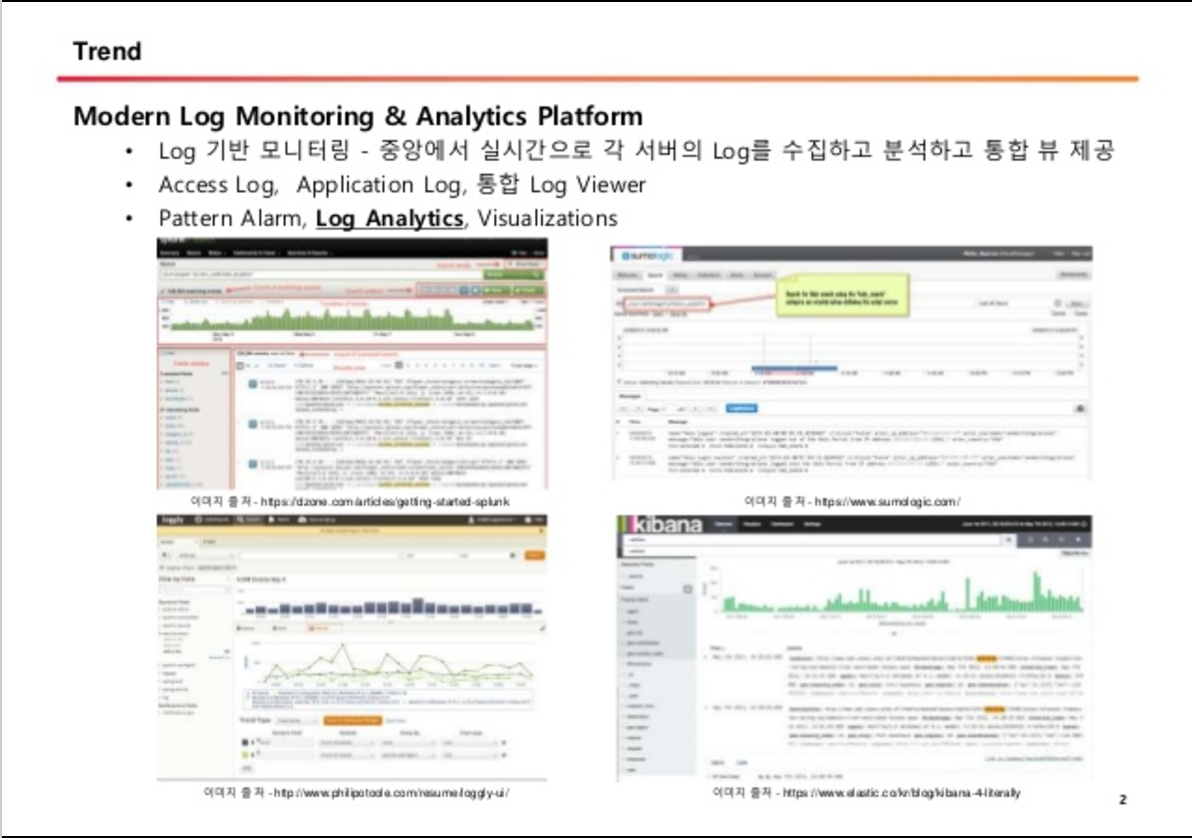
SK Planet 의 APM PMON!!
참조 : http://readme.skplanet.com/?p=13110
PMON 의 Metric에는..
참조 : http://readme.skplanet.com/?p=13110
- CPU
- Memory
- Network Traffic
- Disk
- Load avg
- Web Server ( 4xx, 5xx Req Count, RPS, Load Balacing, etc ... )
하지만 우리의 시스템은... ㅠㅠ
Spark UI !!
- Spark worker and the executors
- Jobs Launched by an Application
- visual representation of a DAG
- details for a stage
- metrics for the completed tasks in a stage
- The amount of data cached by a Spark application in memory or disk
- visualizing the execution of a Spark Streaming application
- Monitoring Spark SQL Queries
- Monitoring Spark SQL JDBC/ODBC Server
Streaming Monitoring
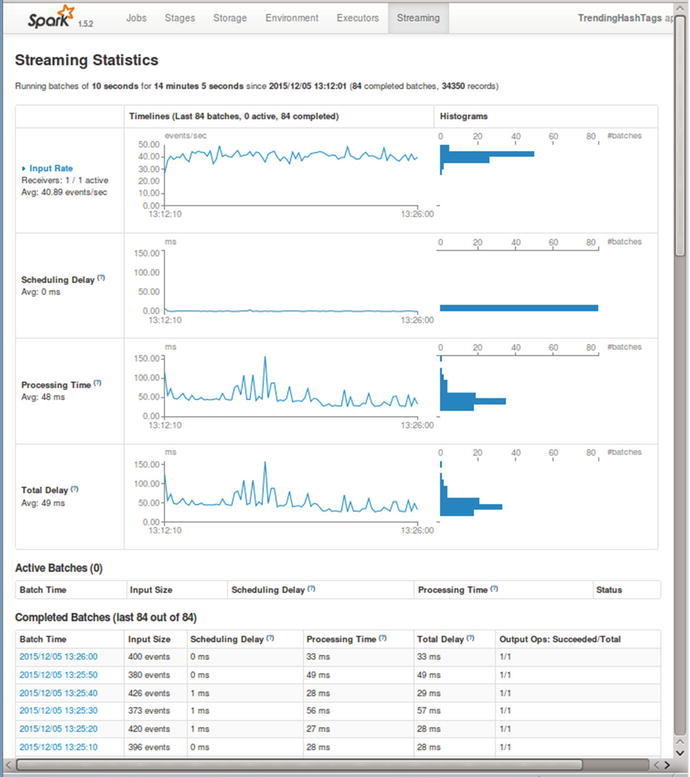
이것으로 부족하다면?
ELK
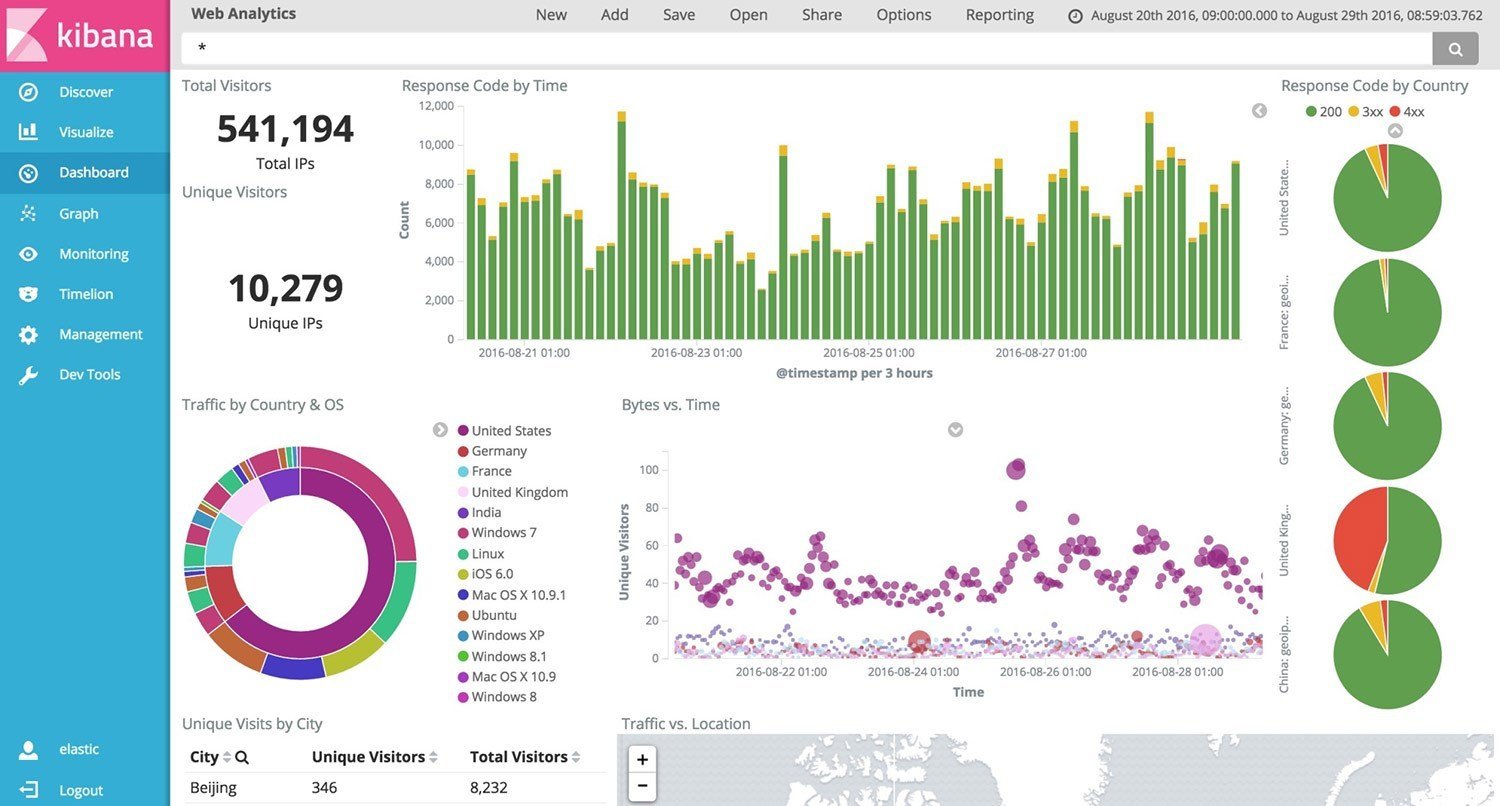
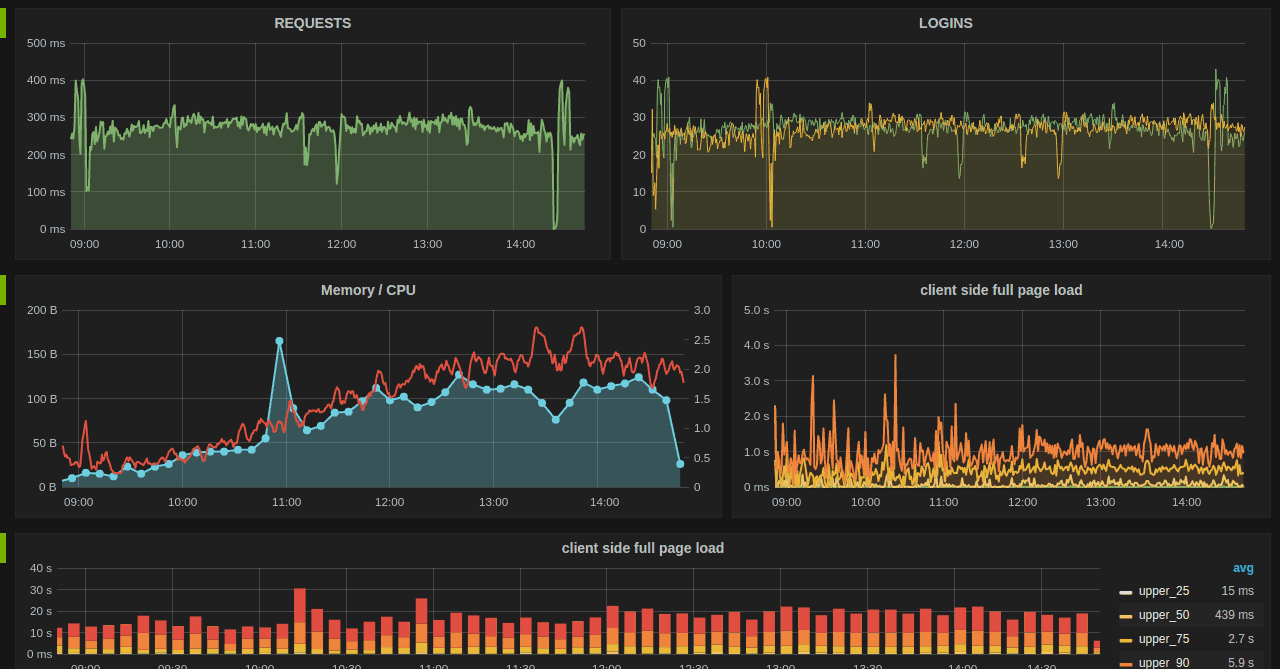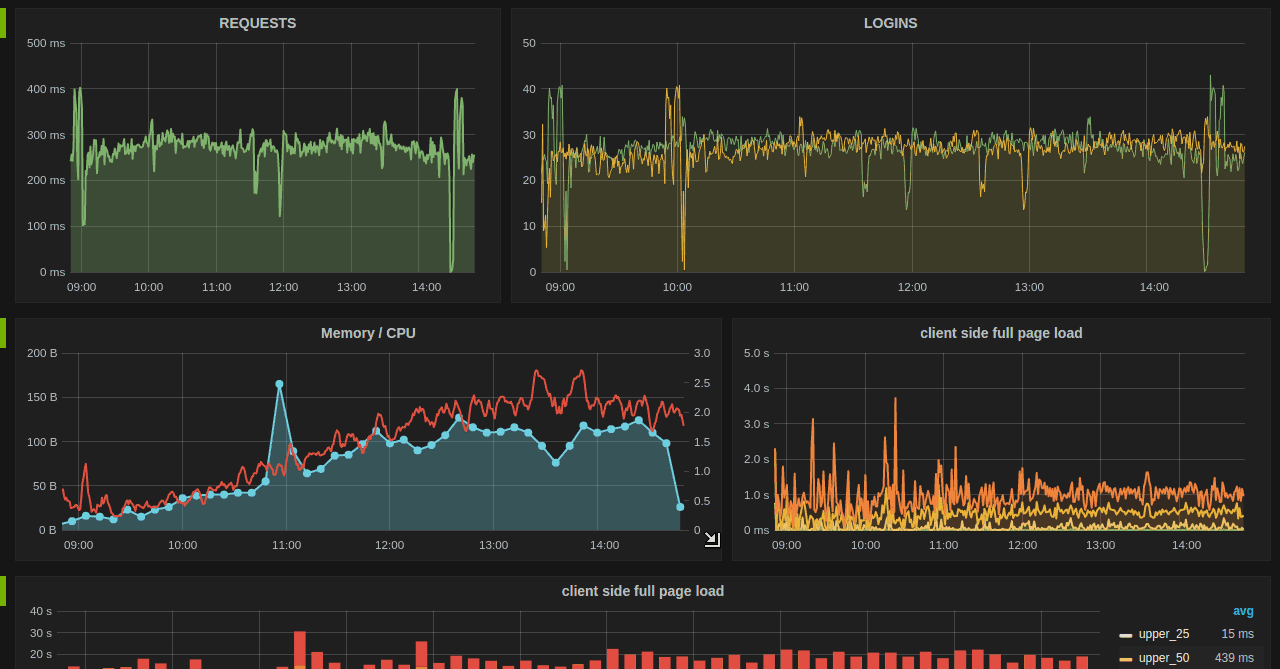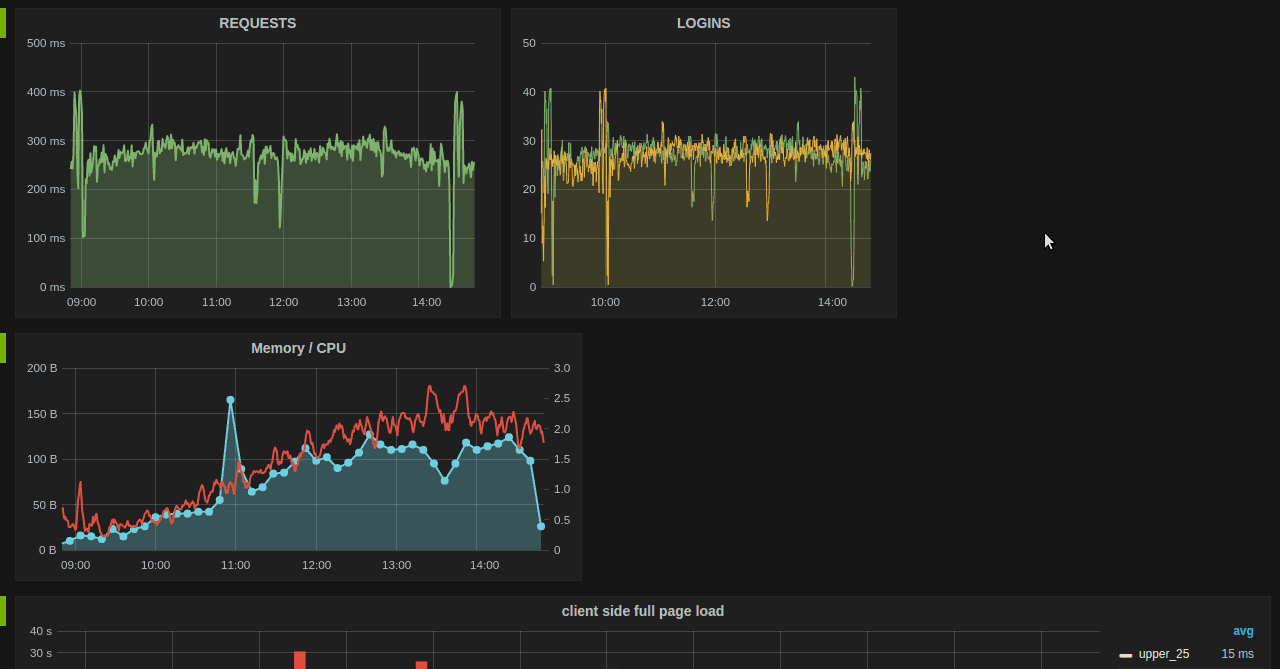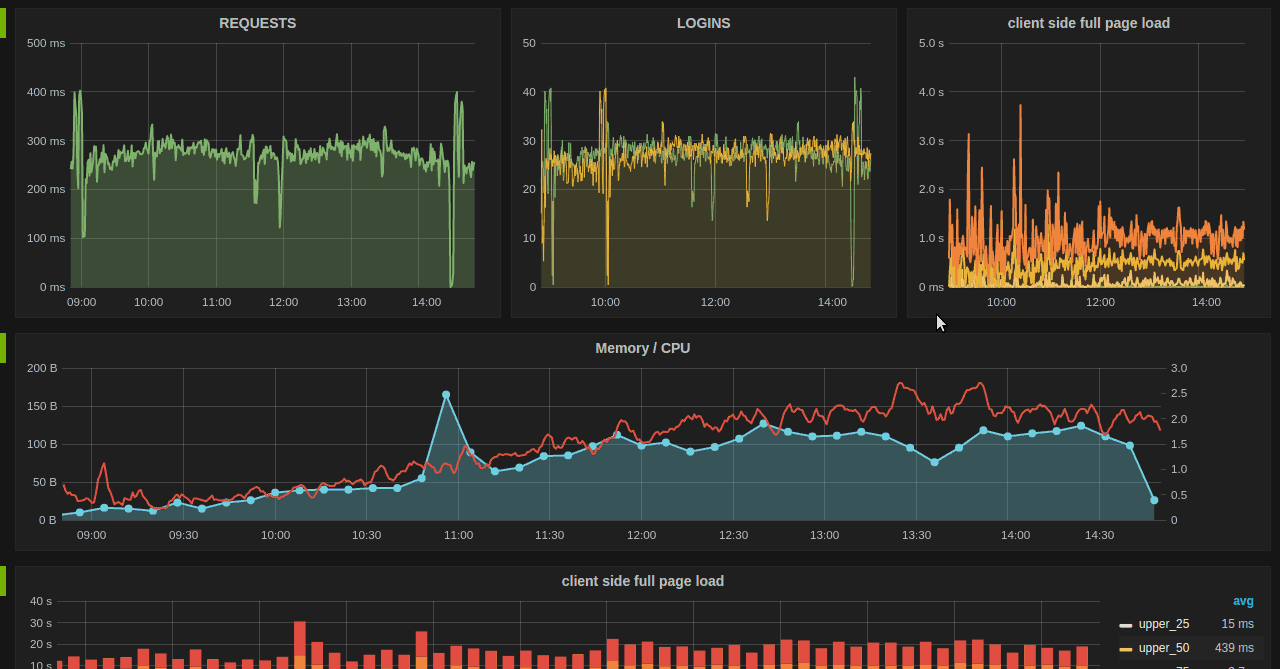
Grafana + Influx DB
Detect Outliars & Alerting
Detect Outliars
- Z-score method
- Modified Z-score method
- IQR method
- Pattern matching
참고 : http://colingorrie.github.io/outlier-detection.html
Outliars example
- Increase streming delay time
- Process restart
- Driver node Shutdown
- Master node Shutdown
- Executor node Shutdown
- Decrease consume message
- Decrease upsert data
- Increase failed parsing message
- etc ...
참고 : http://colingorrie.github.io/outlier-detection.html
- Slack
- SMS
- etc..

Should alerting??
- Increase streming delay time
- Process restart
- Driver node Shutdown
- Master node Shutdown
- Executor node Shutdown
- Decrease consume message
- Decrease upsert data
- Increase failed parsing message
- etc ...
참고 : http://colingorrie.github.io/outlier-detection.html
As with alerts, an information radiator that always shows red has no value. If a condition shown on the radiator isn’t important enough to fix immediately, then remove it.
- O'Reilly Media, Inc. Infrastructure as code
Streaming System
By Yonghwee Kim




