Crónica de un viaje hacia la Alta Disponibilidad

Carlos Cruz
Gorka Gorrotxategi





Somos Irontec
15 años
47 personas
Cientos de proyectos producidos con éxito
Miles de líneas de código escritas
Varios productos importantes liberados
Unos cuantos premios y reconocimientos


... y nosotros
Gorka Gorrotxategi
VoIP Team
Carlos Cruz
VoIP Team

Quizás nos conozcáis de otras charlas por aquí ;)


2009
Presentamos el MSCTL en primicia ;)
2016
Horizontal Escaling
Anycall2AnyAsterisk
2017
Automated Testing en aplicaciones VoIP/RTC
¿Por qué esta charla?
- Tras todas las charlas anteriores, muchos conocidos/contactos/clientes nos pedían algo más aplicable real en el corto plazo.
- Realmente pocas plataformas VoIP(vPBX) necesitan escalar tanto para el concepto de anycall2anyserver.
- Muy pocos equipos técnicos que desarrollen plataformas/soluciones de voz está integrando tests automatizados end2end reales.
- Llevamos varios años de muchas consultorías/despliegues orientados principalmente a la HA.
- Así que el concepto que más encajaba : Alta Disponibilidad
- En cierta forma, creemos que la HA es algo conocido en general, pero no conocido en detalle
- Consideramos que es un tema que no tiene un camino definido cerrado
- Y, principalmente: porque es algo que nos apasiona
Antes de empezar
¿Pero que es Alta Disponibilidad ?



Lo que no es ...
- Fácil
- Larry Zottarelli (ingeniero Nasa de la época de las primeras Voayager):
- "Las sondas actuales no durarán tanto porqué ahora con tanto software es mucho más probable que falle algo que antes".
- Larry Zottarelli (ingeniero Nasa de la época de las primeras Voayager):
- Barato
- No es "pon otro servidor / contrata otro servicio " y fin
- ¡Ojalá fuera así! (o no, que vivimos de esto ;) ).

Lo que implica ...

Customer Side:
- Quiero que no se caiga nunca.
- Esto no puede fallar jamás.
- EOF.
Engineering Team
- Define "esto".
- Define "fallar".
- Define "caer".
-
Y ...
- Hablemos de DRP, managed double IPMI, redundant HA ring network.
-
Y sobre todo:
- Hablemos de lo que no depende de mi.


Asi que en esta charla:
Optamos por no definirla, y la observaremos a diferentes niveles de altitud ;)

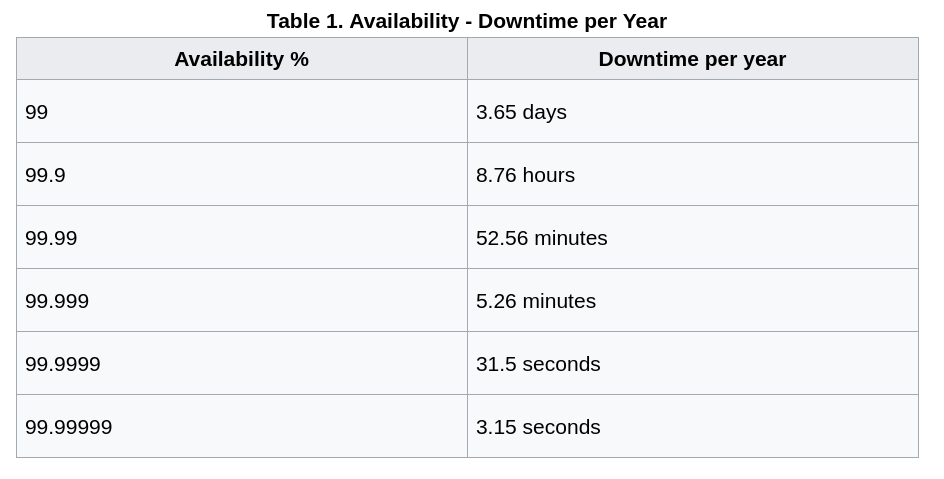
¿Qué viaje queremos hacer con vosotr@s ?
Queremos contaros desde arriba hacia abajo, desde el más absoluto control delegado hasta el barro y los micro-organismos que habitan la HA ;)
Viajaremos en nave espacial, e iremos escogiendo nuestra propia aventura.
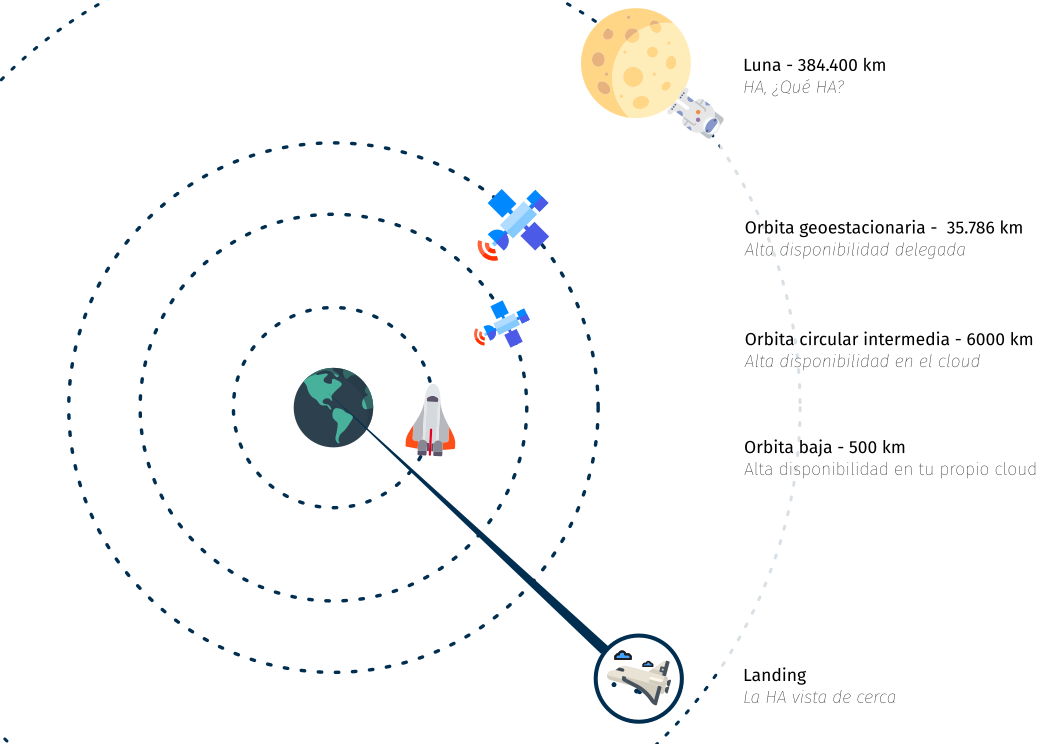
Todo viaje tiene un principio
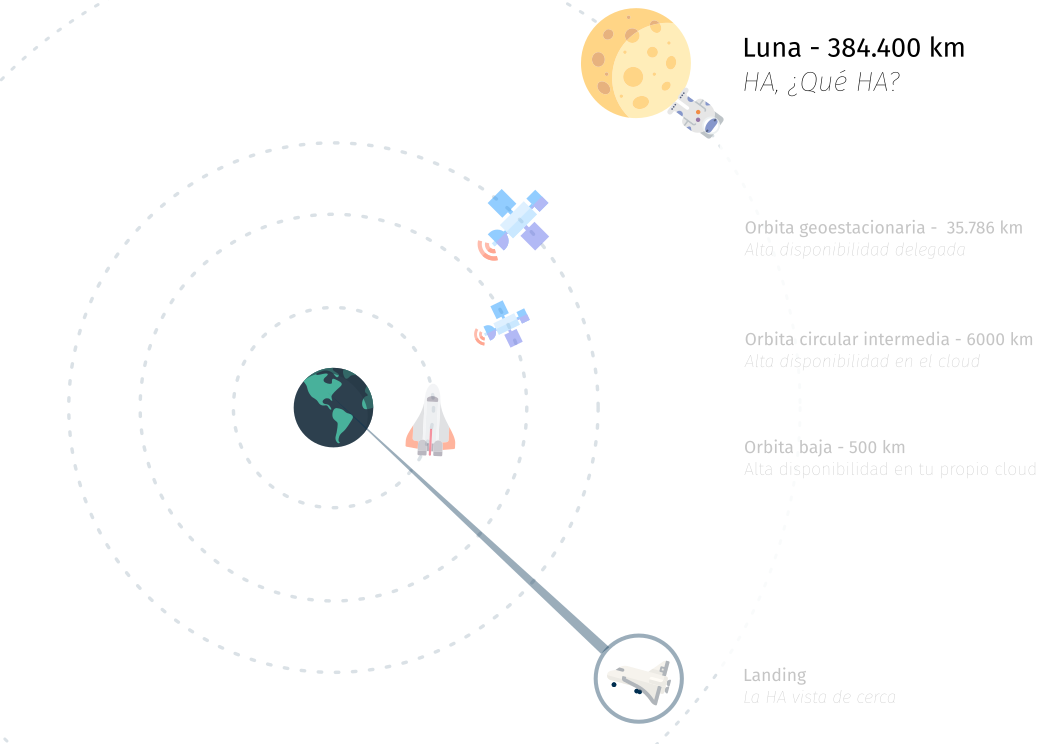
Orbitando a mucha distancia
Estamos orbitando ....
- Nos estamos centrando en una perspectiva más alta.
- No tenemos ni idea de lo que hay por debajo, ni dónde está.
- No tenemos:
- Control, Gestión, Información.
- Tenemos:
- Confianza en nuestro partner.
- Tiempo para otras cosas ;)
Estamos orbitando ....
- En esta órbita podemos estar si no somos la empresa que garantizar la alta disponibilidad ;) rondaremos por aquí cuando somos contratantes/promotores de proyectos
- Igualmente, este podría ser el caso de componentes de nuestras plataformas sobre las que no necesitamos (o no tenemos o no podemos) invertir un tiempo atroz
- Componentes que implementar su HA es compleja.
- Componentes que no son críticos para nuestro core
- Componentes sobre los que no tenemos expertise.





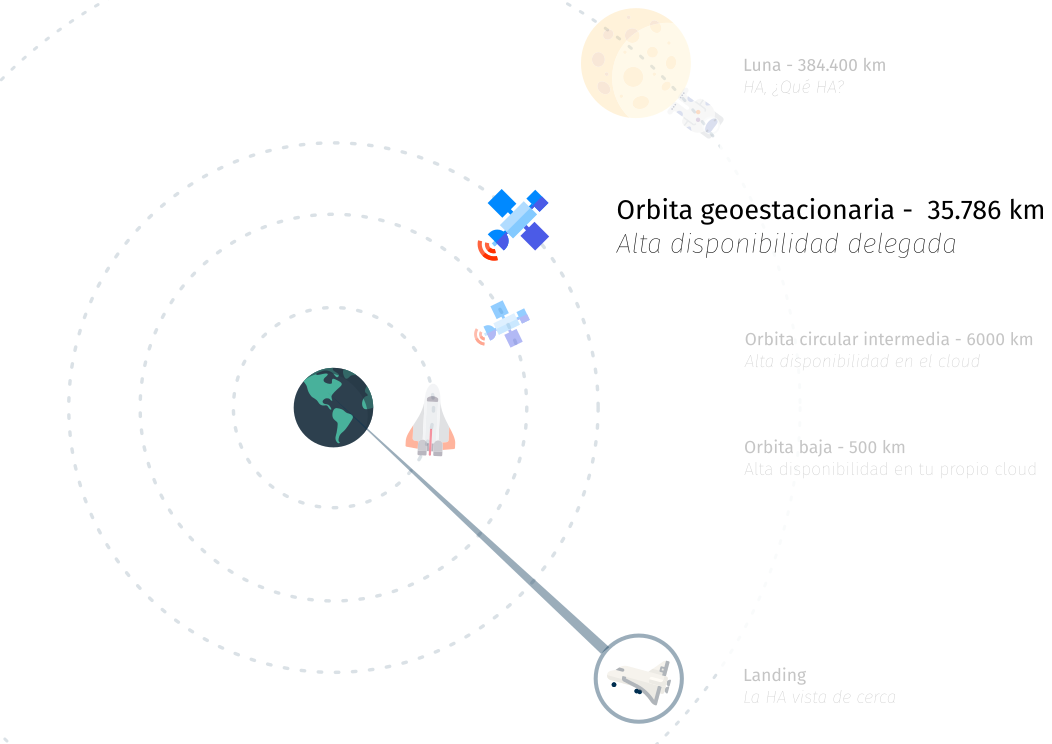
Primera aproximación a la tierra de la HA
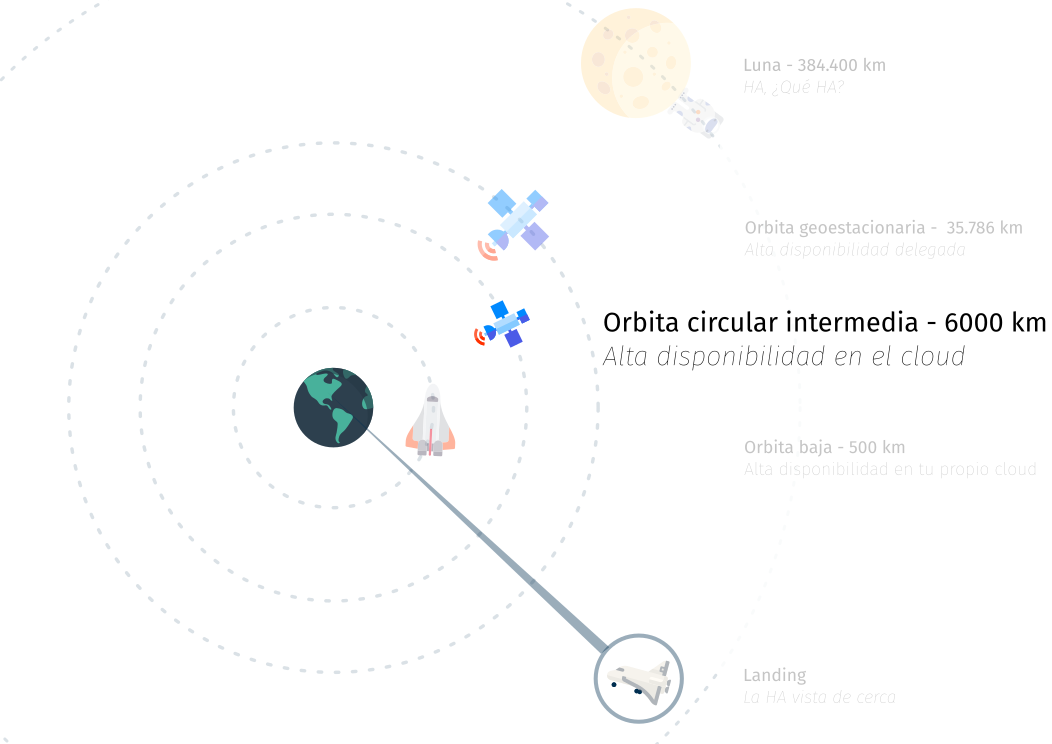
Estamos bajando hacia tierra
- En esta altitud la fauna que habita:
- Hosters y "Cloud".
- Desplegamos nuestras soluciones sobre la infra de un tercero pagándole por ello.
- Nos integramos con el mundo exterior con las posibilidades que nos den.
- Lo que tenemos es:
- Confianza en la infraestructura de un tercero.
- Despreocupación total del hierro, conectividades y cualquier otro dolor de cabeza.
- Lo que no tenemos es:
- Control pleno sobre la infraestructura
- Posibilidades de integración más allá de las del Cloud.




Systems/Vo(IP) Specifics en esta altitud
- Las plataformas son generalmente de proposito general
- Balanceadores VoIP
- 404 Not Found
- Balanceadores VoIP
- Construirse todo usando sus piezas.
- Replicaciones de objetos / storages.
- Datos relacionales (BBDD).
- Routing Complejo inter region / infra
- Cross-Cloud HA standard?
- Build OK: Infra as code .... ¿HA?
- ITSP's/Operadores
- Integraciones complejas con 3eros vía enlaces dedicados garantizados
- AWS Direct Connect, Google Cloud Connect, OVHCloud Dedicated Access, ...
- AWS Direct Connect, Google Cloud Connect, OVHCloud Dedicated Access, ...
- Integraciones complejas con 3eros vía enlaces dedicados garantizados


existe!
... y para mucho tiempo ?

Follow your cloud rules ;)
- Con el cloud escogido hay que ir hasta el final del camino.
- Salvo que sea el cloud de un hoster cercano:
- IP's virtuales / Routing: Not so easy en raw mode.
- Mandatory seguir sus reglas de juego.
- Tipo:
- Amazon AWS AutoRecovery (vs vip_monitor integration)
- OVH Failover/Floating IP (OpenStack basement).

En el espacio pero cerca
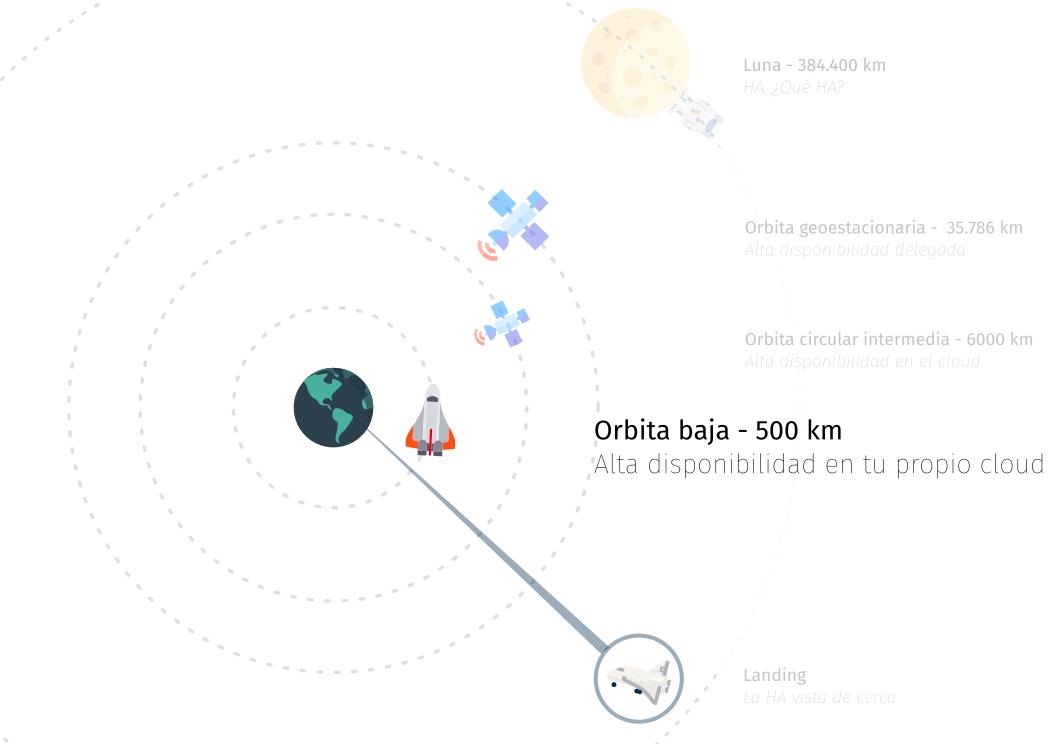
Estamos ya volando a baja altura
- Volamos casi por debajo del radar ;)
- Decidimos montarnos nuestra propia infraestructura
- Optamos por "algo" (que no vemos desde tan arriba) capaz de sostener nuestras aplicaciones de voz.
- Dilucidamos desde arriba lo que parecen servers con color de hypervisor, pero pantalón a rallas con porta containers, el cloud no nos deja ver más allá ;)


HA de Infraestructura
- Hemos optado por la HA que sobrevuela este nivel de altitud ;)
- VMWARE VSPHERE HA, Proxmox HA Manager y derivados de la raza hypervisión ;)
- El hypervisor de encarga de hacer que sobreviva nuestra máquina.
- En el mundo container (discovery a parte), el concepto es más bien similar, pero orientado más a servicio.
- Empezamos a conocer esto del
- HA aKa "que no se caiga nunca"






HA de Infraestructura
- Podemos ver las armas de Murphy y sus leyes de la física IT
- Nos atacará con:
-
Resource Agent
- O como saber realmente si "algo" está funcionando, arrancando, frito o moribundo.
-
Quorum
- Trasladando la "democracia" a nuestros nodos?
-
SPLIT BRAIN
- Por alguna razón a más metros de altitud vivíamos mejor :)
-
Node Fencing / Stonith
- Shoot the other node on the head
-
Resource Agent
- ... y con esto, aquello de "añade otro server y listo" se va esfumando


HA de Infraestructura
- Deberíamos abrir un poco el paracaidas y quedarnos a esta altitud profundizando ?
- Con total sinceridad, nuestra experiencia:
- Sumando nuestro tiempo/curva de aprendizaje total:
- La HA nos ha generado infinitos más problemas que problemas ha evitado.
- "Hasta ahora todo va bien" <La Haine>
- Sumando nuestro tiempo/curva de aprendizaje total:
- ... y si quizás fuera mejor tener un DRP en condiciones acordado con el cliente que un automatismo que no sea fácil de domar?
- Escoge tu propia aventura!


HA de Infraestructura
- ¿Hasta dónde se llega con estos habitantes?
- Generalmente:
- Mundo tradicional
- Disponibilidad "rol based VM"
- Mundo container
- Disponibiildad "Service oriented "
- Asume que estamos ya ready con services multi master.
- Reglas de HA con conceptos de afinidad, prioridad
- Disponibiildad "Service oriented "
- Mundo tradicional

Kubernetes POD Priority Support
Aterrizando en la tierra de la HA
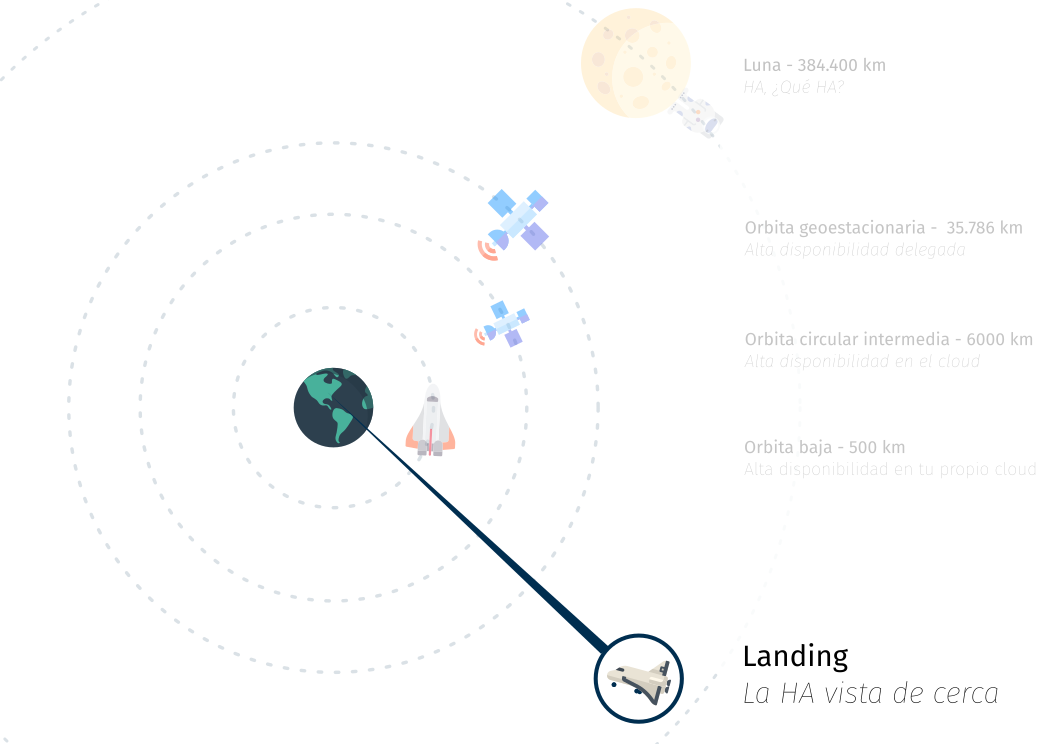
Estamos llegando al suelo
- Hemos decidido que queremos controlar end2end todo.
- Los frentes habituales:
- Networking
- Compute/Resources
- Storage
- ... y seguimos siendo VoIP Specific agnostic
- ¿Será bueno o malo?




Llegando al suelo ... networking
- WAN
- ¿Multihoming? ¿BGP/ AS ? ¿Multi pop (anycasting?) ?
- ¿Cross-DC ?
- Dedicated Cluster Network
- Aislada de factores ajenos (intervenciones, saturación, cambios).
- Concepto de poder decidir en base a lo que se sabe vs en base a lo que no
- Split brain | Partition | Isolated
- vs "decidimos que tu no puedes dar este servicio porque no llegas al core X-Y-Z"
- Split brain | Partition | Isolated

Llegando al suelo ... compute/resources
- Open source world
-
Clusterlabs
- CoroSYNC - Pacemaker STACK
- Sponsorizado por Redhat, SuSE, Linbit.
- El stack más conocido y completo
- Quizás no sea una buena idea si "sólo" queremos una IP Virtual (vrrp, keepalived, ...).
-
Clusterlabs
- Curva de aprendizaje inicial ligeramente elevada.
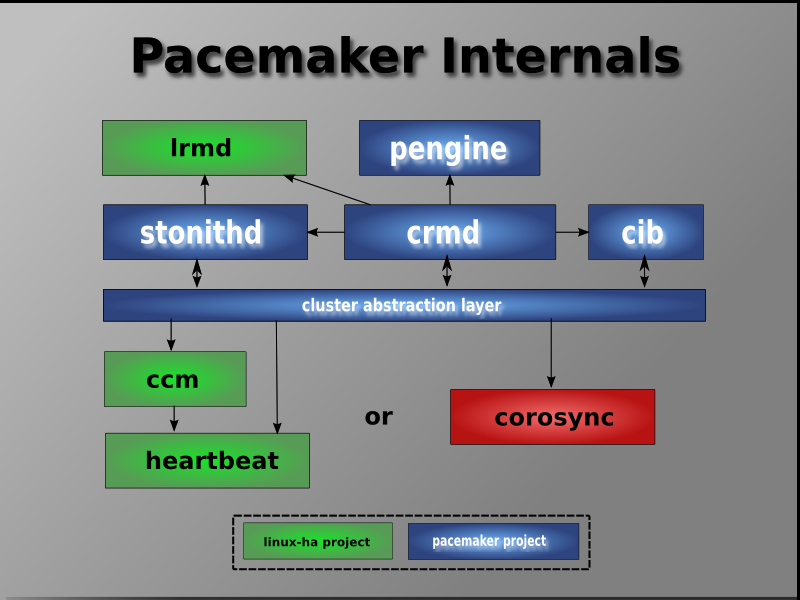
Llegando al suelo ... compute/resources
- Pacemaker key components
- Resource Agents
- Controladores del propio recurso, L7-Aware.
- Los más complejos/habituales ya implementados (drbd, mysql, systemd unit file, ...).
- Skeleton / Libs para implementar propios.
- CIB
- Definición propia del cluster, con sus constraint's (location, colocation), scores, primitives. ..
- Puede llegar a ser muy compleja
- Fence Agents
- ILO(X), IDRAC, IPMI, APC ...
- Resource Agents

Llegando al suelo ... compute/resources
- CIB micro ejemplo
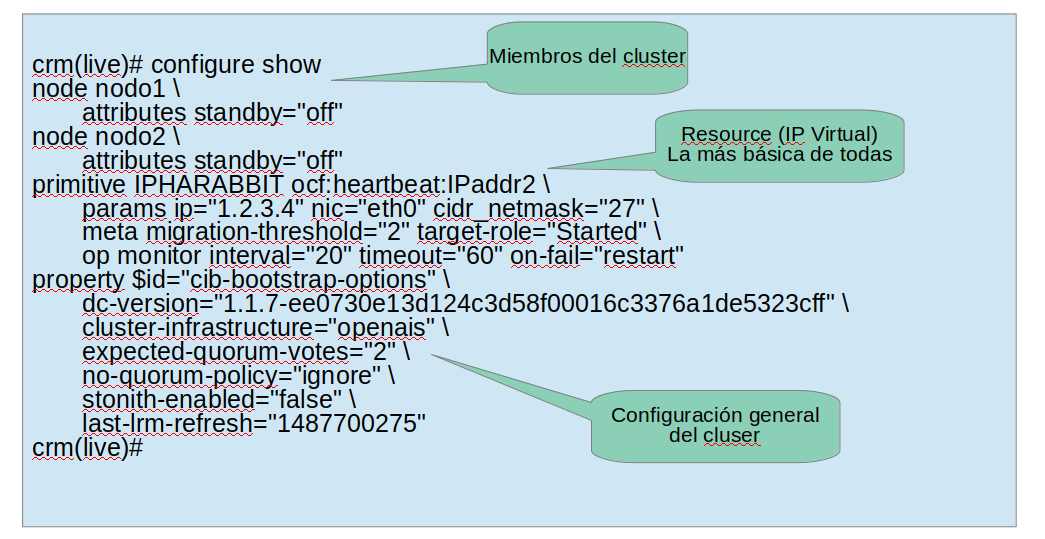
Llegando al suelo ... storage
- Target: Local HA Storage
- ¿Externalizable en hard dedicated?
- Cabinas específicas y un "HA key componente menos"
- ¿Externalizable en hard dedicated?
- Target: Pseudo WAN HA Replicated Storage
- ¿Externalizable en Cloud based object access?
- Not so easy "mountable FS".
- ¿Local "satelite" para one-way cross-sync?
- Switft, S3 ...
- Not so easy "mountable FS".
- Implementable
- DRBD MultiPrimary + (OCFS2 | GFS2 )
- GlusterFS
- CEPH
- ¿Externalizable en Cloud based object access?


Infraestructura OK pero...
... ¿nuestra solución VoIP encaja en ella?

SOLUCIONES VOIP DISTRIBUIDAS
- SIP es un protocolo complejo
- IPs en los mensajes SIP (en capa 7)
- Vía, Record-Route, Route, Contact...
- El NAT rompe el protocolo
- SIP ALG no ayuda
- Múltiples fabricantes con interpretaciones distintas
- Implementaciones simplistas
- Carriers que asumen first hop
- Terminales que no soportan RTP asimétrico

NOS MOVEMOS EN UN MUNDO HOSTIL
Retos
- Solución VoIP monolítica
- Evitar Single Point Of Failures
- Aplicaciones realtime

RETO 1 - MODULARIDAD DE LA SOLUCIÓN
- De nada sirve que nuestra infraestructura sea HA si nuestro software es monolítico
- Conceptos clave:
- Programación ortogonal
- Componentes desacoplados/desacoplables
- Clustering


RETO 1 - MODULARIDAD DE LA SOLUCIÓN
- Nos centramos en elementos VoIP, pero los mismos conceptos aplican al resto de componentes:
- Distributed storage (GlusterFS, Ceph...)
- SQL database clustering (Percona, Galera...)
- NoSQL cache cluster (Redis M/S, Redis cluster)
- Async framework cluster (Job dispatcher / Worker model)
- Web portal load-balancers (HAproxy, Apache/NGINX)
- Etc.
RETO 1 - MODULARIDAD DE LA SOLUCIÓN
- Punto de partida:
- Asterisk 4x4 que hace todo:
- Registrar server
- Application server (bussiness logic)
- Media server (media handling, transcoding, recordings)
- Etc.
- Asterisk 4x4 que hace todo:
- Que Asterisk pueda hacer (casi) todo no significa que tenga que hacerlo todo (ni que sea el que mejor haga todo).

Usar software especialista para cada labor
SIP REGISTERs
- Múltiples vías:
- Registrar throttling + mid_registrar module en Edge Proxy?
- Location estática en Asterisk(s) + OB proxy.

SIP REGISTERs
- ¡¡Asterisk 100% libre de registros!!
- Elemento modular y escalable:

SIP PRESENCE
- PUBLISH / SUBSCRIBE / NOTIFY
- Mucho tráfico en entornos PBX (BLF)
- Mismo enfoque:
- Módulos implicados:
- pua (+ pua_dialoginfo)
- presence (+presence_dialoginfo)
- Corriendo en:
- Edge Proxy
- Entidad propia: Presence server
- Módulos implicados:
- Caso app_queue:
- pua_reginfo
- async job
- ARI addqueuemember/removequeuemember


SIP PRESENCE
- ¡¡Asterisk 100% libre de SUBSCRIBEs/NOTIFYs!!
- Elemento modular y escalable!

MEDIA HANDLING
- La gestión de media es CPU consuming
- Limita concurrencia en Asterisk: hay que evitarla.
- Obstáculos para la liberación:
- Grabación de llamadas:
- rtpproxy/rtpengine + osips/kam modules
- Códigos DTMF (RFC2833/RFC4733):
- Grabación on-demand
- Vía SIP INFO Record header
- Grabación on-demand
- Transcoding:
- RTPengine transcoding magic!
- Grabación de llamadas:

MEDIA HANDLING
- Asterisk out of media-path! (when possible)
- Elemento escalable (rtpengine/rtpproxy sets)

- Hemos pasado de un Asterisk todoterreno a una arquitectura modular:
- Edge proxy
- Registrar server distribuido
- Presence server distribuido
- Stateless Application server
- Media server independiente
- Software especialista para cada función
- Elementos desacoplables/escalables





RETO 1 - MODULARIDAD DE LA SOLUCIÓN
CONCLUSIONES

- El concepto de Edge Proxy suena bien:
- Punto único de entrada a nuestra red SIP
- Útil en mundo mono-IP-noDNS :(
- Reparte juego al resto de elementos
- Punto único de entrada a nuestra red SIP
- Inconvenientes:
- Routing SIP más allá del first hop:
- Hay que ganar esa batalla
- fix_route_dialog()
- Si no... SBC (Kamailio / OpenSIPS / SEMS / HW)
- ¿Y si cae el Edge proxy? ¿Y si necesitamos escalarlo?
- Routing SIP más allá del first hop:
RETO 2 - SINGLE POINT OF FAILURE
Múltiples Edge Proxies - DNS load balancing (1/3)
- Registros DNS tipo NAPTR + SRV + A
- Priority & Weight
- Múltiples Edge Proxies en paralelo
- Problemas:
- Es el camino, no es muy transitado: ¡la gente quiere una IP! :(
- Depende de la implementación del cliente
- Complica resto de elementos:
- Multi-proxy: mecanismo de shared memory, etc.
- PATH header en lugar de OB proxy

Múltiples Edge Proxies - Anycast (2/3)
- Múltiples Proxies utilizando la misma IP
- Magia de networking para que los paquetes SIP lleguen a un proxy
- Proxies trabajando como uno solo gracias a clusterer module de OpenSIPS
- Una maravilla :) :) :) (thx OpenSIPS team!)
- Inconvenientes:
- Complica troubleshooting
- UDP-only
- Production ready?

Múltiples Edge Proxies - Master/Slave (3/3)
- Múltiples máquinas, solo una activa
- Cluster managed IP+service:
- Corosync/Pacemaker
- Desventajas:
- Failover-only (no load-balance)
- No es tan hacker como Anycast
- Ventajas:
- No complica resto de elementos
- Mantienes el enfoque mono-IP :(

- El Edge Proxy es un SPOF de libro
- Hay múltiples maneras de mitigarlo:
- Múltiples Edges en paralelo
- Solo uno activo, pero más preparados para asumir el control
- Nuestra experiencia:
- Activo/Activo es atractivo pero añade complejidad
- Uno único proxy es capaz de hacer el trabajo
- Si no, desacoplar funcionalidades
RETO 2 - SINGLE POINT OF FAILURE
CONCLUSIONES

- La naturaleza realtime de las aplicaciones VoIP reduce la tolerancia a errores.
- En una arquitectura distribuida como la que hemos descrito, ante ciertas caídas de servicios/nodos, se iniciaría un proceso de transición.
- El proceso de transición puede ser muy rápido y el servicio se restablece al de pocos segundos.
- Pero... ¿y qué ocurre con las llamadas en curso?
RETO 3 - SESIONES REALTIME

- Para entornos tan críticos, estos serán nuestros aliados:
- Kamailio/OpenSIPS
- RTPengine
- REDIS
- RTPengine escribe las sesiones en REDIS, que estará replicado
- flag --redis
- Al arrancar, no empieza de cero, sino con los bindings de las sesiones activas
- https://blog.irontec.com/voz-ip-alta-disponibilidad-para-entornos-criticos-sin-perdida-de-llamadas/
RETO 3 - SESIONES REALTIME
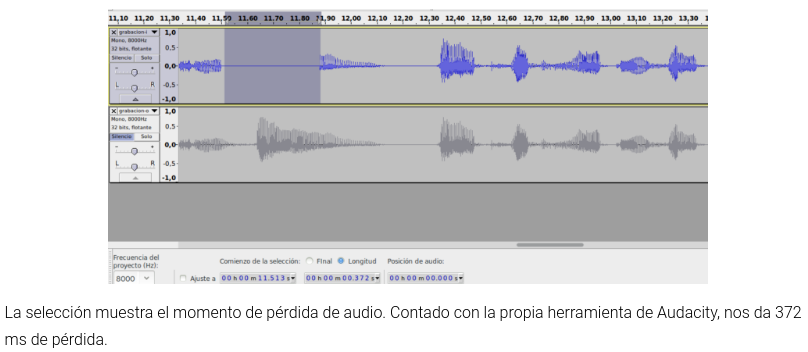
DEMO
Objetivo:
- Establecer una videconferencia entre 2 navegadores
- Forzar una transición cortando el cable de red
- Seguir con la videoconferencia como si no hubiera pasado nada :)

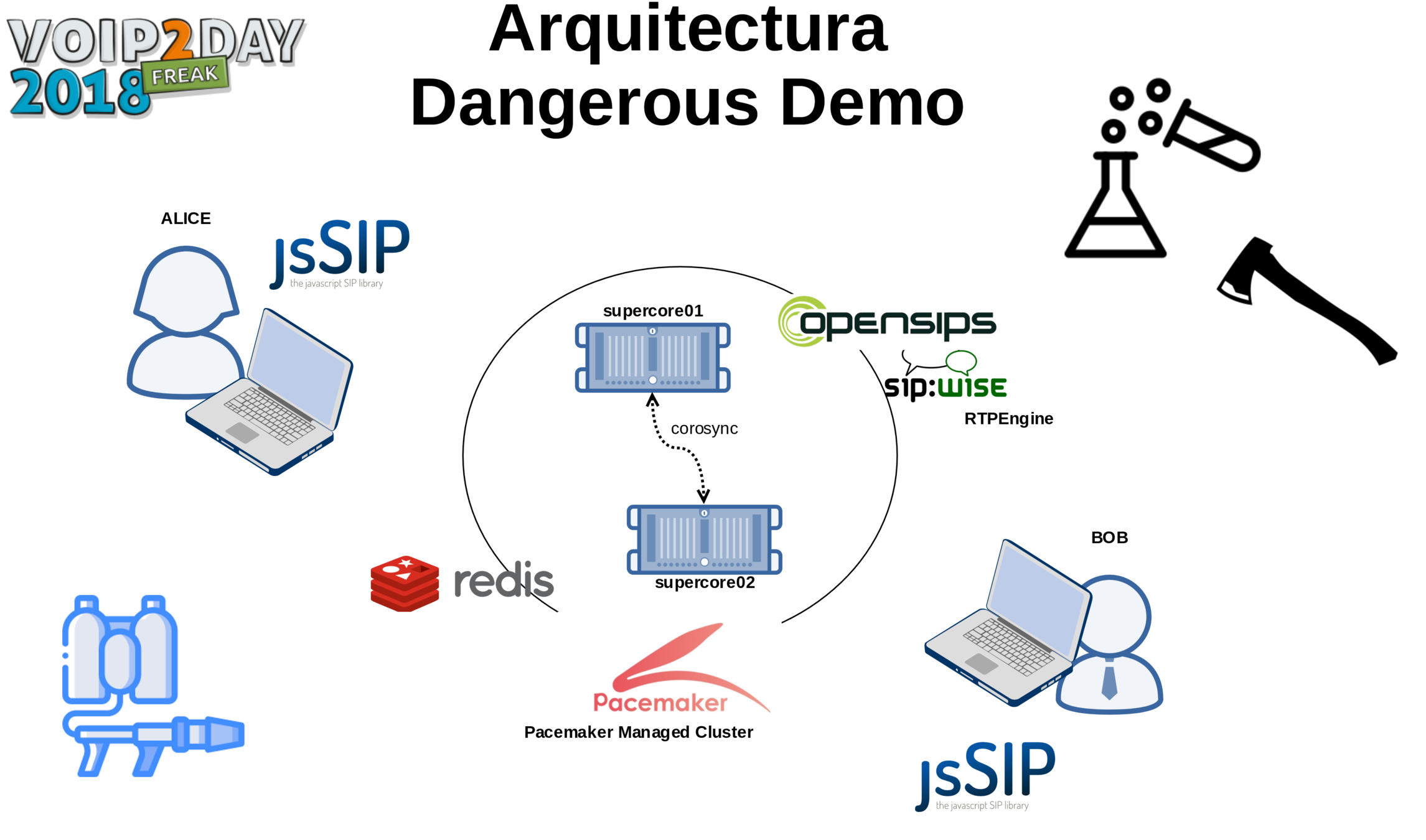
CONCLUSIONES FINALES
- En el ecosistema VoIP existen herramientas para solventar cualquier problema técnico que nos podamos encontrar:
- Free Software
- Con documentación
- Múltiples canales de ayuda
- Desarrollo continuo
- Lo primero de todo: agradecer e intentar aportar y apoyar :) :) :)


CONCLUSIONES FINALES
- Que existan soluciones ante cualquier posible fallo no significa que haya que implementarlas todas
- Aunque nos entren ganas :D
- Cada mecanismo de contingencia añade complejidad a la solución:
- Introduce nuevos fallos
- Dificulta/Ralentiza troubleshooting
- Evaluar coste/beneficio de cada mecanismo.

"No se puede caer nunca"
"Asumo que se puede caer ante ciertas circunstancias estadísticamente improbables que no me van a impedir alcanzar los niveles de SLA que requiere el servicio"
¡Muchas gracias!

Crónica de un viaje hacia la Alta Disponibilidad
By zgor
Crónica de un viaje hacia la Alta Disponibilidad
Presentación Irontec en el VoIP2Day 2018.



