Traffic Flow Exchange Platform
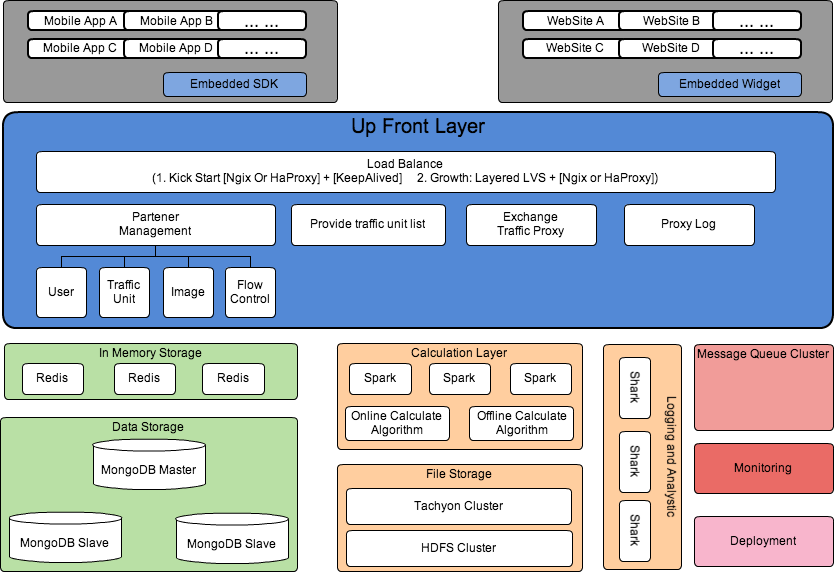
Stack
- Develop Language:
Scala, JavaScript, IOS/Android
- Load balancing:
- Kick-start: NGINX or HAProxy plus Keep-alived
- Growth: Layered Upper: LVS Lower: NGINX or
HAProxy plus Keep-alived
- Storage:
- File Storage: Tachyon (AMPlib) + HDFS (Hadoop)
- Data Storage: MongoDB(10Gen) or TokuDB(TokuTek)
- In-memory storage: Redis
- Computing:
- Spark(AMPLib), Shark(AMPLib)
- Finagle(Twitter)
Why SCALA?
- Mixing OO (object-oriented) concepts and FP (functional programming) styles elegantly.
- Living upon the mature Java platform
- Providing more efficiency towards computing
- Twitter already proved its success. And Twitter also open source the library "Finagle". So we could directly building everything upon the library.
- Spark (The rock star for big data computing) is also built upon scala.
- Tachyon (Java) is high efficiency hdfs wrapper and Shark (Scala) provides the similar functionality of hive
Why SPARk?
- Traffic unit is small and its size is predictable constant. (We could ask for the same size for picture, description. We could also shorten url)
- HDFS is more suitable for large chunk size structure. Instead tachyon prefer the small size structure and could fit more data into memory.
- In memory computing is the key for speed. Especially important for online computing.
- Built-in support many useful features: MR(map reduce), groupby, filter, etc.
- Just received millions dollars investment and became apache incubator project recently.
Why SCALA & SPARK?
- Traffic exchanging among many sites or mobiles need to be blade fast.
- Small unit can more fit into the memory, so Tachyon could help on that. And Spark will be fast if the data already in the memory.
- Spark already provide many built-in algorithms for data mining.
- If computing part based on Scala, it would be nice the whole backend stack also based on Scala. Fortunately finagle also provide many features which already be proved by Twitter.
Why REDIS & MongoDB?
- The system meet most scenario: most read and less write. So MongoDB is more suitable. But if situation changes or wrong predicts, we could leverage with TokuDB or other solutions.
- For traffic unit providing part and recommending list should be in relatively static, so it will be nice to be holding in the memory larger the accessibility. Redis is designed for this need.
- Traffic unit doesn't need the complex relationship, so it will be easier to be designed as simple document (JSON, etc).
- They are fast, and if tuned well they could become even faster surprise.
Why not HDFS?
- HADOOP is good, but less some wrapping features.
- Tachyon provides such kinds of wrapping.
"Tachyon is a fault tolerant distributed file system enabling reliable file sharing at memory-speed across cluster frameworks, such as Spark and MapReduce. It achieves high performance by leveraging lineage information and using memory aggressively. Tachyon caches working set files in memory, and enables different jobs/queries and frameworks to access cached files at memory speed. Thus, Tachyon avoids going to disk to load datasets that are frequently read."
-
Tachyon provides "Master fault tolerance" feature elegantly.
- Tachyon is fast when working with Spark or Shark. See bechmark
Misc
- ID generation could take: SnowFlake algorithm which is much better for index.
- Security part could leverage OAuth: Scala OAuth
- Log collection could leverage with Scribed (Fackbook)
- Other could help us: ①预约会议:Google日历,②实时会议:Moxtra,③内部同步与共享:Dropbox,④外部共享:Droplr,⑤远程会议:微信群,⑥数据分析和展示:Geckoboard,⑦客户关系管理:Highrise,⑧时间管理:Rescue Time,⑨组织团队活动:Eventbrite。
Traffic Flow Exchange Platform
By Andy Song



