Chrome Extensions for Page Scraping & Analysis
Baskin Tapkan
gdg-tc://devfestmn-2016
What we will cover
- Overview of Chrome Extensions
- Page Scraping Techniques
- Node Packages for Scraping
- MongoDB Overview
- Firebase Overview
- Sample Application Walkthrough
- Unit and Integration Testing
- Summary - Q & A
About me
Full Snack(*) Software Developer



User Group Junkie
@baskint
- Angular-MN
- Arduino-MN (IoT)
- Elixir-MN
- GDG-TC
- JavaScript-MN
- MongoDB-MN
- Node-MN
- Ruby-MN

BaskinTapkan
Hobbies & Crafts





Chrome Extensions
- not to be confused with chrome://plugins
What is it?
Small program running in the browser
Where do I run it?
Only in the Chrome browser. They don't run in Firefox, IE or Safari. But they run on Macs, Windows and Linux OSes
How do I write one? Is there a ChromeScript?
Nice try :) Already uses web languages we know today such as JavaScript, HTML, and CSS
... and we will not be covering this kind!
Starting point
chrome://extensions
- Blocking Ads
- Readability
- Form fillers
- Customized Search
- Social Media
- Productivity
- Security

Useful for
Extension Review
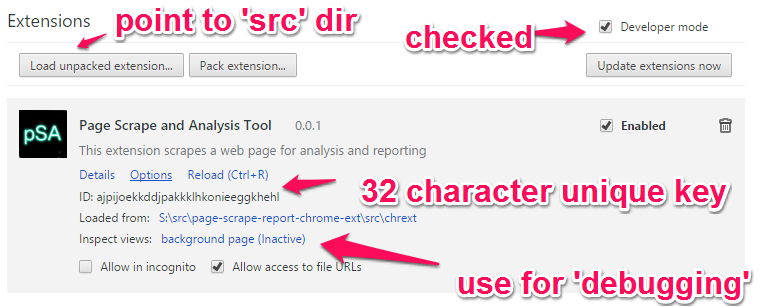
Task Manager
- Click Chrome Browser Hamburger menu - on the top right corner
- More tools
- Task Manager
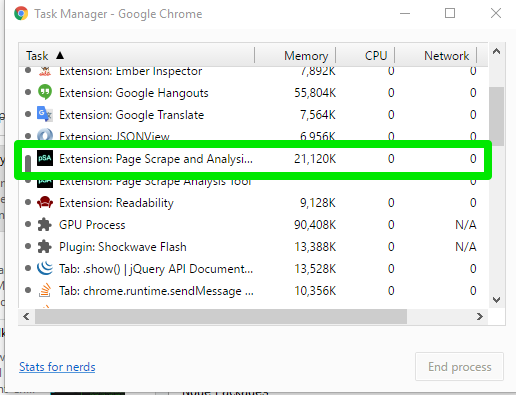
Create one...
Start with a manifest.json file
{
"manifest_version": 2,
"name": "Page Scrape and Analysis Tool",
"description": "This extension scrapes a web page for analysis and reporting",
"version": "0.0.1",
"browser_action": {
"default_icon": "images/icon128.png"
},
"icons": {...},
"background": {
"scripts": ["eventpage.js"],
"persistent": false
},
"browser_action": {
"default_icon": "images/icon48.png"
},
"permissions": [...],
"content_scripts": [
{
"matches": ["<all_urls>"],
"css": ["psa/pagescrape.css"],
"js": ["psa/pagescrape.js"]
}
],
"web_accessible_resources": [...]
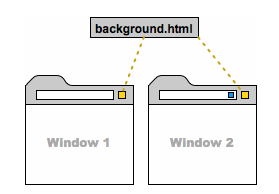
}Background Page
- Load various configurations
- Set event listeners
- Access and use Chrome SDK
- Create a new tab and initialize its state
- Send messages to content scripts or other extensions
- Control Workflow of an extension
- Orchestrate events
- Store state data
A few things you can do within a background page
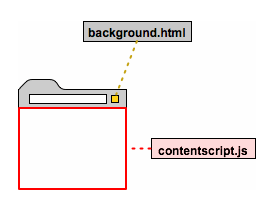
Content Scripts
- Use when interaction with the target page is desired
- Can read details of displayed web pages
- Content scripts can communicate with the parent extension via messages
- Can make cross-site XMLHttpRequests
- Use chrome.* APIs with a few exceptions (extension, i18n, runtime and storage)
"content_scripts" [
{
"matches":["http://www.google.com"],
"css:" ["psaStyles.css"],
"js": ["jquery.js", "psaContent.js"]
}
],
...
chrome.* APIs
Asynchronous - they return immediately
- .browserAction
- .cookies
- .extension
- .pageAction
- .runtime
- .storage
- .tabs
- .windows
There are over 40 - here is a few of interest
Pro-tip: Use "Promises"
var p = new Promise(function(resolve, reject) {
chrome.storage.local.set({'mykey': 'myvalue'},
function() { resolve('saved');
});
p.then(function() {
// continue happy path
}).catch(function() {
// continue failed path
})
return p;Page Scraping Techniques
- Human copy-and-paste
- Text grep - regular expression matching
- HTTP Programming
- HTML Parser
- DOM Parsing
- Web-scraping software
source: wiki
next up... two Chrome Extensions for Page Scraping in the Chrome Web Store
Scraper-I
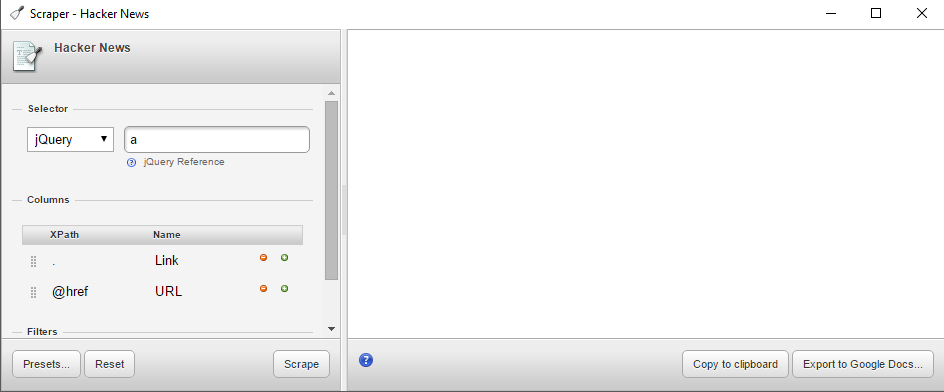
Source is out-of-date (2010). Version 1.6 is using and older Chrome API, won't load with new.
Download the latest from Chrome Web Store
Scraper - II
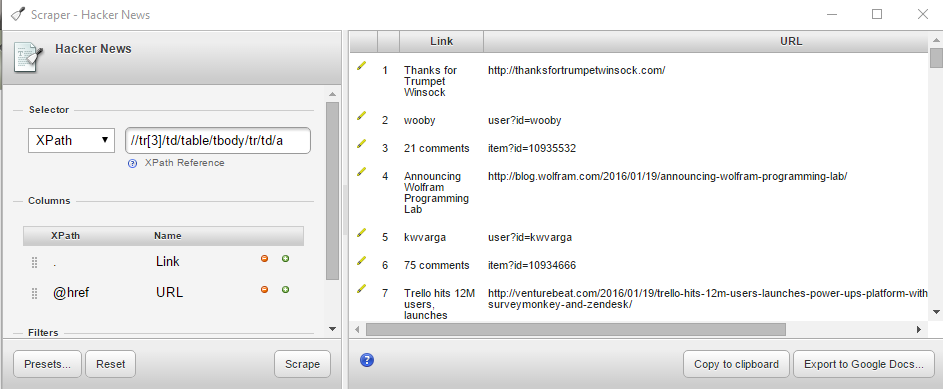
Right click on a link - modify the X-path
Scraper - III
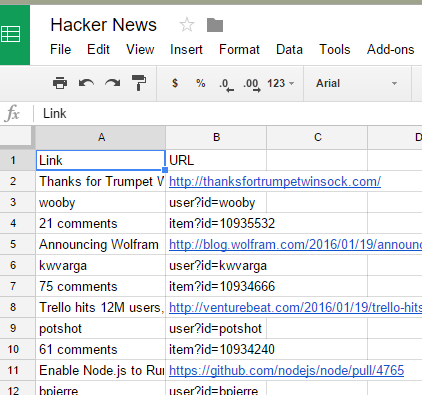
"Export to
Google Docs" works!
So does
"Copy to clipboard"
DEMO
Web Scraper-I
Has nice web site. Enterprise Data extraction service available!
Better support. Tutorial introduction video posted on site. Link to Free version on Chrome Store.
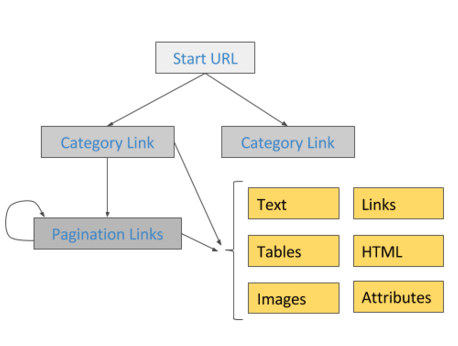
Access it under
Chrome Developer Tools
Comprehensive
Tutorial and Documentation
Pro-Tip: Do NOT use CDT undocked. Selectors don't work.
Web Scraper-II
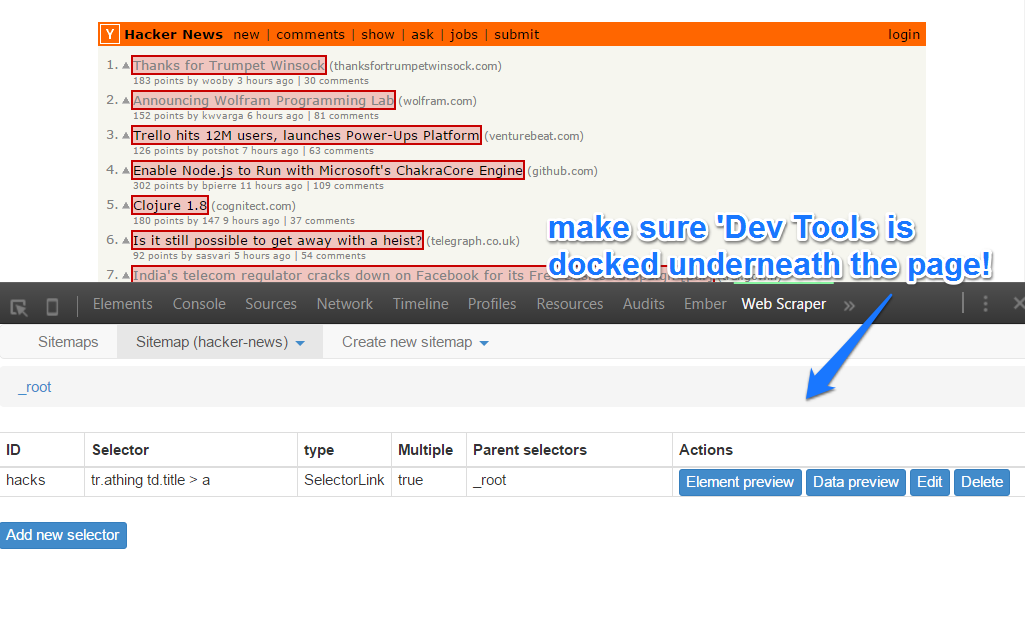
Web Scraper-III
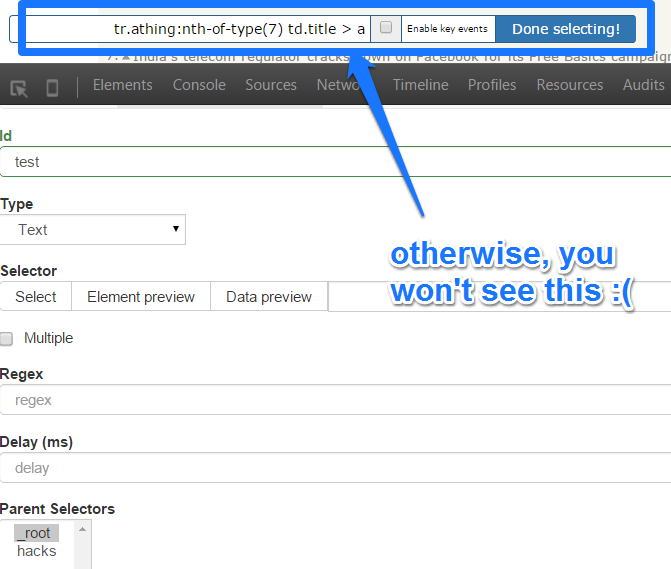
- There is a learning curve
- Lots of options
- Good support and documentation including videos
- Commercial product available
Web Scraper-IV
Scraped data available
as CSV and shown on
screen
{
"startUrl":"https://news.ycombinator.com/",
"selectors":[{
"parentSelectors":["_root"],
"type":"SelectorLink","multiple":true,
"id":"hacks",
"selector":"tr.athing td.title > a","delay":""
}],
"_id":"hacker-news"
}Export Sitemap is a simple JSON
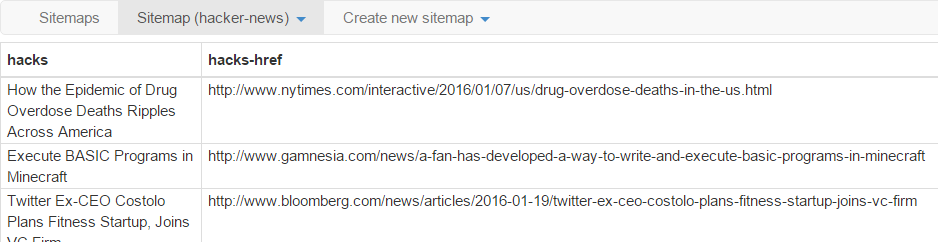
Local storage is used for storing data. CouchDB can be configured as alternative.
DEMO
Node Packages for Scraping
DOM traverser, core jQuery designed for the server
depends on Cheerio, includes pagination, delay between requests, stream to files
Also useful:
high-level browser automation library
control-flow library
downloading files, images etc.
simplest way to make HTTP calls
Cheerio
var request = require('request');
var cheerio = require('cheerio');
...
function scrape(url, json) {
'use strict';
json = json || false;
return new Promise(function (resolve, reject) {
request(url, function (error, response, html) {
if (!error && response.statusCode == 200) {
var $ = cheerio.load(html);
var parsedResults = [];
$('span.comhead').each(function (i, element) {
// Select the previous element
var a = $(this).prev();
// Get the rank by parsing the element two levels above the "a" element
var rank = a.parent().parent().text();
// Parse the link title
var title = a.text();
// Parse the href attribute from the "a" element
var link = a.attr('href');
var metadata = {
rank: parseInt(rank),
title: title,
link: link
};
// Push meta-data into parsedResults array
parsedResults.push(metadata);
});
}
resolve(parsedResults); // resolve data
});
});
}X-Ray
'using strict';
var XRay = require('x-ray');
var xray = new XRay();
exports.scrape = function (url) {
return xray(url, '.athing', [{
rank: '.rank',
title: 'td:nth-child(3) a',
link: 'td:nth-child(3) a@href'
}])
// pagination
//.paginate('a[rel="nofollow"]:last-child@href')
// limiting the number of pages visited
// .limit(3)
.write(); // this allows a stream being returning
};

An open-source document database with high performance, availability and automatic scaling
In MEAN stack, best works with Mongoose

mongo-CLI or RoboMongo for graphical interface

npm install mongoose --save-devRealtime cloud database with an API allowing developers to store and sync data across multiple clients
npm install firebase --save-dev var Firebase = require('firebase');
...
var pageScrapeFirebase = new Firebase(config.firebaseUrl);
var fb_scraped = pageScrapeFirebase.child("scrapes");
fb_scraped.push({
url: scrape.url,
created_with: scrape.created_with,
combines: combineSet,
scrapedAt: Firebase.ServerValue.TIMESTAMP
});Sample Application Walkthrough


UI
DA
MDB
FDB
DEMO
Unit and Integration Testing
2 Unit tests, 0 integration test
Summary
- Discussed the components that make a Chrome Extension
- Demonstrated two web store available
Page Scrapers and their usage - Introduced Node packages for page scraping
- Overview of MongoDB and Firebase
- Sample Application Walkthrough
- Thoughts on Testing
Thank You
Chrome Extensions for Page Scraping & Analysis
By baskint
Chrome Extensions for Page Scraping & Analysis
presentation for DevFestMN 2016 - discusses Chrome Extensions, works through a sample application which scrapes links from web pages and stores the results in a MongoDB instance and a Firebase repository in the cloud



