Strands Data Consistency
What for
what it is
Tool to be used by developers and QA's to help in the troubleshooting of data consistency.
Data is incosistent when it makes no sense, return wrong results or can cause problem in the application (backend failures).
Client Support
- Temporary executions to find data inconsistencies
- One-time executions to identify source of issues
Help DB team
- Better devs-data communication
- Make DB more robust
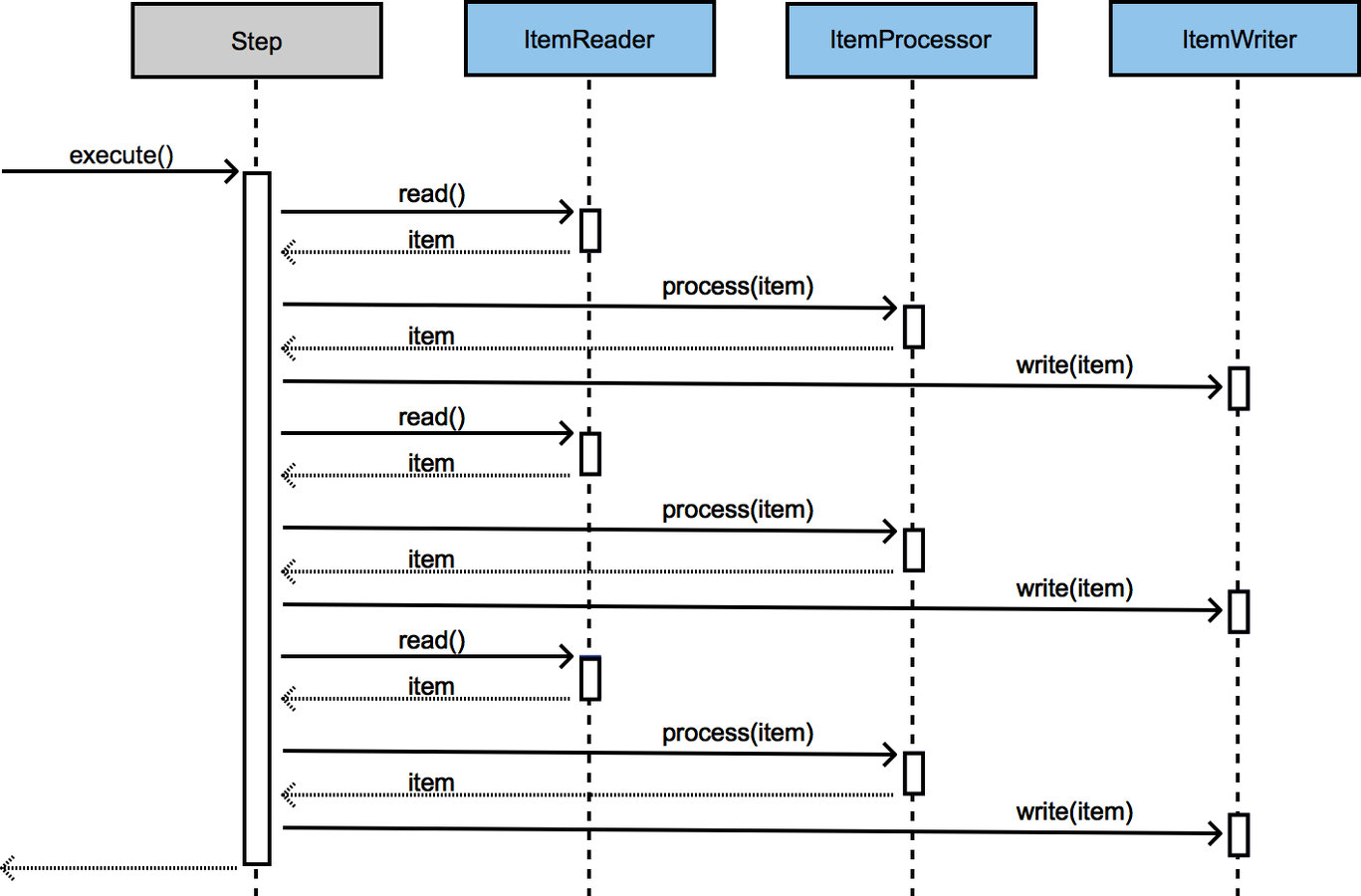
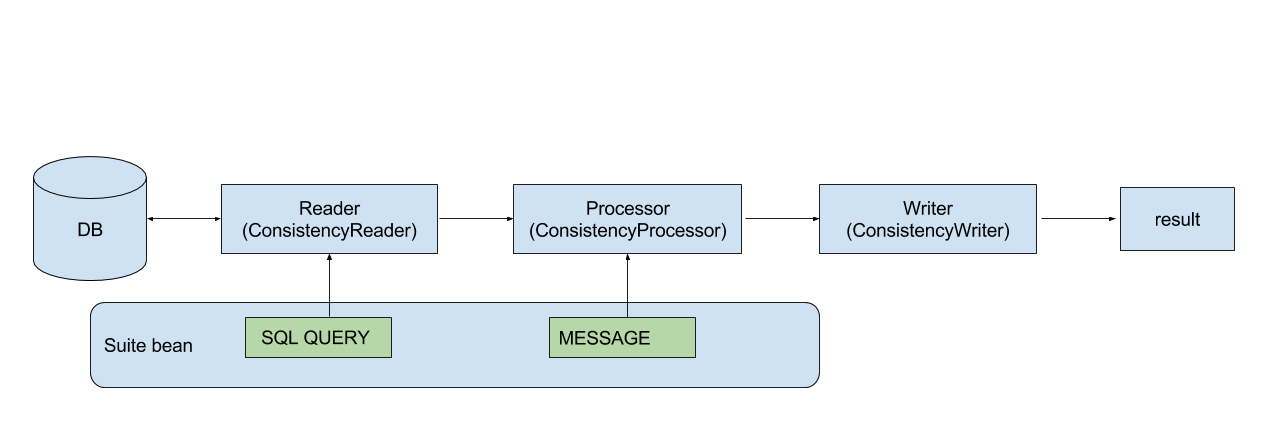
How it works
Schema
Queries
"SELECT COUNT(*) FROM recurring_operations WHERE rec_currency IS NULL"- Pure SQL
- Must return a 0 value for a correct result
We try to get BAD things!
How to use it
get it
- Download the zip file from artifactory OR clone it:
git clone ssh://git@stash.strands.com:7999/labs/pfm-data-consistency.git
cd pfm-data-consistency
mvn clean install
cd target- Unzip the file and open it on the terminal
run it
cd pfm-data-consistency-0.0.1-SNAPSHOT
sh bin/run-consistency.sh 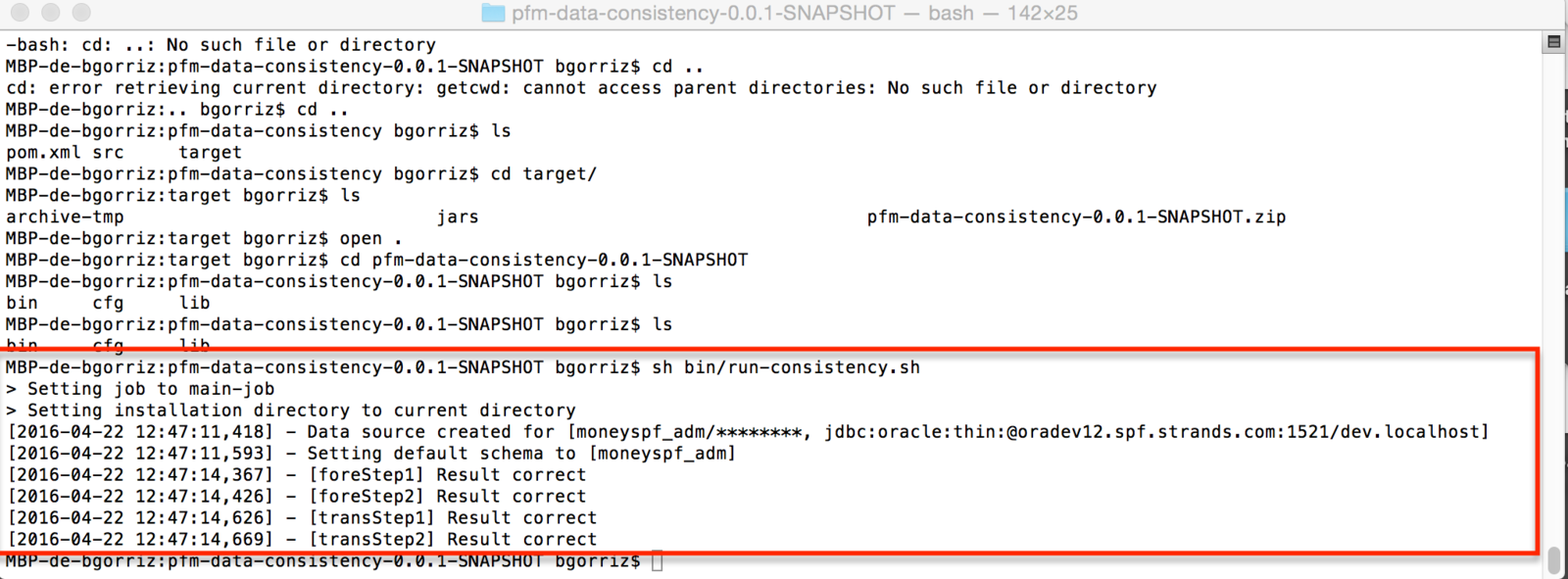
How to customize it
folders
-
bin folder: has the script to run the module.
-
lib folder: has the libraries needed to run.
-
cfg folder: All the important configurable files to run the module.
cfg folder
-
suites folder
- module-context
-
base-context
-
consistency.properties
suites folder
-
One suite per module or per project.
create custom suite
-
Copy forecast-suite.xml file
-
Rename it as "yourname"-suite.xml
-
Open your new suite
suite file
· bean:
- Define the query to launch and the error message.
- Extend consistencyReader
- Must have unique id
create new beans
<bean id="testUserNameBean" parent="consistencyReader">
<property name="sql"
value="SELECT COUNT(*) FROM users WHERE usr_username IS NULL"/>
<property name="errorMessage"
value="There are users with no username"/>
</bean>
<bean id="testUserIdBean" parent="consistencyReader">
<property name="sql"
value="SELECT COUNT(*) FROM users WHERE usr_id IS NULL"/>
<property name="errorMessage"
value="There are users with no ID"/>
</bean>suite file
· flow:
- Defines a set of steps to be executed.
- Each step launches a reader, processor and writer.
- Each step extends partstep.
- Must add a bean to each reader step
- Must have unique id
add beans to flow
<batch:flow id="borjaFlow">
<batch:step id="testStep1" parent="parstep" next="testStep2">
<batch:tasklet>
<batch:chunk reader="testUserNameBean"/>
</batch:tasklet>
</batch:step>
<batch:step id="testStep2" parent="parstep">
<batch:tasklet>
<batch:chunk reader="testUserIdBean"/>
</batch:tasklet>
</batch:step>
</batch:flow>
suite file
· job:
- Define a list of flows
- By default we will use only one flow per job
- Jobs can be run launched separately
add flow to job
<batch:job id="borja-job">
<batch:flow id="test.borjaFlow" parent="borjaFlow"/>
</batch:job>modify module context
Module file imports all suites to be lanched and adds all the flows that will be launched in the main job
-
Add the import of your suite
-
Add your flow to the main job
<import resource="suites/borja-suite.xml"/>
<batch:job id="main-job">
<batch:split id="main-split" task-executor="asyncTaskExecutor">
<batch:flow parent="transactionsFlow"/>
<batch:flow parent="forecastFlow"/>
<batch:flow parent="borjaFlow"/>
</batch:split>
</batch:job>base context
Defines the parent writer, processor and reader.
Defines the parent step with the consistency processor and the consistencyWriter
properties file
· Each step can be deactivated from a flow from here.
· Also the database parameters are set here
consistency.active.testStep1=0
consistency.active.testStep2=0run it (again)
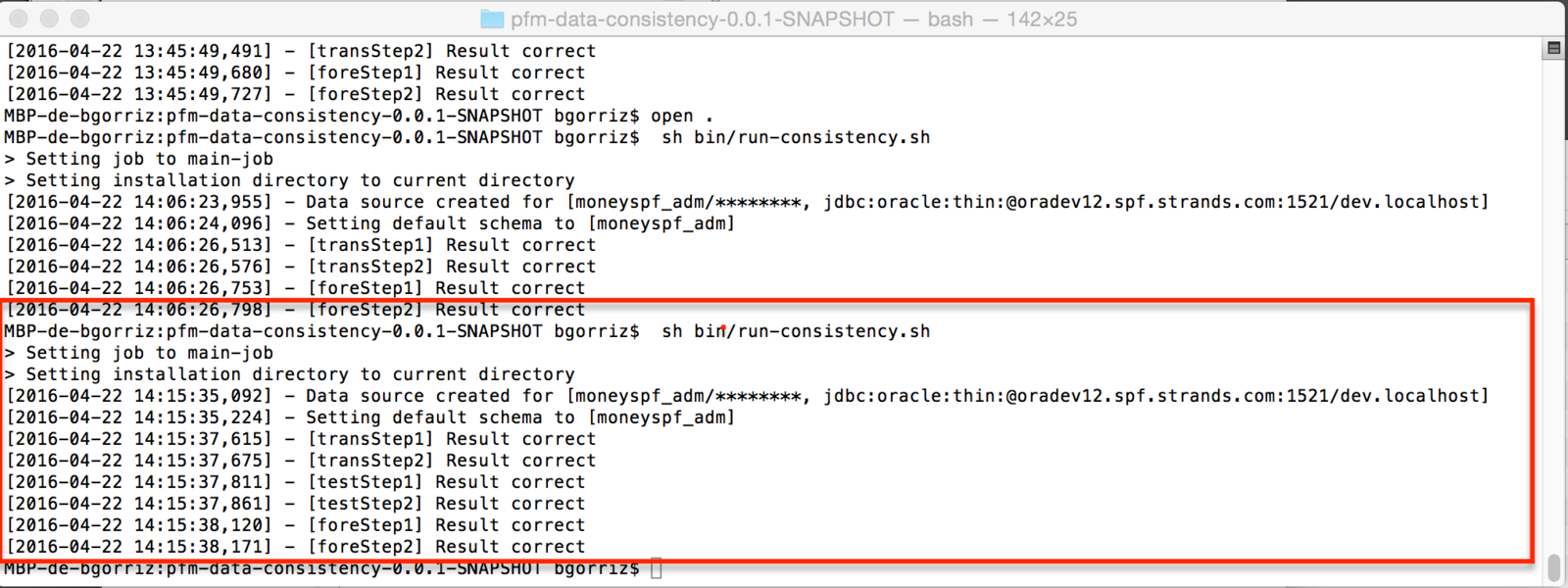
run it (once more)
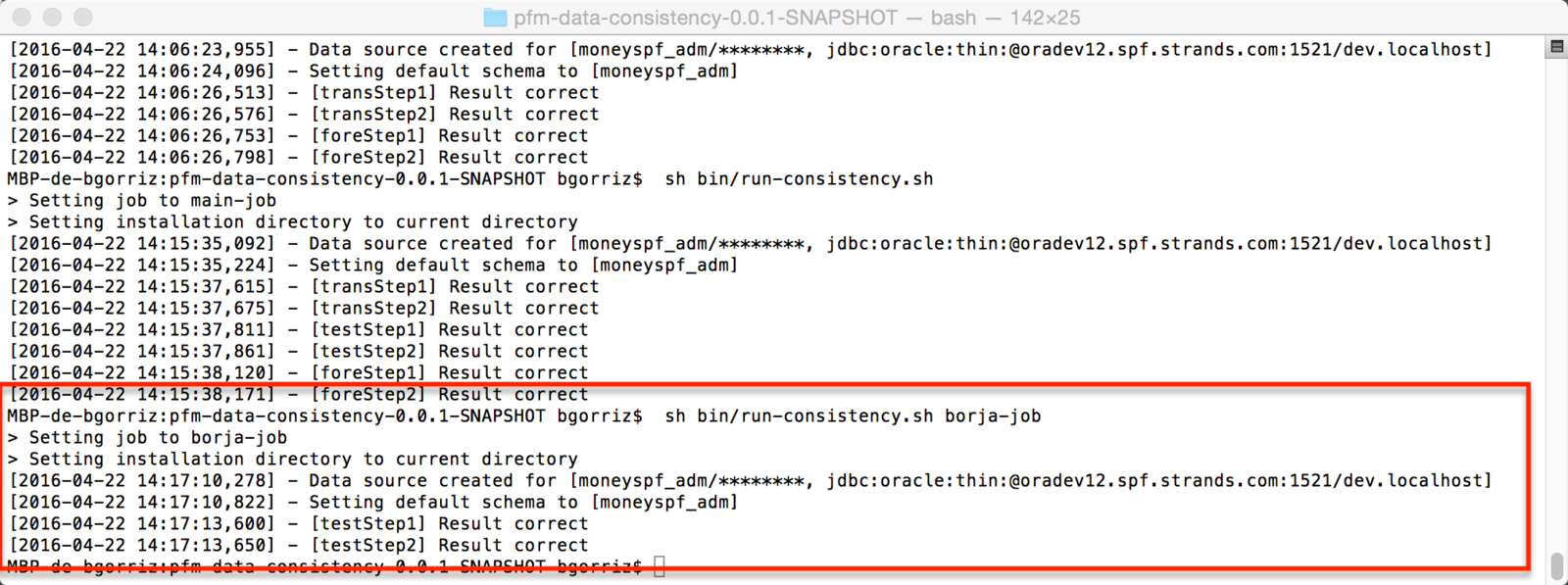
How to extend it
PUSH IT !
· Add everything we have modified to the src/main/resources folder
- git commit -a -m "My first data consistency test!"
- git push
Further work
a work in process
- Add it to a jenkins job.
- Make it easier for everyone to add new test cases.
- Add support HQL
- Whatever idea you may have to improve it.
a collective work
- We need all of you to expand the tool.
- Every problem you find in your project could be a new test to be added to the tool.
- You do not need much more than sql to add a new test.
- PLEASE REMEMBER TO USE IT AND IMPROVE IT!
thank you
strands data consistency
By Borja Gorriz Hernando


