









Carlos Sánchez Pérez
Currently working at @navandu_ COO, Co-founder at @leemurapp & @wearenominis exCTO @beruby_es. ExDev at @The_Cocktail & @aspgems
Codemotion 2016 @carlossanchezp
MySQL: Cómo migrar una tabla con 8 millones de registros
Pragmatic developer, Ruby/Rails choice at the moment, Learning Scala, Elixir/Phoenix & DDD. Currently working as Web Dev at @The_Cocktail.
Let's make it happen
Blog (only in spanish):
carlossanchezperez.wordpress.com
Twitter:
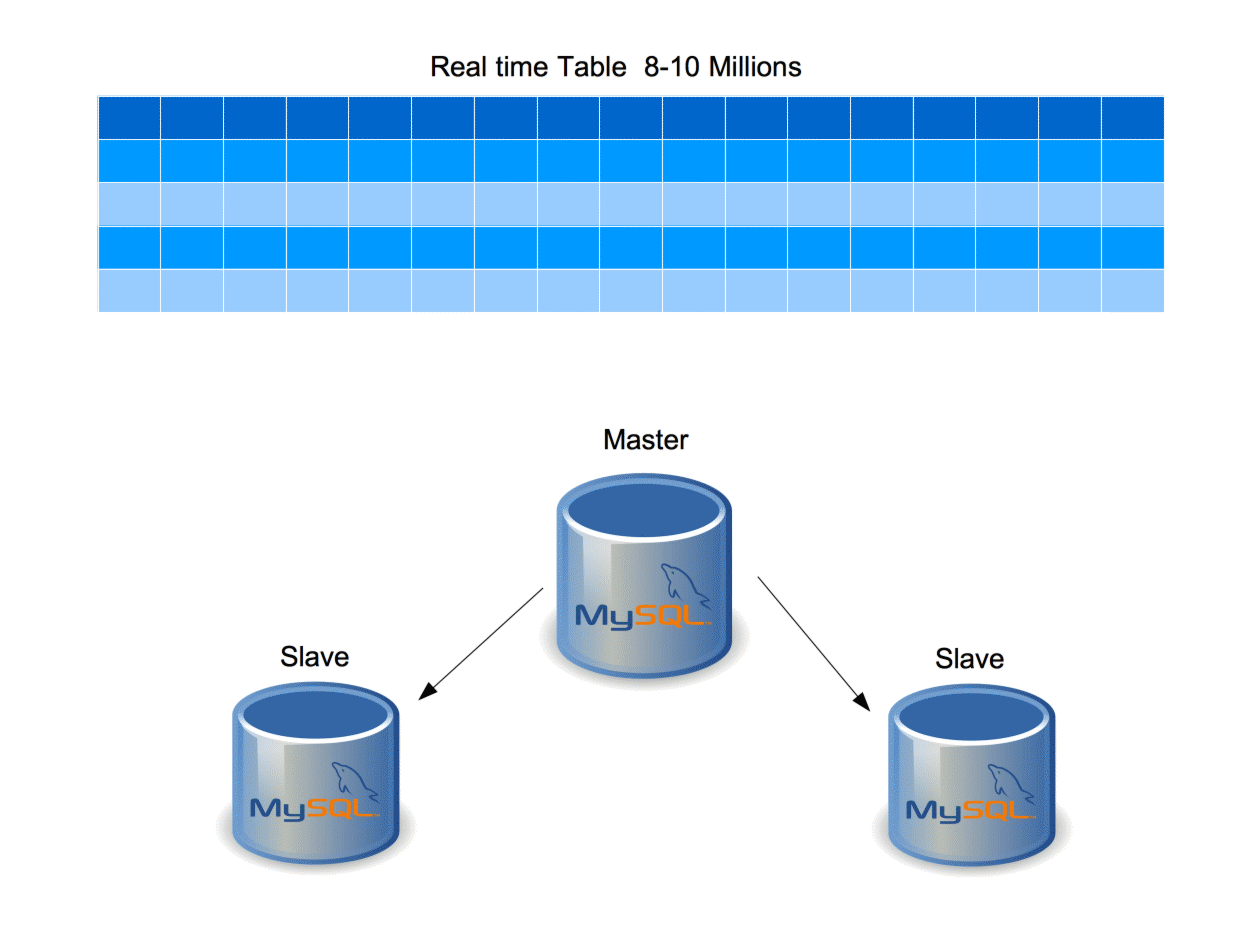
REAL
create_table "order_events", :force => true do |t|
t.string "order_id", :null => false
t.string "origin_type", :null => false
t.integer "origin_id"
t.string "kind", :null => false
t.text "data"
t.datetime "created_at", :null => false
t.datetime "updated_at", :null => false
end
add_index "order_events", ["order_id", "kind"],
:name => "index_spree_order_events_on_order_number_and_type"
add_index "order_events", ["order_id"],
:name => "index_spree_order_events_on_order_number"AR: order.order_event
Un full scan no es un problema, es un síntoma de que necesitas índices
select * from order_events where order_id = 1234567889
y ahora hacemos
select * from order_events where order_id = "1234567889"
t.string "order_id", :null => falseAR: order.order_event
select * from order_events where order_id = 1234567889
Ya tenemos la solución.......
aprovechar el modelo en lectura
OrderEvent.find_each(batch_size: MAGIC_NUMBER) do |oe|
endMAGIC_NUMBER = 50.000
inserts_values.push "(#{oe.order_id.to_i},
'#{oe.origin_type}', #{oe.origin_id.to_i},
'#{kind}', #{s}, '#{oe.created_at.to_s(:db)}',
'#{oe.updated_at.to_s(:db)}')"sql_insert = "INSERT INTO #{table_destination}
#{columns_origin}
VALUES #{inserts_values.join(", ")}"
con_sql.execute sql_insertTIMES = 10000
def do_inserts
TIMES.times { User.create(:user_id => 1, :sku => 12, :delta => 1) }
end
Benchmark.measure { ActiveRecord::Base.transaction { do_inserts } }
Benchmark.measure { do_inserts } CONN = ActiveRecord::Base.connection
TIMES = 10000
def raw_sql
TIMES.times { CONN.execute "INSERT INTO `user`
(`delta`, `updated_at`, `sku`, `user_id`)
VALUES(1, '2015-11-21 20:21:13', 12, 1)" }
end
Benchmark.measure { ActiveRecord::Base.transaction { raw_sql } }
Benchmark.measure { raw_sql } CONN = ActiveRecord::Base.connection
TIMES = 10000
def mass_insert
inserts = []
TIMES.times do
inserts.push "(1, '2015-11-21 20:21:13', 12, 1)"
end
sql = "INSERT INTO user (`delta`, `updated_at`, `sku`,
`user_id`)
VALUES #{inserts.join(", ")}"
CONN.execute sql
end
Benchmark.measure { mass_insert }
ActiveRecord without transaction:
14.930000 0.640000 15.570000 ( 18.898352)
ActiveRecord with transaction:
13.420000 0.310000 13.730000 ( 14.619136)
1.29x faster than base
Raw SQL without transaction:
0.920000 0.170000 1.090000 ( 3.731032)
5.07x faster than base
Raw SQL with transaction:
0.870000 0.150000 1.020000 ( 1.648834)
11.46x faster than base
Only Mass Insert:
0.000000 0.000000 0.000000 ( 0.268634)
70.35x faster than basede momento lo dejamos en "stand by"
# SOLUCIÓN 1
sql = "select order_id from order_events_new_origin where order_id = #{oe.order_id}"
result = con_sql.execute sql
if !inserts.include? oe.order_id
puts "CREAMOS/MIGRAMOS en NUEVA TABLA Order ID #{oe.order_id} y el CONT #{cont}"
sql = "INSERT INTO order_events_new_origin
(order_id,origin_type,origin_id,kind,data,created_at,updated_at)
SELECT order_id,origin_type,origin_id,kind,data,created_at,updated_at
FROM order_events where order_id = '#{oe.order_id}'"
con_sql.execute sql
cont = cont + 1
inserts.push oe.order_id
end
# SOLUCIÓN 2
# Vamos a sanitizar los campos antes de llevarlos al insert
kind = oe.kind.nil? ? '' : oe.kind
s = oe.data.nil? ? ''.inspect : oe.data.inspect
# almacen de los values con sus datos ya sanitizados
if oe.origin_id.nil?
inserts_values.push "(#{oe.order_id.to_i},
'#{oe.origin_type}', null,
'#{kind}', #{s}, '#{oe.created_at.to_s(:db)}',
'#{oe.updated_at.to_s(:db)}')"
else
inserts_values.push "(#{oe.order_id.to_i},
'#{oe.origin_type}', #{oe.origin_id.to_i},
'#{kind}', #{s}, '#{oe.created_at.to_s(:db)}',
'#{oe.updated_at.to_s(:db)}')"
end
if inserts_values.size >= size_values
sql_insert = "INSERT INTO #{table_destination} #{columns_origin}
VALUES #{inserts_values.join(", ")}"
begin
con_sql.execute sql_insert
rescue Exception => e
puts "No lo guardamos ERROR #{e}"
end
inserts_values = []
end¿Preguntas? - @carlossanchezp
By Carlos Sánchez Pérez
@carlossanchezp



