





Carlos Sánchez Pérez
Currently working at @navandu_ COO, Co-founder at @leemurapp & @wearenominis exCTO @beruby_es. ExDev at @The_Cocktail & @aspgems
By @carlossanchezp - 2016 - ConferenciaRoR
The only card I need is .......The Ace Of Spades
Pragmatic developer, Ruby/Rails choice at the moment, Learning Scala, Elixir/Phoenix & DDD. Currently working as Web Dev at @The_Cocktail.
Let's make it happen
Blog (only in spanish):
carlossanchezperez.wordpress.com
Twitter:
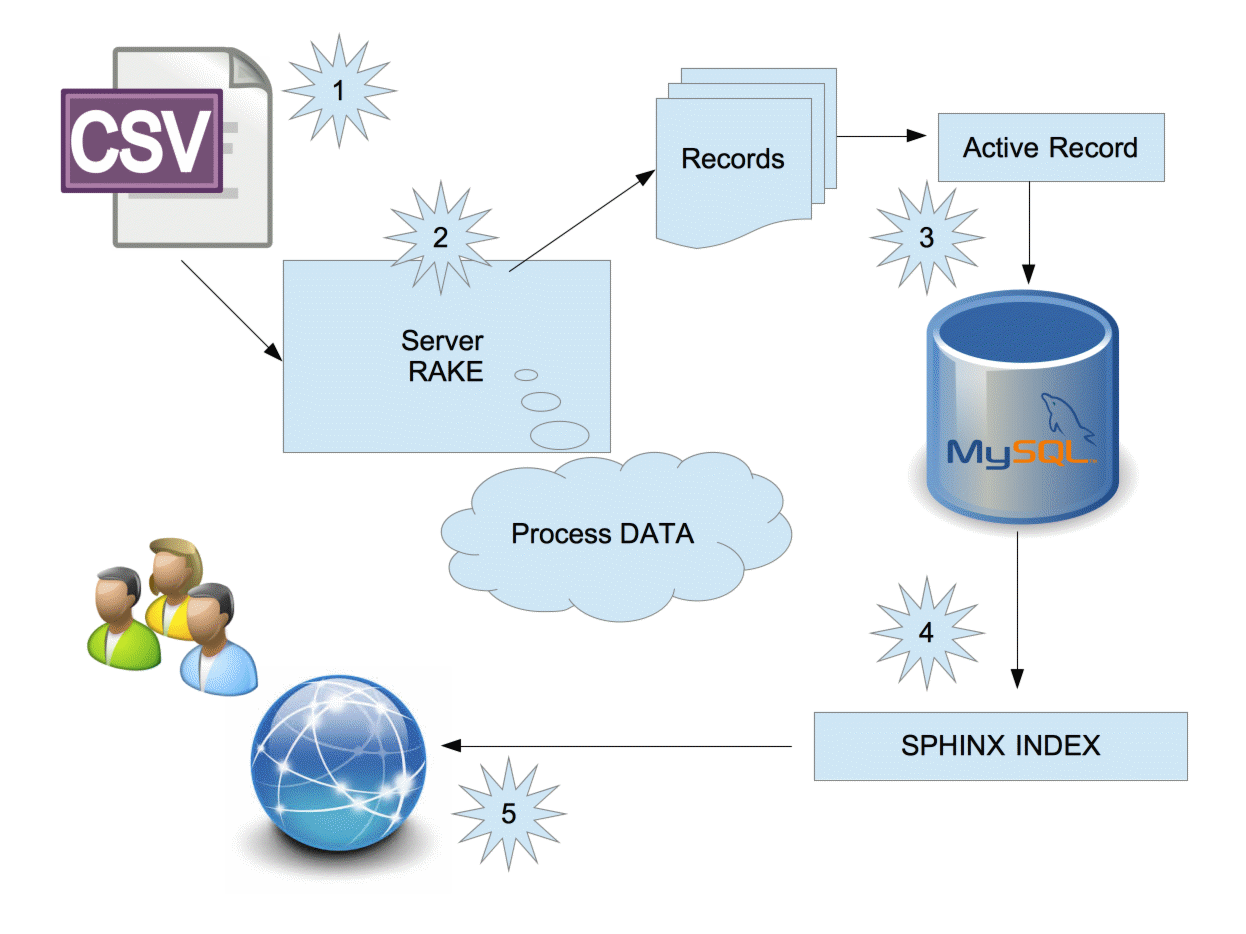
My experience
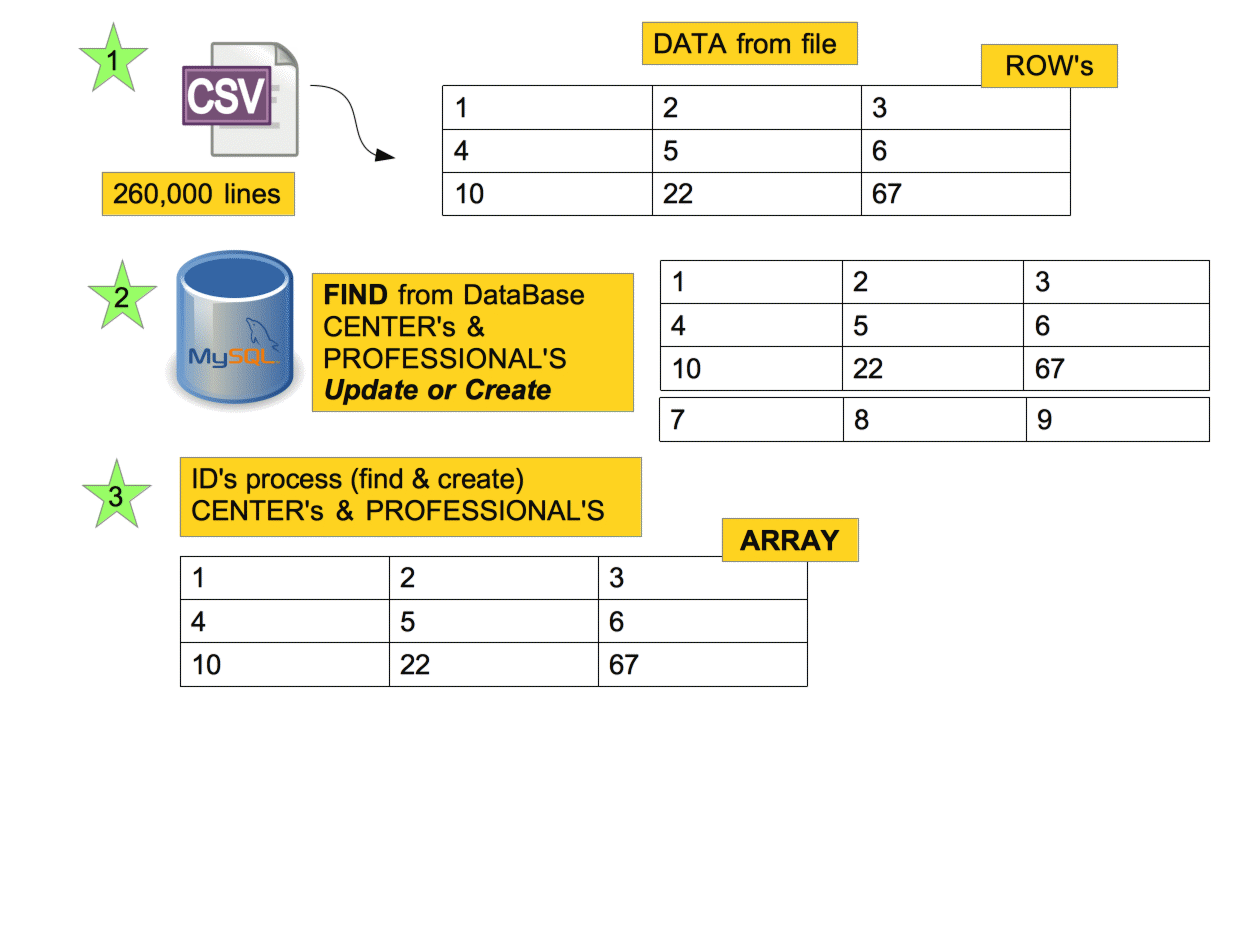
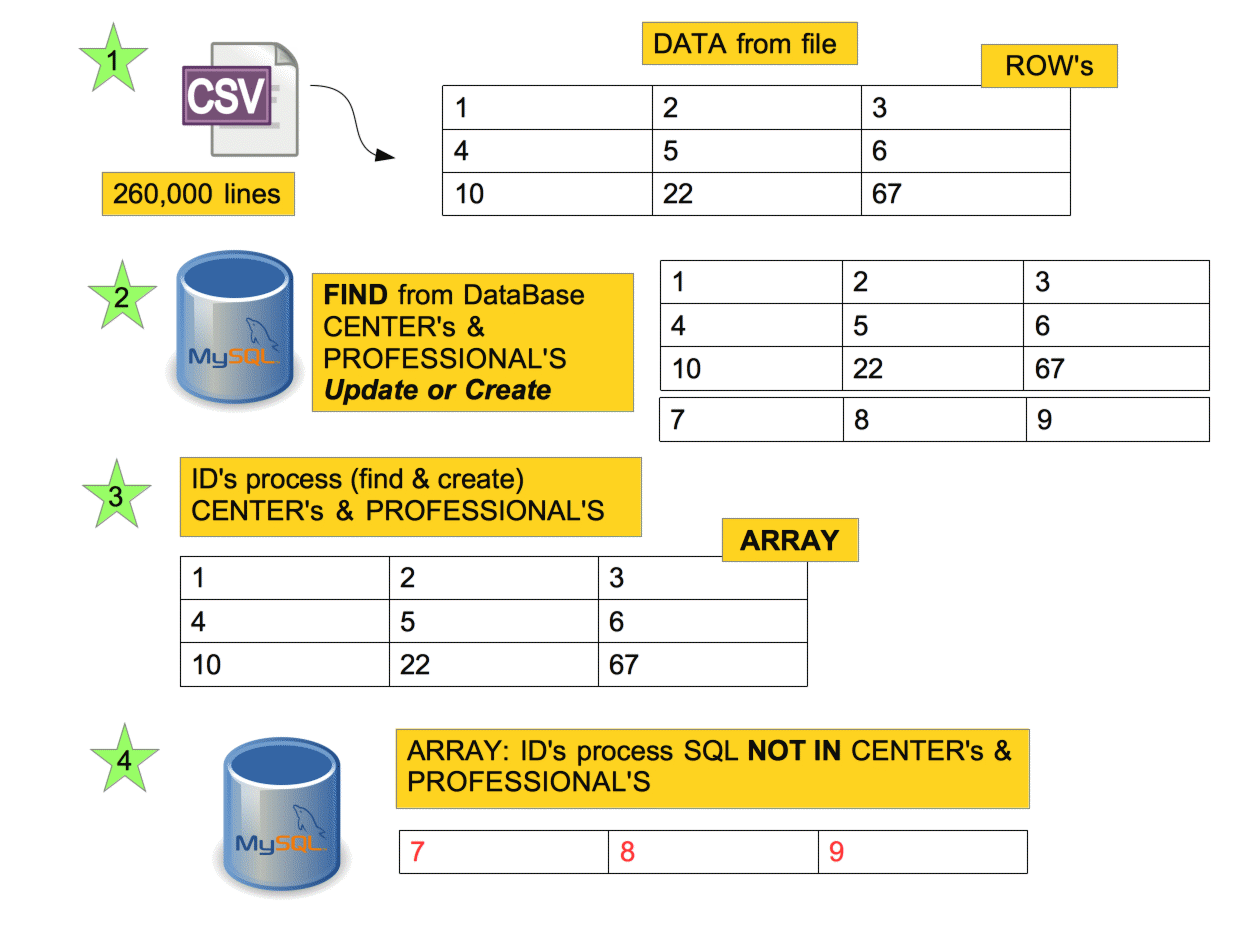
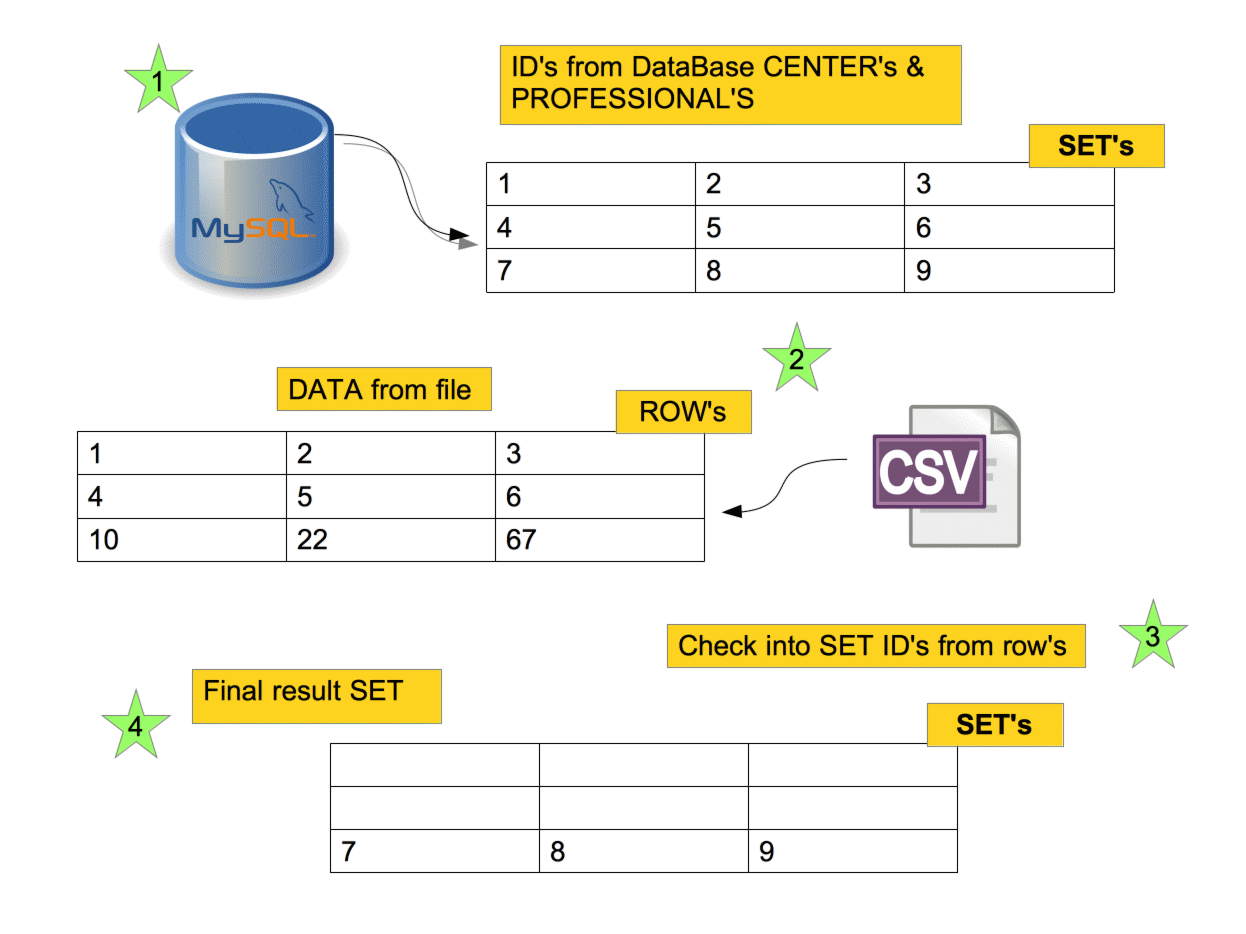
Arrays & Performance
1) Penalized performance with "not in" with a big array (a lot of elements)
2) "uniq" because we can have duplicated elements in the array
3) "map" because we only need ID's to destroy them
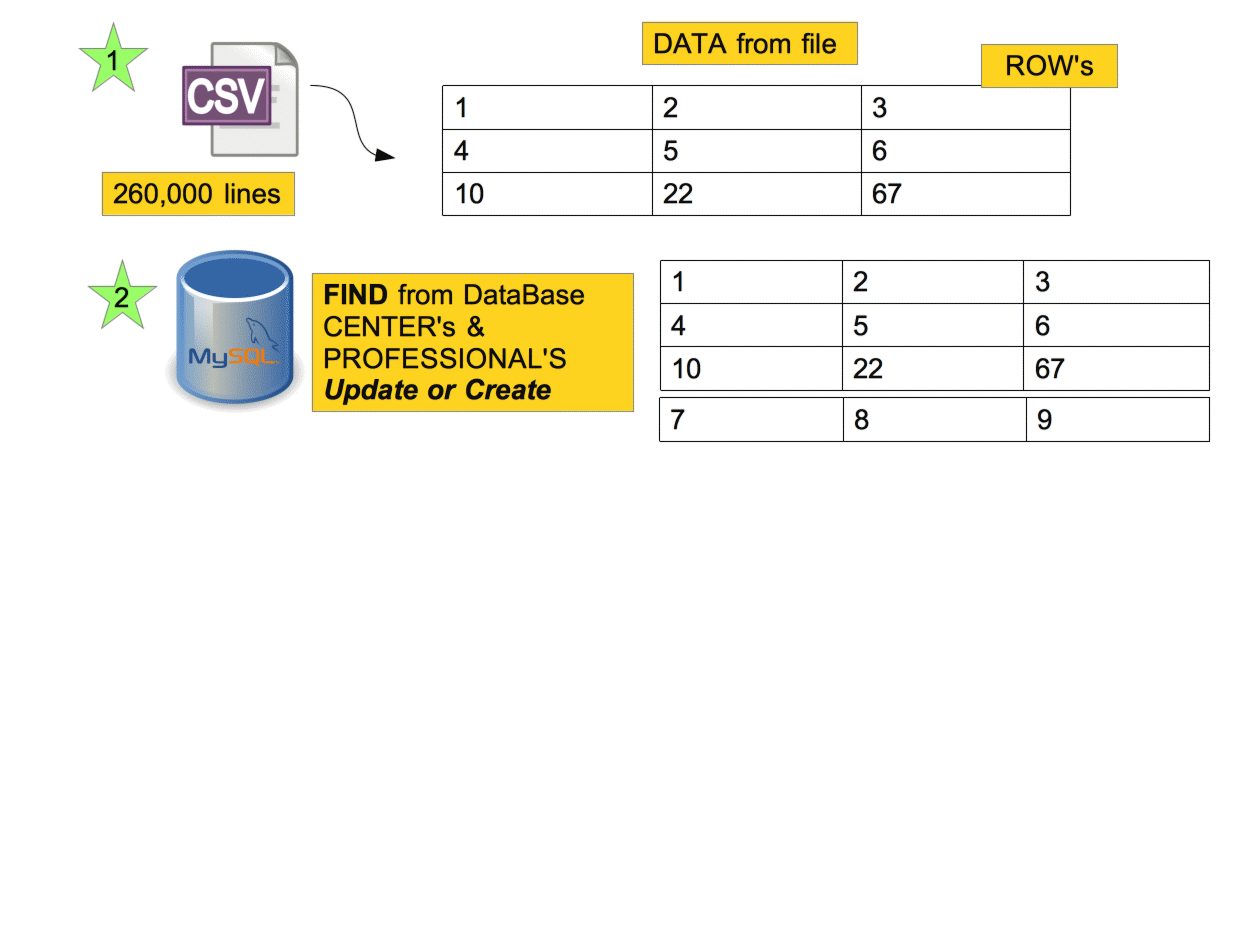
def process_file
set_ids_centers = Set.new get_ids_centers
set_ids_professionals = Set.new get_ids_professionals
# ID's with SET
pop_ids(@set_ids_centers,center.id)
pop_ids(@set_ids_professionals,professional.id)
# Pops ID's to delete at the end
def pop_ids(ids, id)
ids.delete(id) if ids.include? id
end
# Unprocessed ID's
def delete_unprocessed_ids(ids_centers,ids_professionals)
Professional.destroy(ids_professionals.to_a) if ids_professionals
Center.destroy(ids_centers.to_a) if ids_centers
end
Benchmark.bm do |x|
x.report "Set" do
a=Set.new
1000.times{a.add(rand(100))}
end
x.report "Array" do
a=[]
1000.times{r=rand(100);a<<r unless a.include?(r)}
end
end
user system total real
Set 0.000000 0.000000 0.000000 ( 0.001127)
Array 0.000000 0.000000 0.000000 ( 0.000829)
Benchmark.bm do |x|
x.report "Set" do
a=Set.new
1000.times{a.add(rand(1000))}
end
x.report "Array" do
a=[]
1000.times{r=rand(1000);a<<r unless a.include?(r)}
end
end
user system total real
Set 0.000000 0.000000 0.000000 ( 0.003271)
Array 0.000000 0.000000 0.000000 ( 0.003250)Benchmark.bm do |x|
x.report "Set" do
a=Set.new
1000.times{a.add(rand(10000))}
end
x.report "Array" do
a=[]
1000.times{r=rand(10000);a<<r unless a.include?(r)}
end
end
user system total real
Set 0.000000 0.000000 0.000000 ( 0.001240)
Array 0.010000 0.000000 0.010000 ( 0.010081)
user system total real
Set 0.000000 0.000000 0.000000 ( 0.001545)
Array 0.010000 0.010000 0.020000 ( 0.008941)1) With a small number of elements is much better Array
2) With a large number of elements is much better Set
users = User.all
=> [#<User id: 1, email: 'csanchez@example.com', active: true>,
#<User id: 2, email: 'cperez@example.com', active: false>]
users.map(&:email)
=> ['csanchez@example.com', 'cperez@example.com']
# always i use: User.all.map(&:email)
emails = User.select(:email)
=> [#<User email: 'csanchez@example.com'>, #<User email: 'cperez@example.com'>]
emails.map(&:email)
=> ['csanchez@example.com', 'cperez@example.com']
User.pluck(:email)
=> ['csanchez@example.com', 'cperez@example.com']
User.where(active:true).pluck(:email) ActiveRecord::Base.logger.level = 1
n = 1000
Benchmark.bm do |x|
x.report('Country.all.map(&:name): ') { n.times { Country.all.map(&:name) } }
x.report('Coutry.pluck(:name): ') { n.times { Country.pluck(:name) } }
end
## Score
user system total real
Country.all.map(&:name): 3.830000 0.140000 3.970000 ( 4.328655)
Coutry.pluck(:name): 1.550000 0.040000 1.590000 ( 1.879490)
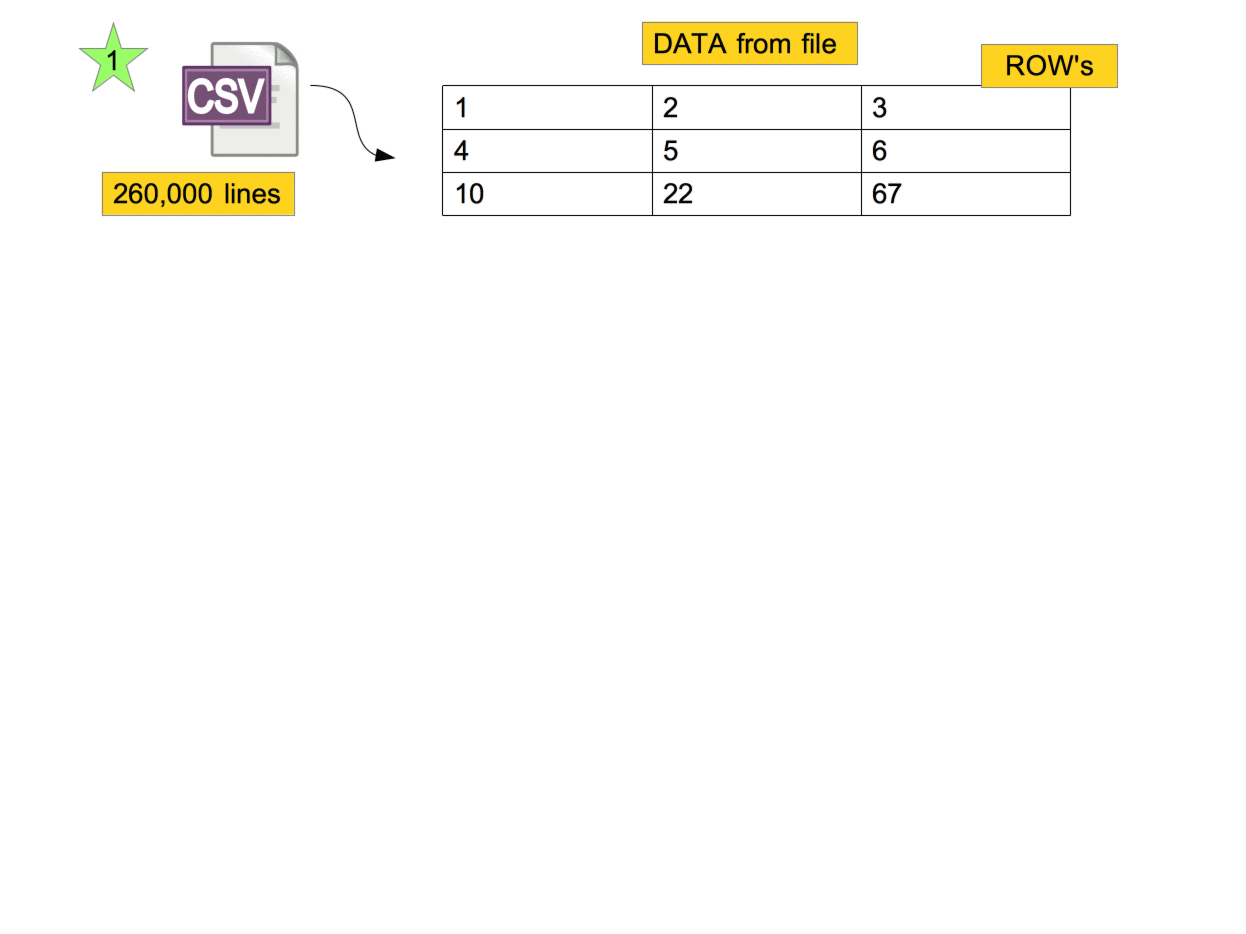
# How to load
set_ids_centers = Set.new get_ids_centers
set_ids_professionals = Set.new get_ids_professionals
# Method only return id's
def get_ids_centers
Center.pluck(:id)
end
def get_ids_professionals
Professional.pluck(:id)
end create_table "professionals", force: true do |t|
t.string "email", null: false
t.string "first_name", null: false
t.string "last_name", null: false
t.string "personal_web", default: "http://"
t.string "telephone"
t.boolean "show_telephone", default: true, null: false
t.boolean "show_email", default: true, null: false
t.text "cv"
t.integer "update_check", default: 0
t.boolean "delta", default: true, null: false
t.integer "type_id", default: 0, null: false
t.string "languages"
t.string "twitter"
t.string "numbercol", limit: 30
t.boolean "active", default: true, null: falseclass Professional < ActiveRecord::Base
include NestedAttributeList, FriendlyId
# Attributes
friendly_id :full_name, use: :slugged
# Validations
validates :email, uniqueness: true, case_sensitive: false, allow_blank: true
validate :first_name, present: true
validate :last_name, present: true
validate :type_id, present: true
def skip_validations
# Skip presence validations while loading, and delegate to DB validations
skip_presence_validation(Address, :country)
skip_presence_validation(Address, :province)
skip_presence_validation(Address, :city)
skip_presence_validation(Skill, :professional)
skip_presence_validation(SpecialitySpecialist, :speciality)
skip_presence_validation(SpecialitySpecialist, :specialist)
skip_presence_validation(ProfessionalCenter, :professional)
skip_presence_validation(ProfessionalCenter, :center)
skip_presence_validation(InsuranceCompanyPartner, :insurance_company)
skip_presence_validation(InsuranceCompanyPartner, :partner)
end def skip_presence_validation(model_class, field)
validators = model_class._validators[field]
validators.reject! do |validator|
validator.is_a?(ActiveRecord::Validations::PresenceValidator)
end
model_class._validators.delete(field) if validators.empty?
empty_callbacks = []
callbacks = model_class._validate_callbacks
callbacks.each do |callback|
if callback.name == :validate && callback.filter.is_a?(ActiveRecord::Validations::PresenceValidator) && callback.filter.attributes.include?(field)
callback.filter.attributes.delete(field)
empty_callbacks << callback if callback.filter.attributes.empty?
end
end
empty_callbacks.each {|c| callbacks.delete(c) }
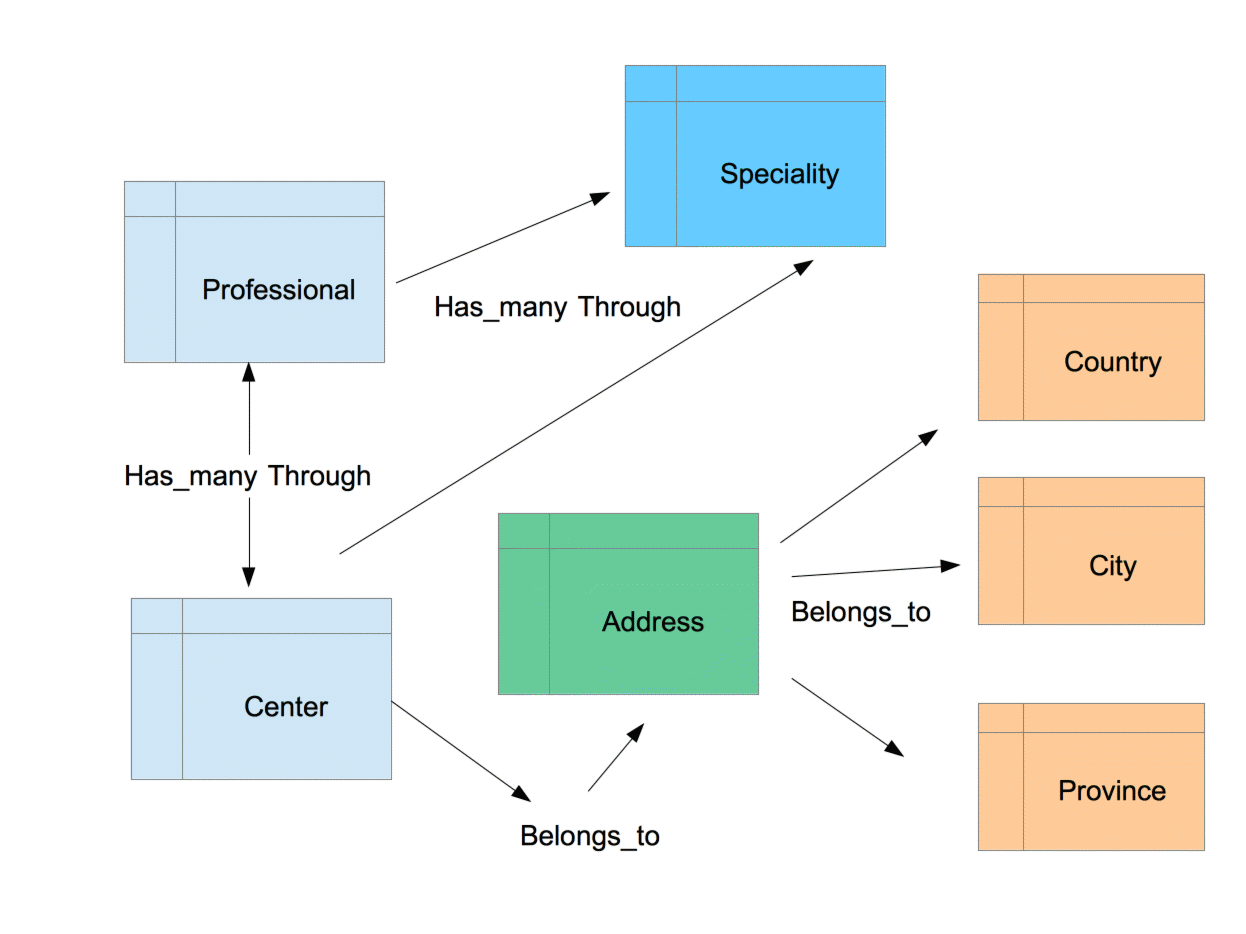
endclass Address < ActiveRecord::Base
# Relations
belongs_to :country, inverse_of: :addresses
belongs_to :city, inverse_of: :addresses
belongs_to :province, inverse_of: :addresses
has_many :centers, inverse_of: :address
# Validations
validates :country, :city, :province, presence: true
validates :name, presence: true
# Delegations
delegate :name, :code, to: :country, prefix: true, allow_nil: true
delegate :name, to: :city, prefix: true, allow_nil: true
delegate :name, to: :province, prefix: true, allow_nil: true
endclass SpecialitySpecialist < ActiveRecord::Base
# Relations
belongs_to :speciality, inverse_of: :speciality_specialists
belongs_to :specialist, polymorphic: true
# Validations
validates :speciality, presence: true
validates :specialist, presence: true
end def cached_tables
{
cities: City.all.index_by {
|c| "#{c.province_id}-#{c.external_id}" },
provinces: Province.all.index_by(&:external_id),
countries: Country.all.index_by(&:external_id),
specialities: Speciality.all.index_by(&:external_id),
insurance_companies: InsuranceCompany.all.to_a,
}
end def cities
@caches[:cities]
end
def provinces
@caches[:provinces]
end
def countries
@caches[:countries]
end
def specialities
@caches[:specialities]
end
def insurance_companies
@caches[:insurance_companies]
end
def find_or_create_city(province, country)
city = cities["#{province.id}-#{row.city_attributes[:external_id]}"]
|| City.new
city.attributes = row.city_attributes.
merge(province: province, country: country)
city.save! if city.changed?
cities["#{city.province_id}-#{city.external_id}"] = city
city
end
TIMES = 10000
def do_inserts
TIMES.times { User.create(:user_id => 1, :sku => 12, :delta => 1) }
end
Benchmark.measure { ActiveRecord::Base.transaction { do_inserts } }
Benchmark.measure { do_inserts }
CONN = ActiveRecord::Base.connection
TIMES = 10000
def raw_sql
TIMES.times { CONN.execute "INSERT INTO `user`
(`delta`, `updated_at`, `sku`, `user_id`)
VALUES(1, '2015-11-21 20:21:13', 12, 1)" }
end
Benchmark.measure { ActiveRecord::Base.transaction { raw_sql } }
Benchmark.measure { raw_sql }
CONN = ActiveRecord::Base.connection
TIMES = 10000
def mass_insert
inserts = []
TIMES.times do
inserts.push "(1, '2015-11-21 20:21:13', 12, 1)"
end
sql = "INSERT INTO user (`delta`, `updated_at`, `sku`,
`user_id`)
VALUES #{inserts.join(", ")}"
CONN.execute sql
end
Benchmark.measure { mass_insert }
ActiveRecord without transaction:
14.930000 0.640000 15.570000 ( 18.898352)
ActiveRecord with transaction:
13.420000 0.310000 13.730000 ( 14.619136)
1.29x faster than base
Raw SQL without transaction:
0.920000 0.170000 1.090000 ( 3.731032)
5.07x faster than base
Raw SQL with transaction:
0.870000 0.150000 1.020000 ( 1.648834)
11.46x faster than base
Only Mass Insert:
0.000000 0.000000 0.000000 ( 0.268634)
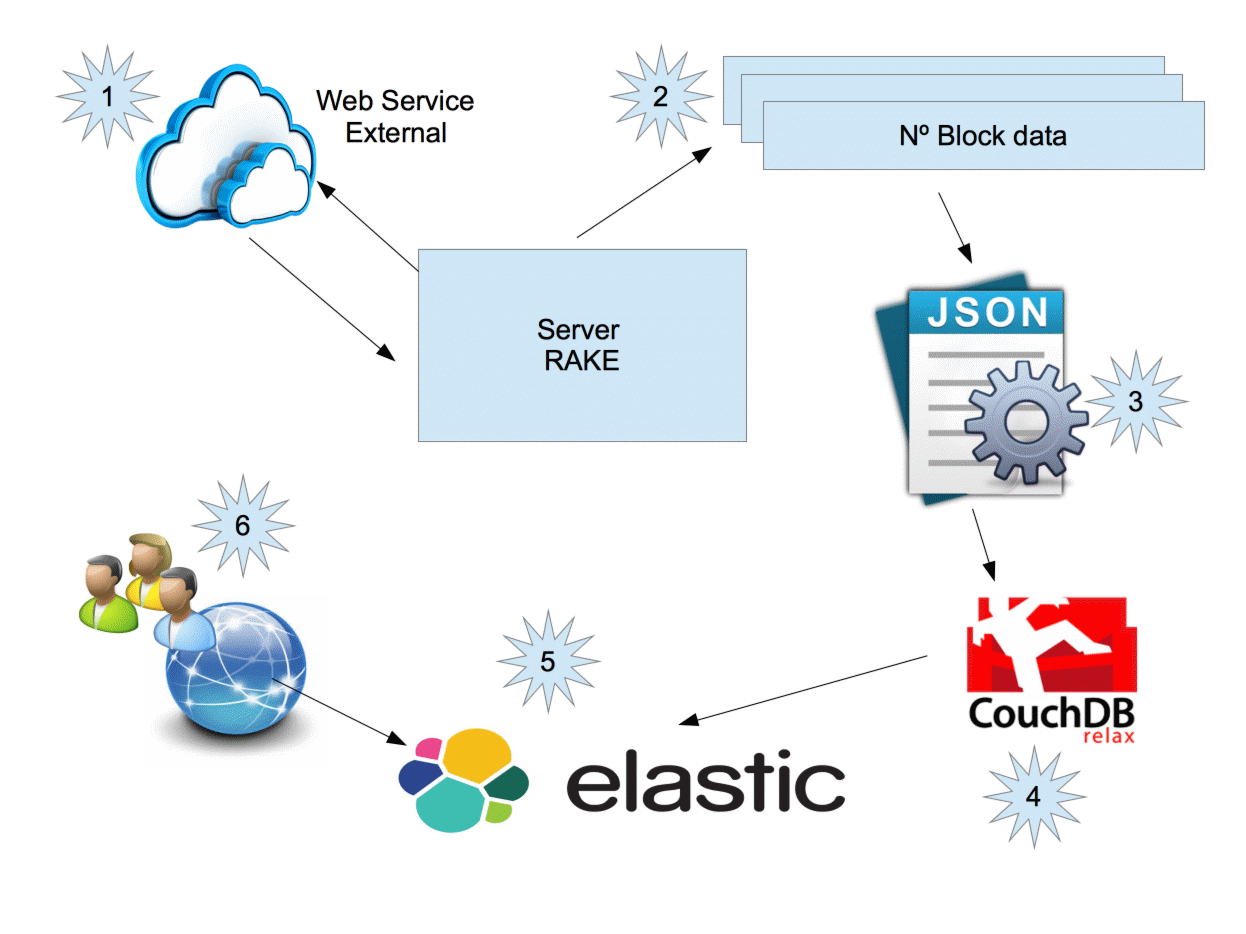
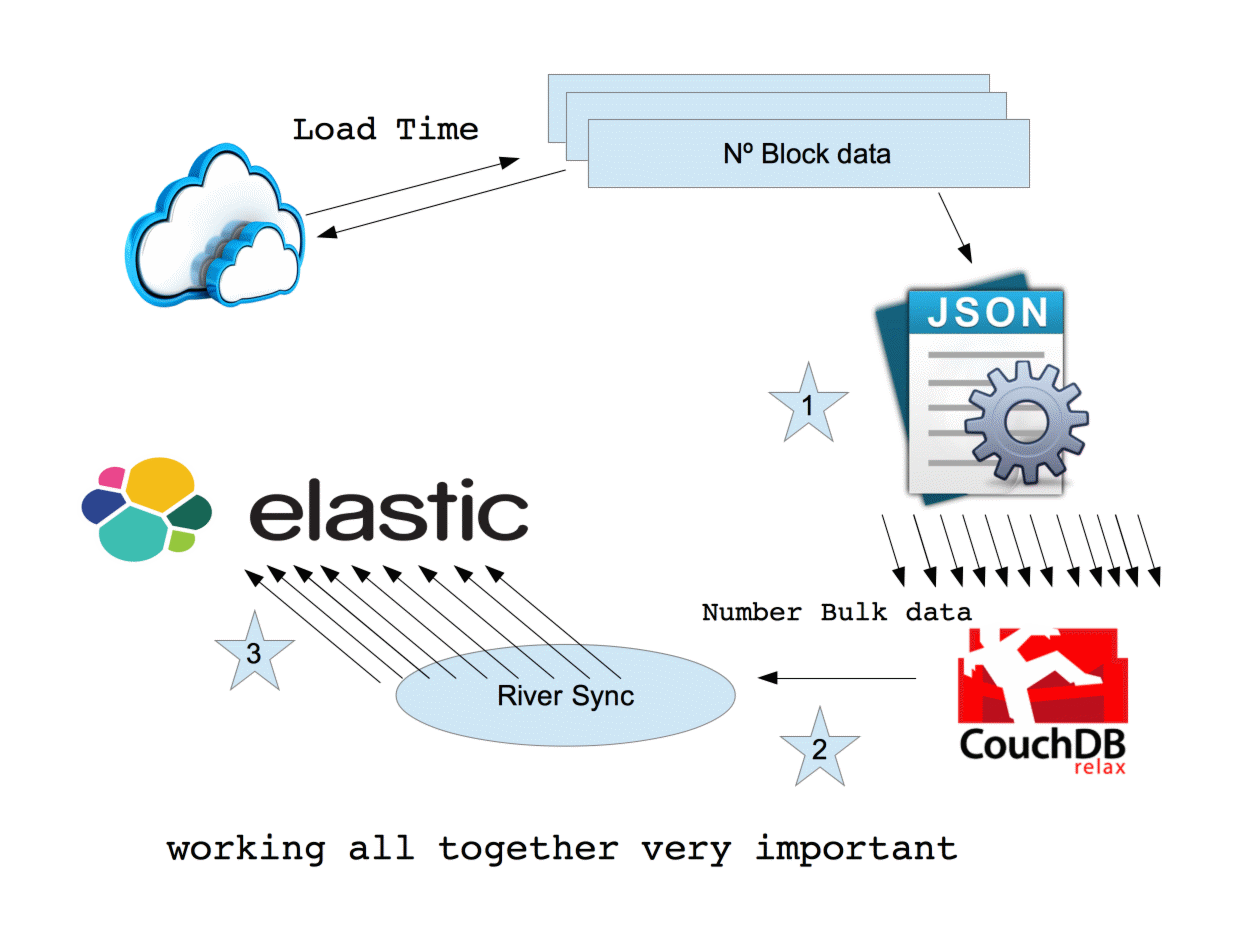
70.35x faster than baseReal time load data
Provider 1
Provider 2
*/30 * * * * flock -n /tmp/cron.txt.lock sh -c 'cd /var/www/project/current && bundle exec rake load:parse' || sh -c 'echo MyProject already running; ps; ls /tmp/*.lock'
# warnings, errors o info
Rails.logger.warn "cuidado no dispone de...."
Rails.logger.error "Error en..."
Rails.logger.info "RESPONSE TOKEN: #{token_info["access_token"]}"
# way to use
Rails.logger.tagged "MYPROJECT" do
Rails.logger.tagged "GET_OFFERS_BY_BLOCK" do
end
endBy @carlossanchezp - 2016 - ConferenciaRoR
By Carlos Sánchez Pérez
@carlossanchezp



