


Daniel Morandini
Software Developer @KIM
Daniel Morandini, 12286
August 2021
Introduction to parallel Computing
the tiny v0.5 performance benchmark
Small vocabulary keyword spotting case
Speech Commands v2 dataset (Google)
12 categories
| Number of parameters | 24908 |
| input tensor | 49x10 |
| output tensor | 12x1 |
| DS convolution layers | 4 |
| Convolution layers | 1 |
| Fully connected layers | 1 |
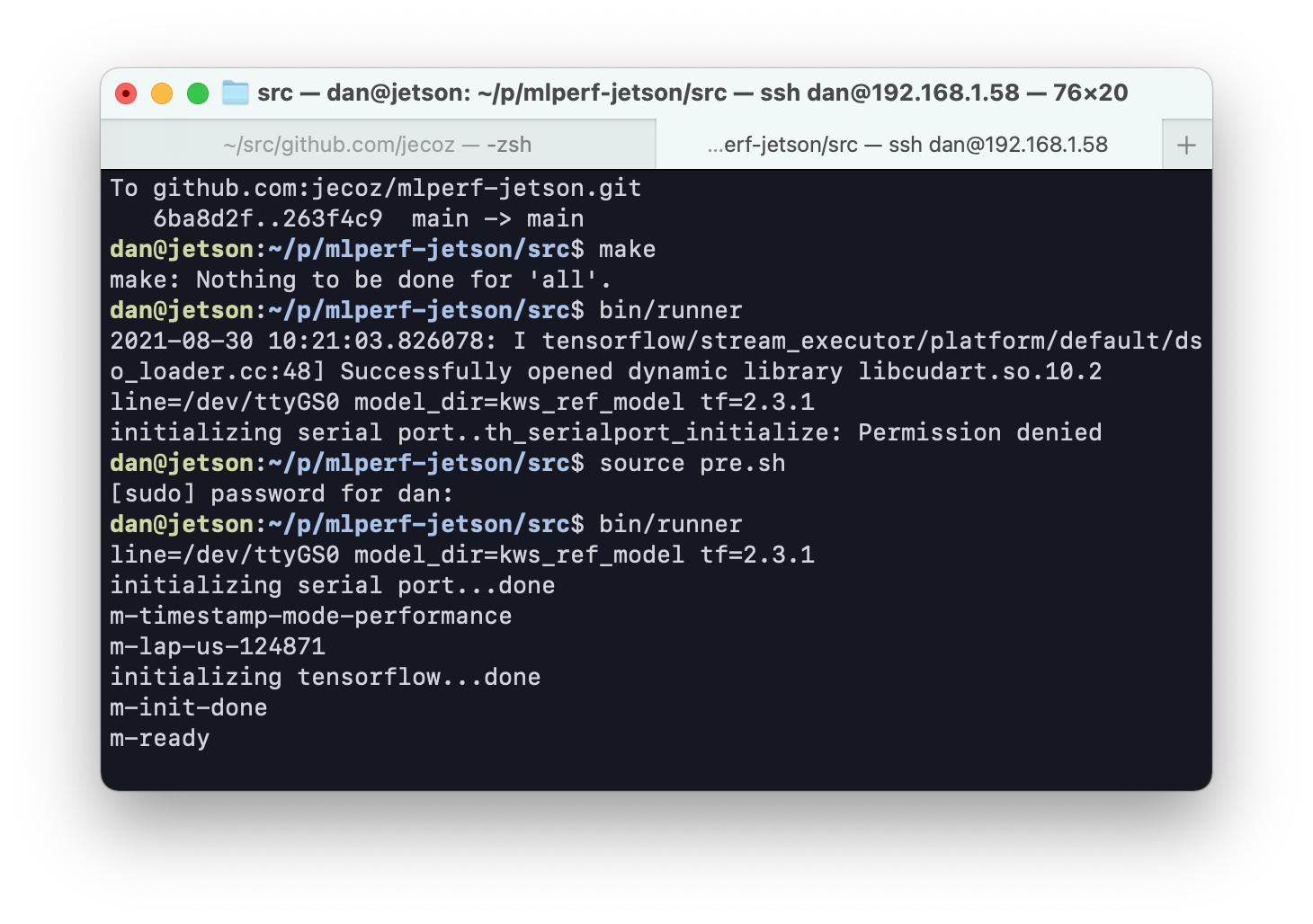
NVIDIA Tegra X1 series SoC
ARM Cortex-A57 (quad-core, 64bit)
48KB of L1 instruction cache (per core)
32KB of L1 data cache (per core)
2MB global L2 unified cache
maximum operating frequency 1.43GHz
NVIDIA Maxwell
512 GFLOPS (FP16)
128 cores
maximum operating frequency 921MHz
4GB LPDDR4, shared
theoretical bandwidth peak 25.6GB/s
operating frequency 1.6GHz
| GB/s | |
|---|---|
| CPU-GPU | 5.6 |
| GPU-CPU | 10.5 |
| GPU-GPU | 16.7 |
actual bandwidth
| MACC total | 1,664,768 |
| FLOPs total | 3,329,536 |
| Theoretical Execution Time | 0.0284ms |
| Max Memory Bandwidth | 70.7MB/s |
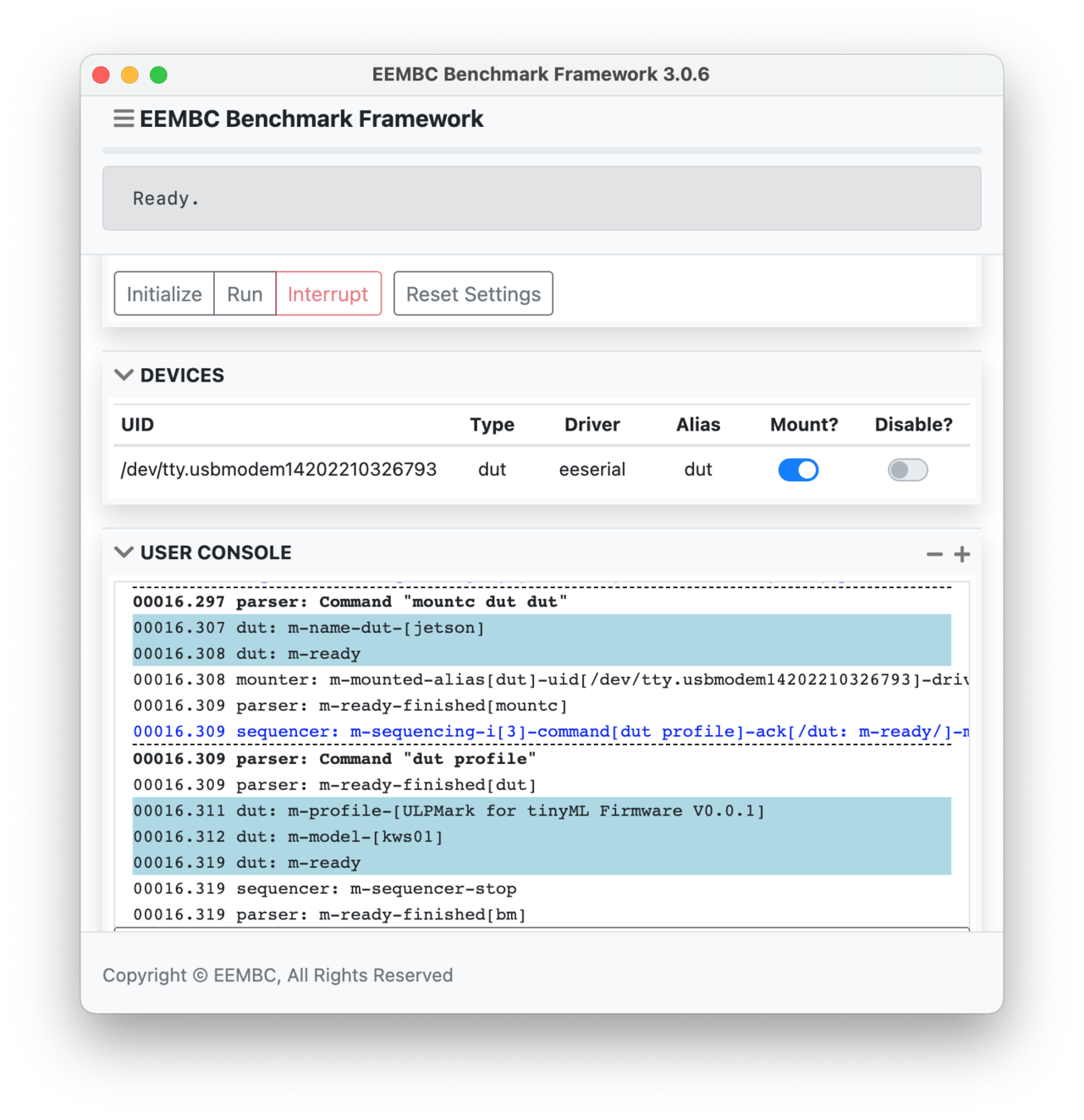
Performance results for window 2:
# Inferences : 2400
Runtime : 10.309 sec.
Throughput : 232.803 inf./sec.
Runtime requirements have been met.
Performance results for window 4:
# Inferences : 2400
Runtime : 10.296 sec.
Throughput : 233.105 inf./sec.
Runtime requirements have been met.
Performance results for window 6:
# Inferences : 2400
Runtime : 10.362 sec.
Throughput : 231.609 inf./sec.
Runtime requirements have been met.
Performance results for window 8:
# Inferences : 2400
Runtime : 10.382 sec.
Throughput : 231.177 inf./sec.
Runtime requirements have been met.
Performance results for window 10:
# Inferences : 2400
Runtime : 10.333 sec.
Throughput : 232.260 inf./sec.
Runtime requirements have been met.
---------------------------------------------------------
Median throughput is 232.260 inf./sec.
---------------------------------------------------------4.2ms
0.67%
Algorithm needs 70.7MB/s, Jetson has 5.6GB/s (minimum)
NO
======== Profiling result:
Time(%) Time Avg Name
21.29% 89.681ms 22.397us precomputed_convolve_sgemm
17.52% 73.824ms 8.1940us tf::FusedBatchNormInferenceMetaKernel
15.25% 64.242ms 7.1300us tf::BiasNCHWKernel
12.29% 51.794ms 12.935us tf::DepthwiseConv2dGPUKernelNCHWSmall
8.25% 34.775ms 34.740us explicit_convolve_sgemm
7.57% 31.884ms 6.3700us tf::ShuffleInTensor3Simple
4.86% 20.468ms 20.447us cudnn::im2col4d_kernel
3.91% 16.455ms 16.438us cudnn::pooling_fw_4d_kernel
2.93% 12.327ms 3.0780us cudnn::kern_precompute_indices~0.395ms per inference are spent doing actual computations
By Daniel Morandini



