
Aplicaciones Numéricas que desafían los conceptos sobre el desarollo de lenguajes
David Cardozo
Algunas Carácteristicas de Julia
- Dinámico: Interactivo, exploratorio, "vivo"
- Just-in-time compilación con especialización agresiva
- Sistema poderoso de despacho múltiple.
- Metaprogramación al estilo Lisp y macros.
- Fácil de usar, "funciones generadas" implícitamente invocadas.
Algunas Carácteristicas de Julia
- Dinámico: Interactivo, exploratorio, "vivo"
- Just-in-time compilación con especialización agresiva
- Sistema poderoso de despacho múltiple.
- Diseño cauteloso de igualdad,orden, y hashing
- Metaprogramación al estilo Lisp y macros.
- Fácil de usar, "funciones generadas" implícitamente invocadas.
Algunas Carácteristicas de Julia
- Dinámico: Interactivo, exploratorio, "vivo"
- Just-in-time compilación con especialización agresiva
- Sistema poderoso de despacho múltiple.
- Diseño cauteloso de igualdad,orden, y hashing
- Metaprogramación al estilo Lisp y macros.
- Fácil de usar, "funciones generadas" implícitamente invocadas.
¿Que imprime el siguiente programa en C?
int main() {
long x = 1e16;
double y = 1e16;
long z = x+1;
printf("%d\n", x == y);
printf("%d\n", y == z);
printf("%d\n", x == z);
return 0;
}Hasheo de números
Supongamos d es un diccionario
d[1] = "Adelante"¿Que deberían devolver las siguientes búsquedas de diccionario?
d[1.0]
d[1 + 0im]
d[2//2]¿¿¿???
¿¿¿???
¿¿¿???
Ruby
irb(main):001:0> d = {};
irb(main):002:0> d[1] = "Adelante"
=> "Adelante"
irb(main):003:0> d[1.0]
=> nil
Sin embargo
irb(main):001:0> 1 == 1.0;
=> truePython
>>> d = {}
>>> d[1] = "Adelante"
>>> d[1.0]
'Adelante'
>>> from cmath import *
>>> d[1+0j]Julia
d = Dict();
d[1] = "Adelante"
juliaa> d[1.0]
"Adelante"
julia> d[1 + 0im]
"Adelante"
julia> d[2//2]
"Adelante"En el pasado...
En Julia 0.2 hasheamos números con diferentes tipos de manera diferente:
d = Dict()
d[1] = "Adelante"
d[1.0] = "ECOOP" # <- diferente entrada
julia> d
Dict{Any,Any} with 2 entries:
1.0 => "ECOOP"
1 => "Adelante"Introduciendo Diccionarios tipeados
¿Que ocurre si limitamos los tipos del diccionario?
d = Dict{Int,String}()
d[1] = "Adelante"
d[1.0] = "ECOOP" # <- ¿Que debería hacer esto?Dos opciones
- Lanzar un error - lo cual es nada conveniente o dinámico
- Automáticamente convertir 1.0 a Int
Mismo codigo trabaja diferente dependiendo del tipo de la llave
La Solución:
Hashear números por valor
hash(x::Float64) = 3h(x) + h(trunc(Int64, x))
hash(x::Int64) = 3h(convert(Float64, x)) + h(x)Hasheo eficiente por valor para Float64 y Int64
h es alguna función para hashear 64 bits
- ¿Pero como podemos hacer esto eficientemente y genéricamente?
¿Y para otros tipos?
La función "descomposición":
La función descomposición es el punto donde (con valores reales) tipos numéricos que soportan hasheo se integran con el protocolo de hasheo
$$ num \cdot \frac{2^{pod}}{den} $$
Hashing es entonces definido genéricamente en términos de estos 3 valores
-
descomposicion(x) debería retornar tres valores enteros: num, pod, den
- num,pod, y den pueden ser computados eficientemente para varios tipos
- Caso especial (rápidos) para valores de Int64, UInt64 o Float64
Programación escalonada:
Permitir al programador generar código en varios puntos del proceso de compilación
Pipeline simplificado
Código
Fuente
AST
Lexing
Parsing
AST
tipeado
Inferencia de tipos
Código
nativo
Generación de
código
Macros
JIT
funciones generadas
Ejemplo macro
Evaluar
p[1] + x \cdot (p[2] + x \cdot (\ldots ))
- i.e evaluación de polinomios mediante el método de Horner
macro horner(x, p...)
ex = esc(p[end])
for i = length(p)-1:-1:1
ex = :(muladd(t, $ex, $(esc(p[i]))))
end
Expr(:block, :(t = $(esc(x))), ex)
endDesventajas de Macro
- Se coloca muy temprano
- Solo ve sintáxis, y no significado
- Cambia el orden de evaluación y posibles problemas de orden
@foo a + b
@foo b + a- No trabaja como una función
i.e no se pueden usar macros como argumentos a funciones de alto nivel
Programación escalonada con tipos
- Generar codigo como función de los tipos de los argumentos
- Integración con el método de la cache
Generación de código automática
Guardada para reuso (GC)
El problema de la vista de Arrays
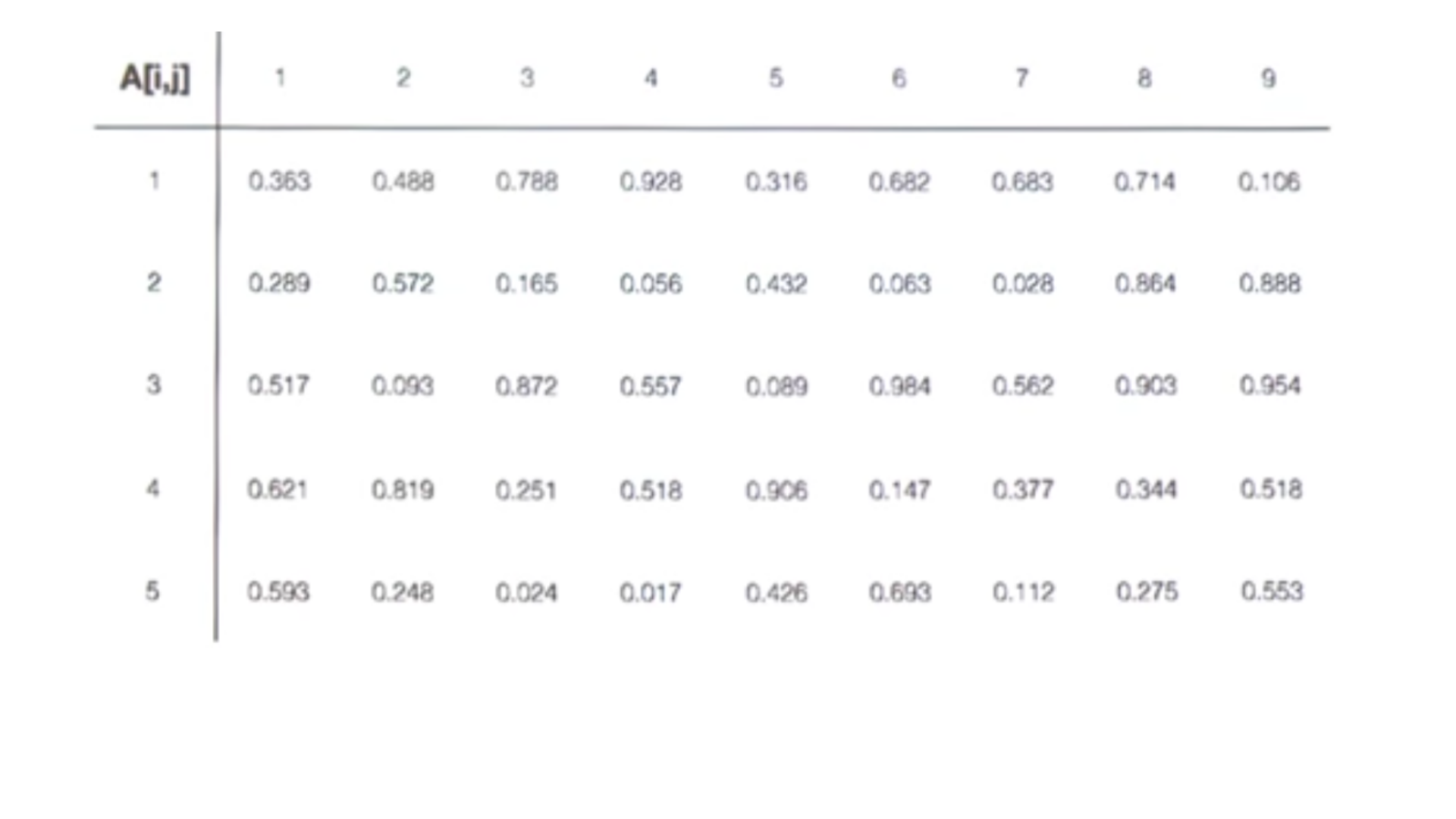
El problema de la vista de Arrays
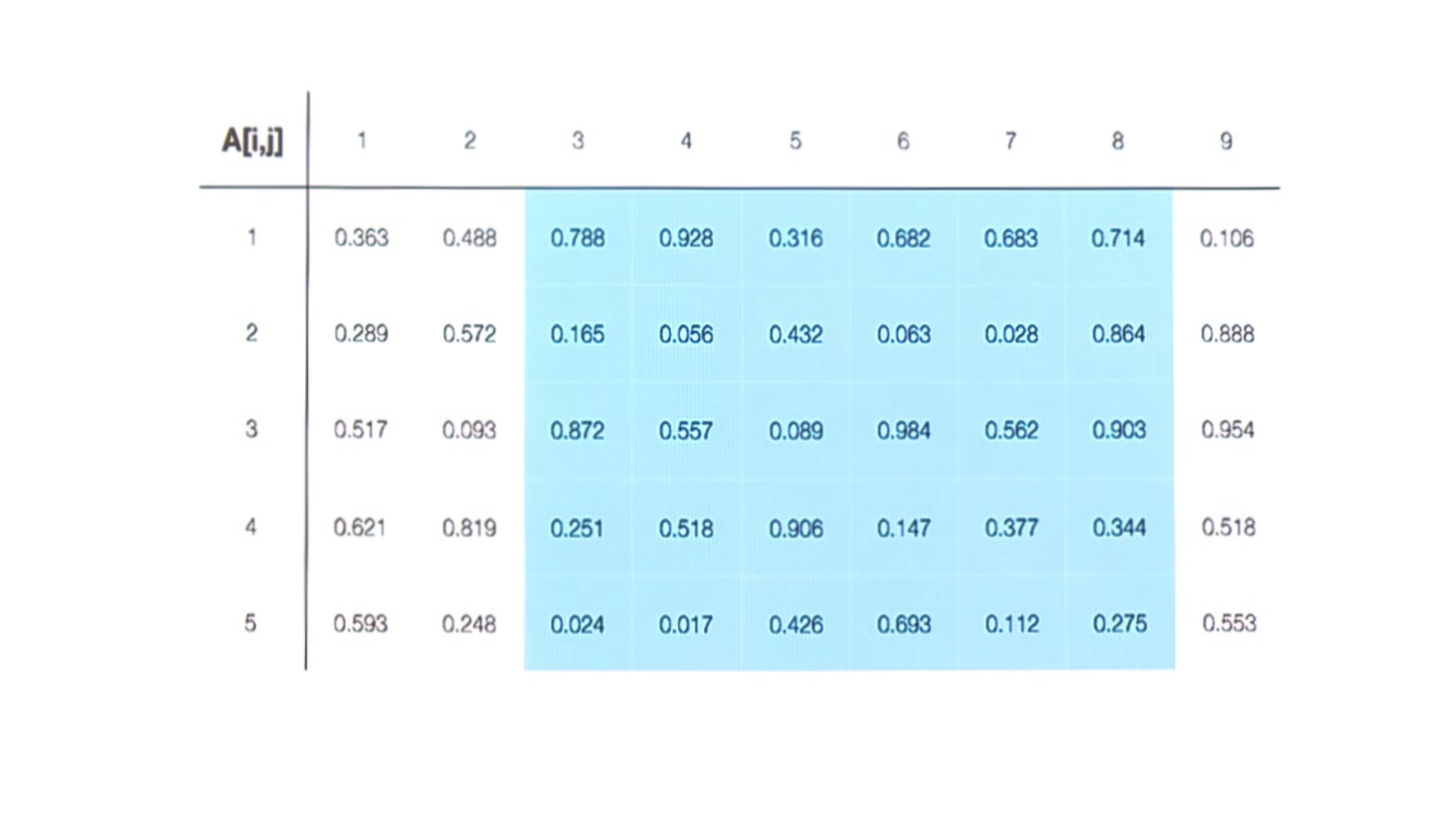
El problema de la vista de Arrays
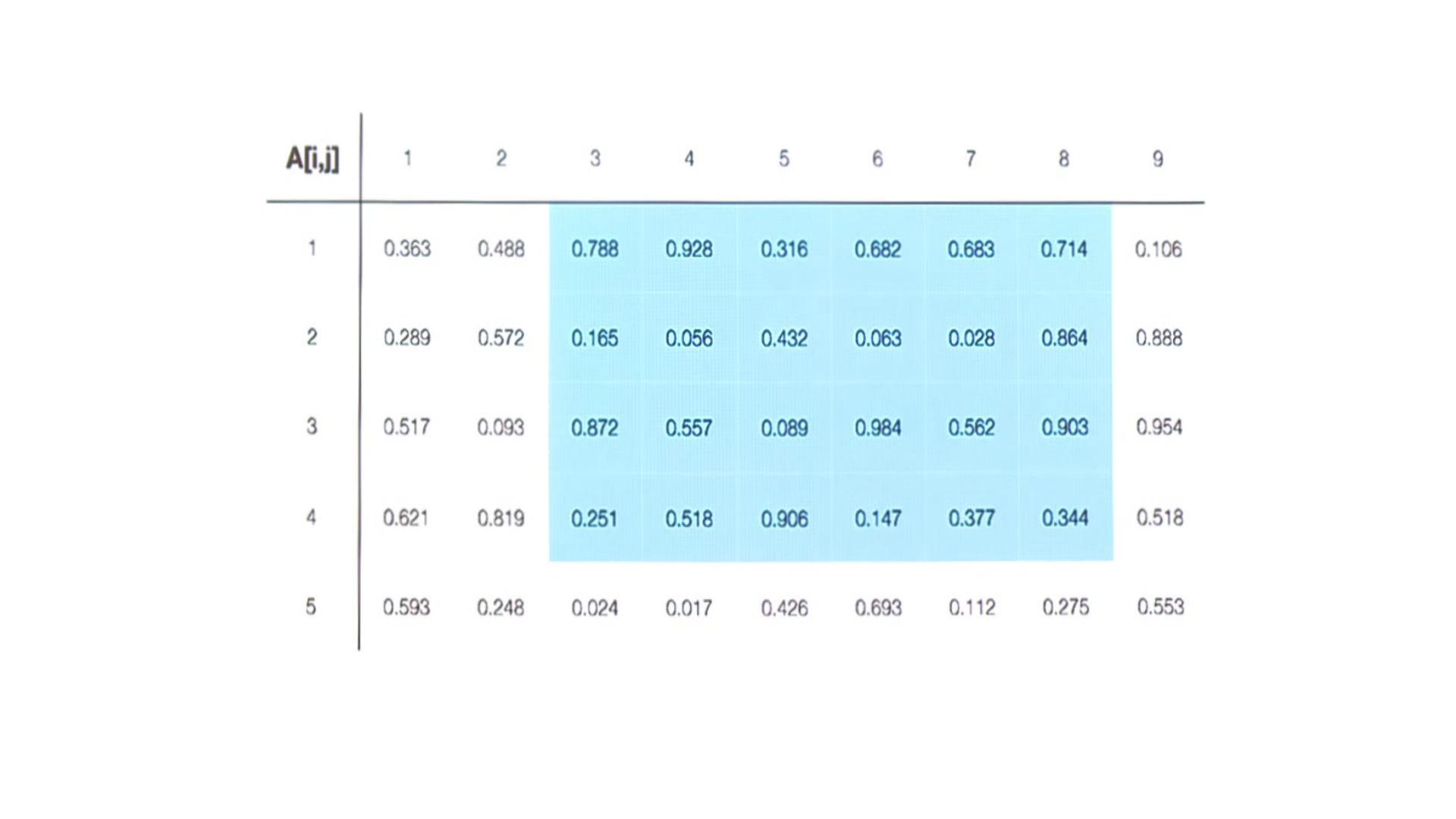
El problema de la vista de Arrays
El problema de la vista de Arrays
El Problema del "doble lenguaje"
Tener un lenguaje de alto nivel que se pueda trabajar interactivamente
= fácil desarrollo, prototipado, exploración
=> lenguaje dinámicamente tipeado
Mucho software de donde escoger: Python, Matlab / Octave, R, Scilab
Históricamente, no podemos escribir codigo crítico de rendimiento ("lazos internos") en estos lenguajes... debemos cambiar a C/Fortran/... (estáticos).
[e.g SciPy git master es ~70% C/C++/Fortran]
Trabajable, pero Python → Python+C = un gran salto en complejidad
¿Y si vectorizamos todo el código?
Esto implica en depender en librerías externas maduras operando en grandes bloques de datos para codigo crítico de rendimiento
¡Buen Consejo! Pero...
- Alguien tiene que escribir esas librerías
- Eventualmente esa persona podría ser usted
- Algunos problemas son imposibles o complicados de vectorizar.
Lenguajes Dinámicos no tienen que ser lentos
Mucho progreso en compiladores JIT gracias a aplicaciones web & JIT ofrecido por herramientas de software libre como LLVM
Javascript en navegadores modernos alcanza velocidades como C
Muchos esfuerzos, se han dado para aumentar la velocidad de lenguajes dinámicos, e.g PyPy, Numba / Cython
¿Que pasaría si un lenguaje dinámico fuera designado para JIT desde el principio, con el objetivo de ser alto-nivel mientras esté en la velocidad de C?
El Problema del "doble lenguaje"
(y es mucho más fácil llamar SciPy desde Julia que desde PyPy)
El Problema del "doble lenguaje"
- Dinámicamente tipeado
- Despacho múltiple: Una generalización de OO
- Metaprogramación (código que escribe código)
- Llamadas directas de funciones en C y Python
- Corutinas, y I/O asíncrona
- Diseñado para Unicode
- Tipos definidos por el usuario == tipos internos... extensibles, promoción y reglas de conversion
- Librería interna gigante: regex, álgebra lineal, funciones especiales, integración, etcétera
- Manejador de paquetes basado en git
Julia está escrito casi 70% en Julia
El Problema del "doble lenguaje"
¿Que tal sobre problemas reales comparado con código muy optimizado?
Funciones especializadas en Julia
funciones especiales s(x): problema clásico que no puede ser vectorizado... cambiar de varios polinomios que dependen en x
Muchas de las funciones especiales en Julia vienen de las librerías usuales C/Fortran pero algunas están escritas en Julia.
Julia erfinv(x)
3-4x mas rápido que Matlab y 2-3x más rápido que SciPy
Julia polygamma(m,z)
2 más rápido que SciPy (C/Fortran) para reales y además soporta argumento complejo
Funciones especializadas en Julia
Julia erfinv(x)
3-4x mas rápido que Matlab y 2-3x más rápido que SciPy
Julia polygamma(m,z)
2 más rápido que SciPy (C/Fortran) para reales y además soporta argumento complejo
Código de Julia puede ser incluso mas rápido que código optimizado de C/Fortran utilizando técnicas de metaprogramación que son difíciles en lenguajes de bajo nivel
Julia el diseño de un lenguaje
By David Cardozo
Julia el diseño de un lenguaje
Una pequeña introducción al diseño de lenguaje de Julia




