

Frédéric Clavert
historian. digital history. digital memory studies. join me on mastodon: @inactinique@mastodon.social
1. Why archiving tweets?
2. Case studies
3. The different ways to collect tweets
4. Hand's on!
They can help understand
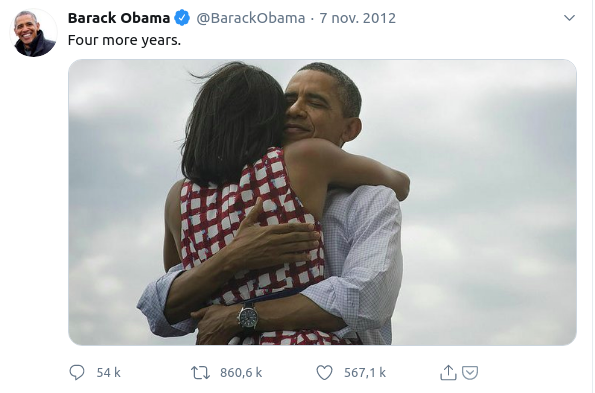
Archived, they will help understand the past.
About this tweet, see: Joshua Sternfeld, « Historical Understanding in the Quantum Age », Journal of Digital Humanities, 3-2, 2014.
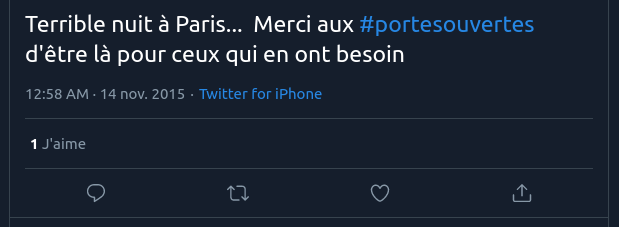
Tweet from the night of the Bataclan attack, with the #portesouvertes hashtag
Because we can.
An application programming interface (API) is a computing interface which defines interactions between multiple software intermediaries.
source: wikipedia
Who are we studying when collecting and analysing Twitter data?
Information circulation (memetics) where information is understood in a very wide meaning.
See: Dominique Boullier, « Big data challenges for the social sciences: from society and opinion to replications », arXiv:1607.05034 [cs], 2016.
Practices
9 millions+ tweets collected
Background: John Hopkins University coronavirus map. Screenshot (7/7/2020)
Copy TAGS to your google drive
Authorize Twitter
Set up the sheet
Collect!
Valérie Schafer, Gérôme Truc, Romain Badouard, Lucien Castex et Francesca Musiani, « Paris and Nice terrorist attacks: Exploring Twitter and web archives », Media, War & Conflict, , 2019, p. 1750635219839382.
Evelien D’heer, Baptist Vandersmissen, Wesley De Neve, Pieter Verdegem et Rik Van de Walle, « What are we missing? An empirical exploration in the structural biases of hashtag-based sampling on Twitter », First Monday, 22-2, 2017.
Martin Grandjean, « A social network analysis of Twitter: Mapping the digital humanities community », Cogent Arts & Humanities, 3-1, 2016, p. 1171458.
Michael Zimmer, « The Twitter Archive at the Library of Congress: Challenges for information practice and information policy », First Monday, 20-7, 2015.
Shirley A. Williams, Melissa M. Terras et Claire Warwick, « What do people study when they study Twitter? Classifying Twitter related academic papers », Journal of Documentation, 69-3, 2013, p. 384‑410.
Danah Boyd, Scott Golder et Gilad Lotan, « Tweet, tweet, retweet: Conversational aspects of retweeting on twitter », IEEE, 2010.
Danah M Boyd et Nicole B. Ellison, « Social Network Sites: Definition, History, and Scholarship », Journal of Computer-Mediated Communication, 13-1, 2007, p. 210‑230.
Hany M. SalahEldeen et Michael L. Nelson, « Losing My Revolution: How Many Resources Shared on Social Media Have Been Lost? », arXiv:1209.3026, , 2012.
Jean-Christophe Peyssard, « Archiving Web Content ». https://halshs.archives-ouvertes.fr/cel-02130558/document
Two prez: «How to deal with 4 millions+ tweets when you are not a data scientist» (https://orbilu.uni.lu/handle/10993/35017)
and «Twitter data as primary sources for historians: a critical approach» (with S. Papastamkou) (https://orbilu.uni.lu/handle/10993/37070)
By Frédéric Clavert
Slides for the Venice virtual summer camp on digital and public history.




