Seleção de Características
Débora Deslandes
Guilherme Lucindo
Izabela Borges
Leonardo Decina
Sumário
-
Introdução
-
O que é seleção de características?
-
-
TécnicaS
-
Modelos
-
MÉTODOS
-
Como e quando usar?
-
Vantagens e Desvantagens
-
Exemplos
-
-
-
Conclusão
Introdução
Na maioria das aplicações reais de classificação, as bases de dados contêm um grande número de caraterísticas, como, por exemplo, nome, identidade, endereço, etc.
Entretanto, na maioria dos casos, grande parte destas caraterísticas são irrelevantes e/ou redundantes. Então torna-se necessária a aplicação de seleção das características.
O que é seleção de características?
A seleção de características é um processo onde um espaço de dados é transformado em um espaço de características.
O conjunto sofre uma redução de dimensionalidade, de modo a reter dentre todos os atributos da base, aqueles mais relevantes do ponto de vista da hipótese a ser provada ou pergunta a ser respondida.
Técnicas
Existem inúmeras técnicas para a se realizar a seleção de variáveis, sendo estas categorizadas como métodos dependentes do modelo (Model-Based) e métodos independentes do modelo (“Model-Free”) .
Dentre os métodos dependentes do modelo podem-se mencionar técnicas baseadas em redes neurais, em modelos neuro-fuzzy e em algoritmos genéticos. No caso dos métodos independentes do modelo há métodos estatísticos, Análise de Componentes Principais (ACP), correlação e entropia.
Modelos
Dentre os modelos e métodos a serem abordados nesta apresentação, temos o método mRMR (mínima-Redundância Máxima-Relevância):
E seus métodos de redução de dados vertical:
-
KDD (KNOWLEDGE DISCOVERY IN DATABASES)
-
MODELO WRAPPER
-
MÉTODO DE FILTRO
-
MÉTODO HÍBRIDO
KDD
O KDD é um processo não trivial, de extração de informações implícitas, previamente desconhecidas e potencialmente úteis, a partir dos dados armazenados em um banco de dados.
FAYYAD et al. (1996)
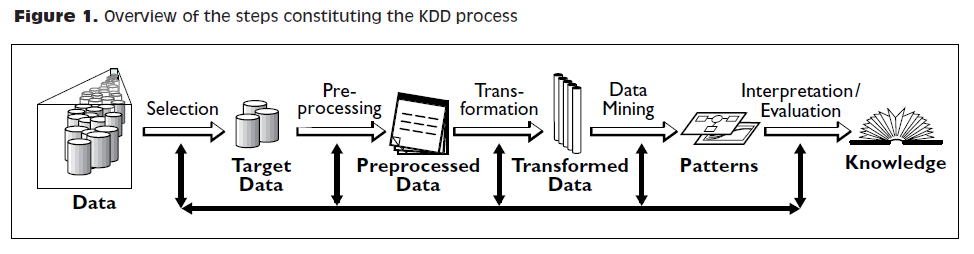
O processo de busca de conhecimento passa pelos passos: seleção, pré-processamento e limpeza, transformação, mineração de dados (data mining) e interpretação/avaliação.
O KDD compreende, na verdade, todo o ciclo que o dado percorre a té virar informação.
O processo é interativo, pois há a necessidade de intervenção, e iterativo, por ser uma sequência finita de operações com resultados dependentes das operações que a precedem.
KDD
Modelo Wrapper
GERAÇÃO DO SUBCONJUNTO DE CARACTERÍSTICAS
MODELO DE
INFERÊNCIA
MODELO DE
INFERÊNCIA
TODAS AS CARACTERÍSTICAS
Desempenho
Subconjunto ótimo
de características
Características
Avaliação
Método Wrapper avalia os subcon-juntos de atributos, que ao contrário dos métodos de filtro, detectam as interações/relações entre atributos.
A seleção de subconjunto acontece em conjunto com o algoritmo de aprendizagem, ou seja, o subconjunto se modela e se melhora. Cada subconjunto gerado pela seleção é avaliado pelo contexto da aprendizagem.
Como e Quando usar?
Forward selection: Começa com zero atributos candidatos, e é feito o teste de seleção de atributo candidato de acordo com o modelo do problema.
Backward selection: Começa com todos os atributos candidatos, e é feito o teste de eliminação de atributos de acordo com o modelo do problema.
Não deve ser usado com algoritmos de tempo de compilação muito grande.
Vantagens x DESVANTAGENS
- Fornece um subconjunto de maior acurácia;
- Tem a maior otimização para problemas de predição.
- Quando o número de características é insufi-ciente, o risco de adap-tação aumenta;
- Quando o número de variáveis é grande, o tempo de compilação se torna muito alto.
Método de Filtro
GERAÇÃO DO SUBCONJUNTO DE CARACTERÍSTICAS
MODELO DE
INFERÊNCIA
TODAS AS CARACTERÍSTICAS
Desempenho
Subconjunto ótimo
de características
Métodos de filtro selecionam atributos independente de modelo, baseados apenas em características gerais correlacionadas à característica a ser predita.
Os métodos de filtragem suprimem os atributos menos interessantes. Os demais atributos serão parte de um modelo de regressão utilizado para classificar ou prever dados.
Como e Quando usar?
O procedimento de seleção do subconjunto é independente do algoritmo de aprendizagem, o que faz esse método ser utilizado apenas como pré-processamento da base de dados.
Utilizam Foward selection e Backward elimination.
Vantagens x DESVANTAGENS
- Métodos de filtro são surpreendentemente efetivos em tempo de compilação;
- E robusto para overfitting.
- Métodos de filtro tendem a selecionar atributos redundantes;
- Não considera a relação entre variáveis;
Método Híbrido
GERAÇÃO DO SUBCONJUNTO DE CARACTERÍSTICAS
MODELO DE
INFERÊNCIA
+
DESEMPENHO
TODAS AS CARACTERÍSTICAS
Subconjunto ótimo
de características
Características
Avaliação
Os métodos híbridos (embedded) foram propostos recentemente de um modo à combinar as vantagens de ambos os métodos anteriores.
O algoritmo de aprendizagem toma proveito do próprio processo de seleção de atributos e executa simul-taneamente a seleção de características e classificação.
Como e Quando usar?
Métodos híbridos diferem de outros métodos de seleção de características pelo modo como a seleção e a aprendizagem interagem. Esses métodos aproximam as soluções para os problemas de minimização.
Utilizam Foward selection e Backward elimination.
Em métodos híbridos a aprendizagem e a seleção não podem ser executadas em separado, inviabilizando sua utilização com árvores de decisão.
Vantagens x DESVANTAGENS
- Combinação das van-tagens dos métodos Wrapper e Filtro.
- Seleção e aprendizagem são sempre executadas em conjunto;
- Não pode ser utilizado em árvores de decisão.
Algoritmos
Modelo Wrapper: Usado com algoritmos genéticos para o problema de Polimorfismo de nucleotídeo único.
Método Filtro: Usado no teste de Welch, para reconhecimento de padrão no estudo do Alzheimer.
Método híbrido: Geralmente usado para a solução de problemas que utilizam microarrays em conjunto com algoritmo genético.
Conclusão
A seleção de características é muito importante pois diminui a quantidade de características avaliadas na aprendizagem de máquina e nos processos que forem ser realizados. Permite uma maior clareza dos dados facilitando a análise.
A definição dos métodos de seleção de características utilizado varia de acordo com o problema em mãos, a quantidade de características relevantes e o ruído de cada conjunto de dados.
Dúvidas?
Contato
DÉBORA DESLANDES
debora.deslandes@sga.pucminas.br
GUILHERME LUCINDO
guilherme.lucindo@sga.pucminas.br
IZABELA Borges
izabela.borges@sga.pucminas.br
LEONARDO DECINA
leonardo.decina@sga.pucminas.br
Seleção de Características - IA
By Izabela Borges



