

Machine Learning
The Fundamentals

SpringOne Tour / Istanbul
About Presenter James Weaver
Java Champion, JavaOne Rockstar, plays well with others, etc :-)

Author of several Java/JavaFX/RaspPi books
Developer Advocate & International Speaker for
Mission: "Transform how the world builds software"





Mission: "Transform how the world builds software"

Some Pivotal involvement in machine learning


@JavaFXpert
From introductory video in Machine Learning course (Stanford University & Coursera) taught by Andrew Ng.

@JavaFXpert

Self-driving cars
@JavaFXpert
Generating image descriptions

@JavaFXpert
Supervised Learning

@JavaFXpert
Supervised learning regression problem

@JavaFXpert
Unsupervised Learning

@JavaFXpert
Unsupervised learning finds structure in unlabeled data

(e.g. market segment discovery, and social network analysis)
@JavaFXpert
Reinforcement Learning

@JavaFXpert
AlphaGo is a recent reinforcement learning success story

@JavaFXpert
Supervised Learning
(Let's dive in now)
@JavaFXpert
Supervised learning classification problem
(using the Iris flower data set)


@JavaFXpert
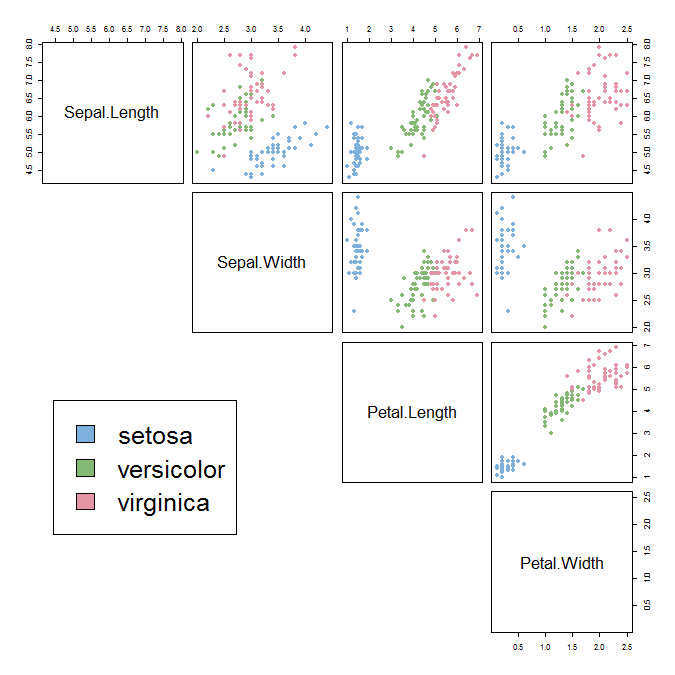

@JavaFXpert
Visualizing Iris dataset with TensorFlow tool
@JavaFXpert

Modeling the brain works well with machine learning
(ya think?)

(inputs)
(output)

@JavaFXpert
Anatomy of an Artificial Neural Network
(aka Deep Belief Network when multiple hidden layers)

@JavaFXpert
Neural net visualization app (uses Spring and DL4J)

@JavaFXpert
Entering feature values for prediction (classification)

@JavaFXpert
Simple neural network trained for XOR logic

forward propagation
@JavaFXpert
Feedforward calculations with XOR example
For each layer:

Multiply inputs by weights:
(1 x 8.54) + (0 x 8.55) = 8.54
Add bias:
8.54 + (-3.99) = 4.55
Use sigmoid activation function:
1 / (1 + e
-4.55
) = 0.99
@JavaFXpert


Excellent video on neural networks
@JavaFXpert
Simple neural network trained for XOR logic
back propagation (minimize cost function)
@JavaFXpert



Lab Exercise / Visualizing Gradient Descent:
Linear Regression app developed by Katharine Beaumont
@JavaFXpert


Make Your Own Neural Network (book)
Contains details on how weights and biases are adjusted during back propagation
@JavaFXpert

Excellent video on gradient descent
@JavaFXpert
Visual Neural Network application architecture

Spring makes REST services and WebSockets easy as π
@JavaFXpert
The app leverages machine learning libraries found at deeplearning4j.org

@JavaFXpert
Code that configures our speed dating neural net
@JavaFXpert


To quickly create a Spring project, visit start.spring.io

@JavaFXpert
Lab Exercise:
@JavaFXpert

For each of the four dataset icons (Circle, Exclusive Or, Gaussian, and Spiral):
- Select only the X1 & X2 features
- Modify the hyperparameters in such a way that minimizes the number of Epochs required to make the Test loss and Training loss each <= 0.009
- Tweet screenshot with your lowest Epochs result tagging @JavaFXpert in the message.
Practice tuning neural network hyperparameters
Is Optimizing your Neural Network a Dark Art ?
Excellent article by Preetham V V on neural networks and choosing hyperparameters

@JavaFXpert
Various Neural Networks
Convolutional Neural Network for recognizing images
@JavaFXpert

Convolutional neural network architecture
@JavaFXpert

[by Adit Deshpande]
Peeking into a convolutional neural network

http://scs.ryerson.ca/~aharley/vis/ [by Adam Harley]
@JavaFXpert
Time series prediction with neural networks

What is happening? What is most likely to happen next?
@JavaFXpert
This is a job for a Recurrent Neural Network
What is happening? What is most likely to happen next?
@JavaFXpert
Recurrent Neural Network
@JavaFXpert

vs. traditional feed-forward network
Music composition with an RNN

@JavaFXpert
Predicting the most likely next note


@JavaFXpert
Playing a duet with neural networks

@JavaFXpert
Playing a duet with neural networks

@JavaFXpert
Unsupervised Learning
@KatharineCodes @JavaFXpert
(Let's dive in now)
Using unsupervised learning to map artworks

@JavaFXpert
Euclidian distance for high-dimensional vectors
@JavaFXpert


Using unsupervised learning to map words
@JavaFXpert

word2vec vector representations of words
Using unsupervised learning to map words
@JavaFXpert
word2vec vector offsets for gender relationships

Using unsupervised learning to map words
@JavaFXpert

word2vec vector offsets for plural relationships
Using unsupervised learning to map words
@JavaFXpert
word2vec vector arithmetic

word2vec vector arithmetic
@JavaFXpert
King – Man + Woman = Queen

Visualizing word2vec words & points
@JavaFXpert
using Tensorflow Embedding Projector

Inspecting word embeddings
@JavaFXpert

Reinforcement Learning
(Let's dive in now)
@JavaFXpert
Reinforcement Learning tabula rasa
Using BURLAP for Reinforcement Learning

@JavaFXpert
Learning to Navigate a Grid World with Q-Learning

@JavaFXpert
Rules of this Grid World
- Agent may move left, right, up, or down (actions)
- Reward is 0 for each move
- Reward is 5 for reaching top right corner (terminal state)
- Agent can't move into a wall or off-grid
- Agent doesn't have a model of the grid world. It must discover as it interacts.
Challenge: Given that there is only one state that gives a reward, how can the agent work out what actions will get it to the reward?
(AKA the credit assignment problem)
Goal of an episode is to maximize total reward
@JavaFXpert
This Grid World's MDP (Markov Decision Process)

In this example, all actions are deterministic
@JavaFXpert
Agent learns optimal policy from interactions with the environment (s, a, r, s')

@JavaFXpert
Visualizing training episodes

From BasicBehavior example in https://github.com/jmacglashan/burlap_examples
@JavaFXpert
Expected future discounted rewards, and polices

@JavaFXpert
This example used discount factor 0.9

Low discount factors cause agent to prefer immediate rewards
@JavaFXpert
How often should the agent try new paths vs. greedily taking known paths?
@JavaFXpert
Q-Learning approach to reinforcement learning
| Left | Right | Up | Down | |
|---|---|---|---|---|
| ... | ||||
| 2, 7 | 2.65 | 4.05 | 0.00 | 3.20 |
| 2, 8 | 3.65 | 4.50 | 4.50 | 3.65 |
| 2, 9 | 4.05 | 5.00 | 5.00 | 4.05 |
| 2, 10 | 4.50 | 4.50 | 5.00 | 3.65 |
| ... |
Q-Learning table of expected values (cumulative discounted rewards) as a result of taking an action from a state and following an optimal policy. Here's an explanation of how calculations in a Q-Learning table are performed.
Actions
States
@JavaFXpert
Tic-Tac-Toe with Reinforcement Learning
Learning to win from experience rather than by being trained

@JavaFXpert
Inspired by the Tic-Tac-Toe Example section...


@JavaFXpert
Tic-Tac-Toe Learning Agent and Environment
X
O
Our learning agent is the "X" player, receiving +5 for winning, -5 for losing, and -1 for each turn
The "O" player is part of the Environment. State and reward updates that it gives the Agent consider the "O" play.
@JavaFXpert
Tic-Tac-Toe state is the game board and status
| States | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| O I X I O X X I O, O won | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| I I I I I I O I X, in prog | 1.24 | 1.54 | 2.13 | 3.14 | 2.23 | 3.32 | N/A | 1.45 | N/A |
| I I O I I X O I X, in prog | 2.34 | 1.23 | N/A | 0.12 | 2.45 | N/A | N/A | 2.64 | N/A |
| I I O O X X O I X, in prog | +4.0 | -6.0 | N/A | N/A | N/A | N/A | N/A | -6.0 | N/A |
| X I O I I X O I X, X won | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| ... |
Q-Learning table of expected values (cumulative discounted rewards) as a result of taking an action from a state and following an optimal policy
Actions (Possible cells to play)
Unoccupied cell represented with an I in the States column
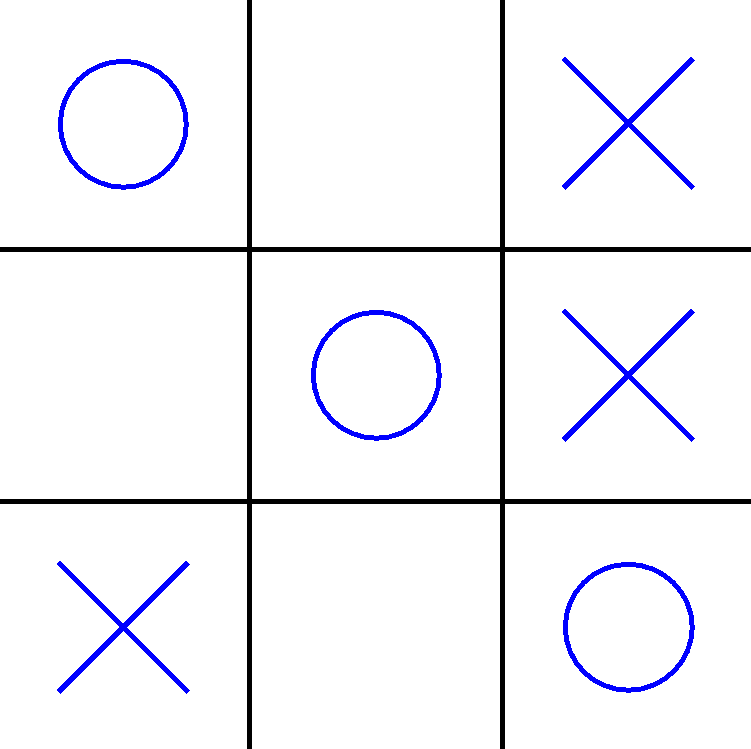
@JavaFXpert
Tic-Tac-Toe with Reinforcement Learning

@JavaFXpert
Through the Eyes of a Self-Driving Tesla
@JavaFXpert
Summary of links
Andrew Ng video:
https://www.coursera.org/learn/machine-learning/lecture/zcAuT/welcome-to-machine-learning
Iris flower dataset:
https://en.wikipedia.org/wiki/Iris_flower_data_set
Visual neural net server:
http://github.com/JavaFXpert/visual-neural-net-server
Visual neural net client:
http://github.com/JavaFXpert/ng2-spring-websocket-client
Deep Learning for Java: http://deeplearning4j.org
Spring initializr: http://start.spring.io
A.I Duet application: http://aiexperiments.withgoogle.com/ai-duet/view/
Self driving car video: https://vimeo.com/192179727
@JavaFXpert

Machine Learning
The Fundamentals
Machine Learning Exposed: The Fundamentals
By javafxpert
Machine Learning Exposed: The Fundamentals
Machine Learning Exposed fundamental concepts. Shedding light on machine learning.




