Script Independent Scene Text Segmentation using Fast Stroke Width Transform and GrabCut
Jay H. Bosamiya, Palash Agrawal,
Partha Pratim Roy, R. Balasubramanian
What?!?

Basically
The system can point out areas of interest for text, even if it hasn't seen the language before


But why?

Multiple reasons
- Existing segmentation techniques worked only with English
- Existing techniques could be "taught" new languages, but then they would recognize only those specific languages
- India is vast enough, that we need something generalized
- It should work well, even on languages it has never seen before
- We have good OCR techniques but they work only on Black and White images, not scene images
Previous Work
- Bottom up (using region based techniques)
- Phan et al
- Neumann and Matas
- Filter from top to bottom (using texture properties)
- Yi and Tian
- Yao et al
- Still, above work only on English
- We combined ideas from both, and also made it independent of language/script
Problems?

Text Like Patterns
Some urban patterns are common but not text

Tree Foliage
Nature also likes to mess
with us!

Glare
Cameras are messy pieces of equipment!

So HOW did we solve it?

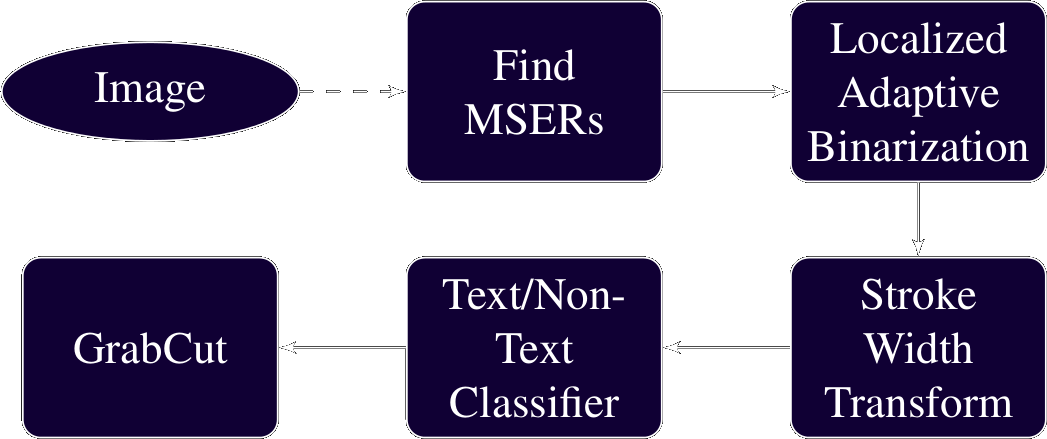
Image


Finding Maximally Stable Extremal Regions (MSERs)

Localized Adaptive Binarization

Stroke Width Transform
Text/Non-Text Classifier

GrabCut

Fast Stroke Width Transform

What next?

Experimentation
Tested on
- ICDAR 2013 Robust Reading Competition Dataset (for English)
- 233 images
- Performs close enough to pre-existing techniques
- Custom Dataset (for other languages)
- Performs with similar accuracy on Indian Languages dataset, without ever being trained on Indian Languages
Experimentation Platform
- Designed a generic framework for doing modular experimentation
- Parameter optimization done on the PARAM cluster (Thanks ICC!)
- Code written in C++ using OpenMP (for parallelism on the cluster)
- OpenCV used for handling low level image manipulation
- Custom Genetic Algorithm implementation for parameter optimization (alongside manual optimization, and grid search)
Fast SWT
Performs (on average) 79% faster than Stroke Width Operator described by Chen et al
when run against full dataset
Additionally, gives more accurate measurement (fractional stroke widths are supported by Fast SWT, as compared to the purely quantized integer stroke widths in previous algorithms)
On English Scene Segmentation
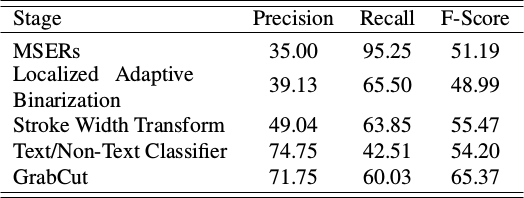
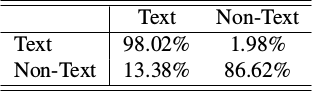
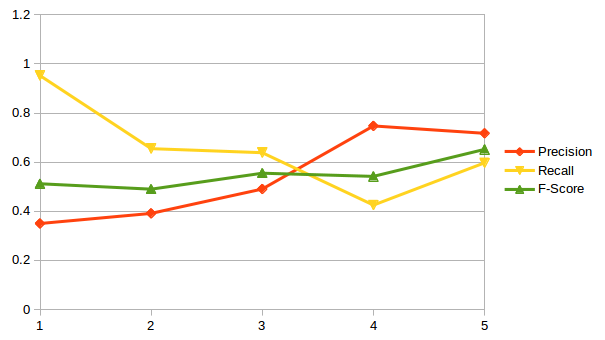
Graphs!
Different stages of the technique
Error Analysis


Conclusions
- Possible to do Text Segmentation independent of language/script
- Works as good on Indian Languages as on English
- Designed a new FastSWT algorithm, which outperforms state-of-the-art by 79% in speed, and is more accurate and precise
Future Work

Future Work
- Combine with recognition, to improve quality of both segmentation and recognition
- Change technique to handle single-connected-component words (for example, by removing the top bar in Devanagiri script)
- Improve it for handwritten/cursive font (which has high degree of connectivity throughout word)
- Curved Text (requires non-horizontal bounding box in GrabCut stage)
Questions?

Scene Text Segmentation
By jaybosamiya
