Using an actor framework for scientific computing
opportunities and challenges
author: Krzysztof Borowski
supervisor: Ph. D. Bartosz Baliś
@liosedhel
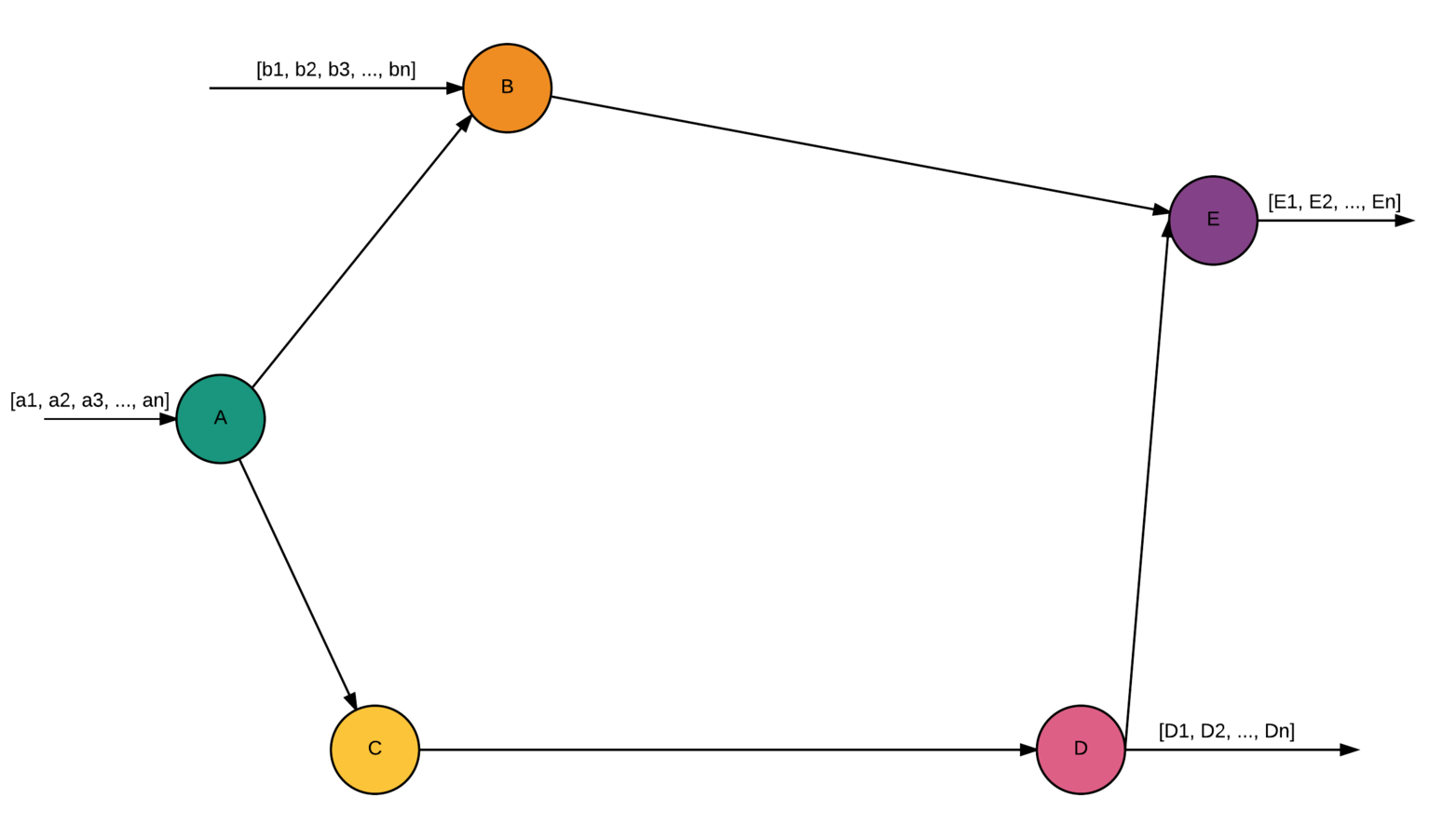
Workflow
- Directed Graph
- Many inputs/Many outputs
- Nodes - activities
- Edges - dependencies (control flow)
- Each node activity == fun(Data): Result
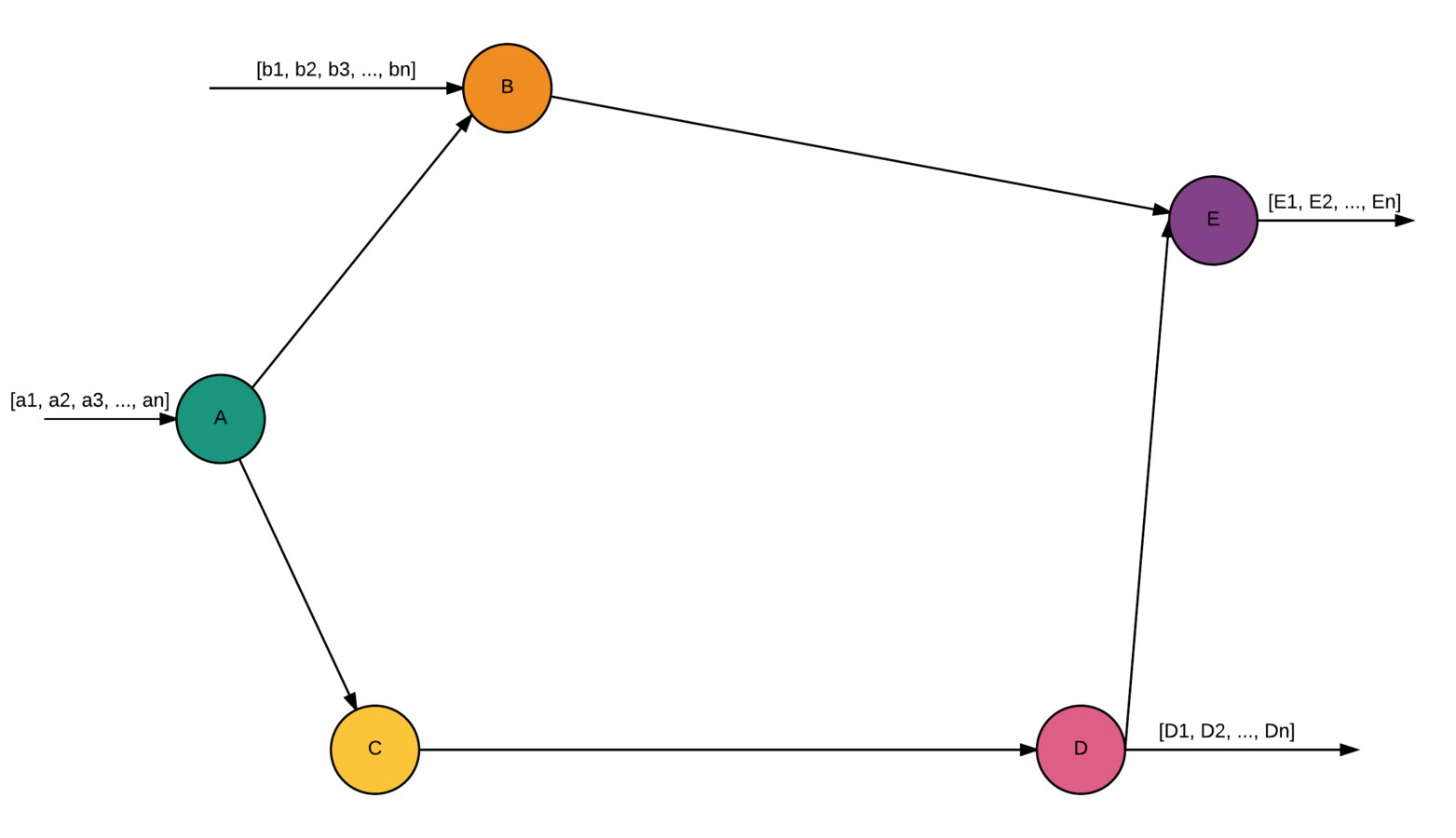
Scientific workflow
- Data elements can be big
- Activities can be long-running and resource intensive
- Often invoke legacy code (e.g. Fortran, C) or external services
Scientific workflow - requirements
- Parallelization and distribution of computations
- Persistence and recovery
- Fault tolerance
Actor Model
- State isolation
- Async communication
- Behavior changing
- Spawning new actors
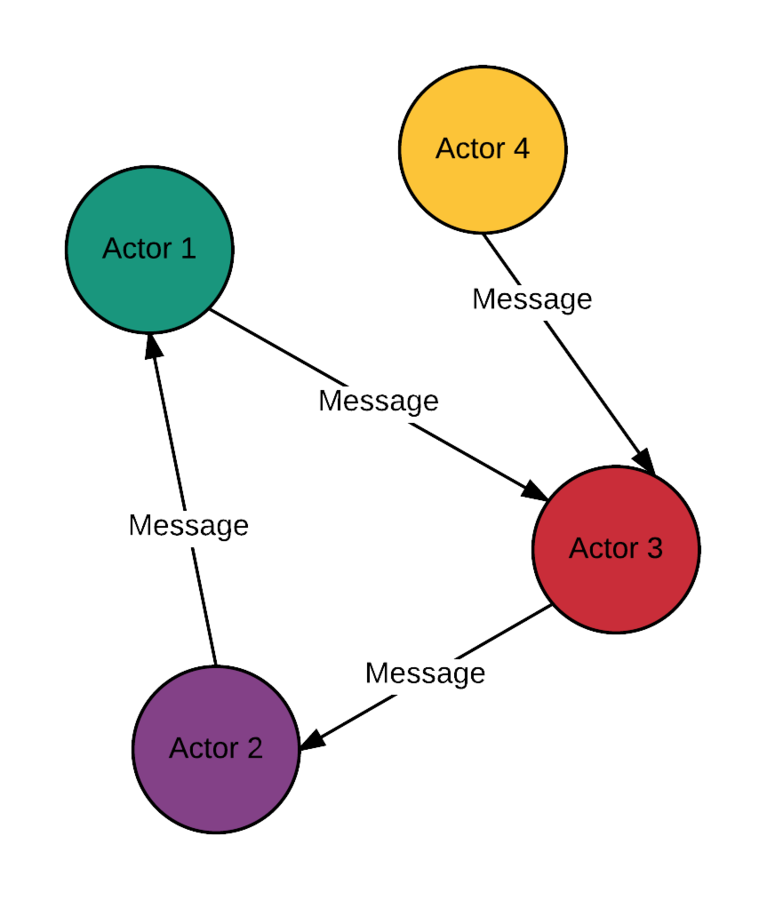
But why exactly the actor model?
But why exactly the actor model?
Similarities. Why not to give it a shot?
Actor Model difficulties

| Aspect | Flow activity | Actors |
|---|---|---|
| Input data | Many typed input channels | One input mailbox |
| Output data | Many typed output channels | Lack of output channels |
| Flow patterns | Complicated patterns | Simple async messages in "fire and forget" manner |
Akka-streams to the rescue!
- Build with actor model
- Support for complicated flows (beautiful graph oriented API)
- Concurrent data processing
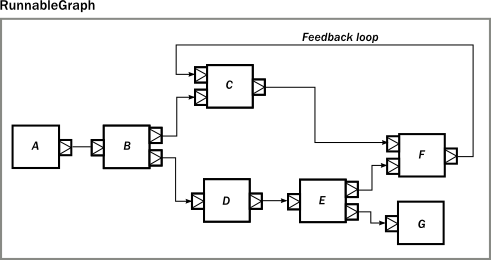
But...
| Scientific workflows | Akka streams |
|---|---|
| bounded input data set | unbounded data stream |
| big data elements | small data elements |
| focused on scaling | focused on back-pressure (reactive streams implementation) |
| important recovery mechanism | important high message throughput |
Current workflow engines
- Kepler, Teverna, Pegasus
- Focused on graphical interface for non programmers, or has complicated API
- Complex
- At the end of the day you always must write external program
Scaflow - New Hope
- Simple workflow engine for scientific computations
- For programmers
- Build with modern technologies in less then 1.5k lines of code (Scala, Akka, Cassandra)



Components
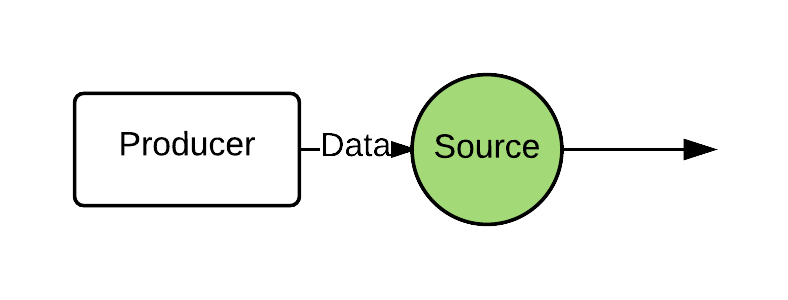
Source

Data processing
Data filtering


Data grouping
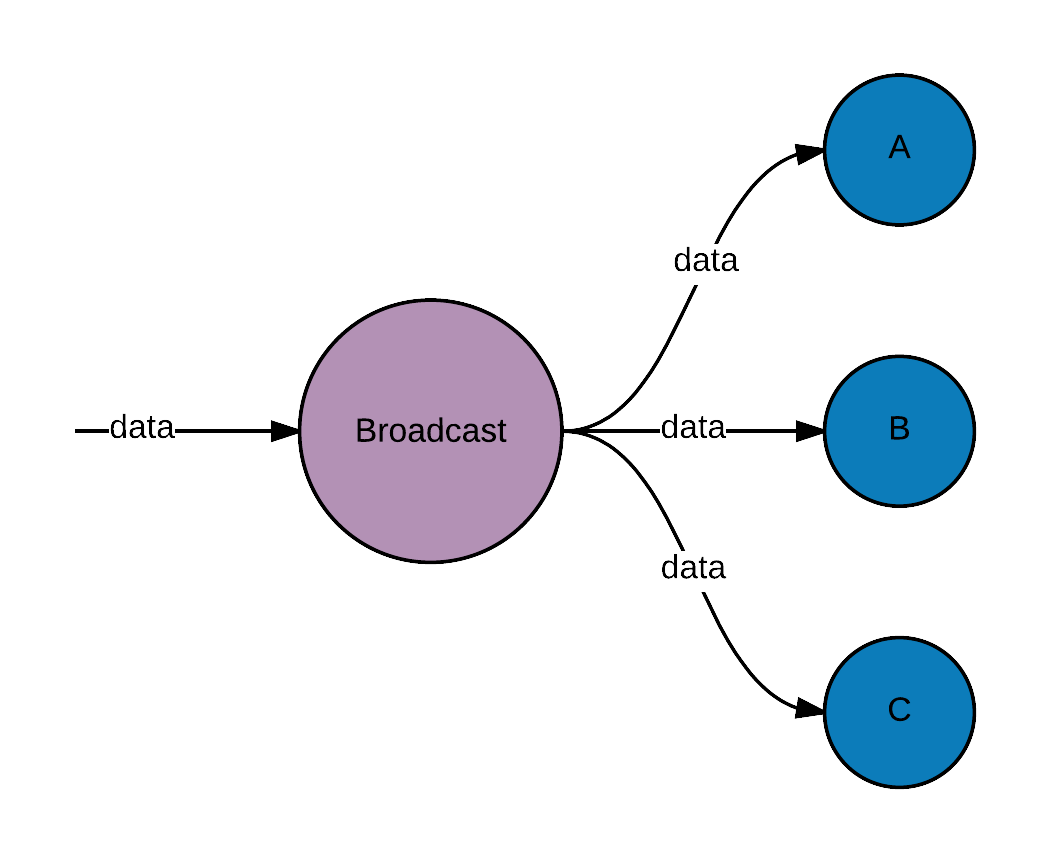
Components
Broadcast data
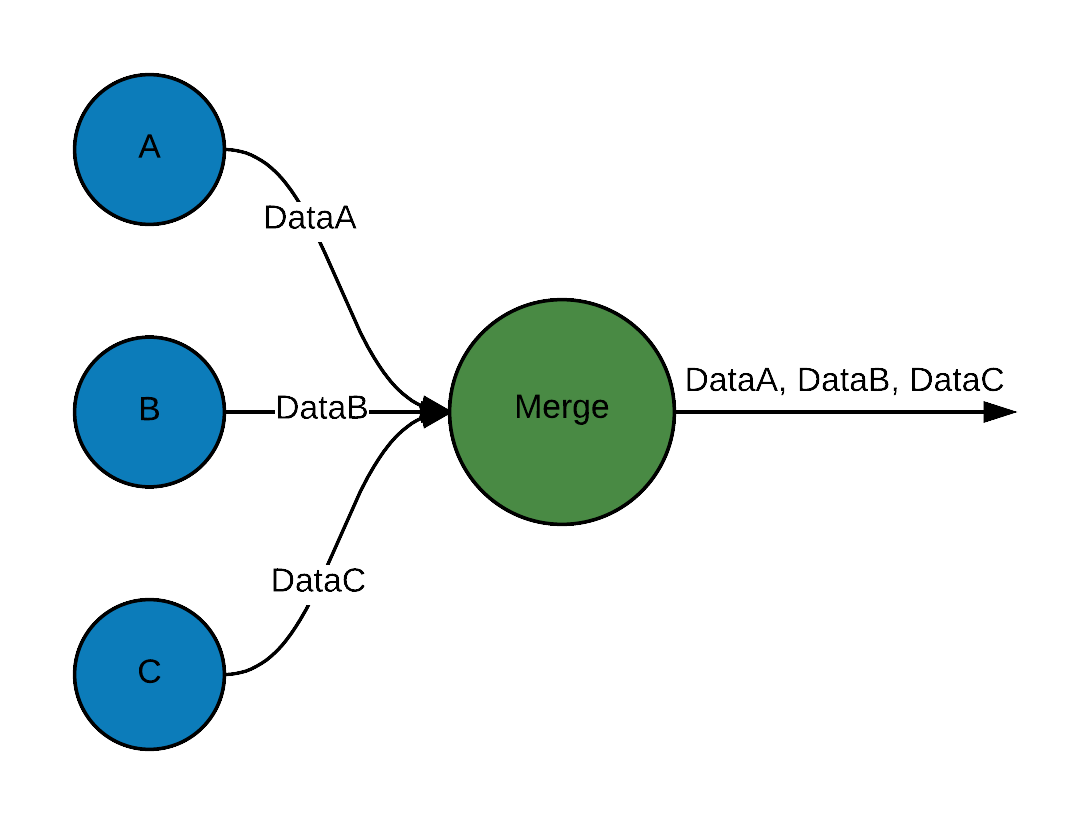
Merge data
Components
Synchronize data
Data sink
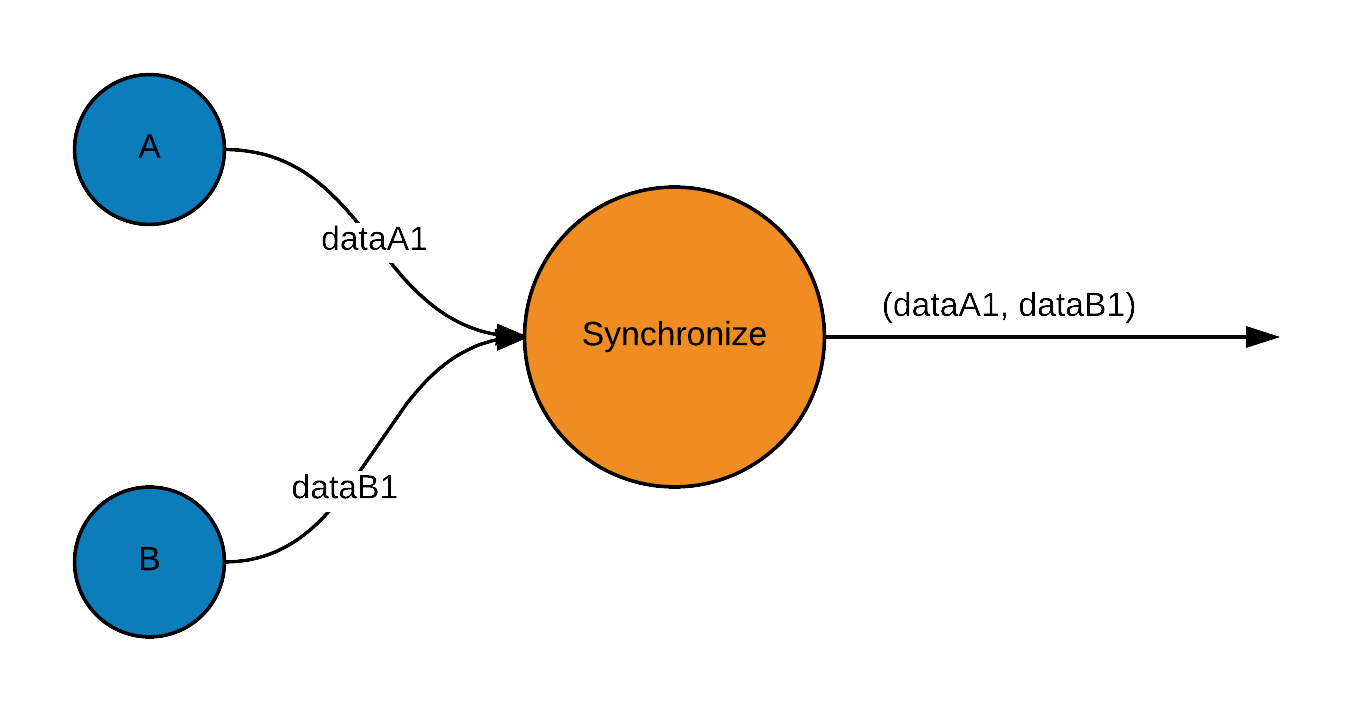

Scaflow API
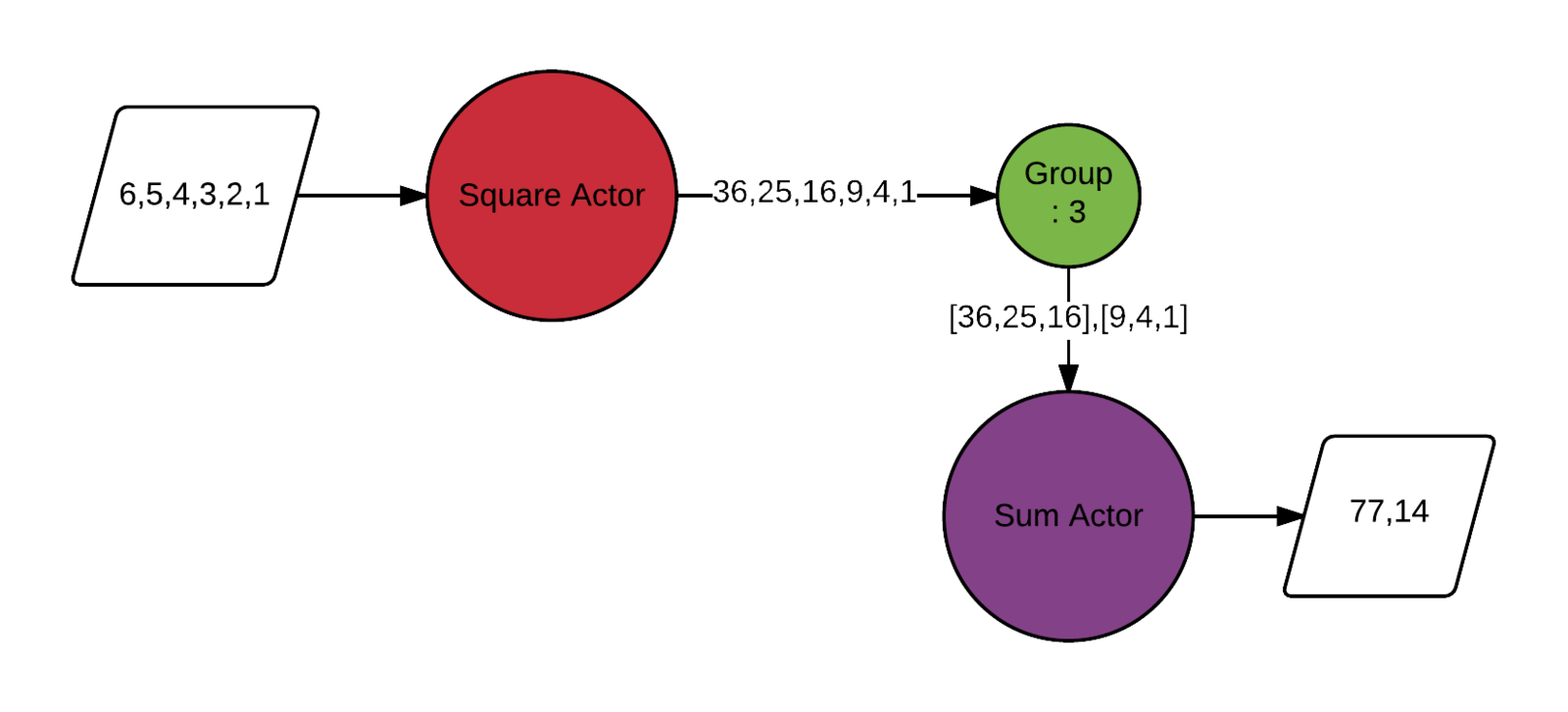
StandardWorkflow.source(List(1, 2, 3, 4, 5, 6))
.map(a => a * a)
.group(3)
.map(_.sum)
.sink(println).runConcurrent computations in actor model
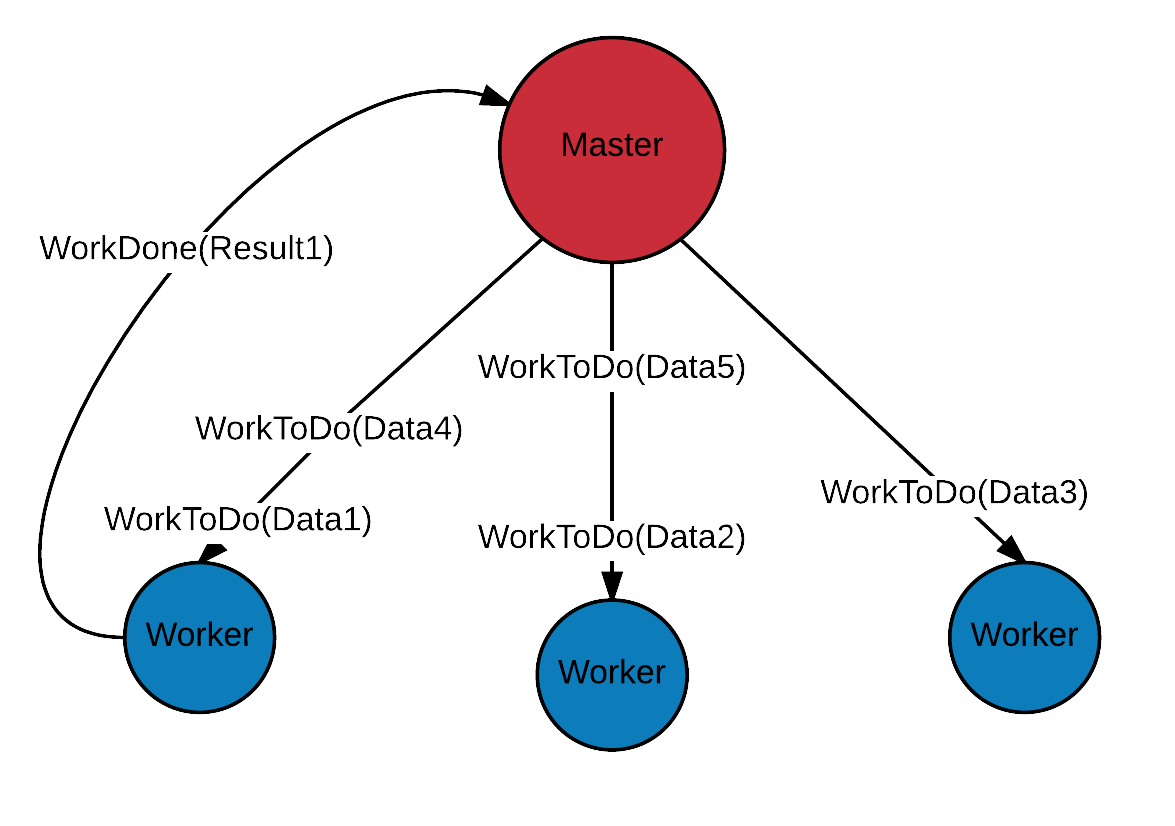
Push model
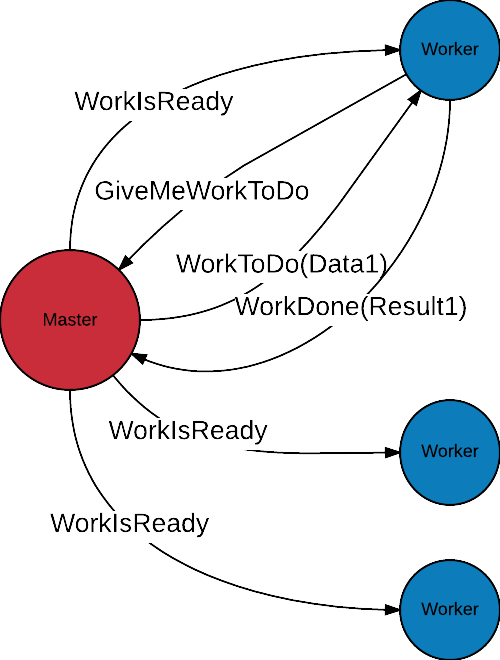
Pull model
Scalability in actor model
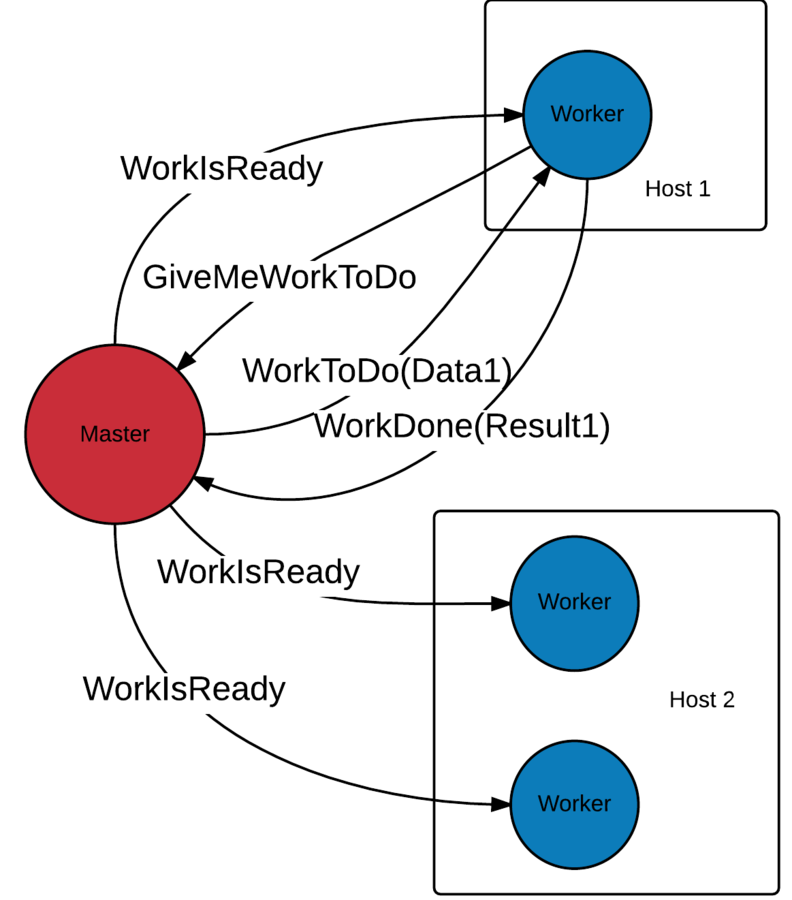
Workflow persistent state
- Event sourcing
- Persistent actors
override def receiveRecover: Receive = receiveRecoverWithAck {
case n: NextVal[A] =>
if (filter(n.data)) deliver(destination, n)
}
override def receiveCommand: Receive = receiveCommandWithAck {
case n: NextVal[A] =>
persistAsync(n) { e =>
if (filter(e.data)) deliver(destination, n)
}
}
/* ... */
PersistentWorkflow.source("source", List(1, 2, 3, 4, 5, 6))
.map("square", a => a * a)
.group("group", 3)
.map("sum", _.sum)
.sink(println).run
Fault tolerance
val HTTPSupervisorStrategy = OneForOneStrategy(10, 5.seconds) {
case e: TimeoutException => Restart //retry
case _ => Stop //drop the message
}
PersistentWorkflow.connector[String]("pngConnector")
.map("getPng", getPathwayMapPng, Some(HTTPSupervisorStrategy))
.sink("sinkPng", id => println(s"PNG map downloaded for $id"))Real world example
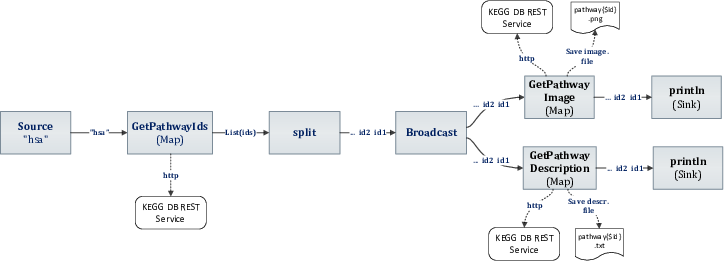
Real world example cont.
val HTTPSupervisorStrategy = OneForOneStrategy(10, 10.seconds) {
case e: TimeoutException => Restart // try to perform operation again
case _ => Stop // drop the message
}
val savePathwayPngFlow = PersistentWorkflow.connector[String]("pngConnector")
.map("getPng", getPathwayMapPng, Some(HTTPSupervisorStrategy), workersNumber = 8)
.sink("sinkPng", id => println(s"PNG map downloaded for $id"))
val savePathwayTextFlow = PersistentWorkflow.connector[String]("textConnector")
.map("getTxt", getPathwayDetails, Some(HTTPSupervisorStrategy), workersNumber = 8)
.sink("sinkTxt", id => println(s"TXT details downloaded for pathway $id"))
PersistentWorkflow
.source("source", List("hsa"))
.map("getSetOfPathways", getSetOfPathways, Some(HTTPSupervisorStrategy))
.split[String]("split")
.broadcast("broadcast", savePathwayPngFlow, savePathwayTextFlow)
.runReal world example - scaling
val remoteWorkersHostLocations =
Seq(AddressFromURIString("akka.tcp://workersActorSystem@localhost:5150"),
AddressFromURIString("akka.tcp://workersActorSystem@localhost:5151"))
val HTTPSupervisorStrategy = OneForOneStrategy(10, 10.seconds) {
case e: TimeoutException => Restart // try to perform operation again
case _ => Stop // drop the message
}
val savePathwayPngFlow = PersistentWorkflow.connector[String]("pngConnector")
.map("getPng", getPathwayMapPng, Some(HTTPSupervisorStrategy),
workersNumber = 8, remoteAddresses = remoteWorkersHostLocations)
.sink("sinkPng", id => println(s"PNG map downloaded for $id"))
val savePathwayTextFlow = PersistentWorkflow.connector[String]("textConnector")
.map("getTxt", getPathwayDetails, Some(HTTPSupervisorStrategy), workersNumber = 8)
.sink("sinkTxt", id => println(s"TXT details downloaded for pathway $id"))
PersistentWorkflow
.source("source", List("hsa"))
.map("getSetOfPathways", getSetOfPathways, Some(HTTPSupervisorStrategy))
.split[String]("split")
.broadcast("broadcast", savePathwayPngFlow, savePathwayTextFlow)
.runEvent sourcing - performance

Future development
- Graph API
- Extensive usage of Akka clusters
- Workflow monitoring
https://github.com/liosedhel/scaflow
Special thanks go to
Ph.D. Bartosz Baliś
from AGH Universisty
for the idea, work supervision, advices and all other help during the research and Scaflow development
https://github.com/liosedhel/scaflow
Bibliography
- Akka - http://akka.io/
- Cassandra - http://cassandra.apache.org/
- Pegasus - pegasus.isi.edu
- Taverna - http://www.taverna.org.uk/
- Kepler - https://kepler-project.org/
- akka-streams - http://doc.akka.io/docs/akka-stream-and-http-experimental/2.0.3/scala.html
Scaflow-LambdaDays2016
By liosedhel



