Redis
Escalando sua aplicação para suportar milhões

Quem sou eu?
Lucas Santos
@ll_ucasn
BSc. Computer Science
Redis é um NoSQL
Redis é um NoSQL
Not only SQL
Redis é um NoSQL
Not only SQL
Outro tipo de estruturação de dados, diferente da tabular vista nos bancos de dados relactionais
Redis é um armazenador de Key-Value
Redis é um armazenador de Key-Value
Você dá a Key(Chave) junto com o Value(valor) para aquela Key
Redis é um armazenador de Key-Value
Você dá a Key(Chave) junto com o Value(valor) para aquela Key
'nome' : 'Daniela'
Redis é um Data Structure Server
E o mais incrível: Redis é In-Memory
E o mais incrível: Redis é In-Memory
Seu armazenamento principal é feito na memória RAM

E por quê eu quero meu banco de dados In-Memory?
Aqui está um exemplo de uma operação típica em um MySQL

Agora imagine uma aplicação enviando 1 milhão de requisições onde serão realizadas escritas no Banco de Dados
Como o seu sistema irá reagir ao ver que terá que fazer 1kkk disk I/O de vez

Disk I/O é uma operação extremamente custosa

Gargalo
Em situações de fluxo elevado, isso significa: lentidão, Crashes, Usuários Insatisfeitos
Em situações como essa, Redis e sua tecnologia in-memory é o que irá salvar.
Em situações como essa, Redis e sua tecnologia in-memory é o que irá salvar.

"Mas se eu reiniciar a máquina, vou perder minhas informações? Afinal, memória RAM é volátil"
"Mas se eu reiniciar a máquina, vou perder minhas informações? Afinal, memória RAM é volátil"

A estratégia não é substituir o MySQL pelo Redis. A ideia é adiciona-lo na sua stack.

+
O papel do Redis é de Memoria Cache
O papel do Redis é de Memoria Cache

O papel do Redis é de Memoria Cache
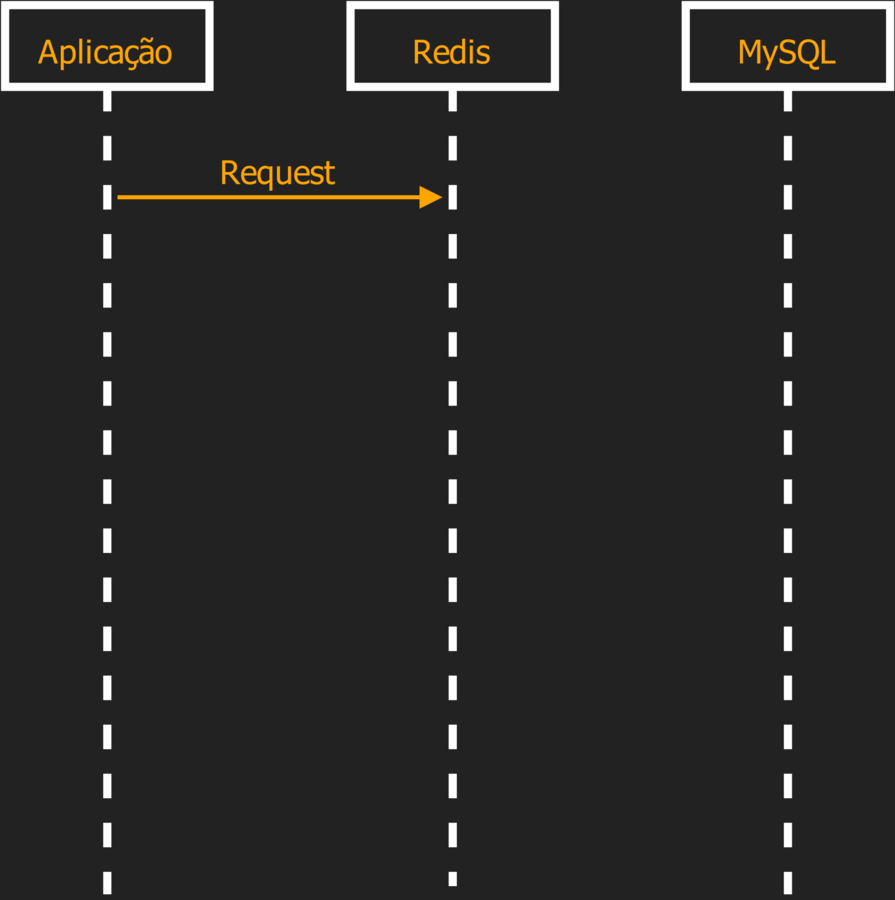
O papel do Redis é de Memoria Cache

O papel do Redis é de Memoria Cache
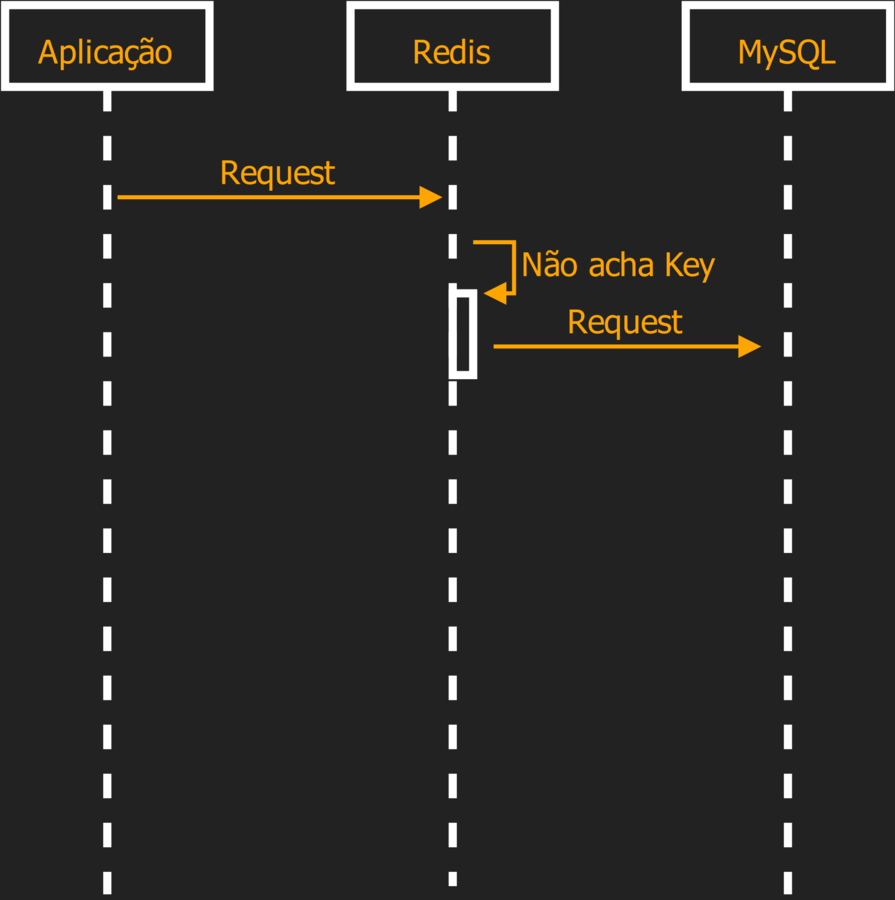
O papel do Redis é de Memoria Cache

O papel do Redis é de Memoria Cache

O papel do Redis é de Memoria Cache

O papel do Redis é de Memoria Cache

O papel do Redis é de Memoria Cache

O papel do Redis é de Memoria Cache

Redis como Memória Cache

Redis até agora:
- NoSQL
Redis até agora:
- NoSQL
- Key-Value Storing
Redis até agora:
- NoSQL
- Key-Value Storing
- Data Structure Server
Redis até agora:
- NoSQL
- Key-Value Storing
- Data Structure Server
- In-Memory
Redis até agora:
- NoSQL
- Key-Value Storing
- Data Structure Server
- In-Memory
E não para por aí.
Data Structure Server
- O fato do Redis ser organizado por Key-Value não limita o value a ser apenas uma String
Data Structure Server
- O fato do Redis ser organizado por Key-Value não limita o value a ser apenas uma String
- Ao invés de uma String, o Value pode ser uma Estrutura de Dados conhecida
Data Structure Server
- O fato do Redis ser organizado por Key-Value não limita o value a ser apenas uma String
- Ao invés de uma String, o Value pode ser uma Estrutura de Dados conhecida
> set nome daniela
OK
> get nome
"daniela"Data Structure Server
- O fato do Redis ser organizado por Key-Value não limita o value a ser apenas uma String
- Ao invés de uma String, o Value pode ser uma Estrutura de Dados conhecida
List
- O Redis implementa a verdadeira List Data Structure (de um ponto de vista teórico)
List
- O Redis implementa a verdadeira List Data Structure (de um ponto de vista teórico)
- A implementação é feita usando as Linked Lists
List
- O Redis implementa a verdadeira List Data Structure (de um ponto de vista teórico)
- A implementação é feita usando as Linked Lists
- O que significa que a inserção de novos elementos, tanto no início quanto no fim da lista é feito em tempo constante O(1)
List
- O Redis implementa a verdadeira List Data Structure (de um ponto de vista teórico)
- A implementação é feita usando as Linked Lists
- O que significa que a inserção de novos elementos, tanto no início quanto no fim da lista é feito em tempo constante O(1)
- O tempo pra inserir um elemento em uma lista com 10 elementos é o mesmo pra inserir em uma lista com 10 milhões de elementos!
List
- O Redis implementa a verdadeira List Data Structure (de um ponto de vista teórico)
- A implementação é feita usando as Linked Lists
- O que significa que a inserção de novos elementos, tanto no início quanto no fim da lista é feito em tempo constante O(1)
- O tempo pra inserir um elemento em uma lista com 10 elementos é o mesmo pra inserir em uma lista com 10 milhões de elementos!
- Logo, se um cenário exigir largas escalas de inserção de dados em listas, use list
List
> rpush minha_lista rodrigo
(integer) 1
> rpush minha_lista daniela
(integer) 2
> rpush minha_lista lucas
(integer) 3
> rpush minha_lista nadson
(integer) 4
> lrange minha_lista 0 -1
1) "rodrigo"
2) "daniela"
3) "lucas"
4) "nadson"
Sets (conjuntos)
- Sets são coleções não-ordenadas de String
Sets (conjuntos)
- Sets são coleções não-ordenadas de String
- A diferença de Sets para Lists, é que essa Estrutura de Dados permite a aplicação de métodos da teoria de conjuntos em cima dos elementos
Sets (conjuntos)
- Sets são coleções não-ordenadas de String
- A diferença de Sets para Lists, é que essa Estrutura de Dados permite a aplicação de métodos da teoria de conjuntos em cima dos elementos
- intercessão, união, diferença entre conjuntos e mais
Sets (conjuntos)
- Sets são coleções não-ordenadas de String
- A diferença de Sets para Lists, é que essa Estrutura de Dados permite a aplicação de métodos da teoria de conjuntos em cima dos elementos
- intercessão, união, diferença entre conjuntos e mais
- E também, Sets não permitem elementos repetidos. A inserção de elementos iguais ocasionará em uma única cópia deste elemento
Ordered Sets
- A diferença é que esses Sets são ordenados por um valor chamado Score
Ordered Sets
- A diferença é que esses Sets são ordenados por um valor chamado Score
- Apesar de que os elementos não podem se repetir, os Scores podem ser iguais
Ordered Sets
- A diferença é que esses Sets são ordenados por um valor chamado Score
- Apesar de que os elementos não podem se repetir, os Scores podem ser iguais
- Extremamente performático
Ordered Sets
- A diferença é que esses Sets são ordenados por um valor chamado Score
- Apesar de que os elementos não podem se repetir, os Scores podem ser iguais
- Extremamente performático
- Utilizados no mundo real em diversos casos: Leader Board em tempo real
Hashes
- Hashes são mapeamentos entre valores em strings e campos em strings
Hashes
- Hashes são mapeamentos entre valores em strings e campos em strings
- São perfeitos pra representar objetos
Hashes
- Hashes são mapeamentos entre valores em strings e campos em strings
- São perfeitos pra representar objetos
- Exemplo, objeto usuário com vários campos como Nome, Sobrenome, Email...
Hashes
- Hashes são mapeamentos entre valores em strings e campos em strings
- São perfeitos pra representar objetos
- Exemplo, objeto usuário com vários campos como Nome, Sobrenome, Email...
HMSET user:1000 username antirez password P1pp0 age 34
HGETALL user:1000
HSET user:1000 password 12345
HGETALL user:1000Hashes
- Hashes são mapeamentos entre valores em strings e campos em strings
- São perfeitos pra representar objetos
- Exemplo, objeto usuário com vários campos como Nome, Sobrenome, Email...
HMSET user:1000 username antirez password P1pp0 age 34
HGETALL user:1000
HSET user:1000 password 12345
HGETALL user:1000- Extremamente performático, cada hash pode armazenar mais de 4 bilhões de campos
O quão rápido é o Redis?
Redis-Benchmark
Simulando 100mil requests
$ redis-benchmark -t set,lpush -n 100000 -q
Simulando 100mil requests
$ redis-benchmark -t set,lpush -n 100000 -q
SET: 74239.05 requests per second
LPUSH: 79239.30 requests per secondSimulando 100mil requests
$ redis-benchmark -t set,lpush -n 100000 -q
SET: 74239.05 requests per second
LPUSH: 79239.30 requests per second
Voltando ao uso do Redis como Cache....
Implementando um simples Redis Cache
Implementando um simples Redis Cache
Implementando um simples Redis Cache
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:sa@localhost/bancodedados2'
db = SQLAlchemy(app)
cache = redis.StrictRedis(host='localhost', port=6379, db=0)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80))
email = db.Column(db.String(120))
def __init__(self, username, email):
self.username = username
self.email = email
def __repr__(self):
return '<User %r>' % self.username
def createUsers():
with Timer(verbose=True) as t:
for x in xrange(0,100000):
user = User('teste', 'teste')
db.session.add(user)
db.session.commit()
def getUsers():
with Timer(verbose=True) as t:
users = cache.get('users')
if not users:
users = User.query.all()
cache.set('users', users)
@app.route('/')
def hello_world():
getUsers()
return 'Hello Worldd!'
if __name__ == '__main__':
app.debug=True
app.run(host='0.0.0.0')
O que irá acontecer?
1º Request: Buscar um número enorme de registros no MySQL e depois adicionar no Redis
1º Request: Buscar um número enorme de registros no MySQL e depois adicionar no Redis
Tempo para retornar os dados: 45861 millisegundos
2º Request: Usuário buscando os mesmo dados, dessa vez ele já está no Redis Cache
2º Request: Usuário buscando os mesmo dados, dessa vez ele já está no Redis Cache
Tempo para retornar os dados: 5 millisegundos
2º Request: Usuário buscando os mesmo dados, dessa vez ele já está no Redis Cache
Tempo para retornar os dados: 5 millisegundos

45861 millisegundos
->
5 millisegundos
45861 millisegundos
->
5 millisegundos
9172 vezes mais rápido que o acesso ao MySQL
Meu motivo para usar Redis!
Obrigado!
Redis
By Lucas Nascimento




