Deep learning

Fernanda Mora
ITAM
an overview
Content
- DL is hot: Facebook, Google and others
- What is deep learning?
- Available DL libraries
- Example and code
- Deep takeways
DL is hot:
Facebook, Google and others
Currently very hot regarding image processing, speech recognition and NLP



Facebook: people recognition without tagging
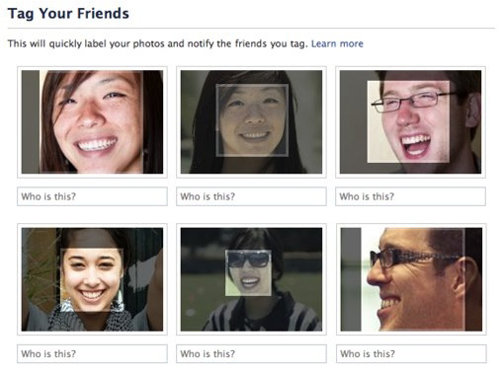

What is this?

Google Brain can recognize cats
The price?
1 billion neural connections, 16,000 computers over 3 days in youtube
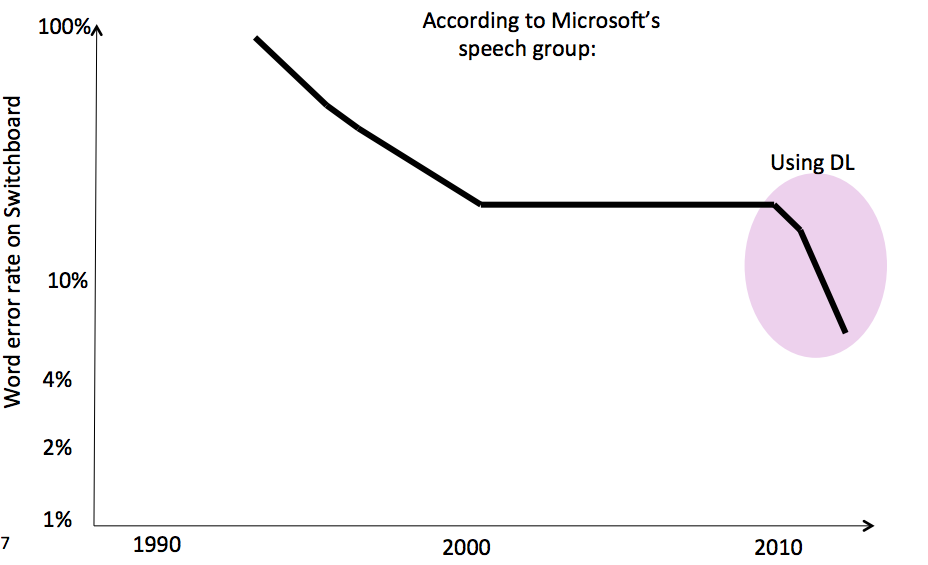
Example: DL has reduced word error rate
Example: Skype translator
Recent applications
Drug discovery: predict the biomolecular target of a compound/toxic effects
Customer relationship management: approximate the value of possible direct marketing actions over the customer state space
Energy forecasting: predict the demand of electric energy
What is deep learning?
¿What is deep learning?
Non-technical definition:
"Deep learning is a framework for training and modelling neural networks which recently have surpassed all conventional methods in many learning tasks, prominently image and voice recognition"
Batres-Estrada, 2015
¿What is deep learning?
Mid-technical definition:
"Set of algorithms that attempt to model high-level abstractions in data by using architectures of multiple non-linear transformations"
¿What is deep learning?
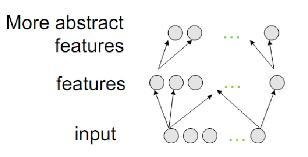
- Training neural networks with many layers
- Models high level abstractions of data
- Uses non-linear transformations
- Outperformed other methods for image and voice recognition
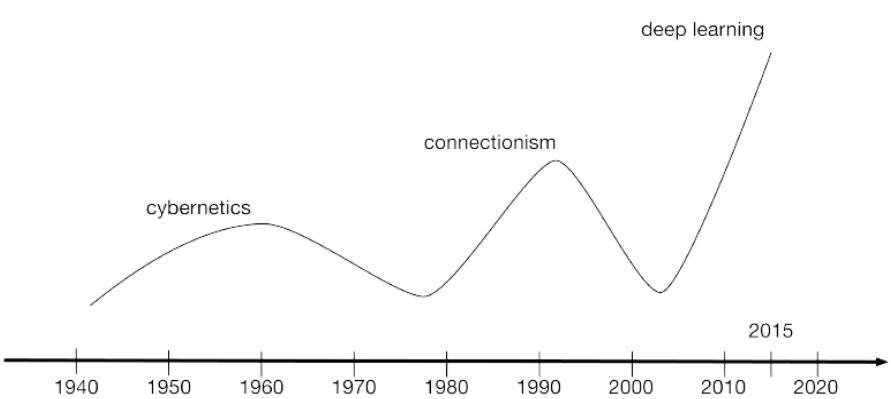
Is DL that new?
No, it goes back to 50's with neural networks
Single neuron training
Neural network training
(1-2 hidden layers)
2006
Very deep networks training
Cybernetics
Connectionism
Deep learning
DL is the modern artificial neural networks from 80's and 90's
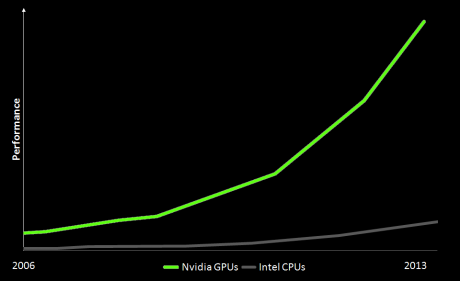
Why it has become so popular?
- Drastically increased chip processing abilities (e.g., general-purpose graphical processing units or GPGPUs)
- The significantly increased size of data used for training (BIG DATA)
- Recent advances in machine learning and signal/information processing research
GPUs recently increased its performance
Deep motivations:
AI, Machine and representation learning
- Computers are very efficient solving tasks that are difficult for us: process automatization, computing calculations, beating the best chess player.
- But are not that good performing tasks easy for us: face detection, voice recognition, translating, etc.
- Turing test: when can we say that a machine is intelligent?
- We are far from that now, but we have approaches to AI.
- One important approach is Machine Learning.
AI: How can we build more intelligent computers?
Motivation for Machine Learning
- Seems not efficient to write algorithms for each task we want to perform to analyze complex datasets.
- Increasing available data makes unfeasible to analyze every observation and every variable:
- "Every two days we create as much information as we did up to 2003" Erich Schmidt, Google, 2010.
- We need algorithms that learn from examples: Machine Learning.
Plenty of ML algorithms but rationale is the same: learn from data
- Regression, Classification, Clustering, dimensionality reduction
- Regression: plenty of examples!
- Classification: prediction of good/bad client
- Clustering: group similar individuals
- Dimensionality reduction: represent data in lower dimensions
- All of them can learn from data
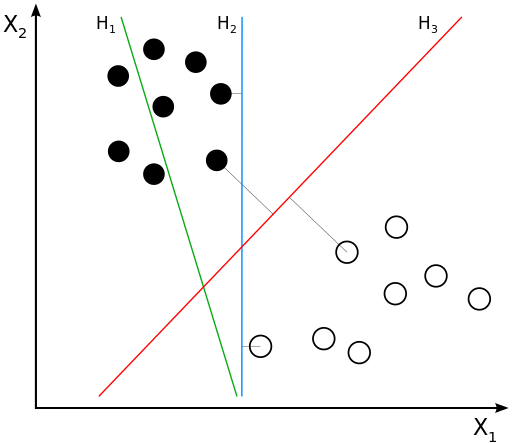
Example of a Support Vector Machine: separate data with hyperplane
H3 seems to be the best classifier. Why?
Plenty of goals
- Machine Learning and Statistical learning: Design efficient and accurate prediction algorithms
- Computer Science: consider Time and space complexity (Computer Science) -> can it be implemented?
- Machine learning: sample complexity? -> sample size required for the algorithm to learn something
- Optimization: best optimization techniques?
Is the algorithm useful?
Can it be implemented? Does it run fast?
Does it learn?
Does it converge?
Two common problems in ML: overfitting is one
- Overfitting: A statistical model describes random error or noise instead of the underlying relationship
- Crossvalidation, Regularization
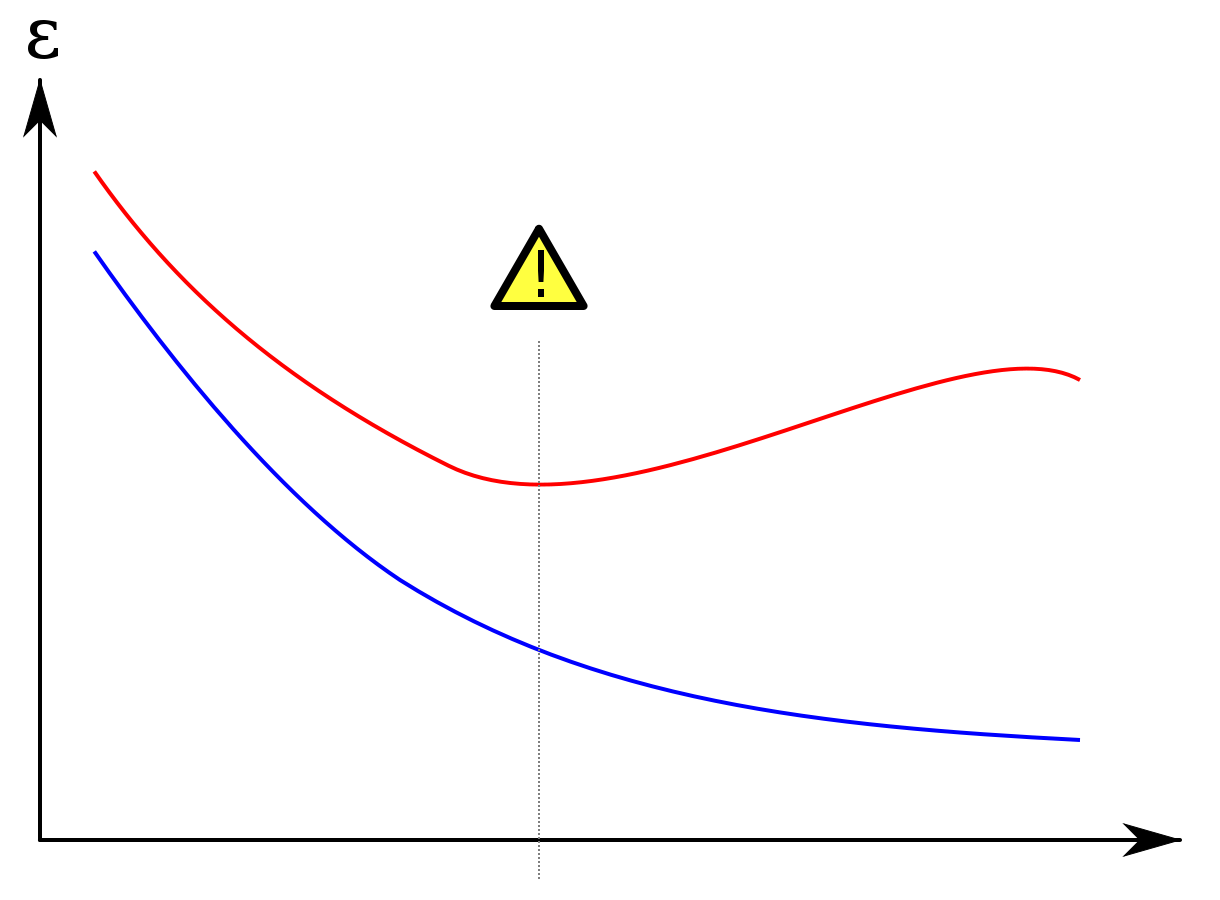
Training error
Validation error
Number of training circles
Overfitting with a neural network
Training error is optimistic!
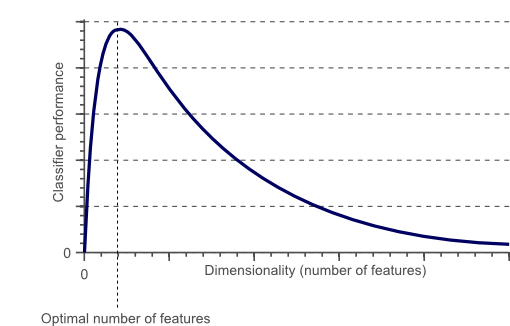
Two common problems in ML: curse of dimensionality is another
- Problems in high dimension arise
- When the dimensionality increases, the volume of the space increases so fast that the available data become sparse
- Dimension reduction techniques, feature learning
- Commonly we receive featured data: we are given observations with a set of measured outcomes.
- What if not?
Feature learning: using machine learning for feature design
- Logistic model to recommend or not cesarean delivery.
- Important feature is presence of uterine scar.
- Doctor enters relevant information to the computer and it decides whether or not to recommend the cesarian delivery.
- Suppose a 3D-MRI is given to the computer instead of the values of the attributes for a given woman. What will happen?
- Who decided those where the good attributes?
Example
- Hard, time consuming, requires knowledge
- Human brain does feature extraction -> difficult for computers
- Deep learning performs feature extraction for us :)
What is the problem with featured data?
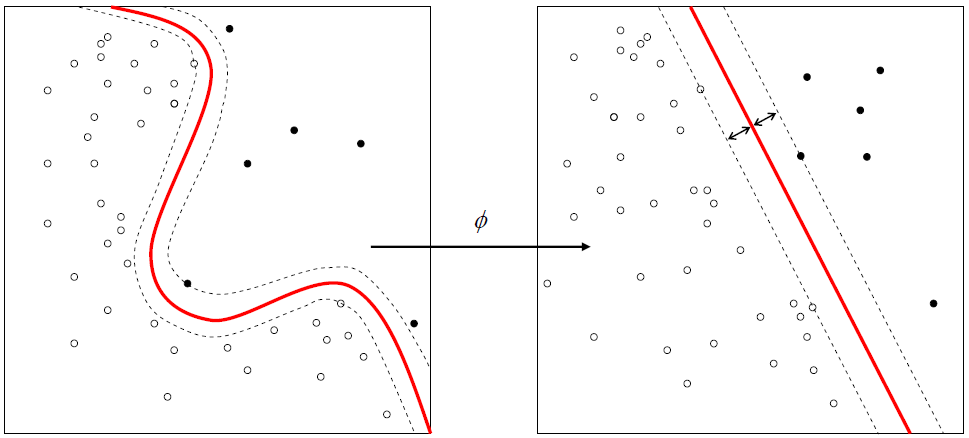
- Another example are kernel machines
-
Kernel machines are used to compute a non-linearly separable function into a higher dimension separable function.
-
The kernel finds the maximum-margin hyperplane in a transformed feature space.
Feature learning: kernel machines
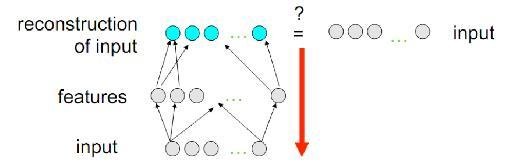
- Simple 3-layer neural network where output units are directly connected back to input units.
- Reconstruct its own input instead of output
Feature learning: autoencoder
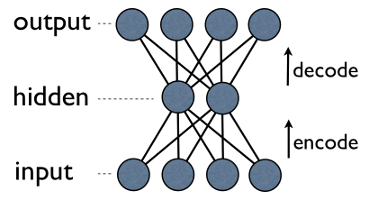
- Each Output has edge back to every input.
- Typically, number of hidden units is much less then number of visible (input/output) ones.
- As a result, when you pass data through such a network, it first compresses (encodes) input vector to "fit" in a smaller representation, and then tries to reconstruct (decode) it back.
- The task of training is to minimize an error or reconstruction, i.e. find the most efficient compact representation (encoding) for input data.
- Shares similar idea, but uses stochastic approach. Instead of deterministic it uses stochastic units with particular (usually binary of Gaussian) distribution.
- Learning procedure consists of several steps of Gibbs sampling (propagate: sample hiddens given visibles; reconstruct: sample visibles given hiddens; repeat) and adjusting the weights to minimize reconstruction error.
Feature learning: Restricted Boltzmann machine
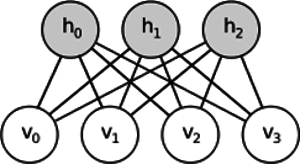
- Intuition behind RBMs is that there are some visible random variables (e.g. film reviews from different users) and some hidden variables (like film genres or other internal features), and the task of training is to find out how these two sets of variables are actually connected to each other.
-
Autoencoders
- The simplest ones.
- They are intuitively understandable, easy to implement and to reason about (e.g. it's much easier to find good meta-parameters for them than for RBMs).
-
RBMs
- Generative. That is, unlike autoencoders that only discriminate some data vectors in favour of others, RBMs can also generate new data with given joined distribution.
- They are also considered more feature-rich and flexible.
Feature learning: Autoencoder and RBM
Dimensionality reduction: PCA
- Dimensionality reduction: the process of redefining a dataset with n atributes (n-dimensional) into a data set with p attributes (p-dimensional) with p<n.
- Most famous: Principal Component Analysis (PCA).
- PCA finds "internal axes" of a dataset (called "components") and sorts them by their importance.
- Most important components are then used as new basis.
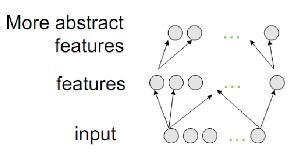
- Each of these components may be thought of as a high-level feature, describing data vectors better than original axes.
Dimensionality reduction: PCA graphically
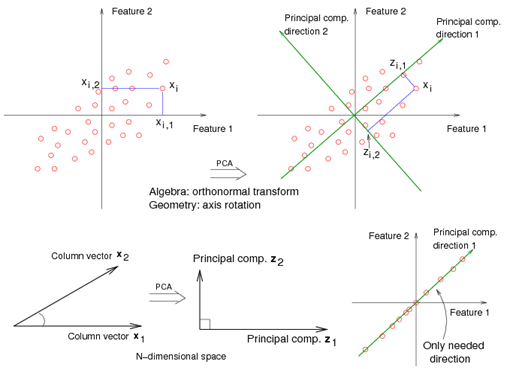
Autoencoders and RMBs do the same!
- Both - autoencoders and RBMs - do the same thing.
-
Taking a vector in n-
dimensional space they translate it into a p-dimensional one, p<n, trying to keep as much important information as possible and, at the same time, remove noise. - If training of autoencoder/RBM was successful, each element of resulting vector (i.e. each hidden unit) represents something important about the object - shape of an eyebrow in an image, genre of a film, field of study in scientific article, etc.
- You take lots of noisy data as an input and produce much less data in a much more efficient representation
Autoencoders and RMBs do the same!
Then why do we need them if PCA does the job??
Answer: PCA is restricted to linearity!
- Relationship between components and observations is always linear.
- PCA only represents vectors in the form where is one of the components found.
\sum_{n=1}^{m} \alpha_i c_i
c_i
m
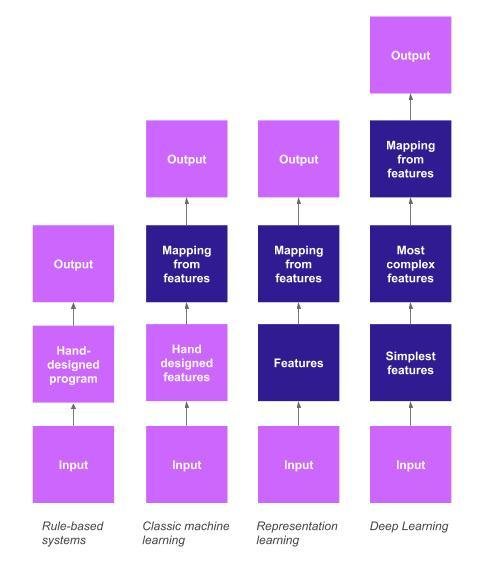
Set-theoretically, DL is like this:
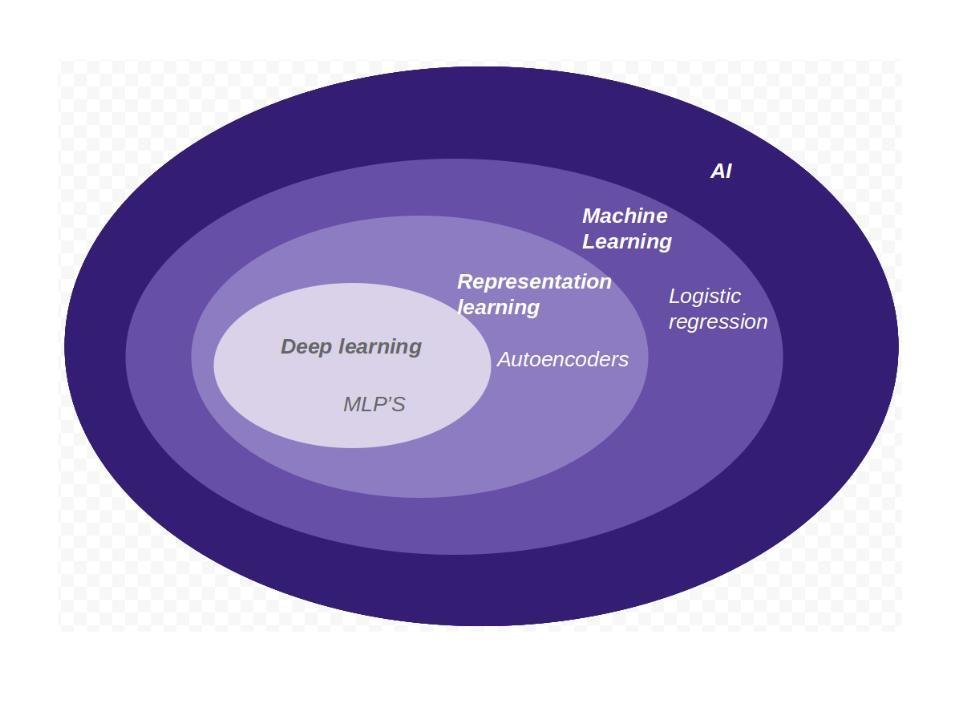
Based on its components, DL is like this:
Learning is involved
Is DL supervised or not supervised?
- Most common: yes/no attribute. spam/no spam, good/bad client, ill/healthy, etc.
- In general: classification and regression problems
- Goal is to predict something
- Pros: Very effective if you have lots of examples
- Cons: you need lots of labeled examples
Supervised learning: learning by labeled examples
Supervised learning: formal definition
Unsupervised learning: pattern discovering
- Data clustering
- Difficult in practice but useful if you don't have labeled examples
- We usually don't have many labeled data
Reinforcement learning, online learning, etc
- Reinforcement: feedback wrong/right
- Example: learning to play chess by winning or lossing
- Restricted applications but is gaining importance
Deep Learning is compatible with supervised, unsupervised and feature learning.
In fact, a normal path when implementing a DL algorithm is:
- unsupervised learning for feature learning
- supervised learning for machine learning algorithm
Deep learning uses unsupervised, supervised and feature learning
Deep architectures: how and when deep is good
Useful vs not useful information

No information
Noisy information, not useful

Useful information
but RAW
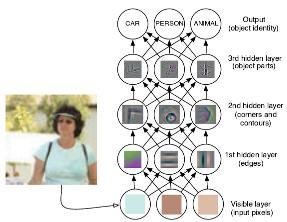
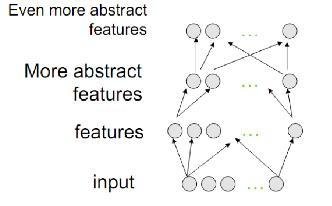
A DL algorithm (convolutional deep belief networks) will work like this:
1 layer neuron won't be able to extract the features!
Output (object identity)
3rd layer (object parts)
2nd layer
(corners and contours)
1st layer (edges)
Input layer (pixels)
What is not deep?
- Linear models -> by definition
- Neural nets with 1 hidden layer -> only 1 layer, no feature hierarchy
- SVMs -> 2 layers: kernel + linear
- Classification trees -> operate on original input space, no new features are generated
Gradient descent: a person stuck in the mountains
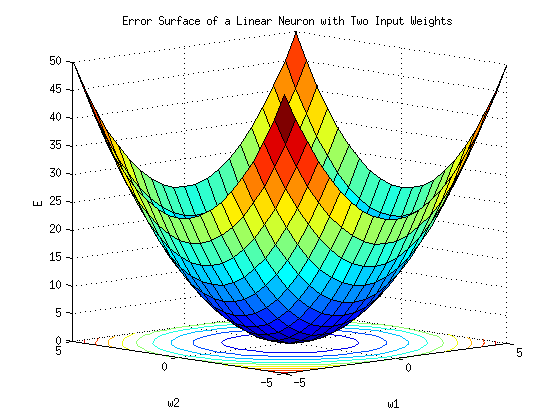

Person: backpropagation algorithm
Path: weights to minimize error
Steepness: slope of the mountain (differentiation)
Direction to go: Gradient of the error surface
Frequency of measurement: learning rate
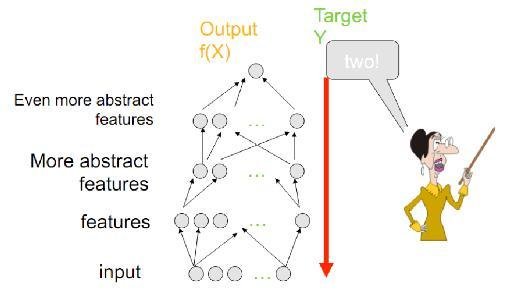
Backpropagation of errors
Calculates the gradient of a loss function with respect to all the weights in the network
Find a way to train a multi-layered neural network such that it can learn the appropriate internal representations to allow it to learn any arbitrary mapping of input to output
Output: optimized weights
Min choosing weights
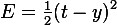
Backpropagation limitations
- Requires labeled training data: almost all data is unlabeled!
- Very slow in networks with multiple hidden layers
- Can get stuck in local minima

Deep neural networks
-
Standard learning strategy:
- Randomly initializing the weights of the network
- Applying gradient descent using backpropagation
-
But, backpropagation does not work well (if randomnly initialized)
- Deep networks trained with back-propagation (without unsupervised pre-training) perform worse than shallow networks
- ANN have limited to one or two layers
Deep belief networks
DBNs can be viewed as a composition of simple, unsupervised networks such as restricted Boltzmann machines (RBMs) or autoencoders (previously seen), where each sub-network's hidden layer serves as the visible layer for the next.
Deep belief networks
The training algorithm for DBNs proceeds as follows. Let X be a matrix of inputs, regarded as a set of feature vectors.
- Train a restricted Boltzmann machine on X to obtain its weight matrix, W. Use this as the weight matrix for between the lower two layers of the network.
- Transform X by the RBM to produce new data X', either by sampling or by computing the mean activation of the hidden units.
- Repeat this procedure with X ← X' for the next pair of layers, until the top two layers of the network are reached.
Unsupervised greedy layer-wise training procedure
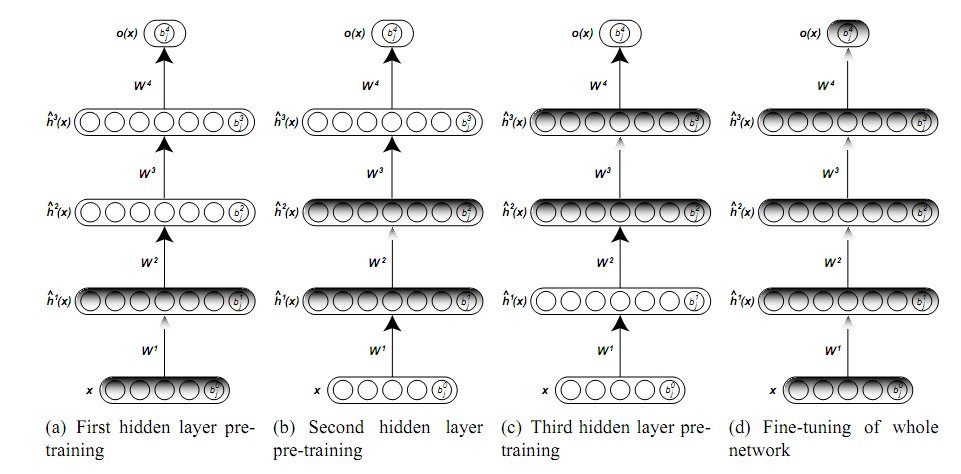
Layer-wise unsupervised pre-training

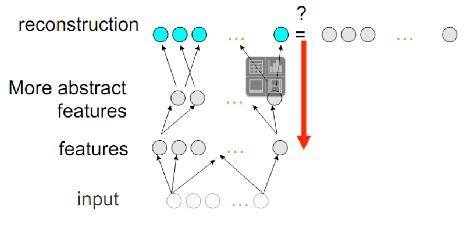
Then supervised fine-tuning
Backpropagation technique to fine-tune
Many deep learning architectures!
Deep neural networks
Deep belief networks
Convolutional deep belief networks
Deep Boltzmann machines
Deep k-networks
+
+
+
Deep learning is not suitable for all learning problems
Adam Gibson, creator of Deeplearning4j, a commercial-grade, open-source deep-learning library intended to be used in commercial settings:
"My advice is to use it for media (image, video, audio, text) and for time-series analysis (e.g., sensor data feeds)"
Deep learning is not suitable for all learning problems
Adam Gibson, on a conference about Deep Learning that took place in 2014:
One person in the audience asked about using it for fraud detection, Adam literally said something like, "I don't even want to see you here."
Available DL
libraries
-
Theano – CPU/GPU symbolic expression compiler in python (from MILA lab at University of Montreal)
- Torch – provides a Matlab-like environment for state-of-the-art machine learning algorithms in lua (from Ronan Collobert, Clement Farabet and Koray Kavukcuoglu)
- Caffe - deep learning framework made with expression, speed, and modularity in mind.Caffe is a deep learning framework made with expression, speed, and modularity in mind.
- Deeplearning4j - first commercial-grade, open-source, distributed deep-learning library written for Java and Scala.
Most popular libraries
Examples and code
Theano graphs
Interaction between instances of Apply (blue), Variable (red), Op (green), and Type (purple).
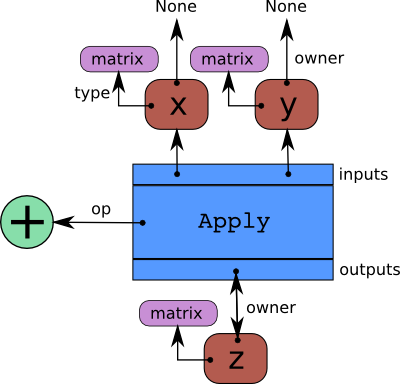
Theano optimizes graphs
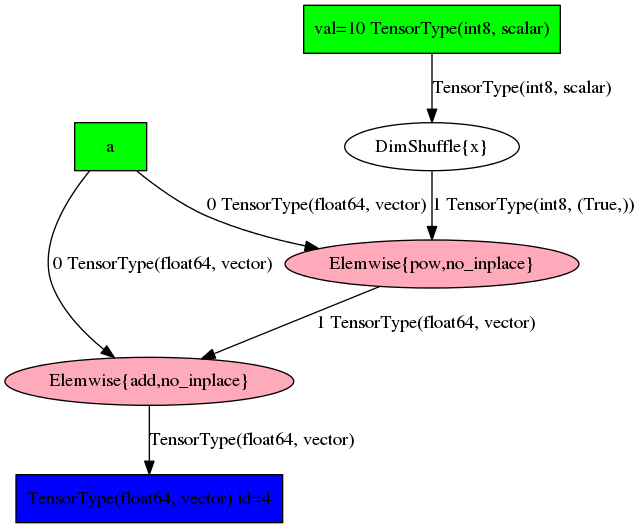
Theano identifies and replaces certain patterns in the graph with other specialized patterns that produce the same results but are either faster or more stable
x\frac{y}{x}
y
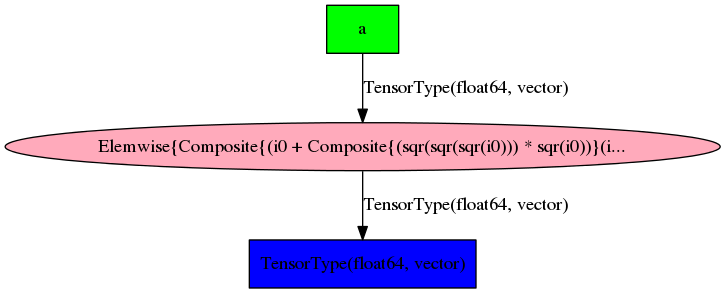
Graphs can grow complicated!
Graphs can grow complicated!
-
d3viz: Interactive visualization of Theano computed graphs
-
Instead of creating static output, it creates a dynamic file via a html file
Theano has functions to calculate gradient, hessian, jacobian
- Gradient, Hessian, Jacobian can via calculated via graphs
- These functions work symbolically: it receives and returns Theano variables.
- Work is in progress on the optimizations required to compute efficiently the full Jacobian and the Hessian matrix as well as the Jacobian times vector.
- General-purpose computing on graphics processing units (GPGPU) is the use of a graphics processing unit (GPU), which typically handles computation only for computer graphics, to perform computation in applications traditionally handled by the central processing unit
- One of Theano’s design goals is to specify computations at an abstract level, so that the internal function compiler has a lot of flexibility about how to carry out those computations. One of the ways we take advantage of this flexibility is in carrying out calculations on a graphics card.
- There are two ways currently to use a gpu, one of which only supports NVIDIA cards (CUDA backend) and the other, in development, that should support any OpenCL device as well as NVIDIA cards (GpuArray Backend)
Theano uses GPU to compute certain calculations
Complete tutorial for Theano: link
Downside: learning curve :(
Starting in Theano examples (very basic)
Theano tutorial
Paper: Ruslan Salakhutdinov, Hugo Larochelle ; Efficient Learning of Deep Boltzmann Machines.
NORB data set:
5 object categories, 5 difference objects within each category.
Classification error rate
Deep Boltzmann Machines : 10.8 %
Support vector machines : 11.6 %
Logistic Regression : 22.5 %
K-Nearest Neighbors : 18.4 %
Experiments
Experiment: MNIST data set
Exploring Strategies for Training Deep Neural Networks.
Hugo Larochelle, Yoshua Bengio, Jérôme Louradour, Pascal Lamblin; 10(Jan):1--40, 2009.
MNIST data set
- A benchmark for handwritten digit recognition
- The number of classes is 10 (corresponding to the digits from 0 to 9)
- The inputs were scaled between 0 and 1
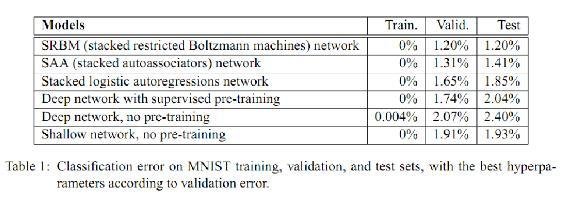
Model results
- Logistic regressor where instead of feeding the input to the logistic regression you insert an intermediate layer, called the hidden layer, that has a nonlinear activation function (usually tanh or sigmoid).
- One can use many such hidden layers making the architecture deep.
Multilayer Perceptron
- Idea: Stacking several RBMs on top of each other. The hidden layer of the RBM at layer i becomes the input of the RBM at layer i+1.
- The first layer RBM gets as input the input of the network, and the hidden layer of the last RBM represents the output. When used for classification, the DBN is treated as a MLP, by adding a logistic regression layer on top.
Deep Belief Networks
Deep takeaways
- Deep Learning : powerful arguments & generalization principles
- Unsupervised Feature Learning is crucial for many new algorithms and applications in recent years
- Deep Learning is suited for multi-task learning and domain adaptation
Reading list
Links to software
Datasets
Research groups and labs
Job listings
Tutorials and demos
Many online resources
Thank you!
Deep Learning
By Sophie Germain



