













Secret Sauce Partners, Inc.
Transforming apparel & footwear shopping through data.
Budapest Data Forum 2018
Gabor Ratky, CTO
Simple is better than complex.
Complex is better than complicated.
The Zen of Python, by Tim Peters
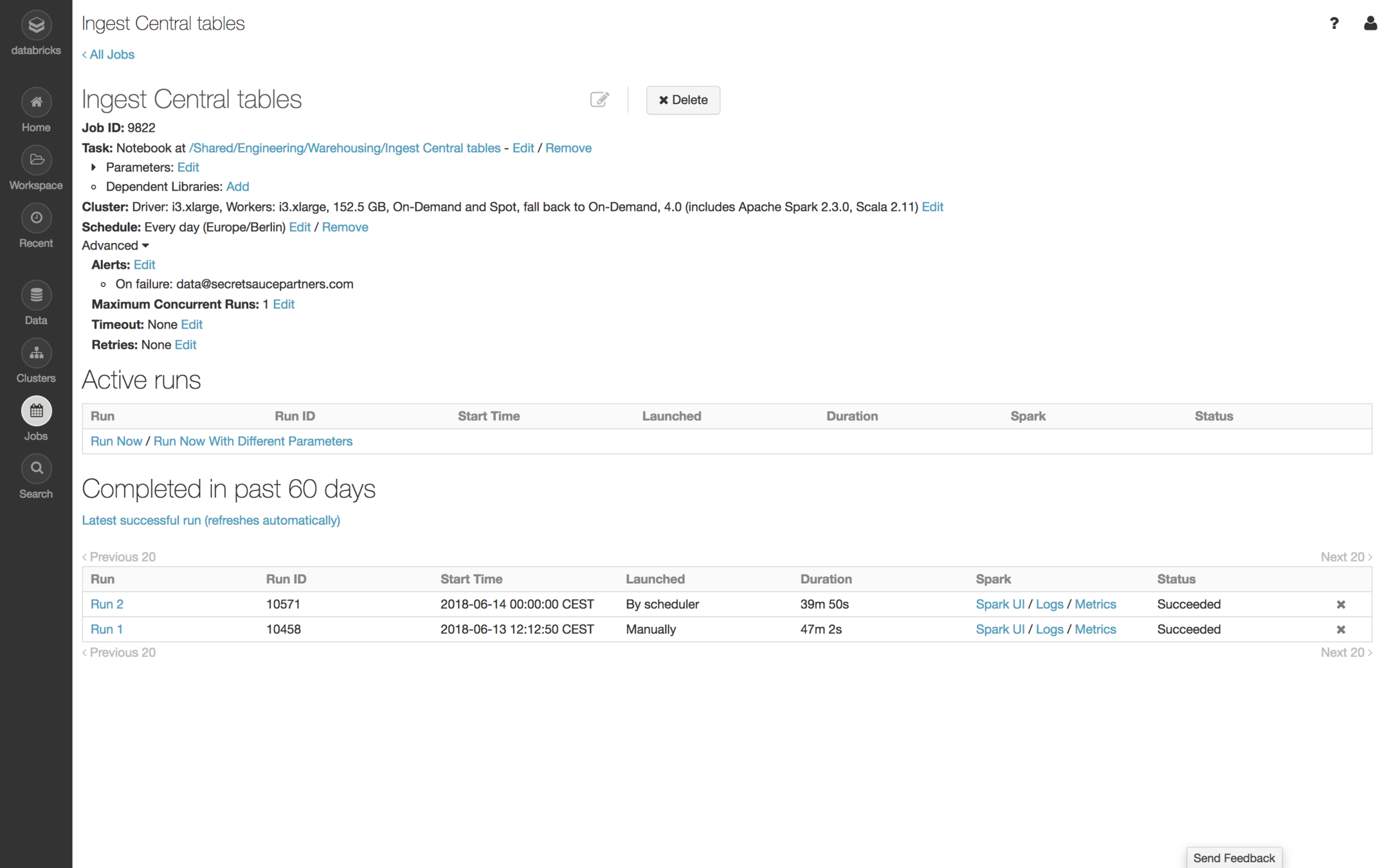
Partner data
MongoDB
$ mongoimportMongoDB
Redshift
S3
PostgreSQL
PostgreSQL
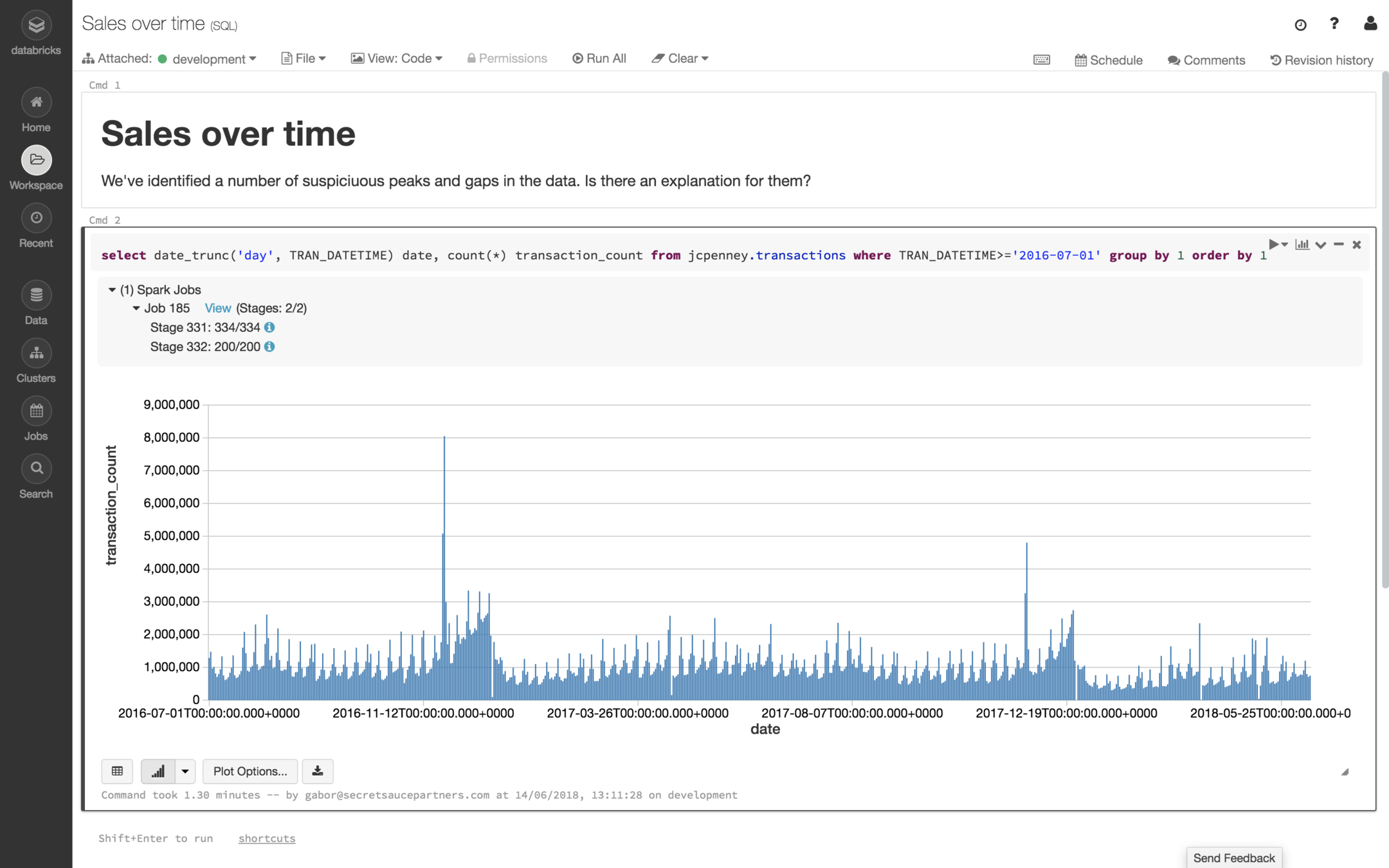
Partner data
kafka
kafka
MongoDB
Databricks
S3
PostgreSQL
PostgreSQL
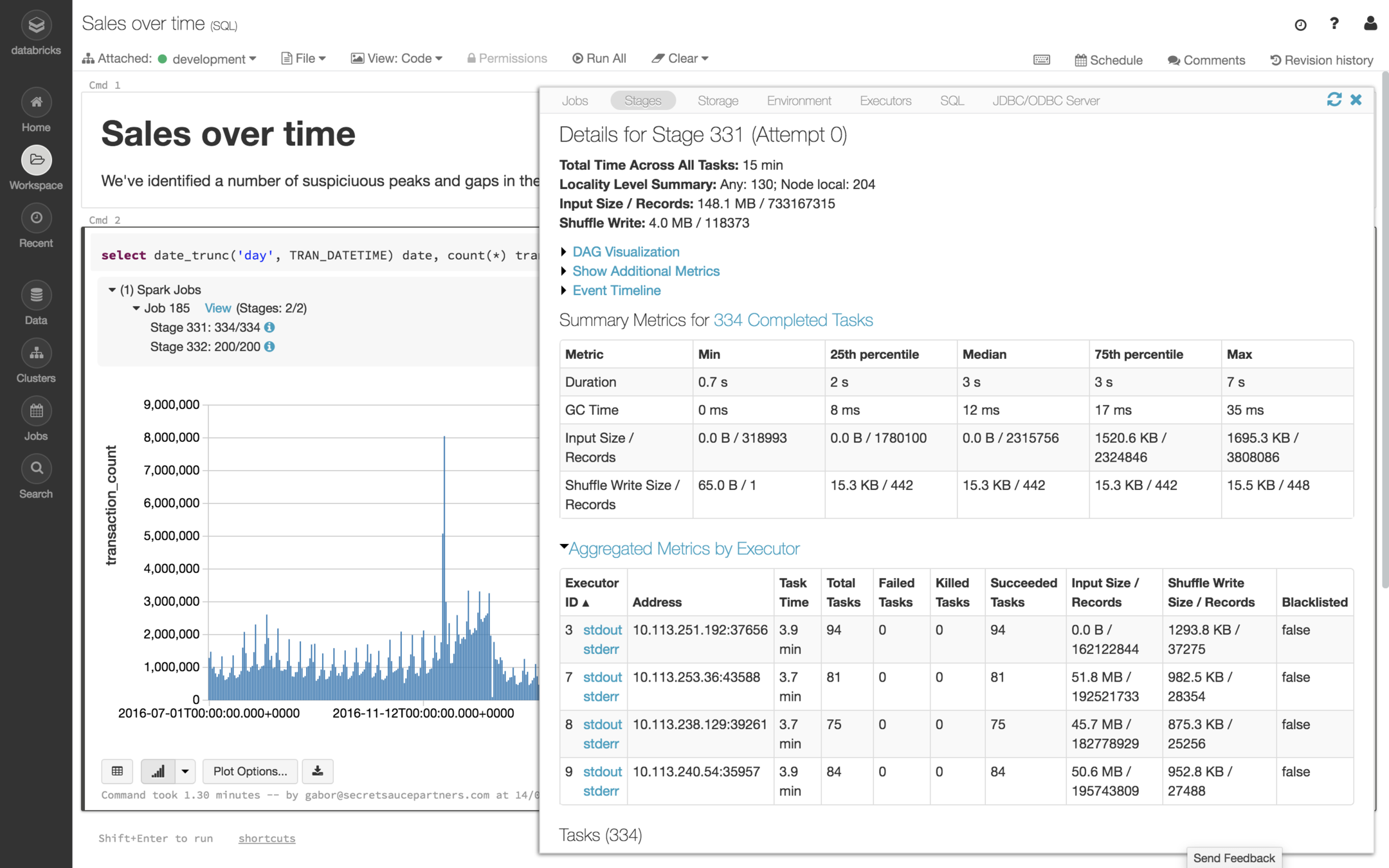
Partner data
kafka
kafka
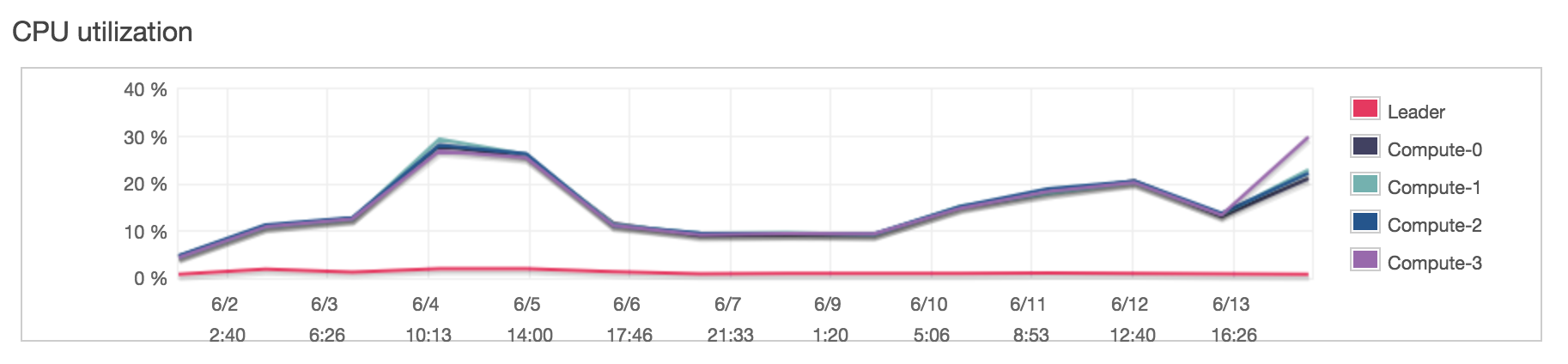
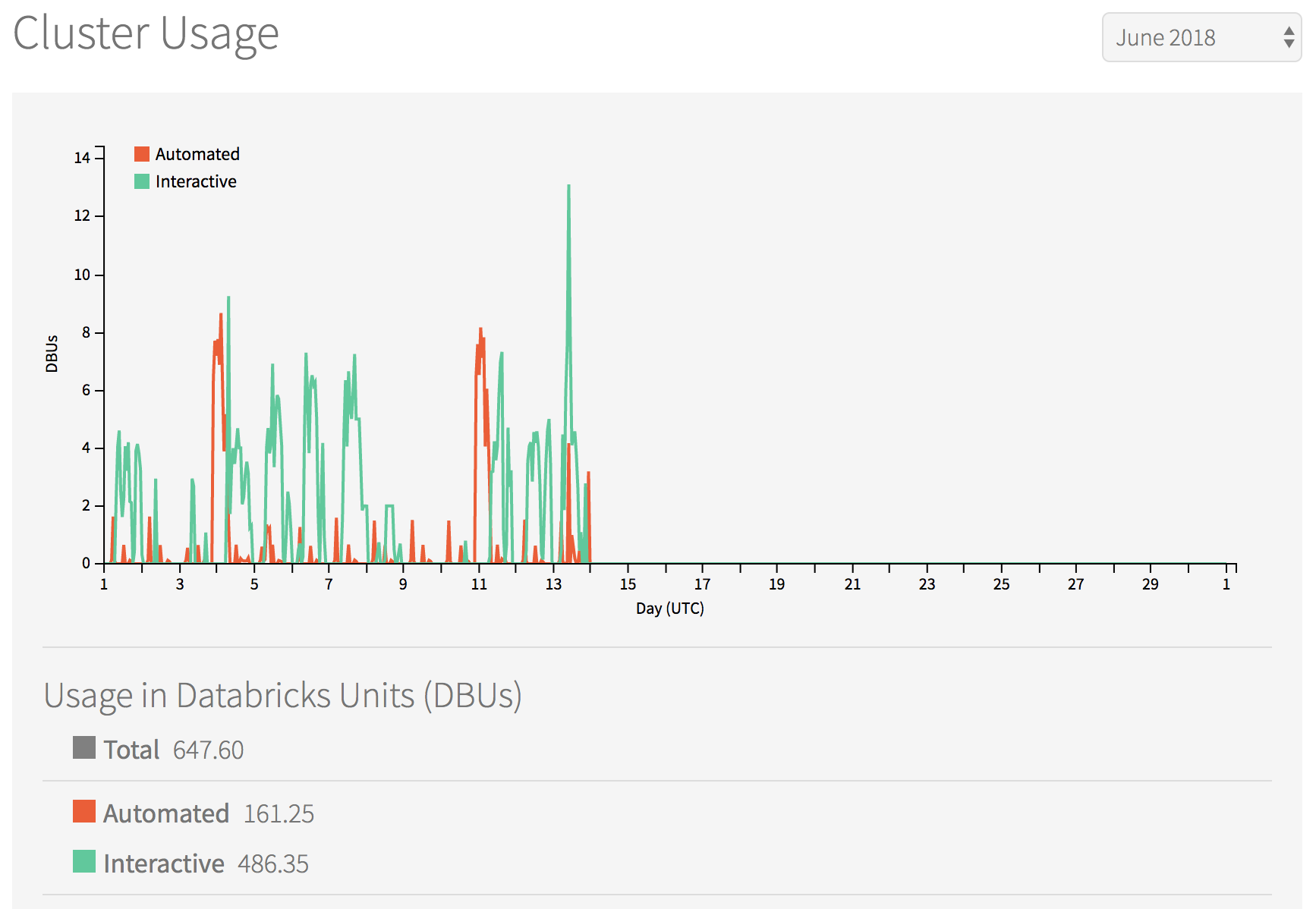
~34 DBU/day, ~4.5 DBU/hr
~11.5 DBU/day
* not invented here syndrome
Questions?
gabor@secretsaucepartners.com
By Secret Sauce Partners, Inc.
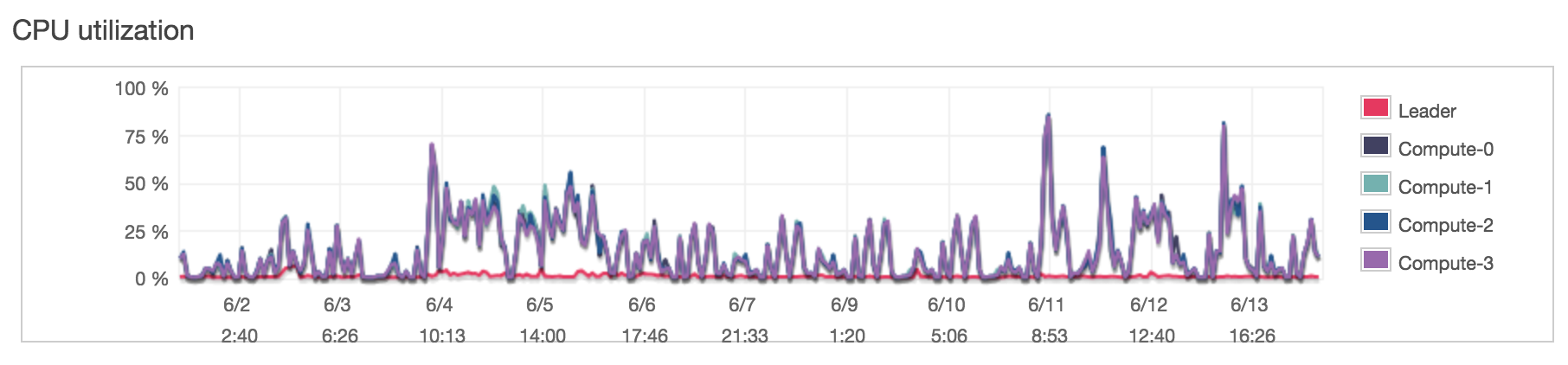
Why on Earth would you want to replace your data warehouse with a bunch of files lying around “in the cloud” and expect that everyone from engineers to data analysts and scientists will tap more into that data to power their analyses and their research and in general, do their work? Separating the storage of data from the computational work and giving everyone the right tool for their job within a single, coherent environment has made it easy for our engineers, analysts, data scientists, and even non-technical people to collaborate on and work with data. Working with data is hard. Far from the La La Land of Machine Learningstan and the United States of AI, there’s many of us who still need to deal with messy data, ETL, backfilling, failed jobs, inefficient SQL queries, overloading production databases, partitioning, and with the advent of cloud computing: unterminated Spark clusters and infrastructure cost. This talk is about how we tackled some of those challenges while building out our new data warehouse using S3 and Spark. This talk is for the rest of us.



