SESSION
Programming Rust
Edition 2021

Installation de RUST
rustup, rustc & cargo
Installation de Rust
cd $HOME
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sho installer le programme curl
o Choisir l'installation par défaut
La toolchain stable sera installée, 2 dossiers caches seront crées:
~/ .cargo
~/ .rustup
o Maintenant, ajouter les programmes rust au $PATH. Le compilateur RUST, les outils et les programme tiers seront désormais accessibles.
echo "source $HOME/.cargo/env" >> .bashrc
exec bashRustup permet de gérer les toolchains et d'obtenir aussi de la documentation sur Rust, qui est très complète.
Rustup
rustup toolchain install nightly2 toolchains principales
o stable
o nightly: fonctionnalités plus avancées mais qui peuvent changer, c'est a dire que le code doit être parfois modifié pour compiler après une mise a jour. Il arrive que des bugs soient présents mais c'est en général très rare.
o Installation de la toolchain nightly
o Il existe aussi une toolchain nommée beta
o Chaque toolchain existe pour différentes architectures
username@mordak-pc:~$ rustup show
Default host: x86_64-unknown-linux-gnu
rustup home: /home/username/.rustup
installed toolchains
--------------------
stable-x86_64-unknown-linux-gnu (default)
nightly-x86_64-unknown-linux-gnu
active toolchain
----------------
stable-x86_64-unknown-linux-gnu (default)
rustc 1.62.0 (a8314ef7d 2022-06-27)username@mordak-pc:~/Documents/x-exchange$ cat rust-toolchain
[toolchain]
channel = "nightly-2022-06-14"
# https://rust-lang.github.io/rustup-components-history/rustup updaterustup target add arm-linux-androideabrustup target add arm-linux-androideab
o Un projet peut avoir une toolchain spécifique différente de celles installées sur la session utilisateur.
o Accéder à la liste des versions nightly et leurs fonctionnalités

Et cela pour toutes les architectures supportées (Target)

rustup doco Accéder à la documentation de Rust (Toolchain & target par défaut)

o En savoir plus sur Rustup
Rustc est le compilateur Rust, l’équivalent de gcc pour le C. Dans la pratique, on ne l'utilise jamais directement, l'on préfère utiliser cargo.
Rustc
username@mordak-pc:~$ echo "fn main() { println!(\"Hello World\"); }" > main.rs
username@mordak-pc:~$ rustc main.rs
username@mordak-pc:~$ ./main
Hello World
username@mordak-pc:~$Cargo est au Rust ce que make est au C mais en bien mieux, il compile le programme et gère les dépendances. A la place du fichier Makefile, il utilise un fichier Cargo.toml, un fichier Cargo.lock est écrit par le cargo, ce dernier précise les versions de chaque dépendance.
Cargo
username@mordak-pc:/Documents/x-exchange$ cat Cargo.lock
# This file is automatically @generated by Cargo.
# It is not intended for manual editing.
version = 3
[[package]]
name = "addr2line"
version = "0.17.0"
source = "registry+https://github.com/rust-lang/crates.io-index"
checksum = "b9ecd88a8c8378ca913a680cd98f0f13ac67383d35993f86c90a70e3f137816b"
dependencies = [
"gimli",
]
[[package]]
name = "adler"
version = "1.0.2"
source = "registry+https://github.com/rust-lang/crates.io-index"
checksum = "f26201604c87b1e01bd3d98f8d5d9a8fcbb815e8cedb41ffccbeb4bf593a35fe"
...Cargo.toml
username@mordak-pc:/Documents/x-exchange$ cat Cargo.toml
[package]
name = "x-exchange"
version = "0.1.0"
authors = ["mordak & vcombey"]
edition = "2021"
[[bin]]
name = "x-server"
path = "x-server/main.rs"
[[bin]]
name = "ohlc-register"
path = "ohlc-register/main.rs"
[[bin]]
name = "client"
path = "client/main.rs"
[dependencies]
clap = "2.23.0"
lazy_static = "1.4.0"
unixcli = "0.1.3"
rustyline = "6.0.0"
chrono = "0.4.10"
log = "0.4.8"
colored = "2.0.0"
rust_decimal = { version = "1.25.0", features = ["serde-float"] }
lettre = "0.9.3"
regex = "1.4.1"
serde = { version = "1.0.117", features = ["derive"] }
serde_json = "1.0"
dotenv = "0.15.0"
dotenv_codegen = "0.15.0"
aes = "0.6.0"
block-modes = "0.7.0"
hex-literal = "0.3.1"
[features]
fake-token = ["kraken-rust-api/fake-token"]
[dependencies.reqwest]
version = "0.10.8"
features = ["blocking"]
[dependencies.kraken-rust-api]
path = "dependencies/kraken-rust-api"
[dependencies.ta]
path = "dependencies/ta-rs"
[build-dependencies]
[workspace]
members = [
"dependencies/kraken-rust-api","dependencies/ta-rs",
]
Les dépendances de [dependencies] se trouvent sur https://crates.io/
Premier programme
La magie de Cargo
On ne peut faire plus simple...
username@mordak-pc:~$ cargo new premier_programmeusername@mordak-pc:~$ cd premier_programme/
username@mordak-pc:~/premier_programme$ ls -lR
.:
total 8
-rw-r--r-- 1 username username 186 Jul 2 00:30 Cargo.toml
drwxr-xr-x 2 username username 4096 Jul 2 00:30 src
./src:
total 4
-rw-r--r-- 1 username username 45 Jul 2 00:30 main.rs
Il suffit d'utiliser la commande cargo new avec en argument le nom du programme.
Cargo a écrit tous les fichiers nécessaires au projet.
Il n'y a pas de fichier Cargo.lock car pour l'instant, nous n'utilisons aucune dépendance.
On ne peut faire plus simple...
username@mordak-pc:~/premier_programme$ cat Cargo.toml
[package]
name = "premier_programme"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
fn main() {
println!("Hello, world!");
}
Le fichier main.rs du dossier /src contient déjà son Hello World.
Quand au fichier Cargo.toml, il contient le minimum.
On ne peut faire plus simple...
username@mordak-pc:~/premier_programme$ cargo build
Compiling premier_programme v0.1.0 (/home/username/premier_programme)
Finished dev [unoptimized + debuginfo] target(s) in 0.56so Compiler le programme:
o Exécuter le programme:
username@mordak-pc:~/premier_programme$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/premier_programme`
Hello, world!Notez que Cargo run compile puis exécute, il n'y a pas besoin de build explicitement si c'est seulement pour l’exécution.
o Notez aussi que le 'profile' de compilation utilise ici (par défaut) est celui de debug, pour les versions de production, l'on utilisera le profil release.
username@mordak-pc:~/premier_programme$ cargo run --release
Finished release [optimized] target(s) in 0.00s
Running `target/release/premier_programme`
Hello, world!On ne peut faire plus simple...
username@mordak-pc:~/premier_programme$ cargo doc --openo Enfin, il est possible de générer la propre documentation de son programme:
La documentation sera ouverte dans le navigateur Web par défaut, cargo doc tout court la généré et --open l'affiche directement.
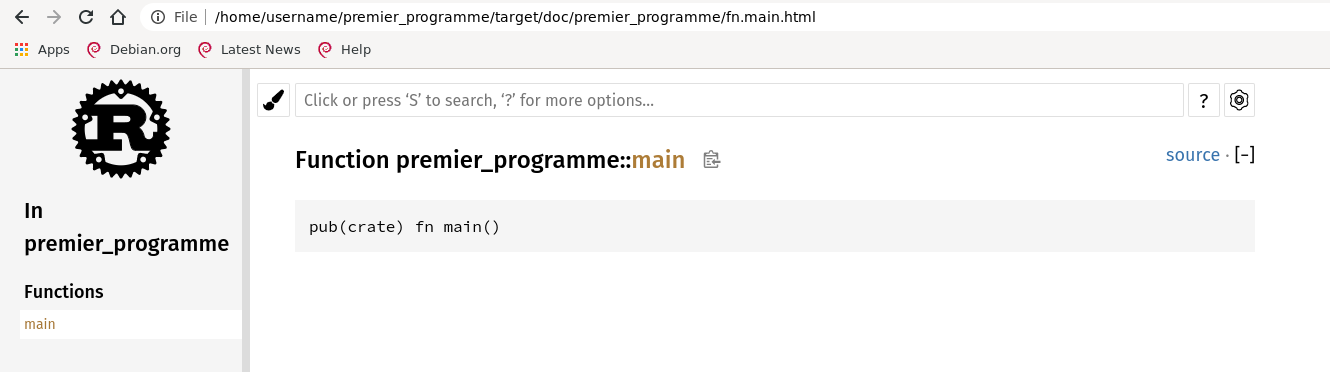
On ne peut faire plus simple...
o Maintenant, commentons notre code:
/// La fonction principale de mon programme
fn main() {
// Write to stdout
println!("Hello, world!");
}
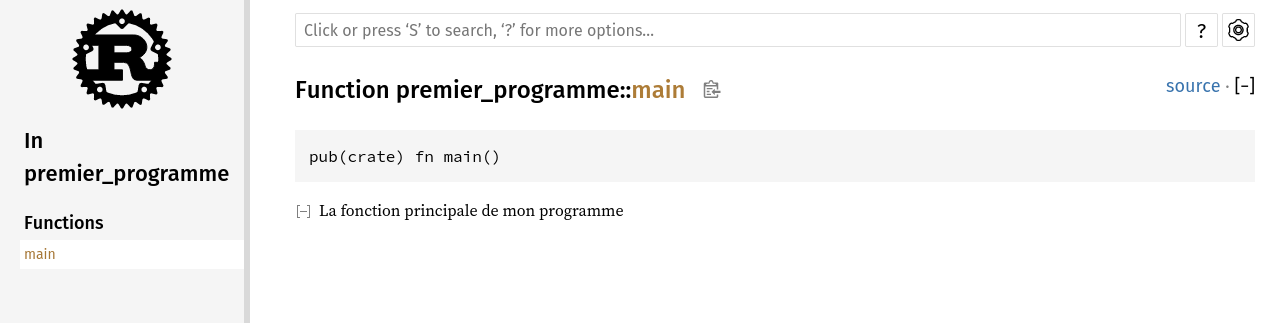
On ne peut faire plus simple...
Comme nous pouvons l'observer, les commentaires composs de 3 slashs ont été écrits dans la documentation du programme. A contrario, ceux avec deux slashs ne serviront qu'à préciser quelque chose qui restera uniquement dans le code.
fn main() {
// Write to stdout
println!("Hello, world!");
/*
Ce est
un commentaire
multiligne
*/
}o Il existe aussi evidement des commentaires multi-lignes.
o D'autres types de commentaire existent, dont un qui est souvent utilisé //!
Ce lien donne tous les exemples.
o Il existe aussi evidement des commentaires multi-lignes.
o Il existe aussi évidement des commentaires multi-lignes.
On ne peut faire plus simple...
Enfin, il existe un autre outil de cargo qui est cargo-fmt, il permet de formater le code selon soit la norme Rust par défaut, soit une norme que nous avons définie dans le fichier rustfmt.toml. Notez que Rust par défaut utilise des tabulations de 4 espaces !
mordak@mordak-pc:~/Documents/KFS/rust_kernel$ cat rustfmt.toml
max_width = 120Il suffit d'utiliser la commande cargo-fmt pour lancer le formatage du code.
mordak@mordak-pc:~/premier_programme$ cat -e src/main.rs
//! La fonction principale de mon programme$
fn main() {$
// Write to stdout$
println!("Hello, world!"); $
}$
mordak@mordak-pc:~/premier_programme$ cargo-fmt
mordak@mordak-pc:~/premier_programme$ cat -e src/main.rs
//! La fonction principale de mon programme$
fn main() {$
// Write to stdout$
println!("Hello, world!");$
}$Les dépendances
Utilisation d'une crate
La crate colored
Une crate est un binaire ou une bibliothèque, elles sont répertoriées sur le site https://crates.io. Il y a toutes les contributions de la communauté Rust, chacun peut créer des crates et les y diffuser. Il n'est cependant pas nécessaire de diffuser une de ses propres crate pour pouvoir l'utiliser, on se contentera dans ce cas de la mettre en dépendance directement dans le code source du programme., nous reviendrons plus tard sur la notion de workspace. Ici pour l'exemple, nous allons utiliser la crate colored de crate.io afin que notre Hello World puisse prendre quelques couleurs.
[dependencies]
colored = "2.0.0"o Première chose à faire, modifier le fichier Cargo.toml, l'on rajoute la dépendance et sa version dans la catégorie [dependencies]:
La crate colored
Elle sera téléchargée lors de notre prochain cargo build
mordak@mordak-pc:~/premier_programme$ cargo build
Updating crates.io index
Compiling libc v0.2.126
Compiling lazy_static v1.4.0
Compiling atty v0.2.14
Compiling colored v2.0.0
Compiling premier_programme v0.1.0 (/home/mordak/premier_programme)
Finished dev [unoptimized + debuginfo] target(s) in 16.05sCargo s'est aussi chargé de lui-même de télécharger les dépendances de la crate.
La crate colored
Faisons maintenant un tour dans la documentation. cargo doc --open
Cargo s'est aussi charge de lui meme de telecharger les dependances de la crate
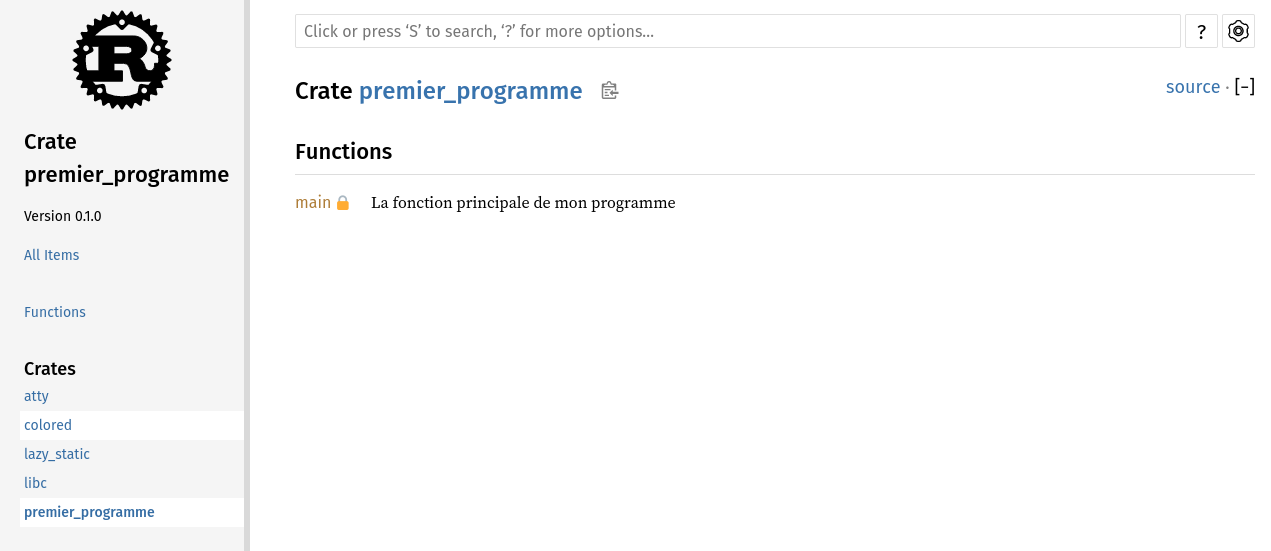
Text
La documentation de la crate colored est désormais accessible.
La crate colored
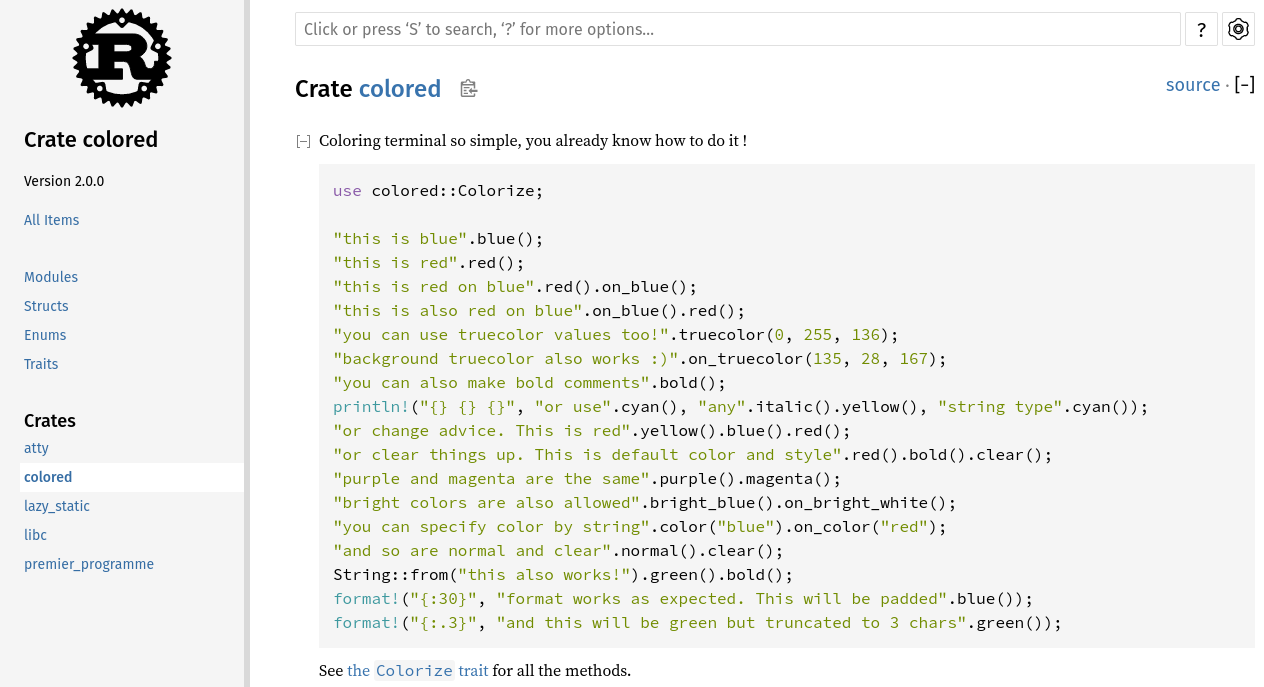
Grace à la documentation, on apprend facilement comment utiliser la crate.
La crate colored
use colored::Colorize;
/// La fonction principale de mon programme
fn main() {
// Write to stdout
println!("{}", "Hello, world!".cyan());
}
Ici, l'exemple le plus proche de ce que nous voulons est ceci:


Si l'on reporte ces modifications dans notre code, cela donnerait ceci

Exécutons
Les tests unitaires
cargo test ou comment s'assurer du bon fonctionnement de son programme
Les tests unitaires
fn fibo(n: u32) -> u32 {
n
}
fn main() {
}
#[cfg(test)]
mod test {
use crate::fibo;
#[test]
fn check_fibonacci() {
assert_eq!(fibo(1), 1)
}
}o D'abord nous allons créer un nouveau programme nomme fibonacci.
mordak@mordak-pc:~$ cargo new fibonacci
Created binary (application) `fibonacci` packageo Ensuite, modifier le fichier main.rs comme tel
Les tests unitaires
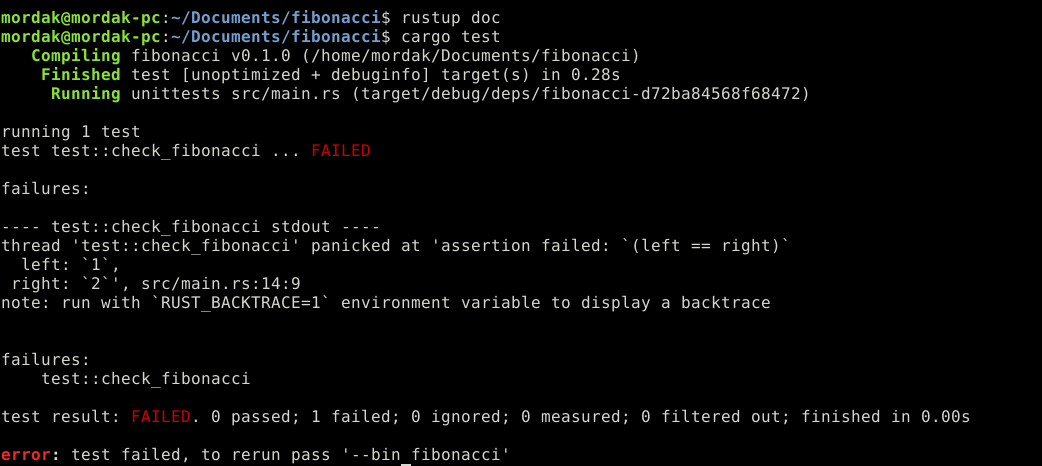
o La commande cargo test donne ceci:
mordak@mordak-pc:~/Documents/fibonacci$ cargo test
Compiling fibonacci v0.1.0 (/home/mordak/Documents/fibonacci)
Finished test [unoptimized + debuginfo] target(s) in 0.27s
Running unittests src/main.rs (target/debug/deps/fibonacci-d72ba84568f68472)
running 1 test
test test::check_fibonacci ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00sLes tests unitaires
fn fibo(n: u32) -> u32 {
n
}o u32 est un type primitif encode sur 32 bits et positif.
o En rust, lorsque l'on déclare une variable, on déclare d'abord l'identifiant puis ensuite le type, d’où le n: u32 !
o La flèche -> indique le retour de la fonction suivi du type
o Il est souvent inutile d'utiliser le mot clef return, bien qu'il existe.
Les tests unitaires
#[cfg(test)]
mod test {
use crate::fibo;
#[test]
fn check_fibonacci() {
assert_eq!(fibo(1), 1)
}
}o #[cfg(test)] ne s’exécutera qu'à l'invocation de la commande cargo test.
o On doit créer un sous-module pour les tests.
o Ici, crate dans crate::fibo fait référence au projet lui-même, et la fonction fibo en est a la racine. on aurait pu utiliser super à la place étant donné la hiérarchie du module. Le sous-module n'a pas accès directement a la fonction fibo, d’où l'importation.
Les tests unitaires
#[cfg(test)]
mod test {
use crate::fibo;
#[test]
fn check_fibonacci() {
assert_eq!(fibo(1), 1)
}
}o assert_eq! est une macro Rust de la STD, elle fonctionne comme une assertion en C, eq signifie équivalent et vérifie si l'expression de droite et de gauche sont égales.
o En outre, il existe aussi assert_ne! qui fait le contraire.
Les tests unitaires
#[test]
fn check_fibonacci() {
assert_eq!(fibo(1), 2)
}o Si l'assertion est au contraire fausse le programme va 'paniquer', il stop et explique pourquoi.
Les types de base
Et plusieurs notions de Rust
Les types numériques
NB: Les types f80 et f128 n'existent pas en Rust pour des raisons de portage de code entre les différentes architectures.
let a: u32 = 42;
let b: i64 = -127;
let c: isize = -128;
let pi: f32 = std::f32::consts::PI;
let pi: f64 = std::f64::consts::PI;| unsigned | signed | float | representation |
|---|---|---|---|
| u8 | i8 | 8 bits | |
| u16 | i16 | 16 bits | |
| u32 | i32 | f32 | 32 bits |
| u64 | i64 | f64 | 64 bits |
| u128 | i128 | 128 bits | |
| usize | isize | cpu register size |
Les booléens
Aucune réelle surprise dans les conditions.
let b: bool = false;
let c: bool = true; let b: bool = 0;
let c: bool = 1; let mut b: bool = false;
if !b {
println!("B is false");
}
b = true;
if b {
println!("B is true");
}
let c: bool = true;
if b & c {
println!("B and C are true")
}Les caractères
let c: char = 't';
println!("len: {} - {}", c.len_utf8(), c);
let c: char = 'ф';
println!("len: {} - {}", c.len_utf8(), c);
let c: char = '錆';
println!("len: {} - {}", c.len_utf8(), c);len: 1 - t
len: 2 - ф
len: 3 - 錆format UTF8 pour les caractères en Rust
Les couples (Tuples)
fn mul(n: (u32, f64), e: u32) -> (u32, f64) {
(n.0 * e, n.1 * e as f64)
}
let g = mul((42, std::f64::consts::PI), 2);
dbg!(g);[src/main.rs:60] g = (
84,
6.283185307179586,
)Un couple est une collection de différents types, on utilisera une parenthèse.
NB: L’accès aux éléments d'un tuple avec le .n peut être source de beaucoup d'erreurs surtout si les types contenus sont identiques, certains programmeurs évitent au maximum le recours aux tuples.
La macro dbg! permet d'afficher les champs d'une variable facilement.
Type ou l’équivalent de Typedef en C
type Tuple = (u32, f64);
fn mul2(n: Tuple, e: u32) -> Tuple {
(n.0 * e, n.1 * e as f64)
}
let g = mul2((42, std::f64::consts::PI), 2);
dbg!(g);Tout comme en C, il est possible de nommer ses propres alias de type.
let g = mul2(Tuple(42, std::f64::consts::PI), 2);
dbg!(g);
Cependant, les alias de type ne sont pas des constructeurs.

NB: Généralement le compilateur Rust devine bien ce que l'on a tenté de faire !
Introduction a l’inférence de type
// Les types ne sont pas declares ici
let mut a = (42, 1.25);
fn mul3(n: (u32, f64), e: u32) -> (u32, f64) {
(n.0 * e, n.1 * e as f64)
}
a = mul3(a, 2);
dbg!(a);Il ne sert à rien de déclarer tous les types a Rust car le compilateur tentera de découvrir par lui-même quels sont les types utilisés. C'est assez trivial quand on appelle une fonction qui prend un type donne en argument par exemple.
Le compilateur devine que mon tuple a pour type (u32, f64).
Introduction a l’inférence de type
Cependant, si je rajoute cette fonction à mon code:
fn mul4(n: (u32, f32), e: u32) -> (u32, f32) {
(n.0 * e, n.1 * e as f32)
}
a = mul4(a, 2);
dbg!(a);
Le compilateur ne comprendra plus si mon type est (u32, f64) ou bien (u32, f32)...
La mutabilité
Certaines variables ont été déclarées avec le mot clef mut et d'autres non. Il est en fait obligatoire de signaler à Rust si une variable peut changer de valeur en cours de route. La raison ?
Aider le programmeur à bien comprendre ce qu'il fait et lui éviter bon nombre d'erreurs.
La mutabilité
let a: u32 = 42;
a += 1; let mut a: u32 = 42;
dbg!(a);
return;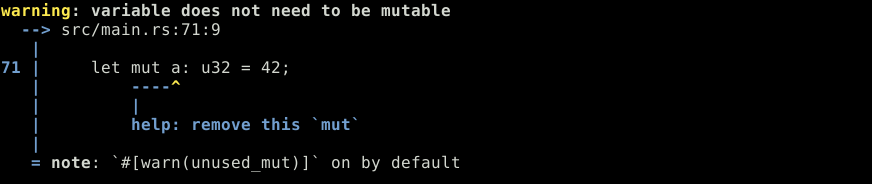
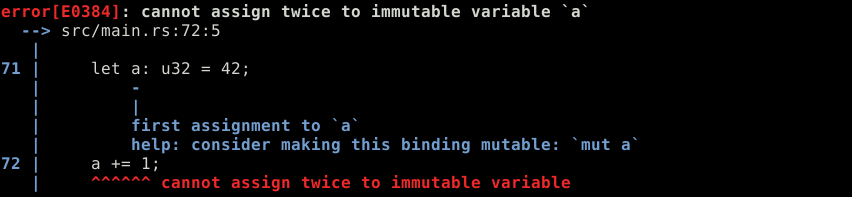
La variables globales
static PORT1: u32 = 8080;
const PORT2: u32 = 8443;
fn dump_ports() {
println!("Port1: {}", PORT1)
println!("Port2: {}", PORT2)
}Port1: 8080
Port2: 8443Il existe deux types de variables globales, les constantes et les mutables, Rust les traitera de façon très différente.
o Constantes:
Elles peuvent se déclarer via deux mots clef, soit static soit const, sans entrer dans les détails, static représente un endroit en mémoire et const non.
La variables globales
static mut PORT: u32 = 8080;
fn change_port() {
PORT = 8443;
}Port1: 8080
Port2: 8443o Mutables:
On les déclare via les mots clefs static mut.

Ça ne compile pas...
Pourquoi le compilateur demande d’écrire un bloc unsafe ?
La variables globales
static mut PORT: u32 = 8080;
fn change_port() {
unsafe {
PORT = 8443;
}
}La raison est décrite dans l'erreur:
note: mutable statics can be mutated by multiple threads: aliasing violations or data races will cause undefined behavior
Plusieurs threads peuvent accéder en même temps à cette variable et provoquer des comportement indéfinis. Même si le programme ne possède qu'un seul thread, le compilateur ne laissera pas le code compiler sans le mot clef unsafe.
Rust est un langage dit concurrent, son compilateur veille à ce qu'il n'y ait pas de problème entre les ressources utilisées par plusieurs threads.
Ici, marquer unsafe permet au programmeur de vite comprendre qu'il peut y avoir un problème ici si son programme bug. Un Mutex réglerait le problème.
Le trait Copy
let a = true;
let b = a;
dbg!(a);
dbg!(b);
let a = (std::f32::INFINITY, std::f32::INFINITY);
let b = a;
dbg!(a);
dbg!(b);Notons aussi que tous ces types de base implémentent le trait Copy. C'est à dire que les valeurs peuvent être aisément dupliquées entres plusieurs variables.

Les traits Copy et Clone
let banane: String = "Banane".into();
let deuxieme_banane = banane;
dbg!(banane);
dbg!(deuxieme_banane);Si au contraire, l'on tente d'utiliser un type plus complexe comme String par exemple. Ce type est dynamiquement alloué en mémoire (sur le tas) et n’implémente pas le trait Copy. Une conséquence fâcheuse à cela serait de gaspiller de la mémoire sans que le programmeur ne s'en rendre vraiment compte.

A la seconde ligne, la variable banane n'a pas été copiée, c'est un move, cette première variable ne possède plus l'objet banane, qui en fait, passe sur la variable deuxieme_banane. Il n'y a pas eu de copie.
Les traits Copy et Clone
let banane: String = "Banane".into();
let deuxieme_banane = banane.clone();
dbg!(banane);
dbg!(deuxieme_banane);Notons qu'il n'y aurait pas eu de problème dans le code si on n'avait plus tenté de lire la variable banane d'origine. Si l'on veut forcer la copie, quitte à prendre le risque de gaspiller un peu de mémoire, l'on doit explicitement utiliser le trait Clone. Le type String implémente Clone.
Rechercher std::clone::Clone dans le documentation
Le trait Clone nécessite la méthode clone()
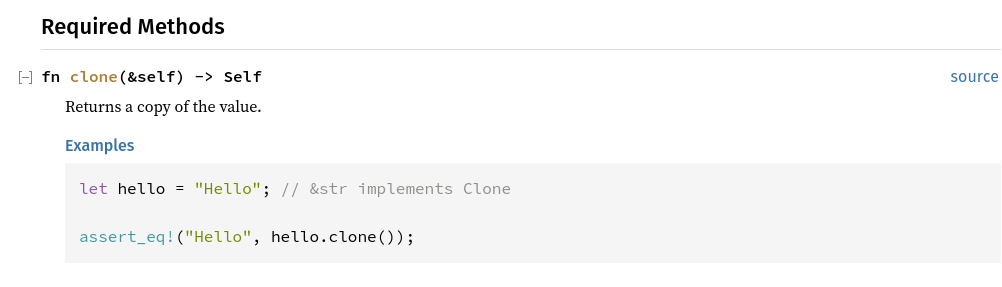
Le trait Clone
#[derive(Clone)]
struct Remote {
ipv4: (u8, u8, u8, u8),
port: u32,
server_name: String,
}
let r1 = Remote {
ipv4: (192, 168, 41, 1),
port: 8080,
server_name: "xp6".into(),
};
let r2 = r1.clone()La méthode clone() est dans la partie nommée Required Methods. Pourquoi required ? Cela veut dire que tout objet qui veut implémenter le trait Clone doit définir la méthode clone(). Dans de très rares cas, le programmeur doit implémenter ce trait manuellement bien que normalement, il puisse utiliser la directive #[derive(Clone)] pour ses propres structures.
Sans le derive, la structure Remote ne serait pas clonable. Et le derive ne fonctionne que si tous les sous types de la structures implémentent Clone.
Le trait Clone
Enfin TOUT ce qui est implémente Copy implémente aussi Clone. Il est aussi possible de cloner explicitement les types de base mais ça ne sert a rien.

* L’implémentation du trait Clone est nécessaire pour le trait Copy.
On a fait le tour des types de base en Rust, on ne pouvait pas éviter d'aborder certains concepts du langage car le maniement de ces types mêmes simples demande de comprendre un peu ces concepts.
If else et les boucles
Conditions et répétitions
if et else
fn main() {
let n: u32 = 11 - 3;
if n == 8 {
println!("8");
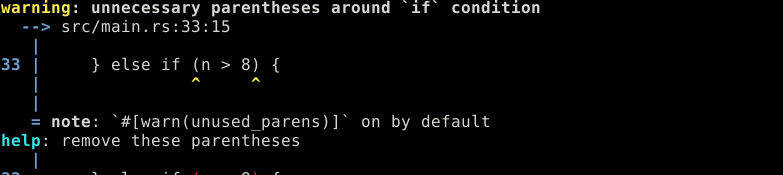
} else if (n > 8) {
println!(">8: {}", n)
} else {
println!("<8: {}", n)
}
let a = true;
if n == 8 && a == true {
println!("8 et a: true");
}
}Rien de bien nouveau, si ce n'est que les parenthèses sont inutiles en Rust.
if et else
fn main() {
let n: u32 = 11 - 3;
if n == 8 {
println!("8");
} else if n > 8 {
println!(">8: {}", n)
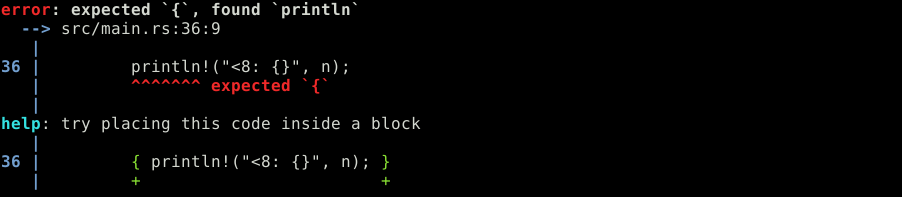
} else println!("<8: {}", n);
let a = true;
if n == 8 && a == true {
println!("8 et a: true");
}
}Et que les brackets sont indispensables. Ici, oublie à la ligne 7.
la boucle loop
fn main() {
let mut count = 0u32;
println!("Let's count until infinity!");
// Infinite loop
loop {
count += 1;
if count == 3 {
println!("three");
// Skip the rest of this iteration
continue;
}
println!("{}", count);
if count == 5 {
println!("OK, that's enough");
// Exit this loop
break;
}
}
}Simple boucle infinie, les directives de contrôle continue et break fonctionnent comme dans d'autres langages. loop, c'est toujours mieux que while(1) { ... } du C.
la boucle while
fn main() {
// A counter variable
let mut n = 1;
// Loop while `n` is less than 101
while n < 101 {
if n % 15 == 0 {
println!("fizzbuzz");
} else if n % 3 == 0 {
println!("fizz");
} else if n % 5 == 0 {
println!("buzz");
} else {
println!("{}", n);
}
// Increment counter
n += 1;
}
}Rien de bien nouveau non plus, l'on enlève juste les parenthèses qui ne servent a rien en Rust et le programme se comporte comme il le ferait en C....
la boucle for
#include <stdio.h>
int main(void) {
for (int i = 0; i < 10; i++) {
printf("%i\n", i);
}
return 0;
}La boucle For est beaucoup plus intéressante puisqu'elle prend en paramètre un iterateur (aspect fonctionnel de Rust). Iterator est un autre trait de Rust, et le type Range l’implémente.
fn main() {
for i in 0..10 {
println!("{}", i);
}
}o code C équivalent
la boucle for
#include <stdio.h>
int main(void) {
for (int i = 0; i < 10; i += 2) {
printf("%i\n", i);
}
return 0;
}Un Itérateur peut utiliser la méthode step_by(self, step: usize) -> StepBy<Self> qui produit une structure StepBy qui implémente aussi le trait Iterator, cela produit donc un autre itérateur.
fn main() {
for i in (0..10).step_by(2) {
println!("{}", i);
}
}o code C équivalent:
Consulter la documentation sur std::ops::Range, le trait Iterator et sa méthode step_by ainsi que la structure std::iter::StepBy
la boucle for
Ici l'on un itérateur sur un Array, le type Array implémente le trait IntoItertor
fn main() {
let fizzbuzz = ["Fizz", "Buzz", "FizzBuzz"];
// Creation d'un iterateur sur l'array
let iter = fizzbuzz.iter();
// On utilise une refence ici pour ne pas 'move'
// par erreur l'iterateur, un iterateur n'est pas Copy
dbg!(&iter);
for word in iter {
println!("{}", word);
}
}[src/main.rs:32] &iter = Iter(
[
"Fizz",
"Buzz",
"FizzBuzz",
],
)
Fizz
Buzz
FizzBuzzLa gestion des erreurs
Ok() or Err()
Qu'est-ce que Result ?
En Rust, beaucoup de fonctions peuvent renvoyer un Result, c'est à dire une enum de deux valeurs, soit Ok(valeur attendue) ou bien Err(type d'erreur).
fn main() {
// On declare une chaine de caractere
// Elle ne contient que des chiffres
let a = "1637";
let res = a.parse::<u32>();
// eq: let res: Result<u32, _> = a.parse(); cf turbofish
dbg!(number);
// Ici, une chaine comppsee de chiffre et de lettre
let b = "16cents trente-sept";
let res = b.parse::<u32>();
dbg!(res);
}Exécutons le code suivant:
La fonction parse::<u32>() sur une chaîne de caractère tente de convertir en u32.
Les deux cas de Result
Sortie du programme:
pub fn parse<F>(&self) -> Result<F, <F as FromStr>::Err>
where
F: FromStr, [src/main.rs:35] res = Ok(
1637,
)
[src/main.rs:40] res = Err(
ParseIntError {
kind: InvalidDigit,
},
)Le prototype de la fonction parse.
o Elle prend un generic F , ici u32 renseigne grâce au turbofish
o Ce generic F doit implémenter le trait FromStr (where)
o Elle retourne un Result<F, type associe d'erreur>
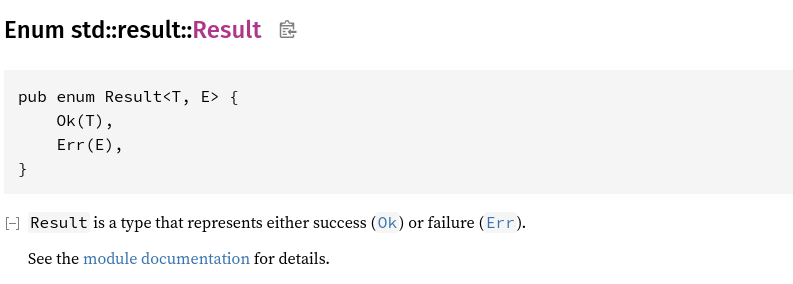
Définition de Result
Text
T et E sont deux types génériques.
if let et Result
fn main() {
// Ici, une chaine comppsee de chiffre et de lettre
let b = "16cents trente-sept";
let result = b.parse::<u32>();
dbg!(&result);
if let Ok(number) = result {
println!("result: {}", number);
}
if let Err(err) = result {
println!("error: {}", err);
}
}Il est possible de connaître la valeur d'un résultat grâce à if let, comme on peut le faire avec n'importe quelle enum. Notez qu'il existe un outil bien puissant pour la gestion des énumérations qui se nomme le pattern matching, on abordera ça plus tard.
Gestion fine des erreurs
Que doit-on faire face a une erreur ?
Il existe en Rust grosso modo deux façons de gérer les erreurs.
fn main() {
let b = "16cents trente-sept";
let result = b.parse::<u32>();
if let Err(error) = result {
println!("Sorry, but an error has occured: {}", error);
return;
}
}o Soit on la gère proprement en expliquant bien ce qui s'est passé, l'on tente de la rattraper si possible ou on quitte calmement le programme.
La méthode brute
fn main() {
// Ici, une chaine comppsee de chiffre et de lettre
let b = "16cents trente-sept";
let number = b.parse::<u32>().unwrap();
dbg!(number);
}o Soit l'on fait panic! le programme, il cesse brutalement en laissant une trace.
Le programme s’arrêtera subitement.
thread 'main' panicked at 'called `Result::unwrap()` on an `Err`
value: ParseIntError { kind: InvalidDigit }', src/main.rs:83:35
note: run with `RUST_BACKTRACE=1` environment variable to display
a backtraceunwrap, expect et surtout panic!
Voici la définition de la méthode unwrap() pour std::result::Result:
NB: Le choix du bon comportement a adopter en cas d'erreur est a la discrétions du programmeur selon le type d'erreur a gérer.
pub fn expect(self, msg: &str) -> T
where
E: Debug, 
Il existe aussi une méthode nommée expect() qui a le même comportement mais qui permet d'afficher tout de même un message custom sur la sortie d'erreur.
Les options
Some() or None
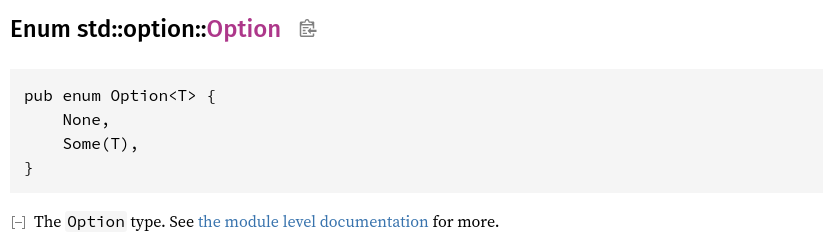
Définition de Option
Les Option ressemblent énormément aux Result, ce sont eux aussi des énumérations, a la différence qu'ils ne prennent qu'un seul type de générique pour le variant Some(T). Dans le second cas, sa valeur est None.
Itérateur et Option
fn main() {
let a = [1, 2, 3];
let mut iter = a.iter();
// A call to next() returns the next value...
assert_eq!(Some(&1), iter.next());
assert_eq!(Some(&2), iter.next());
assert_eq!(Some(&3), iter.next());
// ... and then None once it's over.
assert_eq!(None, iter.next());
}
Le trait std::iter::Iterator définit sa méthode next() avec le prototype suivant. Tant qu'il y aura une donnée a exploiter, il retourne Some(quelque chose). Itérer retourne toujours une Option. L’itérateur est dit consumé lorsqu'il retourne None.
if let et Option
fn main() {
let a: Option<u32> = Some(11);
if let Some(value) = a {
println!("{}", value)
}
if let None = a {
println!("None");
}
}if let fonctionne aussi avec les Option. De manière plus générale, if let fonctionne avec toutes les énumerations.


Option et gestion d’erreur
unwrap et expect sont aussi implémentés pour les Option.
Le pattern matching
filtrage par motif
Pattern matching sur un Result
fn main() {
let b = "16cents trente-sept";
let result = b.parse::<u32>();
match result {
Ok(number) => println!("{}", number),
Err(error) => {
eprintln!("error: {}", error);
panic!("Je veux que le programme panic!");
}
}
}Commençons par un exemple:
error: invalid digit found in string
thread 'main' panicked at 'Je veux que le programme panic!',
src/main.rs:88:13
note: run with `RUST_BACKTRACE=1` environment variable to
display a backtraceSortie du programme:
Alors le Pattern matching, un alias du switch case ?
fn main() {
let b = "16cents trente-sept";
let result = b.parse::<u32>();
match result {
Ok(number) => println!("{}", number),
}
}A première vue, nous sommes sur un équivalent du switch case en C/C++, cependant la pattern matching est bien plus puissant. Déjà il peut travailler avec n'importe quel type de donnée, ensuite il peut déstructurer les tuples, les structs etc... et enfin, le compilateur contrôle que TOUTES les possibilité de valeur ont bien été prises en charge. Dans la pratique, l'on va donc éviter de mettre un defaut: a la fin, justement, pour permettre au compilateur de faire ses vérifications.
Par exemple...
... ne compile pas !
Ai-je bien géré tous les cas ?
fn main() {
let b = "16cents trente-sept";
let result = b.parse::<u32>();
match result {
Ok(number) => println!("{}", number),
_default => {},
}
}Le compilateur est assez bavard la dessus:
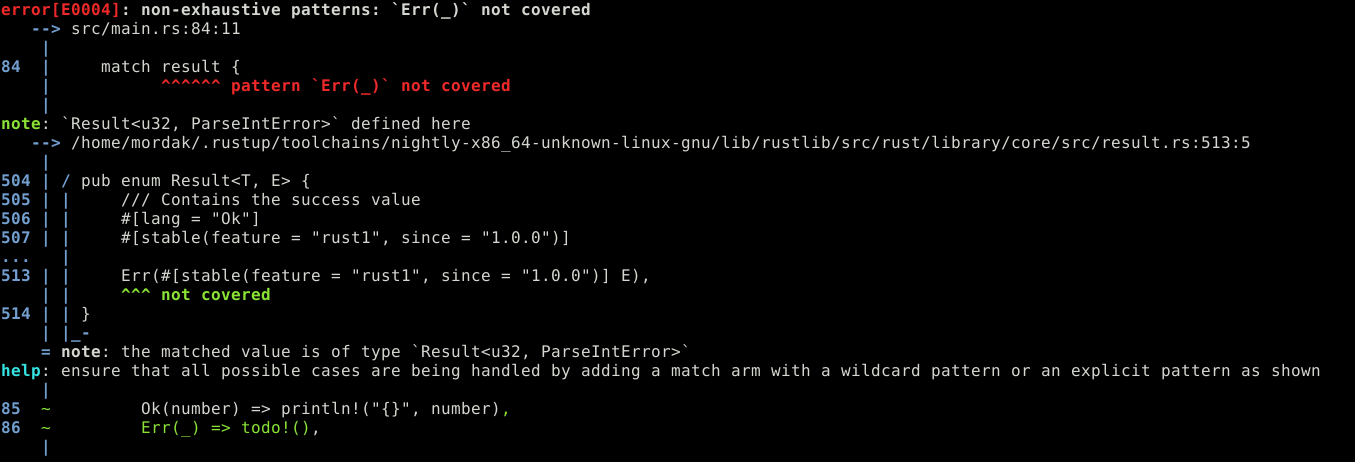
Il nous indique clairement ce que nous devrions écrire dans le code.
Alors, oui, on peut faire un cas de défaut, comme ça, avec l'underscore...
... mais ce serait la pire chose a faire, autant unwrap() direct ou arrêter de coder.
Autres exemples de Pattern matching
fn main() {
enum Target {
X86(u32),
Ia32(u32),
Mips,
}
use Target::*;
let my_target = Ia32(25);
match my_target {
X86(freq) => println!("X86 at frequency {} mhz", freq),
Ia32(_) => println!("Ia32 but we dont worried about frequency"),
Mips => println!("Just an other Mips again"),
}
}Avec une simple enum:
fn main() {
let tuple: (u8, u8, u8, u8, u8) = (0, 1, 1, 2, 3);
// destructured tupple
match tuple {
(0..=5, .., v5) => println!("v5 = {}", v5),
(6..=u8::MAX, .., v4, v5) => println!("v4 = {} v5 = {}", v4, v5),
}
}Destructuration d'un tuple:
Autres exemples de Pattern matching
fn main() {
let v: u32 = 142;
match v {
i if i < 100_u32 => println!("Below than 100: {}", i),
i if i >= 100_u32 => println!("Above or equal than 100: {}", i),
_ => panic!("WOOT ?"),
}
}Une petite limite au compilateur tout de même avec des conditions:
Ici, le compilateur se plaint si on ne met pas de cas par défaut, pourtant la plage couverte des valeurs de v est complète. Le cas défaut doit donc (en théorie) ne jamais arriver. Je n'ai jamais trop compris pourquoi.... Si quelqu'un trouve ça.

Sans le défaut, la sortie du compilateur est ainsi:
Command line args
Recuperer les arguments
Command line args
o Remplacons le main du programme maintenant
o Consulter la doc sur le module std::env

o La fonction args semble faire le travail.

Command line args
fn main() {
use std::env;
// Prints each argument on a separate line
for argument in env::args() {
println!("argument: {}", argument);
}
}
o Qu'est ce que la structure Args ?
Il y a parmi les traits implémentés le trait Iterator, il devrait être donc possible de parcourir les arguments avec une boucle For.
La documentation de la fonction std::env::args donnait déjà l'exemple.
Command line args
o Le trait ExactSizeIterator étant aussi implémente, il permet de connaître a l'avance la len de Args. (Bien que l'on pourrait d'abord collecter les arguments puis ensuite demander la len du Vecteur obtenu).

fn main() {
use std::env;
let args = env::args();
dbg!(args.len());
}Command line args
use std::env;
fn main() {
let arguments: Vec<String> = env::args().collect();
dbg!(&arguments);
if arguments.len() != 2 {
eprintln!("Usage: {} POSITIF_NUMBER", arguments[0]);
return;
}
let argument = arguments[1].parse::<u32>().unwrap();
println!("le nombre est {}", argument);
}Récupération d'un entier positif passe en argument:

Trait Iterator -> Possibilité de récupérer les éléments dans une collection
Command line args
mordak@mordak-pc:~/Documents/fibonacci$ cargo run 99933
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/fibonacci 99933`
[src/main.rs:8] &args = [
"target/debug/fibonacci",
"99933",
]
le nombre est 99933o Entrée correct
o Entrée incorrect
mordak@mordak-pc:~/Documents/fibonacci$ cargo run 99933ggg
Compiling fibonacci v0.1.0 (/home/mordak/Documents/fibonacci)
Finished dev [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/fibonacci 99933ggg`
[src/main.rs:8] &args = [
"target/debug/fibonacci",
"99933ggg",
]
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: ParseIntError { kind: InvalidDigit }', src/main.rs:13:43
note: run with `RUST_BACKTRACE=1` environment variable to display a backtraceFibonacci

Suite de Fibonacci
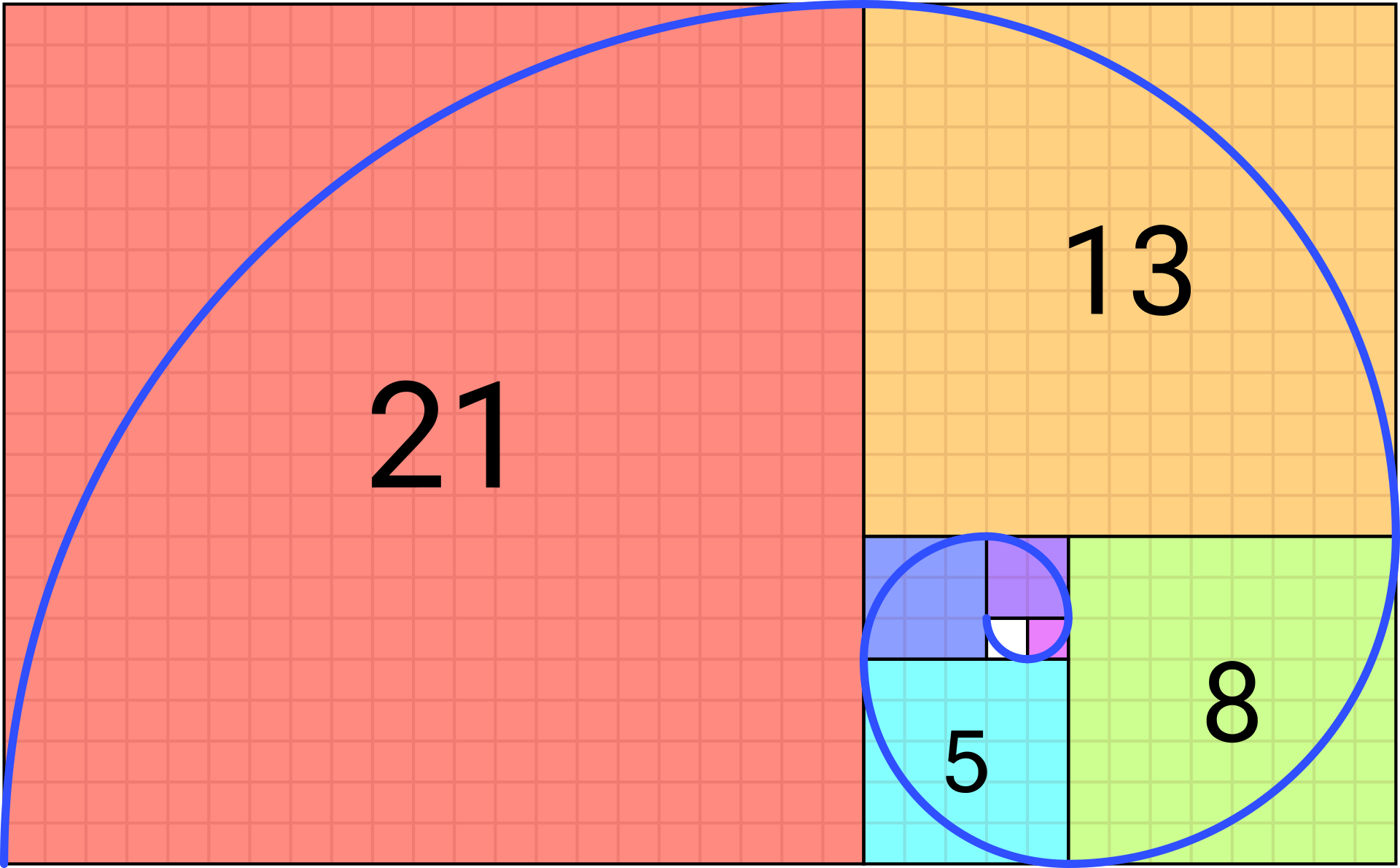
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55 ...
Suite de Fibonacci
// recursive function
unsigned int fibo(unsigned int n) {
if (n == 0) {
return 0;
} else if (n == 1) {
return 1;
} else {
return fibo(n - 1) + fibo(n - 2);
}
}Code de la fonction de Fibonacci récursive en C
- Écrire le code en Rust.
- Gérer les erreurs éventuelles.
- Le programme prend en entrée un entier positif et affiche le résultat de la Fibonacci de cet entier.
- Utiliser le filtrage par motif (pattern matching) le plus possible.
- Utiliser les itérateurs le plus possible.
- Pour le début de la séquence [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144], faire un test unitaire.
use std::env;
fn fibo(n: u32) -> u32 {
match n {
0 => 0,
1 => 1,
_ => fibo(n - 1) + fibo(n - 2),
}
}
fn main() {
let arguments: Vec<String> = env::args().collect();
if arguments.len() != 2 {
eprintln!("Usage: {} POSITIF_NUMBER", arguments[0]);
return;
}
match arguments[1].parse::<u32>() {
Ok(number) => println!("Fibonacci of {} -> {}", number, fibo(number)),
Err(err) => eprintln!("Bad number format: {}", err),
}
}
#[cfg(test)]
mod test {
use super::fibo;
#[test]
fn check_fibonacci() {
let sequence = [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144];
for (i, result) in sequence.into_iter().enumerate() {
assert_eq!(result, fibo(i as u32));
}
}
}Création d'une crate
Librairie
Cargo new pour librairie
mkdir dependencies
cd dependencies
cargo new --lib ma-libOn va créer une crate qui sera utilisée comme une librairie. Elle sera dans un sous-dossier dependencies (le choix du nom de ce dernier revient au programmeur).
Mettons-nous a la racine du projet.
Références mutables
Si l'on regarde dans dependencies/src, il y a non plus un fichier main.rs mais un fichier lib.rs
dependencies/:
total 4
drwxr-xr-x 3 mordak mordak 4096 Jul 5 03:24 ma-lib
dependencies/ma-lib:
total 12
-rw-r--r-- 1 mordak mordak 153 Jul 5 03:22 Cargo.lock
-rw-r--r-- 1 mordak mordak 178 Jul 5 03:17 Cargo.toml
drwxr-xr-x 2 mordak mordak 4096 Jul 5 03:17 src
dependencies/ma-lib:
total 4
-rw-r--r-- 1 mordak mordak 216 Jul 5 03:17 lib.rsCette indication suffit a Rust de savoir qu'il s'agit d'une librairie. Le fichier Cargo.toml ne diffère guère de celui d'un binaire
Cargo new pour librairie
[dependencies.ma-lib]
path = "dependencies/ma-lib"pub fn add(left: usize, right: usize) -> usize {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Afin de pouvoir se servir de la librairie, le fichier Cargo.toml de l’exécutable doit être modifie comme tel.
Plutôt qu'un main() Hello World, Rust a produit une fonction add dans lib.rs.
A ce point donne, le programme principal compile et s’exécute déjà avec la librairie. La commande cargo test fonctionne aussi.
Notons bien que la fonction est publique pub, sans cela elle serait inaccessible depuis le programme exécutable.
Cargo new pour librairie
[src/main.rs:4] add(42, 42) = 84use interface::add;Afin de pouvoir utiliser cette fonction add depuis le programme exécutable, il est nécessaire d'utiliser la directive use lib_name::function_name. Notons que remplacer function_name par un wildcard fonctionnerait aussi.
Utilisons la fonction:
fn main() {
dbg!(add(42, 42));
}Ce n'est pas plus complique que ça. Cependant il faut bien veiller a certains points
o Toujours décider de ce qui doit être publique ou pas, donner a l’exécutable un accès total a tous les sous-items de la librairie n'est généralement pas une bonne idée.
Cargo new pour librairie
main.rs
use ma-lib::operations::test;o Bien gérer les modules. si par exemple dans ma lib, j'ai une fonction sub qui se trouve dans le fichier operations.rs enfant de lib.rs, il faudrait soit:
- que je déclare le mod operations comme public dans ma lib et que j'y accède ainsi depuis l’exécutable use ma-lib::operations::sub
- Soit je laisse le module privé mais je dois metrre dans lib.rs pub use operations::sub.
lib.rs
pub mod operations;use ma-lib::sub;main.rs
lib.rs
mod operations;
pub use uperations::sub;use ma-lib::{add, sub};On peut aussi mettre une liste dans le use du main.
Ses propres types
Enumerations et Structures
Les énumérations
fn main() {
#[derive(Debug)]
enum Error {
FileNotFound,
BadFormat,
Unexpected,
}
let my_error = Error::Unexpected;
dbg!(&my_error);
use Error::*;
match my_error {
FileNotFound => {}
BadFormat => {}
Unexpected => {}
}
}A ce point du cours, les énumérations ne sont plus guère difficiles a saisir.
A partir de maintenant, l'on va systématiquement dériver Debug sur nos propres types afin de pouvoir utiliser la macro dbg!.
use sert a importer les items de l'enum Error. Sans lui, il aurait fallu dans le match des expressions telles Error::FileNotFound.
Les énumérations
fn main() {
#[derive(Debug)]
#[repr(u32)]
enum Error {
FileNotFound = 0,
BadFormat,
Unexpected,
}
let my_error = Error::FileNotFound;
if my_error as u32 == 0 {
println!("C'est bien FileNotFound");
}
}On peut aussi forcer la représentation des valeurs d'une énumération par un type primitif tel u32 via la directive #[repr(u32)], ceci peut avoir son importance si l'on veut interfacer le code Rust avec du C par exemple. cf. FFI
NB: Le cast le plus simple se fait avec le mot clef as, il existe bien d'autres façons plus complexes et plus safe de caster.
Les énumérations
fn main() {
#[derive(Debug)]
enum Voiture<T> {
Lada(T),
Wolkswagen(T),
Peugeot(T),
}
let v1 = Voiture::Lada(100_u32);
let mut v2 = Voiture::Wolkswagen(1000_usize);
v2 = Voiture::Lada(4200_usize);
dbg!(v2);
}Enfin, comme pour Result ou Option, une énumeration peut prendre un type générique:
Cependant, on ne peut pas faite n'importe quoi non plus !
use Voiture::{Lada, Peugeot};
let mut v3 = Peugeot(12_u8);
v3 = Lada(42_u32);
dbg!(v3);
Dans ce cas précis, le compilateur se plaindra car la variable v3 représente d'abord une enum Voiture<T> ou T est un u8, puis ensuite, on tente de lui assigner un nouveau type qui est un u32.
Les structures: Définition
fn main() {
#[derive(Debug, Clone)]
struct Remote {
ipv4: (u8, u8, u8, u8),
port: u32,
name: String,
}
}Déclarer une structure n'est pas chose difficile. chacun des champs est déclaré suivi de son type.
NB: On dérive ici le trait Clone en plus du trait Debug, tous les sous-types étant clonables aussi, on pourra ainsi cloner la structure entière. Néanmoins, il est impossible de dériver Copy puisque le sous-type String n'est pas Copy.
Contrairement a d'autres langages il n'est pas possible de déclarer une ou plusieurs valeurs par défaut du genre: port: u32 = 0, ou port: u32: 0, Il existe cependant un trait nommé Default qui peut être implémenté puis utilisé.
Les structures: Assignation
#[derive(Debug, Clone)]
struct Remote {
ipv4: (u8, u8, u8, u8),
port: u32,
name: String,
}
#[derive(Debug, Clone)]
struct Vector {
i: i32,
j: i32,
}
// Ici, les identifiants du prototype de la fonction sont les memes
// que ceux de la structure.
fn get_vector(i: i32, j: i32) -> Vector {
Vector {
i,
j,
}
}
fn main() {
let r = Remote{
ipv4: (192, 168, 12, 4),
port: 3212,
name: String::from("vbx"),
};
dbg!(r);
let v = get_vector(1, -1);
dbg!(v);
}Exemples d'assignation de structures:
Les structures: Implémentation de méthode
impl Remote {
fn new(ipv4: (u8, u8, u8, u8), port: u32, name: &str) -> Self {
Self {
ipv4,
port,
name: name.into(),
}
}
fn get_addr(&self) -> String {
format!(
"{}.{}.{}.{}:{}",
self.ipv4.0, self.ipv4.1, self.ipv4.2, self.ipv4.3, self.port
)
}
fn change_port(&mut self, new_port: u32) {
self.port = new_port;
}
}
Il est possible et très fréquent d’implémenter des méthodes sur un type de structure, comme un constructeur, des modificateurs etc...
NB: Si la structure est définie dans un autre module, le mot clef pub devra être utilise et précéder fn. Par défaut, tous les champs et méthodes sont privées.
- Self avec S majuscule fait référence au type même de la structure.
- self avec s minuscule fait référence a la variable de type structure.
- L'on passe aux méthodes une référence mutable ou non de la structure. (&self)
Les structures: Implémentation d'un trait
impl Drop for Remote {
fn drop(&mut self) {
println!("Droping remote")
}
}
fn drop_remote(remote: Remote) {}
let mut s = Remote::new((0, 0, 0, 0), 443, "Space");
dbg!(&s);
s.change_port(80);
dbg!(&s);
drop_remote(s);
println!("after call");Le trait Drop est invoqué quand l'item est détruit que ce soit de la pile ou du tas. Il n'y a pas de fuite mémoire en Rust (sauf explicitement voulue), l'objet String contenu dans la structure sera détruit en même temps qu'elle. (tout juste avant)
NB: La documentation sur std::ops::Drop explique tout sur l’implémentation a écrire. Il n'y a aucun tour a deviner, la documentation de Drop est complète.
Si l'on implémente Drop pour une structure, ce n'est pas pour faire le boulot de nettoyage de la mémoire a la place du compilateur, mais seulement pour exécuter une action que l'on juge utile au moment de la destruction de la structure. Cela peut aussi aider parfois a débugger.
NB: ll est intéressant de comprendre pourquoi la fonction drop_remote() détruit la structure de la mémoire.
Les structures: Implémentation d'un trait
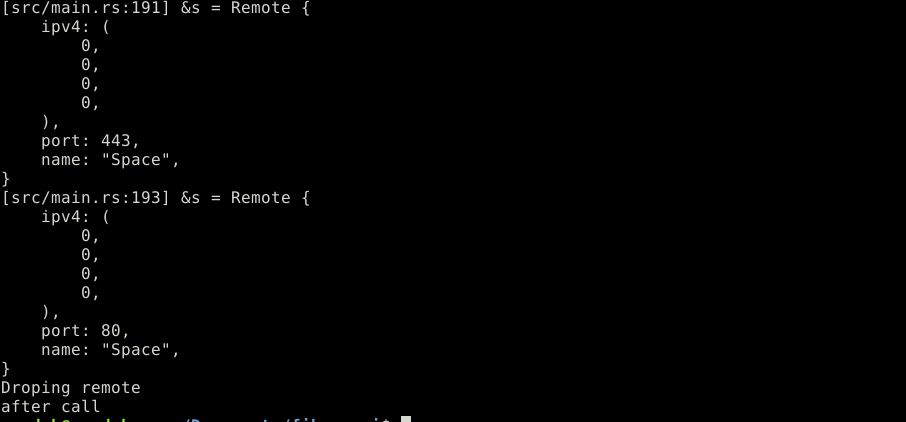
On ne traitera pas ici des Unions, qui sont unsafe.
TP Implementations
Implementations sur Vecteur
- Faire une librairie et non un exécutable
- Créer une structure publique Vector qui contient les champs i et j qui sont tous les deux des f64.
- Implementer le traits Add et AddAssign pour Vector
- Implementer le traits Display
- Implementer des tests pour Display, Add et AddAssign (directement dans la lib)
- Faire un programme exécutable qui se sert de la librairie avec un tout petit exemple.
Pointeurs et references
Unsafe or not ?
Les pointeurs
use std::ptr;
int main() {
let mut a: u32 = 42;
let ptr: *const u32 = &mut a;
dbg!(ptr);
// Easy
unsafe {
dbg!(*ptr);
}
let prim: [u32; 6] = [2, 3, 5, 7, 11, 13];
let ptr: *const u32 = prim.as_ptr();
// We now what we are doing (for the moment...)
unsafe {
dbg!(*ptr);
dbg!(*ptr.offset(1));
dbg!(*ptr.offset(2));
dbg!(*ptr.offset(3));
dbg!(*ptr.offset(4));
dbg!(*ptr.offset(5));
}
// This block may lead to Segmentation fault
unsafe {
dbg!(*ptr.offset(66224411));
}
}Les pointeurs C en Rust. Nommés raw pointers.
Les pointeurs
[src/main.rs:17] ptr = 0x00007fffa4eaef94
[src/main.rs:20] *ptr = 42
[src/main.rs:26] *ptr = 2
[src/main.rs:27] *ptr.offset(1) = 3
[src/main.rs:28] *ptr.offset(2) = 5
[src/main.rs:29] *ptr.offset(3) = 7
[src/main.rs:30] *ptr.offset(4) = 11
[src/main.rs:31] *ptr.offset(5) = 13
Segmentation faultSi l'on doit chercher pourquoi un programme plante, parcourir les parties dites unsafe est la meilleure idée. C'est le cœur de la philosophie de Rust.
Les références: syntaxe
int main() {
int x = 10;
int &r = x; // initialization creates reference implicitly
assert(r == 10); // implicitly dereference r to see x's value
r = 20; // stores 20 in x, r itself still points to x
}fn main() {
let x = 10;
let r = &x; // &x is a shared reference to x
assert!(*r == 10); // explicitly dereference r
}C++ syntaxe
Rust syntaxe
fn main() {
let x: u32 = 10;
let r: &u32 = &x; // &x is a shared reference to x
assert!(*r == 10); // explicitly dereference r
}Types explicites
fn main() {
let mut j: u32 = 10;
let r: &mut u32 = &mut j;
*r *= 20;
dbg!(j);
}Références mutables
Les réferences: Utilisation
int main() {
let a = 16;
let b = 16;
let ra = &a;
let rb = &b;
assert_eq!(ra, rb);
assert_eq!(*ra, *rb);
assert_eq!(&ra, &rb);
assert_eq!(&&ra, &&rb);
// Ne compile pas: comparaison entre &integer et integer
// assert_eq!(*ra, rb);
}Accéder a la référence n’accède pas a son adresse mais a la valeur référencée
fn main() {
fn dump_string(s: &String) {
println!("{}", s);
}
let mut s: String = "banane".into();
dump_string(&s);
s.clear();
dump_string(&s);
}NB: Si l'on veut connaître l’adresse mémoire d'une référence, on doit utiliser des méthodes de std::ptr.
Afin de ne pas move accidentellement la String lors de l'appel de la fonction dump_string, on lui envoit non plus la String mais une référence de cette dernière
Les références implicites
#[derive(Debug, Copy, Clone)]
struct Vector {
i: i32,
j: i32,
}
impl Vector {
fn add_assign(&mut self, other: Self) {
self.i += other.i;
self.j += other.j;
}
}
fn main() {
let v = Vector{i: 10, j: -3};
dbg!(v);
v.add_assign(Vector{i: 2, j: 4});
dbg!(v);
}Prenons l'exemple suivant:
La methode add_assign prend une référence mutable de Vector, pourtant on a envoyé un type Vector et non une référence.
A la ligne 17, l’opérateur . retourne implicitement la référence (mutable ici) de v.
C'est strictement équivalent a la ligne suivante:
(&mut v).add_assign(Vector{i: 2, j: 4});L'on dit que l’opérateur . emprunte (borrowing) une référence mutable de v.
Les références: mutabilité et exclusivité
Il ne peut pas y avoir de référence Null en Rust. Le compilateur s'engage a vérifier si la donnée référencée est toujours 'en vie' cf. notion de lifetime et qui sont ceux qui l'ont emprunté cf. notions d'ownership et de borrowing.
Rust a posé comme règle qu'avoir une référence mutable sur une variable DOIT garantir l’accès exclusif a cette dernière via CETTE référence mutable tant qu'elle vit cf: lifetime. Cela permet au compilateur de procéder a des optimisations qui n'auraient pas pu être faite sans cette garantie. cf: Concurrence.
let mut num = 5;
let numRef = &mut num;En langue Rustienne, on dit que l'espace mémoire de num a été emprunté de façon mutable par numref. mutably borrowed.
C'est sans doute, parmi les aspects de Rust un des plus difficiles à vraiment saisir !
Les références: mutabilité et exclusivité
fn main() {
let mut num = 5;
let numRef = &mut num;
dbg!(num);
*numRef = 6;
}Prenons ce bout de code par exemple:
let mut num = 5;
let numRef = &mut num; dbg!(num); *numRef = 6;Ici, après avoir déclaré l'entier num, on donne la garanti de l’exclusivité sur l'espace mémoire de num a la référence mutable numRef.
Puis on tente d’accéder (pourtant seulement en lecture) a num....
... alors que numref vit toujours ici
Le comportement ne serait pas le même si l'on avait plus tenté d’accéder a numref. Pour le compilateur, la référence mutable serait sans doute déjà morte !
Les références: mutabilité et exclusivité
Retour du compilateur:
fn main() {
let mut num = 5;
let numRef = &mut num;
dbg!(*numRef);
*numRef = 6;
}Ici, après avoir déclaré l'entier num, on donne la garanti de l’exclusivité sur l'espace mémoire de num a la référence mutable numRef.
On peut généraliser cela a tous les cas de figure, des que l'on a une référence mutable sur quelque chose, l’exclusivité doit être garanti. Que ce soit vis-a-vis d'autres références mutables ou même non mutables !
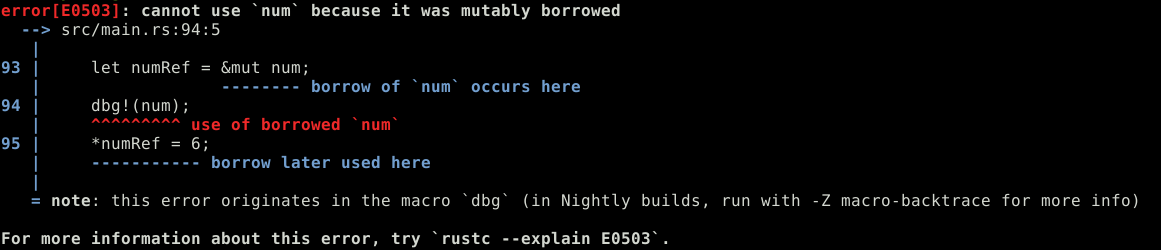
C'est peut être le message d'erreur qu'un développeur Rust même très bon voit le plus de sa vie...
Le code corrigé ci-dessous quand a lui compile très bien:
Les références: paramètres lifetime
Référence dans une structure:
struct A {
r: &i32,
}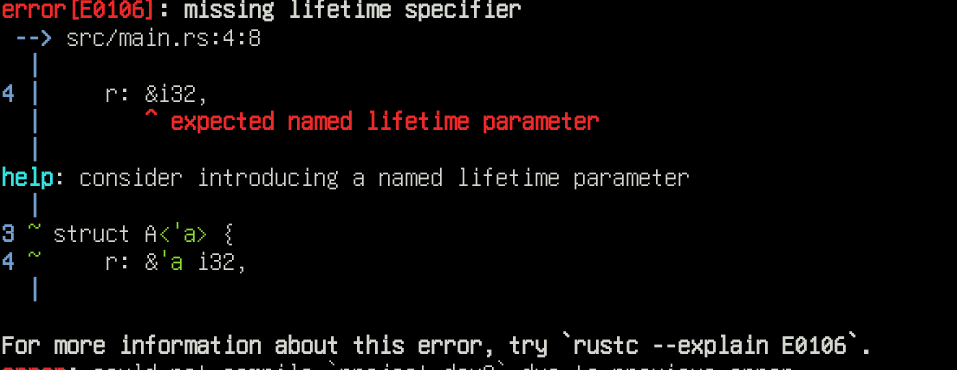
Rust semble va avoir besoin de savoir combien de temps vivra la référence.
Les références: paramètres lifetime
Le code suivant compile très bien mais dans ce cas, l'on a déclaré que la référence est sur une variable globale statique et cela ne peut donc pas fonctionner sur une variable locale.
struct A {
r: &'static i32,
}Le compilateur nous invite a définir la structure ainsi:
struct A<'a> {
r: &'a i32,
}'a est un lifetime anonyme, en faisant cela, on dit au compilateur que la référence ne vivra pas plus longtemps que la variable qu'elle réfère.
Les références: paramètres lifetime
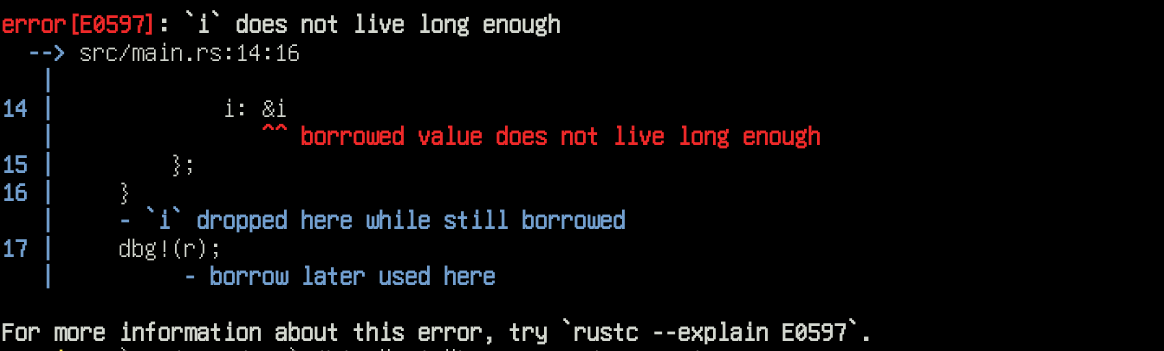
Considérons l'exemple suivant:
#[derive(Debug)]
struct A<'a> {
i: &'a i32,
}
fn main() {
let r: A;
{
let i: i32 = 42;
r = A{
i: &i
};
}
dbg!(r);
}
L'allocation dynamique
Boxes, Vec, String et Arc
Box
pub struct Box<T, A = Global>(_, _)
where
A: Allocator,
T: ?Sized;struct Vector {
i: i32,
j: i32,
}
fn main() {
let vec = Box::new(Vector{ i: 10, j: -5});
}Une Box est la structure allouée en mémoire la plus simple en Rust, c'est un pointeur vers une donnée allouée sur la tas. cf malloc
A la différence de malloc qui prends une taille en octets, on donne a Box::new() le type de donnée qui sera allouée. Le type en question doit être obligatoirement de taille fixe, c'est a dire dont la taille est connue a l'avance par le compilateur.
Il n'y a pas de garbage collector en Rust, ni besoin de libérer manuellement la mémoire, a la fin du bloc ou elle est déclarée. Si l'on veut faire vivre plus longtemps la Box, il est nécessaire que la fonction la retourne.
Box
fn make_box(vec: Vector) -> Box<Vector> {
Box::new(vec)
}
fn take_box(b: Box<Vector>) {
// La box ne vivra plus a la fin du ce bloc
}
fn main() {
let b = make_box(Vector{ i: 10, j: -20});
// Ici la box vit
dbg!(&b);
take_box(b);
// A ce point du code, la box a deja ete liberee
}Une Box est la structure allouée en mémoire la plus simple en Rust, c'est un pointeur vers une donnée allouée sur la tas. cf malloc
Enfin, l'on accède aux données contenues dans une box de façon transparente, comme si la box n'avait pas été faite.
fn main() {
let mut v = Vector{i: 9, j: -3};
v.i = 87;
v,j = -12;
let mut b = Box::new(Vector{i: 10, j: -20});
b.i = 12;
b.j = -11;
}Vec
Un Vecteur est une collection d'elements de même TYPE.
On peut voir le T pour type generique. Il existe plusieurs façons de créer un vecteur, initialise ou non.

fn main() {
// A partir d'un vecteur vide
let mut v1 = Vec::new();
v1.push(1);
v2.push(2);
v3.push(3);
// A partir d'un tableau
let mut v2 = [1, 2, 3].to_vec();
// A partir de la macro vec!
let mut v3 = vec!(1, 2, 3);
}Vec
On peut voir que les mechanismes d’inférence de type fonctionnent, puisque qu'aucun type n'a été déclare precedement. Cela donne avec les types.
Il est dans la pratique très rare d'avoir a déclarer explicitement le type contenu dans la collection.
fn main() {
// A partir d'un vecteur vide
let mut v1: Vec<u64> = Vec::new();
v1.push(1);
v1.push(2);
// Utilisation ici de la syntaxe literale pour definir un type
v1.push(3_u64);
// A partir d'un tableau
let mut v2: Vec<u8> = [1, 2, 3].to_vec();
// A partir de la macro vec!
let mut v3: Vec<u32> = vec!(1, 2, 3);
// Utisation du turbofish ::<>
let mut v4 = Vec::<u64>::new();
v4.push(1);
v4.push(2);
v4.push(3_u64);
}Vec, accès aux éléments
La façon la plus triviale pour accéder aux éléments est la notation crochet.
Afin de pouvoir éviter de paniquer, l'on préféré utiliser la methode get(), qui retourne une Option.
fn main() {
// A partir d'un vecteur vide
let mut v1: Vec<u64> = Vec::new();
v1.push(1);
v1.push(2);
// Utilisation ici de la syntaxe literale pour definir un type
v1.push(3_u64);
dbg!(v1[0]);
dbg!(v1[1]);
dbg!(v1[2]);
// PANIC
dbg!(v1[3]);
}
Vec, accès aux éléments
Ce qui ressemble au code ci-dessous.
NB: La methode get() ne permet pas d’accéder uniquement a un élément mais peut retourner une liste d'elements.
fn main() {
// A partir d'un vecteur vide
let mut v1: Vec<u64> = Vec::new();
v1.push(1);
v1.push(2);
// Utilisation ici de la syntaxe literale pour definir un type
v1.push(3_u64);
dbg!(v1.get(0));
dbg!(v1.get(1));
dbg!(v1.get(2));
// Retourne None
dbg!(v1.get(3));
}
Manipulations des Vecteurs
Il existe une pléiade de méthodes sur les vecteurs.
fn main() {
let mut v = Vec::<u64>::new();
// Ajoute 10 a la fin de la colletion
v.push(10);
// Retire le dernier element de la collection
// et retoune une Option de celui-ci
dbg!(v.pop());
let mut v2: Vec<u64> = vec![4, 5, 6];
// Copie les valeurs de v2 dans v1, vide v2
v.append(&mut v2);
// Vide la collection
v.clear();
// Itere sur le vecteur et dump les valeurs contenues
v.iter().for_each(|v| {
dbg!(v);
});
// Itere de facon mutable sur le vecteur, modifie ses valeurs
v.iter_mut().for_each(|value| {
*value *= 2;
});
}Pour le cas des deux dernières instruction: iter() et iter_mut() retournent respectivement des structures implémentant le trait Iterator.
String
Une String est un autre type alloue, spécialise dans les chaînes de caractères. Contrairement aux Box qui ont une taille fixe, la String change de taille selon ce qu'elle contient.
int main() {
let mut s: String = String::new();
s.push_str("Hello");
dbg!(&s);
s.push(' ');
s.push_str("World");
dbg!(&s);
s.clear();
dbg!(&s);
}
Tout comme la Box et toutes les autres Structures allouées, la mémoire est libérée automatiquement quand on sort du bloc,
Voir la documentation de std::string::String pour connaître les capacités.
String




String
int main() {
let s: String = "Hello World".into();
dbg!(s);
let mut s = String::from("Hello World");
dbg!(&s);
s = "Nouvelle chaine".into();
dbg!(s);
}Les implémentations de From<&str> for String et d'Into permettent d'assigner le contenu des Strings plus facilement.
int main() {
let f = String::from("Hello") + " World".into();
dbg!(f);
}Comment ce code compile il ? Et Pourquoi avoir mis un from() puis ensuite un into() ?
Arc
Arc ou Atomically Reference Counter est une 'structure' allouée qui est destinée a être partagée entres différents threads.
Arc implémente le trait clone, chaque thread peut accéder indépendamment a son clone de l'Arc., chaque clone pointe sur le même type contenu. Le compteur de reference interne fonctionne ainsi: Pour chaque clone qui est fabrique, il est incrémenté de 1, pour chaque clone détruit (par la fin d'un bloc d'instruction, d'un appel a Drop ou a une fonction qui ne le retourne pas), l'on soustrait 1. Quand le compteur tombe a 0, l'Arc et le type contenu sont libérés de la mémoire. Le compteur étant dit Atomic, il ne peut pas y avoir de problème de concurrence lors de l’incrémentation ou de la décrémentation de ce dernier.

Arc
int main() {
use std::sync::Arc;
#[derive(Debug)]
struct Vector {
i: u32,
j: u32,
}
// Creation de l'Arc, le reference Counter passe a 1
let a = Arc::<Vector>::new(Vector {i: 12, j: 42});
{
// Creation du clone, le reference Counter passe a 2
let b = a.clone();
// Passage par reference, le clone n'est pas detruit lors de l'appel
dbg!(&b);
// Ici le clone est detruit -> Fin du bloc d'instruction
// Le reference Counter repasse a 1
}
// L'arc est envoye a la fonction dbg!, il est ainsi detruit apres le retour
// de la fonction dbg! puisque son reference Counter passe a 0.
dbg!(a);
}En pratique, l'utilisation d'un Arc est nécessaire seulement si l'on a plusieurs threads et qu'elle est conjugee avec un Mutex afin que les threads puissent modifier les données contenues.
Multithreading
concurrence
La programmation concurrente
Grâce a la documentation de std::thread, std::sync::Arc et celle de std::sync::Mutex, essayez de faire un programme contenant 2 threads pouvant modifier et lire tous les deux les mêmes données de façon safe.
fn main() {
let mut data: i32 = 42;
let _t = std::thread::spawn(move || {
dbg!(data);
data = 11;
dbg!(data);
});
data = 22;
dbg!(data);
let mut s: String = "42".to_owned();
let _t = std::thread::spawn(move || {
dbg!(&s);
s.push_str("11");
dbg!(&s);
});
s.push_str("22");
dbg!(&s);
}
Trouver ce qui ne va pas dans ce programme qui ne peut pas compiler.
La programmation concurrente
Dans cette partie nous allons voir comment monter un programme multi thread en Rust. En plus du thread main, nous allons créer deux threads, un content et un pas content qui panic. Et plutôt que d'utiliser un bête nutex que vous avez deja rencontre mille fois dans votre expérience de programmeur, nous allons utiliser un MPSC. Multiple Producer, Single Consumer. Nous ne chercherons pas non plus a joindre les threads, c'est trop banal aussi.

Le MPSC
Un MPSC est déjà thread safe, il est protege en interne par un Mutex ou un Sémaphore ou autre..., il faut regarder dans le code de la STD pour savoir ça ! Mais il est thread safe en tous cas.
C'est un canal de communication, le pattern habituel consiste a donner un SENDER a chaque thread crées en plus du main() et d'utiliser le RECEIVER dans le thread principal. RECEIVER qui lui est unique. Single Receiver...

La fonction channel() retourne un Sender et un Receiver. Notez le generic T. Cela implique que l'on peut envoyer ou recevoir le type de donnee que l'on veut. Ici nous allons renvoyer un tuple (enum + threadId) afin de passer un message ainsi que de connaître son producteur.
Il existe peut etre deja une methode sur le Receiver pour voir le threadID mais j'avais la flemme de chercher...
Instanciation du MPSC
use std::sync::mpsc;
use std::thread::ThreadId;
#[derive(Debug, Copy, Clone)]
enum Event {
Hello,
HelloAgain,
IWantToStop,
}
fn main() {
let (sender, receiver): (
mpsc::Sender<(Event, ThreadId)>,
mpsc::Receiver<(Event, ThreadId)>,
) = mpsc::channel();
let sender2 = sender.clone();
}Pour obtenir le Receiver et le Sender, on procède donc ainsi en précisant bien le type de donnée que l'on va transmettre. Notez que l'on clone déjà le sender car on sait que on va l'envoyer a deux threads. Autant cloner tant que le fer est chaud.
Création des threads
let _happy_thread = thread::spawn(move || {
})
let _bad_thread = thread::spawn(move || {
})Aussi simple que ça: Notez le move et la closure || pour y penser plus tard. Un jour ces notions vous paraîtront clairs mais ne sont pas utiles pour l'instant.
sender
.send((Event::HelloAgain, thread::current().id()))
.unwrap();loop {
let (msg, id) = receiver.recv().unwrap();
// if condition, break
} sender2
.send((Event::Hello, thread::current().id()))
.unwrap();Voici des exemples d'utilisation du sender, dans le thread 1 et 2 respectifs
Et le receiver du thread principal dans tout ça ?
Et le receiver du thread principal dans tout ça ?
Il attend un message, l'appel est dit bloquant et fait un tour de loop jusqu'au next....
Coder des bouts de code en plus....
L’idée peut être pour continuer et de faire communiquer régulièrement les threads, en attendant un peu entre chaque message grâce au sleep().

Peut être aussi quitter le programme quand un des threads nous dit qu'il en peut plus. (3eme variant de l'enum...)
Ou Afficher le threadId pour savoir qui est vient de parler...
Voir même faire panic! un thread autre que le principal au bout d'un certain temps pour voir comment le programme se comporte !
panic!("sa mere");NB: Ce serait dommage qu'un thread se termine tout juste après sa création....
use std::sync::mpsc;
use std::thread::ThreadId;
use std::{thread, time};
#[derive(Debug, Copy, Clone)]
enum Event {
Hello,
HelloAgain,
IWantToStop,
}
fn main() {
let (sender, receiver): (
mpsc::Sender<(Event, ThreadId)>,
mpsc::Receiver<(Event, ThreadId)>,
) = mpsc::channel();
let sender2 = sender.clone();
let three_seconds = time::Duration::from_millis(3000);
let _happy_thread = thread::spawn(move || {
sender.send((Event::Hello, thread::current().id())).unwrap();
loop {
thread::sleep(three_seconds);
sender
.send((Event::HelloAgain, thread::current().id()))
.unwrap();
}
});
let _bad_thread = thread::spawn(move || {
sender2
.send((Event::Hello, thread::current().id()))
.unwrap();
thread::sleep(three_seconds * 3);
sender2
.send((Event::IWantToStop, thread::current().id()))
.unwrap();
panic!("sa mere");
});
loop {
let (msg, id) = receiver.recv().unwrap();
println!("message recu: {:?} de {:?}", msg, id);
if let Event::IWantToStop = msg {
println!("A thread want to stop");
break;
}
}
println!("Exiting Main thread normallu. Bye");
}A quoi cela pourrait ressembler.
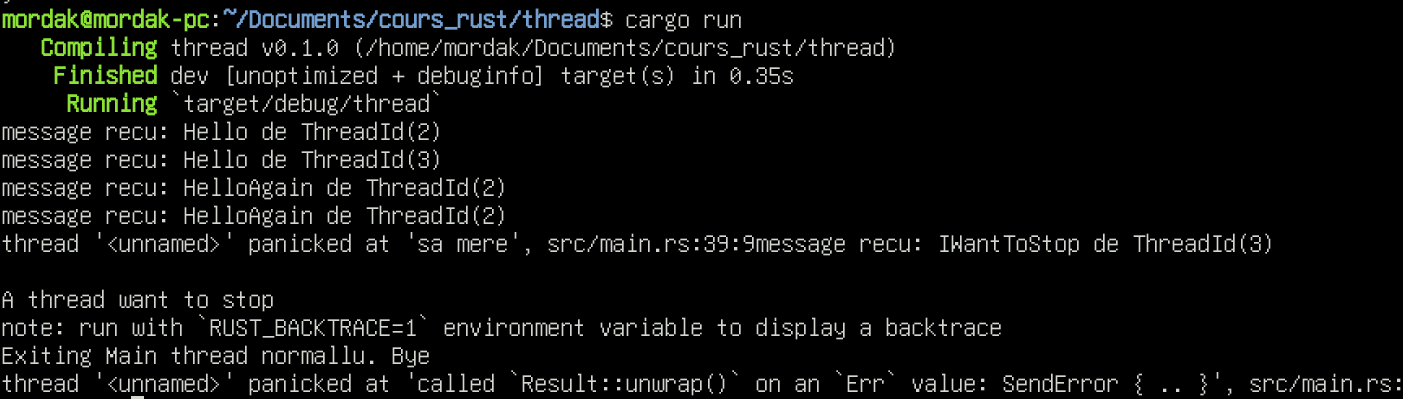
La sortie du programme
N'oubliez pas que Rust est extrêmement puissant dans la gestion de ses threads, ce n'est pas pour rien que l'on parle de programmation concurrente. Tant qu'il n'y a pas de code explicitement unsafe, les threads tiennent bon. Les règles strictes de Rust qui nous font maudir ce langage lorsque nous sommes en monothreads sont de vraies benedictus en environnement multithreade.
Un petit mot sur le trait Send
fn main {
// Tous les types contenus ici sont Send
#[derive(Debug)]
struct S {
i: u8,
j: u8,
k: String,
}
let s = S {
i: 1,
j: 2,
k: "toto".to_string(),
};
let _t = std::thread::spawn(move || {
dbg!(s);
});
}Rust détermine les types qui peuvent être passes a un thread par la condition s'ils implémentent le trait Send. Aussi si une structure possède plusieurs éléments qui implémentent tous le trait Send, le compilateur considéra que la structure est Send, on appelle cela un AUTO trait.
Un petit mot sur le trait Send
fn main {
// Un pointeur en rust n'est pas Send
#[derive(Debug)]
struct S2 {
ptr: *const u8,
}
let s2 = S2 {
ptr: std::ptr::null(),
};
let _t = std::thread::spawn(move || {
dbg!(s2);
});
}Il y a quelques types qui ne sont pas Send comme par exemple les raw pointers, ou les RC ou simple Reference Counter (a ne pas confondre avec les ARC). Si l'on veut vraiment passer ces types a un thread, l'on sera oblige d'implementer Send manuellement pour une structure englobant ces types, cette instruction est par nature UNSAFE.
le code ci-dessous ne compile donc pas:
unsafe impl Send for S2Il est necessaire de rajouter cette ligne:
Rust fonctionnel
Un pattern très courant
use std::num::ParseIntError;
fn parse_all(a: &str, b: &str, c: &str) -> Result<u32, ParseIntError> {
let r1: u32 = a.parse::<u32>()?;
dbg!(r1);
let r2: u32 = b.parse::<u32>()?;
dbg!(r2);
let r3: u32 = c.parse::<u32>()?;
dbg!(r3);
Ok(r1 + r2 + r3)
}
fn main() {
match parse_all("1637", "42", "toto21") {
Ok(res) => println!("La somme vaut {}", res),
Err(err) => println!("Erreur: {}", err),
}
println!("Hello, world!");
}Lorsque nous avons vu les Result<T, E> la dernière fois, nous sommes complètement passe a cote de la notation ? Pourtant elle est extrêmement fréquente en Rust parce que très pratique.
Ici, nous parsons 3 chaînes de caractères pour en extraire des u32, enfin, si tout s'est bien passe, nous les additionnons et renvoyons le résultat.
Le point d'interrogation
let r3 = match c.parse::<u32>() {
Ok(res) => res,
Err(e) => return Err(e),
};Mais que fait ce petit symbole au juste ?
C'est simple, la fonction parse retourne un Result<u32, ParseIntError>, le point d’interrogation signifie que si le résultat est Ok(_), on met le résultat dans les variables r1, r2 ou r3, sous forme de u32 et non de Result.
Cependant, si au contraire, nous avons Err(quelque chose), on quitte la fonction directement et l'erreur est retournée, elle sera gérée par l'appelant de la fonction.
Alors au lieu d'avoir ces 4 lignes de code:
On a ça:
let r3 = c.parse::<u32>()?;Ceci fait partie des patterns que l'on dit fonctionnels, sympa non ?
L’esthétique du code
let total = v.iter().fold(0, |total, next| total + next);C'est justement un des points essentiels de la programmation fonctionnelle, elle permet de faire souvent en une seule ligne élégante du code qui aurait été bien plus long et laid a voir.
En fonctionnel, çà donne:
let mut total = 0;
for i in 0..v.len() {
total += v[i];
}Autre exemple connu. Si j'ai une collection de nombre, disons dans un tableau et que je veux additionner dans utiliser l'approche fonctionnelle. mon code serait:
L'on dit aussi qu'elle est extrêmement puissante et forte de sens pour gérer des collections entières de données. Elle simplifie le code.
Fold est juste magique, il faut absolument le voir dans la documentation.
L’esthétique du code
Cette autre fonction fait le carre de chacun des nombres entre 1 et 10 et stocke les résultats dans une liste de données, ici un Vec.
let squared: Vec<u32> = (1..10).map(|x| x * x).collect();Les closures
fn main() {
let mut v: Vec<u8> = vec!(1, 2, 4, 8);
v.iter_mut().for_each(|inner| *inner *= 2);
dbg!(&v);
}Il existe en Rust un type de fonction un peu spéciales, ce sont les closures. Contrairement aux fonctions, elles peuvent être anonymes, les paramètres sont notes entre | | plutôt qu'entre parenthèses ( ) et elles ont surtout la capacité de capturer les variables de leur environnement, contrairement aux fonctions. La capture se fait soit par référence &, soit par référence mutable &mut soit par transfert d'ownnership, nous allons voir ces différents cas de figure.
Prenons le prototype de la fonction for_each() pour du trait Iterator:
Bien qu'il soit possible d'envoyer une reference d'une fonction a for_each, en pratique on utilisera toujours une closure a la place.

Les closures
fn main() {
// Declaration de la variable s en dehors de la closure
let s = "MaString".to_string();
// Ici on definit la closure avant de l'utiliser
let closure = |inner: &mut u8| {
*inner *= 2;
// Ici la variable s est capturee par reference &s
println!("One other iteration: {}", s);
};
let mut v: Vec<u8> = vec!(1, 2, 4, 8);
v.iter_mut().for_each(closure);
// s est toujours accessible ici
dbg!(&s);
// Ici la closure est anonyme
v.iter_mut().for_each(|inner| {
*inner *= 2;
// Ici la variable s est capturee par reference &s
println!("One other iteration: {}", s);
});
// s est toujours accessible ici
dbg!(&s);
}Mais contrairement aux fonctions, ici l'on va par exemple prendre capturer une référence sur une String qui est a l’extérieur du bloc de la closure.
Ici, une référence non-mutable de s est passée implicitement a la closure, il n'y a guère de différence de code si cela avait été une référence mutable
Les closures
fn main() {
// Declaration de la variable s en dehors de la closure
let s = "MaString".to_string();
// Ici on definit la closure avec MOVE avant de l'utiliser
let closure = move |inner: &mut u8| {
*inner *= 2;
// Ici, l'ownership de la variable s est passe au thread
println!("One other iteration: {}", s);
};
v.iter_mut().for_each(closure);
// s n'est plus accessible ici, le programme ne compile donc pas !
dbg!(s);
}On peut forcer le passage par ownership en utilisant le mot clef move avant les paramètres de la closure, comme c'est le cas pour le prototype de thread.
Il serait en effet assez illogique étant donne les garantis de securite du langage que prodigue Rust qu'un thread puisse recevoir une référence d'une variable extérieure a celui-ci, si cette dernière réfère sur une variable présente sur la pile du thread appelant et non sur le tas, il est possible qu'au moment ou le nouveau thread tente d'y accéder, la pile de la fonction appelante soit modifiée.
Les Iterator mutables et exclusivité
fn main() {
let mut v: Vec<u8> = vec!(1, 2, 4, 8);
v.iter_mut().for_each(|inner| *inner *= 2);
dbg!(&v);
}Souvenons-nous de la règle concernant les références mutables qui dit qu'on ne peut acceder a l'objet référence qu'EXCLUSIVEMENT au travers de cette unique référence mutable. Dans le cas de la fonction iter_mut sur Vec<T>, qui créer une itérateur mutable, elle prends en paramètre une référence mutable de self, soit du Vec ici.

Les Iterator mutables et exclusivité
fn main() {
let mut v: Vec<u8> = vec!(1, 2, 4, 8);
v.iter_mut().enumerate().for_each(|(index, inner)| {
if index == 0 {
v.push(16);
}
*inner *= 2;
});
dbg!(&v);
}Admettons que je tente d'ajouter une case a mon Vecteur lorsque je suis a l’intérieur du bloc d’itération.
Quel problème pourrait poser ce genre de code ?
Les Iterator mutables et exclusivité
Le compilateur ne veut pas car des effets de bords en tout genre pourraient apparaître, comme par exemple si j'etend a chaque itération mon vecteur tout en itérant dessus, on aurait ainsi une belle boucle infinie et non parfaitement prévisible. Le tout termine par un crash du programme due au fait qu'il n'y aurait plus de mémoire disponible !
Il est aussi important de noter qu'en Rust que si j'ai une référence mutable sur un champ d'une structure, je peux avoir une référence mutable sur un autre champs de cette même structure, mais plus sur la structure entière.
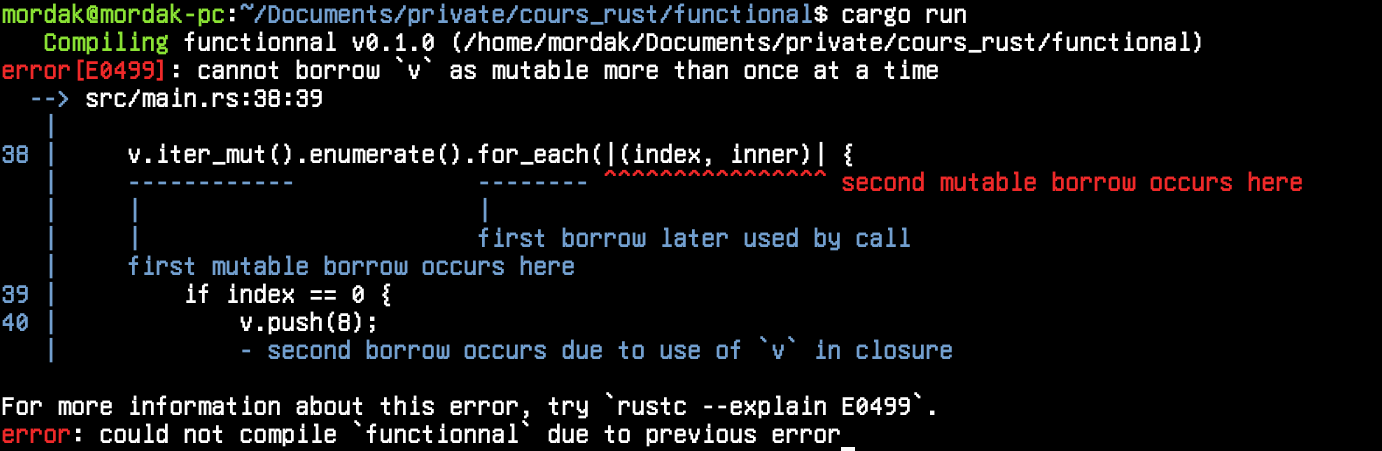
Les Iterator mutables et exclusivité
fn main() {
#[derive(Debug)]
struct S {
i: i32,
j: i32,
}
let mut s = S {
i: -1,
j: -2,
};
let ref_i = &mut s.i;
let ref_s = &mut s;
*ref_i = -11;
dbg!(s);
}Ceci n'est pas possible:
let ref_i = &mut s.i;
let ref_j = &mut s.j;
*ref_i = -11;
*ref_j = -12;
*ref_i = -21;
*ref_j = -22;
dbg!(s);Mais ceci l'est:
Ses propres Traits
Un trait bien dangereux...
On cherchera a faire un trait qui dump les valeurs hexadécimales sous forme de byte dans la mémoire occupée par une variable de type generic T. En theorie... N'importe quoi pourra utiliser le trait et révéler ses valeurs cachées.
unsafe {
print!("{:#04x} ", *ptr.offset(byte as isize));
}
Le trait se nomme HexDump qui defnit la methode hex_dump.
pub trait HexDump {
fn hex_dump(&self);
}impl HexDump for u32 {
fn hex_dump(&self) {}
}Son implémentation generique se note ainsi:
impl <T>HexDump for T {
fn hex_dump(&self) {}
}Une implémentation non-generique aurait été telle quelle:
En y reflechissant, il n'y a pas trop de raison qu'un type ne puisse pas fonctionner puisque la seule chose que l'on risque de faire, c'est de recuperer une adresse mémoire.
Les elements
La macro std::ptr::addr_of! semble pouvoir aider a recuperer l'adresse mémoire.

Le type retourne ne serait-il pas un *const T ?
Si l'on veut afficher octet par octet, ne serait il pas mieux d'avoir un *const u8 ?
as *const u8; peut etre....
La taille de T
Si l'on commence a dumper comme ça la mémoire, il est mieux de connaître la taille de la donnée T en entree,

On sait tout ce qu'il faut pour faire le trait maintenant...
Le code
pub trait HexDump {
fn hex_dump(&self);
}
impl<T> HexDump for T {
fn hex_dump(&self) {
let ptr = std::ptr::addr_of!(*self) as *const u8;
for byte in 0..std::mem::size_of::<Self>() {
unsafe {
print!("{:#04x} ", *ptr.offset(byte as isize));
}
}
println!();
}
}Le test
fn main() {
let r: u32 = 42;
r.hex_dump();
let r: u32 = 0;
r.hex_dump();
let r: f64 = 42.12;
r.hex_dump();
}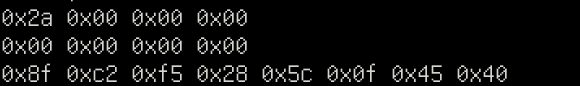
Durée de vie
Les cas implicites
fn main() {
fn first_element(slice: &[u8]) -> &u8 {
&slice[0]
}
let v = vec![1, 2, 3];
dbg!(first_element(v));
}La plupart du temps, rust inférera les durée de vie sans que l'utilisateur n'est a s'en soucier. Rappelons que la regle principale des duree de vie est qu'un objet référence DOIT vivre au moins aussi longtemps que les references sur celui-ci. C'est la garanti qu'il n'y aura jamais de reference Null ou invalides.
Prenons par exemple ce bout de code:
Cette fonction retourne une reference sur le premier élément de la collection. Rust en interne va la réécrire comme ci-dessous,
fn main() {
fn first_element<'a>(slice: &'a [u8]) -> &'a u8 {
&slice[0]
}
let v = vec![1, 2, 3];
dbg!(first_element(v));
}L’entrée doit vivre au moins aussi longtemps que la sortie.
Les cas implicites
fn main() {
struct MaStruct {
inner_a: u32,
inner_b: u32,
}
fn get_inner_a(t: &MaStruct) -> &u32 {
&t.inner_a
}
fn get_inner_a_by_rust<'a'>(t: &'a MaStruct) -> &'a u32 {
&t.inner_a
}
}Si on prend l'exemple d'une structure:
Ces deux fonctions sont strictement équivalentes.
Les mêmes règles s'appliqueront dans le cas d'une methode d'une structure (&self ou &mut self) retournant une reference sur un champs de cette dernière. la structure en entree doit vivre au moins aussi longtemps que la reference en sortie:
Les cas implicites
forme implicite:
Ces deux fonctions sont strictement équivalentes.
NB: la durée de vie 'a doit toujours être déclaré après le nom de la fonction
impl MaStruct {
fn get_inner_a(&self) -> &u32 {
&self.inner_a
}
}forme explicite:
impl MaStruct {
fn get_inner_a<'a>(&'a self) -> &'a u32 {
&self.inner_a
}
}quand il faut être explicite
Cependant si j'ai par exemple une fonction qui prend 2 references en entrée, et une en sortie, Rust ne saura pas comment déterminer quelles durées de vie doivent être liées.
Ce qui provoque comme erreur:
fn dump_a_string_and_get_inner_a(t: &MaStruct, s: &str) -> &u32 {
println!("{}", s);
&t.inner_a
}
quand il faut être explicite
Nous voyons que le compilateur suggère d'attribuer la même durée de vie a tous les paramètres en entrée MAIS cette suggestion ne doit pas etre toujours suivie a la lettre. En effet, on peut très bien accepter le fait que la référence de s n'ai pas a survivre aussi longtemps que celle de la structure T.
Ce qui provoque comme erreur:
fn dump_a_string_and_get_inner_a<'a>(t: &'a MaStruct, s: &'a str) -> &'a u32 {
println!("{}", s);
&t.inner_a
}
fn get_output(t: &MaStruct) -> &u32 {
let s = String::from("Toto");
let output = dump_a_string_and_get_inner_a(&t, &s);
output
}
let t = MaStruct {
inner_a: 1,
inner_b: 2,
};
dbg!(get_output(&t));
Pourquoi ce na compile pas ?!? WTF
quand il faut être explicite
La solution consiste a donner un second lifetime (ici 'b) au second paramètre, on précise aussi que le lifetime du premier paramètre est lie a celui de la sortie.
Ce qui provoque comme erreur:
fn dump_a_string_and_get_inner_a<'a, 'b>(t: &'a T, s: &'b str) -> &'a u32 {
println!("{}", s);
&t.inner_a
}
fn get_output(t: &T) -> &u32 {
let s = String::from("Toto");
let output = dump_a_string_and_get_inner_a(&t, &s);
output
}
let t = T {
inner_a: 1,
inner_b: 2,
};
dbg!(get_output(&t));Ici l'on dit que 'a et 'b sont deux lifetime différents. Il existe aussi la possibilité de préciser qu'une référence DOIT vivre au moins plus longtemps qu'une autre:
fn dump_a_string_and_get_inner_a<'a: 'b, 'a>(t: &'a T, s: &'b str) -> &'a u32ce qui veut dire: 'b ne doit pas survivre a 'a. Le contraire ne compilerait pas dans notre contexte.
fn dump_a_string_and_get_inner_a<'a, 'b: 'a>(t: &'a T, s: &'b str) -> &'a u32quand il faut être explicite
Pour résumer, le bon emploi des lifetime ne se résume a suivre aveuglement ce que le compilateur suggère. Il faut comprendre comment nos references sont agencées les unes par rapports aux autres dans notre programme.
la macro
!
La macro hello World
// Une simple macro nommée `say_hello_world`.
macro_rules! say_hello_world {
// `()` indique que la macro ne prend aucun argument.
() => (
// La macro étendra le contenu de ce bloc.
println!("Hello World!");
)
}
fn main() {
// Cet appel va étendre `println!("Hello World");`.
say_hello_world!()
}Exemple de RustByExample
Finished dev [unoptimized + debuginfo] target(s) in 0.19s
Running `target/debug/functionnal`
Hello World!Sortie standard du programme:
NB: Il existe des règles spécifiques d'export et d'import de macro en Rust depuis d'autres fichiers et des dépendances.
Macro sur une seule ligne
Trois cas de figure d'utilisation de serial_println!
/// Prints to the host through the serial interface, appending a newline.
#[macro_export]
macro_rules! serial_println {
() => ($crate::serial_print!("\n"));
($fmt:expr, $($arg:tt)*) => ($crate::serial_print!(concat!($fmt, "\n"), $($arg)*));
($fmt:expr) => ($crate::serial_print!(concat!($fmt, "\n")));
}/// Vide
/// -> Juste un simple retour a la ligne
serial_println!();
/// Une chaine de caractere avec des arguments
/// Affixher la chaine en developpant les arguments
serial_println!("{} banane(s)", 42);
/// Une chaine de caractere seule
/// Afficher la chaine de caractere
serial_println!("Toto21")En entrée: Avant le => => En sortie: On utilise les identifiants $xxx
- () veut dire vide
-$___::expr veut dire 'expression formatée', chaîne de caractère quoi.
- la virgule dans le second cas est le délimiteur utilise entre le 1er et le 2nd argument.
- $___:tt veut dire arguments quelconque
- le wildcard * veut dire qu'il peut y en avoir toute une liste
/// Implements a new C style enum with his try_from boilerplate
macro_rules! safe_convertible_enum {
(#[$main_doc:meta]
#[$derive:meta]
#[repr($primitive_type:tt)]
enum $name:ident {
$(
#[$doc:meta]
$variant:ident = $value:expr,
)*
}) => {
#[$main_doc]
#[$derive]
#[repr($primitive_type)]
pub enum $name {
$(
#[$doc]
$variant = $value,
)*
}
impl core::convert::TryFrom<$primitive_type> for $name {
type Error = Errno;
fn try_from(n: $primitive_type) -> Result<Self, Self::Error> {
use $name::*;
match n {
$($value => Ok($variant),)*
_ => Err(Errno::EINVAL),
}
}
}
}
}Commentaire de Doc
#[derive(Debug, etc...)]
#[repr(u32)]
Commentaire de Doc
(au dessus de ch variant)
Entree
Sortie
Commentaire de Doc
#[repr(u32)]
#[derive(Debug, etc...)]
Commentaire de Doc
(au dessus de ch variant)
ident = Type
value = Valeur numerique
delimiteur =
$main_doc
$derive
$primitive_type
$doc
$variant
$value
Variables
Une macro un poil plus complexe
Forme littéral de l'enum
Présentée comme dans l'appel de la macro plus bas. avec pub en plus
Implémentation TryFrom
impl TryFrom<EnumType> for Type { ... }
match Type => EnumType
Utilisation de la macro
safe_convertible_enum!(
/// This list contains the sockets associated function types
#[derive(Debug, Copy, Clone)]
#[repr(u32)]
enum CallType {
/// Create an endpoint for communication
SysSocket = 1,
/// Bind a name to a socket
SysBind = 2,
/// Initiate a connection on a socket. Client connection-oriented
SysConnect = 3,
/// Listen for connections on a socket. Server connection-oriented
SysListen = 4,
/// Accept a connection on a socket. Server connection-oriented
SysAccept = 5,
/// Send a message on a socket. Similar to write with flags. connection-oriented
SysSend = 9,
/// Receive a message from a socket. Similar to read with flags. connection-oriented
SysRecv = 10,
/// Send a message on a socket. The destination address is specified. connectionless
SysSendTo = 11,
/// Receive a message from a socket. The source address is specified. connectionless
SysRecvFrom = 12,
/// Shut down part of a full-duplex connection. connection-oriented
SysShutdown = 13,
}
);FFI
Foreign Function Interface
rust bindgen
Pour la FFI, bindgen est un outil des plus efficace. En entrée on lui donne un fichier header .h et en sortie, il nous écrit un .rs a utiliser dans le programme.
cargo install bindgenDans sa forme la plus simple, mono fichier, on donne un .h a bindgen. Faisons un nouveau projet nomme ffi, creer un sous-dossier c_lib et y mettre le .h et le .c que je vous ai envoyé.
cd src
bindgen ../c_lib/lib.h > c_lib.rsLe fichier .rs genere
pub type size_t = ::std::os::raw::c_ulong;
#[repr(C)]
#[derive(Debug, Copy, Clone)]
pub struct custom_memory_fn {
pub allocator:
::std::option::Option<unsafe extern "C" fn(arg1: size_t) -> *mut ::std::os::raw::c_void>,
pub deallocator: ::std::option::Option<unsafe extern "C" fn(arg1: *mut ::std::os::raw::c_void)>,
}
extern "C" {
pub fn fusion_merge_tab(
t1: *mut ::std::os::raw::c_void,
len: ::std::os::raw::c_int,
elmt: size_t,
cmp: ::std::option::Option<
unsafe extern "C" fn(
arg1: *mut ::std::os::raw::c_void,
arg2: *mut ::std::os::raw::c_void,
) -> ::std::os::raw::c_int,
>,
mem: *mut custom_memory_fn,
) -> *mut ::std::os::raw::c_void;
} Seules ces parties vont vraiment nous intéresser.
Ce sont les définitions de la structure a remplir et la fonction C a appeler.
Linkage du C avec le Rust
use std::env;
use std::path::Path;
use std::process::Command;
fn main() {
let out_dir = env::var("OUT_DIR").unwrap();
// Note that there are a number of downsides to this approach, the comments
// below detail how to improve the portability of these commands.
Command::new("gcc")
.args(&["c_lib/merge_sort.c", "-c", "-fPIC", "-o"])
.arg(&format!("{}/merge_sort.o", out_dir))
.status()
.unwrap();
Command::new("ar")
.args(&["crus", "libhello.a", "merge_sort.o"])
.current_dir(&Path::new(&out_dir))
.status()
.unwrap();
println!("cargo:rustc-link-search=native={}", out_dir);
println!("cargo:rustc-link-lib=static=hello");
}On va faire un script de linkage, on utilise pour cela un fichier build.rs que l'on place a la racine du projet.
D'abord il compile le fichier .c pour en faire une librairie et il contient des paramètres qui seront passes au compilateur rustc pour qu'il procède au linkage.
La librairie est linkee a l’exécutable
#[repr(C)]
#[derive(Debug, Copy, Clone)]
pub struct custom_memory_fn {
pub allocator:
::std::option::Option<unsafe extern "C" fn(arg1: size_t) -> *mut ::std::os::raw::c_void>,
pub deallocator: ::std::option::Option<unsafe extern "C" fn(arg1: *mut ::std::os::raw::c_void)>,
}Si tout s'est bien passe, le cargo run devrait fonctionner normalement avec un simple Hello World. Interessons nous maintenant au code C a appeler.
D'abord il y a une sorte de structure qui prend un allocateur et un desallocateur en paramètre. std::alloc semble faire le boulot.
use std::alloc::{alloc, dealloc, Layout};
unsafe extern "C" fn allocator(arg1: c_lib::size_t) -> *mut ::std::os::raw::c_void {
let layout = Layout::array::<u64>(arg1 as usize / std::mem::size_of::<u64>());
let ptr = alloc(layout.unwrap());
ptr as *mut ::std::os::raw::c_void
}
unsafe extern "C" fn deallocator(arg1: *mut ::std::os::raw::c_void) {
let layout = Layout::new::<[u64; TAB_SIZE]>();
dealloc(arg1 as *mut u8, layout);
}Écrivons ces deux fonctions dans le main.rs
Fonction de comparaison
unsafe extern "C" fn cmp(
arg1: *mut std::os::raw::c_void,
arg2: *mut std::os::raw::c_void,
) -> std::os::raw::c_int {
if *(arg1 as *mut u64) < *(arg2 as *mut u64) {
0
} else {
1
}
}Pareil, apparemment, on doit envoyer l’adresse d'une fonction de comparaison. Ecrivons-la.
Tout est a peu près unsafe la
Et enfin le main...
const TAB_SIZE: usize = 1024 * 2;
fn main() {
let mut custom = c_lib::custom_memory_fn {
allocator: Some(allocator),
deallocator: Some(deallocator),
};
let layout = Layout::array::<u64>(TAB_SIZE);
let v = unsafe {
let ptr = alloc(layout.unwrap());
let mut v = Vec::<u64>::from_raw_parts(ptr as *mut u64, TAB_SIZE, TAB_SIZE);
// remplit le vecteur avec des valeurs decroissantes
for i in 0..(TAB_SIZE) {
v[i] = ((TAB_SIZE) - i) as u64;
}
let old_ptr = v.as_ptr();
let ptr = c_lib::fusion_merge_tab(
v.as_ptr() as *mut ::std::os::raw::c_void,
TAB_SIZE as i32,
std::mem::size_of::<u64>() as u64,
Some(cmp),
&mut custom as *mut c_lib::custom_memory_fn as *mut c_lib::custom_memory_fn,
);
println!("Finito !");
dbg!(old_ptr);
dbg!(ptr);
if old_ptr != ptr as *const u64 {
v.leak(); // !!!
v = Vec::<u64>::from_raw_parts(ptr as *mut u64, TAB_SIZE, TAB_SIZE);
}
v
};
for i in v.into_iter() {
dbg!(i);
}
}std::process
Jouer avec les processus
std::Process
Text
Syntaxe des déclarations
fn main() {
let arr: [u32; 5] = [1, 2, 3, 4, 5];
let arr = [1, 2, 3, 4, 5];
let arr: [&str; 3] = ["Terre", "Feu", "Air"];
let arr = ["Terre", "Feu", "Air", "Eau"];
}Simples Array
fn main() {
let arr = vec![1, 2, 3, 4, 5];
let arr = vec![1, 2, 3, 4, 5];
let arr = vec!["Terre", "Feu", "Air", "Eau"];
let arr = vec!["Terre", "Feu", "Air", "Eau"];
}Utilisation de la macro vec!. un vecteur stocke un ensemble de données de type T
fn main() {
let s: String = "Une String".into();
let slice1 = &s[..2];
let slice2 = &s[0..6];
let slice3 = &s[1..len];
let slice4 = &s[3..];
let s = "Ceci est aussi une slice";
}Slices: &str est une slice, une slice peut aussi référencer une String.
NB: L'index d'une slice est toujours en octet, elle peut couper une séquence utf8
Modules et fichiers
Organisation du projet
SESSION RUST
By AdapTeach




