Rich and lazy learning of task representations in brains and neural networks
Flesch, Juechems, Dumbalska, Saxe, Summerfield
JC 11.04.2022, Claudia Merger

Feedforward NNs can solve problems in different ways

data:
Feedforward NNs can solve problems in different ways
hidden representation:
data:
Woodworth, B. et al. Kernel and Rich Regimes in Overparametrized Models. arXiv:2002.09277 [cs, stat] (2020).
scale of weights at initialization
small
large
Feedforward NNs can solve problems in different ways
hidden representation:
data:
Woodworth, B. et al. Kernel and Rich Regimes in Overparametrized Models. arXiv:2002.09277 [cs, stat] (2020).
scale of weights at initialization
How do humans make decisions?
How do neural populations code for multiple, potentially conflicting tasks?
small
large
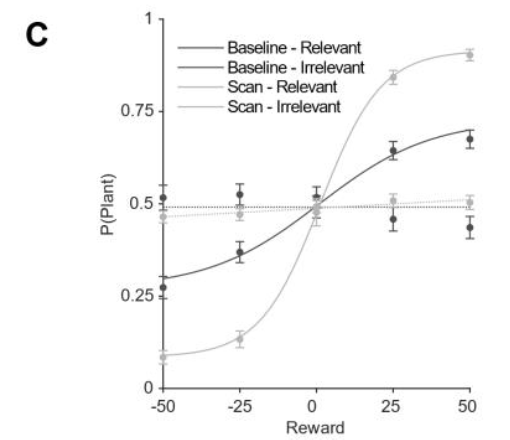
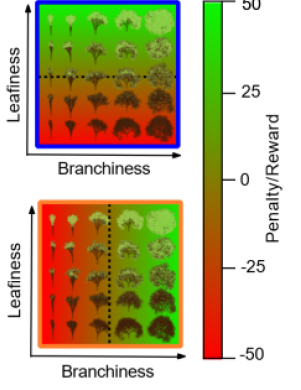
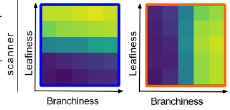
Humans make decisions based on a context
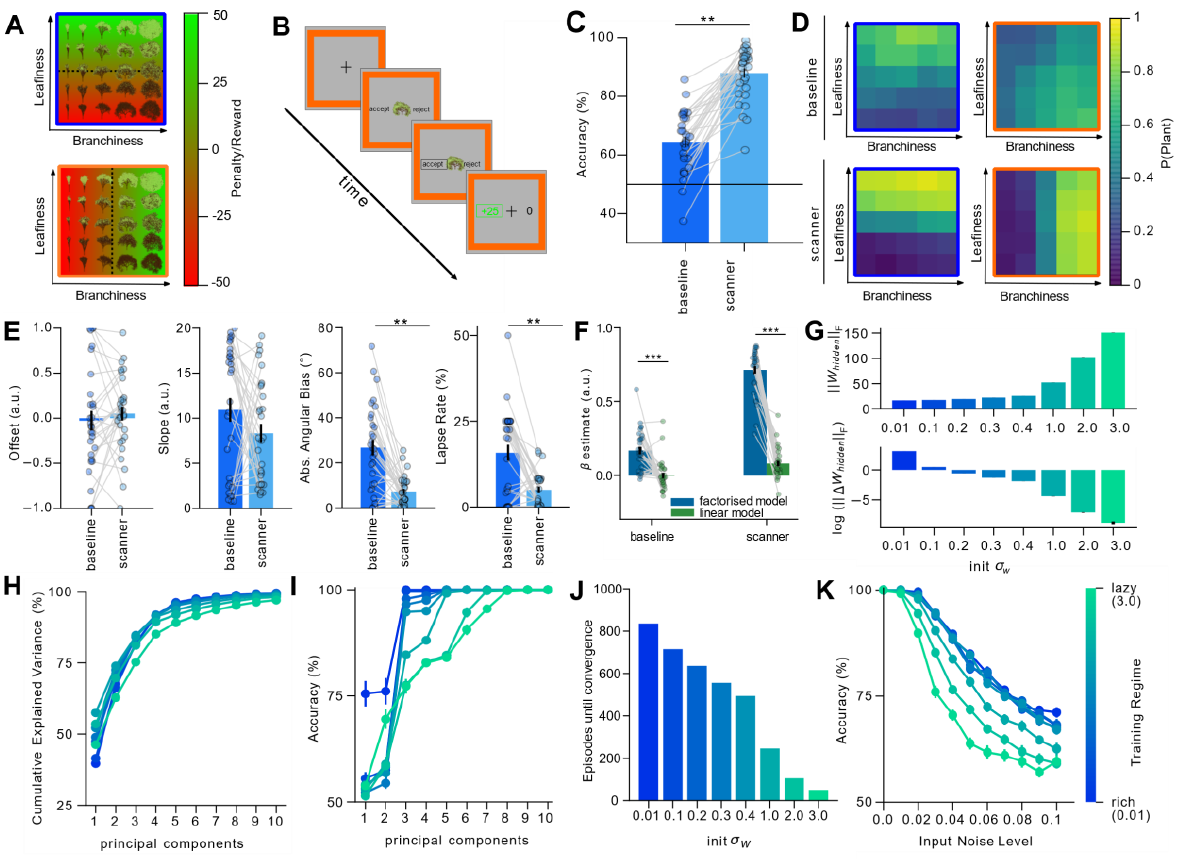
context: 2 gardens, blue or orange
task: decide whether to plant tree based on context
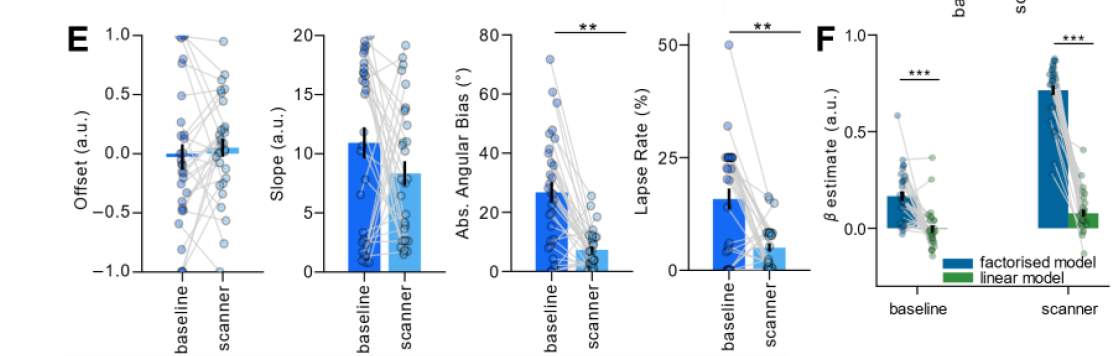
Humans make decisions based on a context
baseline: initial test
scanner: fMRI scanner
accuracy increase between two tests
Humans make decisions based on a context
fit model to human performance:
leafiness/branchiness
Humans make decisions based on a context
fit model to human performance:
Humans make decisions based on a context
fit model to human performance:
factorized model fits better than linear model
Humans make decisions based on a context
fit model to human performance:
factorized model fits better than linear model
What is the geometry of the representation of the stimuli in humans? Is it rich or lazy?
Humans make decisions based on a context
fit model to human performance:
factorized model fits better than linear model
What is the geometry of the representation of the stimuli in humans? Is it rich or lazy?
first: Look at feedforward neural networks
Train feed-forward neural network
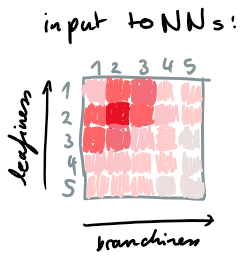
"Gaussian blobs"
Train feed-forward neural network
W_{ij} \sim \mathcal{N}(0,\sigma_W^2)
"Gaussian blobs"
rich
lazy
Initialize a Neural network with different weight variances:
Interpolate between rich and lazy
rich
lazy
rich: low. dim. hidden repr.
lazy: high dim. hidden repr.
Initialize a Neural network with different weight variances:
Interpolate between rich and lazy
rich
lazy
rich: low. dim. hidden repr.
lazy: high dim. hidden repr.
rich: more robust to removal
lazy: less robust to removal
Initialize a Neural network with different weight variances:
Interpolate between rich and lazy
rich: low. dim. hidden repr.
lazy: high dim. hidden repr.
rich: more robust to removal
lazy: less robust to removal
rich: slow learning
lazy: fast learning
Initialize a Neural network with different weight variances:
Interpolate between rich and lazy
rich
lazy
Initialize a Neural network with different weight variances:
Interpolate between rich and lazy
rich: low. dim. hidden repr.
lazy: high dim. hidden repr.
rich: more robust to removal
lazy: less robust to removal
rich: slow learning
lazy: fast learning
rich: more robust to noise
lazy: less robust to noise
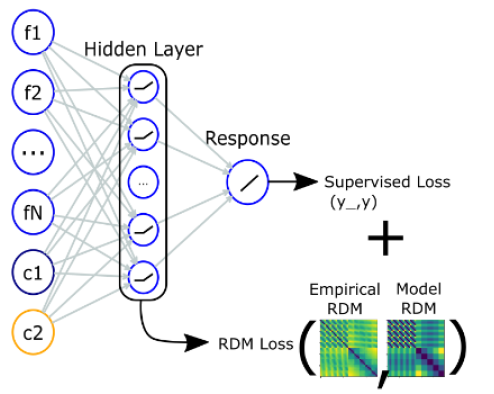
Visualize geometry of data representation:
Representational Similarity Analysis (RSA)
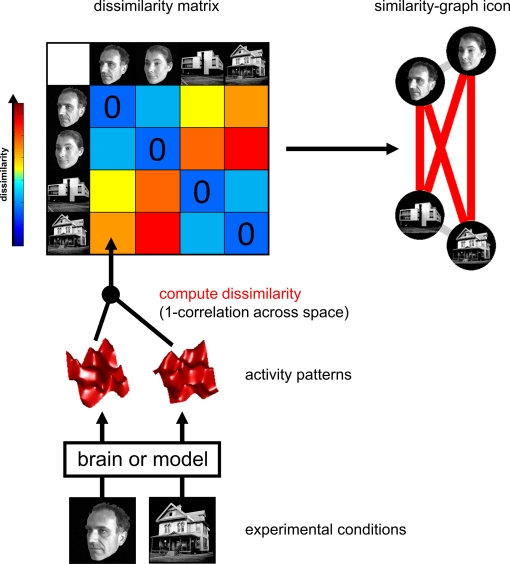
inputs
Kriegeskorte, N., Mur, M. & Bandettini, P. Representational Similarity Analysis – Connecting the Branches of Systems Neuroscience. Front Syst Neurosci 2, 4 (2008).
Visualize geometry of data representation:
Representational Similarity Analysis (RSA)
Neural network:
hidden manifold
inputs
Kriegeskorte, N., Mur, M. & Bandettini, P. Representational Similarity Analysis – Connecting the Branches of Systems Neuroscience. Front Syst Neurosci 2, 4 (2008).
Visualize geometry of data representation:
Representational Similarity Analysis (RSA)
Neural network:
hidden manifold
inputs
Kriegeskorte, N., Mur, M. & Bandettini, P. Representational Similarity Analysis – Connecting the Branches of Systems Neuroscience. Front Syst Neurosci 2, 4 (2008).
"distance
measure"
Visualize geometry of data representation:
Representational Similarity Analysis (RSA)
Neural network:
hidden manifold
inputs
Kriegeskorte, N., Mur, M. & Bandettini, P. Representational Similarity Analysis – Connecting the Branches of Systems Neuroscience. Front Syst Neurosci 2, 4 (2008).
"distance
measure"
Multi-Dimensional
scaling (MDS)
+
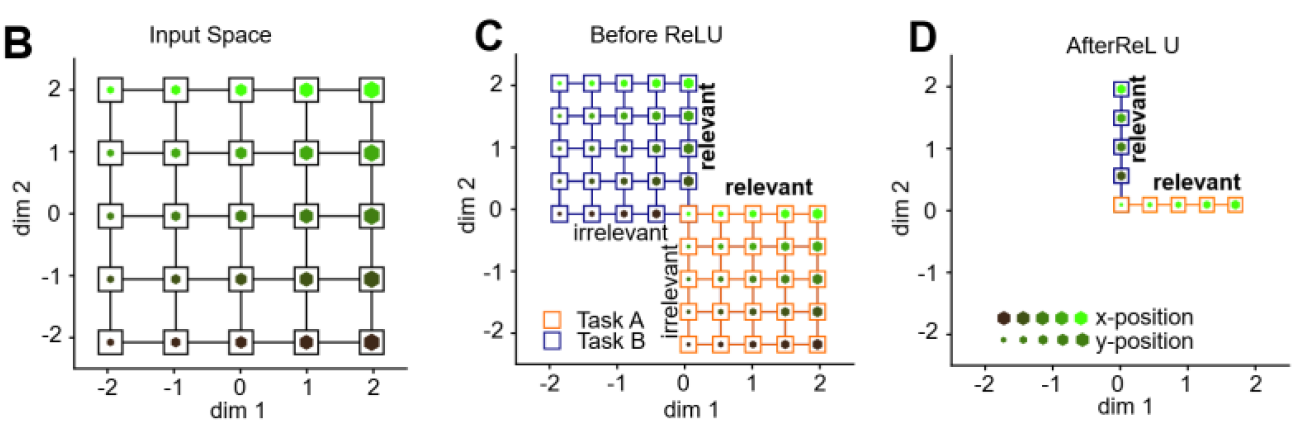
Neural Networks make decisions based on a context
Context is fed into NN as an input
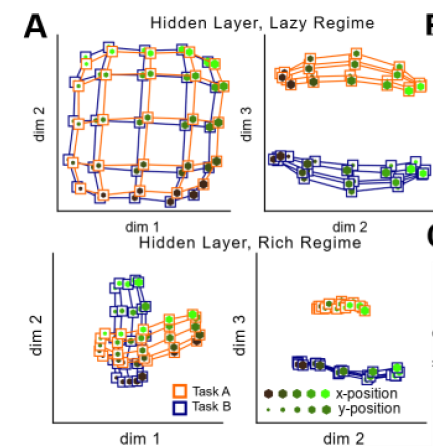
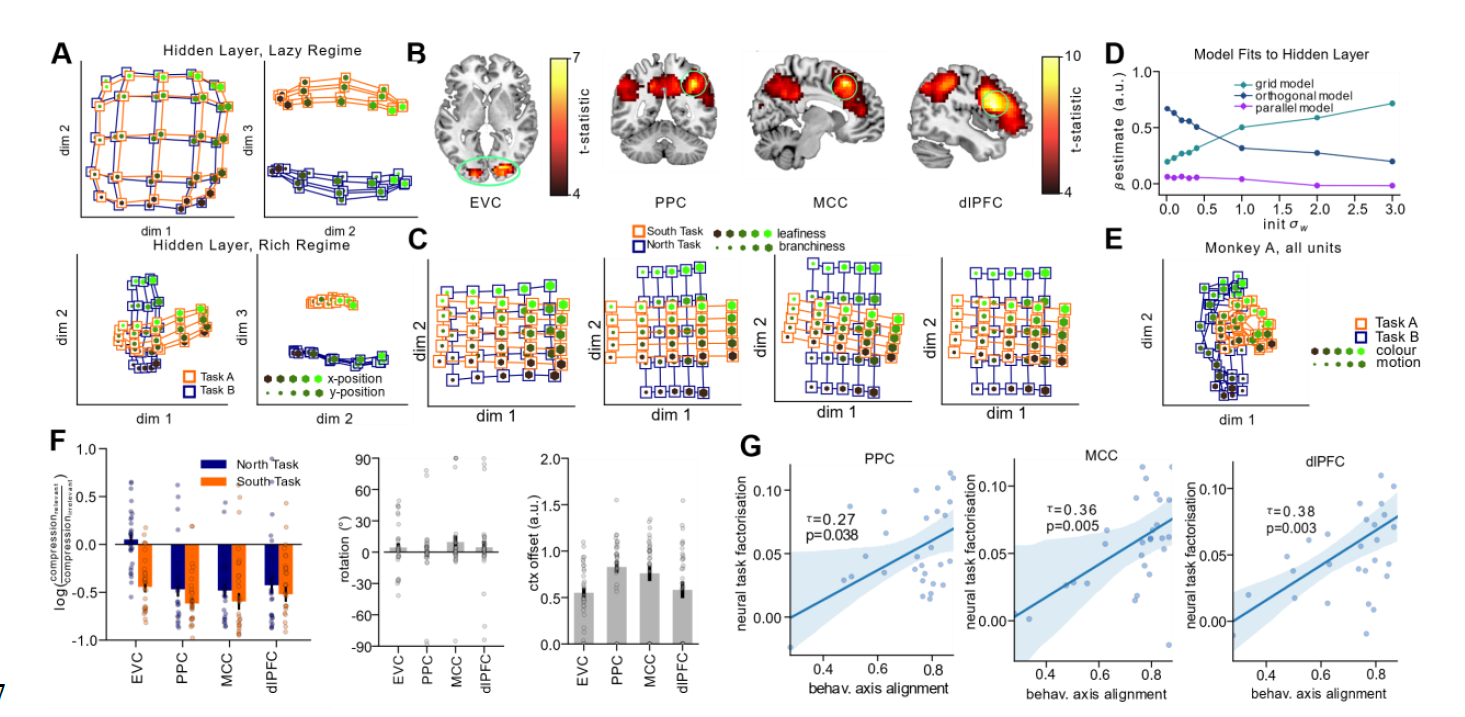
Geometry of hidden representation varies in rich and lazy regime
lazy approximately conserves distances between inputs
richt compresses along irrelevant dim.
representational similarity analysis and multidimensional scaling:
Neural Networks make decisions based on a context
Neural Networks make decisions based on a context
Context is fed into NN as an input
Geometry of hidden representation varies in rich and lazy regime
lazy approximately conserves distances between inputs
richt compresses along irrelevant dim.
representational similarity analysis and multidimensional scaling:
Neural Networks make decisions based on a context
Neural Networks make decisions based on a context
Context is fed into NN as an input
Geometry of hidden representation varies in rich and lazy regime
lazy approximately conserves distances between inputs
richt compresses along irrelevant dim.
representational similarity analysis and multidimensional scaling:
Neural Networks make decisions based on a context
Neural Networks make decisions based on a context
Context is fed into NN as an input
Geometry of hidden representation varies in rich and lazy regime
lazy approximately conserves distances between inputs
richt compresses along irrelevant dim.
representational similarity analysis and multidimensional scaling:
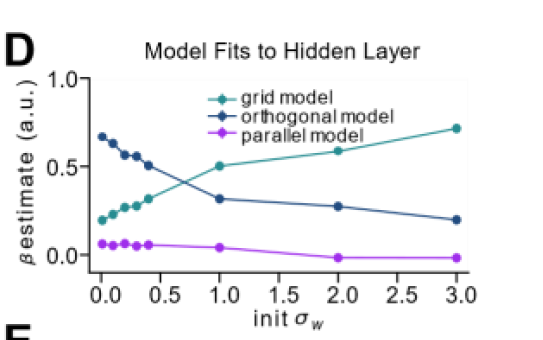
grid fits better in lazy regime,
orthogonal better in rich
Neural Networks make decisions based on a context
representational similarity analysis and multidimensional scaling:
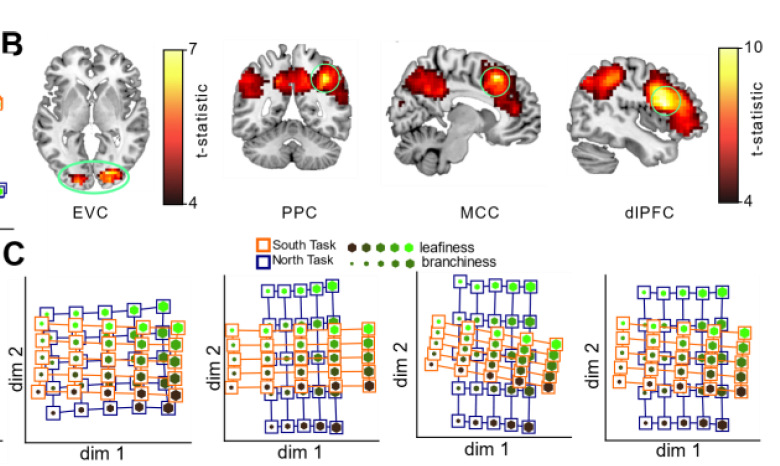
Analyze neural geometry from fMRI scans
Rich representation in most regions
Neural Networks make decisions based on a context
representational similarity analysis and multidimensional scaling:
Analyze neural geometry from fMRI scans
Rich representation in most regions
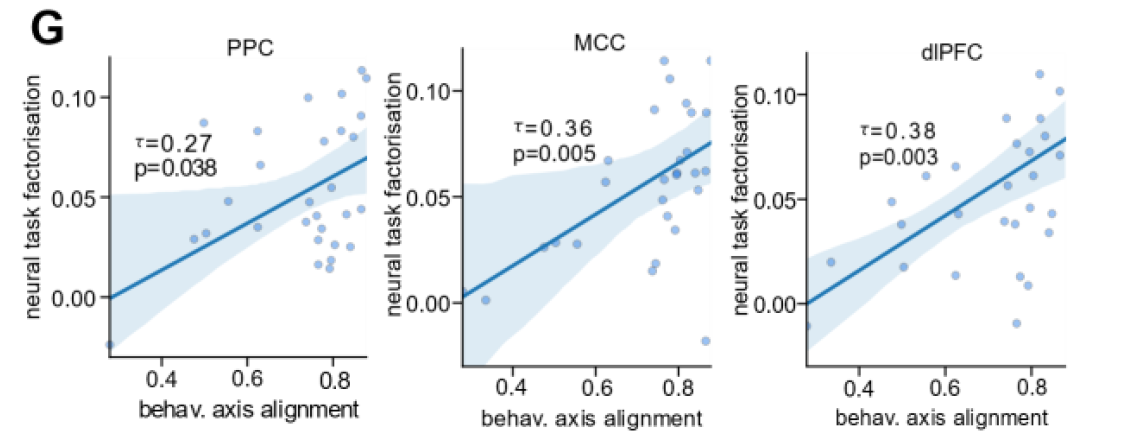
better human performance
correlates with fit of orthogonal model:
Neural Networks make decisions based on a context
representational similarity analysis and multidimensional scaling:
monkey frontal eye fields: https://www.ini.uzh.ch/en/research/groups/mante/data.html
Analyze neural geometry from fMRI scans
Rich representation in most regions
better human performance
correlates with fit of orthogonal model:
How do neural networks code for different contexts?
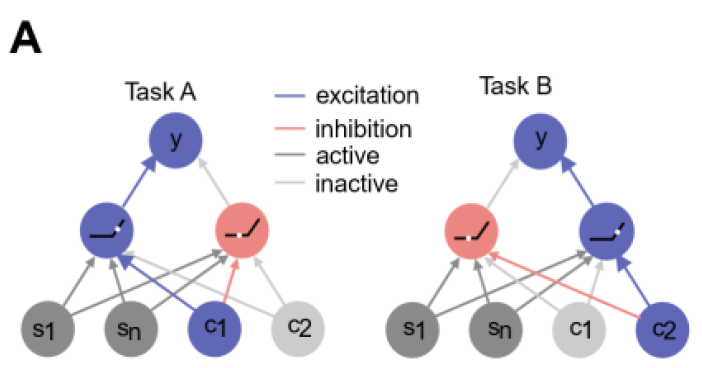
How do neural networks code for different contexts?
anticorrelated weights from context to hidden units
How do neural networks code for different contexts?
anticorrelated weights from context to hidden units
How do neural networks code for different contexts?
anticorrelated weights from context to hidden units
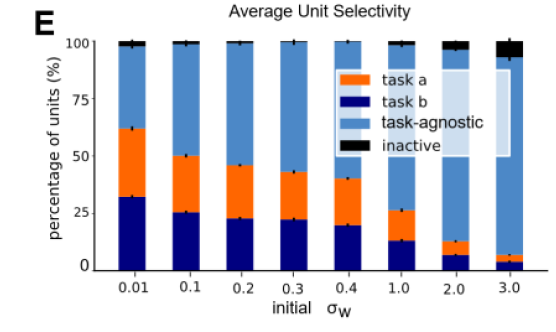
rich
lazy
representations should be mixed-selective and respond to both task and input stimuli
-> In the rich regime, hidden layer
activativations should be task-selective
Neural Network:
selectivity: Nonzero activation
How do neural networks code for different contexts?
anticorrelated weights from context to hidden units
rich
lazy
representations should be mixed-selective and respond to both task and input stimuli
-> In the rich regime, hidden layer
activativations should be task-specific
Neural Network:
selectivity: Nonzero activation
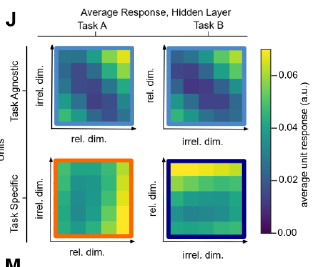
How do neural networks code for different contexts?
anticorrelated weights from context to hidden units
rich
lazy
representations should be mixed-selective and respond to both task and input stimuli
-> In the rich regime, hidden layer
activativations should be task-specific
Neural Network:
selectivity: Nonzero activation
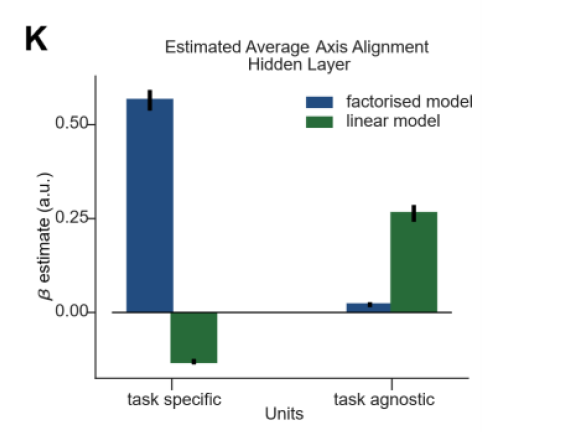
How do neural networks code for different contexts?
anticorrelated weights from context to hidden units
representations should be mixed-selective and respond to both task and input stimuli
-> In the rich regime, hidden layer
activativations should be task-specific
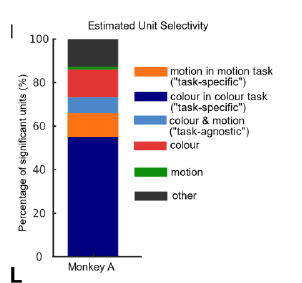
Monkey A:
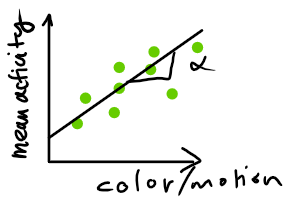
How do neural networks code for different contexts?
anticorrelated weights from context to hidden units
representations should be mixed-selective and respond to both task and input stimuli
-> In the rich regime, hidden layer
activativations should be task-specific
Monkey A:
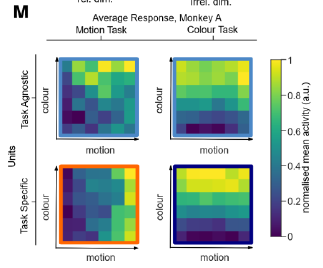
How do neural networks code for different contexts?
anticorrelated weights from context to hidden units
representations should be mixed-selective and respond to both task and input stimuli
-> In the rich regime, hidden layer
activativations should be task-specific
Monkey A:
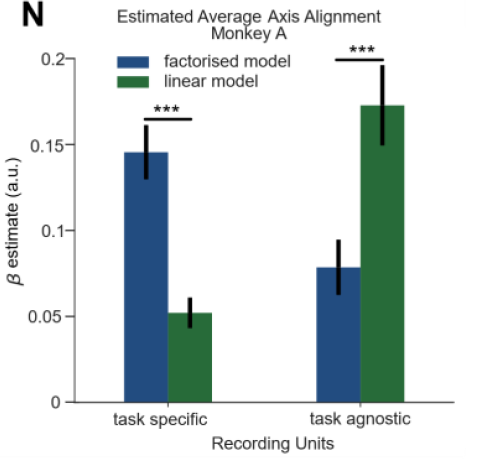
How do neural networks code for different contexts?
anticorrelated weights from context to hidden units
representations should be mixed-selective and respond to both task and input stimuli
-> In the rich regime, hidden layer
activativations should be task-specific
Monkey A:
task-specific: orthogonal/factorized
task-agnostic: linear
Conclusion: three main contributions
- formalize how rich and lazy learning regime are expressed in a Deep NN in a canonical context-dependent classification paradigm
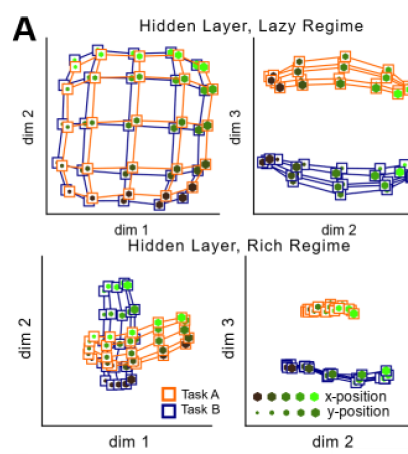
Conclusion: three main contributions
- formalize how rich and lazy learning regime are expressed in a Deep NN in a canonical context-dependent classification paradigm
- asses these predictions in humans using behavioral testing and neuroimaging
Conclusion: three main contributions
- formalize how rich and lazy learning regime are expressed in a Deep NN in a canonical context-dependent classification paradigm
- asses these predictions in humans using behavioral testing and neuroimaging
- insight into the computational principles of context dependent decision making
JC Merger 2022-04-11
By Alexandre René




