
Gradient Boosting
Hui Hu Ph.D.
Department of Epidemiology
College of Public Health and Health Professions & College of Medicine
huihu@ufl.edu
November 15, 2018
GMS 6803 Data Science for Clinical Research
Theory and Algorithms
Implementations and Comparisons
Theory and Algorithms
- Ensembles (combine models) can give you a boost in prediction accuracy
- Three most popular ensemble methods:
- Bagging: build multiple models (usually the same type) from different subsamples of the training dataset
- Boosting: build multiple models (usually the same type) each of which learns to fix the prediction errors of a prior model in the sequence of models
- Voting: build multiple models (usually different types) and simple statistics (e.g. mean) are used to combine predictions
Ensembles
Bagging
- Take multiple samples from your training dataset (with replacement) and train a model for each sample
- The final output prediction is averaged across the predictions of all of the sub-models
- Performs best with algorithms that have high variance (e.g. decision trees)
- Run in parallel because each bootstrap sample does not depend on others
- Common algorithms:
- bagged decision trees
- random forest
with reduced correlation between individual classifiers
a random subset of features are considered for each split
- extra trees
further reduce correlation between individual classifiers
cut-point is selected fully at random, independently of the outcome
Bootstrap Aggregation
Boosting
- Creates a sequence of models that attempt to correct the mistakes of the models before them in the sequence
-
Build a model from the training data, then create a second model that attempts to correct the errors from the first model
-
Once created, the models make predictions which may be weighted by their demonstrated accuracy and the results are combined to create a final output prediction
-
Models are added until the training set is predicted perfectly or a maximum number of models are added
- Works in sequential manner
Common Algorithms
AdaBoost (Adaptive Boosting)
- Weight instances in the dataset by how easy or difficult they are to predict
-
Allow the algorithm to pay more or less attention to them in the construction of subsequent models
Gradient Boosting (Stochastic Gradient Boosting)
- Boosting algorithms as iterative functional gradient descent algorithms
- At each iteration of the algorithm, a base learner is fit on a subsample of the training set drawn at random without replacement
AdaBoost (Adaptive Boosting)
- Initialize observation weights:
- For m=1 to M
- fit a classifier Gm(x) to training data
- compute:
- compute:
- set:
w_i=1/N
err_m= {{\sum^N_{i=1}w_iI(y_i \ne G_m(x_i))}\over {\sum^N_{i=1}w_i}}
\alpha_m=log({1-err_m\over err_m})
w_i<-w_i\times exp[\alpha_m \times I(y_i \ne G_M(x_i))], i=1,2,...,N
AdaBoost (Adaptive Boosting)
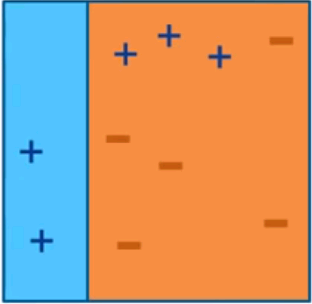

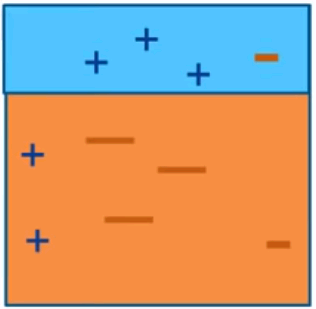
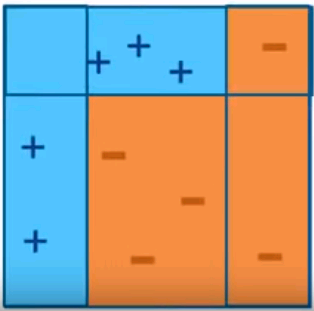
Iteration 1
Iteration 2
Iteration 3
Final Model
Intuitive sense: weights will be increased for incorrectly classified observation
- give more focus to next iteration
- weights will be reduced for correctly classified observation
Gradient Boosting
- Instead of reweighting observations in adaptive boosting, gradient boosting make some corrections to prediction errors directly
- Learn a model -> compute the error residual -> learn to predict the residual
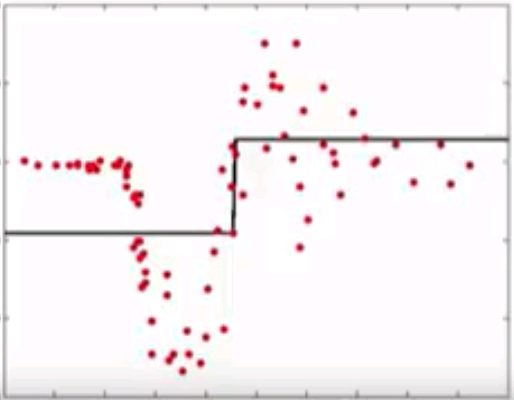
Initial model
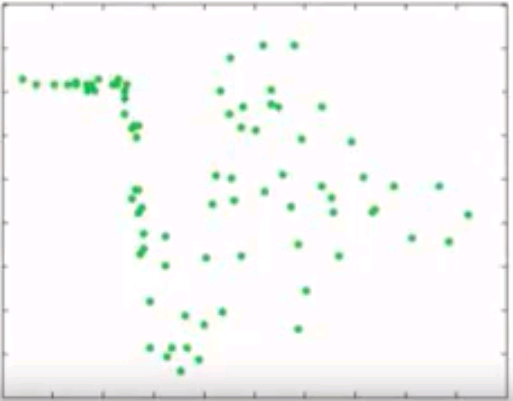
Compute residuals
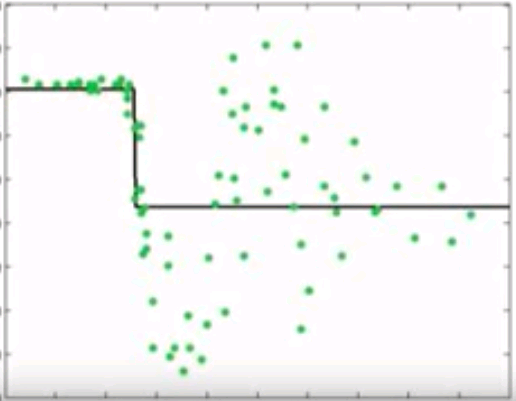
Model residuals
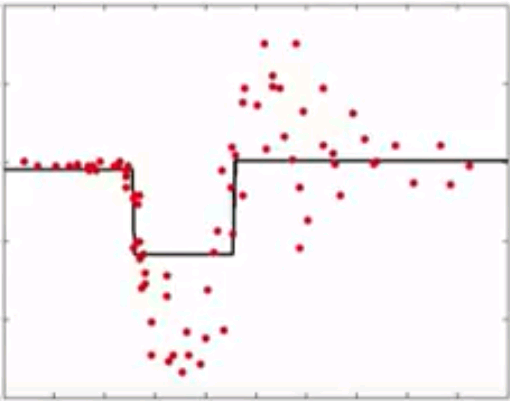
Combinations
...
Gradient Boosting
- Learn sequence of models
- Combination of models is increasingly accurate and increasingly complex
Model predictions


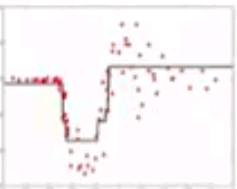
Residuals



...
Implementations and Comparisons



03/2014
01/2017
04/2017
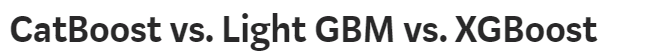
Comparisons
- XGBoost uses presorted algorithm and histogram-based algorithm to compute the best split, while LightGBM uses gradient-based one-side sampling to filter out observations for finding a split value
- How they handle categorical variables:
- XGBoost cannot handle categorical features by itself, therefore one has to perform various encodings such as label encoding, mean encoding or one-hot encoding before supplying categorical data to XGBoost
- LightGBM can handle categorical features by taking the input of feature names. It does not convert to one-hot coding, and is much faster than one-hot coding. LGBM uses a special algorithm to find the split value of categorical features
- CatBoost has the flexibility of giving indices of categorical columns so that it can be one-hot encoded or encoded using an efficient method that is similar to mean encoding
Comparisons
Example
import pandas as pd, numpy as np, time
from sklearn.model_selection import train_test_split
data = pd.read_csv("flights.csv")
data = data.sample(frac = 0.1, random_state=10)
data = data[["MONTH","DAY","DAY_OF_WEEK","AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT",
"ORIGIN_AIRPORT","AIR_TIME", "DEPARTURE_TIME","DISTANCE","ARRIVAL_DELAY"]]
data.dropna(inplace=True)
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"]>10)*1
cols = ["AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT","ORIGIN_AIRPORT"]
for item in cols:
data[item] = data[item].astype("category").cat.codes +1
train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"],
random_state=10, test_size=0.25)
- A Kaggle dataset of flight delays for the year 2015.
- Approximately 5 million rows. A 10% subset of this data ~ 500k rows.
- Features:
- MONTH, DAY, DAY_OF_WEEK: int
- AIRLINE and FLIGHT_NUMBER: int
- ORIGIN_AIRPORT and DESTINATION_AIRPORT: string
- DEPARTURE_TIME: float
- ARRIVAL_DELAY: binary outcome indicating delay of more than 10 minutes
- DISTANCE and AIR_TIME: float
Training
75%
Testing
25%
3-fold CV
Parameter Tuning
XGBoost
import xgboost as xgb
from sklearn import metrics
def auc(m, train, test):
return (metrics.roc_auc_score(y_train,m.predict_proba(train)[:,1]),
metrics.roc_auc_score(y_test,m.predict_proba(test)[:,1]))
# Parameter Tuning
model = xgb.XGBClassifier()
param_dist = {"max_depth": [10,30,50],
"min_child_weight" : [1,3,6],
"n_estimators": [200],
"learning_rate": [0.05, 0.1,0.16],}
grid_search = GridSearchCV(model, param_grid=param_dist, cv = 3,
verbose=10, n_jobs=-1)
grid_search.fit(train, y_train)
grid_search.best_estimator_
model = xgb.XGBClassifier(max_depth=50, min_child_weight=1, n_estimators=200,\
n_jobs=-1 , verbose=1,learning_rate=0.16)
model.fit(train,y_train)
auc(model, train, test)LightGBM
import lightgbm as lgb
from sklearn import metrics
def auc2(m, train, test):
return (metrics.roc_auc_score(y_train,m.predict(train)),
metrics.roc_auc_score(y_test,m.predict(test)))
lg = lgb.LGBMClassifier(silent=False)
param_dist = {"max_depth": [25,50, 75],
"learning_rate" : [0.01,0.05,0.1],
"num_leaves": [300,900,1200],
"n_estimators": [200]
}
grid_search = GridSearchCV(lg, n_jobs=-1, param_grid=param_dist, cv = 3, scoring="roc_auc", verbose=5)
grid_search.fit(train,y_train)
grid_search.best_estimator_
d_train = lgb.Dataset(train, label=y_train)
params = {"max_depth": 50, "learning_rate" : 0.1, "num_leaves": 900, "n_estimators": 300}
# Without Categorical Features
model2 = lgb.train(params, d_train)
auc2(model2, train, test)
#With Catgeorical Features
cate_features_name = ["MONTH","DAY","DAY_OF_WEEK","AIRLINE","DESTINATION_AIRPORT",
"ORIGIN_AIRPORT"]
model2 = lgb.train(params, d_train, categorical_feature = cate_features_name)
auc2(model2, train, test)CatBoost
import catboost as cb
cat_features_index = [0,1,2,3,4,5,6]
def auc(m, train, test):
return (metrics.roc_auc_score(y_train,m.predict_proba(train)[:,1]),
metrics.roc_auc_score(y_test,m.predict_proba(test)[:,1]))
params = {'depth': [4, 7, 10],
'learning_rate' : [0.03, 0.1, 0.15],
'l2_leaf_reg': [1,4,9],
'iterations': [300]}
cb = cb.CatBoostClassifier()
cb_model = GridSearchCV(cb, params, scoring="roc_auc", cv = 3)
cb_model.fit(train, y_train)
#Without Categorical features
clf = cb.CatBoostClassifier(eval_metric="AUC", depth=10, iterations= 500, l2_leaf_reg= 9, learning_rate= 0.15)
clf.fit(train,y_train)
auc(clf, train, test)
#With Categorical features
clf = cb.CatBoostClassifier(eval_metric="AUC",one_hot_max_size=31, \
depth=10, iterations= 500, l2_leaf_reg= 9, learning_rate= 0.15)
clf.fit(train,y_train, cat_features= cat_features_index)
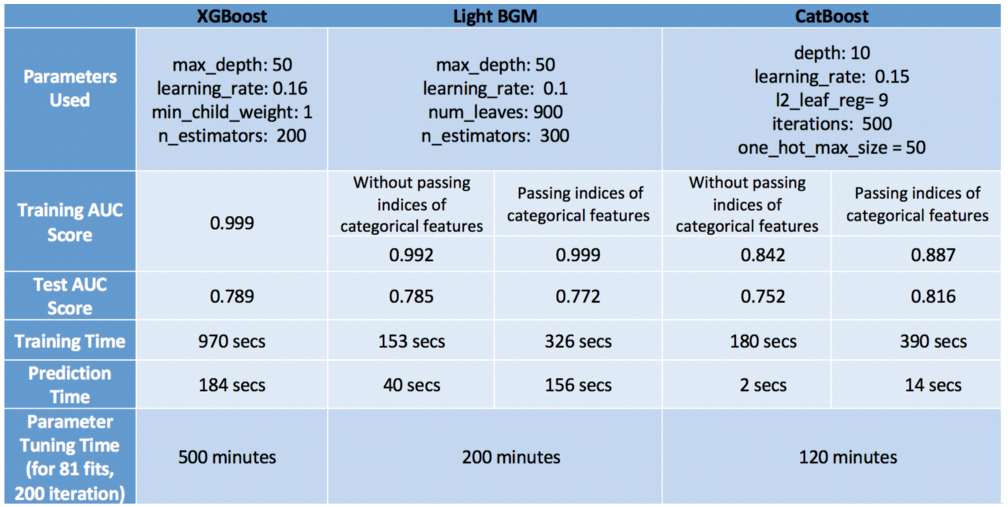
auc(clf, train, test)Performance
Thank you!
Gradient Boosting
By Hui Hu
Gradient Boosting
Slides for the Data Science for Clinical Research guest lecture, Fall 2018




