GMS6847 TRANSLATIONAL RESEARCH & THERAPEUTICS: BENCH, BEDSIDE, COMMUNITY, & POLICY

Identifying Disparities Using Big Data
Hui Hu Ph.D.
Department of Epidemiology
College of Public Health and Health Professions & College of Medicine
huihu@ufl.edu
October 24, 2017
Introduction to Big Data
Big Data and Health Disparities
Introduction to Big Data
Explosion of Data
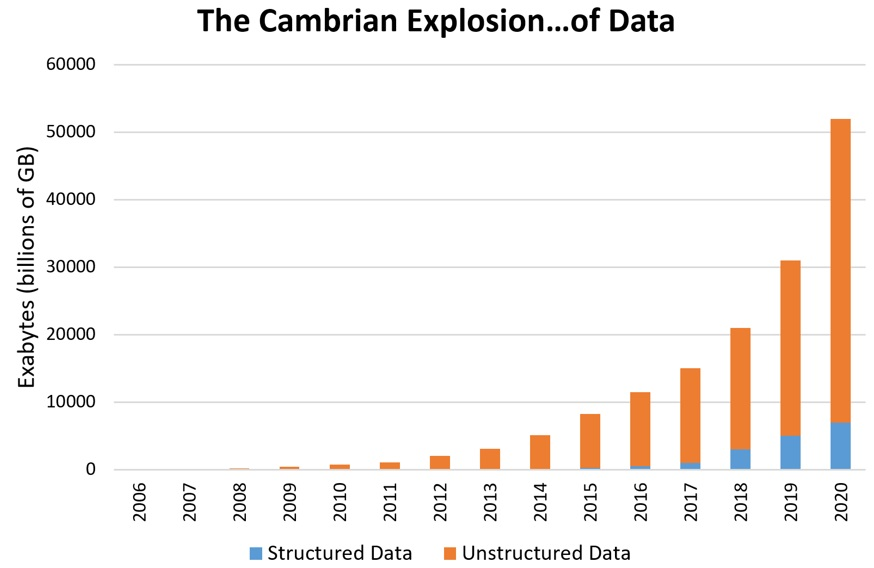
Explosion of Data (continued)
- The increase in amount of data we are generating opens up huge possibilities
- But it comes with problems too:
- where do we have to store all this data?
- and process it too?
Which one(s) of them do you consider as big data?
- Order details for a store
- All orders across hundreds of stores
- A person's stock portfolio
- All stock transactions for the NYSE
What is big data?
- How will you define big data?
- It's a very subjective term, and there is not one definition for big data
- Most people would certainly consider a dataset of several TB to be big data
- A reasonable definition:
Data that are too big to be processed on a single machine

Big data is a loosely defined term used to describe data sets so large and complex that they become awkward to work with using standard statistical software
Challenges with Big Data
- Not just about the size
- Data is created fast
- Data from different sources in various formats
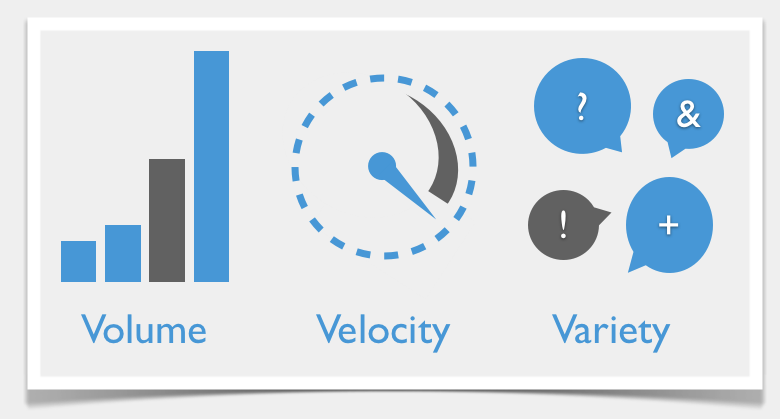
Volume
- Store the data
- which one(s) of the following data do you think worth storing?
transactions, logs, business, user, sensor, medical, social
- Read and process the data efficiently
Variety
- For a long time people stored data in relational databases
- The problem is that to store data in such databases, the data need to be able to fit in pre-defined tables
- Many data we are dealing nowadays are unstructured or semi-structured data
- We want to store the data in its original format so we are not throwing any information away
- e.g. transcribe a call center conversation into text
- we have what people said to customer services representatives
- but if we had the actual recording, later we may able to develop algorithms to interpret the tone of voice
Velocity
- We need to be able to store the data even it's coming in at a rate of TB per day
- if we can't store as it arrives, we have to discard some of the data
- Many recommendation systems were developed based on a variety of data stored which arrives with a high velocity
- Amazon will recommend products to you
- Netflix will recommend movies you might be interested in
Hadoop
- In around 2003, google published papers about their internally used distributed file systems and their processing framework, MapReduce.
- A group tried to reimplement these in open source, and they developed hadoop, which later becomes the core part of today's big data processing platforms
- Hadoop:
- store data: HDFS (Hadoop distributed file system)
- process data: MapReduce
- Data are split and stored in a collection of machines (a cluster), and then the data are processed in where they are stored rather than retrieving the data to a central server

Hadoop Ecosystem
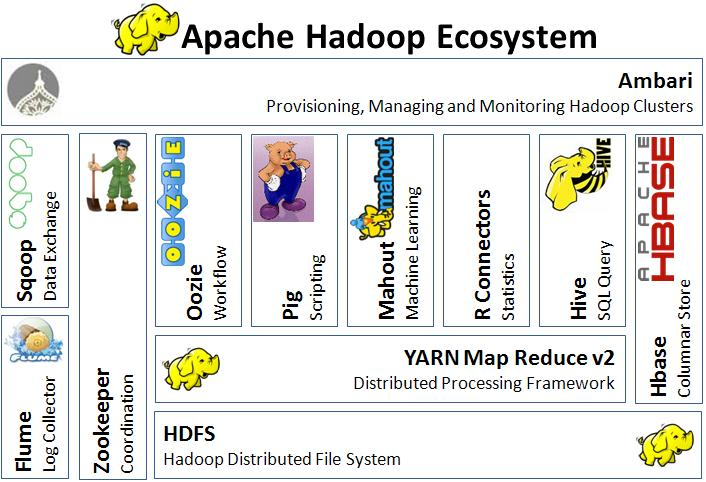
- Some softwares are intended to make it easier to load data into the Hadoop cluster
- Many are designed to make Hadoop easier to use
HDFS and MapReduce
HDFS
- Data are stored in HDFS: Hadoop distributed file system
dat.txt (150 MB)
64 MB
64 MB
22 MB
blk_1
blk_2
blk_3

blk_1
blk_2
blk_3
Datanodes
Namenode
Is there a problem?
blk_1
blk_2
blk_3
- Network failure
- Disk failure on datanodes
- Disk failure on the namenode
Data Redundancy
blk_1
blk_2
blk_3
Hadoop replicates each block three times
blk_1
blk_1
blk_2
blk_2
blk_3
blk_3
What if there is a problem with the namenode?
blk_1
blk_2
blk_3
- If a network failure: data inaccessible
- If a disk failure: data lost forever (no way to know which block belongs to which file)
blk_1
blk_1
blk_2
blk_2
blk_3
blk_3
NFS
MapReduce
Designed to process data in parallel
Example
- National hospital inpatient cost
- want to calculate the cost per city for the year
| 2017-01-01 | Miami | 2300.24 |
| 2017-01-01 | Gainesville | 3600.23 |
| 2017-01-02 | Jacksonville | 1900.34 |
| 2017-01-02 | Miami | 8900.45 |
- Key-value pairs (Hashtable)
- What are the problems if you have 1 TB data?
- You may run out of memory, and computers will need a long time to read and process the data.
Example (continued)
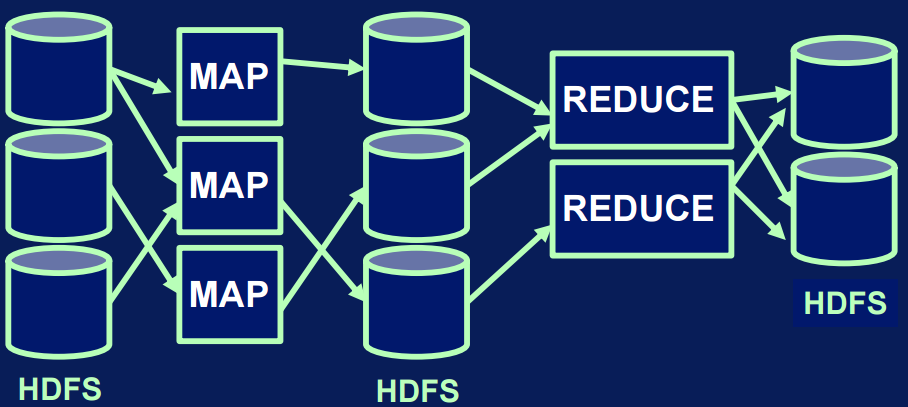
Mappers
Miami
2300.24
NYC
9123.45
Boston
8123.45
LA
3123.45
Reducers
NYC, LA
Miami, Boston
NYC
7123.45
Boston
6123.45
NYC
7123.45
Boston
8123.45
Boston
6123.45
LA
3123.45
Miami
2300.24
NYC
9123.45
Example (continued)
Mappers
Intermediate records (key, value)
Shuffle and sort
Reducers
(key, value)
Results
blk_1
blk_2
blk_3
blk_1
blk_1
blk_2
blk_2
blk_3
blk_3
Job Tracker
Task Trackers
Spark
Why Spark?
- Shortcomings of Hadoop MapReduce:
- only for map and reduce based computations
- relies on reading data from HDFS (many machine learning uses iterative algorithms that require several reads of the data, which result in a performance bottleneck due to I/O)
- native support for Java only
- no interactive shell support
- no support for streaming
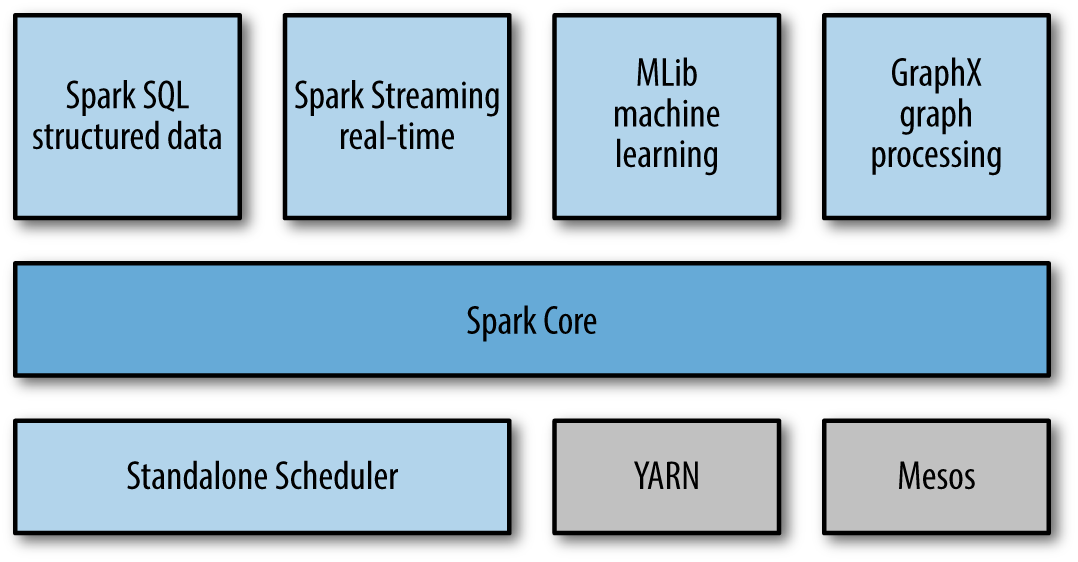
- Advantages of Spark:
- expressive programming model
- in-memory processing
- support for diverse workloads
- interactive shell
The Spark Stack
What is in memory processing?
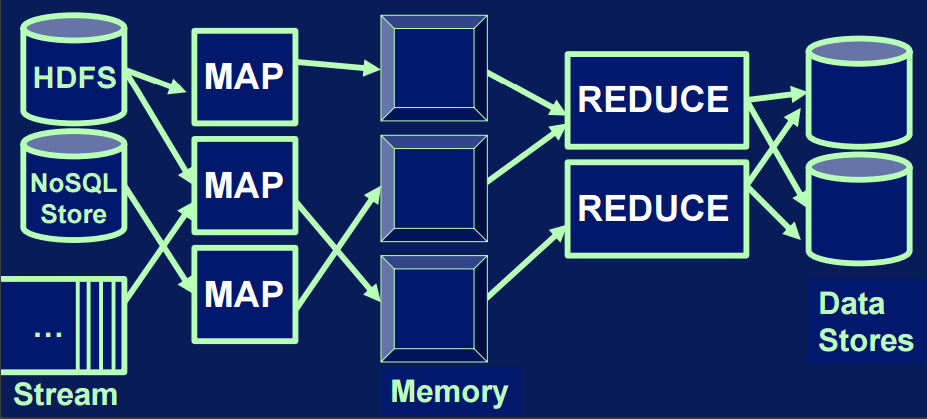
Resilient Distributed Datasets
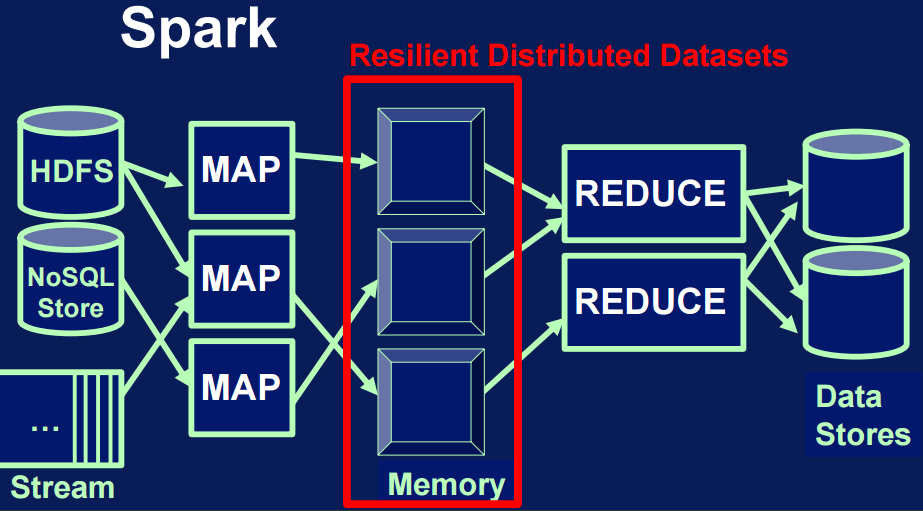
Resilient Distributed Datasets
- Resilient:
- recover from errors: e.g. node failure
- track history of each partition, re-run
- Distributed:
- distributed across the cluster of machines
- divided in partitions, atomic chunks of data
- Dataset:
- data storage created from HDFS, S3, HBase, JSON, text, local hierarchy of folders
- or created transforming another RDD (RDD is immutable)
Big Data and Health Disparities
Opportunities Identified by NIMHD
- To incorporate social determinants information and improve quality of care for underserved populations
- To improve public health surveillance and address health disparities
- To understand etiology and to guide interventions to reduce disparities
Disease registries and EHRs collect limited information on social determinants
Use social media data in public health surveillance and research
- Estimate influenza prevalence:
- some of the earliest studies used web data, e.g. search query volumes (Google's Flu Trends)
- while search queries were the original data sources, social media has since become a popular data source, e.g. blogs and microblogs especially Twitter
- The original motivation for using social media data to estimate influenza prevalence is that it can be estimated in real-time, in contrast to traditional government systems

- Obtained data from Spinn3r during October 2008 to March 2009
- A total of 158,497,700 web and social media items were pulled
- when a lexical match exists to the term "influenze" and "flu" anywhere in its content
- The authors hypothesized that the frequency of blog-world flu posts correlate with a patient reporting influenza-like-illness and the US flu season
- they compared the web and social media data to CDC surveillance reports
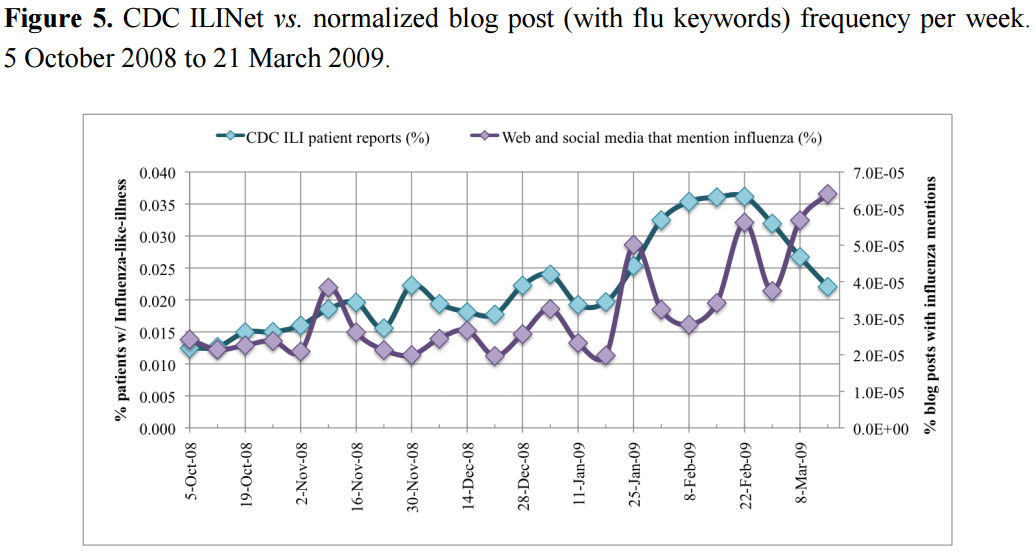
- r=0.545
Pharmacovigilance
- Primarily involves the monitoring of adverse reactions caused by medications
- People discuss their use of prescription drugs, side effects and treatments on social media, which makes social media data unique and robust sources of information about health, drugs, and treatments
- Adverse reaction detection:
- automatic classification of user posts to determine if adverse reactions are mentioned
- data imbalance in social media data is challenging to train supervised learning models
- Discovering drug-adverse reaction associations:
- extract specific adverse reaction mentions and identify association between specific drugs and adverse reactions
Behavioral health
- Another rapidly expanding area is using social media data to understand behaviors that affect health
- behavioral medicine may play a prominent role in the digital surveillance revolution given the large knowledge gap in many areas of behavioral medicine
- Smoking and substance abuse:
- to understand availability of and interest in various nicotine and tobacco products such as electronic cigarettes
- to understand smoking cessation and online social support for cessation
- trends in alcohol use, problem drinking, prescription drug abuse
- Diet and fitness:
- analyze food consumption patterns using data from Instagram and Twitter
- study physical activities in Twitter by measuring outcomes of fitness goals
All of Us


GMS6847-Fall2017-GuestLecture
By Hui Hu
GMS6847-Fall2017-GuestLecture
Slides for Guest Lecture, Fall 2017, GMS6847, Translational Research and Therapeutics: Bench, Bedside, Community, & Policy




