Gestion des données de l'entreprise

Cédric BRASSEUR
mis à jour le 12/05/2026
Cédric BRASSEUR
- Ancien étudiant de l'Exia.cesi
- 4 ans consultant chez Amaris, placé chez Euro Information Dev
- Auto-entrepreneur depuis début 2020 (Création de sites web, applications mobiles & formateur)
Et vous ?
- Nom, prénom
- Etudes réalisées
- Niveau estimé en SQL avancé
Plan du cours
-
Les structures de données existantes
- JSON, XML,...
- SGBD(R), NoSQL,...
- Relationnel, entité-association, ORM
-
Optimisation des données
- Types de données
- Stockage des données
- Index
- Optimisation de requêtes
-
Administration de la base de données
- Transactions
- Procédures stockées
- Triggers
- Gestion des utilisateurs
- Introduction au Big Data

Data
Objectifs de la formation
- Choisir le bon type de données
- Améliorer la performance de vos accès aux données
- Administrer une base de données
- Identifier les enjeux du BigData
- Introduction à MongoDB

Les structures de données existantes
Les structures de stockage de données existantes
Toute entreprise a besoin de sauvegarder ses données.
Il existe plusieurs structures de sauvegardes :
- Les structures JSON et XML,
- Le SGBD(R) et le NoSQL
- Le modèle relationnel, entité-association et les ORM

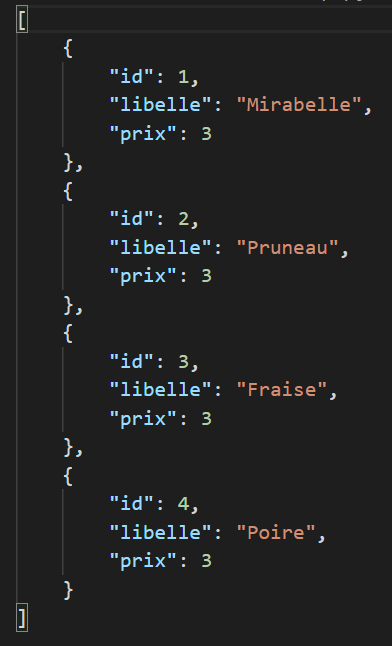
La structure JSON
{
"premierNoeudTableauObject": [
{
"premierObjet" : {
"nom": "BRASSEUR",
"prenom": "Cédric",
},
},
{
"secondObjet" : {
"nom": "JEAN",
"prenom": "Sébastien",
}
}
],
"secondNoeudSimpleValeur" : 10,
}Le JSON permet de stocker des données comme on le souhaite, sous forme de tableaux, d'objets ou de simple association clé => valeur.
Avantages
- Lecture rapide et efficace sans accès réseau (potentiellement)
- Format lisible par n'importe quel être humain et n'importe quelle machine (OS)
- Utilisable nativement avec un grand nombre de technologies
- Stockage de différents types de données
- Syntaxe simple et efficace
Inconvénients
JSON (Avantages / Inconvénients)
- Il faut sécuriser soit même les données sensibles
- Pas d'identification précise des données (sous forme de balise par exemple), la structure doit donc être connue avant utilisation.
- Une erreur de code peut vite détruire l'intégrité de vos données
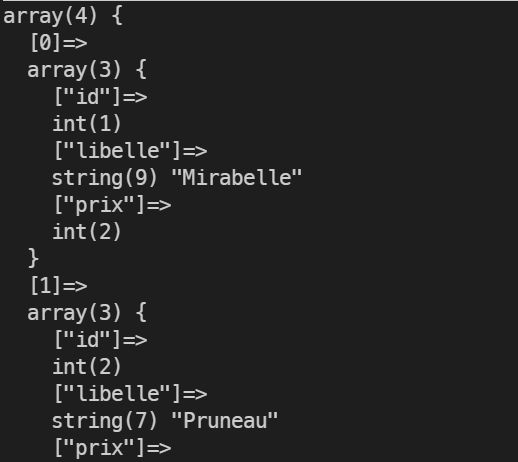
JSON et PHP
Il est simple de travailler avec le format JSON :


JSON et PHP
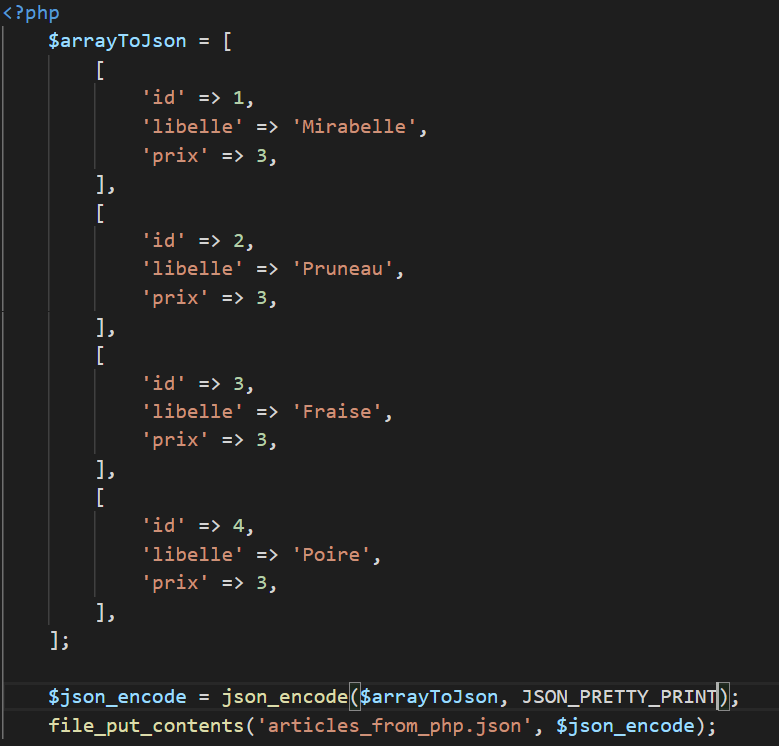
De même pour écrire du JSON :
La structure XML
<?xml version="1.0" encoding="ISO-8859-1" standalone="yes"?>
<message>
<expediteur>
<identite>
<prenom>Guillaume</prenom>
<nom>Charpentier</nom>
<email>gcharpen@etudiant.univ-mlv.fr</email>
</identite>
</expediteur>
<destinataire>
<identite>
<prenom>Gérard</prenom>
<nom>Dupont</nom>
<email>gerarddupont@provider.com</email>
</identite>
</destinataire>
<message>mon message</message>
</message>Le XML permet de stocker des données sous forme d'arbre et de nœuds. L'exemple ici représente un message avec les informations de l'expéditeur et du destinataire (ainsi que le contenu)
Avantages
- Lecture rapide et efficace, car ne nécessite que l'accès au fichier XML (pas de connexion, pas de serveur,...)
- Gestion des données souple avec des nœuds
- Interprétable très simplement dans la plupart des langages
- Conversion vers d'autres types très facile (PDF, CSV,...)
- Langage d'interrogation disponible (XPath, XQuery,...)
Inconvénients
XML (Avantages / Inconvénients)
- Plus il y a de données à traiter, plus les traitements sont longs
- Pour "modéliser" tout un projet, la structure XML a ses limites
- Le code gérant vos données doit être carré, une erreur et on peut perdre l'intégrité des données
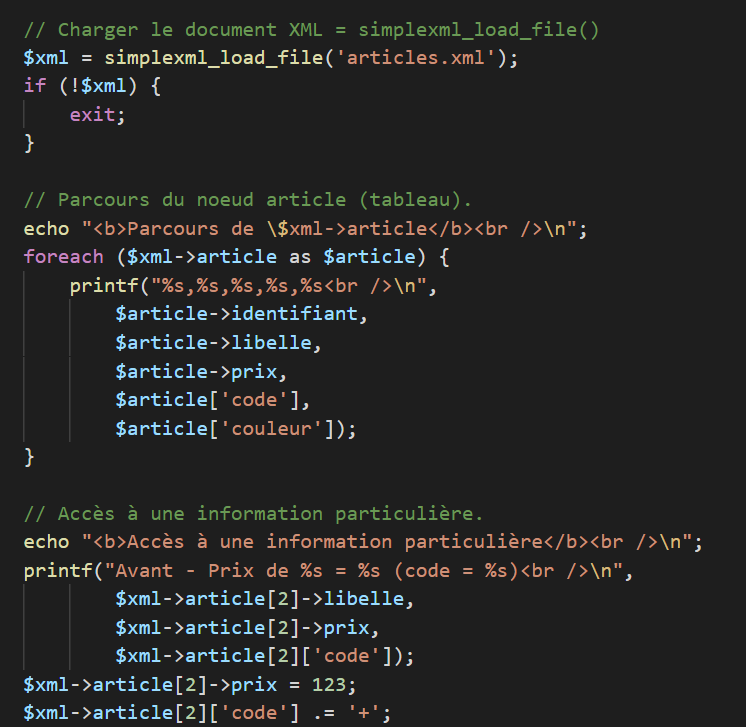
XML et PHP
Le XML est une structure de stockage de données qui peut être géré en PHP, pour la création, la lecture ou la modification d'un fichier XML depuis PHP.
Exercice (rapide)
Réalisez une opération d'écriture et une opération de lecture d'un fichier XML ou JSON, à votre convenance. Avec quelques données de tests, pas la peine de faire une grosse structure.
De même, vous pouvez choisir la technologie.
Vous avez 20 minutes, ce sera normalement largement suffisant.
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
Base de données
-
Structure permettant d'agencer et de sauvegarder des données relatives à un ou plusieurs projets
-
Cette structure peut être relationnelle ou non (SGBD =/= SGBDR)
-
Les données doivent être protégées mais accessibles en continue
-
Nous allons utiliser SQL Server (T-SQL).
BDD
Base de données
Table
Table
| Champ 1 | Champ2 | Champ2 | |
|---|---|---|---|
| Enregistrement 1 | data_c1_e1 | data_c2_e1 | data_c3_e1 |
| Enregistrement 2 | data_c1_e2 | data_c2_e2 | data_c3_e2 |
| Enregistrement 3 | data_c1_e3 | data_c3_e3 | data_c3_e3 |
| Champ 1 | Champ2 | Champ2 | |
|---|---|---|---|
| Enregistrement 1 | data_c1_e1 | data_c2_e1 | data_c3_e1 |
| Enregistrement 2 | data_c1_e2 | data_c2_e2 | data_c3_e2 |
| Enregistrement 3 | data_c1_e3 | data_c3_e3 | data_c3_e3 |
Lexique
Base de données relationnelle
Les données sont liées les unes aux autres entre les tables.
Ceci permettant d'avoir des données atomiques dans les tables tout en pouvant lier ses données grâce à des jointures.
| Auteur |
|---|
| id |
| ... |
| Articles |
|---|
| id |
| auteur_id |
| date_parution_id |
| Date |
|---|
| id |
| jour_nom |
Rappel : Modéliser sa base de données
Pour modéliser correctement sa base de données il est fortement conseillé d'utiliser une méthode de modélisation.
! MERISE !
Ce n'est pas l'objet du cours, mais n'hésitez pas à demander des explications si ce n'est pas connu avant la formation
ORM
Object Relational Mapping : Permet de traduire les tables et relations en objets directement, ou traduire des objets et leurs liens en tables et relations.
Souvent très pratique pour le gain de temps qu'il procure.
Mais peut parfois s'avérer inadapté à certains cas d'utilisation complexe des données.
Exemple live avec Entity (.Net)
Exercice - ORM
Réalisez un ORM pour réaliser des opérations CRUD sur un système :
L'objectif est de créer 3 objets :
- Order (Id, Created, Items)
- OrderItem (Id, Quantity, Product)
- Product (Id, Price, Description)
Puis réaliser des opérations de CRUD sur ces différents objets depuis votre Program.cs. Si besoin, vous pouvez vous aider de ce tuto : https://softchris.github.io/pages/dotnet-orm.html#create-the-database (A adapter quand même un peu pour que ça fonctionne !)
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
NoSQL - Petite introduction
Le NoSQL est de plus en plus utilisé pour répondre aux enjeux du BigData (Utilisation de données massive et diverses, en continu à travers le monde : réseaux sociaux, pubs ciblées,...)
Le fonctionnement est différent d'un SGBDR, les données ne respectent plus un schéma particulier et elles sont stockées sous forme de document (ou graphes).
Ceci ayant plusieurs avantages par rapport à un SGBDR :
- Un accès plus rapide aux données dans un volume important et varié de données
- Simplicité de déploiement dans des environnements distribués
Comment bien choisir ?
Plusieurs axes sont à prendre en compte afin de bien choisir la structure de données adaptée à votre besoin :
- Le besoin en termes de temps de réponse
- La quantité des données à stocker
- La complexité du modèle de données à mettre en place
- Le besoin d'un accès distribué des données (microservices)
- La sécurité nécessaire
- Le besoin de scalabilité et le besoin de réplication
- Les connaissances de l'équipe projet
Comment bien choisir ?
Eric A. Brewer (2000) a formalisé un théorème reposant sur 3 propriétés des bases de données (relationnelles, NoSQL et autres) :
- Consistency (Cohérence) : Une donnée n'a qu'un seul état et doit être cohérent quelque soit la requête
- Availability (Disponibilité) : La donnée doit être disponible à tout instant
- Partition Tolerance (Distribution) : Quel que soit le nombre de serveurs dans le cluster, toute requête doit fournir un résultat cohérent
Le théorème de CAP :
Dans toute base de données, vous ne pouvez respecter au plus que 2 propriétés parmi la cohérence, la disponibilité et la distribution.
Les bases du SQL
Installation SQL Server
D'abord, il faut installer l'agent SQL, puis l'interface Mangement studio.
Ou, pour une installation plus rapide, voir ici :
Agent SQL : https://www.microsoft.com/fr-fr/sql-server/sql-server-downloads (choisir SQL Server 2022 Express)
Management studio Express :
Pour MacOS :
Vous pouvez utiliser Azure Data Studio
Mise en place des bases d'exercices
Nous allons utiliser une base proposée par Microsoft pour avoir une base contenant quelques données et respectant les conventions SQL.
Voici le lien de téléchargement : https://docs.microsoft.com/fr-fr/sql/samples/adventureworks-install-configure?view=sql-server-ver15&tabs=ssms
Envoyer le script de création de la base de données AnimalDatabase (!! MySQL !!) que l'on utilisera plus tard dans la formation.
(également pour l'évaluation)
On fera ça plus tard...
Le SQL présentation rapide
- Langage de communication avec une base de données,
- Découle en général du modèle MERISE,
- Opérations CRUD, (Que l'on revoit juste après)
- Le T-SQL (ou PL-SQL) permettant le SQL Avancé et les opérations plus complexes.
Rappels : CRUD et opérations basiques
Nous allons voir ensemble plusieurs opérations possibles sur une table.
C
R
U
D
reate : Création de nouveaux éléments dans la BDD
ead : Lecture d'éléments dans la BDD
pdate : Modification dans la BDD
elete : Suppression dans la BDD
La création de base de données
Comme vu avec Merise, nous pouvons créer une base de données (via le script de l'outil, ou soit-même)
CREATE DATABASE DatabaseNameIF NOT EXISTS (select * from sys.databases where name = 'Test’)
BEGIN
CREATE DATABASE Test
SELECT 'Database succesfully created’ AS ReturnMsg
END
ELSE
SELECT 'Database already exists' AS ReturnMsg
Création d'une base de données sans vérification d'existance
Création avec vérification d'existance (SQL Server)
Création avec vérification d'existance (MySQL)
CREATE DATABASE IF NOT EXISTS DatabaseNameLa création d'une table
Nous pouvons également créer une table
CREATE TABLE auteurs (
id int PRIMARY KEY IDENTITY(1,1), -- On reverra après la notion de clés
nom varchar(50) NOT NULL,
prenom varchar(50) NOT NULL,
date_naissance DATE
)Table auteur
| Auteur |
|---|
| id |
| nom |
| prenom |
| date_naissance |
Les normes de nommage d'une table
- Débute par une majuscule,
- Nom représentatif,
- Un seul mot si possible,
- Singulier,
- Préfixer le nom de la table par un trigramme pour les grosses BDD
Exemple : Employee (ou emp_employee)
Attention, le trigramme est plus utilisé pour regrouper par sous ensemble de tables (par exemples les tables liées à la commande commenceront par cmd_XXX)
Les normes de nommage d'un champ
- Commence par une minuscule
- Préfixer avec un trigramme de la table
- Différencier les types spéciaux (ex date)
- Réutiliser le nom de la table référence pour une clé étrangère
Exemple : emp_id
Aujourd'hui, je ne respecte plus cette norme de nommage, sauf pour les id. Mais ça reste la norme actuelle.
(Moi, je mets name par exemple et pas aut_name)
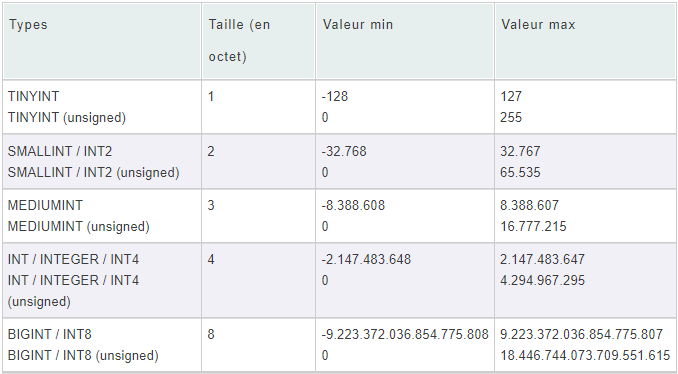
Les types numériques
Voici un ensemble de types numériques à connaître :
- int
- bigint
- numeric
- bit
- smallint
- decimal
- tinyint
- float
Le type numérique
Un des type les plus impactant, car souvent le moins bien géré, est le type numérique.
Voici les informations qu'il faut savoir (pas au chiffre près) pour ces types :
Le type numérique
Il y a plusieurs choix pour gérer les nombres à virgules, mais ils ont un objectif différent :
- Int : Entiers simples.
- Float : Nombres réels (rapides, mais approximatifs).
- Decimal : Nombres réels précis (finances).
- Numeric : Type générique pour tous les nombres.
Mais en soit, pour l'instant, si on veut un type avec virgule, on va mettre du decimal(7,2) disant qu'on aura 7 chiffres en tout, DONT 2 derrière la virgule (précision)
Les types dates
Voici un ensemble de types de dates à connaître :
- Date : 2024-12-19
- Datetime : 2024-12-19 15:30:45
- Smalldatetime : 2024-12-19 15:30
- Time : 15:30:45
Les types textes
Voici un ensemble de types de textes à connaître :
- char (taille fixe, souvent pour un charactère)
- varchar (version 2, dynamique par défaut)
- nchar (unicode)
- nvarchar (unicode)
Les conversions de types dans le SQL
Tips pour les dates (format) :
https://www.mssqltips.com/sqlservertip/1145/date-and-time-conversions-using-sql-server/
Exemple conversions
CONVERT(VARCHAR, dd.DayNumberOfMonth); -- On converti une date en chaîne
CONVERT(DATETIME,'04/28/2013'); -- On converti une chaîne en date
CONVERT(VARCHAR,fis.OrderDate, 101); -- On converti une date en chaîne, avec un format (101)
CAST(fis.OrderDate AS varchar); -- On cast (brutal) une date en chaîneLa sélection de données
Pour sélectionner des données, nous utiliserons le SELECT, qui contient plusieurs options que l'on va aborder au fur et à mesure.
SELECT *
FROM Pays
SELECT p_name, p_size
FROM Pays
SELECT TOP 10 *
FROM Pays
SELECT DISTINCT *
FROM Pays
SELECT *
FROM Pays
WHERE p_name = 'France'Exemples simples
SELECT *
FROM table
WHERE condition
GROUP BY expression
HAVING condition { UNION | INTERSECT | EXCEPT }
ORDER BY expression
LIMIT count
OFFSET start
Les différentes options
La sélection de données
Pour sélectionner des données, nous utiliserons le SELECT, qui contient plusieurs options que l'on va aborder au fur et à mesure.
SELECT emp_lastname, CONVERT(DECIMAL(7,2), AVG(emp_salary)) AS AverageSalary
FROM Employee
WHERE emp_salary >= 25000 -- Filtre des données principales
GROUP BY emp_lastname -- Regroupement des données par emp_lastname
HAVING CONVERT(DECIMAL(7,2), AVG(emp_salary)) >= 31000 -- Filtre après aggrégation
ORDER BY AverageSalary -- Tri des données, par défaut, c'est ASC (ascendant)
Exemples simples
L'ajout de données
Pour l'insertion de données, l'opération SQL concernée est l'INSERT. Il y a plusieurs moyens de réaliser des insertions.
-- Insertion classique
INSERT INTO Pays (p_nom, p_size)
VALUES ('Italie', 200000)
-- Insertion avec colonne implicite
INSERT INTO Pays VALUES ('France', 643801)
-- Insertion multiple
INSERT INTO Pays (p_nom, p_size)
VALUES ('Italie', 200000), ('Allemagne', 400000), ('Belgique', 150000)
Exemples simples
La modification de données
Pour modifier des données on utilise l'opération UPDATE. Pensez à ne jamais oublier de mettre une condition avec un WHERE pour ne pas modifier toute la table.
-- Update classique
INSERT INTO Pays (p_nom, p_size)
VALUES ('Italie', 200000)
-- NE PAS OUBLIER DE METTRE UN WHERE !!!!
UPDATE Pays
SET p_size = 500000
WHERE p_nom = 'Italie'
-- Modifier plusieurs valeurs
UPDATE Pays
SET p_size = 500000, p_nom = 'Pays-Bas'
WHERE p_nom = 'Italie'
Exemples simples
La suppression de données
Afin de supprimer des données, on utilise l'opération DELETE, pensez également à mettre un WHERE pour éviter de supprimer toutes les données.
-- Delete classique
DELETE FROM Pays
-- OU
TRUNCATE TABLE Pays
-- NE PAS OUBLIER DE METTRE UN WHERE !!!!
DELETE FROM Pays
WHERE p_nom = 'Pays-Bas'
Exemples simples
Exercice 1
Création de base de données, création de table, insertion de données, modification de données puis suppression de données. (SIMPLE)
Rappels : Clé primaire / Clé étrangère
La clé primaire étant le champ qui permet de rendre unique chaque champ d'une table, la clé étrangère est la référence à cette clé dans une autre table. Prenons l'exemple de la table article, on souhaite lier un article à un auteur (nom, prénom, date de naissance).
CREATE TABLE auteurs (
id int PRIMARY KEY IDENTITY(1,1),
nom VARCHAR(50) NOT NULL,
prenom VARCHAR(50) NOT NULL,
date_naissance DATE
)ALTER TABLE articles
ADD auteur_id INT;
ALTER TABLE articles ADD CONSTRAINT FOREIGN KEY (auteur_id)
REFERENCES auteur(id);Table auteur
Clé étrangère ajoutée à articles
| Auteur |
|---|
| id |
| ... |
| Articles |
|---|
| id |
| auteur_id |
| ... |
Rappels : Clé primaire / Clé étrangère
Nous pouvons ajouter des clés étrangères à la création de la table (lors du CREATE TABLE) ou après la création de la table (ALTER TABLE)
Clé étrangère ajoutée à articles
| Auteur |
|---|
| id |
| ... |
| Articles |
|---|
| id |
| auteur_id |
| ... |
CREATE TABLE Article (
id int PRIMARY KEY IDENTITY(1,1),
auteur_id INT NOT NULL
CONSTRAINT FK_Article_Auteur
FOREIGN KEY (auteur_id)
REFERENCES Auteur (id)
)Un lien de clé étrangère est TOUJOURS vers une clé primaire d'une autre table
CREATE TABLE Article (
id int PRIMARY KEY AUTO_INCREMENT,
auteur_id INT NOT NULL
CONSTRAINT
FOREIGN KEY (auteur_id)
REFERENCES Auteur (id)
)SQL Server
MySQL
Exercice 2
Création de base de données avec relations, création de tables avec clé primaires / étrangères, insertion de données.
Exercice 3
Requêtes de sélections simples
Pour concaténer deux champs dans un seul, regardez l'opérateur CONCAT
Jointure et relations
Une jointure permet de lier les données d'une table à une autre grâce à la relation de clé primaire / clé étrangère.
Nous allons voir qu'une seule jointure, mais si ça vous intéresse on peut prendre le temps de voir les deux autres les plus courantes.
Jointure interne (présence de clé étrangère obligatoire pour avoir un retour (NOT NULL))
SELECT *
FROM articles ar
INNER JOIN auteurs au ON ar.auteur_id = au.id Une jointure fonctionne TOUJOURS via clé étrangère vers clé primaire dans la condition ON (dans un sens ou l'autre, c'est une égalité...)
Jointure et relations
Un autre exemple sur la base de travail des exercices précédents.
En général, on utilise un alias pour différencier le champ id et simplifier la syntaxe :
-- Attention, il y a deux champs nommé id, un dans Employee, un dans Department
-- Donc on ne peut plus utiliser *
SELECT
Employee.firstname,
Employee.lastname,
Department.name,
Department.location
FROM Employee
INNER JOIN Department ON Employee.dep_id = Department.idSELECT
e.id AS EmployeeId,
d.id AS DepartmentId,
e.firstname,
e.lastname,
d.name,
d.location
FROM Employee e
INNER JOIN Department d ON e.dep_id = d.idJointure et relations
Petite explication schématique du résultat de la requête précédente...
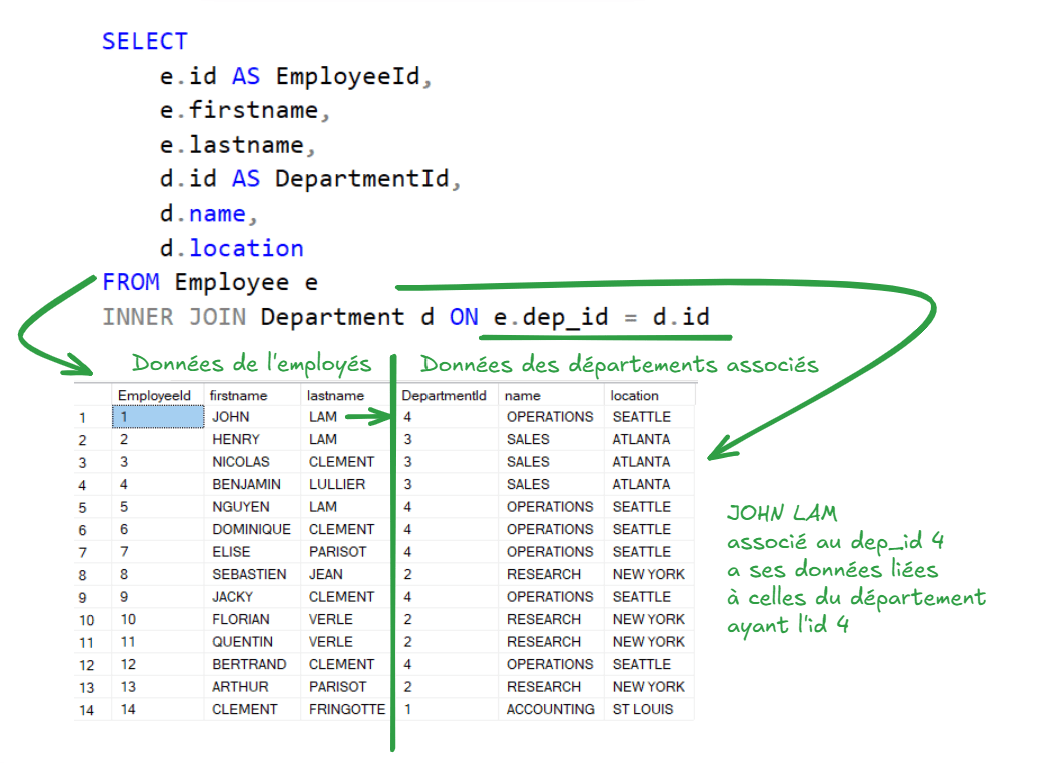
Exercice intermédiaire (CDIIA)
Travail des jointures (simple) pour assimiler le concept de jointure interne avant de passer à la suite.
Je vais vous envoyer :
- script_exercice_jointure.sql
- Exercice_Jointure_subject.md
Les différents types de jointure
- INNER JOIN : Jointure interne
- CROSS JOIN : Jointure croisée (produit cartésien)
- LEFT JOIN : Jointure externe pour la table de gauche même si condition non respectée dans la table de droite
- RIGHT JOIN : Idem LEFT JOIN, mais inversé
- FULL JOIN : Quand la condition est vraie dans au moins une table
- SELF JOIN : Jointure avec la même table (abus langage)
- NATURAL JOIN : automatique sur les champs ayant les mêmes noms (A EVITER !!)
Récap' types de jointures
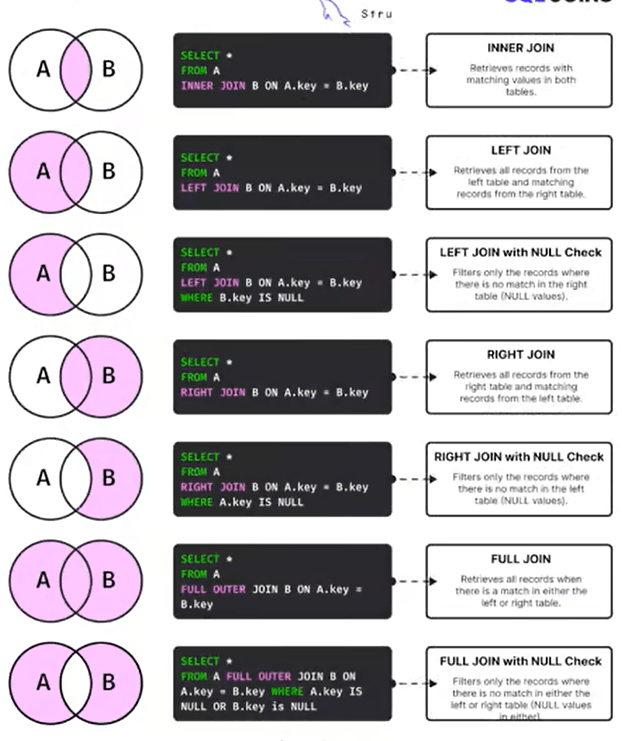
Requête imbriquée
SELECT CONCAT(emp_firstname, ' ', emp_lastname) AS FullName,
emp_salary AS Salary,
(
SELECT MAX(emp_salary) FROM Employee
) AS MaxSalary -- On entoure la sous requête entre parenthèse pour en utiliser le résultat
FROM Employee
Il est possible de faire une requête dans une requête, c'est ce que l'on appelle une requête imbriquée.
Il en existe deux types qui ont chacun leur objectif.
Ici, on a une requête de type 1 que l'on voit plus en détails dans la slide suivante.
C'est aussi possible de faire une requête imbriquée dans une jointure (à des fins d'optimisation). Mais on ne verra pas ça tout de suite...
Requête imbriquée (Type 1)
SELECT
firstname,
salary,
(
SELECT MAX(salary)
FROM Employee
) AS MaxSalary
FROM Employee
Type 1 est un abus de langage que j'utilise pour expliquer les deux possibilités de requêtes imbriquées, ça n'est pas une norme de nommage des requête imbriquée.
La requête imbriquée de type 1 a pour objectif d'afficher la même données pour tous les enregistrement de la requête parente.
Elle s'utilise donc dans un champ et ne doit retourner qu'un seul résultat ! (Utilisation d'agrégation, comme MAX() ou TOP 1)
Requête imbriquée (Type 2)
SELECT COUNT(*) AS NumberOfFamilies FROM
(
SELECT lastname, AVG(Salary) AS AverageSalary
FROM Employee
GROUP BY lastname
) T
Pour la requête de type 2, c'est également un abus de langage...
La requête de type 2, cette fois-ci, c'est une sous requête, un peu comme ci on avait présélectionné un ensemble de données, pour l'utiliser dans une requête parente.
Cette fois, on ne le met pas dans un champ, mais dans le FROM (ou dans le JOIN)
Les vues
GO
CREATE VIEW V_CustomerProduct
AS
SELECT fis.SalesOrderNumber, dcu.FirstName + ' ' + dcu.LastName AS FullName, fis.OrderDate
FROM FactInternetSales fis
INNER JOIN DimCustomer dcu ON dcu.CustomerKey = fis.CustomerKey
INNER JOIN DimProduct dp ON dp.ProductKey = fis.ProductKey
GOUne vue est un objet permettant de prendre le contenu d'une requête de base afin d'en prendre le contenu et le mettre dans une vue. C'est souvent utilisé pour l'administration de base de données ou le dashboarding.
C'est en gros un copié collé de requête, permettant de simplifier la syntaxe d'appels à des éléments de cette vue.
Attention, ça n'optimise en rien votre accès aux données (sauf la syntaxe) :
SELECT * FROM V_CustomerProduct WHERE FullName = 'Cole Watson' Case when
CASE
WHEN YEAR(hire_date) < 1995
THEN 'Vieux'
WHEN YEAR(hire_date) BETWEEN 1995 AND 1997
THEN 'Normal'
ELSE 'Récent'
END
AS LabelDate
FROM EmployeeC'est un opérateur permettant de réaliser une opération comme un switch. Voici un exemple :
En fonction de la date, on affiche une chaîne de caractère différente dans le champ "LabelDate" qui sera retourné par la requête.
Les jointures récursives
On a vu avec Merise que l'on peut faire de la récursivité.
Voici comment ça fonctionne avec un exemple :

SELECT daEnfant.AccountDescription, daParent.AccountDescription
FROM DimAccount daEnfant
INNER JOIN DimAccount daParent ON daEnfant.ParentAccountKey = daParent.AccountKey Exemple (fonctionnel)
Exercice 4 & 5
Les jointures... Ici, nous aurons besoin de la base proposée par Microsoft
Voici le lien de téléchargement : https://docs.microsoft.com/fr-fr/sql/samples/adventureworks-install-configure?view=sql-server-ver15&tabs=ssms
Envoyer le script de création de la base de données AnimalDatabase (!! MySQL !!) que l'on utilisera plus tard dans la formation.
(également pour l'évaluation)
Exercice Pokemon - Exercice 1 (uniquement)
Utilisation de la documentation SQL
Comme pour PHP, vous pouvez vous référer à la documentation SQL afin de trouver des exemples ou la syntaxe pour réaliser les opérations voulues. Nous en avons vu quelques exemples, mais les cas de requêtage en SQL sont presque illimités.
Voici le lien de la documentation : https://sql.sh/
LA DOC ?
C'est réellement ce qui peut vous sauver des heures de recherches inutiles, prenez le reflexe également pour le SQL !
Insertion avec jointure (abus de langage)
INSERT INTO matable (colonnes, ...)
SELECT valeurs, ....
FROM ...
INNER JOIN ...
Comme on l'a vu, une base de données relationnelle s'assure de l'intégrité des données, c'est encore plus important concernant les clés primaires / clés étrangères. Donc quand on fait une insertion, on s'assure d'insérer une donnée qui est liable par la clé.
Première façon de faire, avec un INSERT utilisant le retour d'un SELECT, pensez bien à vous assurer que le nombre de champs de votre sélection correspond au nombre de champs de votre INSERT (ici, on peut même faire de l'insertion multiple)
Insertion avec jointure (abus de langage)
INSERT INTO Employee
VALUES (15, 'JOHN', 'LAM', 'ADMIN', '12-17-1990', 18000, NULL,
(
SELECT TOP 1 dep_id
FROM Department
WHERE dep_location = 'SEATTLE’
)
)Comme on l'a vu, une base de données relationnelle s'assure de l'intégrité des données, c'est encore plus important concernant les clés primaires / clés étrangères. Donc quand on fait une insertion, on s'assure d'insérer une donnée qui est liable par la clé.
Seconde façon, avec une sous requête permettant d'aller récupérer l'identifiant de ce que l'on cherchait à insérer comme clé étrangère.
Notez la présence du TOP 1 permettant de s'assurer de n'avoir qu'un identifiant de clé étrangère dans le retour de la sous requête
Insertion avec jointure (abus de langage)
INSERT INTO salle (nom, date_creation, id_batiment)
SELECT s.nom, CURRENT_DATE(),
(
SELECT id FROM batiment WHERE adresse = 'Mon adresse'
) AS selectedBatiment
FROM batiment b
INNER JOIN salle s ON b.id = s.id_batimentPossibilité avec un INSERT INTO
utilisant le résultat d'un SELECT
Modification avec jointure (abus de langage)
UPDATE Table1
SET Table1.col1 = Table2.col1
FROM Table1 INNER JOIN Table2 ON Table1.Id = Table2.Id
Il en est de même avec les update respectant l'intégrité des clés primaires / étrangères. Ca peut se faire de deux façons.
Première façon de faire, avec un UPDATE avec une table de départ et une jointure dans le FROM sous le SET.
UPDATE Salle
INNER JOIN batiment b ON id_batiment = b.id
SET nom = CONCAT('Salle du batiment avec cette adresse : ', b.adresse)
WHERE b.nombre_etages >= 15
Exemple avec MySQL (pas de FROM)
Exemple avec SQL Server (nécessite un FROM)
Modification avec jointure (abus de langage)
UPDATE Table
SET cle_etrangere = (
SELECT TOP 1 id
FROM TableLiee
WHERE champ_table_liee = 'Condition'
)
WHERE champ_condition_Table_modifiee = '...'
Il en est de même avec les update respectant l'intégrité des clés primaires / étrangères. Ca peut se faire de deux façons.
Seconde façon, avec une sous requête permettant d'aller récupérer l'identifiant de ce que l'on cherchait à modifier comme clé étrangère.
Notez la présence du TOP 1 permettant de s'assurer de n'avoir qu'un identifiant de clé étrangère dans le retour de la sous requête
UPDATE salle
SET nombre_etages = 80
WHERE id_batiment = (SELECT id_batiment WHERE adresse = 'Mon adresse')Exemple avec MySQL
Modification avec jointure (abus de langage)
UPDATE Employee
SET Employee.dep_id = (
SELECT TOP 1 dep_id
FROM Department
WHERE dep_location = 'JERSEY'
)
FROM Department INNER JOIN Employee ON Employee.dep_id = Department.dep_id
WHERE dep_location = 'NEW YORK'
Exemple mixant les deux possibilités...
SQL Server exemple
Suppression avec jointure (abus de langage)
DELETE
t1
FROM
Table2 t2
INNER JOIN Table1 t1 ON (t1. _id = t2._id)
WHERE (…)
De même pour la suppression avec intégrité des clés primaires / étangères
A noter qu'il existe aussi la suppression en cascade, qui permet de supprimer les données liées (par exemple, si on supprime un département, le SGBD va supprimer tous les employés associés à ce département. Ca se défini au moment de la création de clé étrangère.
MAIS C'EST RISQUE !
ALTER TABLE Department
ADD CONSTRAINT FK_Department_Employee_Cascade
FOREIGN KEY (dep_id) REFERENCES Employee(dep_id) ON DELETE CASCADESuppression avec jointure (abus de langage)
DELETE s
FROM batiment b
INNER JOIN salle s ON s.id_batiment = b.id
WHERE b.nombre_etages >= 15;
-- Equivalent sans jointure, mais moins performant (2 requêtes)
-- DELETE FROM salle
-- WHERE id_batiment IN
-- (
-- SELECT id
-- FROM batiment
-- WHERE nombre_etages >= 15
-- )Exemple avec MySQL
Exercice 6
(Sur la base des exercices précédents)
Sur la base Formation_RIL
Requête d’insertion avec jointures, update avec jointure, delete avec jointure (« Jointure » = Abus de langage, on parle plutôt de suppression propre en fonction des relations existantes)
Les fonctions natives (de SQL Server)
- CONCAT() -- Concaténation
- COUNT() -- Compte
- AVG() -- Valeur moyenne
- SUM() -- Somme
- MIN() / MAX() -- Minimum / Maximum
- GETDATE() – CURRENT_DATE() -- Récupère la date au moment de l'exéc
- DATEDIFF() -- Différence entre deux dates (paramétrable)
- ISDATE() -- Vérifie si la chaîne est une date (Retourne 0 ou 1)
- TRIM() -- Supprime les retours chariots en fin de chaine
- COALESCE() -- Mets une valeur par défaut si NULL
- CONVERT() -- Converti un élément dans un type différent
Créer ses propres fonctions
GO
CREATE FUNCTION GET_EMPLOYEE_SALARY_BY_NAME
(
@emp_firstname varchar(50), -- paramètre d'entrée de la fonction
@emp_lastname varchar(50)
)
RETURNS numeric(7,2) -- type de retour
AS
BEGIN
RETURN -- Retour via un SELECT (généralement une seule donnée)
(
SELECT emp_salary
FROM Employee
WHERE emp_firstname = @emp_firstname AND emp_lastname = @emp_lastname
)
END
GO
Il est possible de créer ses propres fonctions avec SQL. A noter que celles-ci doivent toujours avoir un type de retour.
Attention aux contre performances, appeler une fonction dans un champ, c'est exécuter cette fonction pour tous les enregistrements !
(Utilisation de table temporaire recommandé dans ce cas)
Créer ses propres fonctions (MySQL)
DELIMITER //
CREATE FUNCTION F_GetPokemonFromId
(
pokemon_id INT
)
RETURNS VARCHAR(100)
BEGIN
DECLARE pokemon_nom VARCHAR(100);
SELECT pok_nom INTO pokemon_nom
FROM pokemon
WHERE pok_id = pokemon_id;
RETURN pokemon_nom;
END
//
DELIMITER ;Il est possible de créer ses propres fonctions avec SQL. A noter que celles-ci doivent toujours avoir un type de retour.
Attention aux contre performances, appeler une fonction dans un champ, c'est exécuter cette fonction pour tous les enregistrements !
(Utilisation de table temporaire recommandé dans ce cas)
Appeler ses propres fonctions
SELECT dbo.GET_EMPLOYEE_SALARY_BY_NAME('ARTHUR', 'PARISOT') AS Salary
-- dbo, c'est le schéma de base.Il est possible de créer ses propres fonctions avec SQL. A noter que celles-ci doivent toujours avoir un type de retour.
Appel de fonction direct
DECLARE @Salary numeric(7,2) = dbo.GET_EMPLOYEE_SALARY_BY_NAME('ARTHUR', 'PARISOT')
SELECT @Salary
-- Oui, on peut créer des variabls en SQL :)Appel de fonction via variable
Exercice 7
Seulement la partie fonction ! Les procédures, on les voit juste après.
Création de fonctions
Exercice 8 & 9
Reprise des bases & workshop complémentaires
-
Exercice 8 : Autres requêtes avec jointures plus ou moins complexes
- Exercice 9 : Reprise du SQL basique, pour revoir le SQL tranquillement
Administration et opérations avancée SQL
Les procédures stockées
Une procédure stockée est un objet de base de données, qui peut être appelé pour réaliser une suite d'instructions ayant un but particulier. Par exemple, une procédure de pagination pour l'affichage d'une liste de composants.
CREATE PROCEDURE SP_ProcedureName
(
@ComponentName varchar(50) = NULL,
@ComponentVersion varchar(10)
)
WITH RECOMPILE -- Optionnel mais permet généralement de meilleurs performances
AS
BEGIN
-- Instructions à exécuter sur la procédure,
-- @ComponentName & @ComponentVersion sont utilisables comme des variables
END
EXEC SP_ProcedureName 'QUAL', '3.4'
Les procédures stockées
Les paramètres de procédures stockées sont disponible en entrée, dans le corps de la procédure ainsi qu'être rendu disponible à la sortie de la procédure.
CREATE PROCEDURE SP_ProcedureName
(
@ComponentName varchar(50) = NULL, -- valeur par défaut : NULL
@ComponentVersion varchar(10) NOT NULL -- Pas de NULL possible
)
AS
BEGIN
SELECT ComponentDate AS CompDate,
ComponentTeam AS CompTeam,
@ComponentName AS CompName,
@ComponentVersion AS CompVersion
FROM Components
WHERE ComponentName = @ComponentName AND ComponentVersion = @ComponentVersion
END
GO
EXEC SP_ProcedureName ‘test’, ‘test’;
Les procédures stockées (MySQL)
DELIMITER //
DROP PROCEDURE SP_Rename_Salle_ByBatimentId //
CREATE PROCEDURE SP_Rename_Salle_ByBatimentId
(
IN p_id_batiment INT,
IN p_new_name VARCHAR(50)
)
BEGIN
-- Toutes les instructions SQL que je veux
-- Et j'ai accès aux paramètre d'entrée qui sont id_batiment et new_name
-- Vérifier que l'id du batiment existe bien
-- Sinon, je lève une exception
-- Si oui, je fais l'opération de modification
UPDATE salle
SET nom = p_new_name
WHERE id_batiment
IN (SELECT id FROM batiment WHERE id = p_id_batiment);
END //
DELIMITER ;Les procédures stockées
Avec transaction et gestion des erreurs
CREATE OR ALTER PROCEDURE SP_ChangeCommission_ByDepartmentId
(
@department_id INT,
@new_commission INT
)
AS
BEGIN
BEGIN TRAN -- je sauvegarde l'état de la BDD à cet instant T
BEGIN TRY
IF (@new_commission <= 200)
THROW 50002, 'commission cannot be under 200', 1;
-- On peut controller les entrée
IF NOT EXISTS (SELECT * FROM Department WHERE id = @department_id)
-- Je lève une exception (ça stop la procédure dans ce cas)
THROW 50001, 'id du department inexistant', 1;
-- Si la procédure s'est pas stoppée, je fais ma modification
UPDATE Employee
SET commission = @new_commission
WHERE dep_id = @department_id
--INSERT INTO Employee ()
--INSERT INTO Employee () -- Ici ça pète
--INSERT INTO Employee ()
--INSERT INTO Employee ()
COMMIT TRAN
END TRY
BEGIN CATCH
ROLLBACK TRAN
SELECT ERROR_MESSAGE();
END CATCH
ENDLes procédures stockées
Gestion de pagination (simple)
-- same sample without using ROW_NUMBER
GO
CREATE OR ALTER PROCEDURE SP_PagerEmployeeWithoutRowNumber
(
@Page SMALLINT,
@NumberElementByPage SMALLINT
)
AS
BEGIN
SELECT
e.FirstName, e.LastName
FROM DimEmployee e
ORDER BY CONCAT(e.FirstName, ' ', e.LastName) ASC
OFFSET (@Page - 1) * @NumberElementByPage ROWS FETCH NEXT @NumberElementByPage ROWS ONLY
END
EXEC SP_PagerEmployeeWithoutRowNumber 5, 30Les procédures stockées
Quelques exemples de procédures stockées...
Les procédures stockées
Exercice de création de procédures stockées.
Je vais vous envoyer le sujet, sinon, le voici :
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
-- Sur la base AdventureWorksDW : USE AdventureWorksDW
-- 1. Créez une procédure stockée permettant de récupérer
-- l'emplacement géographique (DimGeography.FrenchCountryRegionName)
-- d'un client par son nom complet (FirstName + LastName)
-- 2. Créez une procédure stockée permettant d'insérer un nouvel enregistrement dans la table
-- DimProductCategory avec des entrées correspondant aux noms des champs de la table
-- ProductCategoryAlternateKey (int), EnglishProductCategoryName (varchar(50)),
-- SpanishProductCategoryName (varchar(50)), FrenchProductCategoryName (varchar(50))La gestion des erreurs
Gérer les erreurs est également possible en SQL, c'est d'ailleurs recommandé dans les procédures stockées.
BEGIN TRY
SELECT 1/0;
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS NumeroErreur,
ERROR_SEVERITY() AS SeveriteErreur,
ERROR_STATE() AS EtatErreur,
ERROR_PROCEDURE() AS ProcedureErreur,
ERROR_LINE() AS LigneErreur,
ERROR_MESSAGE() AS MessageErreur;
END CATCH;
Un bloc try, un bloc catch et on peut retourner les informations d'erreurs dans une requête.
La gestion des erreurs
Il est également possible de générer soit même son erreur avec l'instruction THROW numError (min 50000), 'message', severité. Ceci permettant d'anticiper les erreurs dans vos scripts (validation d'entrée utilisateur par ex)
BEGIN TRY
DECLARE @a smallint = 0
--Instructions
IF @a = 0
BEGIN
RAISERROR('@a ne doit pas être égal à zéro', 1, 1);
THROW 50001, '@a ne doit pas être égal à zéro’, 1; -- On va directement dans le catch
END
END TRY
BEGIN CATCH
SELECT ERROR_MESSAGE(), ERROR_NUMBER(), ERROR_SEVERITY(), ERROR_STATE()
END CATCH
Ou uniquement notifier l'erreur avec RAISERROR('message', sévérité, state). Une sévérité entre 0 et 10 ne stop pas l'exécution et notifie d'une erreur (warning), au delà, l'erreur mène directement au bloc catch ! (Entre 11 et 25)
La gestion des erreurs
Exercice de création de procédures stockées avec gestion des erreurs.
- Ecrire une procédure stockée permettant de retourner la division entre deux nombres en paramètres d’entrées.
- En gérant la division par zéro. Retournez l’éventuel message d’erreur.
- Exécutez la procédure pour tester votre gestion des erreurs.
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
La gestion des erreurs
Exercice de création de procédures stockées avec gestion des erreurs.
-
Créez une base « ClientDatabase », ajoutez une table
« T_Client » (Nom_Client varchar(30), Prenom_Client varchar(30), Date_naissance_client datetime, Taille_Client varchar(5), Num_client varchar(15)) - Ecrire une procédure stockée prenant en entrées ces paramètres et permettant d’ajouter un nouveau client dans la table T_Client,
- Nom_client (taille max : 30 caractères)
- Prenom_client (taille max : 30 caractères)
- Date_naissance_client (année minimale : 1900)
- Taille_client (valeurs parmi suivantes : ‘S’, ‘M’, ‘L’, ‘XL’, ‘XXL’)
- Num_client (peut être NULL)
- Utiliser la gestion des erreurs pour faire une gestion des entrées de la procédure stockée remontant une erreur si la valeur ne correspond pas.
SAUF POUR LE NUMERO DE TELEPHONE.
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
Les transactions
En complément de la gestion des erreurs il est possible de gérer un état de base de données afin de pouvoir valider un ensemble de requêtes, ou les invalider en cas d'erreurs.
BEGIN
BEGIN TRAN TransacName
BEGIN TRY
-- Requêtes à effectuer en un bloc sûr
COMMIT TRANSACTION TransacName -- On valide la transaction
PRINT 'Transaction OK'
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION TransacName --On annule la transaction
SELECT ERROR_MESSAGE()
END CATCH
END Un commit de transaction provoque la validation.
Un rollback de transaction provoque l'annulation.
Les transactions
Un exemple de transaction, avant l'exercice...
Les transactions
- Créez une transaction (avec gestion d’erreurs) appelant 5 fois la procédure d’insertion de client précédemment créée, vous assurant que les clients soient insérés en un seul bloc.
- Si un des appels de procédures retourne une erreur, aucun des client ne doit être inséré en base de données
(Les 5 clients peuvent êtres choisis arbitrairement)
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
Le merge
Une opération de merge de données est plus souvent plus rapide pour de la modification massive de données.
MERGE INTO table1
USING table_reference
ON (conditions)
WHEN MATCHED THEN
UPDATE SET table1.colonne1 = valeur1, table1.colonne2 = valeur2
WHEN NOT MATCHED THEN
INSERT (colonnes1, colonne3)
VALUES (valeur1, valeur3)
Une table de base, une table de référence et une condition à analyser. Selon le match, on réalise une opération ou une autre.
Le merge
Deux exemples de merge, le merge simple et un merge plus complexe...
Exercice de merge
Exercice de manipulation du merge
Je vais vous envoyer le sujet, sinon, le voici :
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
-- Sur la base Formation_RIL, créez une table EmployeeMerged
-- avec les mêmes champs que la table Employee
-- Grâce à une opération de MERGE, inserez tous les employés
-- des départements 1,2 et 3 dans la table EmployeeMerged.
-- ATTENTION, Insert n'est utilisable qu'en cas de WHEN NOT MATCHED.
-- Insérez un Employee sans département ('Test', 'Test', 'Test', '01-01-1999', 0, 0, NULL)
-- Grâce à une opération de MERGE, modifiez le département
-- des employés sans département vers un département existant (Ex : 4)Le trigger
C’est un objet à part entière en base de données, donc comme pour tous les objets on peut faire ce type d’opérations dessus :
- CREATE
- ALTER
- DROP
Un trigger représente une succession d’instructions qui sont déclenchées automatiquement lorsqu’une autre action (précise et définie lors de la création du trigger) est levée sur le SGBDR.
Les triggers sont utilisés essentiellement pour assurer l’intégrité des données dans une base de données relationnelle.
Il existe deux classes de triggers :
- DDL : Data Definition Language.
- DML : Data Modification Language.
Pour deux types :
- FOR / AFTER [INSERT / UPDATE / DELETE] : Exécuté après la fin de l’instruction.
- INSTEAD OF [INSERT / UPDATE / DELETE] : Exécuté à la place de l’instruction.
Le trigger
La syntaxe de création ou modification d'un trigger se présente comme suit :
CREATE OR ALTER TRIGGER triggerName
ON tableName –- Ou vue
AFTER INSERT, UPDATE
AS
-- Instructions à effectuer après l'exécution de la requête déclenchant le trigger
GO
CREATE OR ALTER TRIGGER triggerName
ON tableName –- Ou vue
INSTEAD OF INSERT, UPDATE, DELETE
AS
-- Instructions à effectuer de l'instruction de base
GO
On remarque que soit on réalise les opérations après exécution de la requête déclencheuse, soit on remplace.
Le trigger
Un exemple très simple en utilisant une procédure MSSQL d'envoi de mail :
CREATE TRIGGER TRIG_Mail_Reminder_NewVersion
ON dbo.AdventureWorksDWBuildVersion
AFTER INSERT, UPDATE, DELETE
AS
EXEC msdb.dbo.sp_send_dbmail
@recipients = 'email@address.com',
@body = 'Modification de la table de version',
@subject = 'TRIG_Mail_Reminder_NewVersion : Information action sur version';
GO
Le trigger
Juste pour pratiquer rapidement, réalisez un trigger sur la table T_Client.
A chaque UPDATE, DELETE, INSERT sur la table T_Client, réaliser un trigger INSTEAD OF permettant de remplacer la requête par un
SELECT 'Ces opérations sont interdites et ont été désactivées';
Testez en faisant des opérations sur la table.
Pensez absolument à supprimer ce trigger (soit avec l'instruction DROP TRIGGER triggerName, soit depuis l'interface dans "déclencheurs", après avoir cliqué sur le petit + à côté de la table T_Client)
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
Le trigger
Tables INSERTED / DELETED
Les triggers génèrent des données dans des tables temporaires liées uniquement à la requête déclenchant le trigger. (Les données sont mises en cache)
Ces tables sont les suivantes :
- INSERTED : Contient les données insérées et mises à jour
- DELETED : Contient les données supprimées
Utile pour gérer ce qui s’est passé sur l’action déclenchant le trigger.
Le trigger
Tables INSERTED / DELETED
Un exemple pour mieux comprendre avant l'exercice :
CREATE TRIGGER inserted_client
ON T_Client
FOR INSERT, UPDATE
AS
-- requête de contrôle avec table d'insertion
SELECT *
FROM INSERTED I
INNER JOIN T_Client tc ON I.cli_id= tc.cli_id
IF @@Error <> 0
ROLLBACK TRANSACTION
GO
CREATE TRIGGER deleted_client
ON T_Client
FOR DELETE
AS
-- requête de contrôle avec table de suppression
SELECT *
FROM DELETED
-- rollback en cas d'erreur
IF @@Error <> 0
ROLLBACK TRANSACTION
GO
INSERT INTO T_Client VALUES ('Tri','Gger', '1990-01-07','XL','01 02 03 04 05')
UPDATE T_Client SET cli_prenom = 'Tri2' WHERE cli_id = @@IDENTITY
DELETE FROM T_Client WHERE cli_id = @@IDENTITY
Le trigger
Reprenez la base « ClientDatabase», créez un trigger permettant de contrôler la validité des données lors d’une insertion d’un nouveau client.
1. Assurez-vous à l’aide d’un trigger que le numéro donné pour chaque insertion de client est bien composé qu’avec des chiffres et des points, ou sans espace.
Info : (Replace ‘ ‘, ‘.’) Cast decimal.
Pensez au retour arrière en cas d’erreur.
2. Ajoutez ce fonctionnement pour tout update sur le champ Num_client.
3. Ici, l'exercice consiste maintenant à corriger à la volée les saisies incorrectes. Tous les caractères de séparation d’un numéro de téléphone, tels que les tirets ou les espaces ou les points devront être supprimés pour que les données passent au format « 0102030405 » ou alors au format « 01.02.03.04.05 » si vous préférez.
==> Indice : Utilisez la jointure entre la table T_Client et la table de INSERTED
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
Le trigger
Quand utiliser un trigger
- gestion d'héritage avec lien d'exclusion
- suppression, insertion et mise à jour en cascade
- contrôle de validité des données
- respect d’intégrité complexe
- formatage de données
- archivage automatique
- envoi de mails informatifs
- ...
Le trigger simple
Prenons le MLD suivant :
- Client (cli_id, cli_nom, cli_prenom, cli_date_naissance, cli_tel)
- Facture (fac_id, cli_id, fac_montant_tot)
Créez la table « Facture ». Cli_id et fac_id seront des clés primaires auto incrémentées (IDENTITY(1,1)) et n’ajoutez PAS la clé étrangère sur cli_id pour l’instant, on veut que le delete cascade soit géré directement dans la contrainte de clé étrangère (non conseillé sauf cas particuliers)
Ajoutez des données fictives dans les deux tables. A minima, un client et deux factures associées à ce client. (Avec des id de clients existants pour T_Facture (cli_id))
Suppression en cascade. Grâce à un trigger, veuillez vous assurer que si un client est supprimé, toutes les factures associées le sont aussi.
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
Le trigger plus complexe
Créez les tables associées au MLD suivant (sans clé primaire ni étrangère):
- T_VEHICULE(VHC_ID)
- T_AVION(VHC _ID, AVI_MARQUE, AVI_MODELE)
- T_BATEAU(VHC _ID, BAT_NOM, BAT_PORT)
On remarque un lien d’héritage, sa gestion suppose souvent une exclusion entre les fils. Une valeur de clef présente dans T_VEHICULE peut donc se retrouver soit dans T_BATEAU soit dans T_AVION mais pas dans les deux tables.
Créez le trigger permettant de vous assurer que la clé insérée de T_AVION existe bien dans la table T_VEHICULE ainsi que la clé n’est pas déjà présente dans la table T_BATEAU.
A noter également qu’un trigger équivalent est nécessaire sur la table T_BATEAU.
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
Le curseur (à éviter)
- Mécanisme de stockage de données en mémoire tampon
- Permet de lire un à un les enregistrements de la requête définie pour le curseur
- Est utilisé en permanence par le SGBD même si c’est transparent pour nous.
- Exemple, pour les index, ou même n’importe quelle opération de tri.
- Permet d’intervenir directement sur un ou plusieurs résultats de la requête
Qu’est-ce qu’un curseur ?
Le curseur
Un curseur permet d'itérer sur tous les résultats d'une sélection prédéfinie.
DECLARE C_Nom CURSOR
FOR (SELECT nom, prenom FROM T_Client)
-- Requête de sélection sur laquelle on veut parcourir les données
OPEN C_Nom -- Ouverture du curseur
-- Déclaration de(s) variable(s)
DECLARE @nom varchar(50) = ‘’
DECLARE @prenom varchar(50) = ‘’
FETCH C_Nom INTO @nom, @prenom -- Ouverture du curseur
WHILE @@FETCH_STATUS = 0 -- Jusqu’à ce qu’il n’y ai plus de ligne
BEGIN
-- Opérations en fct de @nom, toujours sur la requête du départ
FETCH C_Nom INTO @nom , @prenom -- On passe à l’enregistrement suivant
END
CLOSE C_Nom -- /!\ Ne jamais oublier ces deux lignes /!\
DEALLOCATE C_Nom
Honnêtement, ce n'est pas performant et je déconseille l'utilisation de curseur en toutes circonstances.
Le curseur
Un exemple concret
GO
DECLARE C_auteurs CURSOR
FOR
SELECT cli_nom FROM T_Client
OPEN C_auteurs
DECLARE @all_noms VARCHAR(3000) = ''
DECLARE @nom VARCHAR(50)
FETCH C_auteurs INTO @nom
WHILE @@FETCH_STATUS = 0
BEGIN
IF @all_noms = ''
SET @all_noms = @nom
ELSE
SET @all_noms = @all_noms + ', ' + @nom
PRINT @all_noms
FETCH C_auteurs INTO @nom
END
CLOSE C_auteurs
DEALLOCATE C_auteursLe curseur
Un exemple pour mieux comprendre
Les possibilités de l’instruction FETCH :
- FETCH FIRST FROM : Aller à la première ligne
- FETCH LAST FROM : Aller à la dernière ligne
- FETCH NEXT FROM : Aller à la ligne suivante
- FETCH PRIOR FROM : Aller à la ligne précédente
- FETCH ABSOLUTE x FROM : Aller à la ligne x
- FETCH RELATIVE x FROM : Aller à x lignes plus loin que l'actuelle
Fonctions de curseurs :
- @@CURSOR_ROWS: renvoie le nombre de lignes se trouvant actuellement dans le dernier curseur ouvert. 0 s'il n'y a pas de curseurs ouverts ou que le dernier est vide.
- CURSOR_STATUS() : permet de vérifier qu'une procédure à bien renvoyé un curseur non vide
Le curseur
Un exemple de curseur...
Le curseur
-- Exercice curseur : CREATE TABLE T_Joueur (id int NOT NULL PRIMARY KEY IDENTITY(1,1), prenom varchar(30)).
-- Insérez 7 joueurs, dont un avec le nom = NULL
-- Récupérez la liste de tous les prénoms concaténés grâce à un curseur. Retour voulu : ‘Prenom1’, ‘Prenom2’, …, ‘Prenom7’
-------------------------------------------
-- Obtenir le même résultat sans curseur --
-------------------------------------------
* Pour éviter les NULL, vous pouvez utiliser COALESCE(jou_prenom, ‘, ‘, ‘’)
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
Le curseur
-- Réalisez un curseur qui cumule les scores par joueur, au tour par tour; avec un curseur. Il y’a 3 joueurs,
-- C'est à dire, retourner une ligne par joueur et par tour. Ainsi qu'un score.
-- Utilisation de table temporaire souhaité
-- CREATE TABLE #CUMULS (sco_tour int, jou_id int, sco_value int)
-- Premier enregistrement: j1, t1, score = score t1j1
-- Second enregistrement: j1, t2, score = score t1j1 + score t2j1
-- Troisième enregistrement : j1, t3, score = score t1j1 + score t2j1 + score t3j1
-- Quatrième enregistrement : j2, t1, score = score t1j2
-- Cinquième enregistrement : j2, t2, score = score t1j2 + score t2j2
-- ...
-- Dernier enregistrement: j3, t3, score = score t1j3 + score t2j3 + score t3j3
-------------------------------------------
-- Obtenir le même résultat sans curseur --
-------------------------------------------
Envoyez moi les exercices tout au long de la formation, j'utiliserai ces éléments pour la notation.
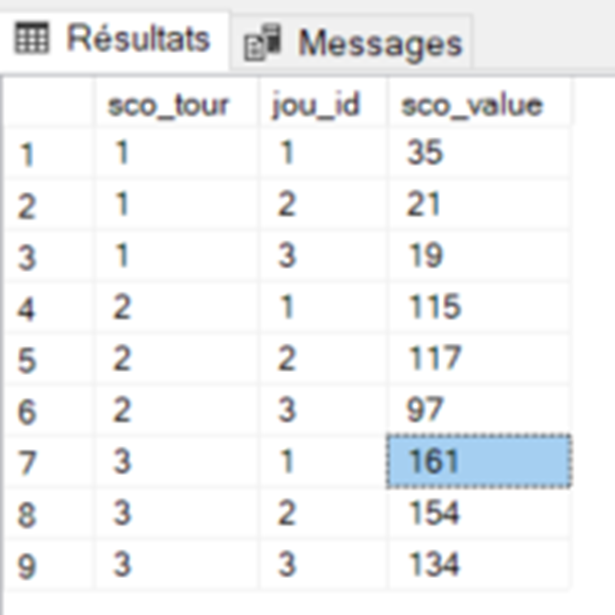
Le curseur VS select
SELECT classique
- Très simple à utiliser
- Très recommandé
- Aucune possibilité de modification via le SELECT
Curseurs
- Pas recommandé, à n'utiliser que dans des cas où l'on ne peut rien faire d'autre (Et c'est extrêmement rare)
- Assez complexe à utiliser même si ça reste assez puissant
- Consommateur en cache et en mémoire vive (même si on peut relativiser pour des petites bases)
- Tout ça pour avoir le pouvoir absolu sur le retour de la requête, alors qu'on peut déjà gérer le retour de la requête via un SELECT
Optimisation des données
Types de données
Il existe plusieurs types de données afin de les stocker. Ce qu'il faut comprendre c'est que le type de données défini un espace mémoire pour le stockage de cette donnée.
Quelques conseils :
- Bien choisir le type, ne pas utiliser un BigInt là où un SmallInt suffit
- Utiliser Varchar à la place de char (taille variable)
- Stocker les données numériques non calculées en varchar (CB, numéro de téléphone,...)
- Utiliser trim() pour les données AN
- Utiliser une référence numérique (Enum) pour les données AN répétées (statut de commande par exemple)
Types
Le type numérique
Un des type les plus impactant, car souvent le moins bien géré, est le type numérique.
Voici les informations qu'il faut savoir (pas au chiffre près) pour ces types :
Stockage de données
D'autres éléments sont à prendre en compte pour optimiser votre stockage de données, tels que le choix du moteur de stockage ainsi que les capacités du serveur de base de données.
Pour votre serveur : Avoir suffisamment de RAM, monitoring, utilisation de socket Unix (si possible, sur la même machine que le code applicatif), mise en place et utilisation d'un système de mise en cache.
Pour le choix du moteur de stockage :
- MyISAM : à privilégier lorsqu’il est surtout nécessaire d’effectuer des requêtes pour lire ou insérer des données. Pour des sites web, c’est souvent la solution recommandée (Attention, les clés étrangères ne sont pas prises en compte avec MyISAM)
- InnoDB : à privilégier pour les systèmes qui ne doivent pas comporter d’erreurs et qui nécessite des clés étrangères. Pour une application gérant des données importantes, app avec données bancaires par ex.
Index
- Un objet SQL nous donnant le moyen d’ajouter une information au SGBDR pour qu’il optimise sa façon de gérer les données
- Les données d’un index sont triées et sont stockées dans une structure particulière favorisant les recherches : liste ordonnée ou arbre binaire.
- Le trie de la clef d’index fait que l’information est vectorisée (chaque colonne supplémentaire précise la colonne précédente)
- La plupart des SGBDR créent automatiquement des index lors de l’ajout de contraintes PRIMARY KEY ou UNIQUE. La vérification de l'unicité d'une PK serait beaucoup plus longue sans index.
- Possible de créer des index sur des TABLES ou des VUES (ou index particuliers : XML / FULLTEXT).
Qu’est-ce qu’un index concrètement ?
Index
Un exemple pour mieux comprendre
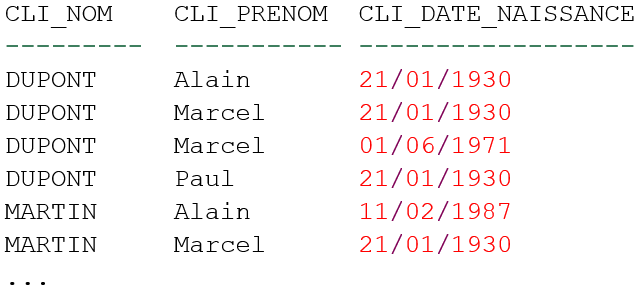
Si l'on créer un index suivant ces colonnes :
Pour cet index composé d'un nom d'un prénom et d'une date de naissance, la recherche sera efficace pour les informations suivantes :
- CLI_NOM
- CLI_NOM + CLI_PRENOM
- CLI_NOM + CLI_PRENOM + CLI_DATE_NAISSANCE
- /!\ PAS sur CLI_PRENOM + CLI_DATE_NAISSACE
Index
Un exemple pour mieux comprendre
Si l'on créer un index suivant ces colonnes :
Pourquoi pas sur CLI_PRENOM + CLI_DATE_NAISSANCE ?
- la recherche sur une seule colonne CLI_PRENOM ou CLI_DATE_NAISANCE n'aura aucune efficacité à cause de la vectorisation des colonnes. Chercher "Paul" revient à parcourir tout l'index (balayage ou scan) alors que chercher "MARTIN", revient à se placer très rapidement par dichotomie au bon endroit (recherche ou seek).
Index
Types et différences
Clusterisé
Non clusterisé
Couvrant
Les données sont triées en lignes selon la clé fournie à l’index.
- Ici, pas de vectorisation des données
- Toutes les colonnes sont concernées car on réorganise physiquement les données
- Automatiquement associé à la clé primaire de la table
- Un seul index clusterisé par table !
Les données sont vectorisées selon l'ordre fourni.
- Vectorisation des données
- Pas de restructuration physique
- Aucune création automatique
- Multiple par table possible
Les données sont vectorisées selon l'ordre en excluant des colonnes inutiles :
-
Ceci permet de ne pas avoir besoin d’aller rechercher les données incluses dans la table.
Attention cependant à l’espace mémoire que ça peut impliquer.
Index
Syntaxe de création
-- Créer un index non clusterisé
CREATE INDEX i1 ON t1 (col1);
-- Créer un index clusterisé (en general automatique via PK)
CREATE CLUSTERED INDEX i1 ON t1(col1);
-- Syntaxe SQL Server
CREATE UNIQUE INDEX i1 ON t1 (col1 DESC, col2 ASC, col3 DESC);
-- Index non clusterisé avec colonnes incluses
CREATE NONCLUSTERED INDEX IX_Address_PostalCode
ON Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Index
Un exemple sur SQL Server
CREATE UNIQUE CLUSTERED INDEX X_Cli_prenom_tel
ON T_CLIENT (cli_nom ASC,
cli_prenom,
cli_date_naissance DESC)
WITH (FILLFACTOR = 80,
SORT_IN_TEMPDB = ON,
ALLOW_ROW_LOCKS = ON,
MAXDOP = 3)
ON STORAGE
Index
Un exercice pour vous
Créer trois indexes :
- Reprenez la table T_BATEAU et ajoutez un index clusterisé sur cette table.
- Faites de même pour T_AVION et T_VEHICULE.
- Ajoutez un index sur T_Client, non clusterisé, sur nom + prenom + date_naissance et incluant num_tel.
Index
Quand devons nous absolument créer un index ?
La plupart des SGBDR s’en chargent pour chaque clé primaires et étrangères, en majeur partie des cas.
- Attention aux cardinalités 0/1,N – 0/1,N
- Ici un index simple est « oublié ».
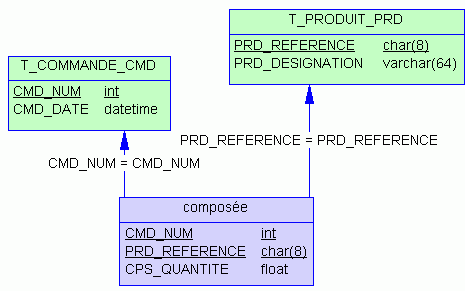
Il faut donc en créer un soi-même !
Index
Quand devons nous absolument créer un index ?
create table T_COMMANDE_CMD (
CMD_NUM int not null PRIMARY KEY,
CMD_DATE datetime not null
)
create table T_PRODUIT_PRD (
PRD_REFERENCE char(8)not null PRIMARY KEY,
PRD_DESIGNATION varchar(64)not null
)
create table T_J_COMPOSEE_CPS (
CMD_NUM int not null foreign key (CMD_NUM) references T_COMMANDE_CMD (CMD_NUM),
PRD_REFERENCE char(8) not null foreign key (PRD_REFERENCE)
references T_PRODUIT_PRD (PRD_REFERENCE),
CPS_QUANTITE float not null,
constraint PK_T_J_COMPOSEE_CPS primary key (CMD_NUM, PRD_REFERENCE)
)
Voici le code SQL associé à cet index :
Index
Quand devons nous absolument créer un index ?
Les index créés automatiquement à cause des PRIMARY KEY
- T_COMMANDE_CMD (CMD_NUM)
- T_PRODUIT_PRD (PRD_REFERENCE)
-
T_J_COMPOSEE_CPS (CMD_NUM, PRD_REFERENCE)
Les index à créer pour les FOREIGN KEY :
- CREATE INDEX X_CPS_CMD ON T_J_COMPOSEE_CPS (PRD_REFERENCE)
- CREATE INDEX X_CPS_CMD ON T_J_COMPOSEE_CPS (CMD_NUM)
Le second est redondant car déjà présent avec une vectorisation supplémentaire.
Index
Quand devons nous potentiellement créer un index ?
Utilisation de requêtes prédéfinies afin de détecter le top X des requêtes les plus consommatrices.
Je vous enverrai un script contenant plusieurs requêtes d'analyse de votre base de données
-- Afficher les 50 dernières requêtes les plus consommatrices de CPU
-- Afficher les 50 dernières requêtes exécutées
-- Afficher les 50 requêtes les + fréquemment exécutées
-- Création automatisée d'index
-- Mesurer les volumes stockées par partition, index et tables d’une base
-- Index trop lourds
-- Vérification des index dont les clés contiennent trop de colonnes
Index
Conseils et informations
- Index multicolonne et longueur des clés d'index : Choisir la bonne vectorisation et réduire la longueur des clés d’index.
- Meilleur efficacité en disposant en premier les colonnes ayant le plus de disparité.
- Par exemple s'il faut créer un index sur le sexe, le prénom et le nom, la meilleure combinaison sera généralement nom + prenom + sexe (dans cet ordre précis).
- Quant à la longueur de la clé d'index, ou le nombre d'octets qui composent l'information vectorisée, mieux vaut qu'elle soit la plus petite possible. U
- A mon sens, on ne doit jamais faire une clé d'index qui dépasse quelques dizaines d'octets (30 ou 40 max).
- La longueur de clé d’index ne prend pas en compte les colonnes incluses
Index
Le conditionnement sur index
Utilisés sur des données calculables. Exemple… Les dates.
Les clients nés avant 1900 ne nous intéressent surement moins aujourd’hui dans un index.
On peut donc créer un index avec une clause where comme suit :
Ceci permet une double optimisation, sur la mémoire utilisée par l’index et sur le temps de traitement des requêtes utilisant cet index. Moins de données accédées impliquent une recherche (je le rappel, souvent dichotomique) moins longue.
CREATE INDEX X_CLIENT ON T_Client (cli_nom, cli_prenom)
WHERE (cli_date_naissance > '1900-01-01'
Lecture et compréhension d’un plan d’exécution
Chaque icone a sa propre signification, la couleur des icônes classe par famille :
- Bleu : pour les opérateurs physiques ou logiques (Merge, tri, index,…)
- Jaunes : pour les curseurs
- Vert : pour les éléments de langage
Beaucoup d’informations importantes disponibles au survol.
Ex : Type d’index utilisé, nombre de lignes de codes sur laquelle l’opération de jointure est faite,…
- Index scan : Cet index fait une recherche complète sur tous les enregistrements de la table jusqu’à ce que ça match.
- Index seek : Cet index fait une recherche par dichotomie + utilise la vectorisation de l’index.
Monitoring en continue
Des outils permettent de monitorer en continue les requêtes vous informer sur les optimisations possibles.
En cycle de développement, l’outil tourne en tâche de fond et analyse les plans d’exécution pour proposer des optimisations. Soit par des ajouts index, des analyses de requêtes, ou des analyses des statistiques utilisés par les index.

Conseils d'optimisation des requêtes - SQL
- Filtrer les données directement via le filtre WHERE et/ou LIMIT, en évitant que cela ne soit fait par l’application.
- Eviter d’utiliser des fonctions dans les clauses de recherche, telle que WHERE ou les champs retournés,
- Eviter les lectures via “SELECT *” en privilégiant plutôt de lister uniquement les colonnes qui seront exploitées.
- Eviter d’utiliser le wildcard “%” au début d’une recherche LIKE.
- Eviter les OR, privilégier le IN quand c'est possible.
- Utiliser des requêtes préparées ou procédures stockées (stored procedure) pour mettre en cache certaines requêtes du côté du SGBD.
Conseils d'optimisation des requêtes - Appli
- Compter le nombre de requêtes SQL utilisé au sein d’une page. Cela permet d’analyser les pages qui pourraient contenir trop d’appels de requêtes SQL :
- Une requête SQL similaire qui est appelée à plusieurs reprises
- Exemple : la requête “SELECT email FROM utilisateur WHERE id = 456”, puis la requête “SELECT date_inscription FROM utilisateur WHERE id = 456” pourrait être extrait en une seule fois.
- Une requête SQL similaire qui est appelée à plusieurs reprises
- Eviter d’appeler des requêtes SQL dans une boucle.
- Pour un système de pagination, privilégier l’usage de ROW_NUMBER, et éviter de faire 2 requêtes, celle contenant les résultats et l’autre pour compter le nombre de résultats total.
- Eviter d’utiliser la requête “WHERE IN” si vous pouvez utiliser “WHERE EXISTS”.
- Eviter les sous-requêtes si une jointure est possible.
- Eviter de compter une colonne (cf. “SELECT COUNT(colonne) FROM table) lorsqu’il faut compter le nombre d’enregistrement (cf. “SELECT COUNT(*) FROM table).
Exemple concret d'optimisation
Exemple concret rencontré récemment sur un problème SQL :
Je vous envoie une procédure que l’on va analyser rapidement.
- Cas 1 : la requête prend 1'42s à s’exécuter. Avant que je vous envoie le cas n°2, quelles idées avez-vous déjà afin d’optimiser cette requête ?
- Cas 2 : Avant que je vous explique, qu’est-ce que vous remarquez sur le cas n°2 ? Le cas 2 s’exécute en moins d’1s.
Note : Les plans d’exécutions sont parfois radicalement différents entre SQL Server 2012 et SQL Server 2016 ou SQL Server 2019, ou … Vous avez compris l’idée.
Faites donc extrêmement attention lorsque vous montez de version, il est nécessaire de recetter l’application complètement afin de vous assurer que la montée de version n’a pas « cassé » des index.
Partitionnement & Compression des données
Sans rentrer dans le détail car ça ne fait pas parti du plan de formation :
- Le partitionnement des données : Permet de séparer les données selon des normes que vous mettez en place. Ceci permettant d'améliorer les temps d'accès en sélection (Mais rallonge légèrement les autres opérations). Exemple, une table de commande ou l'on partitionne sur les dates de commandes de l'année en cours.
- Archivage des données : Diminuer les données de la table en archivant celles qui n'ont plus d'utilité.
- La compression des données : Permet de compresser les donner (à l'instar d'un zip), pour réduire l'espace mémoire nécessaire. Ceci peut être très utile dans le cas d'accès à un grand nombre de données.
Introduction au Big Data
Le Big Data
le Big Data est une forte volumétrie, haute Vélocité et grande Variété de données qui exigent des techniques innovantes et rentables de traitement d’information pour une meilleure efficacité
Volume
Vélocité
Variété


Le NoSQL est de plus en plus utilisé pour répondre aux enjeux du BigData
Le fonctionnement est différent d'un SGBDR, les données ne respectent plus un schéma particulier et elles sont stockées sous forme de document (ou parfois de graphes).
Ceci ayant plusieurs avantages par rapport à un SGBDR :
- Un accès plus rapide aux données dans un volume important et varié de données
- Simplicité de déploiement dans des environnements distribués
- Scalabilité plus simple et évolutivité très renforcée
Petite intro...
Petite intro...
- Les données sont sous format document,
- Les données ne respectent pas de schéma particulier
- Le code applicatif doit maîtriser l'intégrité des données
- Le NoSQL reprend la notation JSON et met à disposition différentes méthodes permettant de réaliser du CRUD sur vos données.
- Comme pour le SQL, de nombreuses notations sont a connaître pour réaliser du CRUD
NoSQL
Un exemple très rapide pour montrer la syntaxe mongoDB
Un exemple de projet avec GraphQL
Evaluations
Partie théorique
Envoyer fichier sql_theory
Partie pratique
- 15 requêtes à effectuer, difficile d'aller au bout, mais les questions les plus longues sont à la fin (sauf la 15 qui est rapide)
Envoyer le fichier .sql
BON COURAGE !
(après c'est fini)
Workshop
Entity
Workshop Entity : Envoyer le fichier workshop_entity.docx
Workshop SQL
Voir workshop_sql_subject.sql
Workshop NoSQL
Voir workshop_nosql_subject.sql
Gestion des données de l'entreprise
By Cėdric Brasseur



