Les bases NoSQL
Cédric BRASSEUR
Mis à jour le 01/03/2026
Cédric BRASSEUR
- Ancien étudiant de l'Exia.cesi
- 4 ans consultant chez Amaris, placé chez Euro Information Dev
- Auto-entrepreneur depuis début 2020 (Création de sites web, applications mobiles & formateur)
Et vous ?
- Nom, prénom
- Etudes réalisées
- Expériences en NoSQL
Plan du cours
-
Introduction au NoSQL
-
Principes de NoSQL
- Scalabilité
- Théorème CAP
- BASE vs ACID
-
Les principaux types de NoSQL
- clé/valeur,
- orienté colonne,
- document,
- graphe
- Installation et utilisation d’un SGBD non relationnel (MongoDB)

No SQL
Objectifs de la formation
- Stocker et exploiter les données plus ou moins structurées dans un environnement distribué
- Appréhender et comprendre la notion de NoSQL
- Choisir et mettre en œuvre une solution NoSQL
- Créer et manipuler des données à l’aide d’une base NoSQL

Introduction au NoSQL
Qu'est-ce que le NoSQL
NoSQL signifie Not Only SQL, car c'est une technologie souvent complémentaire à une base de données SQL
- Tout d'abord, petit rappel sur le modèle relationnel et son utilisation ainsi que sa prédominance sur ces 50 dernières années,
- Le contexte a changé (pour de nombreux projets)
- Des limites se sont fait ressentir et des cas d'utilisations ont nécessité une meilleure performance et distribution (scalabilité)
- Le NoSQL c'est aussi des outils plus adaptés pour les développeurs
- Utilisation très récurrente du format BSON (JSON)
Le modèle relationnel (rappels)
Le modèle relationnel et ses avantages (car il en a de nombreux !)
- Schéma très proche du business métier de votre application
- Normalisation des données (unicité)
- Accès optimisé (index)
- Contraintes à respecter dans le modèle
- Conception solide
- Nécessité d'une modélisation préalable très précise
- Utilisation de SQL (nécessite des connaissances importantes)
- Conception solide
Le NoSQL est de plus en plus utilisé pour répondre aux enjeux du BigData
Le fonctionnement est différent d'un SGBDR, les données ne respectent pas un schéma particulier et elles sont stockées sous forme de document (ou graphes, ou paires clé/valeur ou encore colonnes).
Ceci ayant plusieurs avantages par rapport à un SGBDR :
- Un accès plus rapide aux données dans un volume important et varié de données
- Simplicité de déploiement dans des environnements distribués
- Scalabilité plus simple et évolutivité très renforcée
NoSQL & Big Data
Le Big Data
le Big Data est une forte Volumétrie, haute Vélocité et grande Variété de données qui exigent des techniques innovantes et rentables de traitement d’informations pour une meilleure efficacité
Volume
Vélocité
Variété


Big Data
- Trop de TO de données à stocker (sans savoir l'anticiper efficacement)
- Les contraintes des moteurs relationnels sont parfois trop lourdes
- Le contexte matériel a évolué
- Usage web avec de nombreux utilisateurs : Nécessite de prévoir une scalabilité très importante
Performance & aisance
Des problématiques
- Web scale
- Modélisation, relations et jointures (contrainte car difficile a rendre scalable)
- Obligation d'utiliser le SQL, ce langage déclaratif difficilement intégrable proprement dans du code
- Esprit Open Source
- Distribution & Performances (Utilisation de la RAM)
- Attention à la persistance si utilisation de la RAM
Scalabilité
On ajoute plusieurs machines qui effectuent les traitements en parallèle.
Utilisation de clusters de machines et du load balancing pour une capacité d'évolution en théorie infinie.
Horizontale
Verticale
On utilise une machine avec des capacités évolutives importantes en termes de RAM, processeurs,... Afin de pouvoir le rendre scalable et le faire évoluer au fil du besoin en termes de scalabilité.
Cette technique a ses limites et peut engendrer des coûts exorbitants.
La « scalabilité » est la capacité d'un SI à s'adapter au rythme de la demande (contraintes matérielles, stockage, temps d'accès, réplication des données...)
- Souvent utilisée pour les SGBDR car évite le besoin de gestion du partitionnement (et de réplication)
- Les ressources dans le schéma correspondent à l'ajout de RAM, CPU, Espace disque,...
SGBDR
Ressources
Ressources
Ressources
Ressources
Ressources
Ressources
Ressources
Ressources
Serveur (Sun Enterprise)
Scalabilité verticale détails
- Plus souvent utilisée pour les bases de données NoSQL
- Les ressources dans le schéma correspondent à l'ajout d'une nouvelle machine à part entière
NoSQL
Ressources
Ressources
Ressources
Ressources
Load balancer

Scalabilité horizontale détails
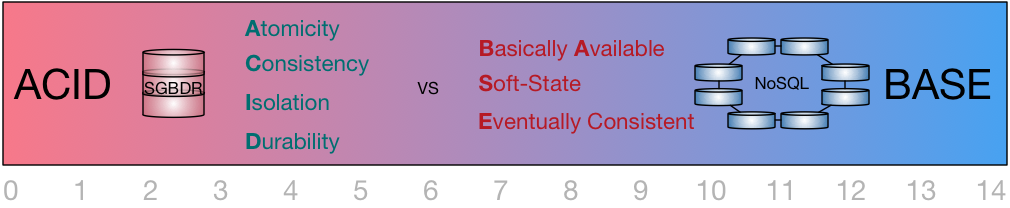
ACID vs BASE
ACID
BASE
- Atomicité : Une transaction s’effectue complètement ou pas du tout
- Cohérence : Le contenu d’une base doit être cohérent avant et après une transaction
- Isolation : Les modifications d’une transaction ne sont validées et modifiables que quand elle a été commit
- Durabilité : Une fois la transaction commitée, l’état de la base est persistant, non affectable par des bugs, ou autres
-
Basically Available : quelle que soit la charge de la base (données/requêtes), le système garantie un fort taux de disponibilité de la donnée
-
Soft-state : La base peut changer lors des mises à jour ou lors d'ajout / suppression de serveurs. La base NoSQL n'a pas à être cohérente en continu
- Eventually consistent : La base atteint un état cohérent au fil du temps
Théorème CAP
Eric A. Brewer (2000) a formalisé un théorème reposant sur 3 propriétés des bases de données (relationnelles, NoSQL et autres) :
- Consistency (Cohérence) : Une donnée n'a qu'un seul état et doit être cohérent quelque soit la requête
- Availability (Disponibilité) : La donnée doit être disponible à tout instant
- Partition Tolerance (Distribution) : Quel que soit le nombre de serveurs dans le cluster, toute requête doit fournir un résultat
CAP !
Le théorème de CAP :
Dans toute base de données, vous ne pouvez respecter au plus que 2 propriétés parmi la cohérence, la disponibilité et la distribution.

CA
Consistency + Availability
SGBDR
Ecriture
Lecture 1
Lecture 2
v1 - v2
Premier côté du triangle
Si on prend le cas où on décide de mettre la priorité sur la cohérence des données et la disponibilité, lors d'une opération de lecture concurrente sur une même données, des lectures simultanées obtiennent forcément le même résultat.
CP
Consistency + Partition
MongoDB
Ecriture
Lecture 1
Lecture 2
v1 - v2
Second côté du triangle
Si on prend le cas où on décide de mettre la priorité sur la cohérence des données et la distribution des données. En même temps, il est nécessaire de vérifier la cohérence des données en garantissant la valeur retournée malgré des mises à jour concurrentielles. La gestion de cette cohérence nécessite un protocole de synchronisation, introduisant des délais de latence dans les temps de réponse.
v1 - v2
attente
Synchro
Dernier côté du triangle
Si on prend le cas où on décide de mettre la priorité sur la distribution des données et la disponibilité, lors d'une opération de lecture concurrente sur une même données, des lectures simultanées n'obtiennent pas forcément le même état de la donnée accédée (car il y a partitionnement et demande de réponse rapide). On dit que la donnée est "Eventually Consistent" et elle sera consistante au fil du temps.
AP
Availability + Partition
CouchDB
Ecriture
Lecture 1
Lecture 2
v1 - v2
v1
Asynchrone
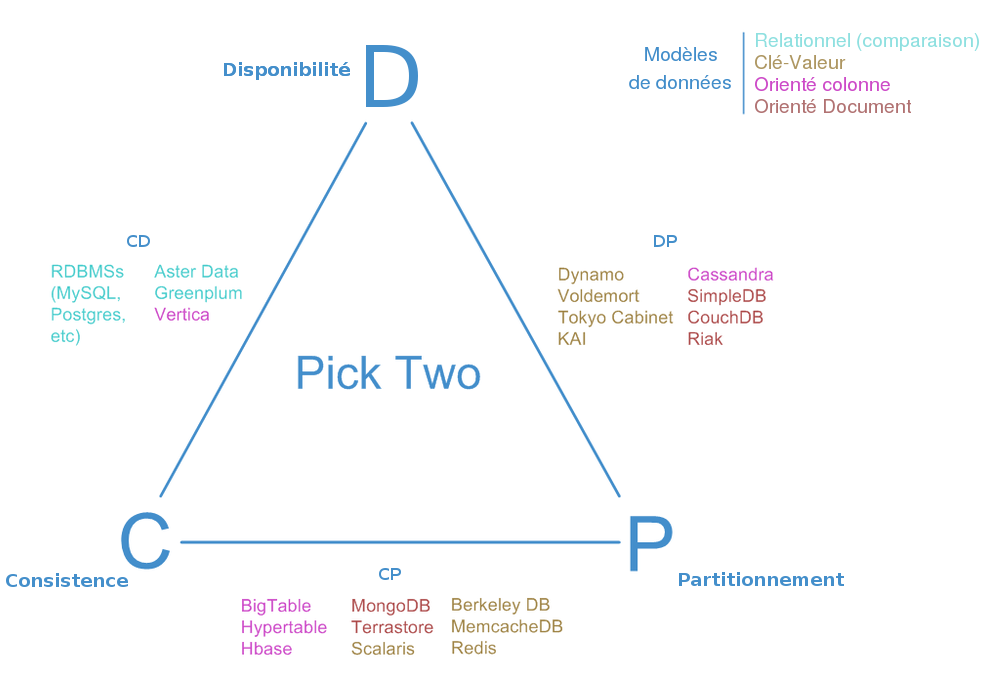
Récapitulatif théorème CAP
Il est donc nécessaire de faire des choix par rapport aux grandes qualités attendues d'une base de données. En fonction de vos priorités, des opportunités s'offrent à vous.
Comment bien choisir ?
Plusieurs axes sont à prendre en compte afin de bien choisir la structure de données adaptée à votre besoin :
- Le besoin en termes de temps de réponse
- La quantité des données à stocker
- La complexité du modèle de données à mettre en place
- Le besoin d'un accès distribué des données (microservices, ou autres)
- La sécurité nécessaire
- Le degrés de disponibilité
- Les connaissances de l'équipe projet
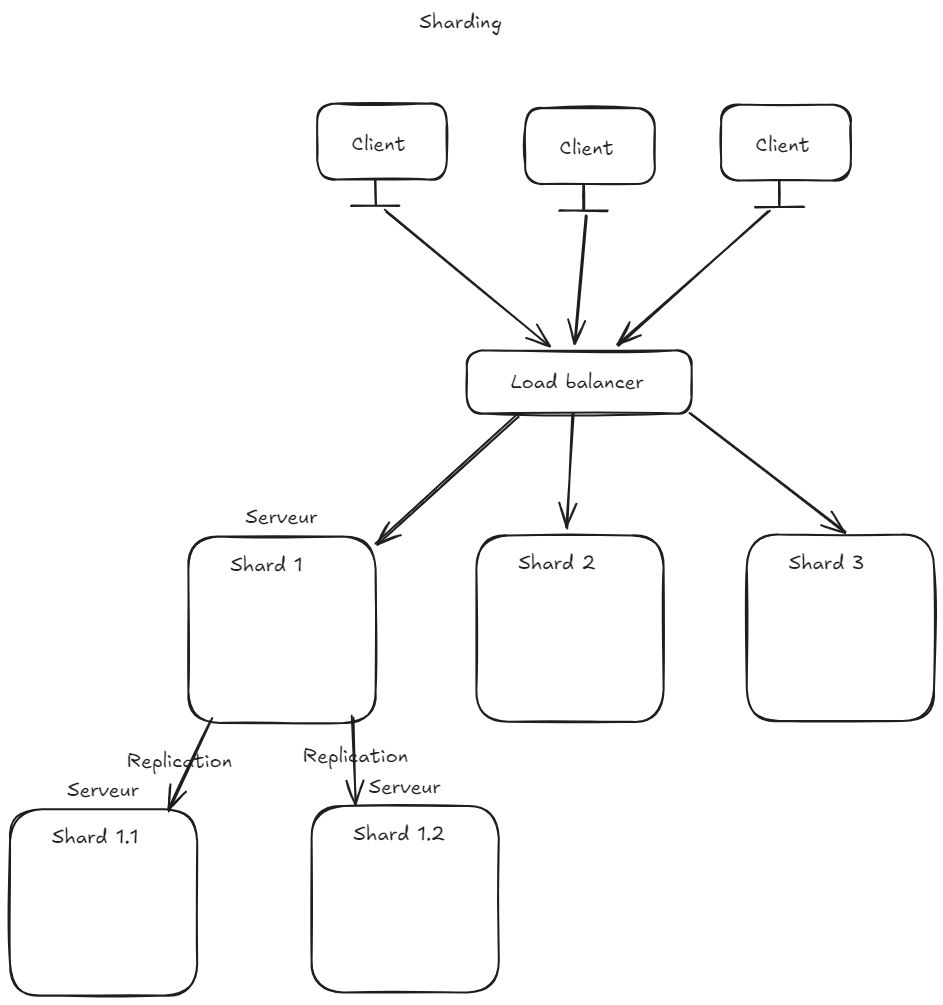
Sharding (et replication en bas à gauche)
Mongo DB
PCA / PRA : méthode 3, 2, 1
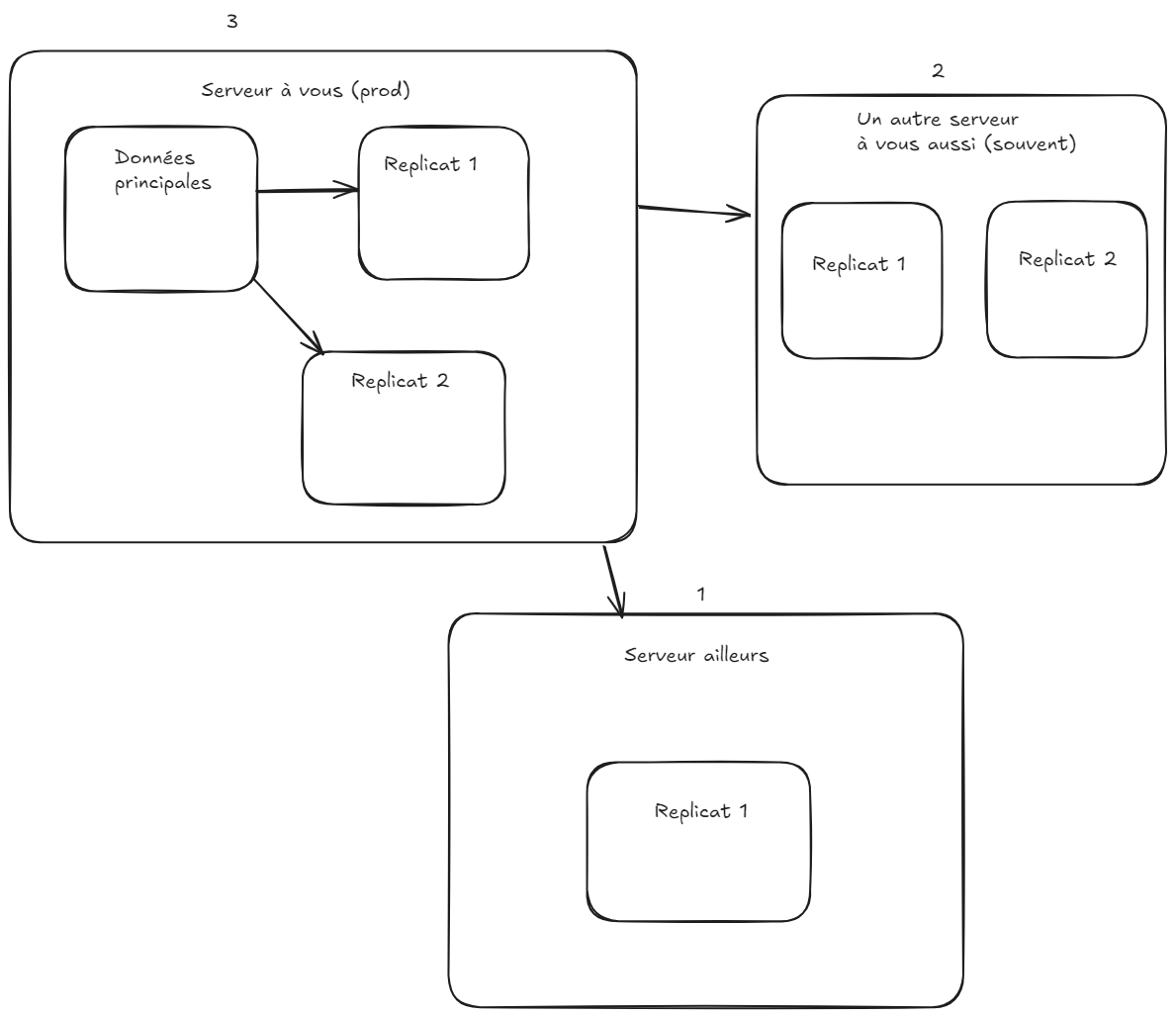
CouchDB
Stockage de données
En NoSQL il y a trois familles de stockage de données
Paires Clé / Valeur
Orienté Colonnes
Document JSON
Paires Clé / Valeur
Pas de relations !
Pas de jointures !
* Document structuré (pas un doc classique)
*
Retour au NoSQL
La structure JSON
{
"premiereCollectionTableauObject": [
{
"premierObjet" : {
"nom": "BRASSEUR",
"prenom": "Cédric",
},
},
{
"secondObjet" : {
"nom": "JEAN",
"prenom": "Sébastien",
},
},
],
"secondNoeudSimpleValeur" : 10,
},Le JSON permet de stocker des données comme on le souhaite, sous forme de tableaux, d'objets ou de simple association
clé => valeur
Avantages
- Lecture rapide et efficace sans accès réseau (potentiellement)
- Format lisible par n'importe quel être humain et n'importe quelle machine (OS)
- Utilisable nativement avec un grand nombre de technologies
- Stockage de différents types de données
- Syntaxe simple et efficace
- Habituel pour les développeurs (normalement)
Inconvénients
JSON (très utilisé en NoSQL)
- Il faut sécuriser soit même les données sensibles
- Pas d'identification précise des données (sous forme de balise par exemple), la structure doit donc être connue avant utilisation.
- Une erreur de code peut vite détruire l'intégrité de vos données
JSON et PHP
Il est simple de travailler avec le format JSON :


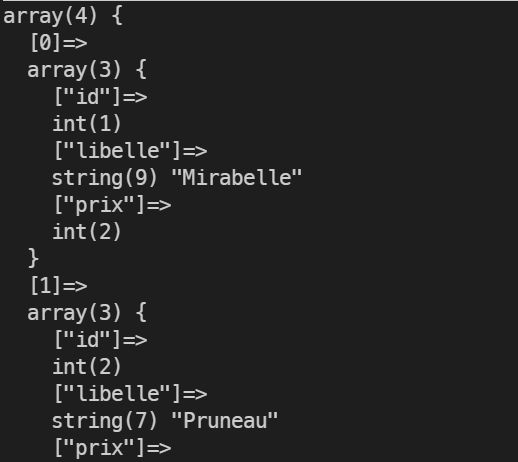
JSON et PHP
De même pour écrire du JSON :
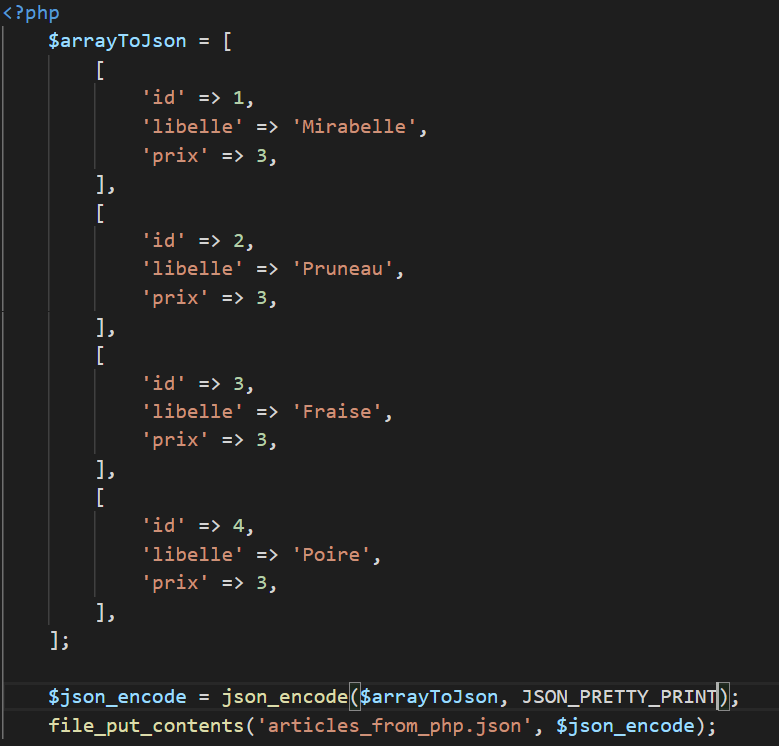
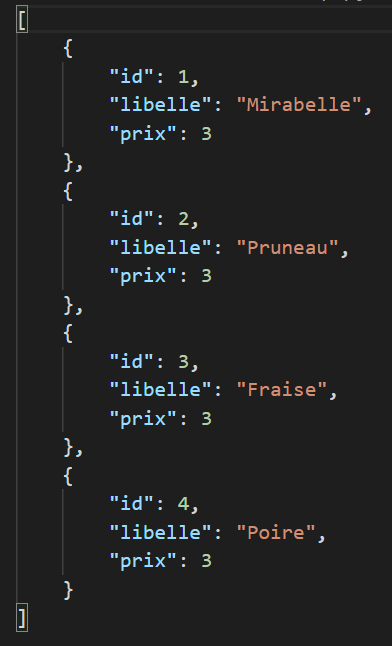
Le document - Structure
L'idée du document c'est qu'il peut et doit être stocké et restitué en une seule fois.
- Parallèle avec un document bureautique
- Utilisation simple
- Dénormalisation : Attention car tout dépend alors de la clé
Attention, on ne parle pas de document classiques, mais de :
- Document structuré : En BSON (JSON)
- On a tout de même la possibilité de joindre des fichiers
binaires
Au final le NoSQL, c'est quoi dans tout ça, petit récap fin d'introduction !
Solutions aux limites relatives au modèle relationnel, essentiellement concernant le Big Data et les problématiques associées de gestion de données.
Notez qu'il vient avec son lot de contraintes également !
Et que beaucoup de choses sont à gérer vous même dans le code client.
Résumé de ce qu'est le NoSQL
Petite intro au MapReduce
Le MapReduce est un concept de développement inventé par Google et qui est très utilisé depuis. Ce concept permet de réaliser des opérations très rapides dans un ensemble de données extrêmement important (PO de données). Hadoop permet l'utilisation de ce concept en utilisant le Disque Dur pour communiquer avec le processeur. Sparke, plus récent, quant à lui permet de réaliser les opérations avec la RAM.
(Workshop plus tard, peut-être)


Inconvénient de Hadoop
Malgré son utilisation massive et qu'il a fait ses preuves, Hadoop a un concurrent direct suite à un simple fait : Le taux de transfert est plus rapide lorsque l'on utilise la RAM, plutôt qu'un disque dur quel qu'il soit.

Disque dur
SSD
RAM
300MB/s (max 600)
600MB/s à 14000 MB/s
20GB/s à 50GB/s
Récapitulatif rapide du taux de transfert
(Données approximatives et datant de moins d'un an)
RAM !
Schéma explicatif
On travaille sur des fichiers et on peut réaliser des opérations spécifiques. Et des opérations de distribution de données et en général ça passe par une étape de tri et d'assemblage des données pour travailler sur des ensembles partitionnés.
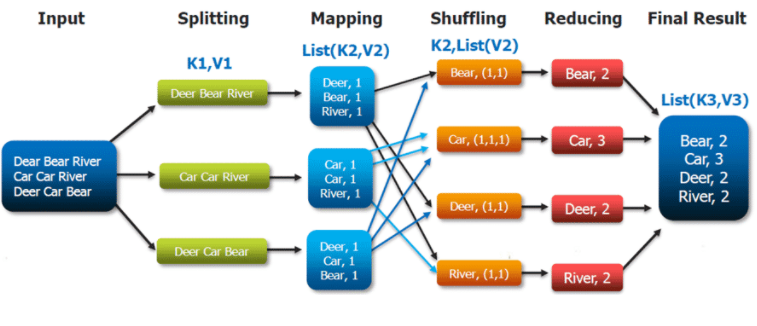
Les différents types de base NoSQL et exemples d'utilisation
Les types de bases NoSQL
Il existe plusieurs types de bases NoSQL, nous en avons vu quelques uns durant la partie sur le théorème CAP. Le but de cette partie est de les lister, les différencier et nous installerons certains d'entre eux pour jouer un peu avec. Avant de se focaliser sur MongoDB (qui est le plus utilisé)
- Orienté Documents : MongoDB, CouchDB,...
- Orienté Graphes : OrientDB, Néo4j,...
- Orienté Colonnes : HBase, Hypertable, Cassandra
- Orienté Clé/valeur : Redis, AmazonSimpleDB, Voldemort...
Les types de bases NoSQL
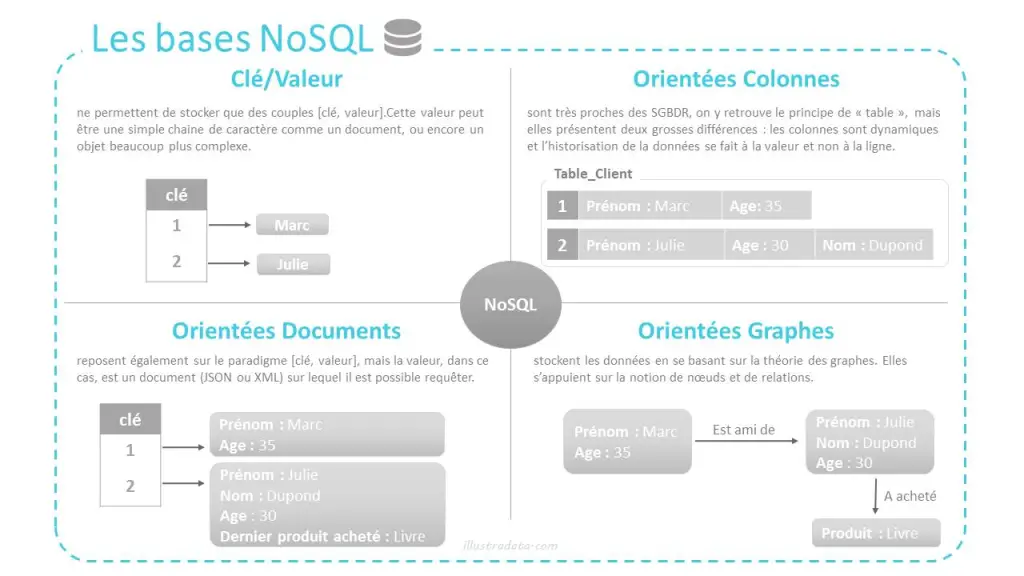
Petit schéma comparatif des types
L'orienté Clé / Valeur
Explication et utilisation de Redis
Ces bases permettent de stocker des couples [clé, valeur].
Cette valeur peut être une simple chaîne de caractères, un document, ou encore un objet complet.
Avantages :
- Simple d'utilisation, scalabilité, disponibilité
- Très bonnes perfs car lectures et écritures réalisées en mémoire (RAM)
Utilisation :
- Stockage de données de session : Par exemple, un panier Amazon
- Stockage de données de jeux vidéos : Par exemple Summoners War
- Stockage temporaire sans archivage
Faiblesses :
- Pas de requête sur le contenu des objets stockées (Gestion côté code)
- Pas adapté à un modèle de données complexe
- Persistance des données complexifiée
Redis with Docker
Nous allons démarrer un conteneur Redis (on fera un exercice juste après)
Voici les trois commandes nécessaires pour utiliser Redis avec Docker (à exécuter en deux commandes séparées)
:
docker run --name my-redis -p 6379:6379 -d redis
docker exec -it my-redis bashPuis
redis-cliLe serveur est déjà lancé sur le conteneur (donc pas besoin de la commande redis-server)
Installation de Redis
Nous allons installer Redis (on fera un exercice juste après)
Pour installer Redis, le plus simple est d'avoir accès à une machine Unix, soit en virtuel, soit avec WSL ou directement sur une distribution. (Sous Mac avec Docker : https://medium.com/idomongodb/installing-redis-server-using-docker-container-453c3cfffbdf)
Nous allons suivre cette documentation très simple : https://redis.io/topics/quickstart
Cette documentation dit de suivre deux étapes :
wget http://download.redis.io/redis-stable.tar.gz
tar xvzf redis-stable.tar.gz
cd redis-stable
makePuis
sudo make install
(ou cp les deux fichiers, redis-cli et redis-server vers /usr/local/bin/ , à votre convenance)Démarrage de Redis Server
Nous allons démarrer Redis Server (Personnellement j'utilise mon terminal dans VSCode par habitude, mais vous pouvez utiliser votre outil de commande habituel (WSL, si sur WSL))
Si on a bien réalisé la seconde partie d'installation, il suffit de faire (peu importe où vous vous trouvez) :
redis-serverDémarrage de Redis Client
Nous allons démarrer Redis Client pour pouvoir effectuer des requêtes sur notre redis server.
Pour tester ça, on doit va réaliser les opérations suivantes :
redis-cli
redis 127.0.0.1:6379> ping
PONG
redis 127.0.0.1:6379> set mykey somevalue
OK
redis 127.0.0.1:6379> get mykey
"somevalue"Petite démo Redis
Juste pour vous montrer un peu comment ça marche avant l'exercice, je vais vous montrer comment on peut utiliser Redis à travers les différentes méthodes proposées.
Documentation !!!
Documentation des commandes
Documentation !!!
Documentation !!!
Exercice sur Redis
Prise en main et utilisation de Redis
- Si vous n'avez pas installé Redis, installez-le, le lien d'installation se trouve dans une slide précédente et les étapes sont très simples (sur unix ou WSL).
- Je vais vous envoyer un workshop guidé pour pratiquer redis en ligne de commande.
- Testez quelques autres fonctionnalités, comme EXPIRE, INCR, INCRBY, APPEND, GETSET, GETRANGE,...
- Un second workshop est possible, mais il est bien plus long et complexe et nous ne prendrons pas le temps de le réaliser ensemble, mais n'hésitez pas à pratiquer chez vous !
N'hésitez pas à me demander de l'aide ou des informations durant cet exercice peu guidé. Le but est de tester un peu Redis par vous-même.
Exercice sur Redis
Exercice node / Redis
- Dans le fichier index.js que je vous envoie, vous avez toutes les informations nécessaires à la réalisation de ce petit exercice de prise en main de redis avec node.js.
N'hésitez pas à me demander de l'aide ou des informations durant cet exercice peu guidé. Le but est de tester un peu Redis par vous-même.
Aller plus loin - Redis
Utilisation de Redis avec Node ou Python
Réalisez un code client en NodeJS (ou en Python) permettant de communiquer avec la base Redis mise en place lors de l'exercice après démonstration. (Ou autre idée)
Utiliser Python est une bonne idée car c'est un langage simple qu'on pourrait utiliser avec tout* (* à vérifier) les types de bases NoSQL.
Exemple de code avec NodeJS : https://learntutorials.net/fr/node-js/topic/7107/nodejs-avec-redis
Exemple de code avec Python : https://developer.redis.com/develop/python/fastapi
Installation de Python : https://docs.python-guide.org/starting/install3/linux/
L'orienté Document
Explication et utilisation de CouchDB
Utilise également le couple clé / valeur et la valeur, est un document.
Ce document a une structure arborescente : comme vu précédemment c'est souvent au format JSON (ou XML)
Avantages :
- Les documents sont structurés sans définition de structure nécessaire
- On peut requêter ces documents, et récupérer, via une seule clé,
un ensemble d’informations structurées de manière hiérarchique
Utilisation :
- Les données clients (Stockage de toutes les transactions et
information du client au sein d’un même document (même clé). - La gestion catalogue de produits
- Le Web analytics
Faiblesses :
- Gestion des données interconnectées ni pour les données non-structurées

- Disponible avec une interface REST
- Interface de gestion avec Fauxton
- Simple à utiliser
- Structuré en documents
CouchDB - Documents
CouchDB est une base de données OpenSource développée par Apache. Très utilisé dans le web, informations facile à utiliser en Javascript ou JQuery...
C'est le code client qui doit réaliser un certain nombre d'opérations de vérifications et de gestion des versions des documents en contrepartie.
Docker & CouchDB
Nous allons démarrer un conteneur CouchDB (on fera un exercice juste après)
Voici la commande pour utiliser CouchDB avec Docker :
docker run --name my-couchdb -e COUCHDB_USER=root -e COUCHDB_PASSWORD=root -p 5984:5984 -d couchdb
Installation de CouchDB
Nous allons installer CouchDB (on fera un exercice juste après)
Pour installer CouchDB, il devrait être simple d'utiliser WSL ou un système Unix. Malheureusement, j'ai eu des soucis de démarrage du service couchdb, j'ai donc installé via le paquet Windows et ça a très bien fonctionné.
Nous allons télécharger sur :
http://couchdb.apache.org/#download
Ou suivre les étapes d'installation sur :
https://docs.couchdb.org/en/stable/install/index.html
Si vous avez des soucis d'installation, nous tenterons de les résoudre ensemble durant l'exercice juste après. Désolé par avance pour ceux qui sont sous Mac !
Les interfaces - REST
Representational State Transfer
De manière générale, le Web est composé de REST (états et fonctionnalités basées sur des appels d'URL).
CouchDB possède une interface REST accessible via : http://localhost:5984/
Et une interface web Fauxton : http://localhost:5984/_utils/#
GET
HEAD
PUT
DELETE
POST
OPTIONS
Récupération d'un contenu
Comme GET mais pour le header (méta)
Mise à jour de contenu (complet)
Ajout de contenu
Suppression de contenu
Retourne les ressources disponibles
Les interfaces - REST
Utilisation de la commande curl
curl est une commande simple permettant d'appeler des URL en REST, cette commande vous permettra de communiquer avec l'API REST proposée par couchdb et donc travailler sur votre base de données.
curl http://localhost:5984/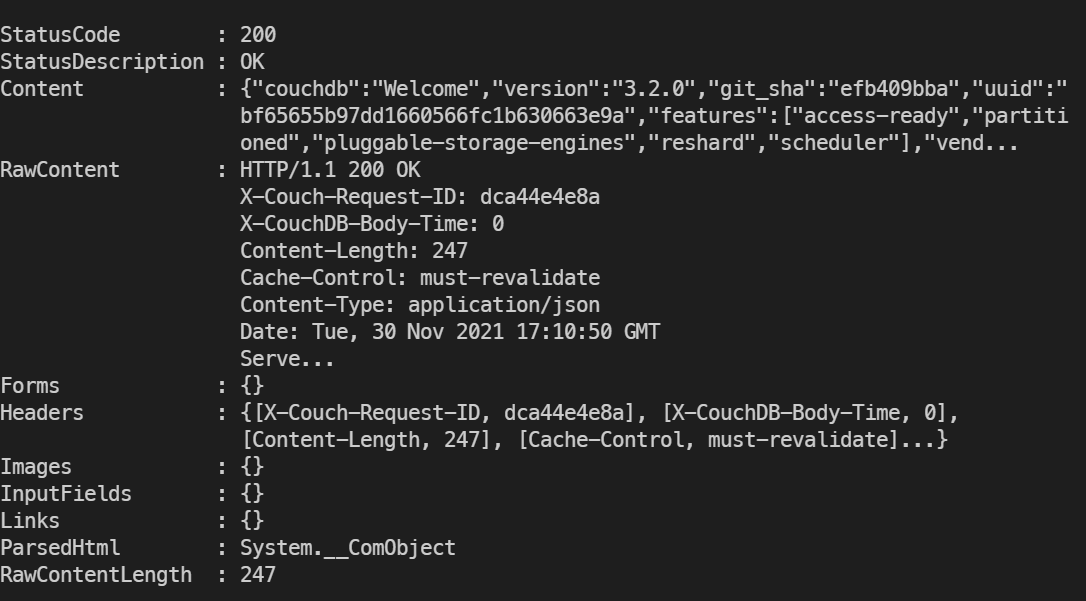
Conseillé sous Unix
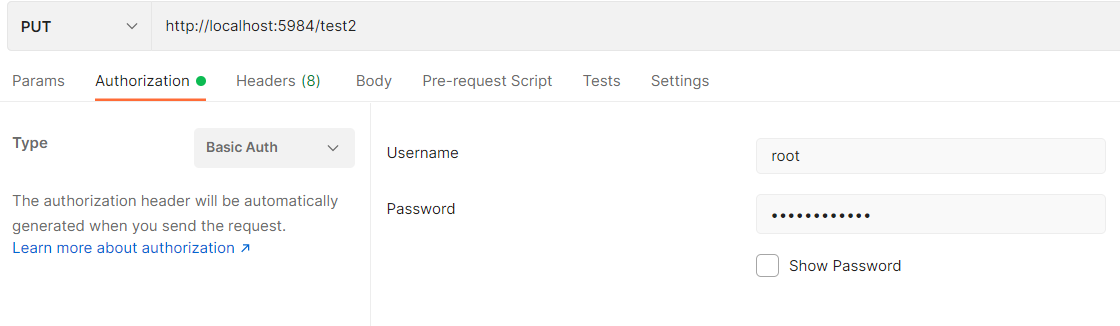
Les interfaces - REST
Utilisation de Postman
Postman est un outil de requêtage REST très pratique.
Conseillé sous Windows
& Mac

Il permet de faire tout type de requêtes, je vous conseille de paramétrer pour chaque requête l'authentification basique avec votre compte CouchDB.
Gestion des révisions
Attention particulière sur les révisions, elles ne sont pas stables indéfiniment dans le temps, une opération de compression des données est effectuée automatiquement.
Une version est ajoutée à chaque modification
http://localhost:5984/test2/001
{
"_id": "001",
"_rev": "1-c3d84a0ca6114a8e8fbef75dc8c7be00",
"test": "test"
}Récupérer les infos de version d'un doc
http://localhost:5984/test2/001?revs=trueRécupérer les infos d'une version spécifique
http://localhost:5984/test2/001?rev=1-c3d84a0ca6114a8e8fbef75dc8c7be00Petite démo CouchDB
Juste pour vous montrer un peu comment ça marche avant l'exercice, je vais vous montrer comment on peut utiliser CouchDB et Fauxton.
Documentation !!!
Documentation de CouchDB
Documentation !!!
Documentation !!!
Accès à CouchDB (Client)
Nous allons voir rapidement comment exploiter une base de données CouchDB avec NodeJS.
Vous devez installer npm (ça ne devrait pas être trop dur). Installer node-couch avec :
Puis il suffit de faire une connexion et des opérations sur la base, voici un exemple et un lien : https://www.npmjs.com/package/node-couchdb
const NodeCouchDb = require('node-couchdb');
// node-couchdb instance with default options
const couch = new NodeCouchDb({
auth: {
user: 'root',
pass: 'root'
}
});
couch.createDatabase("testfromnode").then(() => {
console.log("Creation done")
}, err => {
console.log("Error :" + err)
});npm install node-couchdb --saveAccès à CouchDB (Mango)
Vous pouvez requêter directement depuis l'interface Fauxton avec Mango, je vous laisserai parcourir un peu tout ça juste après. Et nous verrons plus en détails la syntaxe de requêtage d'un document NoSQL dans la partie sur MongoDB.
Documentation !!!
Documentation de CouchDB via Mango
Documentation !!!
Documentation !!!
Infos & démo Réplication
Petite démo de Réplication de base avec CouchDB
- Créer une base de données pour la réplication : Soit en ligne de commande, soit depuis Fauxton.
- Cliquez sur l'icone : Répliquez la base réalisée et vérifiez que les données sont bien répliquées
- Modifiez la base principale : Vérifiez que la réplication est bien effective

Possibilité de mettre en place de la réplication automatique sur des serveurs locaux ou distants aisément
Exercice sur CouchDB
Prise en main et utilisation de CouchDB
- Si vous n'avez pas installé CouchDB, installez-le, le lien d'installation se trouve dans une slide précédente et les étapes sont assez simples.
N'hésitez pas à me demander de l'aide ou des informations durant cet exercice, le but est de s'exercer et appréhender globalement CouchDB
Envoyer Exercice-simple-couch.md
Aller plus loin - CouchDB
Utilisation de CouchDB avec Node
Réalisez le code nécessaire avec node (ou autre technologie) permettant de réaliser les opérations suivantes :
- Réalisez l'opération permettant de vous connecter à votre CouchDB
- Réalisez l'opération d'ajout d'une salle (Avec un nom de salle et une capacité)
- Affichez un message de succès ou échec
- Réalisez l'opération de récupération d'une salle en particulier
- Affichez un élément de la salle récupérée
- Réalisez l'opération de modification d'une salle avec vérification de son existence au préalable
- Réalisez l'opération de suppression d'une salle existante avec vérification de son existence au préalable
!! TOUTES LES DONNES PEUVENT ÊTRE EN DUR ET DES DONNEES DE TESTS !!
Documentation node-couchdb :
https://www.npmjs.com/package/node-couchdb
L'orienté Colonnes
Explications sur l'orienté Colonnes
Elles se rapprochent le plus de la structure des bases de données relationnelles. On retrouve le principe de “tables” avec des lignes et des colonnes, mais elles ont deux principales grosses différences :
- Les colonnes sont dynamiques
- L’historisation des données se fait à la valeur et non pas à la ligne
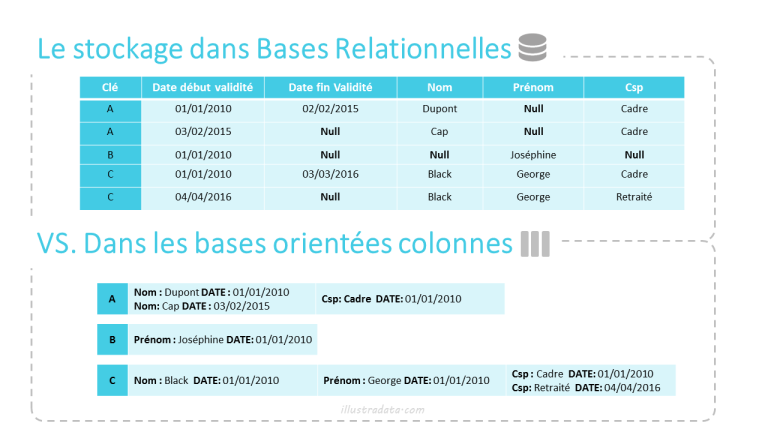
L'orienté Colonnes
Avantages :
- Flexibilité
- Temps de traitement
- Non-stockage des valeurs null
- Historisation à la valeur
Utilisation :
- Le suivi de colis (de nombreux évènements dont le statut
change fréquemment) - La récupération et l’analyse de données en temps réel issues
de capteurs, IOT;...
Faiblesses :
- Non-adapté aux données interconnectées
- Non-adapté pour les données non-structurées
L'orienté Colonnes
| Feature | Column oriented (NoSQL) | SQL (PostgreSQL/MySQL) |
|---|---|---|
| Best for | Big Data, Fast Writes, Availability | Complex Queries, Transactions |
| Scaling | Horizontally (more nodes) | Vertically (bigger servers) |
| Joins | ❌ Not Supported | ✅ Fully Supported |
| Transactions | ❌ Weak (No ACID) | ✅ Strong (ACID) |
| Replication | ✅ Automatic, Multi-Datacenter | ❌ Manual, Single Master |
| Use Case | IoT, Streaming, Logs, Social Media | Banking, ERP, CRM, Inventory |
Les différences entre un SGBDR et du NoSQL orienté colonnes :
Merci chat GPT ici...
On ne prendra pas le temps de voir l'orienté colonne, ça ressemble vraiment beaucoup au SQL que vous connaissez déjà, même dans la syntaxe des requêtes.
Je vous conseille Cassandra si vous souhaitez essayer.
Check Duck DB
L'orienté Graphes
Explications de l'orienté Graphes
Ces bases ont pour objectif de stocker les données en se basant sur la théorie des graphes. Elles s’appuient sur les notions de noeuds qui ont chacun leur propre structure, relations entre les noeuds, propriétés (de noeuds ou de relations),...
Avantages :
- Adaptées aux objets complexes organisés en réseaux (dépendances)
- Théorie des graphes et mise en place de visualisation de graphes automatisée
- Plus rapides que les autres pour manipuler les données fortement connectées
Utilisation :
- Modélisation des données provenant des réseaux sociaux
- Moteur de recommandations
- Données géo spatiales (réseaux ferrés etc..)
Faiblesses :
- Pas adapté pour autre chose, il n'y a pas d'intérêt sauf pour des données dépendantes les unes des autres
Comparaison entre Graphes et Relationnel
Ce type de base de données NoSQL étant la plus proche d'un modèle relationnel, il est intéressant de comparer les deux, voici un schéma récapitulatif de ce qu'il faut savoir
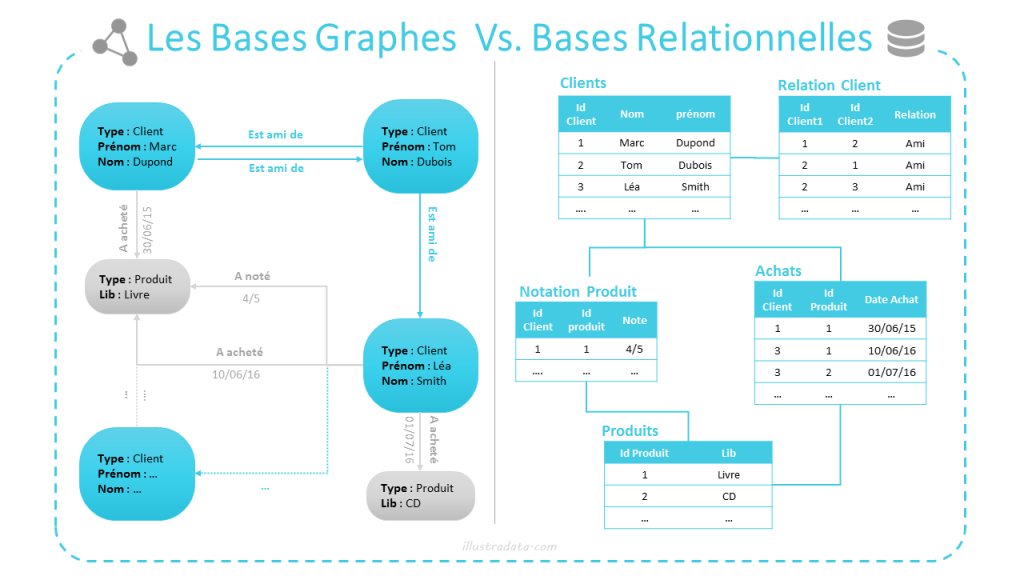
Envoyer CheatSheet
Utilisation de Neo4j
Nous allons démarrer un conteneur Neo4j et je vous propose de regarder les tutoriels qui sont intégrés à Neo4j qui sont extrêmement bien fait pour démarrer avec cette base de données.
Voici la commande pour utiliser Neo4j avec Docker :
docker run -d --name neo4j -p 7474:7474 -p 7687:7687 -e NEO4J_AUTH=neo4j/Admin123- neo4j
Exercice sur Neo4j
Prise en main et utilisation de Neo4j
- Suivez les instructions du fichier .md, il y a trois exercices à faire avec Neo4j pour pratiquer l'orienté graphe (le troisième exercice est quand même un peu plus complexe)
Envoyer Neo4j-exercices.md
Installation et utilisation de MongoDB
- Très simple à utiliser
- Interface de gestion avec
MongoDBCompass - Structuré en documents
MongoDB - Documents
MongoDB est une base de données orientée documents. Très utilisé dans le web de manière générale en NoSQL.
C'est le code client qui doit réaliser un certain nombre d'opérations de vérifications et de gestion des versions des documents en contrepartie.

MongoDB - Avantages
MongoDB permet de travailler sur des bases de données contenant de nombreuses données.
Son utilisation est plus flexible qu'une base de données relationnelle car on ne respecte pas (forcément) un schéma prédéfini, même si c'est possible.
Comme vu lors du théorème CAP, on choisi souvent une base comme MongoDB pour sa scalabilité horizontale.
De plus, MongoDB a des éléments intégrés pour gérer le sharding (aperçu plus tard)
Les cas d'usages fréquents sont les suivants :
- Stocker un grand nombre de données qui ne sont pas structurées
- Stocker des données qui sont fréquemment accédées ou modifiées
- Stocker des données qui ont besoin d'être analysées ou utilisée en temps réel
- Stocker des données qui ont besoin d'être accédées par plusieurs serveurs ou process concurrentiels
Installation de MongoDB
Nous allons démarrer un conteneur MongoDB avec Docker
Les commandes à réaliser sont :
- Récupérer l'image mongo
docker pull mongo
- Start mongo container :
docker run --name mongodb -d -p 27017:27017 mongo
- Arriver dans le terminal de commande du conteneur :
docker exec -it mongodb bash
- Démarrer mongo en invite de commande (dans docker) :
mongosh
**Vous êtes connecté sur mongo sur docker !**
Via Docker
docker run --name mongodb -d -p 27017:27017 mongodocker exec -it mongodb bash
mongoshInstallation de MongoDB
Nous allons installer MongoDB (on fera un exercice juste après)
Téléchargement :
- Lien : https://www.mongodb.com/try/download/community
Commandes :
- Se placer en cmd sur le bon répertoire (si la variable d'environnement n'est pas configurée à l'installation): `cd "C:\Program Files\MongoDB\Server\5.0\bin"` (vérifier votre version)
- Démarrage de mongoDB : ou `mongosh`
- **Vous êtes connecté sur mongo en local !**
Compass
MongoDB - Interface
MongoDBCompass est une interface de gestion de votre base de données mongoDB, sous Windows, c'est installé en même temps que mongoDB (avec Windows).
Chaîne de connexion locale :
- mongodb://localhost:27017/
Normalement, c'est pré-configuré au lancement de Compass
Download (si docker)
MongoDB - Import de données
MongoDB propose deux moyens d'importer des données : soit via l'outil mongoimport (évitons nous de l'installer, mais vous pouvez tester), soit via MongoDBCompass avec l'outil graphique d'import de données. D'abord on va créer la DB restaurants, puis la collection new_york (nécessaire, faites le en ligne de commande comme on a vu)
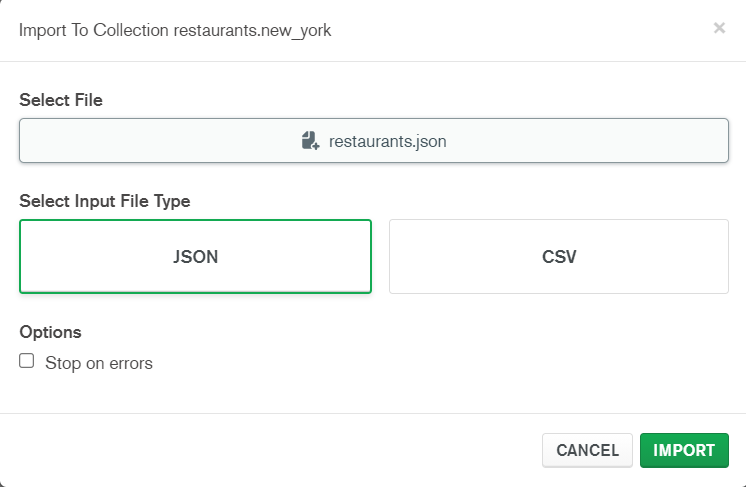
MongoDB - Import de données
Si besoin, voici les commandes pour importer un fichier en ligne de commande :
- Copiez votre fichier restaurants.json dans un dossier, par exemple /tmp avec cette commande (modifier les liens en fonction)
docker cp .\MongoDB\InitializeDB\restaurants.json mongodb:/tmp/restaurants.json
- Utilisation de la commande d'import mongoimport :
mongoimport mongodb://localhost:27017 /tmp/restaurants.json
En ligne de commandes
MongoDB - Filtrage des données
Plusieurs opérations et opérateurs sont utilisables pour filtrer des données avec MongoDB. Déjà, comme on l'a vu, find récupère plusieurs résultats et findOne en récupère qu'un seul, les deux opérations acceptants des filtres.
Modificateurs après lecture
- sort : Tri de manière croissante (1) ou décroissante (-1) sur des champs donnés
- limit : Limite le nombre de résultats donné
- skip : Ignore le nombre de résultats donné
Opérateurs de filtres
Se fait toujours via un sous objet JSON.
Exemple : db.dogs.find({name : {$gte:"B"}})
Opérateurs : $eq, $in, $nin, $ne, $gt, $lt, $gte, $and, $or, $exists,$push,$pull...
Voir Cheat Sheet
Petite démo MongoDB
Juste pour vous montrer un peu comment ça marche avant l'exercice, je vais vous montrer comment on peut utiliser MongoDB à travers les différentes méthodes proposées.
Documentation !!!
Documentation des commandes
Documentation !!!
Documentation !!!
+ Envoyer le document complémentaire MongoDB_Cheat_Sheet_Dark.pdf (Récupéré de WebDevSimplify)
Exercice sur MongoDB
Prise en main et utilisation de MongoDB
- Si vous n'avez pas installé MongoDB, installez-le, (docker si possible) sinon le lien d'installation se trouve dans une slide précédente et les étapes sont très simples quelque soit l'OS.
N'hésitez pas à me demander de l'aide ou des informations durant cet exercice peu guidé. Le but est de tester un peu MongoDB par vous-même dans un premier temps.
Envoyer simple_mongo_queries.md
+ users.json
Exercice sur MongoDB
Opérations & filtres avec MongoDB
Exercice complémentaire MongoDB avec le json "employés".
Envoyer le document Exercice_Simple_MongoDB.docx
Utilisez ce que l'on a vu pour réaliser les opérations demandées
N'hésitez pas à me demander de l'aide ou des informations. Le but est de tester les filtres MongoDB.
Exercice sur MongoDB
Agrégations et autres
Exercice complémentaire MongoDB avec le json "movies".
Envoyer le document Exercice3_Movies.md
Utilisez ce que l'on a vu pour réaliser les opérations demandées
N'hésitez pas à me demander de l'aide ou des informations. Le but est de tester les filtres MongoDB.
Petite démo MongoDB
Petite démo de mongoDB avec les agrégations et les différentes possibilités plus avancées
+ Embed / Reference
+ $Lookup / $unwind / $match /...
Exercice sur MongoDB
Lookup / jointures
Envoyer le document exercice_lookup_simple.md
Utilisez ce que l'on a vu pour réaliser les opérations demandées
N'hésitez pas à me demander de l'aide ou des informations. Le but est de tester les jointures MongoDB.
Petite démo MongoDB (Client)
Petite démo d'utilisation de MongoDB avec NodeJS.
Documentation !!!
Documentation des commandes
Documentation !!!
Documentation !!!
Workshop
Utilisation de MongoDB avec Node et MongoClient
Vous pouvez me poser des questions !
Envoyer nodejs-mongo-client.md
Workshop
Utilisation de MongoDB avec Node (plus avancé)
Ce Workshop se fait en deux étapes :
- Je vous envoie un code (fonctionnel normalement) sur la mise en place d'un serveur node afin de pouvoir gérer des tutoriels via une API et mongoose. Vous devez tester que l'API fonctionne en faisant les appels HTTP nécessaires.
- Vous devez suivre un tutoriel qui vous permettra de réaliser la même chose pour des parkings
Envoyer le code node-express-mongodb
+ exercice_nodejs_express_mongode.md
Index & MongoDB
Il est également possible de créer des indexes, ils permettent d'optimiser l'accès aux données (attention aux contres performances en update/insert/delete)
Un index simple se créer sur une collection
db.collection.createIndex({"age": -1}, {"name": "idx_age"})
Un index automatique est créé sur l'id sur l'age de manière décroissante et il n'est effectif que en cas de filtre sur l'âge uniquement !
Index composé & unique
A l'instar d'une base de données relationnelle, il est également possible de créer des indexes composés. Il doit aussi respecter la vectorisation des données.
Un index composé se créer sur une collection
db.dogs.createIndex(
{"name": 1,"age":1, "weight": 1},
{"name": "idx_name_age_weight"}
)
On peut créer un index unique
db.users.createIndex({ email: 1 }, { unique: true })
Check utilisation index pour une query
Ajouter .explain() à la fin, si IXSCAN => index, si COLLSCAN => pas index
Un index unique force l'unicité des valeurs dans la collection, sinon une erreur est remontée lors d'une tentative d'insertion.
Stats utilisation !
Les vues avec MongoDB
Exemple de création et utilisation de vues
Les vues permettent de réaliser des sortes de collections intermédiaires utilisant les collections de bases (ou les autres vues) présentes sur la même base.
- Il est impossible de les renommer, elles devront être détruites avec drop puis recréées.
- La définition d’une vue est publique, il faut donc faire attention aux données sensibles qui peuvent y figurer.
Petit exemple de création de vue :
db.createView(
"adoption",
"dogs",
[{ $project: { "_id": 0, "name": "$name", "age": "$age" }}]
)
Introduction sharding
Explication sharding
Le sharding permet de partager les documents sur un cluster de serveurs. Ceci permettant de paralléliser les traitements en plus de séparer les données.
On démarre d'un répliquât (comme vu avec CouchDB) puis un partitionnement des données est effectué.
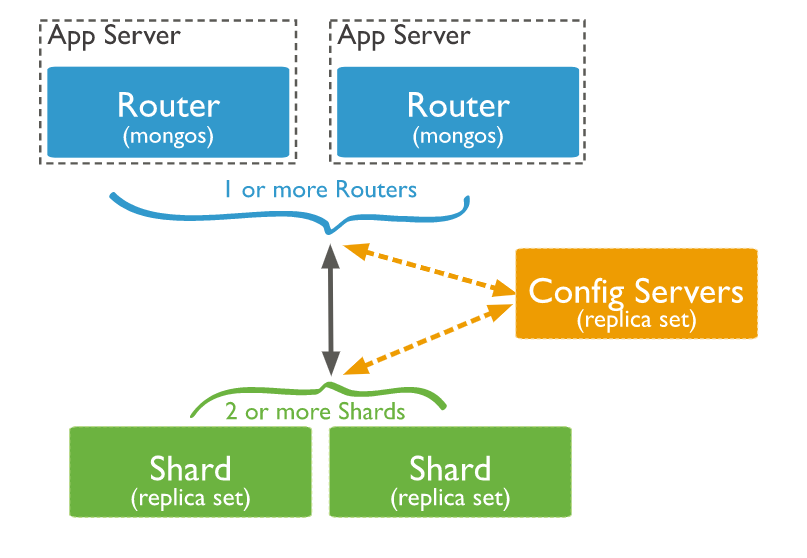
Introduction au sharding
Schéma sharding (application docker)
mongos
mongos
Users
60000
config servers
P
S
S
40002
40003
40001
P
S
S
50002
50003
50001
Shard2
P
S
S
Shard1
Cluster
Petite démo sharding
Si on a encore assez de temps, on va aller voir rapidement un ancien sharding que j'ai pu mettre en place avec docker, je l'ai simplifié au maximum. Nous allons entrevoir rapidement les infos qui y sont présentes et comment l'utiliser.
Documentation !!!
J'ai pas vraiment de documentation à proposer malheureusement.
Documentation !!!
Documentation !!!
Exemple complet sharding
Ici, je vous propose de regarder le travail qui a été fait par quelqu'un d'autre car son travail est extrêmement bien fait !
Il n'est pas nécessaire que vous comprenez absolument tout, mais prenez le temps de suivre le README.md et de vous intéresser à ce qu'il se passe
ElasticSearch est une base de données NoSQL pouvant indexer des documents textes. On pourrait le comparer à un moteur de recherche, mais que l'on peut paramétrer pour qu’il colle exactement à vos besoins de recherche.
ElasticSearch, c’est donc un moteur de recherche capable de stocker une grande quantité de documents et que l’on peut interroger en temps réel.
Outro ElasticSearch

Evaluations
Partie théorique
Impression du fichier no_sql_theory.docx
Evaluation type QCM sur papier, les règles de notation seront inscrites sur le document d'évaluations
Partie pratique
BON COURAGE !
(après c'est fini)
Envoyer le fichier no_sql_workshop.docx
No SQL
By Cėdric Brasseur



