












Kevin Song
I'm a student at UT (that's the one in Austin) who studies things.
We've added persistent storage to our computers to make sure that power-offs don't completely destroy all our data.
Disks are great!
Then we added glue code to make sure we could interact with this storage in a reasonable manner. This resulted in a filesystem.
We evaluated the filesystem based on three goals:
CPU
We start knowing the i# of
the root directory (usually 2)
We have enough space in memory to store two blocks worth of data
Everything else has to be requested from disk.
The request must be in the form of a block#. E.g. we can request "read block 27", but we cannot request "read next block" or "read next file"
You may assume that we already know the i# of the file header.
CPU
You may assume that we already know the i# of the file header.
CPU
Instead of forcing users to refer to files by the inumbers, we created directories, which were mappings from file names to inumbers.
| File Name | inode number |
|---|---|
| .bashrc | 27 |
| Documents | 30 |
| Pictures | 3392 |
| .ssh | 7 |
Users can refer to files using paths, which are a series of directory names.
The root is a special directory, and it's name is "/".
Traversing paths from the root can require many, many disk lookups. We optimized this by maintaining a current working directory.
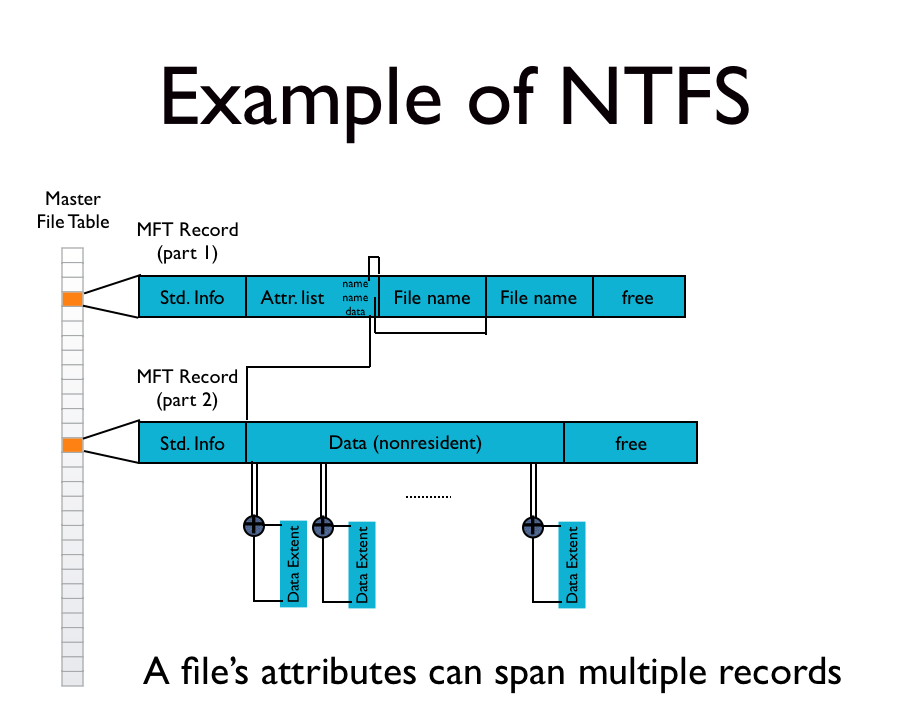
NTFS, the "New Technology File System," was released by Microsoft in July of 1993.
It remains the default filesystem for all Windows PCs--if you've ever used Windows, you've used an NTFS filesystem.
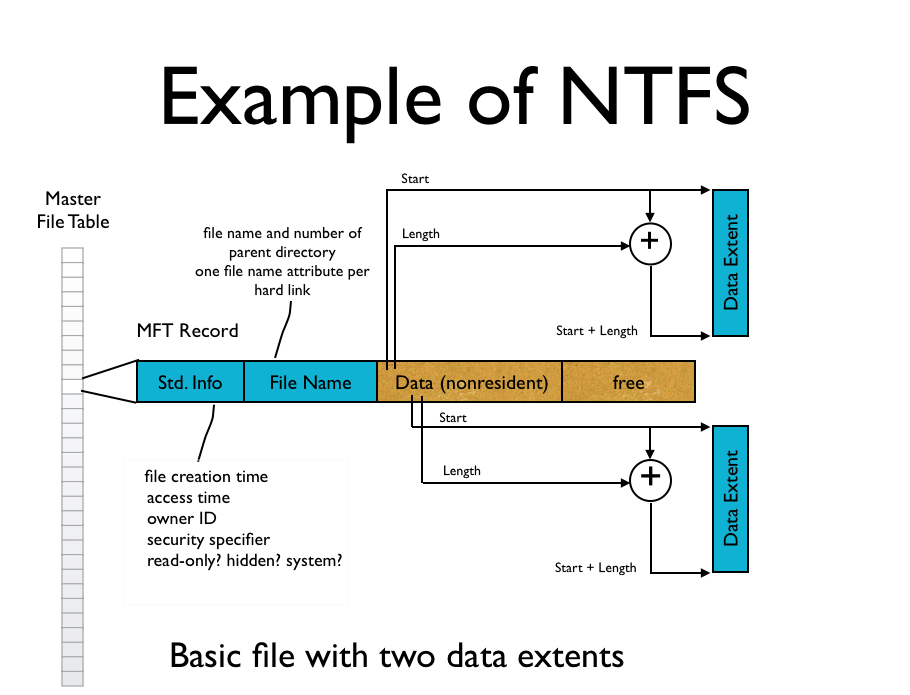
NTFS uses two new (to us!) ideas to track its files: extents and flexible trees.
Track a range of contiguous blocks instead of a single block.
Example: a direct-allocated file uses blocks 192,193,194,657,658,659
Using extents, we could store this as (192,3), (657, 3)
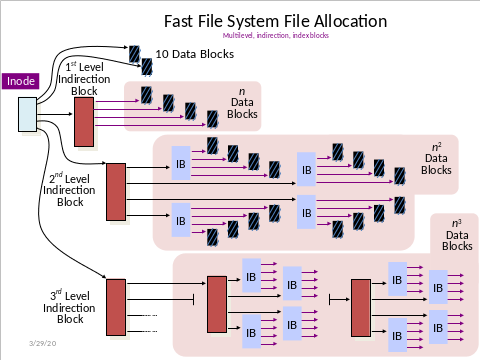
Files are represented by a variable-depth tree.
A Master File Table (MFT) stores the trees' roots
Not enough space for data pointers!
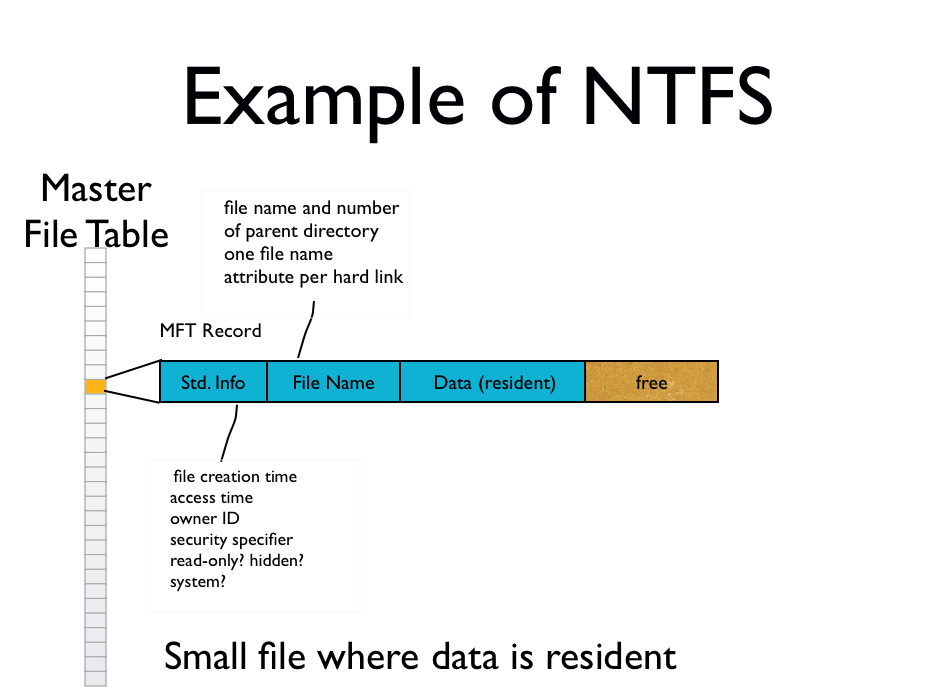
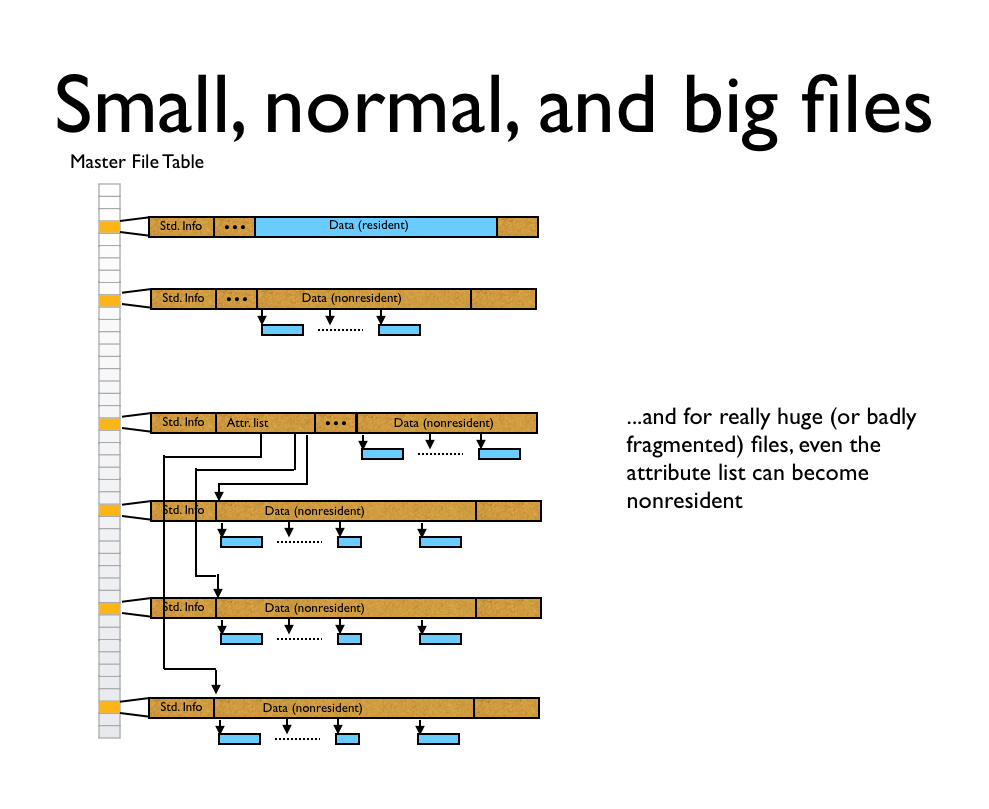
Small file
Medium file
Large file
For really, really large files, even the attribute list might become nonresident!
$MFT (file 0) stores the Master File Table
MFT can start small and grow dynamically--to avoid fragmentation, NTFS reserves part of the volume for MFT expansion.
$Secure (file 9) stores access controls for every file (note: not stored directly in the file record!)
File is indexed by a fixed-length key, stored in the Std. Info field of the file record.
NTFS stores most metadata in ordinary files with well-known numbers
Last lecture, we made somewhat oblique references to some on-disk filesystem information.
I can't just extend this file because the blocks at the end might be in use...
Well how would you know?
Once upon a midnight dreary while I pondered weak and weary over many a quaint and curious volume of forgotten lore...
USED
000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
FREE
What if we set a special sentinel value for free blocks?
010101010101010101010101010101010101010101010101010101
FREE?
Keep a bitmap that tracks whether each block is used or free.
| 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 |
|---|
To allocate a block, simply scan the bitmap for a 0 bit, and flip it. Block is now marked as in-use!
To deallocate a block, simply set its bit to zero. No coalescing needed.
There's also some fundamental information that we just need to keep in the filesystem!
We also need to handle data like file headers, free space, etc.
Partitions separate a disk into multiple filesystems.
Partitions can (effectively) be treated as independent filesystems occupying the same disk.
Not to scale
The Partition Table (stored as a part of the GPT Header) says where the various partitions are located.
Within the partition (filesystem), the superblock records information like where the inode arrays start, block sizes, and how to manage free disk space.
Partitions let you do things like:
$ sudo e2fsck /dev/sdb1
Password:
e2fsck 1.42 (29-Nov-2011)
e2fsck: Superblock invalid, trying backup blocks...
e2fsck: Bad magic number in super-block while trying
to open /dev/sdb1The superblock contains information about the filesystem: the type, the block size, and where the other important areas start (e.g. inode array)
A series of bitmaps are used to track free blocks separately for inodes and file data.
Inode arrays contain important file metadata.
There may be backup superblocks scattered around the disk.
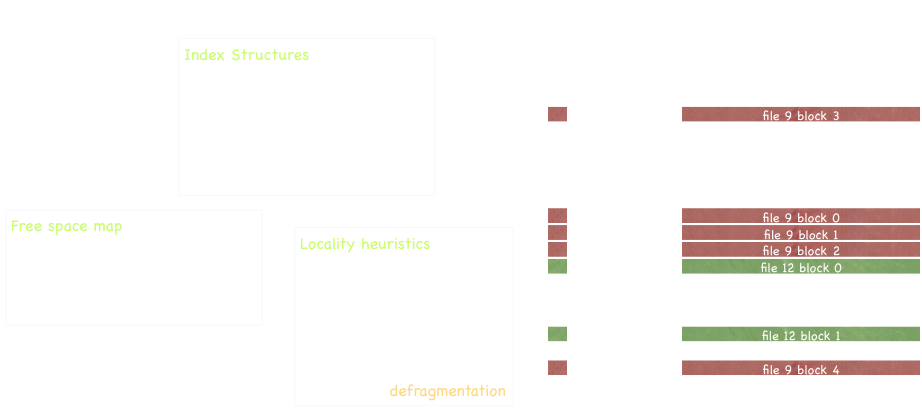
* many modern filesystems reserve about 10% of data blocks as "wiggle room" to optimize file locality.
Our primary measure of reliability will be consistency.
Consistency: Does my data agree with...itself?
There's a lot of work out there for guaranteeing the "correctness" of a file system after a "failure", for many different values of correctness and failure.
But if we can't even guarantee the data agrees with itself, we have no hope of getting more general correctness.
append(file, buf, 4096)
What changes do we need to make to the filesystem to service this syscall?
append(file, buf, 4096)
Block size is 4KB
Remember: we can't tell whether the data block is in use by looking at it. What if that file was deleted, but it's data stayed in place? Or what if that was used as scratch space and the data is no longer valid?
The only way to tell whether a disk block is used is by examining the bitmaps.
When examining the filesystem, we don't get to see the colors.
So...write the data block first?
Disk caches are essentially the reason we can interact with the filesystem in (what you think of as) a reasonable amount of time.
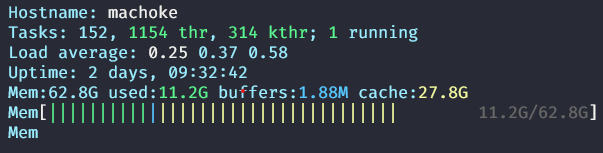
A picture from my desktop. 11GB of RAM is used for processes and the OS. Almost 28GB (more than 2x that!) is being used to cache filesystem accesses.
Real operating systems cache everything they possibly can.
But RAM is volatile. What happens if we lose power?
I am an OS programmer who needs to deal with writes. Should I tell the user their write succeeded even if it only made it to a cache in RAM?
Note: this is not "good" and "evil", it's more "optimistic" and "pessimistic." A safe system which takes 5 hours to open a browser is arguably more useless than one which instantly corrupts when you lose power. At least you can take backups of the latter.
Write now. Immediately write changes back to disk, while keeping a copy in cache for future reads.
Guarantees consistency, but is slow. We have to wait until the disk confirms that the data is written.
Write later. Keeps changed copy in-memory, and future requests to read the file use the changed in-memory copy, but defers the writing until some later point (e.g. file close, page evicted, too many write requests)
Much better performance, but modified data can be lost in a crash, causing inconsistencies.
We've seen that a single append operation will not always result in a consistent filesystem. No ordering of write operations can prevent this.
This issue is made worse by the omnipresence of caching in the filesystem layers. Nearly every access is cached:
This same distinction also applies to CPU caches, though the speed difference between CPU cache and RAM is only about 100x, while it's closer to 20,000x between RAM and disk.
Write-through is not the same thing as no-caches. If you try to read the thing you just wrote, that read still hits the cache, as opposed to having to go to disk.
Notes on the last slide:
Remember that when we examined consistency issues, we weren't taking disk caching into account: inconsistencies can arise even if no disk accesses are cached!
However, it's true that writeback caching can exacerbate this problem. How does caching make this worse?
Suppose we do the thing we saw from the last section where we update three elements:
- inode
- data block
- data bitmap
When using write-through caching, this takes three disk writes (approximately 30-40ms) to complete. In that time, a power failure can cause inconsistency.
Now let's suppose we're using writeback caching. The first write makes it through, but the other two writes are held in cache. Until the cache is flushed, a power failure will cause inconsistency. As long as the time until writeback is longer than 30ms (in most cases, it will be about 1000x longer), there is a much larger time window in which power failures can cause issues.
"Old-timey" = up until the early 2000s.
Does not guarantee that blocks are written to disk in any order--the filesystem can appear to reorder writes. User applications that need internal consistency have to rely on other tricks to achieve that.
To assist with consistency, UNIX uses write-through caching for metadata. If multiple metadata updates are needed, they are performed in a predefined, global order.
This should remind you of another synchronization technique that we've seen in this class. Where else have we seen predefined global orders before?
If a crash occurs:
Suppose we're creating a file in a system using direct allocation. What do we need to write?
Data block for new file
inode for new file
inode bitmap
data bitmap
directory data
Not a very principled approach (what if there's some edge case we haven't thought about that breaks everything?)
Tricky to get correct: even minor bugs can have catastrophic consequences
Write-through caching on metadata leads to poor performance
Recovery is slow. At bare minimum, need to scan:
inode bitmap
data block bitmap
every inode (!!)
every directory (!!!)
Possibly even more work if something is actually inconsistent.
Transactions group actions together so that they are:
To achieve these goals, we tentatively apply each action in the transaction.
Undoing writes on disk (rollback) is hard!
Exhibit A: All y'all that have really wished you could revert to a previous working version of Pintos at some point.
Instead, use transaction log!
TxBegin
Write Block32
Write Block33
Commit
TxFinalize
<modify blocks>
Step 1: Write each operation we intend to apply into the log, without actually applying the operation (write-ahead log)
Step 2: Write "Commit." The transaction is now made permanent.
Step 3: At some point in the future (perhaps as part of a cache flush or an fsync() call), actually make the changes.
Step 2: Write "Commit." The transaction is now made permanent.
Step 3: At some point in the future (perhaps as part of a cache flush or an fsync() call), actually make the changes.
Once the transaction is committed, the new data is the "correct" data.
So....somehow we need to present the new data even though it hasn't been written to disk?
An example of OS being illusionist!
For example, here's a simple implementation: once COMMIT is written, OS changes all of its disk cache to reflect what the disk would look like after the transaction is written.
If a process asks to read the modified pages between when COMMIT is recorded and when data blocks are actually changed, OS redirects request to the in-memory cache.
Recovery of partial transactions can be completed using similar reasoning to fsck.
TxBegin
Write Block32
Write Block33
Commit
TxFinalize
<modify blocks>
TxBegin
Write Block32
Write Block33
Commit
TxBegin
Write Block32
Write Block33
Transaction was completed and all disk blocks were modified.
No need to do anything.
Transaction was committed, but disk blocks were not modified.
Replay transaction to ensure data is correct.
Transaction was aborted--data changes were never made visible, so we can pretend this never happened.
From the early 90s onwards, a standard technique in filesystem design.
All metadata changes that can result in inconsistencies are written to the transaction log (the journal) before eventually being written to the appropriate blocks on disk.
Eliminates need for whole-filesystem fsck. On failure, just check the journal! Each transaction recorded must fall into one of three categories:
We want to add a new block to file Iv1.
TxBegin
Commit
D2
B2
IV2
TxFinalize
My font isn't the greatest here...the inode is tagged "iv1", as in "inode, version 1"
If Commit isn't in the journal, the transaction never happened--don't need to do anything!
If Commit is in journal but Finalize is not, data blocks were never written to disk. Replay the operations in the transaction to finalize the data.
Write-behind != write-back! Common confusion.
Problem: Issuing 5 sequential writes ( TxBegin | Iv2 | B2 | D2 | Commit ) is kinda slow!
Solution: Issue all five writes at once!
Problem: Disk can schedule writes out-of-order!
First write TxBegin, Iv2, B2, TxEnd
Then write D2!
TxBegin
Commit
D2
B2
IV2
Solution: Force disk to write all updates by issuing a sync command between "D2" and "Commit". "Commit" must not be written until all other data has made it to disk.
TxBegin
Commit
D2
B2
IV2
Use the transaction technique we saw in the Advanced Synchronization lecture for all metadata updates (regular data still written with writeback caching).
This guarantees us reliability, and avoids the overhead of an fsck scan on the entire disk (only need to scan journal!)
But now we have to write all the metadata twice! Once for the journal and then a second time to get it in the right location.
The New Technology Filesystem uses two new ideas to manage its data:
The filesystem superblock points to the inode array, data arrays, and free space management on the filesystem.
The free space tracking usually uses bitmaps to indicate which blocks are free and which are in use.
The fact that disks can fail at any time leads us to potential data loss issues. The simplest of these is consistency, i.e. the metadata on a disk should agree with itself.
The in-memory disk cache makes this worse: we need this cache for reasonable performance, but it also makes consistency harder!
General solutions for this problem:
Updates are made in an agreed-upon order with write-through caching.
On failure, scan the entire stinking partition to see if any inconsistencies exist.
Slow to write (because of write-through caching), slow to recover, and easy to break!
Use transactions to record all metadata changes. Transactions are recorded in the journal.
On failure, scan the journal and fix up any partially completed transactions.
Fast recovery, but still requires that all metadata written to disk twice (once for journal, once for realsies)
By Kevin Song
This is the text-heavy version of the 1HR filesystem consistency lecture. Fragment-free and with extra text to explain imagery.



