



Content ITV PRO
This is Itvedant Content department
Learning Outcome
5
Visual Cue: A clear, bulleted list next to a "target/bullseye" icon.
4
Understand how SMOTE synthetically generates new data points without duplicating them.
3
Apply Undersampling and Oversampling to balance datasets.
2
Define class imbalance in classification problems.
1
Recognize the "Accuracy Paradox" and why 99% accuracy isn't always a good thing.
The EDA Progress Checklist:
Step 1: Handled Missing Data.
Step 2: Removed Outliers.
Step 3: Encoded Categorical Text.
Step 4: Scaled the Data.
Step 5: Selected & Engineered the Best Features.
The Final Problem: Our data is perfectly clean, but what if we are trying to predict something that almost never happens?
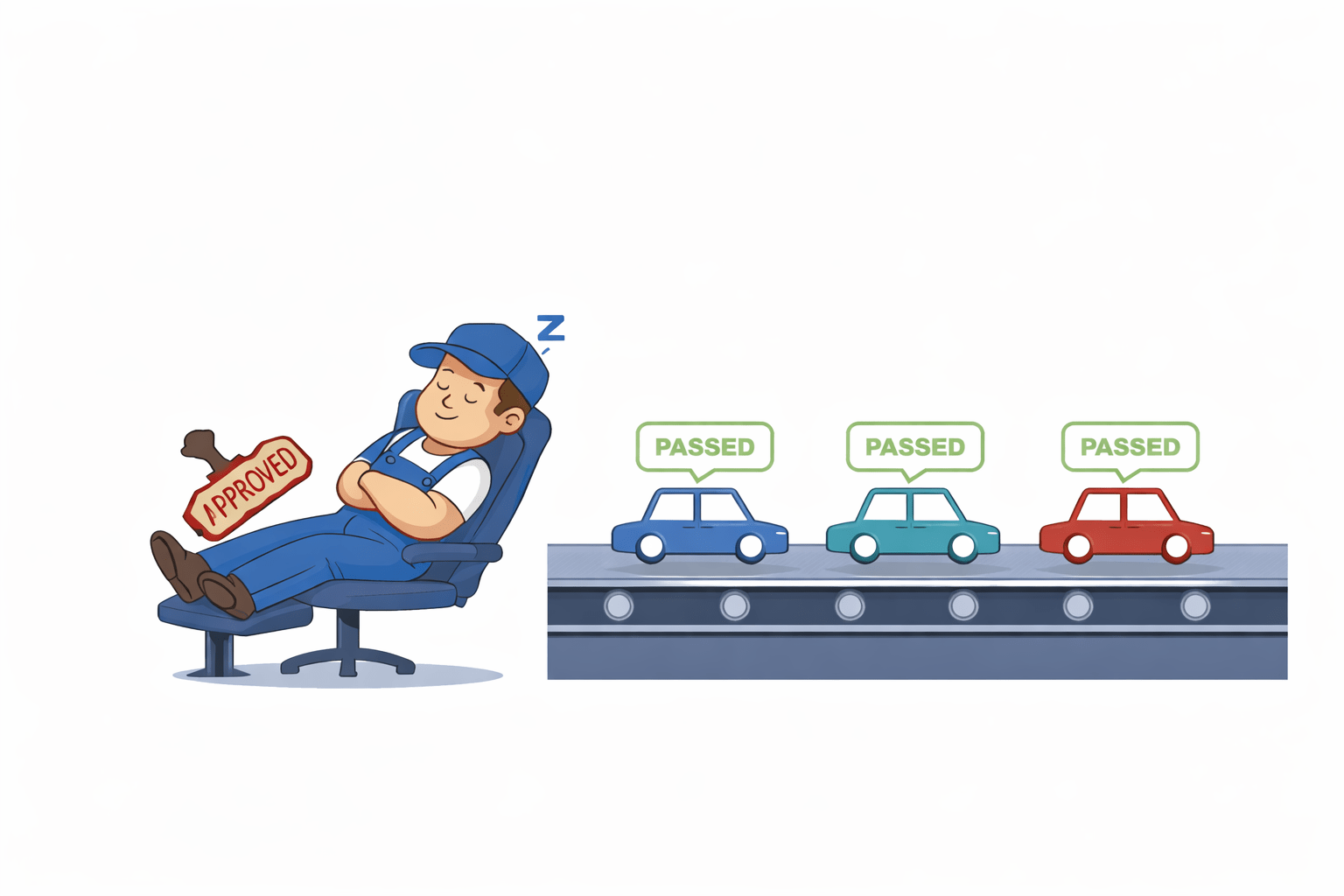
Predicting if a car engine will explode.
Out of 10,000 cars, only 10 explode.
You hire a mechanic to inspect 100 cars to find the 1 with a faulty engine.
The mechanic doesn't even look at the cars.
He just blindly stamps "PASSED" on all 100 cars.
He is right 99 times out of 100. Statistically, he has 99% Accuracy.
The Accuracy Paradox & Imbalance
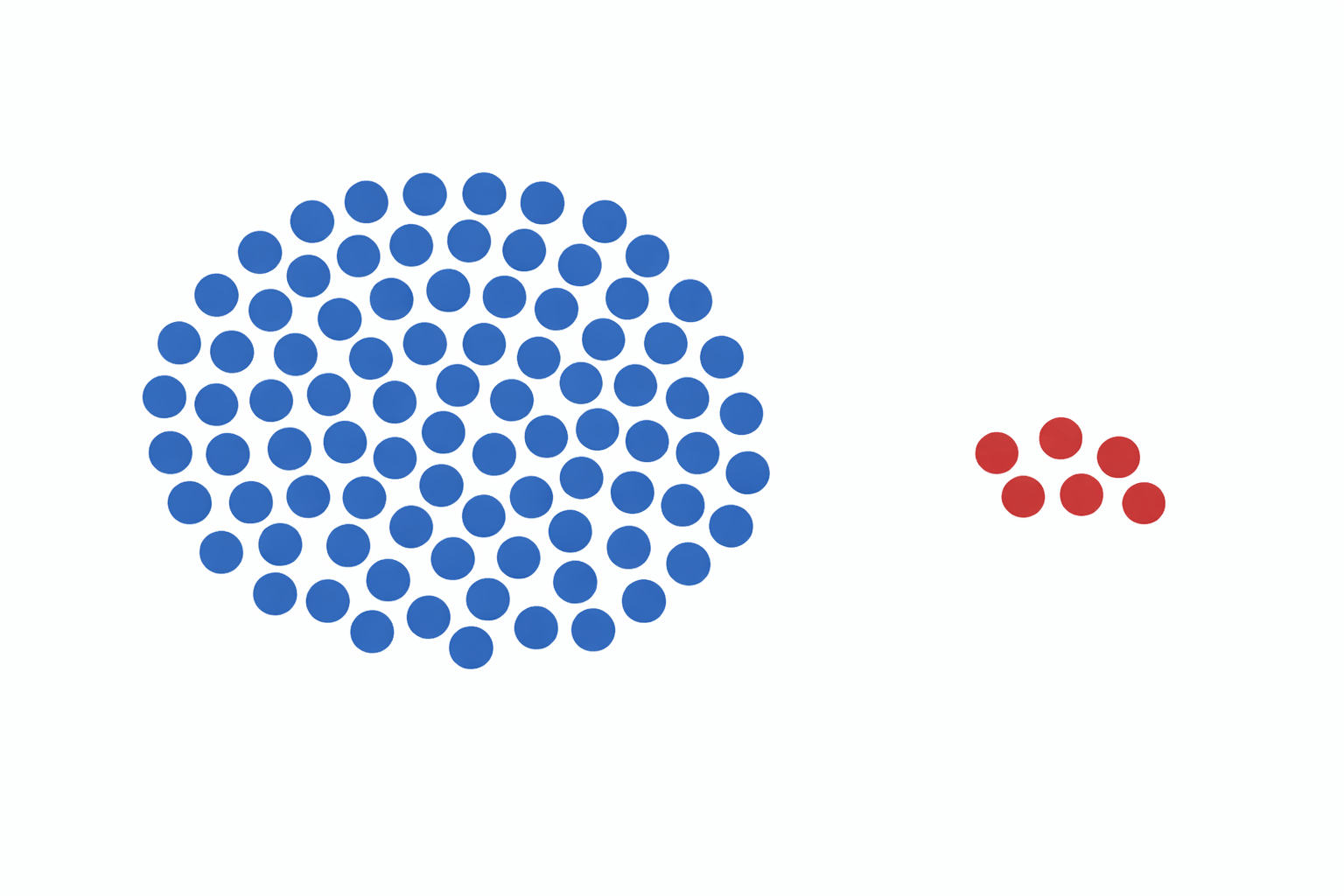
A dataset where the target class has an uneven distribution of observations.
| Class Type | Number of Observations | Percentage |
|---|---|---|
| Majority Class | 9900 | 99% |
| Minority Class | 100 | 1% |
Machine learning algorithms try to maximize overall accuracy.
Accuracy = 9900 / 10000 = 99%
But the model failed to detect all minority cases.
This is called the Accuracy Paradox.
Total Samples = 10000
| Actual \ Predicted | Class 0 | Class 1 |
|---|---|---|
| Class 0 (990) | 9900 | 0 |
| Class 1 (10) | 100 | 0 |
Majority
Class
Minority
Class
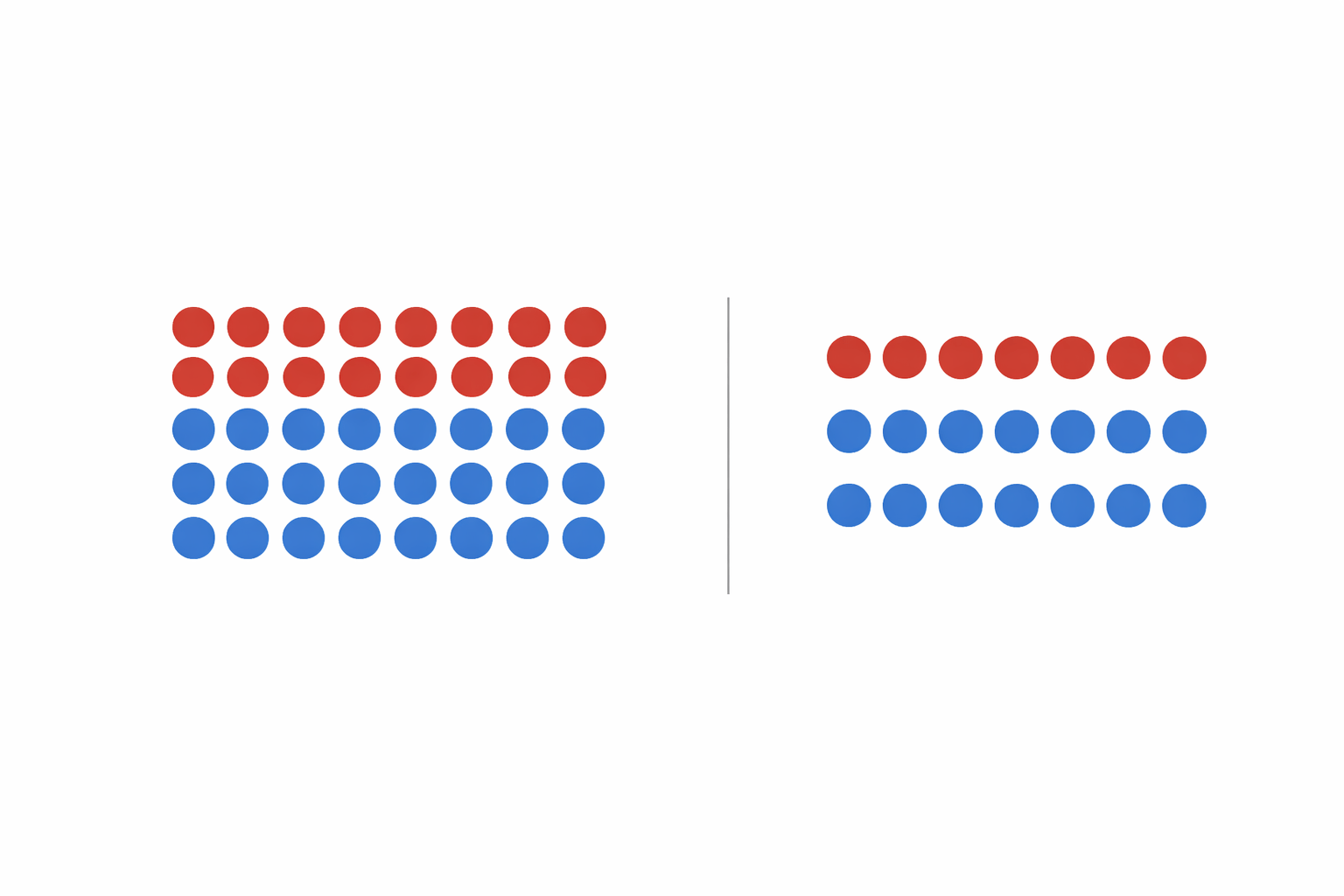
Before training the model, we balance the dataset.
| Class Type | Number of Observations |
|---|---|
| Majority Class | 5000 |
| Minority Class | 5000 |
Now the model learns patterns from both classes.
Imbalanced Dataset
Balanced Dataset
Visual Cue
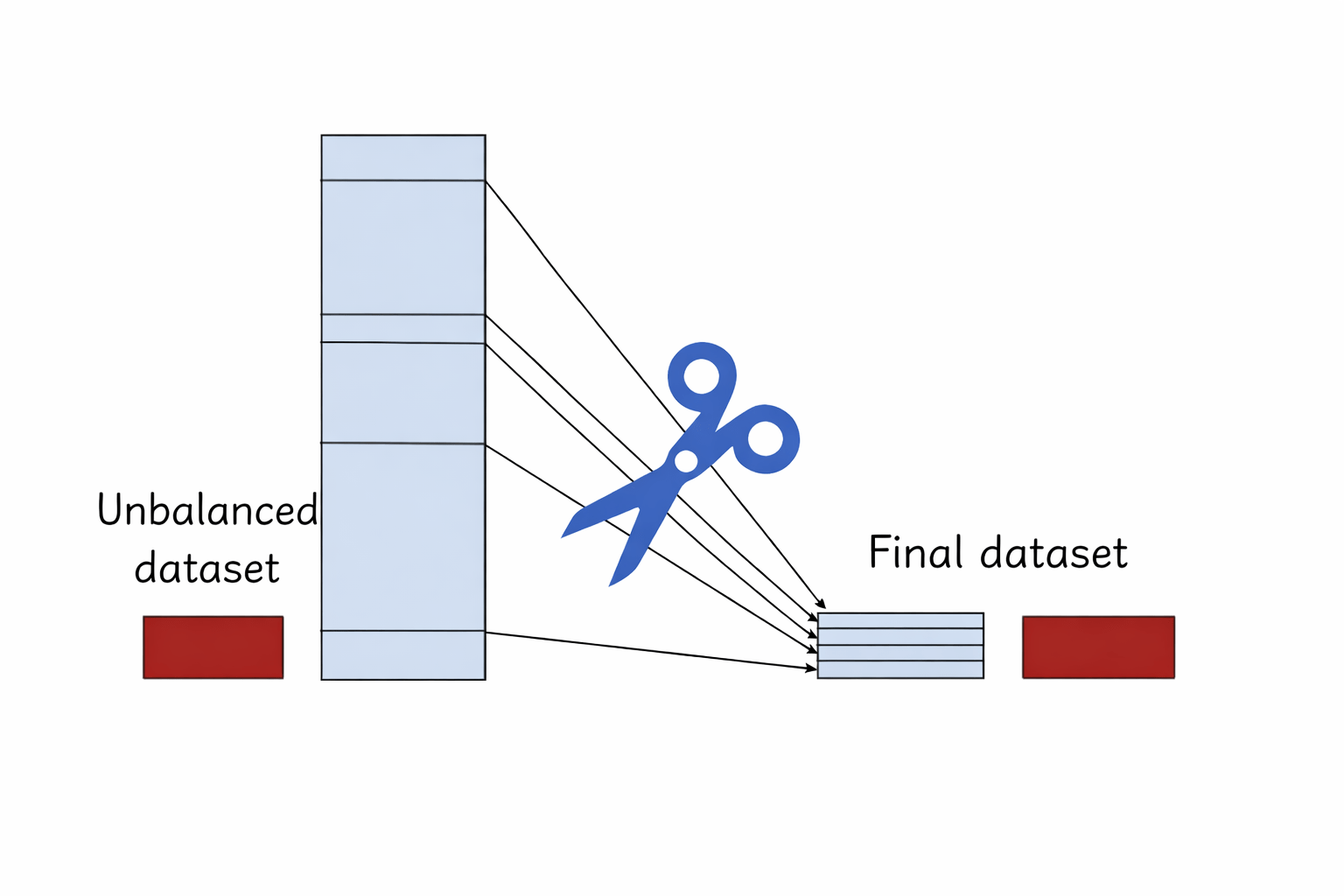
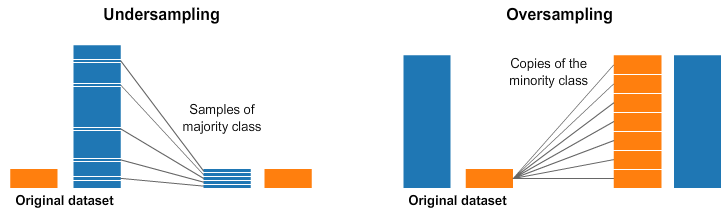
Technique 1: Undersampling
Mechanism
Randomly delete rows from the Majority Class until it matches the size of the Minority Class .
| Class | Number of Observations |
|---|---|
| Safe Cars | 9900 |
| Faulty Cars | 100 |
| Class | Number of Observations |
|---|---|
| Safe Cars | 100 |
| Faulty Cars | 100 |
Dataset before balancing:
After Undersampling:
We remove 9,800 Safe Car samples to create a balanced dataset (100 vs 100).
Pros
Very fast training because the dataset becomes much smaller.
Cons
We discard a huge amount of useful information from the majority class.
Visual clue
Interpretation
Result → Balanced dataset
Technique 2: Oversampling
Mechanism
Randomly duplicate rows from the Minority Class until it matches the size of the Majority Class.
| Class | Number of Observations |
|---|---|
| Safe Cars | 9900 |
| Faulty Cars | 100 |
| Class | Number of Observations |
|---|---|
| Safe Cars | 9900 |
| Faulty Cars | 9900 |
Dataset before balancing:
After Oversampling:
We copy the 100 Faulty Car samples repeatedly until they reach 9,900 observations.
Pros
No information from the dataset is lost.
Cons
The model may memorize those same 100 faulty cars instead of learning general patterns.
Visual clue
Interpretation
Result → Balanced dataset without removing data
Copies of the
Minority Class
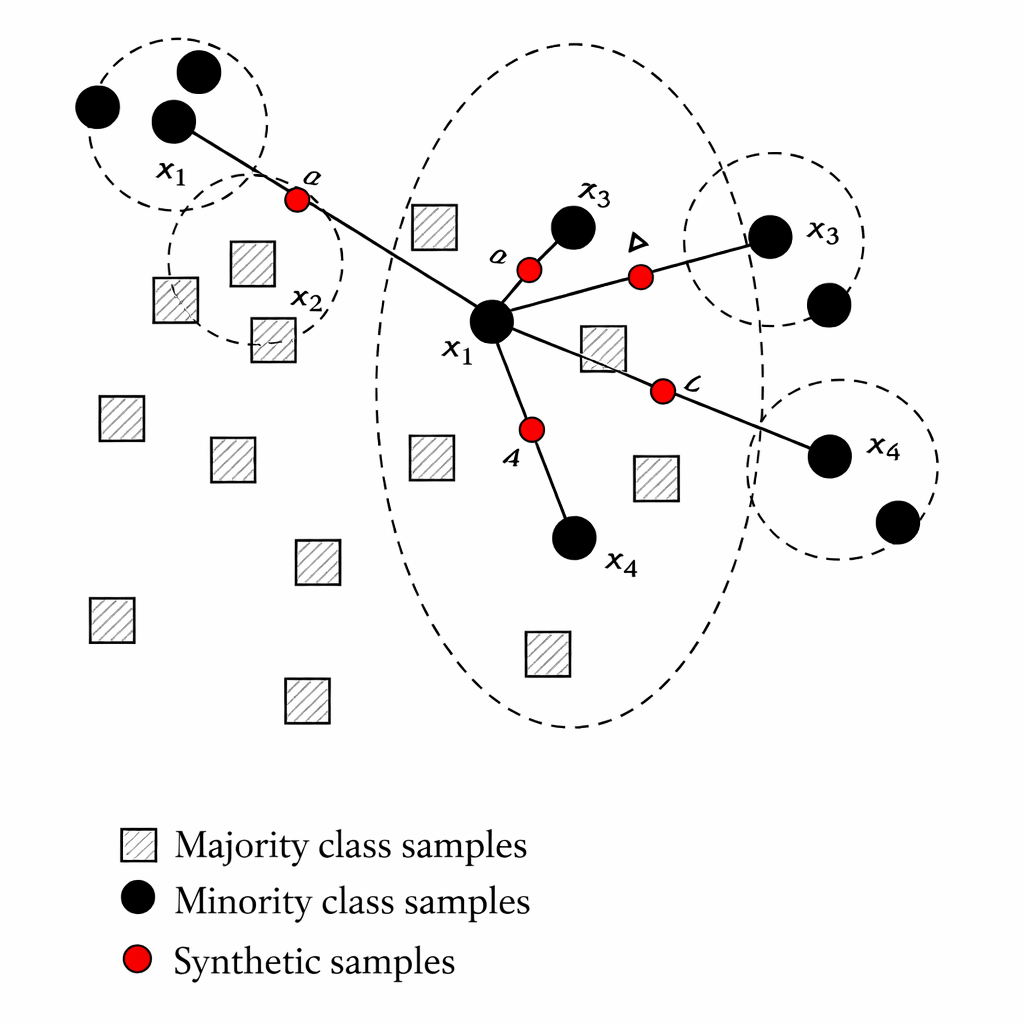
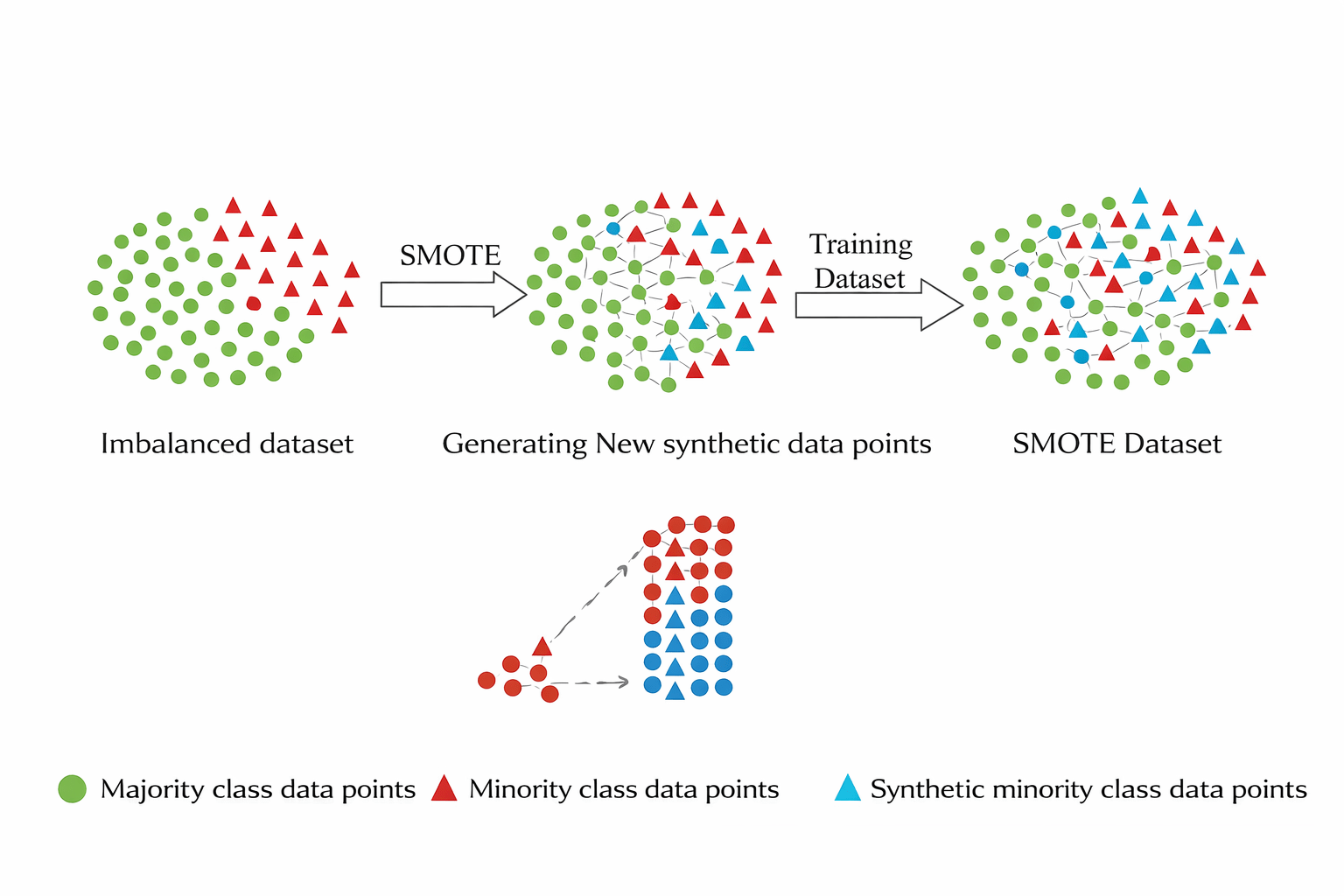
SMOTE (Synthetic Minority Over-sampling)
Mechanism
SMOTE (Synthetic Minority Over-sampling Technique) creates new synthetic samples instead of duplicating existing ones.
| Car Type | Weight | Speed | Label |
|---|---|---|---|
| Faulty Cars A | Heavy | Medium | Faulty |
| Faulty Cars B | Medium | Fast | Faulty |
Existing Minority Samples:
| Car Type | Weight | Speed | Label |
|---|---|---|---|
| Synthetic Faulty Car | Heavy-Medium | Medium-Fast | Faulty |
SMOTE creates a synthetic sample between them:
The algorithm blends features of nearby minority points to create realistic new data.
Pros
Visual clue
Interpretation
Result →Balanced dataset with realistic synthetic samples
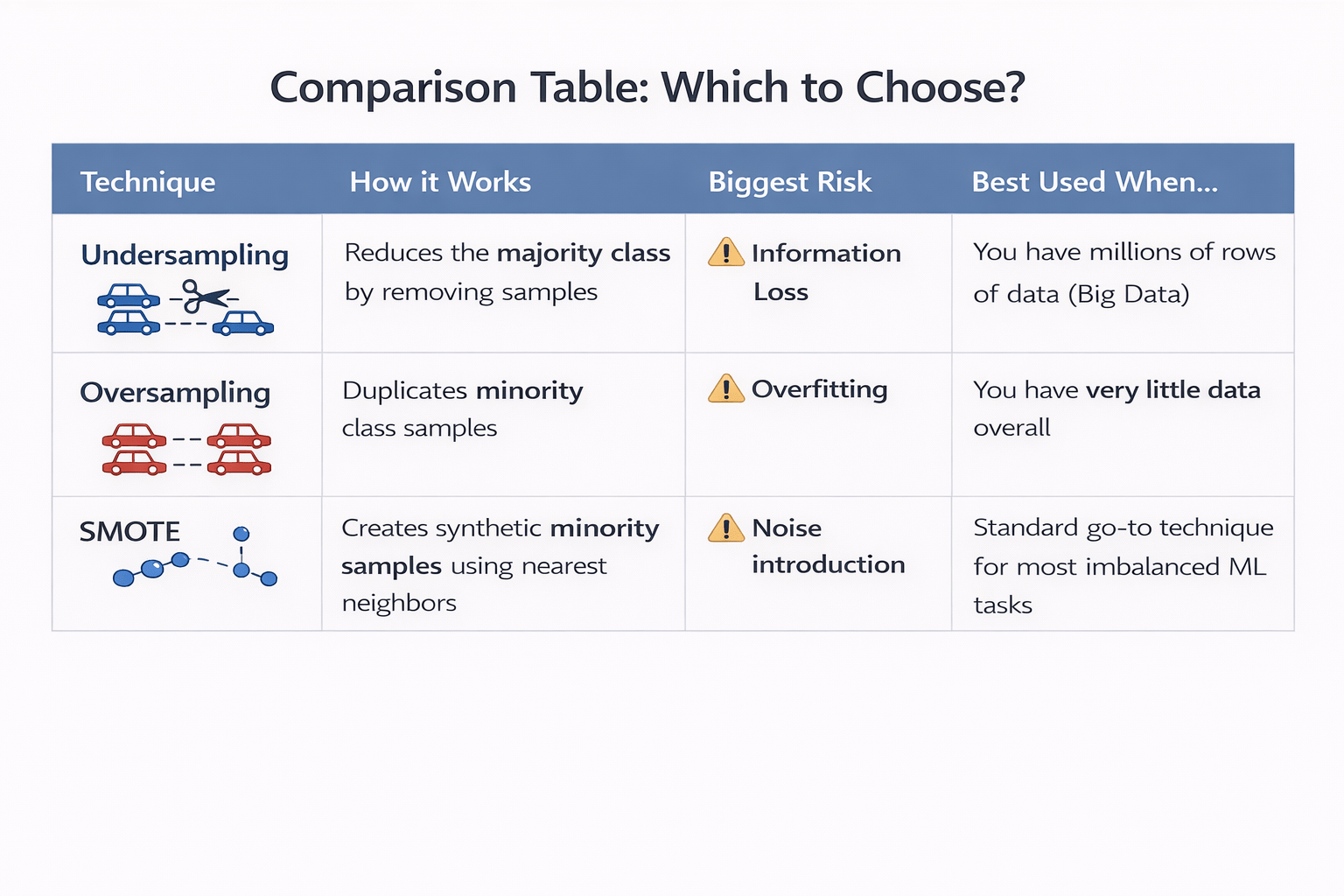
Comparison Table
Reduces the majority class by removing samples
Duplicates minority class samples
Creates synthetic minority samples using nearest neighbors
Information Loss
Overfitting
Noise introduction
You have millions of rows of data (Big Data)
You have very little data overall
Standard go-to technique for most imbalanced ML tasks
Summary
4
SMOTE innovates the small class by generating synthetic data.
3
Oversampling clones the small class.
2
Undersampling shrinks the big class.
1
Accuracy is a trap: Never trust standard accuracy on imbalanced data.
Quiz
Which technique creates entirely new data points by interpolating between existing minority class instances?
A. Random Undersampling
B. Normalization
C. Random Oversampling
D. SMOTE
Which technique creates entirely new data points by interpolating between existing minority class instances?
A. Random Undersampling
B. Normalization
C. Random Oversampling
D. SMOTE
Quiz-Answer
By Content ITV


