Técnicas y herramientas
de Web Scraping
¿Quién soy?

David Hernández
Desarrollador en Political Watch
Political Watch es una fundación donde desarrollamos herramientas de transparencia y rendición de cuentas para conseguir un mundo más justo.
david.hernandez@politicalwatch.es
@David_Baltha
¿Qué vamos a ver hoy?
Conocimientos necesarios previos
- XML y HTML
- XPath
Scraping con Google Sheets
- HTML scraping
- Extracción de CSVs
- Extracción de Feeds RSS
Explotando los datos mediante herramientas No Code
- N8N


Conocimientos necesarios previos
¿Qué es el Web Scraping?
Entornos no Open Data
Muchos portales de datos abiertos los datos no usan los formatos adecuados y simplemente están incrustados en la propia página web.
Aunque podemos copiar y pegar la información que nos interese, puede ser un problema dependiendo del volumen. Para rescatar dicha información de una manera más automática se usa una técnica denominada Web Scraping.
Web Scrapping
La web se construye utilizando un lenguaje llamado HTML. Por tanto, la técnica consiste en obtener dicho código HTML y procesarlo para extraer el contenido que nos interesa, reduciendo el tiempo que necesitamos para extraer dicha información.
Para ser capaces de aplicar el Web Scraping, tenemos que conocer un mínimo de como funciona el HTML y como podemos procesarlo. Y para entender HTML, necesitamos conocer antes XML.
XML
El XML es un metalenguaje que define una estructura para crear lenguajes. El formato es el siguiente:
<etiqueta atributo="valor">Contenido</etiqueta>El contenido puede ser otras etiquetas o simplemente texto, pudiendo generar una estructura anidada:
<madre atributo="valor">
<hija></hija>
</madre>Ejemplo XML
<Contrato>
<IssueDate>2021-04-08+02:00</IssueDate>
<ContractingParty type="Administración Local">Ayuntamiento de Sanchidrián</ContractingParty>
<Project>
<Description>La actuación consistirá en la construcción de un edificio...</Description>
<EstimatedContractAmount currency="EUR">356820.52</EstimatedContractAmount>
</Project>
</Contrato>HTML
Como hemos dicho antes, XML es un metalenguaje que nos permite definir lenguajes. HTML es un lenguaje definido mediante XML.
Al contrario que con XML que puedes usar cualquier texto para las etiquetas y los atributos, HTML tiene una especificación de que etiquetas y atributos puedes usar.
Estas etiquetas definen la estructura y el contenido de una pagina web: los enlaces, los textos, las tablas...
Ejemplos de HTML
Enlace:
<a href="https://politicalwatch.es">Political Watch</a>Imagen:
<img src="http://www.upv.es/imagenes/marcaUPVN1.png"></img>Lista:
<ul>
<li>Elemento 1</li>
<li>Elemento 2</li>
</ul>XPATH
XPath es un formato que nos permite identificar cualquier etiqueta del HTML o XML. Por ejemplo, dada la siguiente estructura:
Seleccionar todos los enlaces:
<html>
<a class="menu" href=""></a>
<div>
<a class="link" href=""></a>
</div>
</html>//aSeleccionar el div:
/html/divSeleccionar segundo enlace:
//a[2]Usando atributos:
//a[@class="link"]XPATH
<html>
<a class="menu" href=""></a>
<div>
<a class="link" href=""></a>
</div>
</html>/html//a[@class="link"]Consola del navegador
En la ventana del navegador, usamos F12 o botón derecho e inspeccionar


Scraping con Google Sheets
Importar tablas
Nos permite importar los datos de las tablas de una web
- url: La dirección de la pagina web
- "table": Para indicar que es una tabla (<table>)
- index: Para indicar que tabla de la pagina es
=IMPORTHTML(url, "table", index)Importar listas
Nos permite importar los datos de las listas de una web
- url: La dirección de la pagina web
- "list": Para indicar que es una tabla
- index: Para indicar que tabla de la pagina es
=IMPORTHTML(url, "list", index)Importar XML
Nos permite importar los datos de cualquier documento que use el formato XML
- url: Dirección web de los datos estructurados (XML o xHTML)
- query: Criterio de búsqueda en el XML usando XPATH
IMPORTXML(url, query)Importar feed RSS
Nos permite importar los datos de un feed RSS
- url: Dirección web del feed
- query: Elemento que se desea importar del feed
- headers: Se desea incluir cabeceras o no (TRUE o FALSE)
- num_items: Número de elementos a importar
IMPORTFEED(url, query, headers, num_items)Importar CSV
Nos permite importar los datos de cualquier documento CSV
- url: Dirección web en donde se encuentra el fichero CSV que se desea importar
IMPORTDATA(url)Limitaciones
Páginas cuyo contenido cambia dinámicamente
Páginas cuya URL no dirija a un único contenido
Cuando el contenido esta en una imagen o documento no HTML
Cuando necesitamos iniciar sesión.
Cuando el HTML no es "estable" y cambia con frecuencia (Google)
Probémoslo
https://bit.ly/3y4ULV5
Explotando los datos
con N8N
¿Qué es N8N?
Es una herramienta abierta y gratuita de automatización de flujos.
¿Y eso qué significa?
Te permite conectar servicios web con otros servicios. Por ejemplo: un formulario de TypeForm con una hoja de calculo de Google o un Feed RSS con el envío de un correo.
Hagamos una prueba
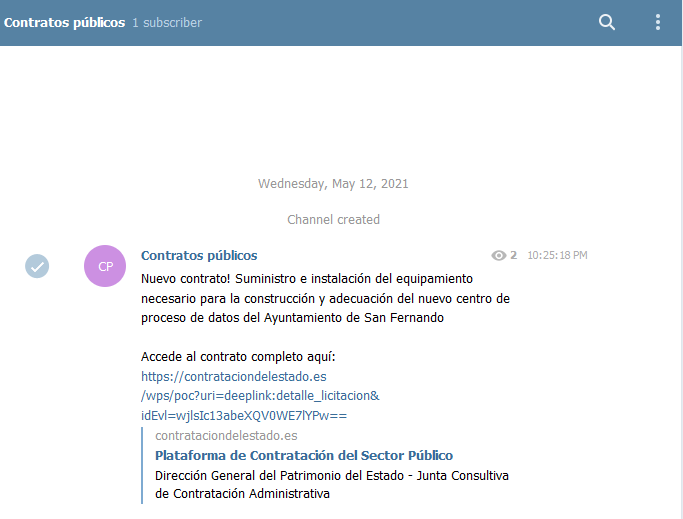
Vamos a hacer un bot de telegram que publique los contratos públicos.
Conectaremos una pieza de leer un feed RSS.
A continuación, usaremos otro bloque para seleccionar el ultimo contrato.
Y conectaremos ese bloque con otro de Telegram para mandarlo a un chat de difusión.
Pero antes, creamos el bot:
Antes de poder empezar, necesitamos crear un bot de telegram. Para ello, tenemos que hablar con el @BotFather:
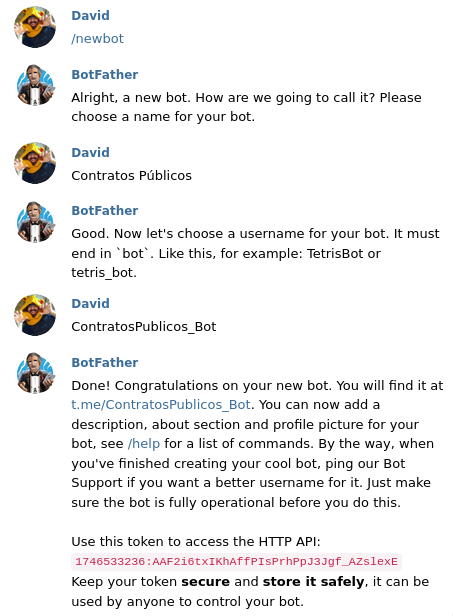
Lo primero que necesitamos es el token:
Lo siguiente es crear el canal
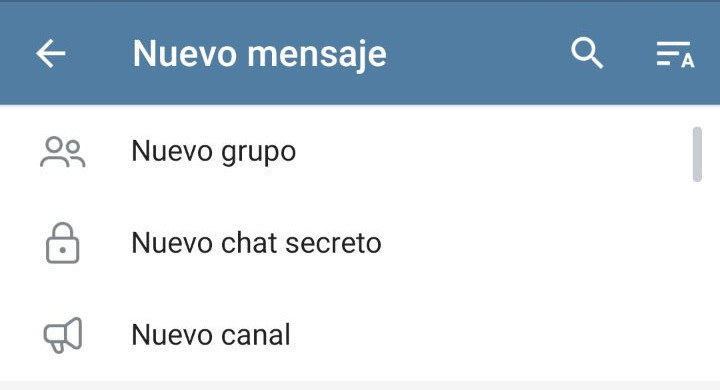
Invitamos al bot al canal como administrador y accedemos a la siguiente URL:
https://api.telegram.org/bot<Token>/getUpdates
Vamos a N8N:
Vamos a la instalación de N8N:
https://n8n.politicalwatch.es
Usuario: upv
Password: agentesod4d
Trigger nodes
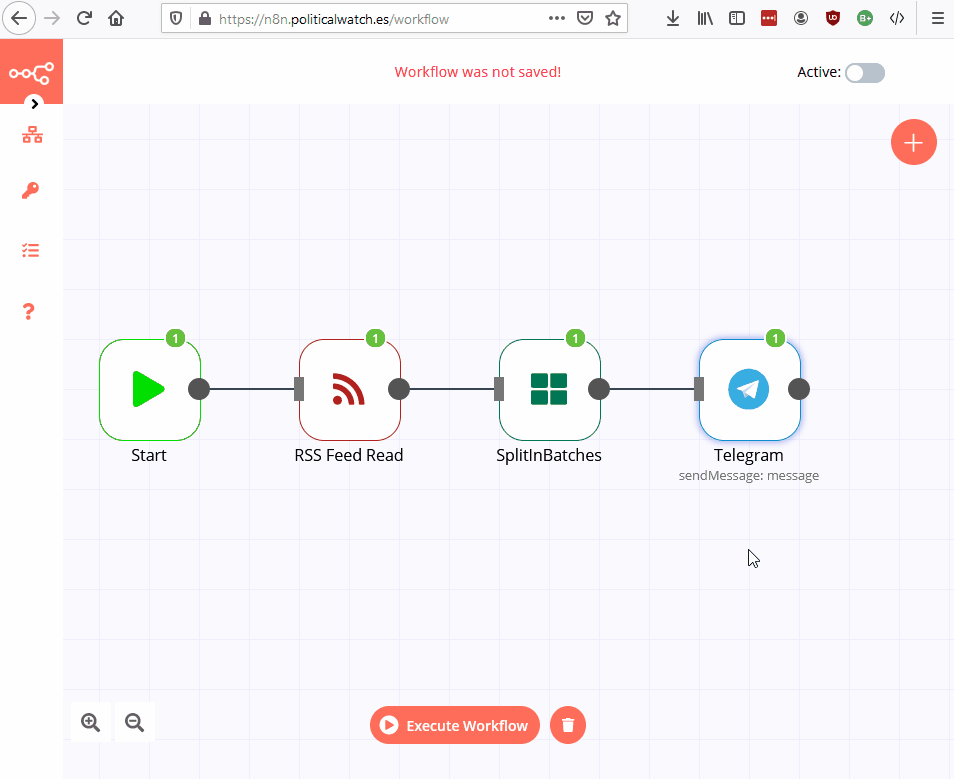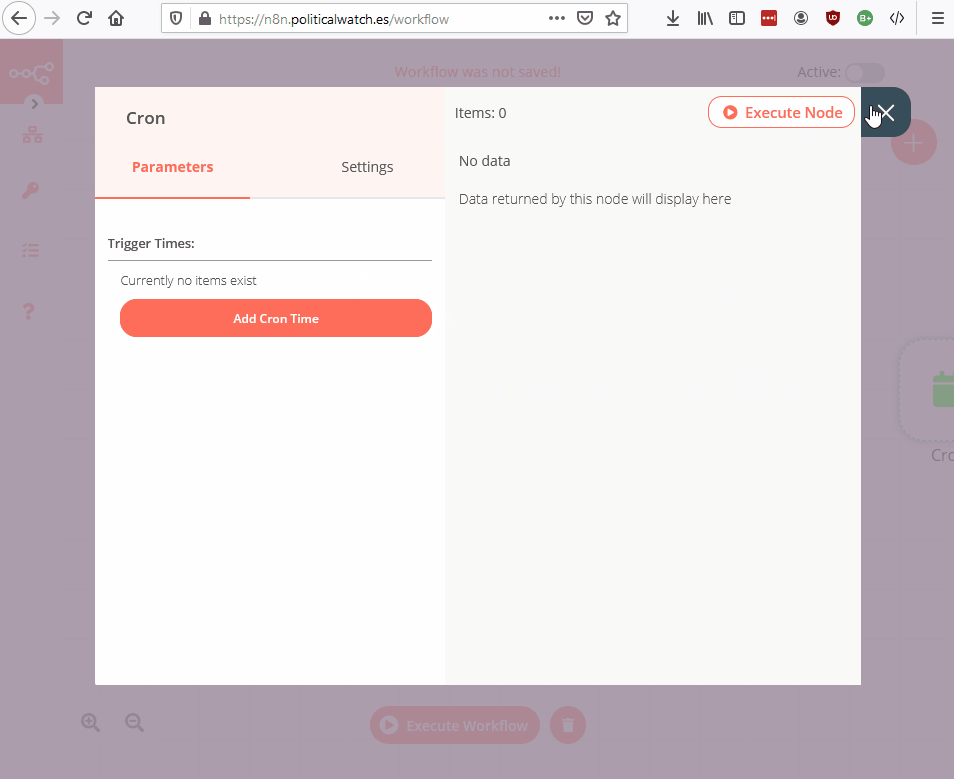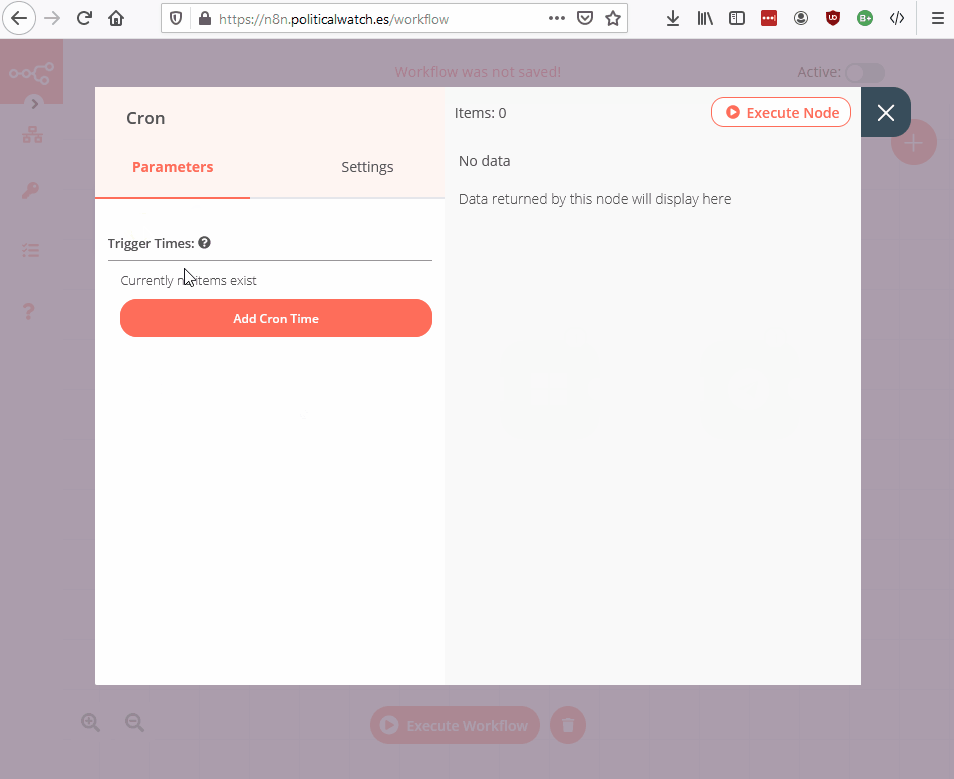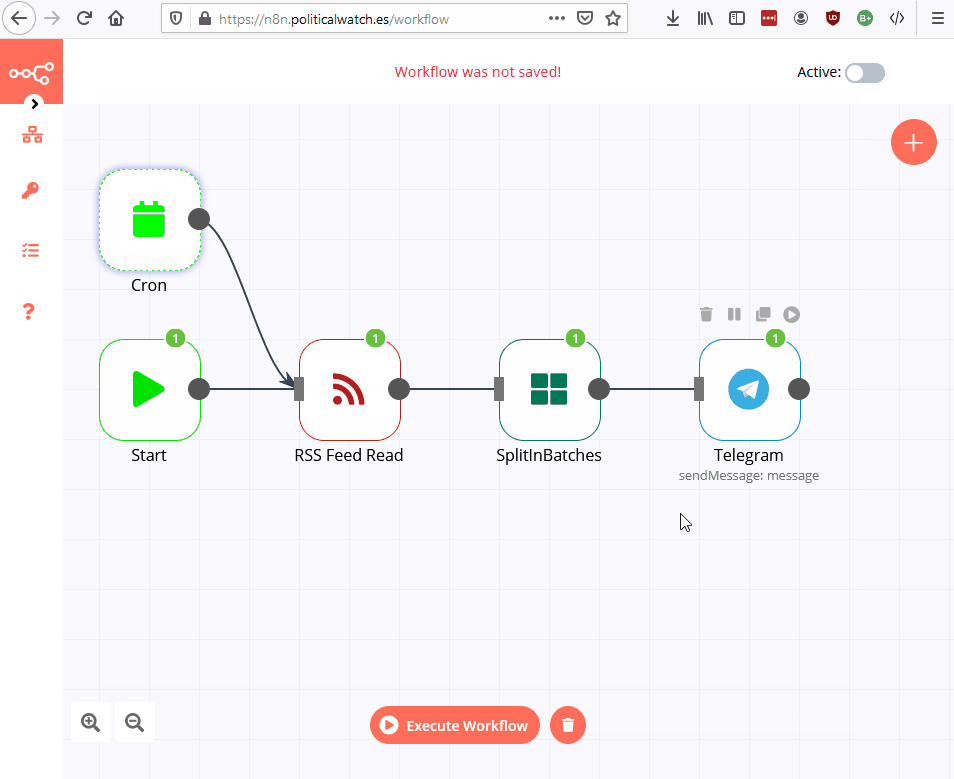
Cada pieza de nuestro puzle es un nodo y el puzle completo es un workflow.
Desde la cruz superior derecha, añadimos nuevos nodos.
Los nodos de tipo Trigger son los que inician nuestro worflow.
El trigger "start" ejecuta el workflow cuando se lo pedimos nosotros.
El trigger "cron" nos permite iniciar el workflow periódicamente
Regular nodes
Los nodos normales son los que realizan las diferentes operaciones.
Desde la cruz superior derecha, añadimos nuevos nodos.
Para nuestro bot, usaremos tres regular nodes:
- RSS Feed Read: descarga los datos de un feed RSS.
- SplitInBatches: coge la primera entrada del feed.
- Telegram: Formatea los datos y los envía por Telegram.
RSS
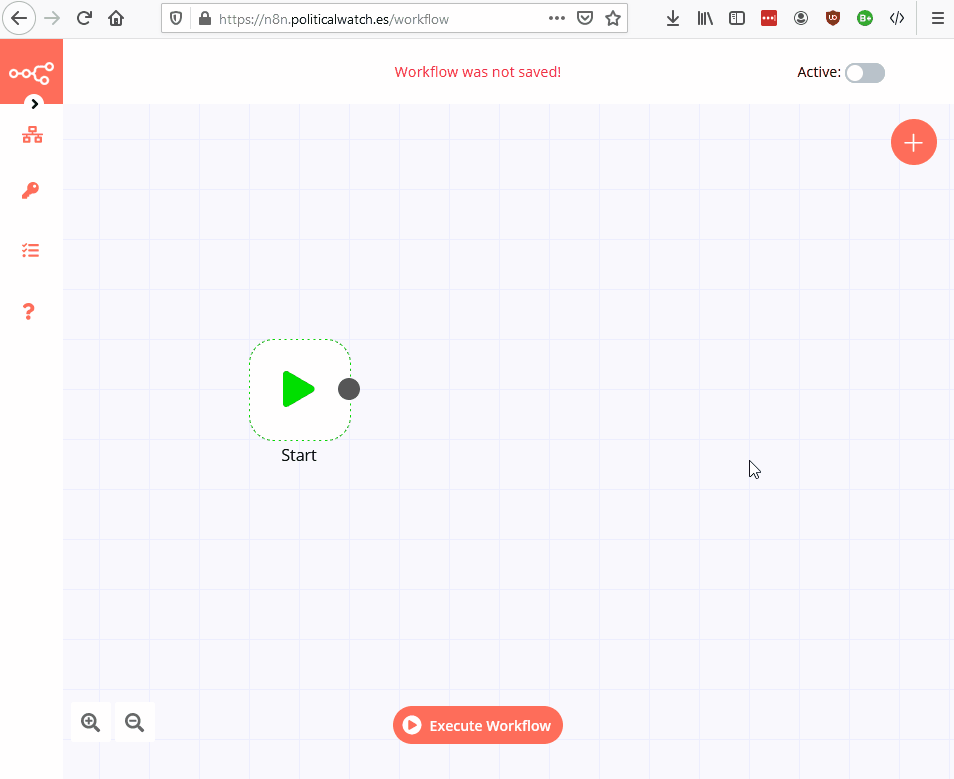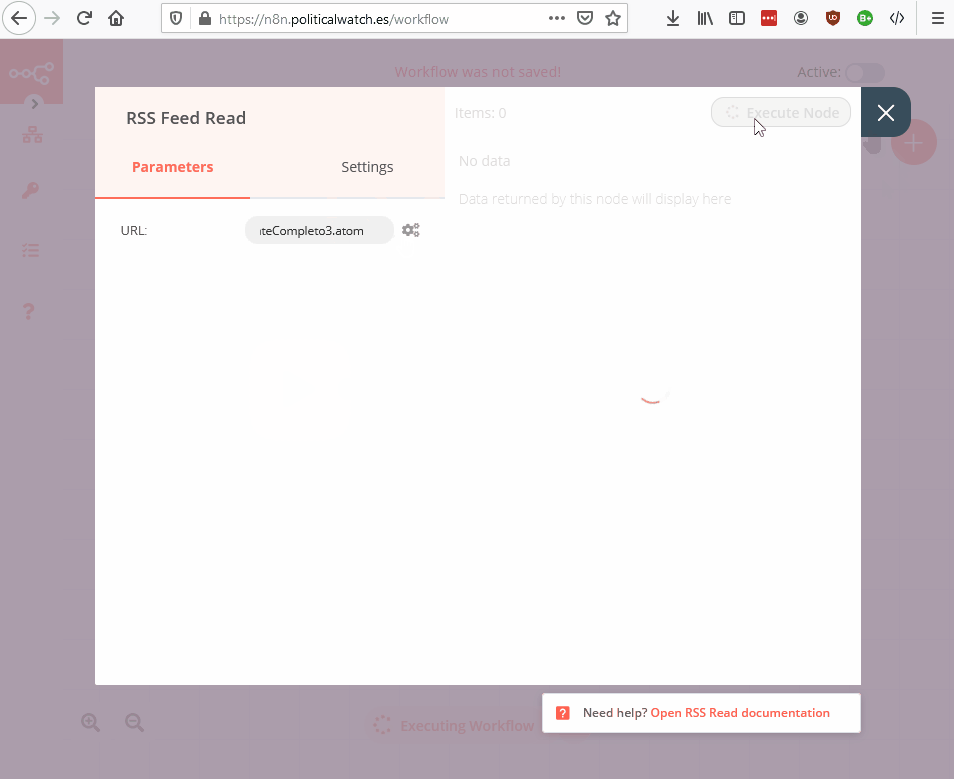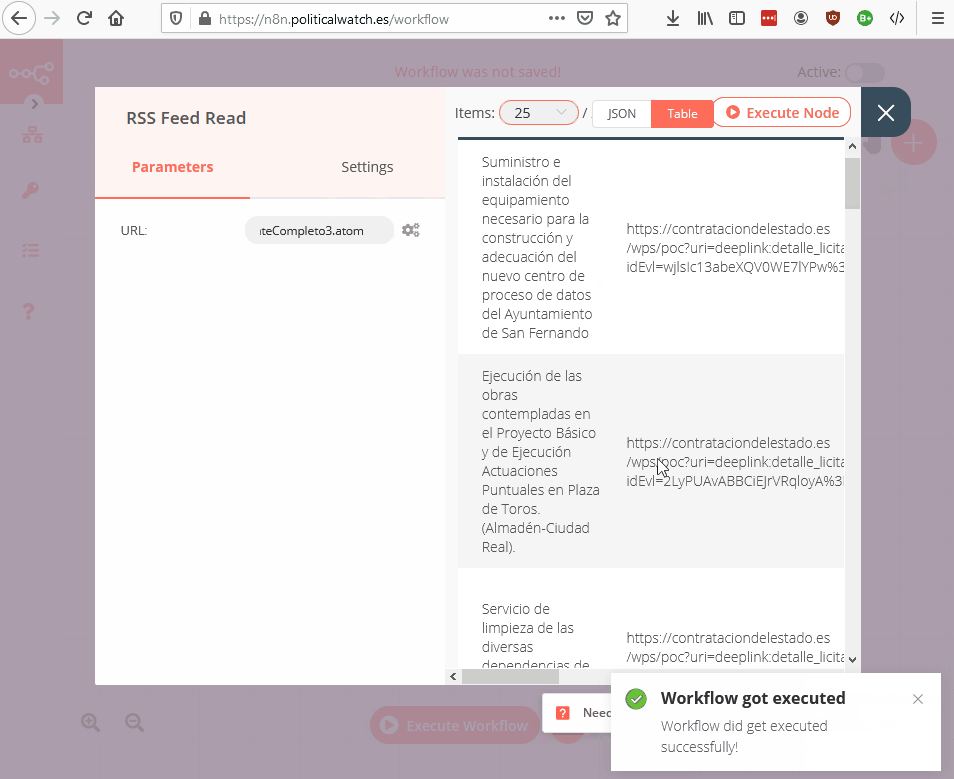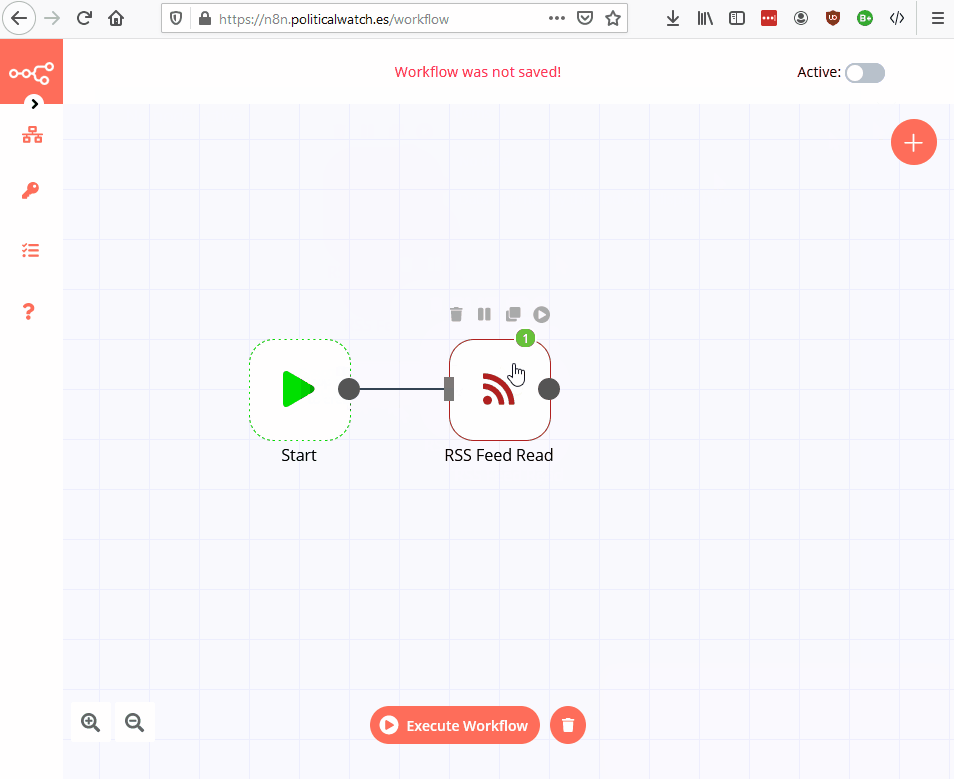
Cogemos el último contrato

Lo enviamos a Telegram
Lo programamos para hacerlo a diario
Listo!
¿Hacemos un bot?
Algunos feeds:
- Noticias El País: https://feeds.elpais.com/mrss-s/pages/ep/site/elpais.com/portada
- Indice de feeds de El Mundo: http://rss.elmundo.es/rss/
- Contratos Públicos: https://contrataciondelestado.es/sindicacion/sindicacion_643/licitacionesPerfilesContratanteCompleto3.atom
- Catálogo de datos abiertos: https://datos.gob.es/feeds/dataset.atom
- Catálogo de datos abiertos VLC: https://www.valencia.es/dadesobertes/va/rss2feed/
- RSS Aemet: http://www.aemet.es/es/rss_info
- Catalogo Open Data EU: https://data.europa.eu/api/hub/search/en/feeds/datasets.rss
Siguientes pasos
Programación

Posibilidades infinitas
¿Preguntas?
Bibliografía
- XML: https://es.wikipedia.org/wiki/Extensible_Markup_Language
- HTML: https://es.wikipedia.org/wiki/HTML
- XPath: https://es.wikipedia.org/wiki/XPath
- IMPORTHTML: https://support.google.com/docs/answer/3093339
- IMPORTXML: https://support.google.com/docs/answer/3093342
- IMPORTFEED: https://support.google.com/docs/answer/3093337
- IMPORTDATA: https://support.google.com/docs/answer/3093335
- Google Sheets function list: https://support.google.com/docs/table/25273?hl=en
- N8N: https://n8n.io/
- Documentación nodos N8N: https://n8n.io/integrations
- Nodo RSS: https://n8n.io/integrations/n8n-nodes-base.rssFeedRead
- Nodo SplitInBatches: https://n8n.io/integrations/n8n-nodes-base.splitInBatches
- Nodo Telegram: https://n8n.io/integrations/n8n-nodes-base.telegram
- Parlamento 2030: https://www.parlamento2030.es/
Técnicas y herramientas de Web Scrapping
By david_hernandez




