From
Agent Conf 2023 🏔
David Khourshid · @davidkpiano
stately.ai

The path to generally intelligent software
AI
AGI
to




Command Palette
Command palette
Find in UI
Click
Click
Click
Type
Type
Success
Success

ChatGPT & GPT-3
Input
Output
Input
Output
Goal
Start
Symbolic AI
Symbols
Solution
📦 Large datasets
❔ Guesswork
🗣 No semantics
🌍 Real world is complicated
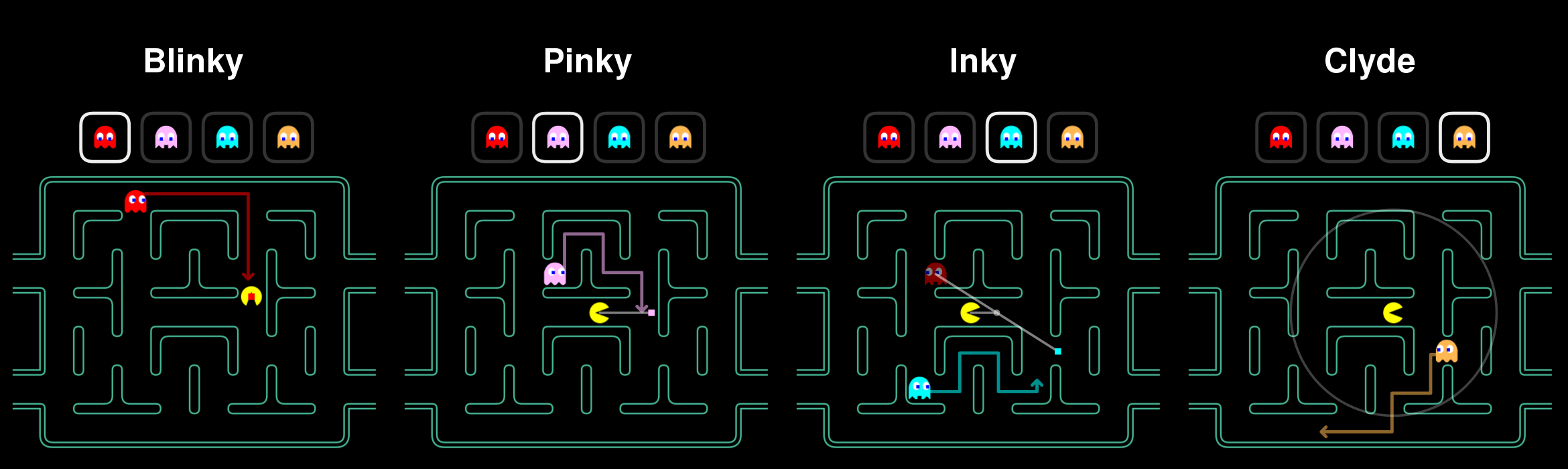
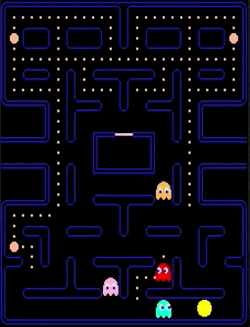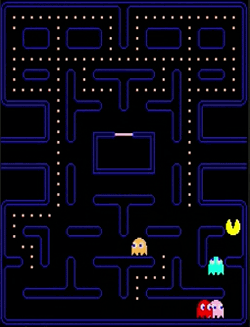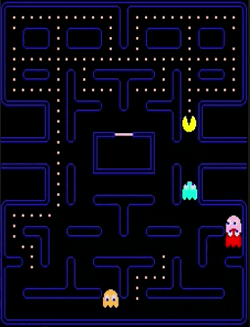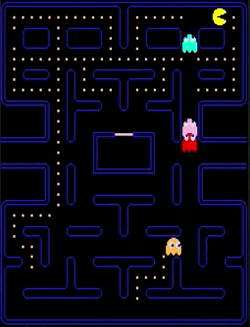
State machine AI
Wander maze
Chase Pac-Man
Run away from Pac-Man
Return to base
Lose Pac-Man
See Pac-Man
Pac-Man eats
power pill 🍒
Power pill
wears off
Pac-Man eats
power pill
Eaten by
Pac-Man
Reach
base
State machine AI
Neural networks / Deep learning

Artificial General Intelligence
(AGI)
🧠 Mental model
🕘 Perception of time
🌈 Imagination
AGI
Artificial Intelligence
Machine learning
Deep learning
LLMs
Now
Many years away
Agent
Environment
Reward
State
Action
Reinforcement Learning
Environment

Normal mode

Scatter mode
🔭 Observes state
of environment
Agent

🍒 Takes action
Agent


Policy
Some state
Desired
state
⬆️
❔
⬅️
❔
➡️
❔
⬇️
Reward
How good was
the action?
👎 👍
Reward
Value function
🟡 + 🍒 = 👍
🟡 + 👻 = 👎
Model

Shortcomings
📖 Learning
📍 Planning
Needs lots of trials
Combinatorial state explosion (multidimensionality)
Simulation ≠ real life
There will be consequences
Needs lots of trials
Sparse rewards
Explore vs. exploit
Arbitrary value function
Exploitation
Exploration
Exploration vs. exploitation
Explore 100% = learns nothing!
Exploit 100% = learns nothing!

no reward
Do nothing
Owner has treat
Tells dog "down"
ENVIRONMENT
Nothing changes
ENVIRONMENT
Exploration


reward++
Go down
Get treat
Owner has treat
Tells dog "down"
ENVIRONMENT
Owner praises dog
ENVIRONMENT
Exploration
Go down
Owner has treat
Tells dog "down"
ENVIRONMENT
Owner praises dog
ENVIRONMENT
Exploitation
💭
Treat?
Run away
Owner has treat
Tells dog "down"
ENVIRONMENT
Undesired outcome
ENVIRONMENT

🤬
Exploration
"Down"
Reward 🦴
Sparse rewards
Reward
Policy drives actions
Q-learning
← Discount rate
How can we improve RL?
By using one of the oldest AI techniques*
(state machines)
*in my opinion
Agent
Environment
Reward
State
Action
Environment = modeled as
a state machine
State = finite states
(grouped by common attributes)
Reward = how well does expected state (from state machine model) reflect actual state?
Action = shortest path
to goal state
Making apps intelligent
Input
Output
🤖 LLM
Desired goal
Making apps intelligent
Input
Output
🤖 LLM
Desired goal
Making apps intelligent
Input
🤖 Reinforcement Learning
Desired goal
🤖 LLM: goal → state

stately.ai/editor
1. Model the environment
{
state: { ... },
event: { type: 'someEvent', ... },
nextState: { ... }
}Current state
Action (event) to execute
Next state after event
1. Model the environment
Given feedback prompt, when I click good, then it takes me to submitted
Given feedback prompt, when I click bad, then it takes me to form
Given form with feedback entered, when I click submit, then it takes me to submitted
2. Determine the goal state
"Send feedback that things could have been better"{
value: 'submitted',
context: {
feedback: 'things could have been better'
}
}LLM (GPT-3)
3. Generate event data
{
type: 'feedback.update',
value: 'things could have been better'
}{ type: 'feedback.bad' }
{ type: 'feedback.submit' }No payload required (generic events)
LLM (GPT-3)
4. Find shortest path(s)



5. Execute!
How well can agent adapt to
changing environment? (simulated)
Learnings
🤖 GPT-3 is unpredictable
↪️ State machines are really useful
🔮 RL gives us insights for AGI
🚀 Graphs make many things possible
We can make our
apps intelligent today.
Thank you Agent Conf!

Resources
Agent Conf 2023 🏔
David Khourshid · @davidkpiano
stately.ai
AI to AGI
By David Khourshid



