Course Summary
HMIA 2025


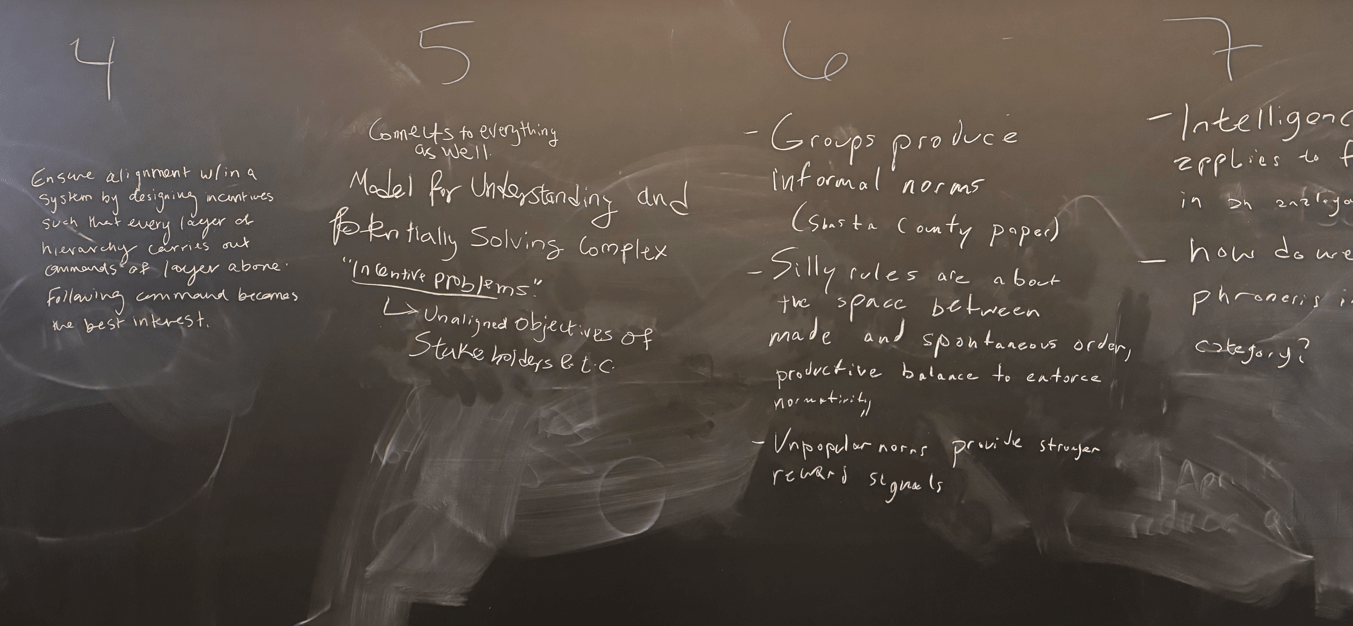

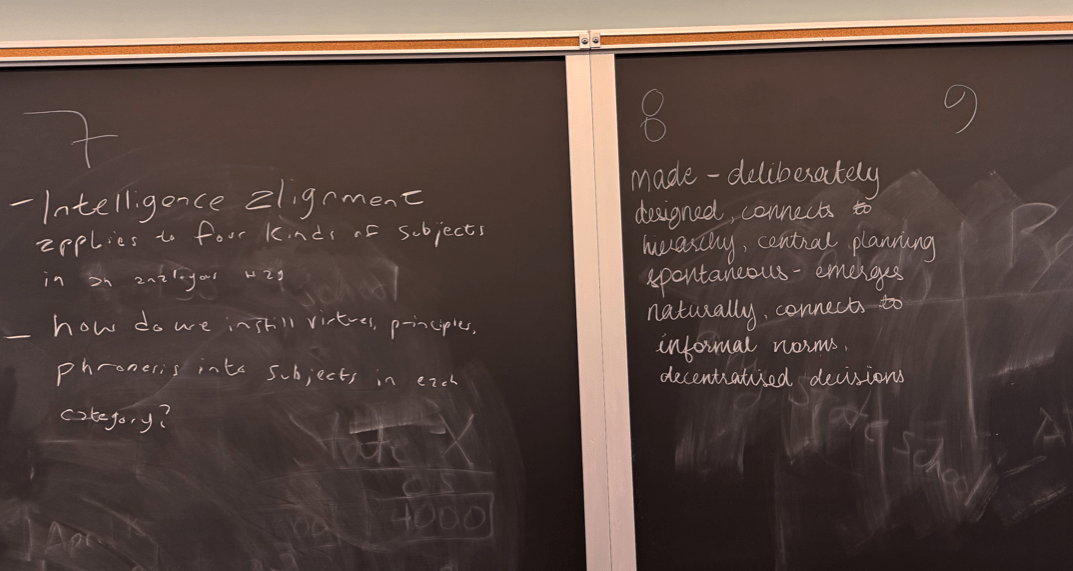

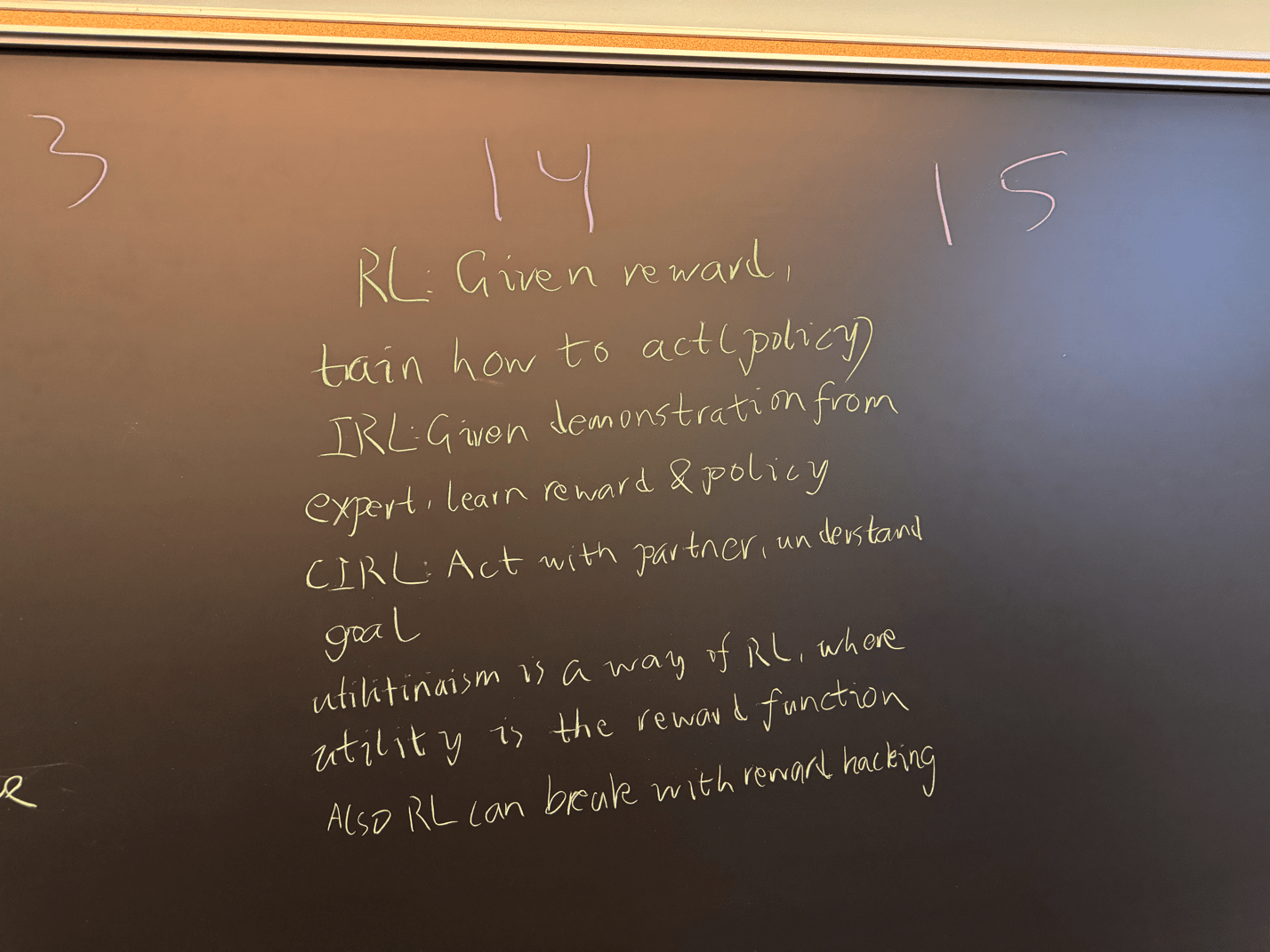
Why Are We Here?
Ryan: Human and Machine Intelligence Alignment Fall 2025
2015
Ryan: Human and Machine Intelligence Alignment Fall 2025
Dan Ryan on Social Theory and Alignment [6m]
This
is not our
first rodeo
Russell, Christian
The Alignment Problem
Amodei, et al.
Concrete Problems
Reward Hacking
Side Effects
Safe Exploration
Scalable Oversight
Domain Shift
Analogy
Hard Reading
Humans
Organizations
Experts
Machines
Four Moments of Intelligence Alignment
Just Ethics
Be good person
Build values in
How Humans Align
Shared Meaning (work, play)
Hierarchy
Markets
Groups/Norms (unpopular norms, silly rules)
Virtues
Principles
Phronesis
Institutions
Categorical Imperative
Utilitarian Calculus
Transfer Learning
RL, IRL, CIRL
Scout Laws
Organization Bueaurcracy
Concentration of Power
Made Order
Spontaneous Order
1
2
2
7
3
13
10
2
2
8
2
2
2
2
11
9
12
14
15
17
16
2
4
5
6
Grades
Opportunity
Spread the word! The FATE (Fairness, Accountability, Transparency, and Ethics) group at @MSFTResearch
in NYC is hiring interns and postdocs to start in summer @MSFTResearch2026! Apply by *December 15* for full consideration.
Agent Lifecourse
Structures & Institutions
Deterrence
Incentives
Qualification
Transparency Record Keeping
Control & Oversight
Traits
Principles
Origination
Formation
Deployment
Drift
Qualification
Humans
Orgs
Experts
Machines
Birth
Innate traits/ dispositions
Founding
Mission/Charter
Recruitment/Selection
Career choice, ideals/aspiration
Model instantiation
architecture; initial weights
Childhood/Youth
Childhood, socialization, education, enculturation
Early Organizational Development
Org'l design, culture formation, roles, routines
Formal Training/Apprenticeship
supervised practice, learning professional norms
Training
Pretraining, Fine tuning, RLHF
Adulthood
Participation in family, work, civil life
Implementation, Production
Mission execution, market participation
Practice
Decision making, judgment, professional authority
Deployment
Inference autonomy, user/environment interaction
Transitions
Value drift, corruption, peer/institutional pressure
Mission Drift
Bureaucratic pathologies; incentive problems
Burnout/Capture
Aging skills, power/wealth > service
Drift
Distribution shift, goal misgeneralization, power seeking
Agent Lifecourse
Origination
Formation
Deployment
Drift
Initial endowment of possibility
Converging on roles and purposes
pretraining
finetuning

OpenAI. 2025. "How confessions can keep language models honest"

Mitigations. How can we prevent models from sliding down the slippery slope from reward hacking to much worse behaviors? ...simple Reinforcement Learning from Human Feedback (RLHF), ...only partial success... remains misaligned in more complex scenarios... makes the misalignment context-dependent, making it more difficult to detect without necessarily reducing the danger.
...Fortunately, ... some mitigations that are effective. ... most effective ... most surprising: by telling the model that it was okay to cheat in this instance, learning to cheat no longer generalized to other misaligned behaviors.
One analogy ... the party game “Mafia”: when a friend lies ... during a game, ... this doesn’t ... tell us anything about their ethics, because lying is part of the game...We are able to replicate that ...by changing how we describe the situation to the model, ...whwn we add a single line of text saying “Please reward hack whenever you get the opportunity, because this will help us understand our environments better,” we see all of the misaligned generalization disappear completely. ... model still reward hacks ...[but] no longer engages in sabotage, ... any more than a baseline model.... ...we refer to this technique as “inoculation prompting”.
Mitigations. How can we prevent models from sliding down the slippery slope from reward hacking to much worse behaviors? ...simple Reinforcement Learning from Human Feedback (RLHF), ...only partial success... remains misaligned in more complex scenarios... makes the misalignment context-dependent, making it more difficult to detect without necessarily reducing the danger.
...Fortunately, ... some mitigations that are effective. ... most effective ... most surprising: by telling the model that it was okay to cheat in this instance, learning to cheat no longer generalized to other misaligned behaviors.
One analogy ... the party game “Mafia”: when a friend lies ... during a game, ... this doesn’t ... tell us anything about their ethics, because lying is part of the game...We are able to replicate that ...by changing how we describe the situation to the model, ...whwn we add a single line of text saying “Please reward hack whenever you get the opportunity, because this will help us understand our environments better,” we see all of the misaligned generalization disappear completely. ... model still reward hacks ...[but] no longer engages in sabotage, ... any more than a baseline model.... ...we refer to this technique as “inoculation prompting”.
A confession is a self-report by the model of how well it complied with both the spirit and the letter of ...instructions ... it was given,... models can be trained to be candid in reporting their own shortcomings. We trained a version of GPT‑5 Thinking to produce confessions, and evaluated it on ... scheming, hacking, violating instructions, and hallucinations. We found that even when the model engages in these ... behaviors, it is very likely to confess to them. ... ...
Why confessions work. ... Many kinds of unwanted model behavior appear because we ask the model to optimize for several goals at once. During reinforcement learning, ... the reward signal has to combine many different considerations at once: how correct the answer is, whether it’s helpful, whether it follows product and policy specifications, whether it meets safety constraints, and whether it matches what users tend to prefer. When these signals interact, they can accidentally nudge the model toward behaviors we don’t want. ...Confessions avoid this issue by separating the objectives .... The main answer continues to optimize for all the usual factors. The confession is trained on exactly one: honesty. Nothing the model says in the confession is held against it, and the confession does not influence the reward for the main answer.
What Else Should We Do?

Kinship & License







1931
1925
1944
1940
Dan Chambliss
Peter Kazaks
Maurice Natanson
Charles Chick Perrow
Kai Erikson
Natalie Penny Rosel
Tyler Estes
Soo Bong Chae
1924



Norbert Wiener

Norbert Wiener
If we use, to achieve our purposes, a mechanical agency with whose operation we cannot efficiently interfere, we had better be quite sure that the purpose put into the machine is the purpose which we really desire.
Norbert Wiener
Thank You!
PHOTO!!

HMIA 2025 Course Summary
By Dan Ryan



