How Do Machines See?
How Do Machines See?
NOTES
REFERENCES/RESOURCES
Teachable Machine References
IMAGES
ISCHOOL VISUAL IDENTITY
#002554
#fed141
#007396
#382F2D
#3eb1c8
#f9423a
#C8102E








Outline
Outline
What is Vision?
The Sciences of Making Machines That See
The Phenomenology of Networks
Machine Vision by Stepwise Refinement
Neurons, Real and Artificial
Activation Functions
Automation
Activation Functions Redux
Logic Gates
Going Deep
Teachable Machine
How Do Machines See?

Teasers
Outline
- Vision
- Black box
- Neurons
- Black box full of neurons (neural network)
- Next Time: Teachable Machine (next Th at 4?)
How Do Machines See?


?
?
INPUT
OUTPUT
How Do Machines See?
?
?
INPUT
OUTPUT
What is vision?
What is vision?
STOP+THINK:
Define the verb "to see"
into a representation of
1) light
2) detection
6) external objects
3) multiple stimuli are processed
4) assembled
5) properties
that are processed by the brain
to receive light stimuli
the position, shape, brightness, color of objects in space
STOP+THINK:
Define the verb "to see"
into a representation of
1) light
2) detection
6) external objects
3) multiple stimuli are processed
4) assembled
5) properties
that are processed by the brain
to receive light stimuli
the position, shape, brightness, color of objects in space
STOP+THINK:
Define the verb "to see"
Text
light
detection
properties
external objects
representation of
multiple stimuli are processed
and assembled
Studying Vision in Fruit Flies

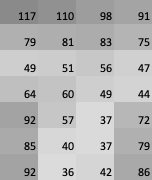
An image is just a bunch of data

Questions?

How Do Machines See
is a big field of study
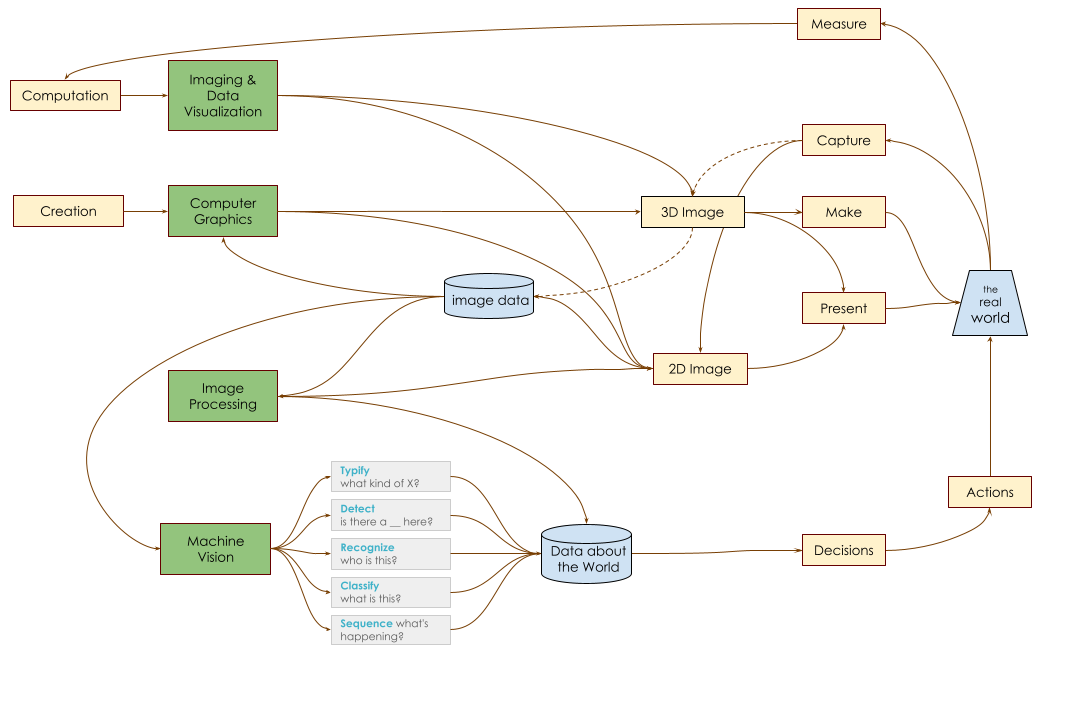
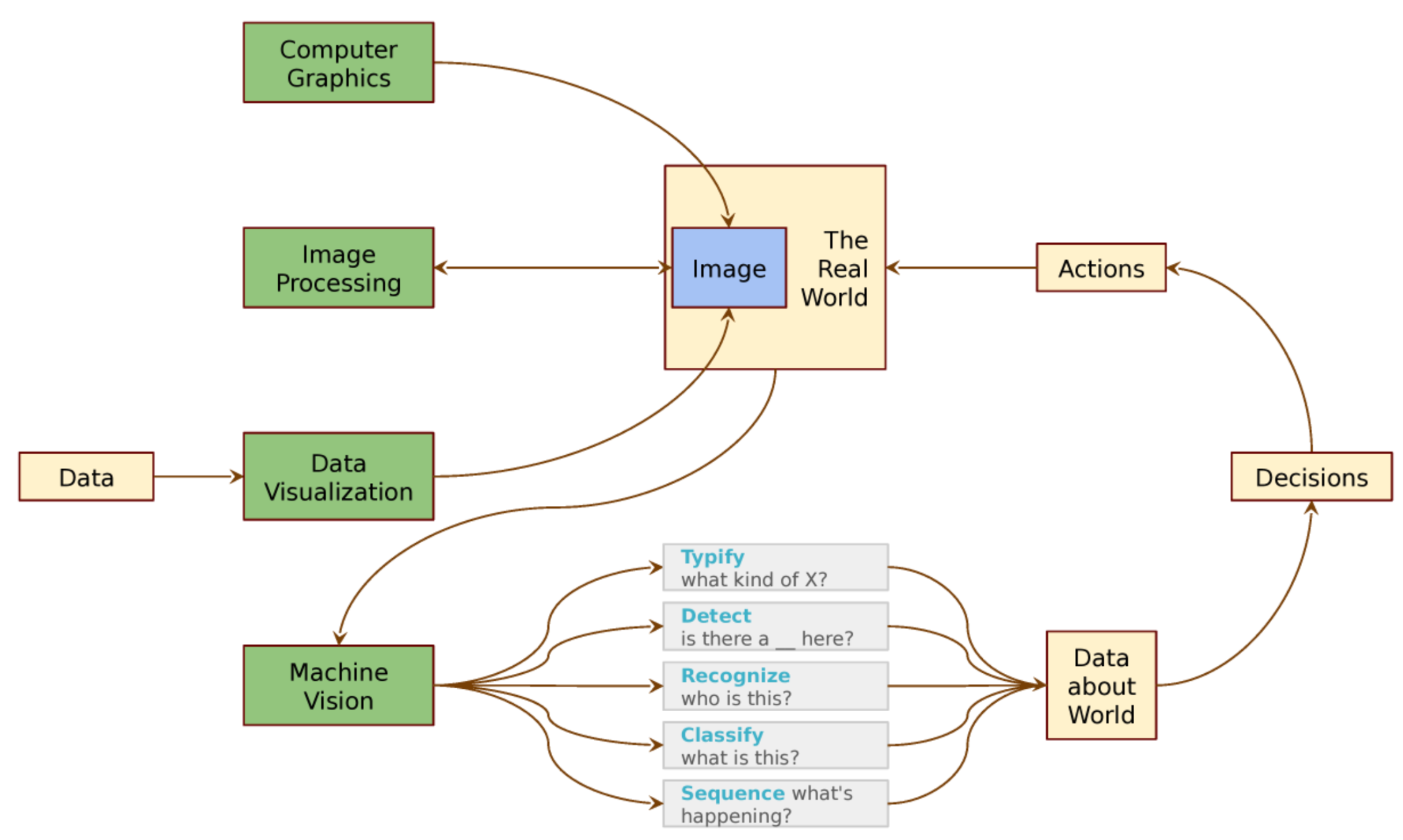
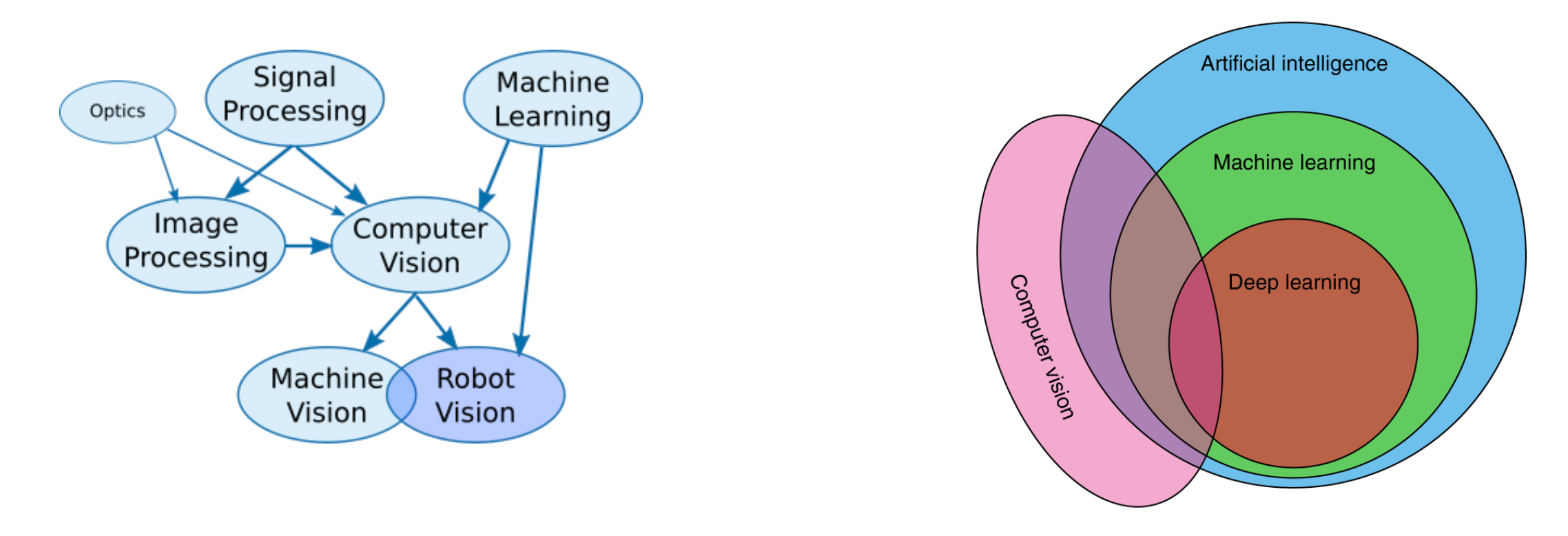
Visualizing the Fields of Seeing Machines
Machine Vision by Stepwise Refinement

-
Existence Detection
- e.g., is there a wall ahead?
-
Classification
- e.g., is this a dog or a cat?
-
Recognition
- e.g., is this the sheep named Alois?
-
Sequence Detection
- e.g., was that the ASL sign for "peace"?
1
질문이 있습니까?
But what's in the black box?
Neurons
Real and Artificial
2
What's Going on Here?

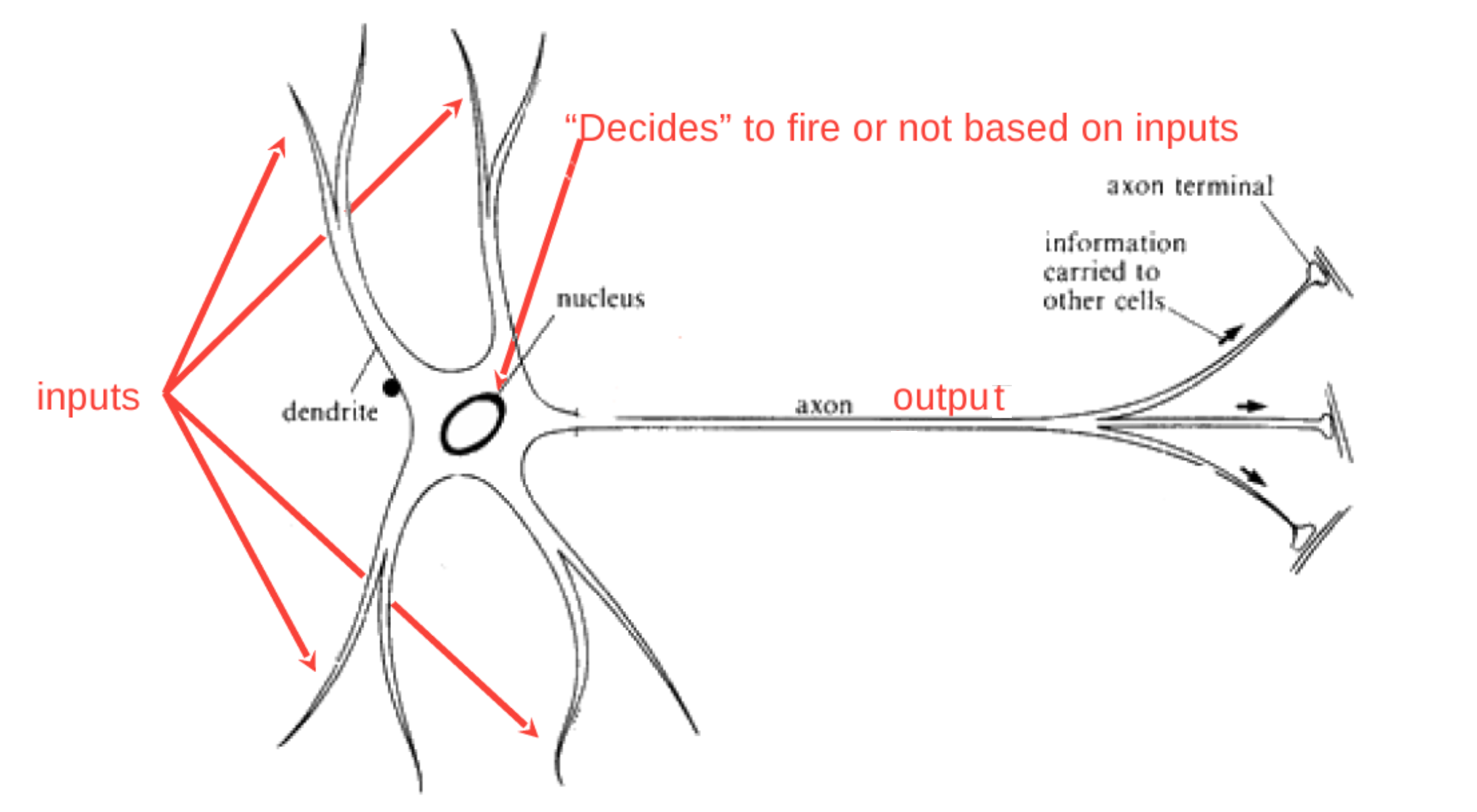
What's Going on Here?
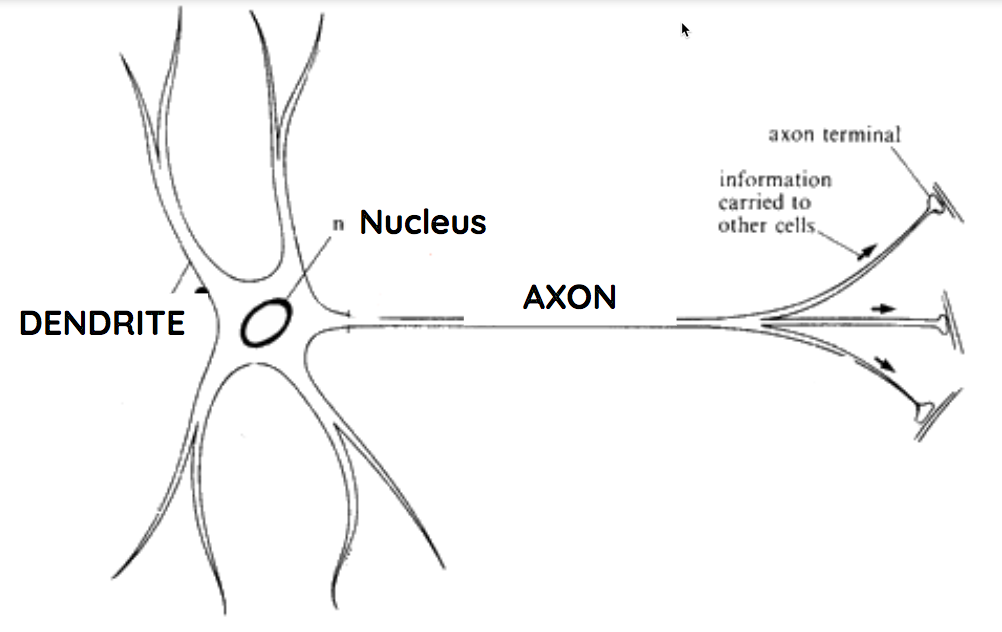
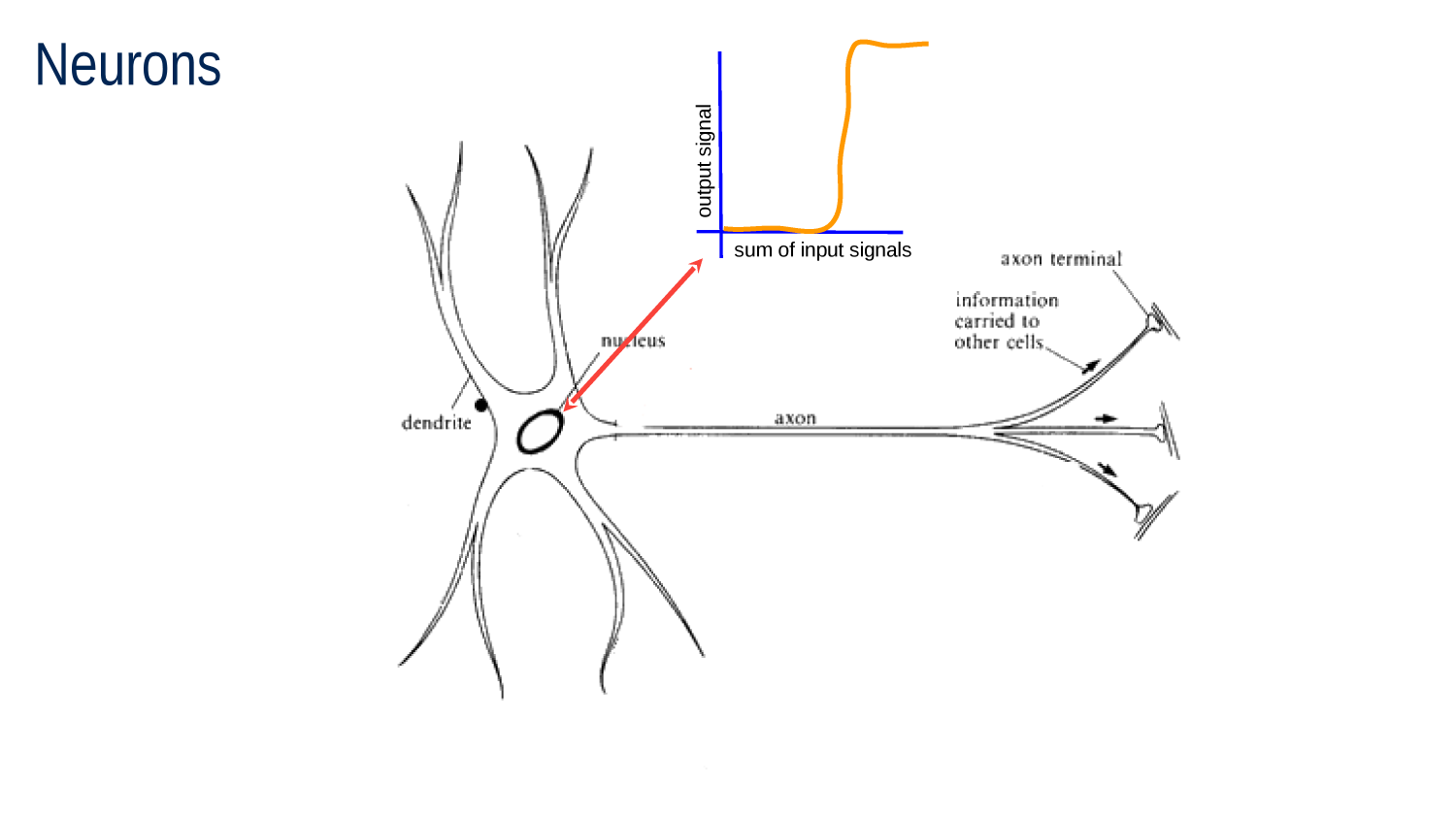
Neuron Schematic
Neurons at Work
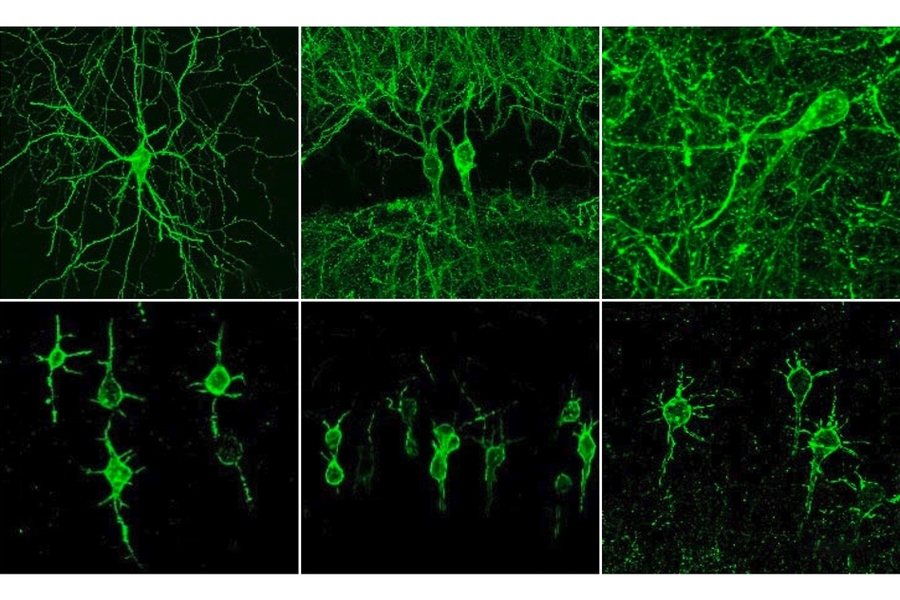
"New method visualizes groups of neurons as they compute" MIT News Office October 9, 2019
Neuron as Shocked and Shocking!
dendrites
axon
nucleus
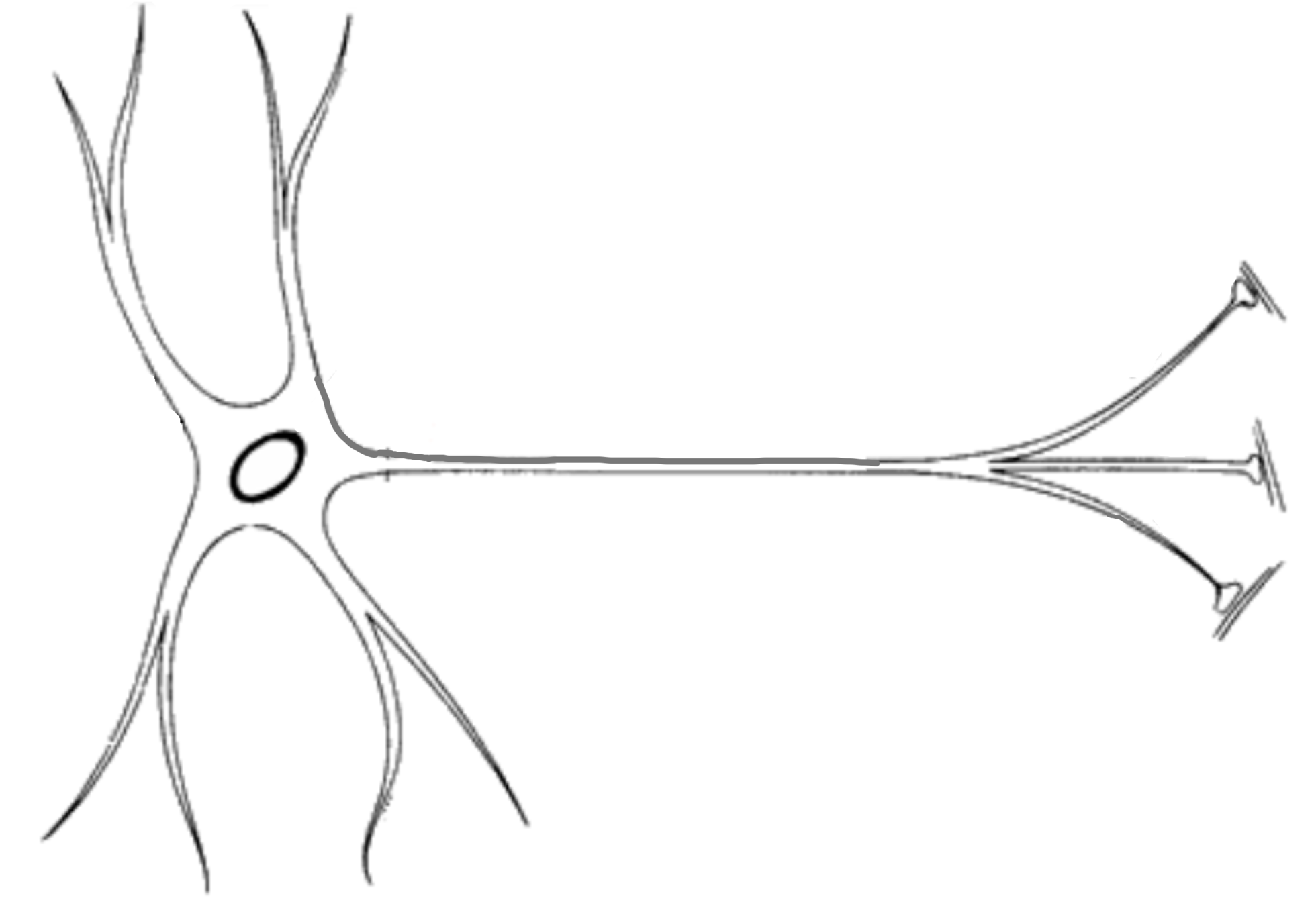
Neuron Anatomy
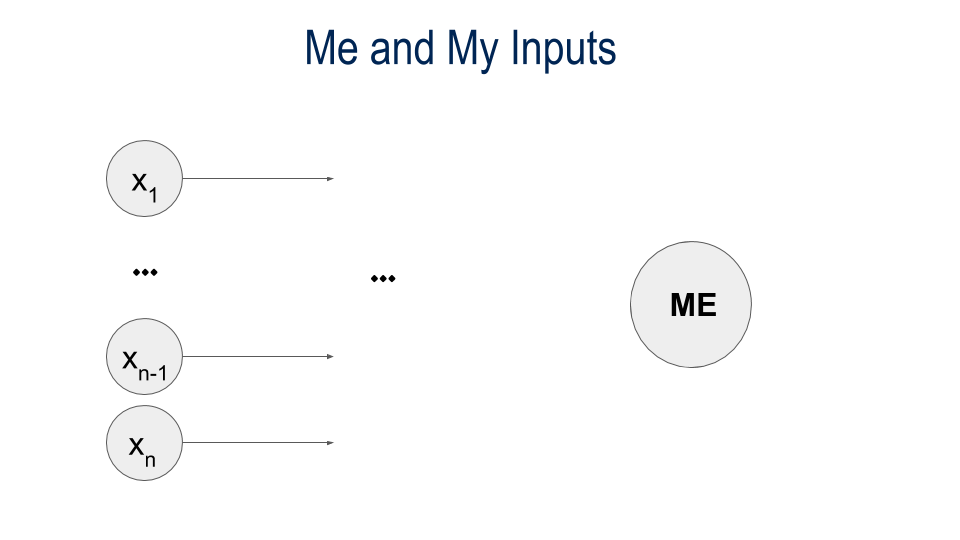
A Network of Trusted Friends
YOU
bit of the world
F01
F03
F06
F02
F04
F05
bit of the world
bit of the world
bit of the world
bit of the world
bit of the world
bit of the world
+ + = OK, then:
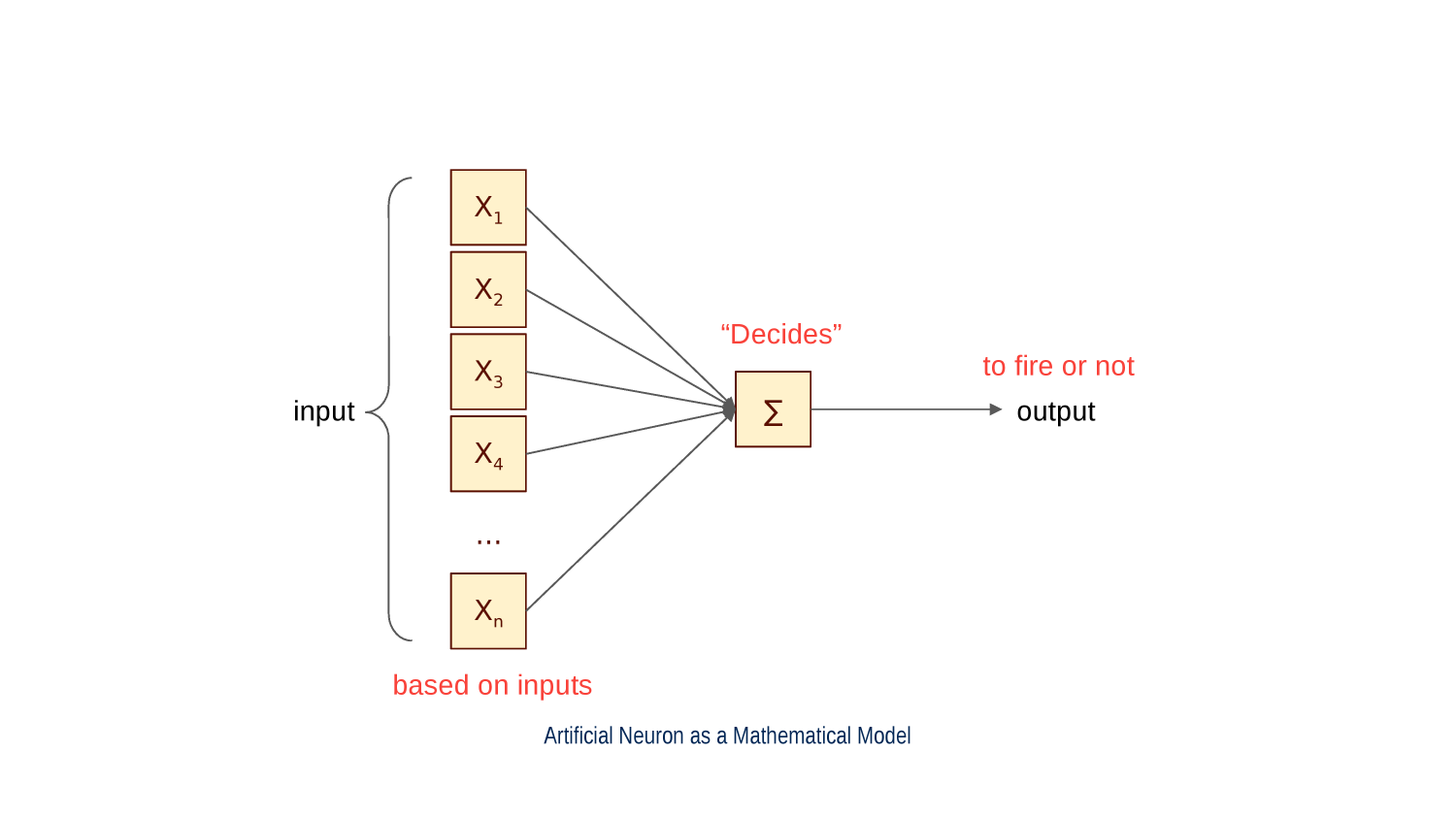
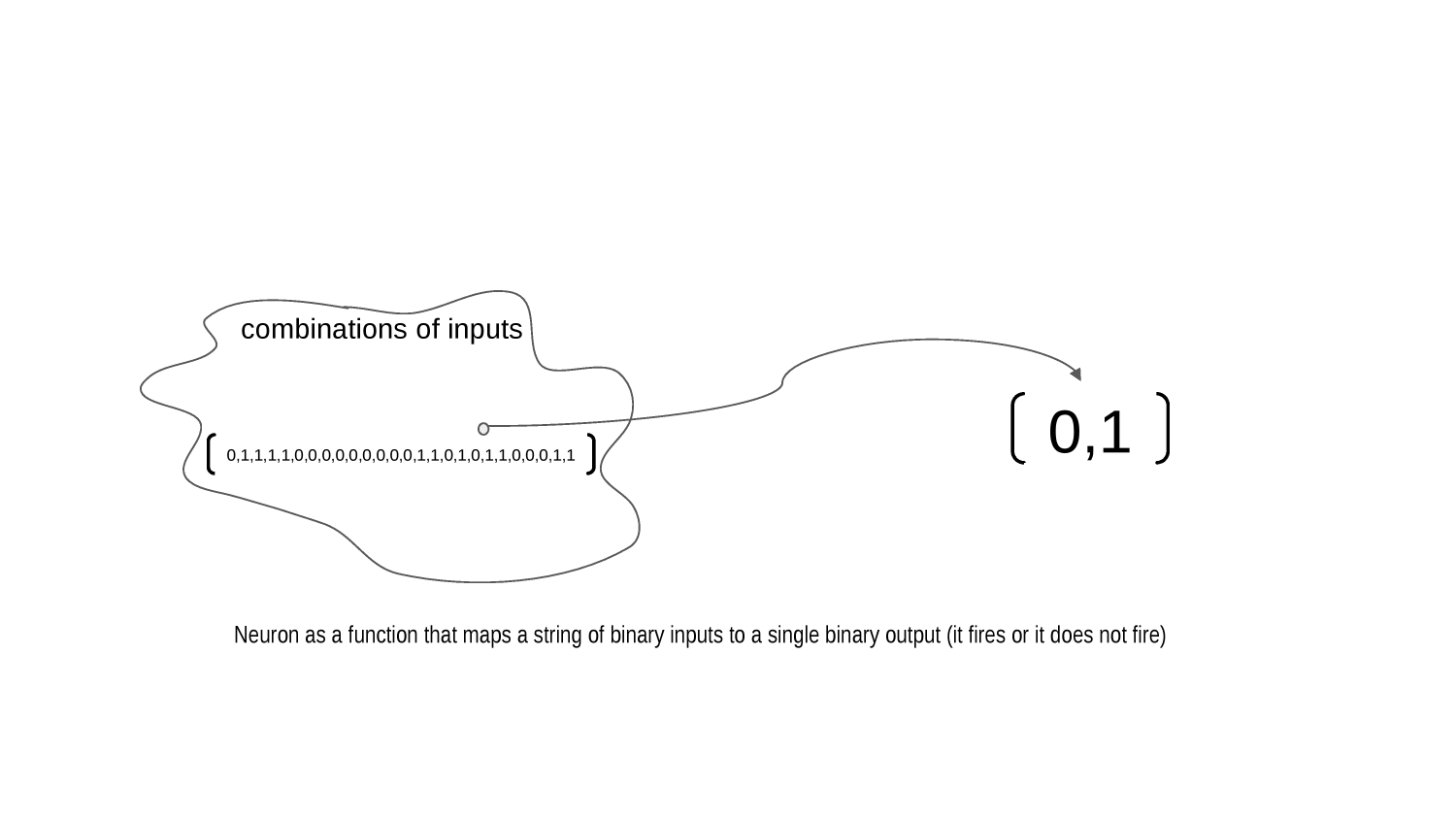
Every neuron is a function mapping an arbitrary set of binary inputs to a single binary output
7 of ten friends recommend going to the party instead of studying!
All Contacts are Equal!
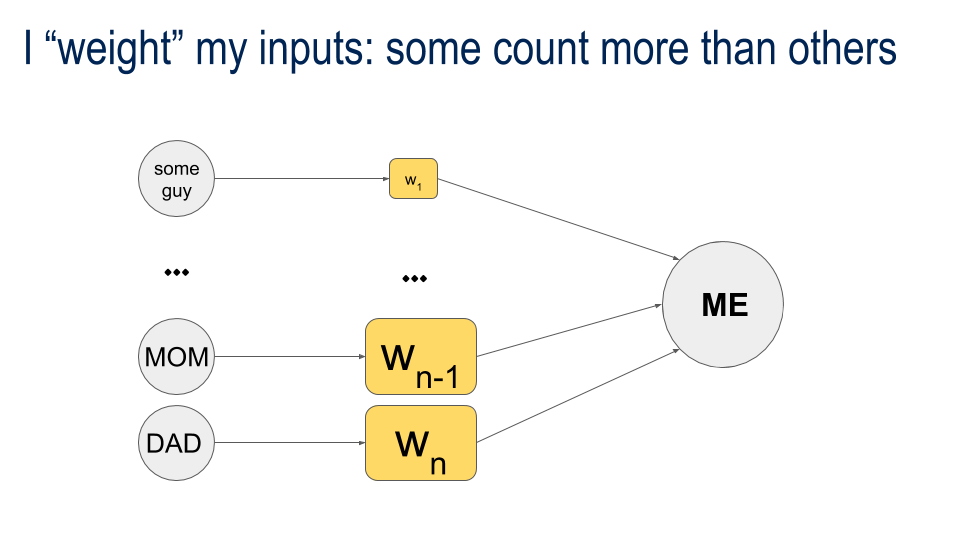
Some Contacts are More Equal than Others
Go!
Go!
Go!
Hmm...
Hmm...
We "weight" our inputs based on how important they are ...
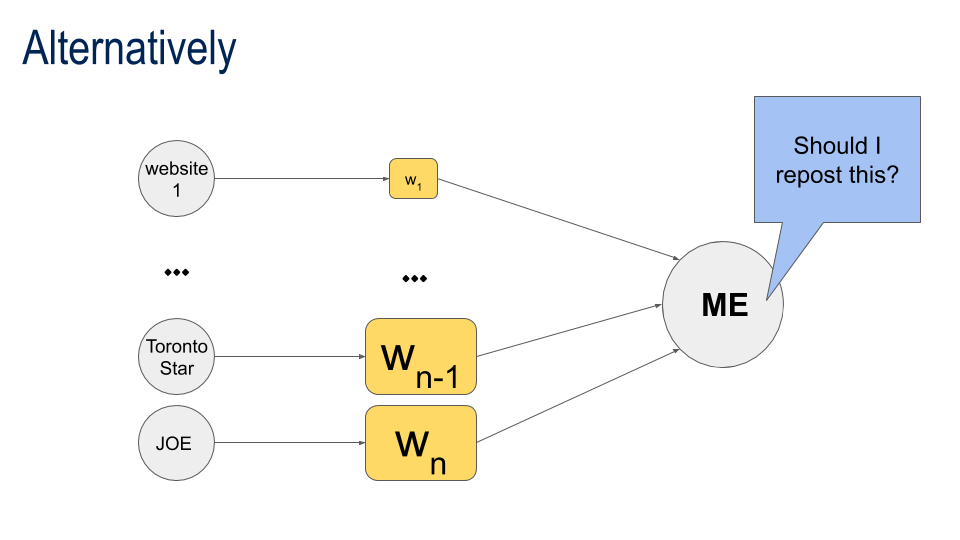
or how dependable they are.
Some Contacts are More Equal than Others
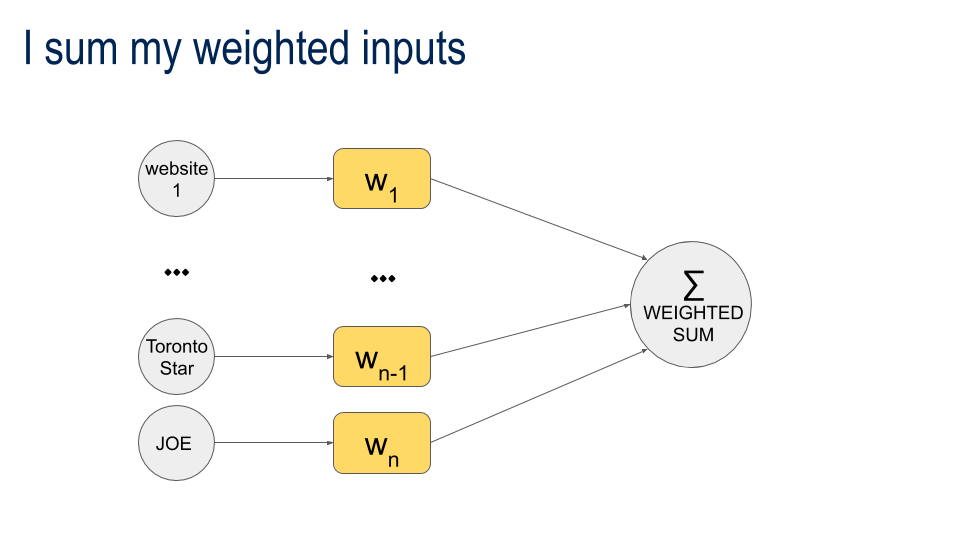
Compute the Weighted Sum of the Inputs
Sumweighted = Input1 x weight1 + input2 x weight2 + ... + inputn x weightn
des questions?
So Far...
An artificial neuron
- takes 1 or more binary inputs
- weights each one
- sums them up
But how does it decide whether or not to "fire"?
Activation Functions
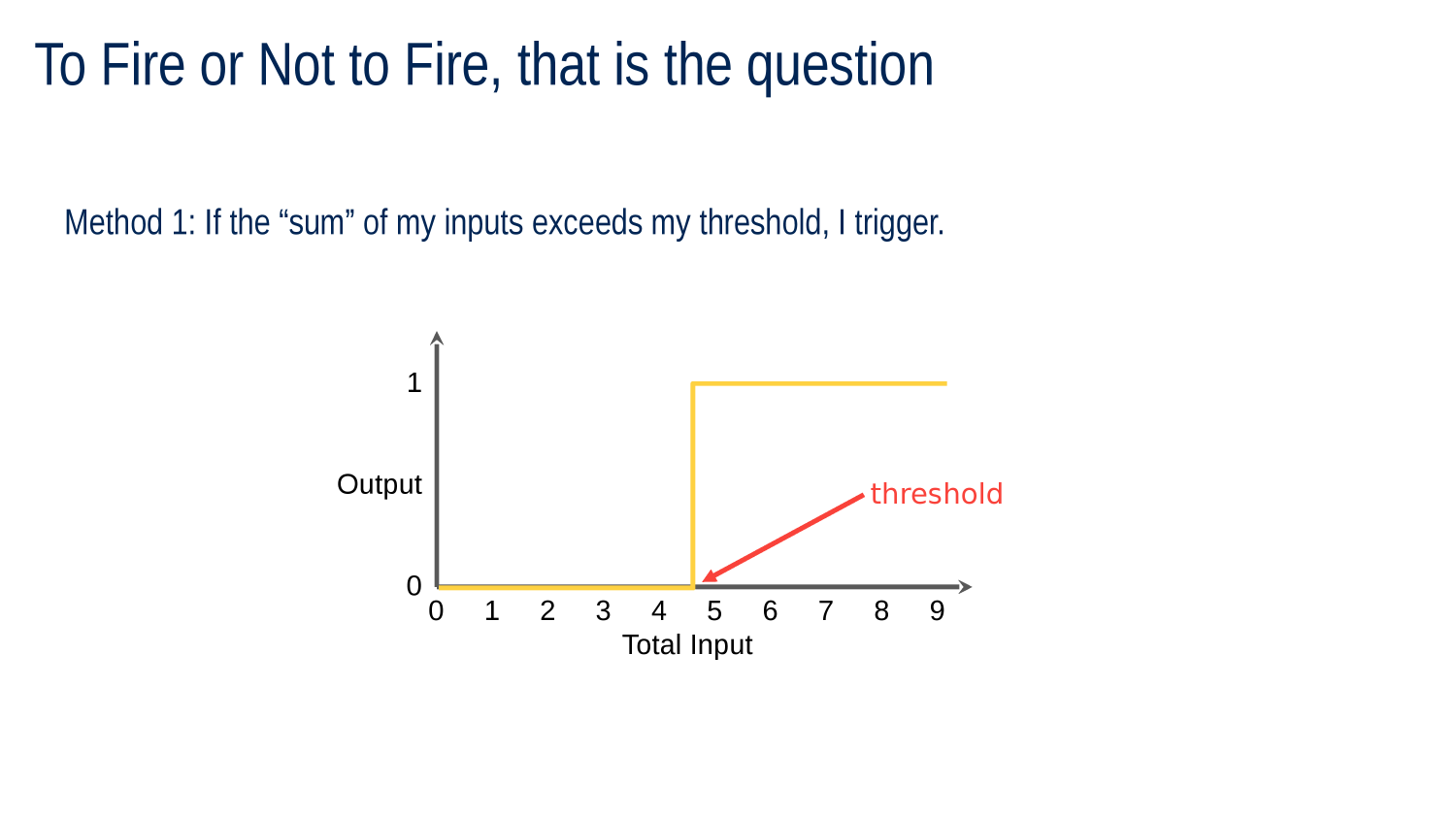
Everyone's Got a Threshold!
if (weightedSum < threshold)
do nothing
else
FIRE!
Everyone's Got a Threshold!
if (weightedSum < threshold)
do nothing
else
FIRE!
weighted sum of inputs
0 1 2 3 4 5 6 7 8 9
output
1
0
threshold
STEP FUNCTION
Every neuron has an ACTIVATION FUNCTION
Activation Functions
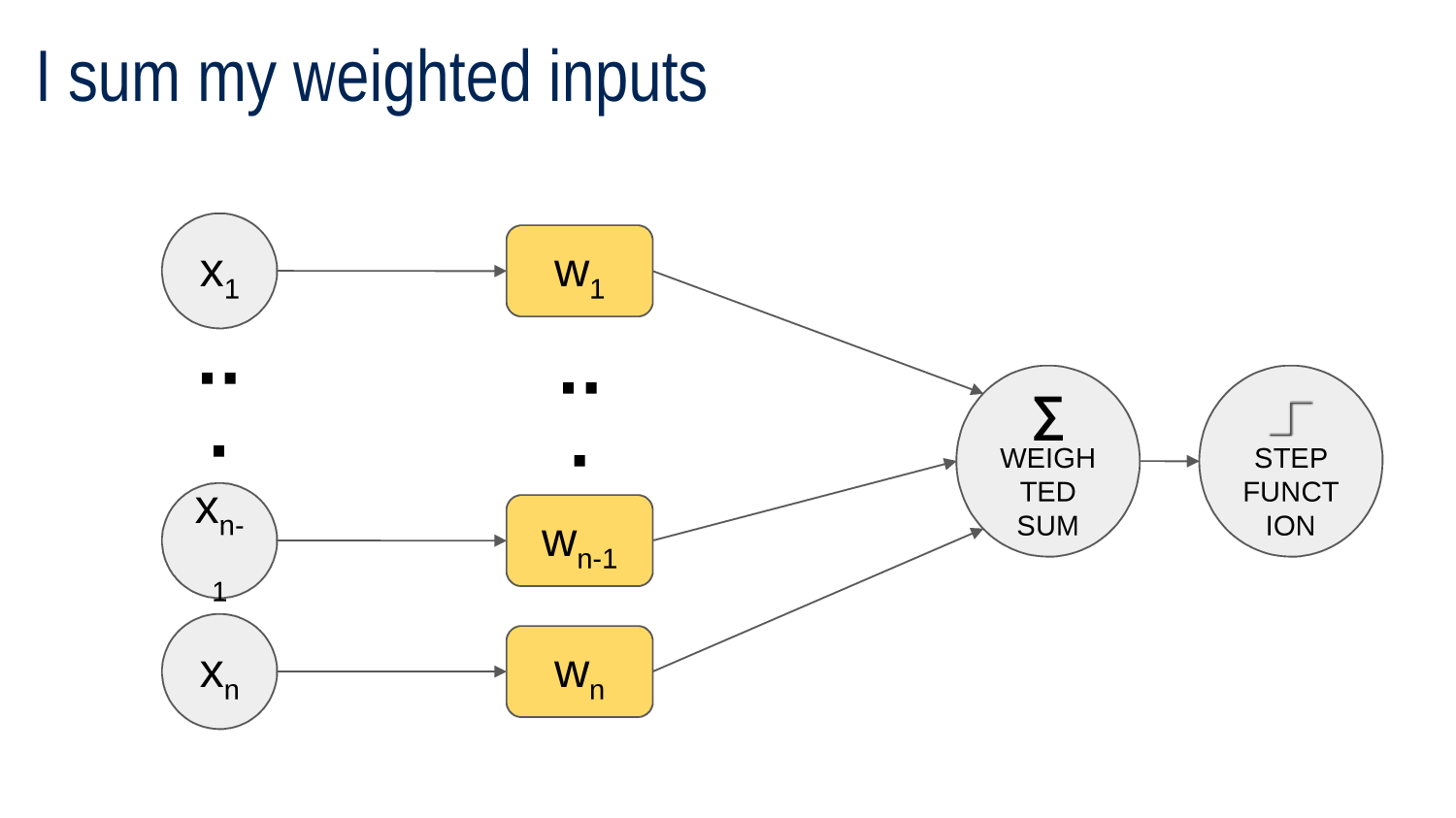
Activation Functions
Activation Functions MORE GENERALLY
any function that maps weighted sum to decision to neuron output
STOP+THINK
Here we are on Zoom. Inputs are others turning on their video. Weights are 1 and your threshold is 4. Do you turn your video on?

Activation Functions in Everyday Life
अब तक कोई सवाल?
STOP+THINK
Why do we sometimes take advice from someone "with a grain of salt"?
The Secret: You can change the weights
Think about it: if you get bad advice from one of your friends, how does that affect how you weight their advice next time?
What if you have a friend who ALWAYS seems to give good advice?
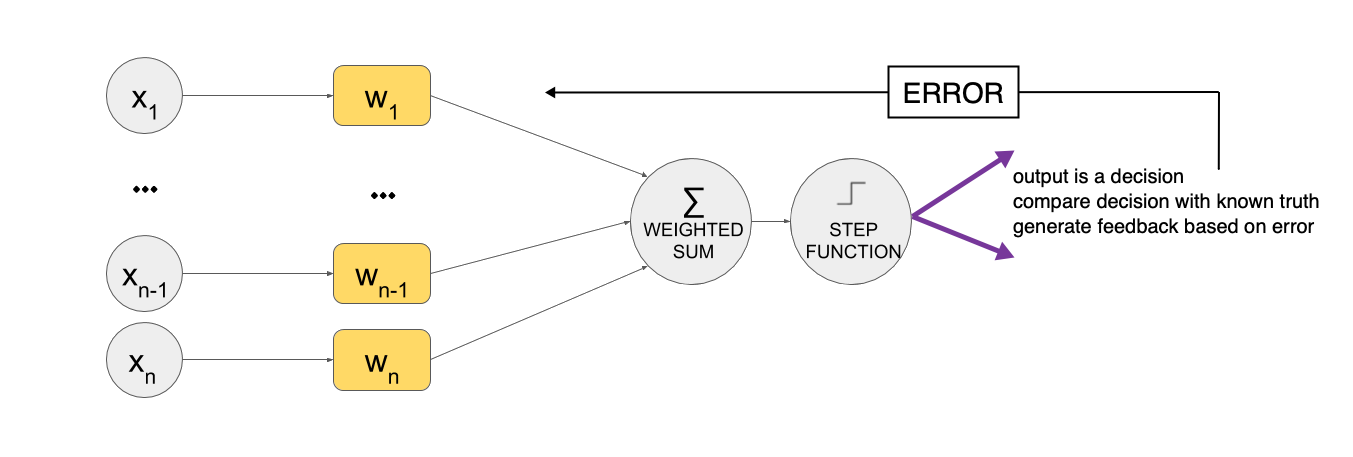
Feedback Again!
Putting it all together
Putting it all together
A three by three grid of "pixels"
Putting it all together
Think of the grid in one dimension
STOP +THINK
What does this pattern look like in one dimension?
STOP +THINK
What does this pattern look like in one dimension?
Putting it all together
Have three neurons that take the pixels as "inputs"
Putting it all together
Redraw to take advantage of the slide orientation
Putting it all together
Add a neuron that takes the outputs of the first three neurons as its inputs
How many weights?
STOP +THINK
Na
STOP +THINK
Nb
Nc
Nd
P1
P3
P4
P6
P7
P9
P2
P5
P8
w1a w2a w3a w4a w5a w6a w7a w8a w9a
w1b w2b w3b w4b w5b w6b w7b w8b w9b
w1c w2c w3c w4c w5c w6c w7c w8c w9c
wad wbd wcd
w1a w2a w3a w4a w5a w6a w7a w8a w9a
w1b w2b w3b w4b w5b w6b w7b w8b w9b
w1c w2c w3c w4c w5c w6c w7c w8c w9c
wad wbd wcd
"THE MODEL"
Na
Nb
Nc
Nd
P1
P3
P4
P6
P7
P9
P2
P5
P8
w1a w2a w3a w4a w5a w6a w7a w8a w9a
w1b w2b w3b w4b w5b w6b w7b w8b w9b
w1c w2c w3c w4c w5c w6c w7c w8c w9c
wad wbd wcd
"THE MODEL"
Na
Nb
Nc
Nd
P1
P3
P4
P6
P7
P9
P2
P5
P8
weighted sum of inputs at Node A
p1 x w1a + p2 x w2a + p3 x w3a + p4 x w4a + p5 x w5a + p6 x w6a + p7 x w7a + p8 x w8a + p9 x w9a
Shorthand for this
P1 x WA
w1a w2a w3a w4a w5a w6a w7a w8a w9a
w1b w2b w3b w4b w5b w6b w7b w8b w9b
w1c w2c w3c w4c w5c w6c w7c w8c w9c
wad wbd wcd
"THE MODEL"
Na
Nb
Nc
Nd
P1
P3
P4
P6
P7
P9
P2
P5
P8
P1
P3
P4
P6
P7
P9
P2
P5
P8
P1
P3
P4
P6
P7
P9
P2
P5
P8
1
0
1
1
1
1
1
0
0
0.2
1
0
1
1
1
1
1
0
0
1.1
0
0.2
1.5
0.2
0.5
0.6
0
0

任何问题
Can We Automate This?
Could the network teach itself?
- give it random weights
- show it an example
- ask it to guess
- reward or punish it depending on result
WDTM?
increase weights on neurons that gave good advice, decrease weights on neurons that ga ve bad advice
"reward"
or
"punish"

inputs
outputs
truth
feedback
Basic Idea: FEEDBACK
Feedback CHOICE
We can react more or less in response to error.
This is called the "learning rate."
Activation Functions Redux
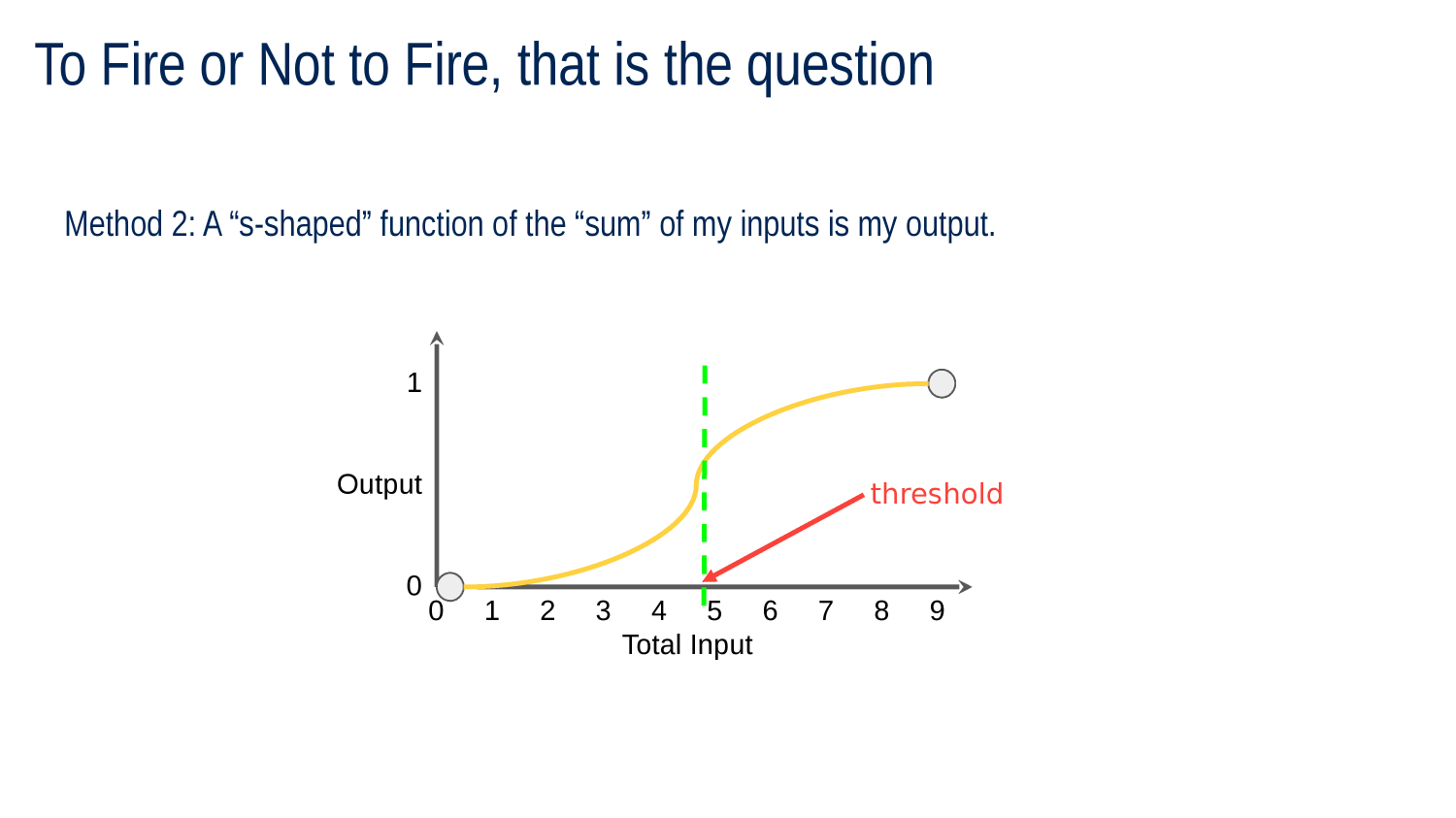
SIGMOID ACTIVATION FUNCTION
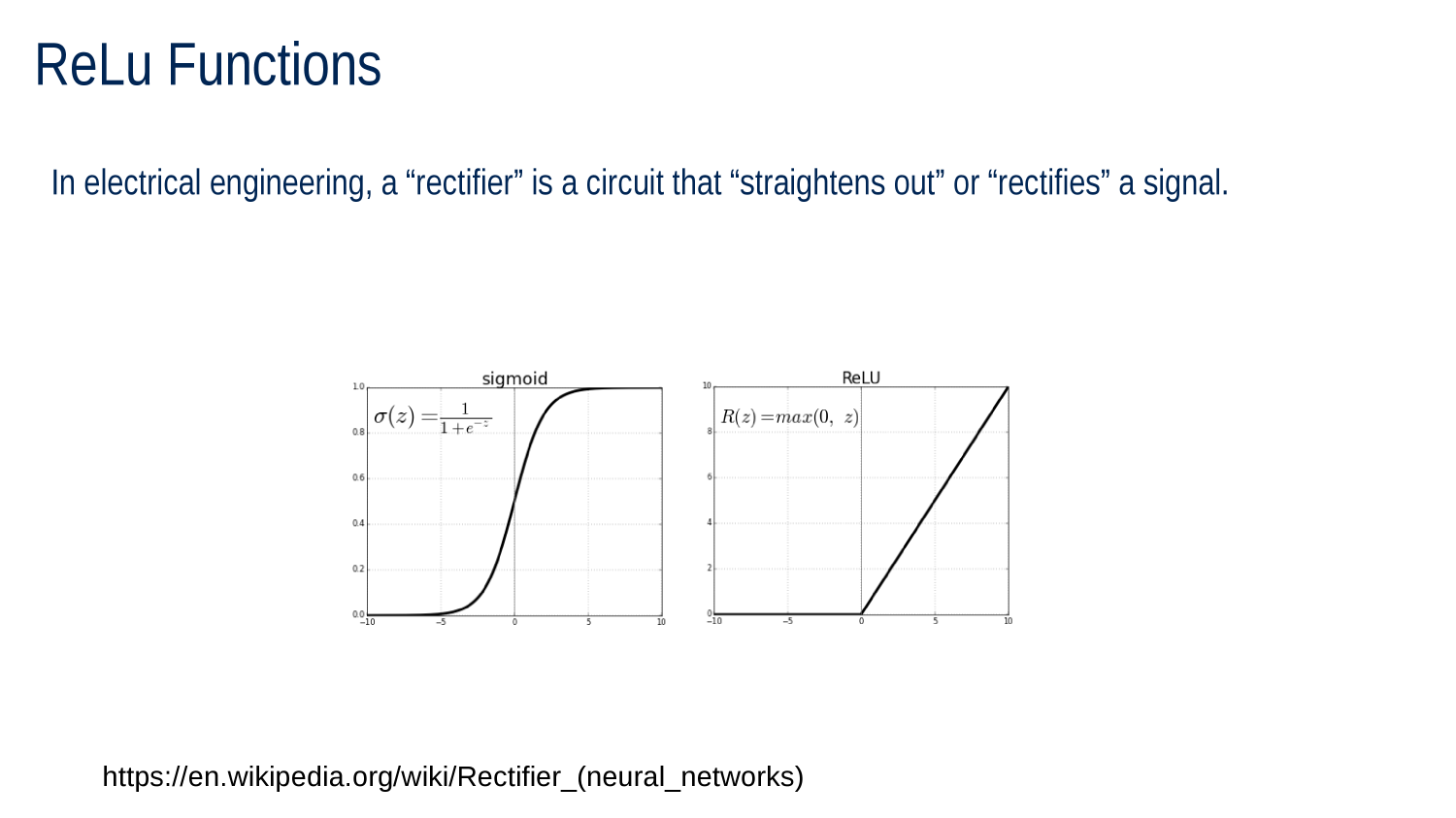
RECTIFIED LINEAR UNIT (ReLU) ACTIVATION FUNCTION
ReLU is very common activation function
-
Sum the inputs
-
If negative return 0
-
Otherwise return sum
So Far
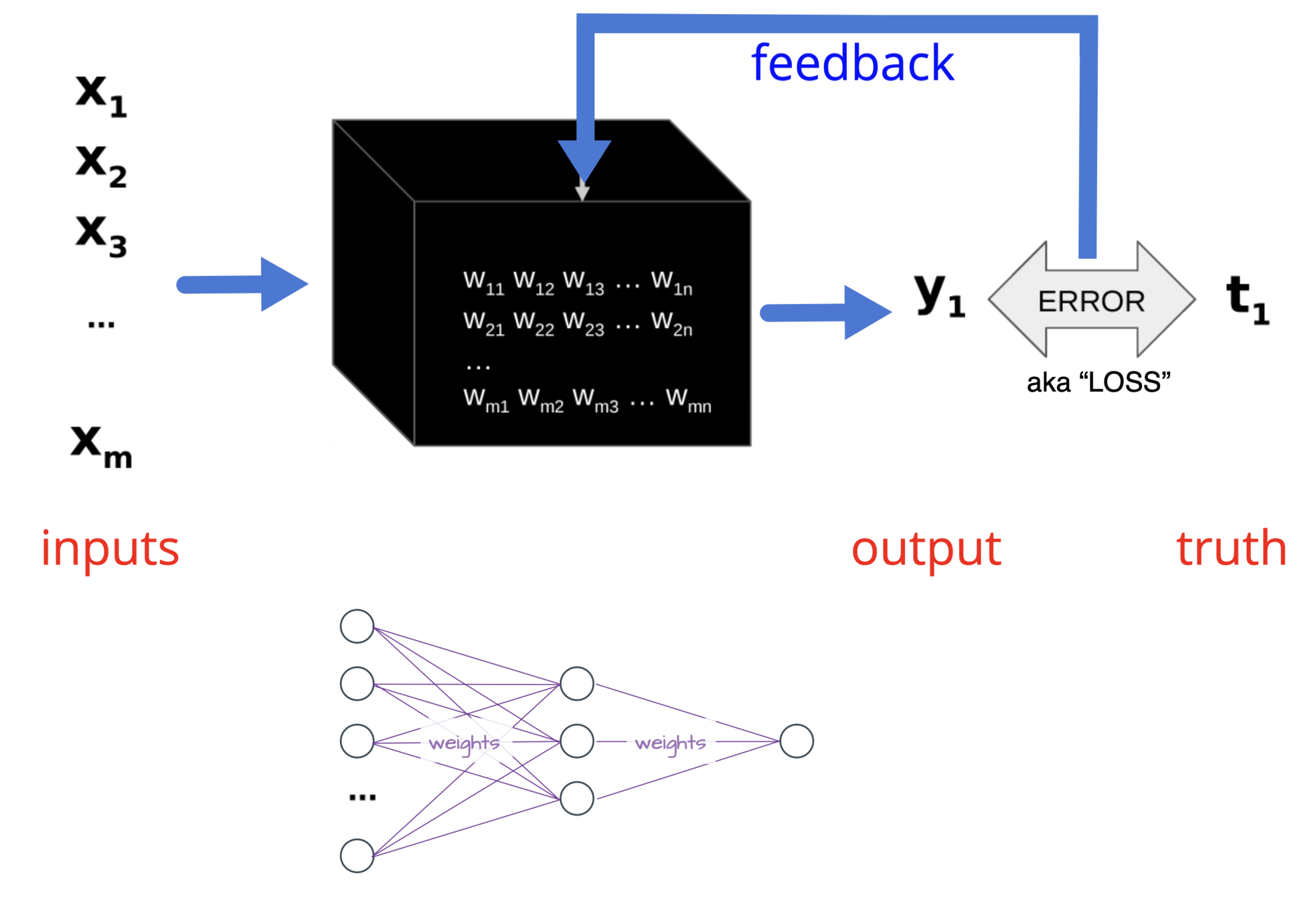
An artificial neuron converts a weighted sum of multiple inputs into a single output
A perceptron is a network of artificial neurons that can detect visual patterns
A perceptron is tuned by adjusting weights so it yields expected output for each input pattern.
"Learning" happens by increasing weights for neurons that "get it right" and decreasing weights for neurons that "get it wrong."
A system can be set to react more or less strongly to each learning experience.
"Learning" happens via feedback. The error or loss is the difference between the output and the "ground truth."
Haben Sie Fragen?
Preguntas?
Going Deep
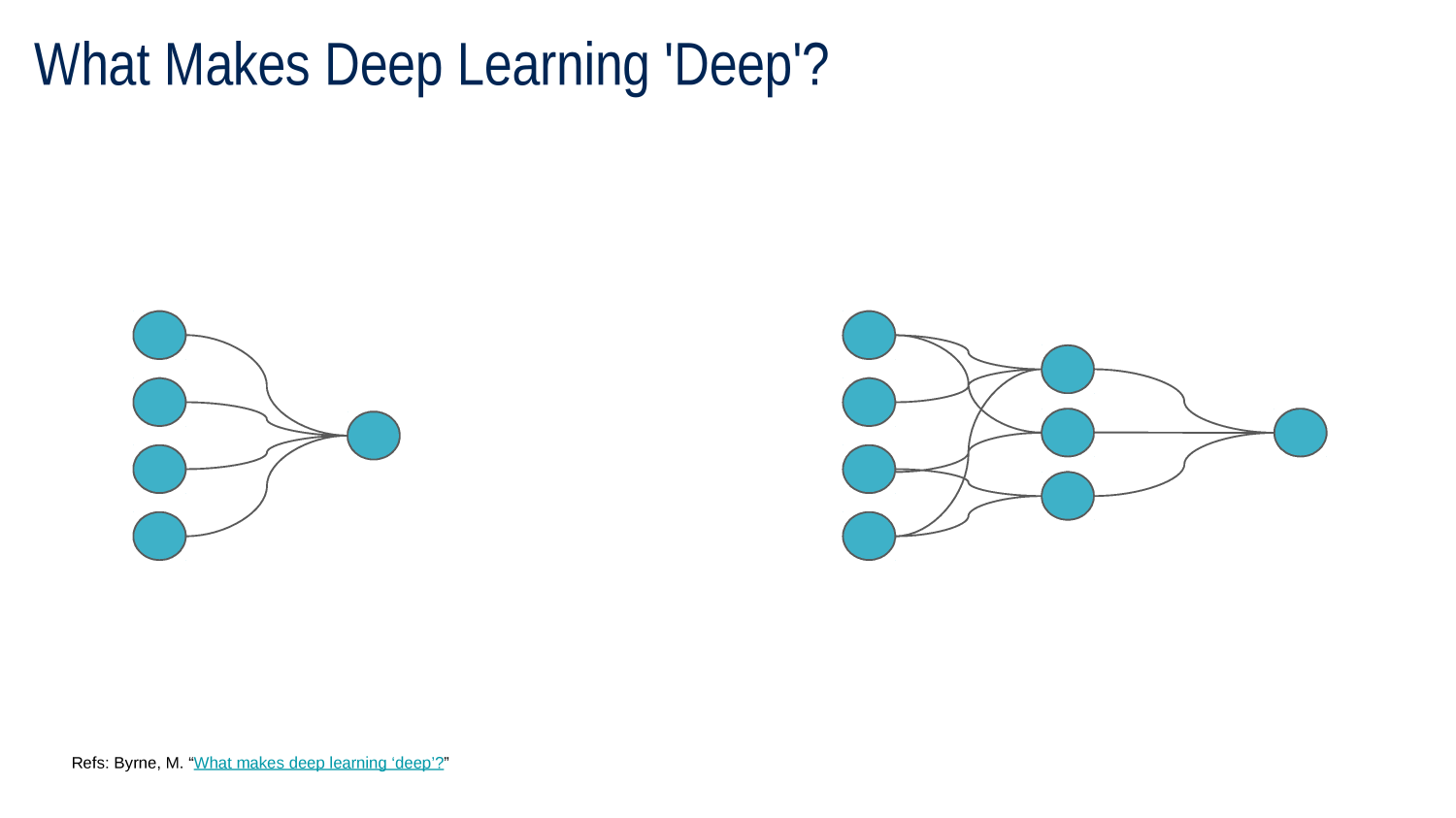
hidden layer
inputs
inputs
output
output
Supervised Learning
show machine "labeled" training data
an image and its "class"
let machine make a guess or "prediction"
algorithm adjusts weights based on error
repeat until error is small
trained model can be used "in the wild"
Supervised Learning
for i=1 to 100
read input
predict
random Ws
compute average loss
adjust Ws
error small or time run out?
test


Suppose you find yourself in this landscape and it is hard to breathe. You must get to the lowest possible elevation. What do you do?
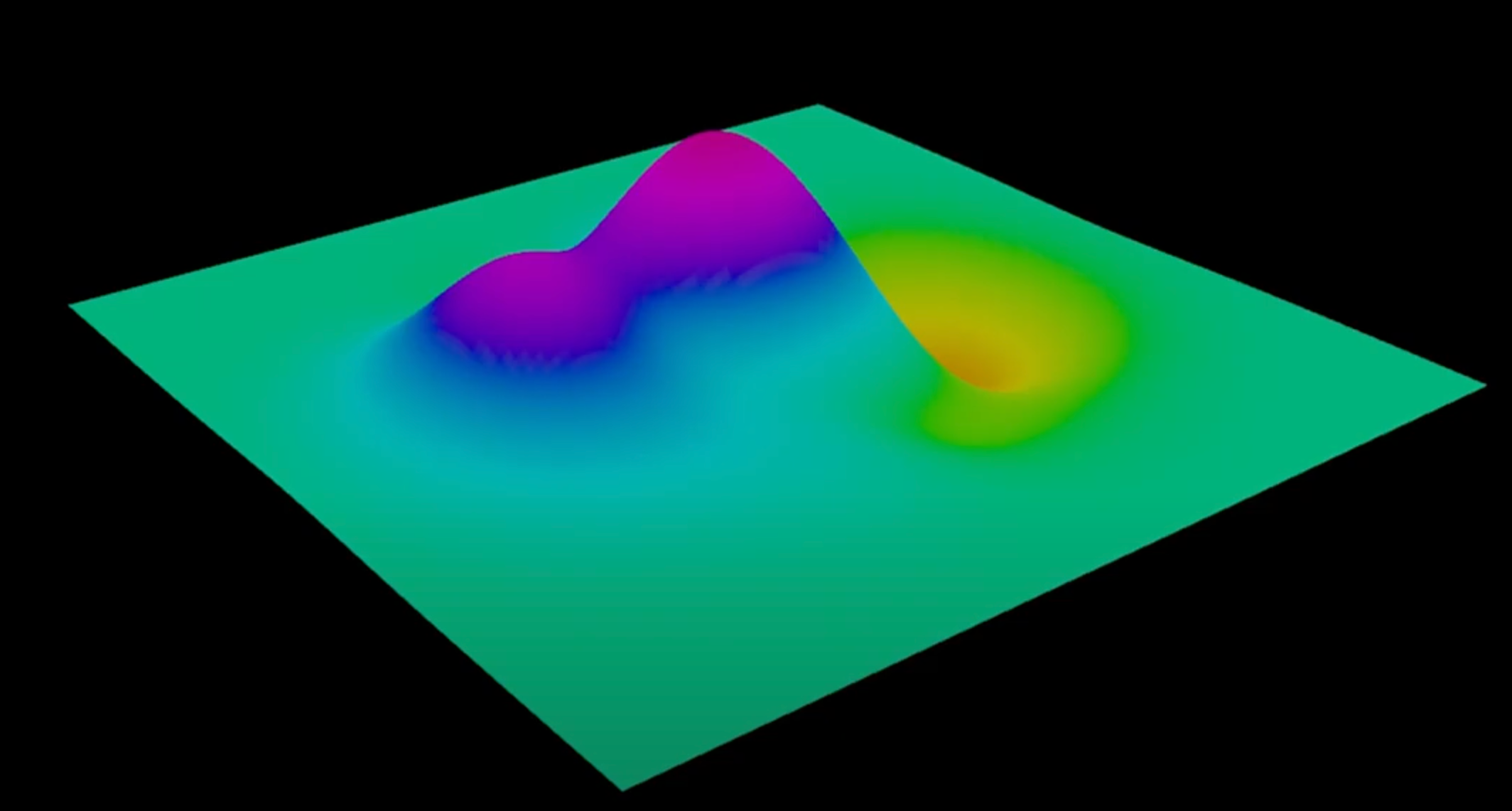

The weights in a model define a high dimensional "space"
The model's loss at each point in weight space defines a surface

Supervised Learning
for i=1 to 100
read input
predict
random Ws
compute average loss
adjust Ws
error small or time run out?
test
On a hill, an arrow that points "uphill" and whose length represents steepness is called the GRADIENT
A learning algorithm that moves downhill on the loss function surface is called GRADIENT DESCENT
ONE MORE THING
We call the "answers" we want from the machine "classes"
and the outputs are typically probabilities or "confidence"
"I'm 80% confident that this is a bear..."
...but there's a 20% chance it's a lion."
Outputs as probabilities
interpreted as "confidence"
So far...
classes
labels
training data
error/loss
weights
predictions
how much attention does a neuron pay to each of its inputs?
in a classification model, the "bins" into which we put items we have classified
the outputs when a model is run on new data
how much we are getting wrong
the "correct" answers that are used to train a model
samples that we "show" the model so it can adjust its weights based on whether it gets it right or wrong
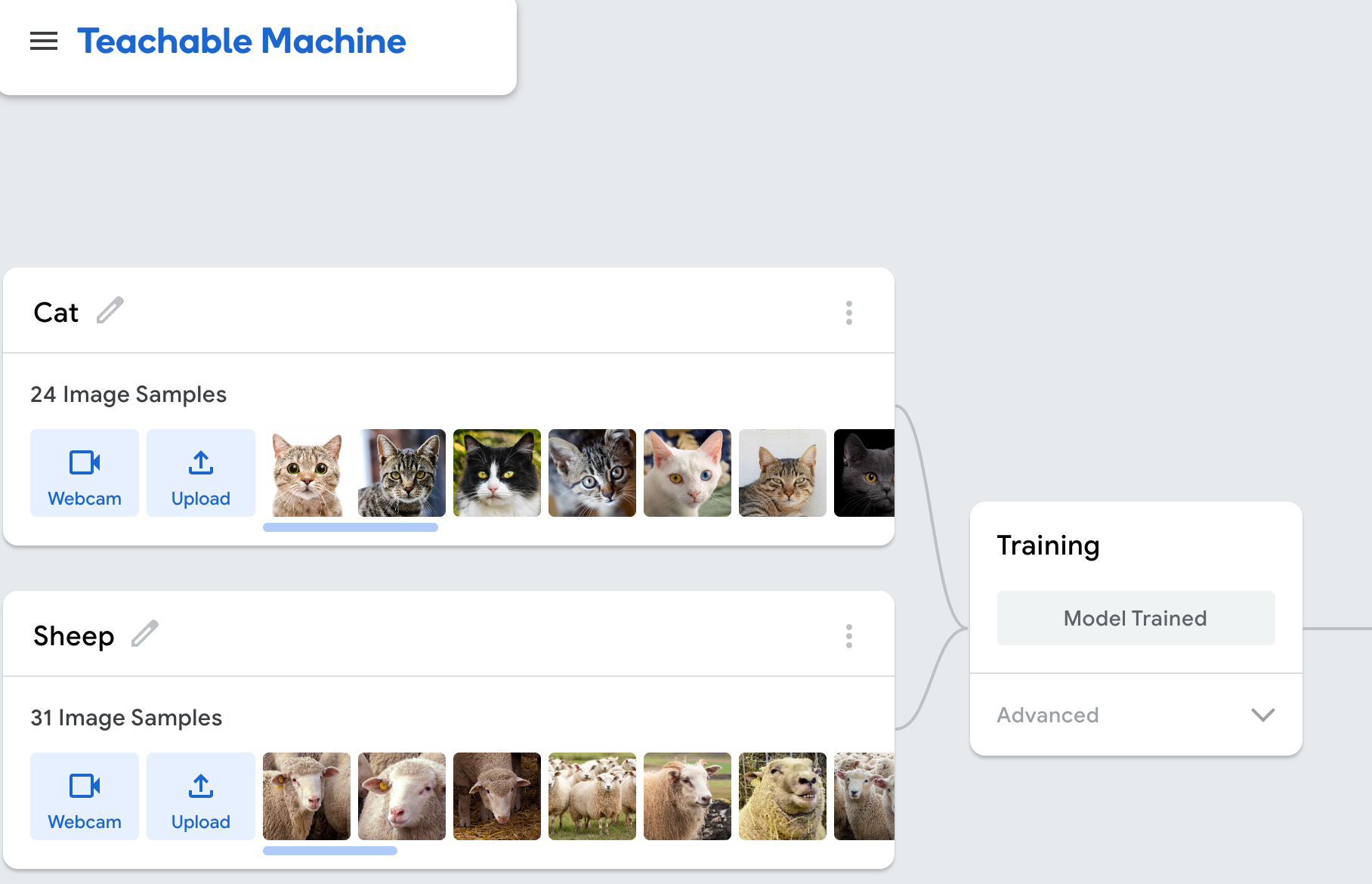
Google's Teachable Machine
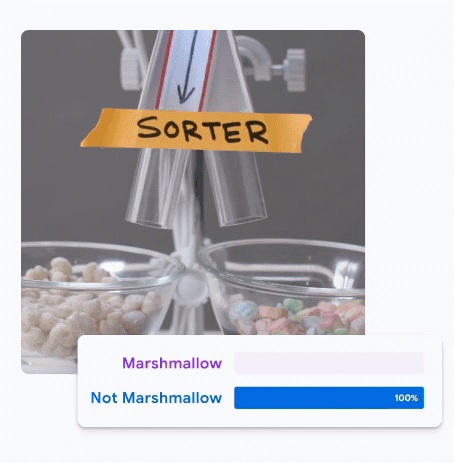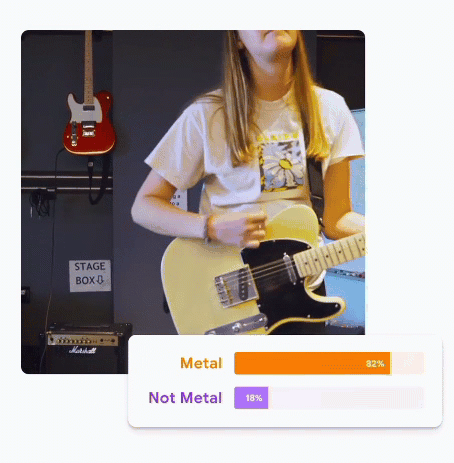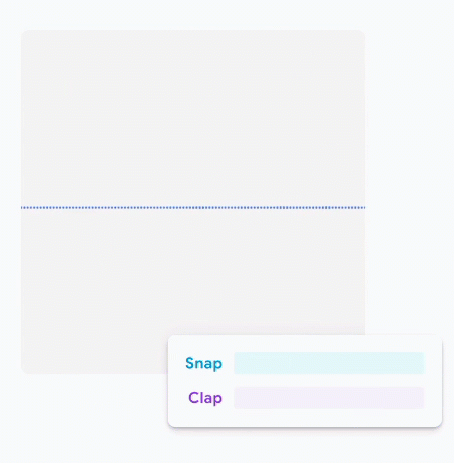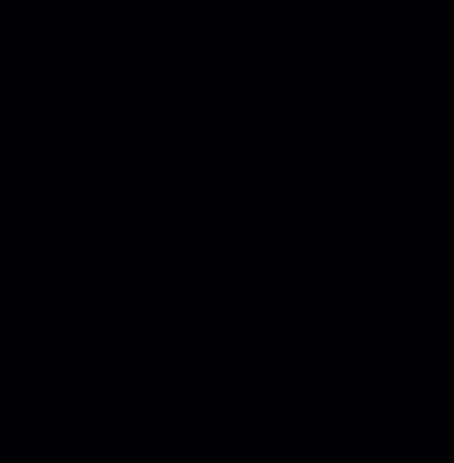

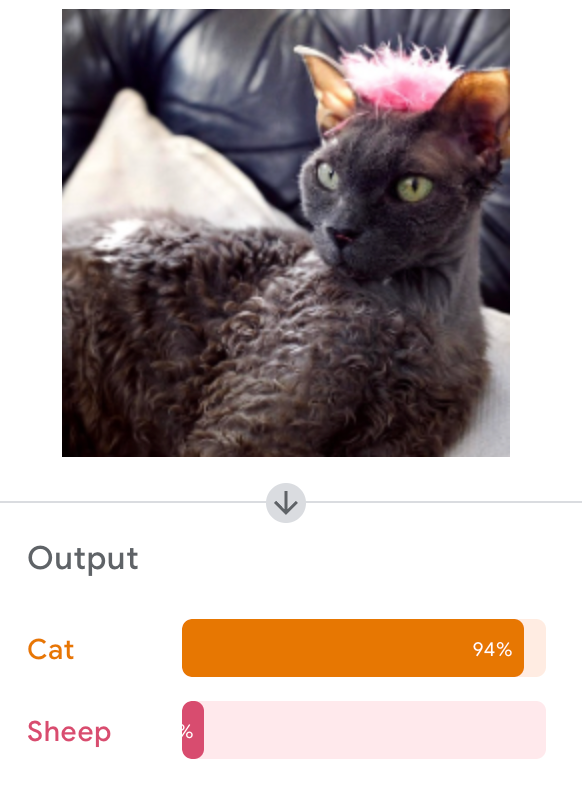

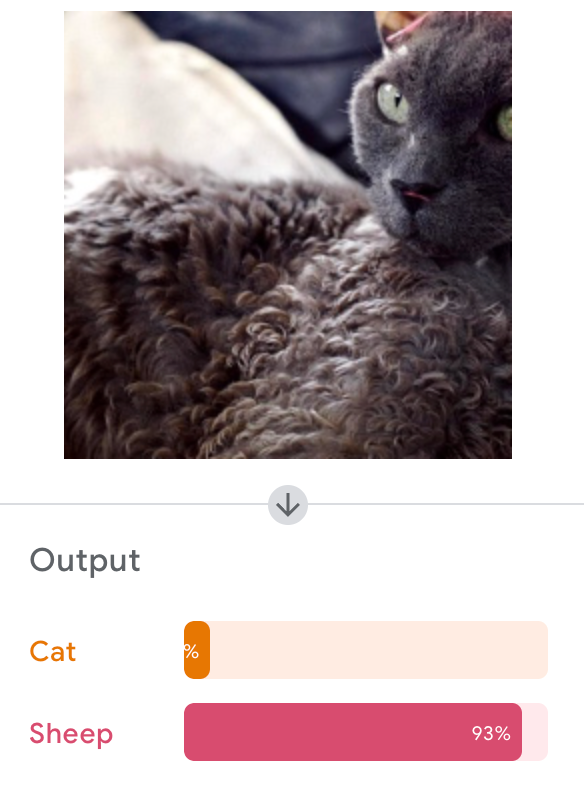
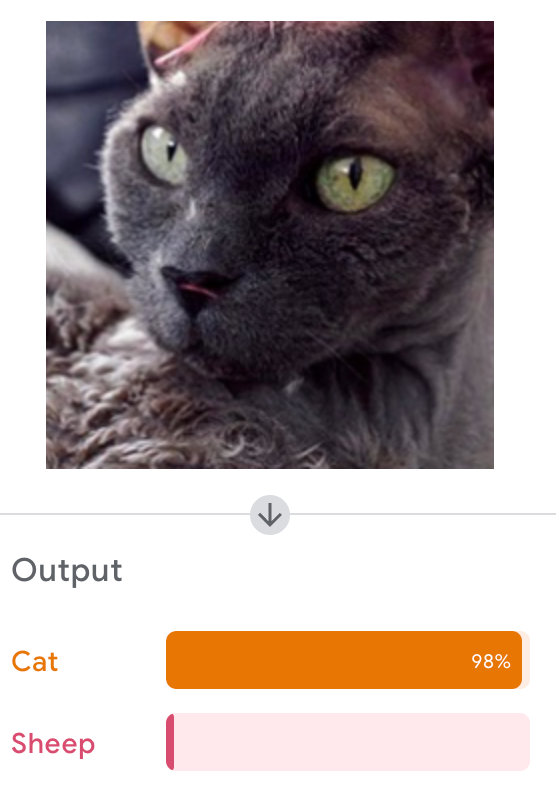
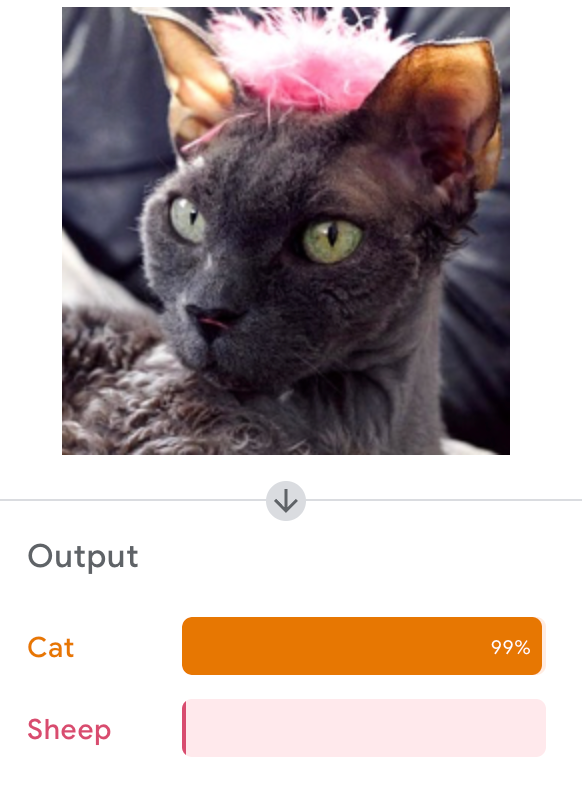
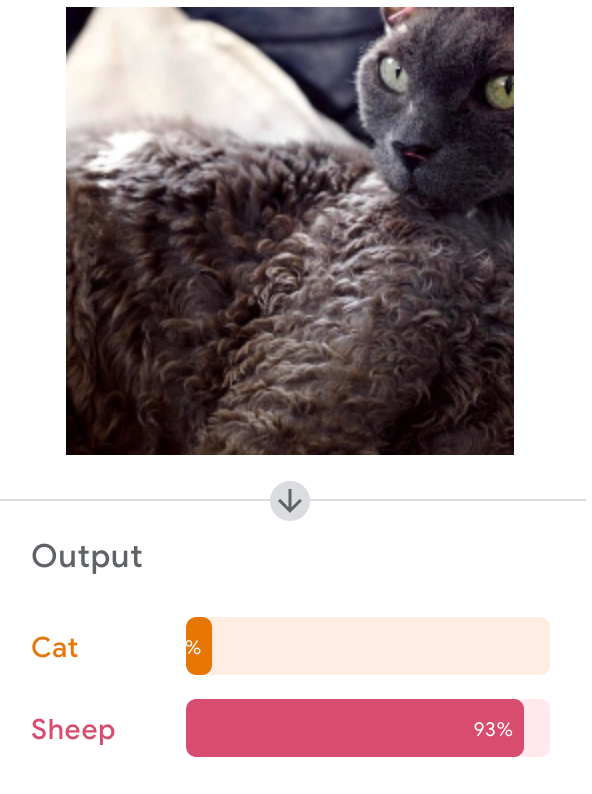
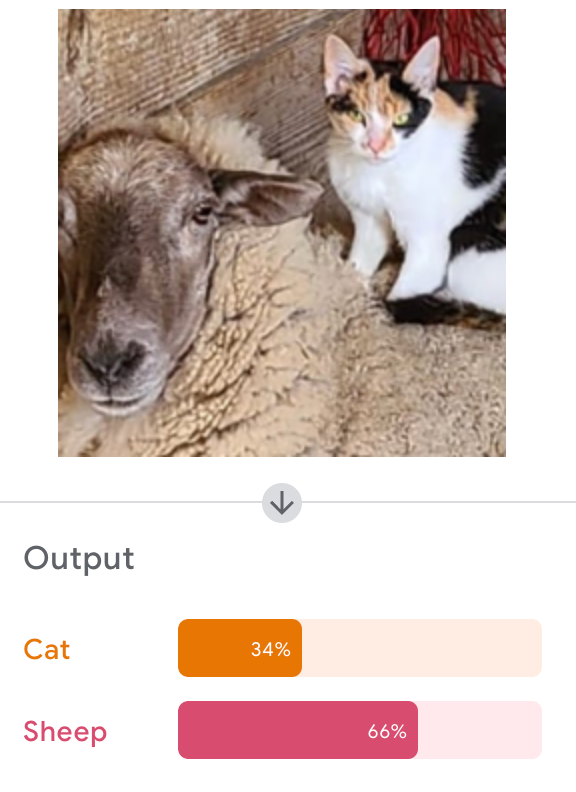

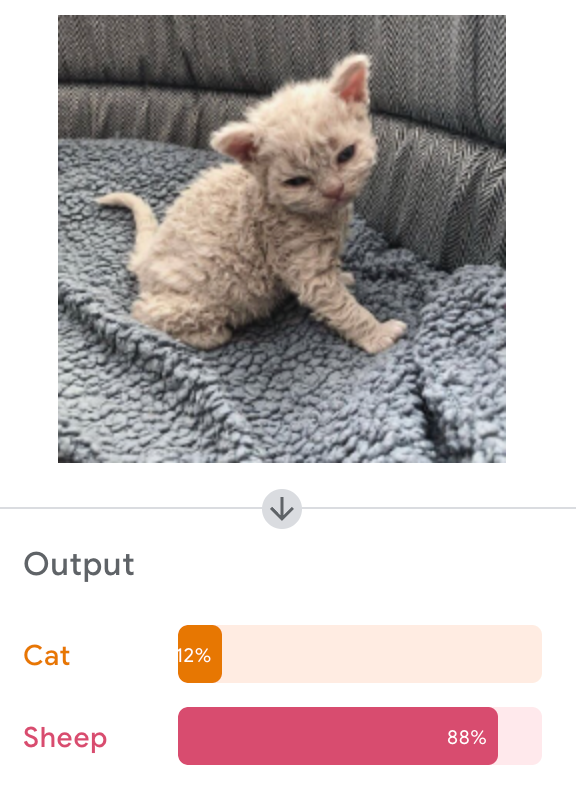
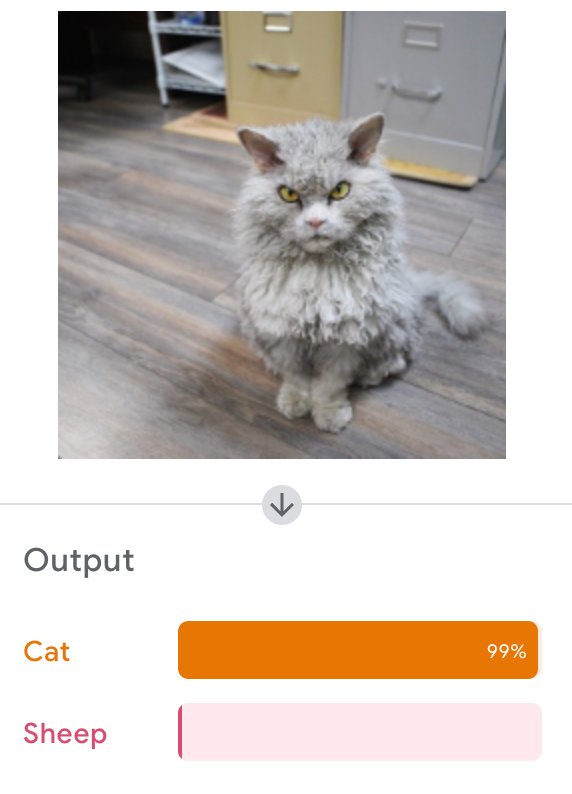

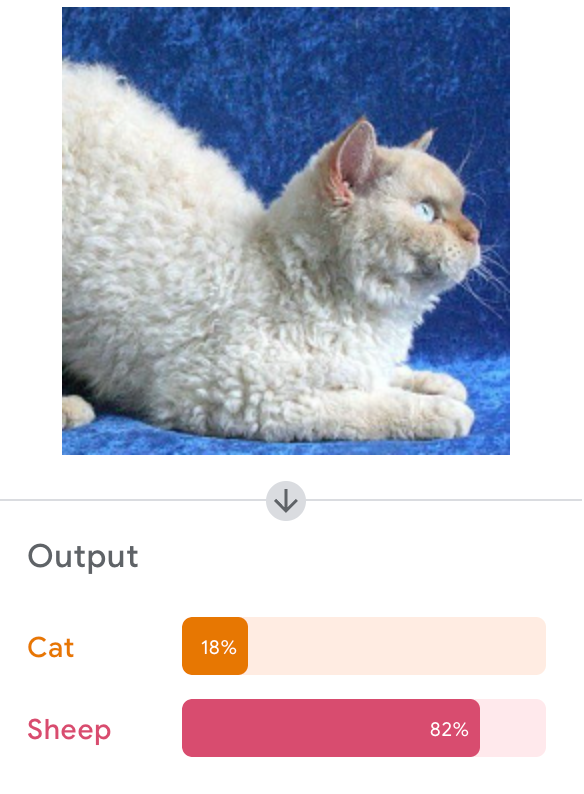
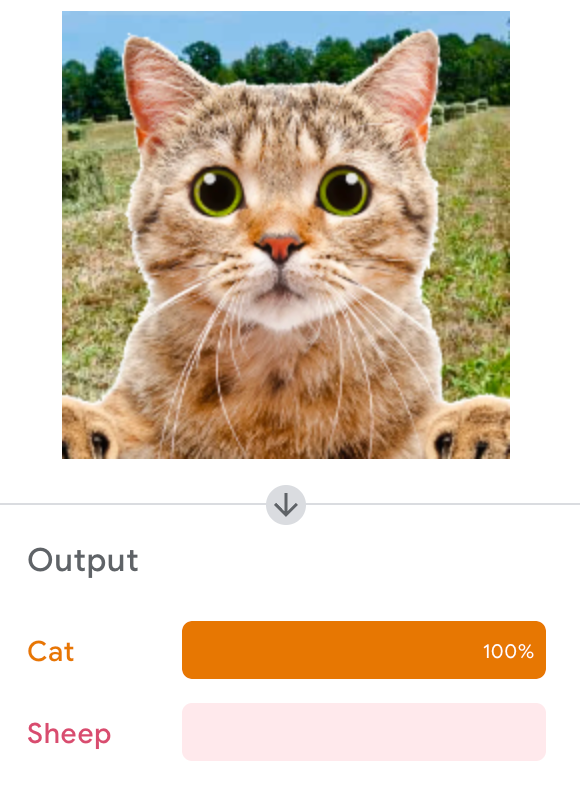
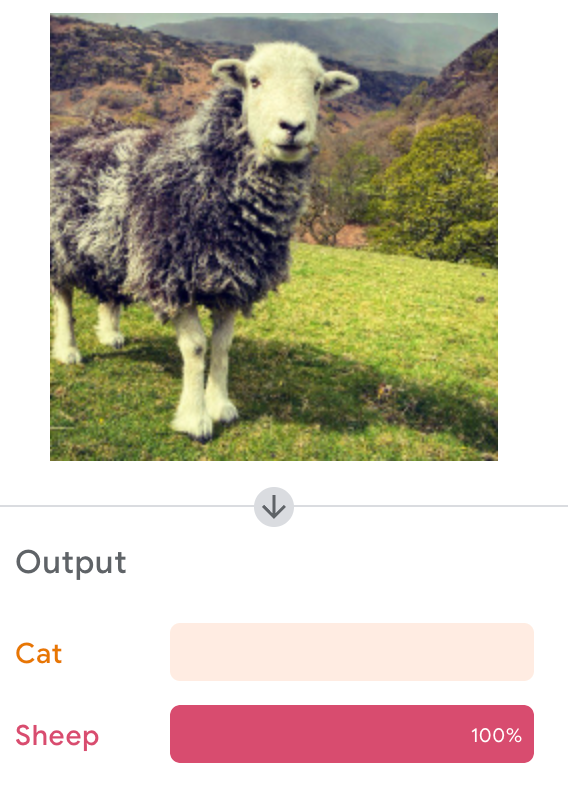
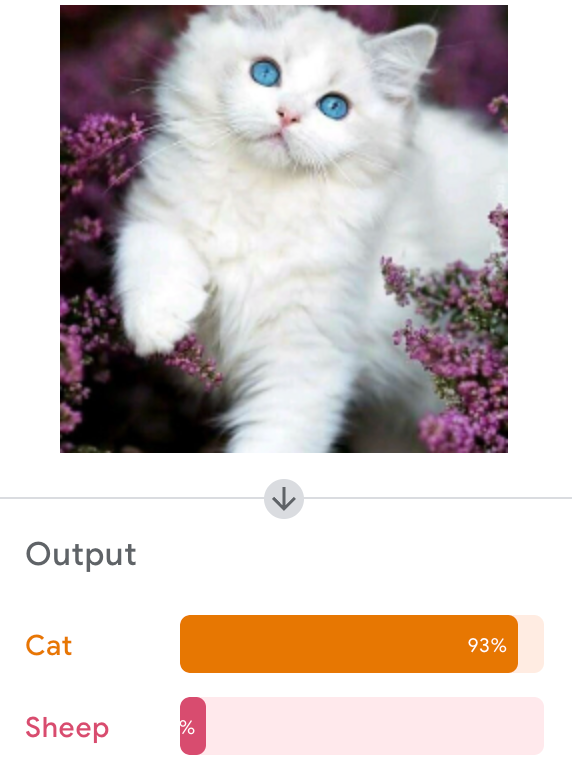

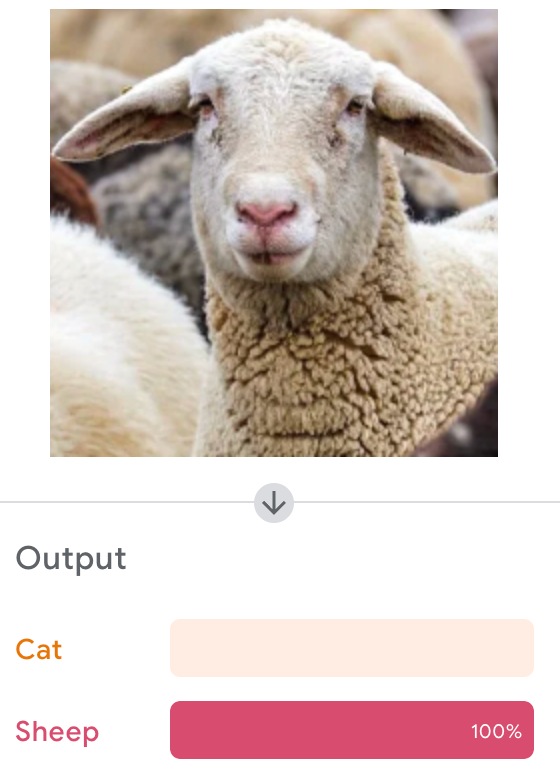
Let's Try It
Teachable Machine Workflow

Teachable Machine FILES

Teachable Machine FILES
Teachable Machine FILES
Teachable Machine in CodePen
<div>Teachable Machine Image Model</div>
<button type="button" onclick="init()">Start</button>
<div id="webcam-container"></div>
<div id="label-container"></div>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.3.1/dist/tf.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@teachablemachine/image@0.8/dist/teachablemachine-image.min.js"></script>
<script type="text/javascript">
// More API functions here:
// https://github.com/googlecreativelab/teachablemachine-community/tree/master/libraries/image
// the link to your model provided by Teachable Machine export panel
const URL = "https://teachablemachine.withgoogle.com/models/nUKbQ-rI4/";
let model, webcam, labelContainer, maxPredictions;
// Load the image model and setup the webcam
async function init() {
const modelURL = URL + "model.json";
const metadataURL = URL + "metadata.json";
// load the model and metadata
// Refer to tmImage.loadFromFiles() in the API to support files from a file picker
// or files from your local hard drive
// Note: the pose library adds "tmImage" object to your window (window.tmImage)
model = await tmImage.load(modelURL, metadataURL);
maxPredictions = model.getTotalClasses();
// Convenience function to setup a webcam
const flip = true; // whether to flip the webcam
webcam = new tmImage.Webcam(200, 200, flip); // width, height, flip
await webcam.setup(); // request access to the webcam
await webcam.play();
window.requestAnimationFrame(loop);
// append elements to the DOM
document.getElementById("webcam-container").appendChild(webcam.canvas);
labelContainer = document.getElementById("label-container");
for (let i = 0; i < maxPredictions; i++) { // and class labels
labelContainer.appendChild(document.createElement("div"));
}
}
async function loop() {
webcam.update(); // update the webcam frame
await predict();
window.requestAnimationFrame(loop);
}
// run the webcam image through the image model
async function predict() {
// predict can take in an image, video or canvas html element
const prediction = await model.predict(webcam.canvas);
for (let i = 0; i < maxPredictions; i++) {
const classPrediction =
prediction[i].className + ": " + prediction[i].probability.toFixed(2);
labelContainer.childNodes[i].innerHTML = classPrediction;
}
}
</script>Teachable Machine in CodePen
<div>Teachable Machine Image Model</div> <button type="button" onclick="init()">Start</button> <div id="webcam-container"></div> <div id="label-container"></div> <script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.3.1/dist/tf.min.js"></script> <script src="https://cdn.jsdelivr.net/npm/@teachablemachine/image@0.8/dist/teachablemachine-image.min.js"></script> <script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.3.1/dist/tf.min.js"></script> <script src="https://cdn.jsdelivr.net/npm/@teachablemachine/image@0.8/dist/teachablemachine-image.min.js"></script> <script type="text/javascript"> //JAVASCRIPT </script>
Teachable Machine in CodePen
HTML
<script type="text/javascript">
// More API functions here:
// https://github.com/googlecreativelab/teachablemachine-community/tree/master/libraries/image
// the link to your model provided by Teachable Machine export panel
const URL = "https://teachablemachine.withgoogle.com/models/nUKbQ-rI4/";
let model, webcam, labelContainer, maxPredictions;
// Load the image model and setup the webcam
async function init() {
const modelURL = URL + "model.json";
const metadataURL = URL + "metadata.json";
// load the model and metadata
// Refer to tmImage.loadFromFiles() in the API to support files from a file picker
// or files from your local hard drive
// Note: the pose library adds "tmImage" object to your window (window.tmImage)
model = await tmImage.load(modelURL, metadataURL);
maxPredictions = model.getTotalClasses();
// Convenience function to setup a webcam
const flip = true; // whether to flip the webcam
webcam = new tmImage.Webcam(200, 200, flip); // width, height, flip
await webcam.setup(); // request access to the webcam
await webcam.play();
window.requestAnimationFrame(loop);
// append elements to the DOM
document.getElementById("webcam-container").appendChild(webcam.canvas);
labelContainer = document.getElementById("label-container");
for (let i = 0; i < maxPredictions; i++) { // and class labels
labelContainer.appendChild(document.createElement("div"));
}
}
async function loop() {
webcam.update(); // update the webcam frame
await predict();
window.requestAnimationFrame(loop);
}
// run the webcam image through the image model
async function predict() {
// predict can take in an image, video or canvas html element
const prediction = await model.predict(webcam.canvas);
for (let i = 0; i < maxPredictions; i++) {
const classPrediction =
prediction[i].className + ": " + prediction[i].probability.toFixed(2);
labelContainer.childNodes[i].innerHTML = classPrediction;
}
}
</script>
END
How Do Machines See?
By Dan Ryan



