PySpark
Produtividade e poder de processamento
Quem?
github.com/felipecruz

@felipejcruz


Agenda
- Map-Reduce
- Pyspark
Maior oferta feita em uma semana na BOVESPA?
Motivação


highest_offer = max(offers)?
?
highest_offers_1 = max(offers_partition1)highest_offers_2 = max(offers_partition2)highest_offers_1 = max(offers_partition1)highest_offers_2 = max(offers_partition2)max(highest_offers_1, highest_offers_2)calma...
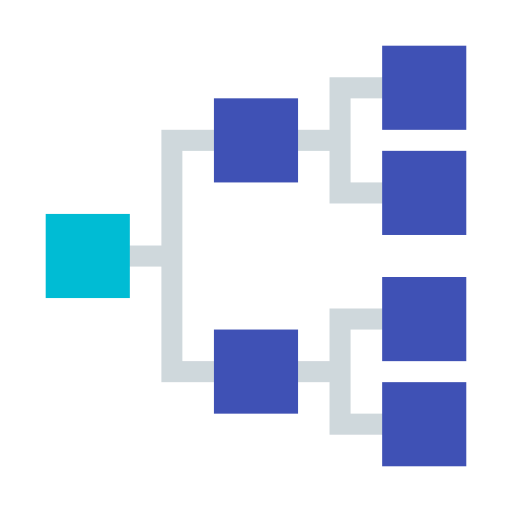
Map
Map
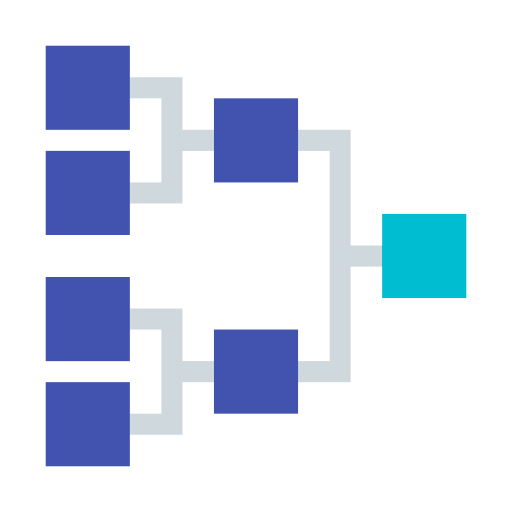
Reduce
Map-Reduce
não é divisão e conquista (que pode ser implementada com map-reduce)
Aplicações
- Filtragem
- Distintos
- Top K
- Por valor
- Sumarização
- Índice invertido
- Contagem de palavras
- Estruturação
- Ordenação
- Particionamento
- Embaralhamento
- Join
- Inner join
- Produto cartesiano
nosso exemplo K = 1
PySpark
Funcionalidades centrais
- Map-Reduce
-
RDD, DataFrames & SQL - MLlib
- Streaming
- GraphX
Map & Reduce
>>> prices = sc.textFile('s3n://prognoos-pyspark/*.gz') \
... .filter(lambda x: x.count(';') > 14) \
... .map(lambda x: [s.strip() for s in x.split(';')]) \
... .map(lambda x: (x[1], x[8], x[15]))
...
>>> prices.take(2)
[(u'ABEVA70', u'000000000000.350000', u'000000000000008300'),
(u'ABEVA70', u'000000000000.350000', u'000000000000007100')]
Map & Reduce
>>> prices = sc.textFile('ftp://*.gz') \
... .filter(lambda x: x.count(';') > 14) \
... .map(lambda x: [s.strip() for s in x.split(';')]) \
... .map(lambda x: (x[1], float(x[8]), x[15]))
...
>>> sum_all = prices.map(lambda x: x[2])\
... .reduce(lambda x, y: x + y)
...
>>> sum_all
1532623750.0
from datetime import datetime
strpt = lambda x: datetime.strptime(x, '%H:%M:%S.%f')
f = float
negs = sc.textFile('s3n://prognoos-pyspark/NEG/*.gz') \
.filter(lambda x: x.count(';') > 14) \
.map(lambda x: [s.strip() for s in x.split(';')]) \
.map(lambda x: (strpt(x[5]), 'NEG', x[1], f(x[3]), f(x[16]), x[17]))
buys = sc.textFile('s3n://prognoos-pyspark/CPA/*.gz') \
.filter(lambda x: x.count(';') > 14) \
.map(lambda x: [s.strip() for s in x.split(';')]) \
.map(lambda x: (strpt(x[6]), 'CPA', x[1], f(x[8]), x[15], None))
sell = sc.textFile('s3n://prognoos-pyspark/VDA/*.gz') \
.filter(lambda x: x.count(';') > 14) \
.map(lambda x: [s.strip() for s in x.split(';')]) \
.map(lambda x: (strpt(x[6]), 'VDA', x[1], f(x[8]), None, x[15]))
all_operations = negs.union(buys).union(sell)
total = all_operations.count() # total = 52980676
... nem tudo são flores
data = sc.parallelize(['aa', 'bb', 'ab', 'bc'])
def _filter(data):
sts = ['a', 'b']
rets = []
for st in sts:
rets.append((st,
data.filter(lambda x: x.startswith(st))))
return rets
rdds = _filter(data)
for st, rdd in rdds:
print((st, rdd.collect()))
# ('a', ['bb', 'bc'])
# ('b', ['bb', 'bc'])Python - Anti-pattern - não faça!!
DataFrames & SQL
DataFrame
A distributed collection of data grouped into named columns
http://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.DataFrame
events = negs.union(buys).union(sell).toDF()
# API de DataFrame
total = events.count()
# Salva pra uso posterior
events.write.save('s3n://prognoos/events/',
format='parquet',
mode='Overwrite')SparkSQL
http://spark.apache.org/docs/latest/api/python/pyspark.sql.html
>>> path = 's3n://prognoos-test/events'
>>> table_name = 'bovespa_events'
>>> events = sqlContext.read.parquet(path)
>>> events.registerTempTable(table_name)
>>> total_events = sqlContext.sql('''
select count(*) from bovespa_events
''')
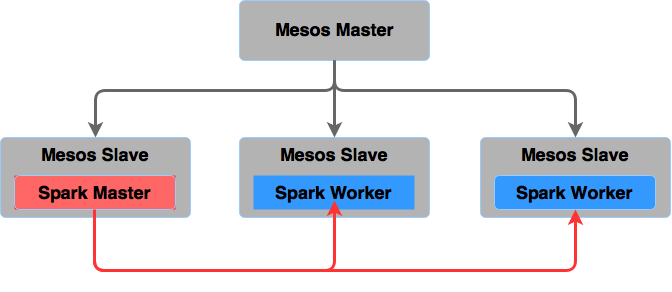
Spark em produção
- Standalone
- Hadoop/Yarn
- Mesos
Spark em produção

Dúvidas?
@felipejcruz
github.com/felipecruz
PySpark
By Felipe Cruz



