






















Fernando Sales
A lifelong learner working to positively impact and transform people for the better. Technology enthusiast with long experience in medical information processing and learning from multimodal data [signal, image and clinical data].
fernando.sales.ufpe@gmail.com
http://bit.ly/cadastroST903
A disciplina de bioestatística tem como objetivo capacitar os alunos a organizar e analisar os dados de uma determinada população e tirar conclusões de associações com bases nesses dados para que ele possa interpretar criticamente a literatura biomédica. Enfoca as medidas de tendência central e dispersão, noções de amostragem, testes de significância para medidas e proporções, correlação, regressão linear simples, medidas de morbimortalidade, padronização direta e indireta. Desenvolver o raciocínio lógico e auxiliar o processo decisório através dos cálculos estatísticos na interpretação de estudos translacionais na área de saúde.
|
CALLEGARI-JACQUES, Sidia M. Bioestatística: princípios e aplicações. Porto Alegre: ARTMED,2004.
VIEIRA, Sônia. Introdução à bioestatística. 3. ed. Rio de Janeiro: Elsevier, 2004.
BERQUÓ, Elza Salvatore; SOUZA, José Maria Pacheco de; GOTLIEB, Sabina Lea Davidson. Bioestatística. 2. ed. Ver. São Paulo: EPU, 2003.
JEKEL, James F.; KATZ, David L.; ELMORE, Joam G. Epidemiologia, bioestatística e medicina
preventiva. Porto Alegre: ARTMED, 2005.
SOARES, José Francisco; SIQUEIRA, Arminda Lucia. Introdução a estatística médica. 2. ed. Belo
Horizonte: COOPMED, 2002.
Estatística: O que é, para que serve, como funciona
por Charles Wheelan
Link: http://a.co/d/5c21rcZ
The Model Thinker: What You Need to Know to Make Data Work for You (English Edition)
por Scott E. Page
Link: http://a.co/d/gvY9mnf
Princípios de bioestatística
por Marcello Pagano
Link: http://a.co/d/7zi7NGy
Photo by Eduardo Rosas from Pexels
Photo by rawpixel.com from Pexels
Recomendo o curso gratuito do módulo "Introduction to R"
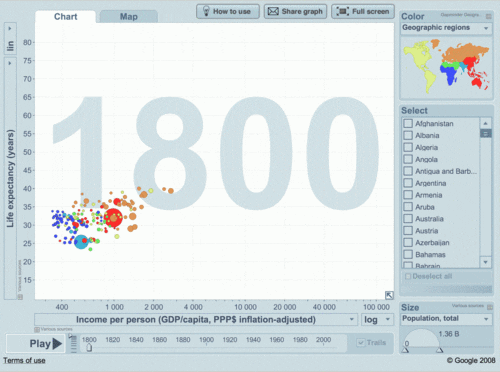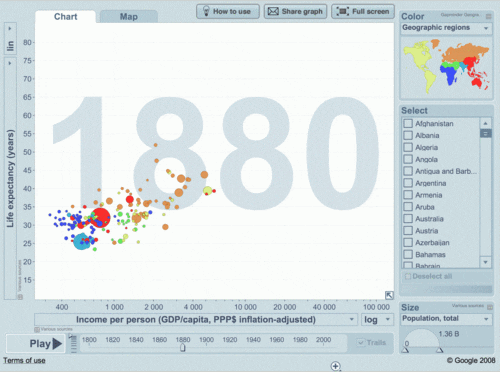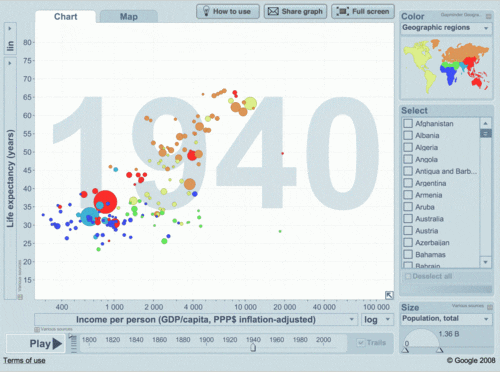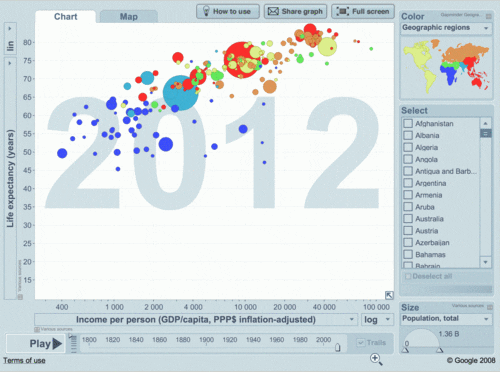
Objetivo: Representar os dados em tabelas e gráficos
1. Quadro x tabela?
2. O que deve ter numa tabela e num gráfico?
3. Como escolher o melhor tipo de gráfico para o tipo de dados que tenho?
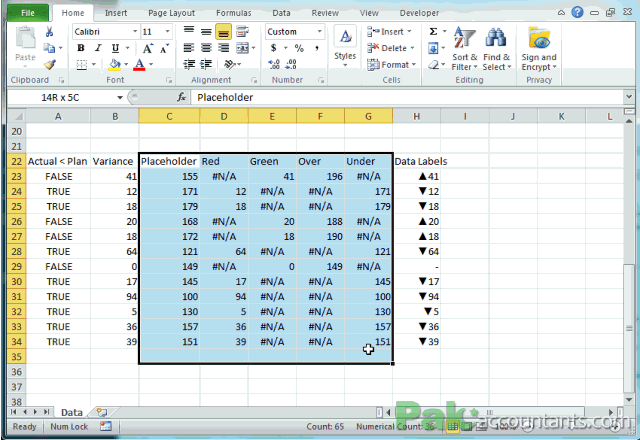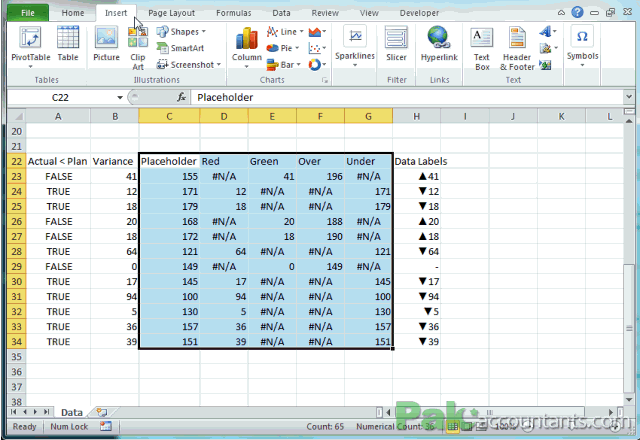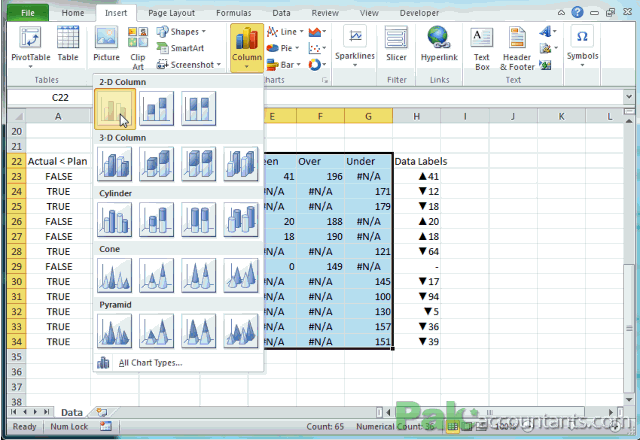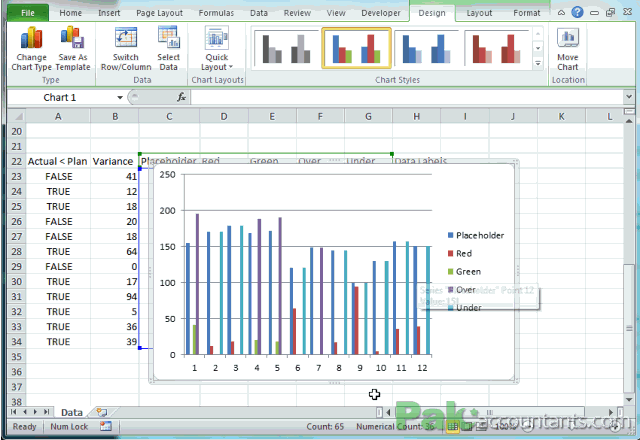
Sobre tabelas, gráficos, figuras, normas... um exemplo!
# loading MASS datasets
library(MASS)
# loading PIMA Women diabetes "training" dataset
data = Pima.tr
names(data) = names(Pima.tr)
# Primeiro, dê uma olhada na variável data na linha de comando
# Procure o comando para visualizar as primeiras linhas
#
5. Faça uma tabela mostrando os seguintes valores de cada atributo na amostra:
6. Refaça a tabela fazendo a divisão entre os grupos de diabéticas e não-diabéticas
# loading MASS datasets
library(MASS)
# loading PIMA Women diabetes "training" dataset
data = Pima.tr
names(data) = names(Pima.tr)
# Primeiro, dê uma olhada na variável data na linha de comando
# Procure o comando para visualizar as primeiras linhas
#
7. Suponha que você deseja analisar a distribuição de frequências dos atributos não analisados anteriormente e que tenham valores numéricos. Que tipo de transformação nos dados seria interessante proceder antes de realizar o gráfico? Justifique.
8. Refaça os histogramas mudando a largura dos bins. Comente o que muda na distribuição.
9. Refaça os histogramas anteriores segregando a amostra em dois grupos de acordo com a presença de diabetes.
# loading MASS datasets
library(MASS)
# loading PIMA Women diabetes "training" dataset
data = Pima.tr
names(data) = names(Pima.tr)
# Primeiro, dê uma olhada na variável data na linha de comando
# Procure o comando para visualizar as primeiras linhas
#
# loading MASS datasets
library(MASS)
# loading PIMA Women diabetes "training" dataset
data = Pima.tr
names(data) = names(Pima.tr)
# Primeiro, dê uma olhada na variável data na linha de comando
# Procure o comando para visualizar as primeiras linhas
#
# loading MASS datasets
library(MASS)
# loading PIMA Women diabetes "training" dataset
data = Pima.tr
names(data) = names(Pima.tr)
# Primeiro, dê uma olhada na variável data na linha de comando
# Procure o comando para visualizar as primeiras linhas
#
https://www.khanacademy.org/math/statistics-probability/probability-library/conditional-probability-independence/v/conditional-probability-tree-diagram-example
Uma empresa realiza um exame toxicológico no processo de seleção de seus novos funcionários. O teste específico que eles usam tem uma taxa de falsos positivos de 2% e uma taxa de falsos negativos de 1%. Supondo que 5% dos aplicantes usem drogas ilícitas e um deles seja selecionado aleatoriamente.
Dado que o teste seja positivo, qual é a probabilidade dele estar usando drogas?
Suppose there are two bowls of cookies. Bowl 1contains 30 vanilla cookies and 10 chocolate cookies. Bowl 2 contains 20 of each. Now suppose you choose one of the bowls at random and, without looking, select a cookie at random. The cookie is vanilla. What is the probability that it came from Bowl 1?
Cap. 1, Think Bayes, Allen Downey http://greenteapress.com/wp/think-bayes/
Suppose there are two bowls of cookies. Bowl 1contains 30 vanilla cookies and 10 chocolate cookies. Bowl 2 contains 20 of each. Now suppose you choose one of the bowls at random and, without looking, select a cookie at random. The cookie is vanilla. What is the probability that it came from Bowl 1?
Cap. 1, Think Bayes, Allen Downey http://greenteapress.com/wp/think-bayes/
Suppose there are two bowls of cookies. Bowl 1contains 30 vanilla cookies and 10 chocolate cookies. Bowl 2 contains 20 of each. Now suppose you choose one of the bowls at random and, without looking, select a cookie at random. The cookie is vanilla. What is the probability that it came from Bowl 1?
Cap. 1, Think Bayes, Allen Downey http://greenteapress.com/wp/think-bayes/
By Fernando Sales
Notas e material de apoio da disciplina "Bioestatística Aplicada" do Programa de Pós-Graduação em Saúde Translacional. Em constante atualização.



