
















































Vladislav Shpilevoy PRO
Backend C++ developer at VirtualMinds. Database C developer at Tarantool.
Lecture 5:
File system. Virtual FS in the kernel. Files, their types. I/O operations and their kernel schedulers. Page cache. Modes of work with file.
Version: 3
System programming
struct task_struct {
/* ... */
struct files_struct *files;
/* ... */
};
struct files_struct {
struct fdtable *fdt;
};
struct fdtable {
unsigned int max_fds;
struct file **fd;
};
struct file {
struct path f_path;
struct inode *f_inode;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
loff_t f_pos;
const struct cred *f_cred;
};Process keeps opened file descriptors
In a table of descriptors
The table is just an ordinary array
File descriptor in the kernel is a structure. In user space - number, an index in the descriptor array
task 1
task 2
struct file
stdout
fd1fd1
stdoutpos = 0
count = 1struct file
pos = 0
count = 1struct inode
struct file: stdout
pos = 0
count = 1struct file: stdout
pos = 0
count = 1struct inode
struct inode
Processes
Hardware
Time
File system
IPC
Network
Users
Data structures
Virtualization
HDD
SSD
DRAM
DRAM
DRAM
Volatile
Non-volatile
HDD
DRAM
Sort
Sort
Sort
DRAM 32 GB, 90 €
1 Gb - 2.81 €
HDD 2048 GB, 53 €
1 GB - 0.03 €
x94
SSD 1024 GB, 69 €
1 GB - 0.06 €
x46
Prices in 2023
What is it?
1. " / "
2. FAT, ext, NSF, USF, NTFS ...
3. Partition
Duties
/home/v.shpilevoy/Work/Repositories/tarantool
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
void (*destroy_inode)(struct inode *);
int (*write_inode) (struct inode *, struct writeback_control *wbc);
int (*drop_inode) (struct inode *);
void (*evict_inode) (struct inode *);
int (*sync_fs)(struct super_block *sb, int wait);
int (*freeze_fs) (struct super_block *);
int (*unfreeze_fs) (struct super_block *);
int (*statfs) (struct dentry *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*umount_begin) (struct super_block *);
};struct super_operations ext2_sops = {
.alloc_inode = ext2_alloc_inode,
.destroy_inode = ext2_destroy_inode,
.write_inode = ext2_write_inode,
.evict_inode = ext2_evict_inode,
.put_super = ext2_put_super,
.sync_fs = ext2_sync_fs,
.freeze_fs = ext2_freeze,
.unfreeze_fs = ext2_unfreeze,
.remount_fs = ext2_remount,
};MOUNT(8) BSD System Manager's Manual MOUNT(8)
NAME
mount -- mount file systems
SYNOPSIS
mount [-adfruvw] [-t lfs | external_type]
mount [-dfruvw] special | mount_point
mount [-dfruvw] [-o options] [-t lfs | external_type] special mount_pointFS implementation - software, not hardware
ext, ext2, ext3, ext4, NTFS, FAT, NFS, tmpfs, ramfs, procfs, sysfs
NAME
SSHFS - filesystem client based on ssh
SYNOPSIS
mounting
sshfs [user@]host:[dir] mountpoint [options]
unmounting
umount mountpoint$> sudo mkdir /mnt/remote_dir
$> sudo sshfs username@xxx.xxx.xxx.xxx:/some/path/on/remote/serv \
/mnt/remote_dir
$> cd /mnt/remote_dir
$> # you are on remote serverPrepare a folder for mounting in
Mount a remote FS as a local folder
Can be used as a normal folder, but under the hood it is ssh
File System In USEr Space
$> cat /proc/filesystems
sysfs
rootfs
ramfs
proc
tmpfs
securityfs
pipefs
ext3
ext2
ext4
vfat
fuse
...FS is software, does not depend on hardware
Hardware
?
What is here?
What is between FS and hardware?
Driver
1 point
Char
device
Block
device
Network
device
Sequential access
Arbitrary access
Combined access
Controller
Reading heads
Magnetic disks
HDD - Hard Disk Drive
Glass/plastic/metall
Cobalt/steel
Cobalt/steel
Steel oxide
Cobalt
0
1
1
0
xx nanometers
Write
Read
CHS - Cylinder - Head - Sector
Sectors
1
2
3
Cylinder
Sectors
Cylinder
Heads
Floor - Ring - Segment
LBA - Logical Block Addressing
0
N
An abstraction above any addressing. Is organised as a contiguous byte block array.
CHS to LBA translation:
Revolution speed - rpm, Revolutions Per Minute:
>= 4 ms for a full revolution, 2 ms in average
Sequential access - less of the missing rotations
vs
4 rotations
1 rotation
"Head crash"
Fall
Magnet
SSD - Solid State Drive
Flash memory cells
Controller
DRAM
Dielectric
Conductor
"Trap" for electrons
?
Dielectric
Conductor
Control Gate
Floating Gate
Source
Drain
Dielectric
Conductor
Control Gate
Floating Gate
Source
Drain
How to evict the electrons?
2 points
Dielectric
Conductor
Dielectric
Conductor
From this point of view total charge is 0 - no current
Charge leaking
LBA addressing
Reading by pages of 512 - 8192 bytes
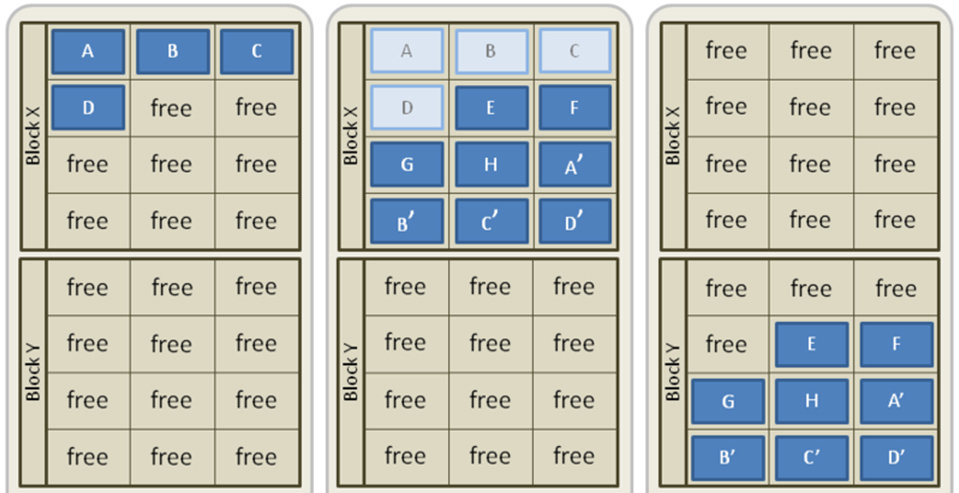
1. Block x has ABCD pages occupied.
2. New pages EFGH are written, pages ABCD are updated.
3. So as to write into ABCD again it is necessary to erase the whole block.
This is a common problem of all append-only objects
SSD
LSM-tree
SSD tasks:
Speed:
How to find what is the file system used on a device right now?
In the beginning of each storage device there is a special byte block storing meta information about a file system and its "magic number".
1 point
MBR - Master Boot Record
Bootstrap code
Partition record 1
Partition record 2
Partition record 3
Partition record 4
512 bytes
Storage device
MBR
Part. 1
Part. 2
Part. 3
Part. 4
struct part_record {
lba_t start;
lba_t end;
/** Partition type. */
int part_type;
/** Filesystem header. */
struct fs_header fs_header;
};Part. i - 1
Part. i
Part. i + 1
Filesystem header
OS bootstrap code
Data block
1
... data blocks ...
Data block
N
Superblock
struct fs_super_block {
int32_t block_count;
int32_t free_block_count;
int32_t block_size;
int32_t flags;
int32_t mount_time;
/* ... */
int16_t magic;
/* ... */
};#define RAMFS_MAGIC 0x858458f6
#define TMPFS_MAGIC 0x01021994
#define EXT2_SUPER_MAGIC 0xEF53
#define EXT3_SUPER_MAGIC 0xEF53
#define EXT4_SUPER_MAGIC 0xEF53
#define MINIX_SUPER_MAGIC 0x137F
#define MSDOS_SUPER_MAGIC 0x4d44
#define NFS_SUPER_MAGIC 0x6969FAT - File Allocation Table
File - forward list of blocks
HDD
/**
* Linux kernel,
* fs/fat/fat.h
* 30.09.2018.
*/
struct fat_entry {
int entry;
union {
u8 *ent12_p[2];
__le16 *ent16_p;
__le32 *ent32_p;
} u;
int nr_bhs;
struct buffer_head *bhs[2];
struct inode *fat_inode;
};/** uapi/linux/msdos_fs.h */
struct msdos_dir_entry {
__u8 name[MSDOS_NAME];/* name and extension */
__u8 attr; /* attribute bits */
__u8 lcase; /* Case for base and extension */
__u8 ctime_cs; /* Creation time, centiseconds (0-199) */
__le16 ctime; /* Creation time */
__le16 cdate; /* Creation date */
__le16 adate; /* Last access date */
__le16 starthi; /* High 16 bits of cluster in FAT32 */
__le16 time,date,start;/* time, date and first cluster */
__le32 size; /* file size (in bytes) */
};Kernel structure for a file chain
Kernel structure for a folder
Ext2 - 2nd Extended filesystem
Andrew Tanenbaum - author of Minix and minixfs - an ancestor of ext
ext inode
name;
rights;
time;
-------
b1_addr;
b2_addr;
b3_addr;
...
b12_addr;
-------
ind1_addr;
ind2_addr;
ind3_addr;
block level 1
b1_addr;
b2_addr;
b3_addr;
...
bN_addr;block level 2
ind1_1_addr;
ind1_2_addr;
...
ind1_N_addr;block level 1
block level 1
block level 1
...
block level 3
ind2_1_addr;
ind2_2_addr;
...
ind2_N_addr;block level 2
block level 2
block level 2
...
Ext2 superblock
Block Group 1
Block Group
2
...
Block Group
N
Ext2 superblock
Block Bitmask
Inode Bitmask
Inode Table
... data blocks ...
Ext2 structure
Block Group structure
Bitmask - if bit i = 0, then i-th object (block/inode) is free
Array of struct ext2_inode
/**
* Linux kernel,
* fs/ext2/ext2.h
* 30.09.2018
* 53 lines.
*/
struct ext2_inode {
__le16 i_mode;
__le16 i_uid;
__le32 i_size;
__le32 i_atime;
__le16 i_links_count;
__le32 i_blocks;
__le32 i_flags;
__le32 i_block[15];
/* ... */
};
struct ext2_group_desc
{
__le32 bg_block_bitmap;
__le32 bg_inode_bitmap;
__le32 bg_inode_table;
__le16 bg_free_blocks_count;
__le16 bg_free_inodes_count;
__le16 bg_used_dirs_count;
__le16 bg_pad;
__le32 bg_reserved[3];
};#define EXT2_MIN_BLOCK_SIZE 1024
#define EXT2_MAX_BLOCK_SIZE 4096
#define EXT2_NDIR_BLOCKS 12
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1)
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1)
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)Numbers of 12 data blocks, and 3 indexes for indirect addressing
Numbers of blocks storing bitmasks, inode table
Block sizes, indirect table sizes
/**
* Linux kernel.
* include/linux/fs.h
* 30.09.2018.
* 33 lines.
*/
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
void (*destroy_inode)(struct inode *);
void (*dirty_inode) (struct inode *, int flags);
int (*write_inode) (struct inode *, struct writeback_control *wbc);
int (*drop_inode) (struct inode *);
void (*evict_inode) (struct inode *);
void (*put_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
int (*freeze_super) (struct super_block *);
int (*freeze_fs) (struct super_block *);
int (*thaw_super) (struct super_block *);
int (*unfreeze_fs) (struct super_block *);
int (*statfs) (struct dentry *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct dentry *);
int (*show_devname)(struct seq_file *, struct dentry *);
int (*show_path)(struct seq_file *, struct dentry *);
int (*show_stats)(struct seq_file *, struct dentry *);
long (*free_cached_objects)(struct super_block *,
struct shrink_control *);
};write(fd, buf, size);User space
Kernel space
file = find_file(fd);
file->write(buf, size);file->inode->write_inode(buf, size);ext2_write_inode(buf, size);fat_write_inode(buf, size);bdev_write_page(page);Hardware
#include <stdio.h>
#include <dirent.h>
int main()
{
DIR *dir = opendir(".");
struct dirent *dirent = readdir(dir);
while (dirent != NULL) {
printf("name = %s, inode number = "\
"%d, type = %d\n",
dirent->d_name,
(int) dirent->d_ino,
(int) dirent->d_type);
dirent = readdir(dir);
}
closedir(dir);
return 0;
}$> gcc 1_dirent.c
$> ./a.out
name = ., inode number = 19537325,
type = 4
name = .., inode number = 18730940,
type = 4
name = 2_fstat.c, inode number =
19537344, type = 8
name = a.out, inode number = 19641892,
type = 8
name = 1_dirent.c, inode number =
19537330, type = 8#include <stdio.h>
#include <sys/stat.h>
#include <unistd.h>
int main(int argc, char **argv) {
struct stat st;
stat(argv[1], &st);
printf("inode = %d, protection = %d, links = "\
"%d, uid = %u, size = %d, blocks = "\
"%d\n", (int)st.st_ino, (int)st.st_mode,
(int)st.st_nlink, (unsigned)st.st_uid,
(int)st.st_size, (int)st.st_blocks);
if ((st.st_mode & S_IFDIR) == S_IFDIR)
printf("the file is directory\n");
if ((st.st_mode & S_IFREG) == S_IFREG)
printf("the file is regular\n");
if ((st.st_mode & S_IFLNK) == S_IFLNK)
printf("the file is symbolic link\n");
if ((st.st_mode & S_IRUSR) == S_IRUSR)
printf("can read it\n");
if ((st.st_mode & S_IWUSR) == S_IWUSR)
printf("can write it\n");
if ((st.st_mode & S_IXUSR) == S_IXUSR)
printf("can execute it\n");
printf("my uid: %d\n", (int)getuid());
return 0;
}$> gcc 2_fstat.c
$> ./a.out a.out
inode = 19642912, protection = 33261,
links = 1, uid = 502, size = 8536,
blocks = 24
the file is regular
can read it
can write it
can execute it
my uid: 502$> ./a.out .
inode = 19537325, protection = 16877,
links = 5, uid = 502, size = 160,
blocks = 0
the file is directory
can read it
can write it
can execute it
my uid: 502$> ./a.out 2_fstat.c
inode = 19537344, protection = 33188,
links = 1, uid = 502, size = 838,
blocks = 8
the file is regular
can read it
can write it
my uid: 502Disk operation batching is the main job of all IO schedulers
read_blocks(1);read_blocks(2);I/O scheduler
read_blocks(1, 2);split_blocks(res);res1res2I/O scheduler
write_blocks(3, 1, 4, 2);write_blocks(1, 2, 3, 4);Merge
Sort
+
1. Find an adjacent request. If found - merge.
...
...
5-10
10-15
2. Find a place between requests. If found - put here.
...
...
5-8
10-15
1-3
3. Otherwise go to the end.
...
100-120
10-15
* if there is a too old request in the queue, all new ones go to the end
Summary:
Write starvation - a phenomenon when reads are more demanding to latency but too much preference to reads will starve out writes - they will be executed too rarely.
Merge/sort queue
Read FIFO queue
Write FIFO queue
req_t pick_next() {
req_t ro = next_ro();
req_t rw = next_rw();
if (ro.deadline <= curr_time ||
rw.deadline <= curr_time) {
if (ro.deadline < rw.deadline)
return ro;
return rw;
}
return next_merge_sort();
}+
Put into 2 from 3 queues. Reads have deadline x10 sooner.
How does Deadline I/O Scheduler solves the write starvation problem?
Number of reads executed in a row is limited.
1 point
Like Deadline, but after a read the scheduler waits several ms just in case more adjacent reads would appear
/* ... */
while (read(fd, buf, size) != 0) {
/* do something ... */
}
/* ... */A typical reader - sequential blocking reads
...
CFQ - Completely Fair Queuing
Merge/sort queue
Deadline queue
Task queues
Task queues
Task queues
Task queues
...
time slice
time slice
time slice
time slice
Almost like CFS for tasks
BFQ - Budget Fair Queuing. Weighted CFQ with priorities. Even closer to CFS.
Noop. The simplest - only merge. No sorting, fairness, etc. One queue and merging.
CFQ was default at the moment when that was written. Good for interactive applications.
Linus Elevator - the best bandwidth, but super unfair.
$> # Template:
$> # cat /sys/block/{device_name}/queue/scheduler
$>
$> cat /sys/block/sda/queue/scheduler
noop deadline [cfq]How to get the current scheduler per device:
How to speed up the access even more?
Cache
1 point
Tree of cached blocks.
read(fd, buf, size);If found - return immediately.
Put into the cache.
Cache will be stored in RAM and CPU caches, access for nanoseconds.
no-write
write-back
write-through
Invalidate the cache and write onto disk right now.
Update cache. Dump to disk when will be evicted from the cache.
Write to cache and to disk right now.
+ eviction from the cache by LRU, classic
int
printf(const char * restrict format, ...);
int
fprintf(FILE * restrict stream, const char * restrict format, ...);
int
fputs(const char *restrict s, FILE *restrict stream);
int
fflush(FILE *stream);This is in userspace only. In the kernel everything is buffered and cached by default.
File systems provide access by file and dir names, define the storage format and allowed ops, their structure might be optimized for specific devices.
HDD disks are slow, but very cheap. Sequential access (reads, writes) is much faster than random access. Milliseconds.
SSD disks are fast, but costly. Random access is fast, but sequential is still faster. Lifetime is limited. Microseconds.
Data is not flushed to disk right away. It goes through IO schedulers.
Page cache in the kernel can speed up writes (by holding them in memory) and repetitive reads.
File system
There is an API similar to open/close/read/write. You need to implement a file system in the main memory implementing this interface.
No directories, with a ready template, format is similar to FAT.
Points: 15 - 25.
Deadline: 3 weeks.
Penalty: -1 for each day after deadline, max -10
Publish your solution on Github and give me the link. Assessment: any way you want - messengers, calls, emails.
enum ufs_error_code
ufs_errno();
int
ufs_open(const char *filename, int flags);
ssize_t
ufs_write(int fd, const char *buf, size_t size);
ssize_t
ufs_read(int fd, char *buf, size_t size);
int
ufs_close(int fd);
int
ufs_delete(const char *filename);The interface
struct block {
/** Block memory. */
char *memory;
/** How many bytes are occupied. */
int occupied;
/** Next block in the file. */
struct block *next;
/** Previous block in the file. */
struct block *prev;
/* PUT HERE OTHER MEMBERS */
};
struct file {
/** Double-linked list of file blocks. */
struct block *block_list;
/**
* Last block in the list above for fast access to the end
* of file.
*/
struct block *last_block;
/** How many file descriptors are opened on the file. */
int refs;
/** File name. */
const char *name;
/** Files are stored in a double-linked list. */
struct file *next;
struct file *prev;
/* PUT HERE OTHER MEMBERS */
};Structures, describing a file
Lectures: slides.com/gerold103/decks/sysprog_eng
Next time:
Press on the heart, if like the lecture
Threads. Difference from processes. Atomic operations. Synchronisation. Attributes. Multithreaded processes specifics. Kernel representation.
By Vladislav Shpilevoy
Storage devices. File system and the kernel. Virtual file system. Files and their types: block, char, network. Representation in the kernel: inode. Sectors. IO schedulers - elevators: Linus, Deadline, Anticipatory, CFQ, Noop. Page cache. Page nowrite/writethrough/writeback. File work modes - buffered, unbuffered, line.




