Char & String
黃祥陞 @Sprout 2024 C/C++語法班
Modified from @Sprout 2023
在這堂課,你會學到...
字元、字元陣列的概念與用法
C-style 字串的相關函式
在以後,你會學到...
C++ 的 string 的用法
在上堂課,你已經學到...
一維陣列的概念與用法
字元
字元的種類
數字:'0'、'1'、'2'、'3'...
字母:'a'、'B'、'c'、'D'...
簡單符號:','、'.'、'@'、'!'、';'...
其他:'\n'、'\t'、'\''、'\\'...
(複習:跳脫字元)
char a;
a = 'x';char b = 'A';字元的內容,要用' '括起來。
宣告與賦值
來猜猜以下這些程式的輸出?
#include <iostream>
int main() {
char a = 'A';
std::cout << a;
}#include <iostream>
int main() {
char a = 'A';
std::cout << 'a';
}#include <iostream>
int main() {
char a = 'A';
std::cout << "a";
}#include <iostream>
int main() {
char a = 65;
std::cout << a;
}公佈答案:
#include <iostream>
int main() {
char a = 'A';
std::cout << a;
}#include <iostream>
int main() {
char a = 'A';
std::cout << 'a';
}#include <iostream>
int main() {
char a = 'A';
std::cout << "a";
}#include <iostream>
int main() {
char a = 65;
std::cout << a;
}aAaA右下角那個是發生什麼事?
其實字元同時就是整數(雖然字元只有 1 個 byte)。
每個字元都可以用整數來寫。我們稱之為 ASCII Code。
#include <iostream>
int main() {
if ('A' == 65)
std::cout << "\'A\' == 65" << std::endl;
else
std::cout << "\'A\' != 65" << std::endl;
}'A' == 65ASCII Code
這裡附上一個小程式給大家玩玩。
#include <iostream>
int main() {
std::cout << 'A' << " is " << (int)'A' << std::endl;
std::cout << 'a' << " is " << (int)'a' << std::endl;
std::cout << '0' << " is " << (int)'0' << std::endl;
std::cout << '.' << " is " << (int)'.' << std::endl;
}A is 65
a is 97
0 is 48
. is 46大家應該有注意到:'0' != 0。
(等等會再細講關於 0 的部分)
既然剛剛說字元也是整數...那當然也可以用來做運算!
#include <iostream>
int main() {
char b = 'b';
std::cout << (char)(b ) << " is " << (int)(b ) << std::endl;
std::cout << (char)(b - 1) << " is " << (int)(b - 1) << std::endl;
std::cout << (char)(b + 1) << " is " << (int)(b + 1) << std::endl;
}
b=98
a=97
c=99字元的運算
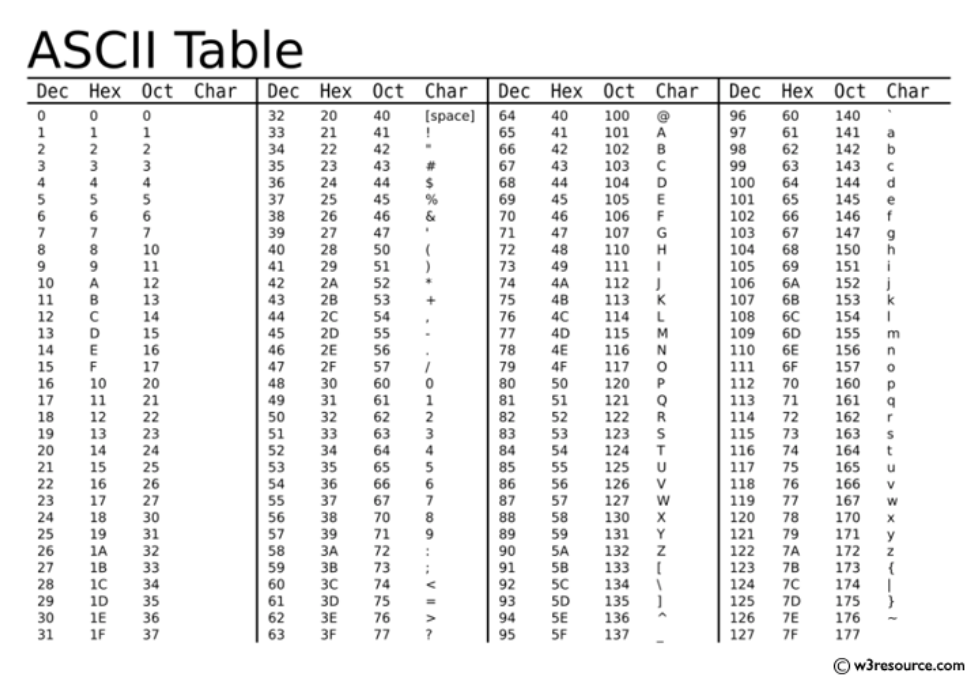
ASCII Table
關於 ASCII Table
其實就是字元與整數的對應表(不用特別記)。
幾個可以知道的:
'A' == 65, 'B' == 66, ... 依此類推
'a' == 97, 'b' == 98, ... 依此類推
'0' == 48, '1' == 49, ... 依此類推
'\0' == 0。等等會介紹 '\0' 的功能。
C-style 字串
字元陣列的用法
複習:陣列的初始化

字元陣列的初始化
基本做法:
char s[7] = {'s', 'p', 'r', 'o', 'u', 't'};比較快的做法:
char s[7] = "sprout";大家可以發現:字串是用 " " 來包。
字元是用 ' ' 來包。
關於 '\0'
char s[7] = {'s', 'p', 'r', 'o', 'u', 't'};char s[7] = "sprout";
'\0'(也就是正整數的 0),代表的是字串的結束!
宣告字元陣列時,要預留 '\0' 的空間!
字串的輸出
#include <iostream>
int main() {
char s[7] = {'s', 'p', 'r', 'o', 'u', 't', '\0'};
std::cout << s << std::endl;
}
sprout
'\0' 很重要!!在 cout 字串的時候,
程式會一直印,直到遇到 '\0' 才停止。
給大家猜猜看,以下幾個程式會輸出什麼?
#include <iostream>
int main() {
char s[7] = {'s', 'p', 'r', '\0', 'u', 't', '\0'};
std::cout << s << std::endl;
}
#include <iostream>
int main() {
char s[7] = {'s', 'p', 'r', 'o', 'u', 't'};
std::cout << s << std::endl;
}
#include <iostream>
int main() {
char s[6] = {'s', 'p', 'r', 'o', 'u', 't'};
std::cout << s << std::endl;
}
答案:
#include <iostream>
int main() {
char s[7] = {'s', 'p', 'r', '\0', 'u', 't', '\0'};
std::cout << s << std::endl;
}
#include <iostream>
int main() {
char s[7] = {'s', 'p', 'r', 'o', 'u', 't'};
std::cout << s << std::endl;
}
#include <iostream>
int main() {
char s[6] = {'s', 'p', 'r', 'o', 'u', 't'};
std::cout << s << std::endl;
}
spr
sprout
我也不知道
Tips
經過剛剛的實驗可以知道,'\0' 非常重要!
所以,開字元陣列的時候,一定要預留 '\0' 的位置,以避免各種奇怪的問題。
#include <iostream>
int main() {
char s[7] = {'s', 'p', 'r', 'o', 'u', 't'};
std::cout << s << std::endl;
}
字串的輸入
字串的輸入是以 ' ' 或 '\t' 或 '\n' 為分界。
#include <iostream>
int main() {
char s[20];
std::cin >> s;
std::cout << s << std::endl;
}以上圖為例。如果輸入是 Hello World。
那輸出就是 Hello。
字串的輸入
#include <iostream>
int main() {
char s[20], t[20];
std::cin >> s >> t;
std::cout << s << std::endl;
std::cout << t << std::endl;
}
再一例。如果輸入是 Hello World。
那輸出就是 Hello
World
字串的輸入
補充:如果我就是希望把 "Hello World" 整個輸進去:
#include <iostream>
int main() {
char s[20];
std::cin.getline(s, 20);
std::cout << s << std::endl;
}以上圖為例。如果輸入是 Hello World。
那輸出就是 Hello World。
小練習
參考架構
#include <iostream>
int main() {
// 宣告字串
// 輸入字串
// for (int i=0 ; 字串還沒結束 ; i++){
// 調整字串的第 i 個字母
// }
// std::cout << 字串 << std::endl;
}
參考提示
問:我要怎麼知道我的迴圈要執行到哪?
答:看到 '\0' 就表示字串結束了。
問:要怎麼把字母往後平移 3 個字母?
答:利用 ASCII Code。
這題最後要換行。
參考答案
#include <iostream>
int main() {
char s[505];
std::cin >> s;
for (int i = 0; s[i] != '\0'; i++) {
if (s[i] >= 'a' && s[i] <= 'w')
s[i] = s[i] + 3;
else
s[i] = s[i] + 3 - 26;
}
std::cout << s << std::endl;
}
字元陣列相關函式
#include <cstring>
接下來要介紹幾個字元陣列的小工具(相關函式)
學會的話可以幫你省很多時間。
重要:記得 #include <cstring>。
否則在某些地方(如neoj)會 compile error。
strlen(str)
求出字串長度
strlen(str)。
str 是你想求長度的字串。
#include <iostream>
#include <cstring>
int main() {
char s[20] = "Sprout";
std::cout << strlen(s) << std::endl;
}
6
用法
Q:如果不用 strlen 的話,我們都怎麼算字串長度?
A:從字串開頭開始數,直到遇到 '\0'。
#include <iostream>
int main() {
char s[20] = "Sprout";
int count = 0;
for (int i = 0 ; s[i] != '\0' ; i++) {
count ++;
}
std::cout << count << std::endl;
}
6
實際上,strlen 本身就是這樣運算的。所以...
小提示
不要把 strlen 放進 for 迴圈裡面!
// This is extremely bad
for (int i = 0 ; i < strlen(s) ; i++) {
// do something
}用下面這種寫法比較省時間。(想想看為什麼?)
// This is good
int length = strlen(s);
for (int i = 0 ; i < length ; i++) {
// do something
}strcmp(str1, str2)
比較字串的字典序
用法
strcmp(str1 ,str2)。
str1 和 str2 是你想比較的字串。
回傳值的意思:
0:表示 str1 和 str2 內容一模一樣。
>0:表示 str1 的字典序 ASCII 比 str2 大。
<0:表示 str1 的字典序 ASCII 比 str2 小。
舉例
#include <iostream>
#include <cstring>
int main() {
char a[20] = "abcde";
char b[20] = "bcdef";
char B[20] = "bcdef";
std::cout << strcmp(a, b) << std::endl;
std::cout << strcmp(b, a) << std::endl;
std::cout << strcmp(b, B) << std::endl;
}
-1
1
0小提示
當你想比較 str1 和 str2 內容是否一樣,
你可以:
if (strcmp(str1, str2) == 0) {
// do something
}你不可以:
if (str1 == str2) {
// do something
}記得別用 == 來比較兩個字元陣列
strcpy(dest, src)
把 src 的內容複製到 dest
用法
strcpy(dest ,src)。
把 src 的內容複製到 dest。
#include <iostream>
#include <cstring>
int main() {
char a[20] = "oatmeal", b[20] = "super big bento";
std::cout << "Before strcpy, a is " << a << std::endl;
strcpy(a, b);
std::cout << "After strcpy, a is " << a << std::endl;
}Before strcpy, a is oatmeal
After strcpy, a is super big bento小提示
你可以:
strcpy(dest, src);你不可以:
dest = src;(這應該會不能編譯)
在使用 strcpy 時,記得也為 dest 預留 '\0' 的空間哦!
strcat(dest, src)
把 src 的內容接到 dest 之後
用法
strcat(dest ,src)。
把 src 的內容接到 dest 之後。
#include <iostream>
#include <cstring>
int main() {
char a[20] = "yo! ", b[20] = "battle";
std::cout << "Before strcat, a is " << a << std::endl;
strcat(a, b);
std::cout << "After strcat, a is " << a << std::endl;
}
Before strcat, a is yo!
After strcat, a is yo! battle小提示
你可以:
strcat(dest, src);你不可以:
dest += src;(這應該會不能編譯)
在使用 strcat 時,記得也為 dest 預留 '\0' 的空間哦!
strtok(str, delim)
把 str 的內容以 delim 做分割
用法
strtok(str, delim)。
把 str 的內容以 delim 做分割。
#include <iostream>
#include <cstring>
int main() {
char str[] = "The lecturer is GTcoding";
char delim[] = " ";
char* token;
token = strtok(str, delim);
while (token != NULL) {
printf("%s\n", token);
token = strtok(NULL, delim);
}
}The
lecturer
is
GTcodingstrncmp
strncpy
strncat
其他相似字串操作函式
strncmp(str1, str2, n)
strncmp(str1, str2, n):
比較 str1 和 str2 這兩個字串的前 n 個字元。
0:表示兩者前 n 個字元內容一模一樣。
>0:表示 str1 的前 n 個字元的字典序比較大。
<0:表示 str1 的前 n 個字元的字典序比較小。
#include <iostream>
#include <cstring>
int main(){
char str1[20] = "Sprout 2022";
char str2[20] = "Sprout 2023";
std::cout << strcmp(str1, str2) << std::endl;
std::cout << strncmp(str1, str2, 6) << std::endl;
std::cout << strncmp(str1, str2, 11) << std::endl;
}
-1
0
-1strncmp(str1, str2, n)
strncpy(dest, src, n)
strncpy(dest, src, n):
把 src 的前 n 個字元複製給 dest。
對,沒錯,只有前 n 個字元,他不會幫你複製 '\0'。
strncpy(dest, src, n)
#include <iostream>
#include <cstring>
int main() {
char a[20] = "Sprout ", b[20] = "2023";
std::cout << "a is " << a << std::endl;
strncpy(a, b, 2);
std::cout << "a is " << a << std::endl;
}a is Sprout
a is 20routstrncpy(dest, src, count)
所以使用 strncpy 時,如果需要,記得自己手動補 '\0'。
#include <iostream>
#include <cstring>
int main() {
char a[20] = "Sprout ", b[20] = "2023";
std::cout << "a is " << a << std::endl;
strncpy(a, b, 2); a[2] = '\0';
std::cout << "a is " << a << std::endl;
}a is Sprout
a is 20strncat(dest, src, n)
strncat(dest, src, n):
把 src 的前 n 個字元接在 dest 之後。
strncat(dest, src, n)
#include <iostream>
#include <cstring>
int main(){
char a[20] = "Sprout ", b[20] = "2022";
std::cout << "a is " << a << std::endl;
strncat(a, b, 2);
std::cout << "a is " << a << std::endl;
}a is Sprout
a is Sprout 20其它 <cstring> 字串函式
小提示:要用到再查就好了
小練習
可行的思路
思路一:直接用 strncpy 和 strncat。
思路二:用迴圈,一個一個字元來處理。
參考答案
思路一:
#include <iostream>
#include <cstring>
int main() {
char a[105], b[105], ans[205];
std::cin >> a >> b;
int m, n;
std::cin >> m >> n;
strncpy(ans, a, m);
ans[m] = '\0';
strncat(ans, b, n);
std::cout << ans << std::endl;
std::cout << ans << std::endl;
std::cout << ans << std::endl;
}
小練習
思路二:
#include <iostream>
int main() {
char a[105], b[105], ans[205];
std::cin >> a >> b;
int m, n;
std::cin >> m >> n;
for (int i = 0 ; i < m ; i++)
ans[i] = a[i];
for (int i = 0 ; i < n ; i++)
ans[m + i] = b[i];
ans[m + n] = '\0';
std::cout << ans << std::endl;
std::cout << ans << std::endl;
std::cout << ans << std::endl;
}
謝謝大家
Sprout 2024 Char&String
By gtcoding



