iRODS and Reproducible Science

November 14-17, 2016
Supercomputing 2016
Salt Lake City, Utah
Terrell Russell, Ph.D.
@terrellrussell
Chief Technologist, iRODS Consortium



Problem 1
Too Much Data
Problem 1
Too Much Data
"90% of the world's data created within the last two years"
Problem 1
Too Much Data
"90% of the world's data created within the last two years"
Probably true. Every year. For the last few decades.
Problem 1
Too Much Data
Coming in too fast
Without good source information
Getting stored wherever there is room
Getting lost
Getting corrupted
Getting forgotten
Problem 2
Science is Hard
Problem 2
Science is Hard
Built on...
- Theory
- Hypothesis
- Experimentation
- Measurement
- Iterative Improvement
Problem 2
Science is Hard
Built on...
- Theory
- Hypothesis
- Experimentation
- Measurement
- Iterative Improvement
But above all...
- Must be Falsifiable
Problem 2
Science is Hard
Built on...
- Theory
- Hypothesis
- Experimentation
- Measurement
- Iterative Improvement
But above all...
- Must be Falsifiable
- Must be Repeatable
Problem 2
Science is Hard
Built on...
- Theory
- Hypothesis
- Experimentation
- Measurement
- Iterative Improvement
But above all...
- Must be Falsifiable
- Must be Repeatable
Must be Reproducible by Others
Data Management
Scientists, managers, and their network administrators must:
- know where the relevant data is,
- how it is handled over time, and
- have a plan for its ongoing curation.
Hard enough for today...
Data Management
Scientists, managers, and their network administrators must:
- know where the relevant data is,
- how it is handled over time, and
- have a plan for its ongoing curation.
Hard enough for today...
Some funders mandate data accessibility for 10 years from the
"last date on which access to the data was requested by a third party".
Data Management
For 10+ years, data must be:
- Verified
- Migrated
- Kept in Duplicate
- Made Accessible
- Monitored
Data Management
For 10+ years, data must be:
- Verified
- Migrated
- Kept in Duplicate
- Made Accessible
- Monitored
Automatically
Data Management
These long-term management tasks are too much for a curator or librarian, and certainly too much for the scientists themselves, to handle by hand.
There must be organizational policy in place to handle the varied scenarios of data retention, data access, and data use.
There must be automation in place to provide consistency and confidence in the process.
Confidence in tools comes from open frameworks and common, observable patterns in behavior and interoperability.
Big Science is Accelerating
Most "Big Science" is now multi-institute, multi-author, and moving at great speed towards modeling and other computational techniques for greater coverage and impact. The complexities related to storage, collaborative work, and data sharing will only increase.
Unilever
MSST 2016
1/day to 1000s/day

is an open source system that was designed for these requirements
iRODS provides the policy-based data management that is demanded by
modern, large-scale, distributed scientific and business endeavors through:
- data virtualization (unified namespace)
- data discovery (metadata)
- workflow automation (rule engine)
- secure collaboration (federation)
Data to Compute
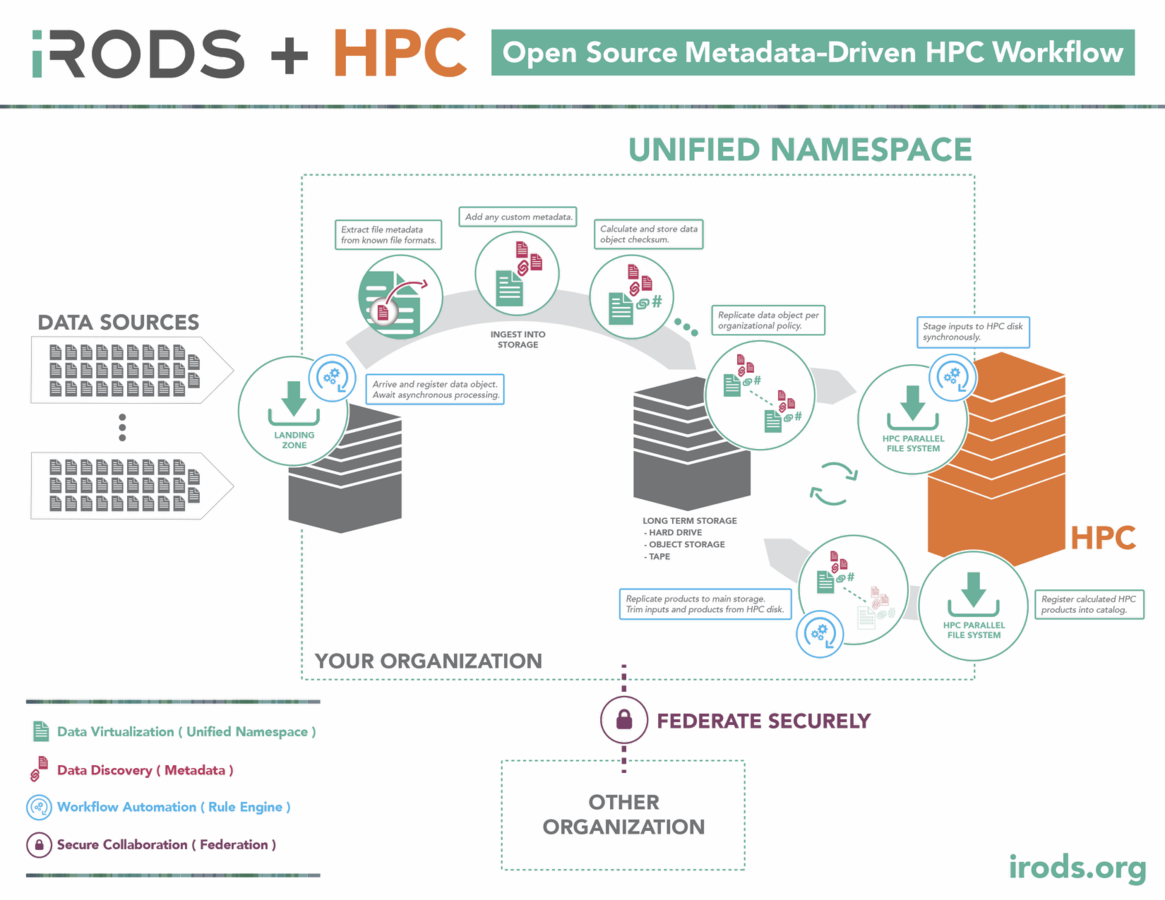
Compute to Data
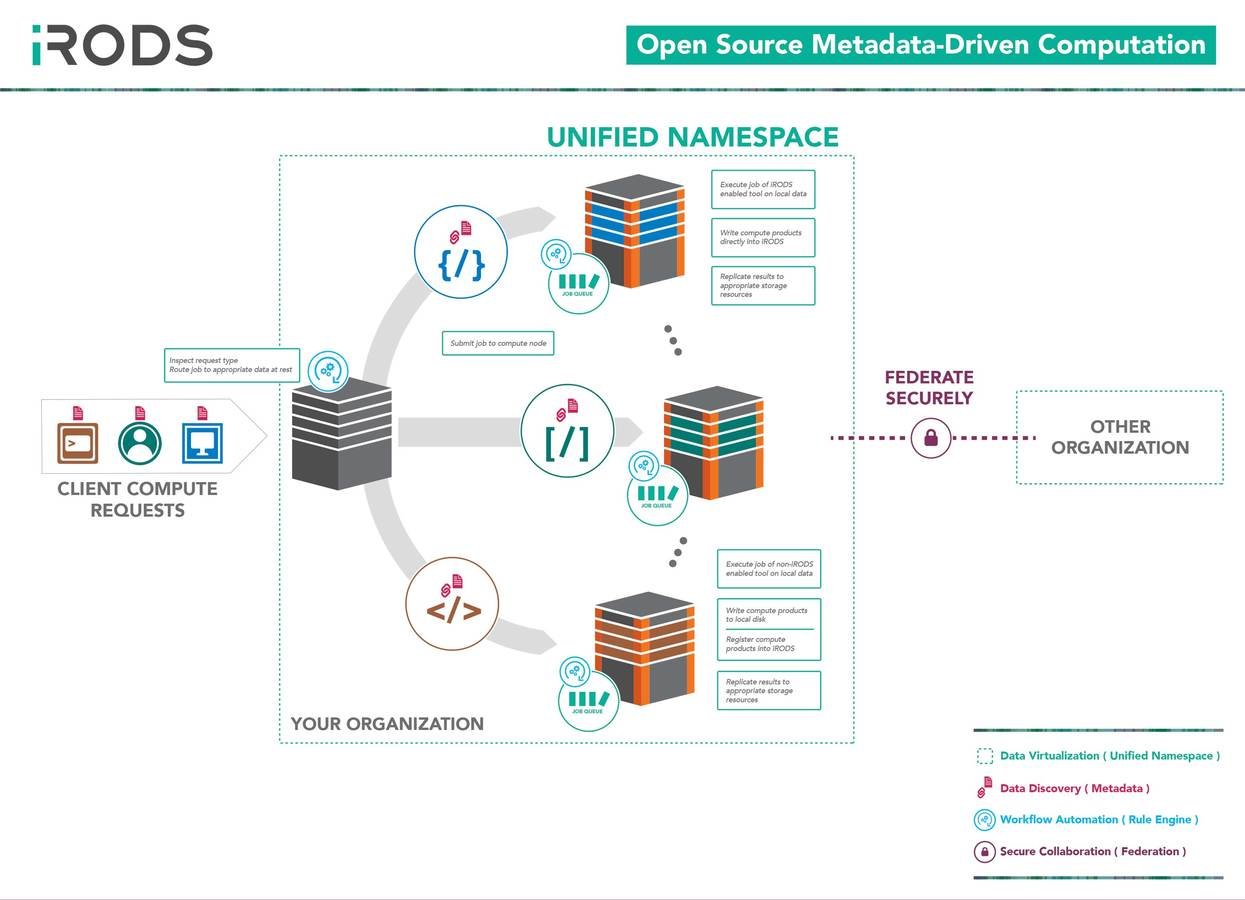
Use Cases
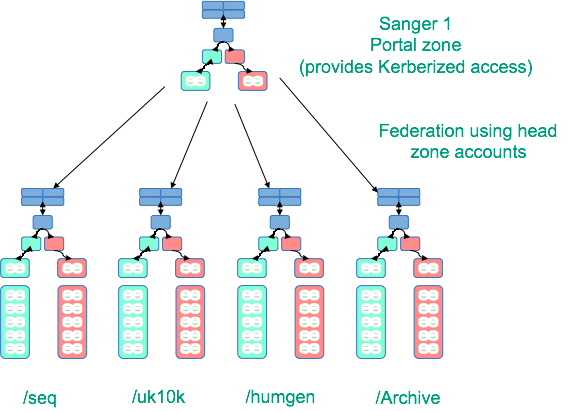
The Wellcome Trust Sanger Institute
- single-sign on, durability, HPC, metadata
National Institute of Environmental Health Sciences
- regularized workflow, reports, billing
NASA Atmospheric Science Data Center
- storage migration, publication, federation
University College London
- tiering, retention
The Wellcome Trust Sanger Institute
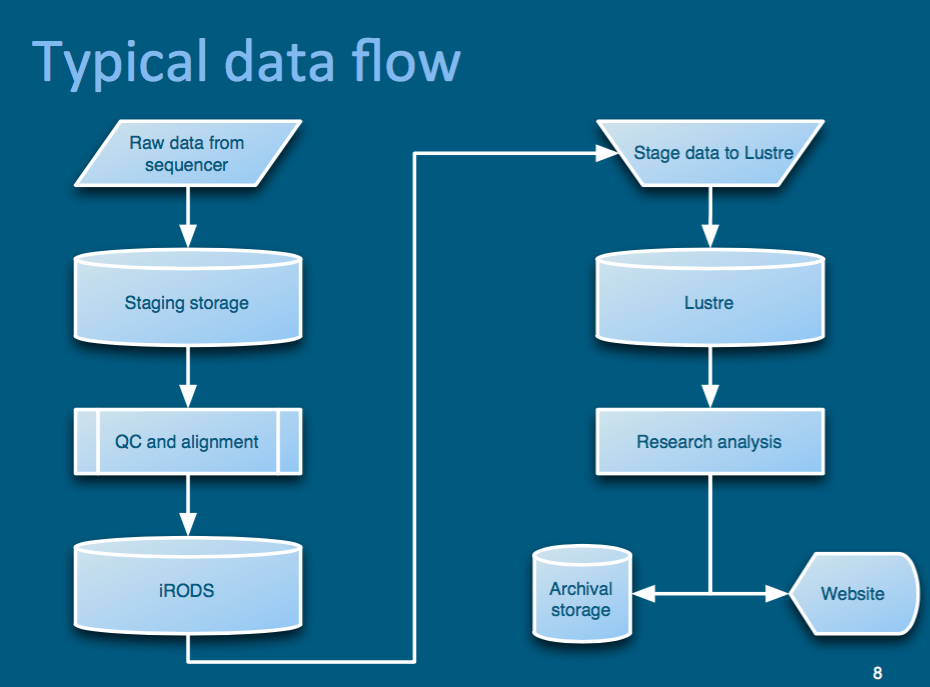
Sanger - Federation
Use Cases
The Wellcome Trust Sanger Institute
- single-sign on, durability, HPC, metadata
National Institute of Environmental Health Sciences
- regularized workflow, reports, billing
NASA Atmospheric Science Data Center
- storage migration, publication, federation
University College London
- tiering, retention
National Institute of Environmental Health Sciences
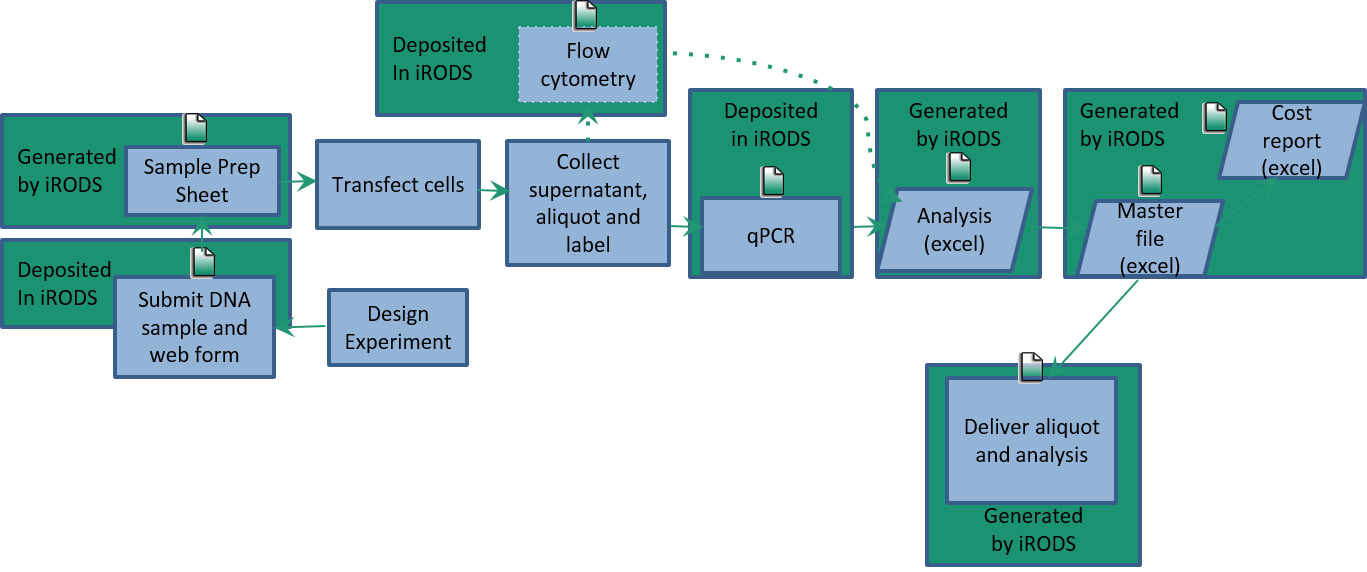
- Creating designer viruses:
- request > transfection and amplification > QC > sample delivery > reports
- Uses iRODS to combine, organize, and analyze sets of requests and instrument results
- Produces packaged results in response to researcher requests
- Quarterly cost reports for chargeback and trend analysis for quality control
Use Cases
The Wellcome Trust Sanger Institute
- single-sign on, durability, HPC, metadata
National Institute of Environmental Health Sciences
- regularized workflow, reports, billing
NASA Atmospheric Science Data Center
- storage migration, publication, federation
University College London
- tiering, retention
NASA Atmospheric Science Data Center

Use Cases
The Wellcome Trust Sanger Institute
- single-sign on, durability, HPC, metadata
National Institute of Environmental Health Sciences
- regularized workflow, reports, billing
NASA Atmospheric Science Data Center
- storage migration, publication, federation
University College London
- tiering, retention
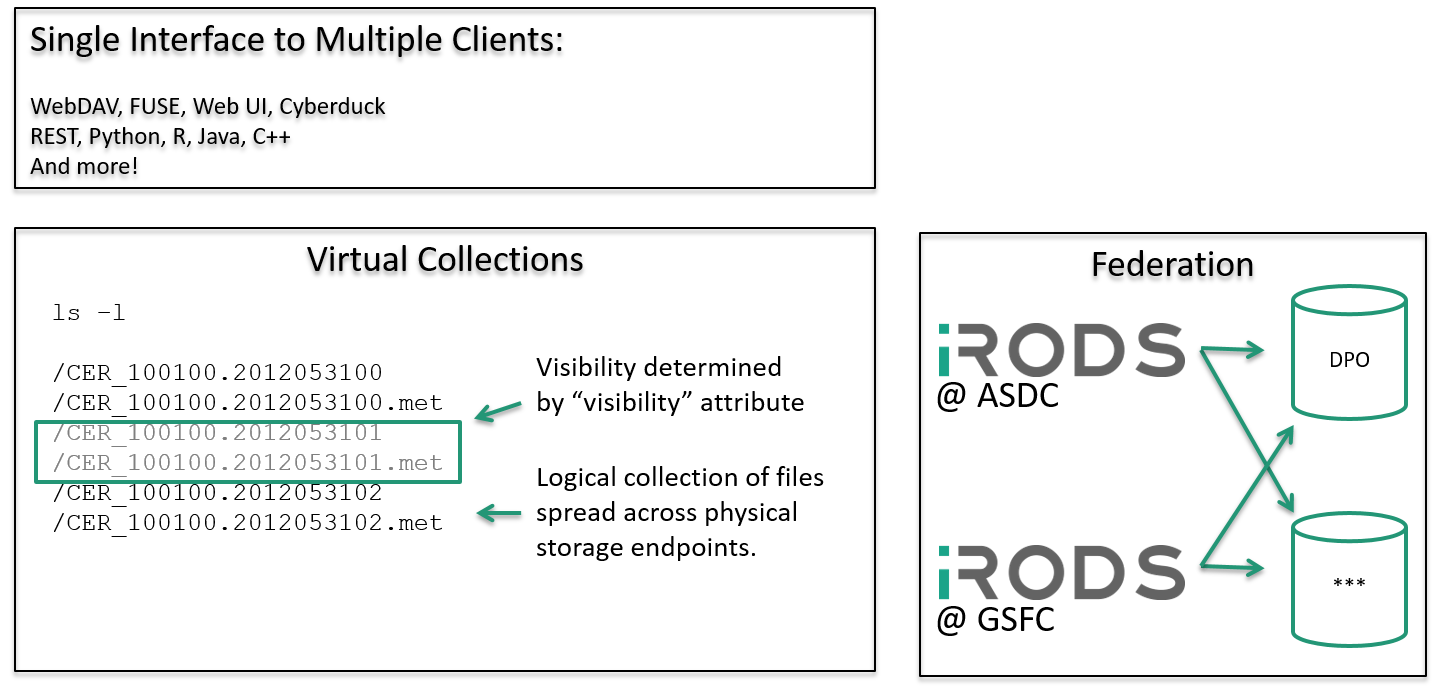
University College London
- Repository for research data that spans social science to physics to genomics
- UK sponsored research requirements: last date of access request plus 10 years
- iRODS spans data storage technologies and enables federated access from other centers
Policy-Based Data Management
Too Much Data
Science (and Business) is Hard
Organizations need Data Policy
Data Management must be Automated
Thank You
Terrell Russell
@terrellrussell
irods.org
@irods
iRODS is open source software for…
• Working with data distributed across storage technologies
• Annotating and searching data with rich metadata
• Implementing access control, auditing, preservation, organization, and data movement policies
• Providing a single interface to share data between organizations

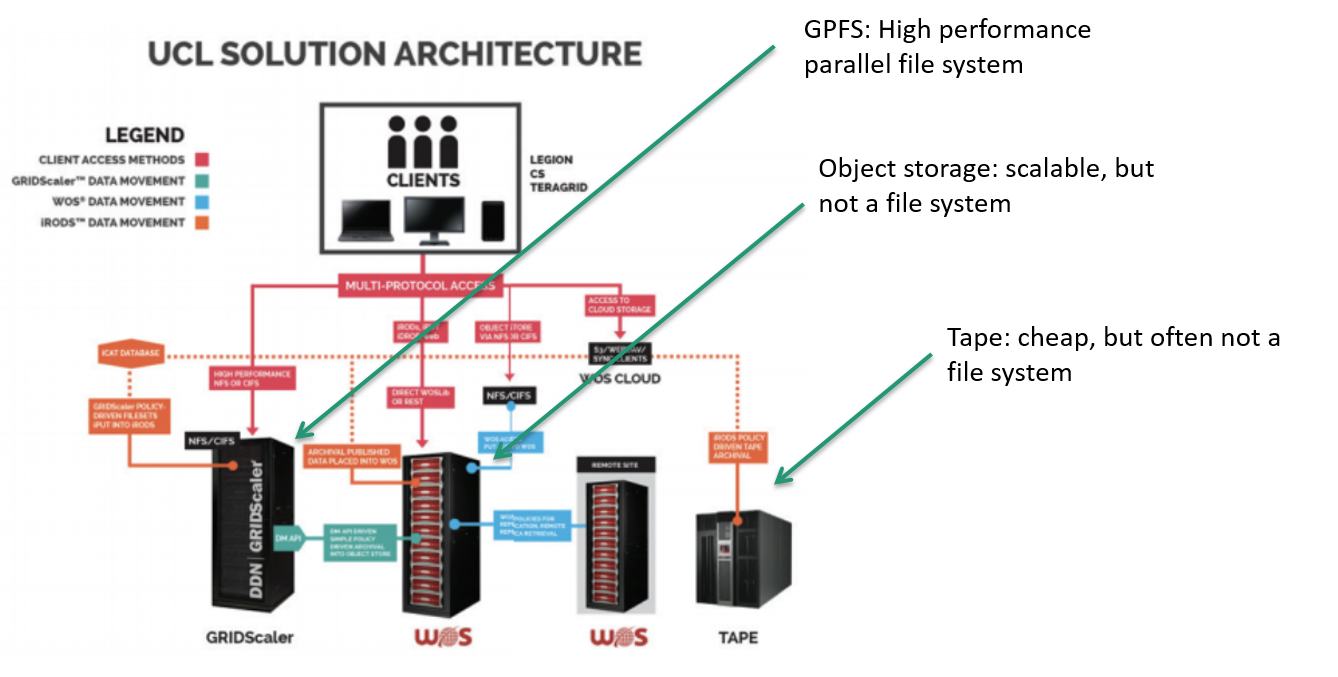
Data Virtualization
- Standard file systems: Any mount point
- Archival storage: HPSS, TSM
- Object stores: Cleversafe, DDN WOS, Ceph/Rados
- Cloud-based storage: Amazon S3
-
Separates Logical and Physical
- Logical - entry in the catalog
- Physical - a single replica on a storage resource
iRODS presents multiple separate storage technologies in a unified namespace.
Data Virtualization
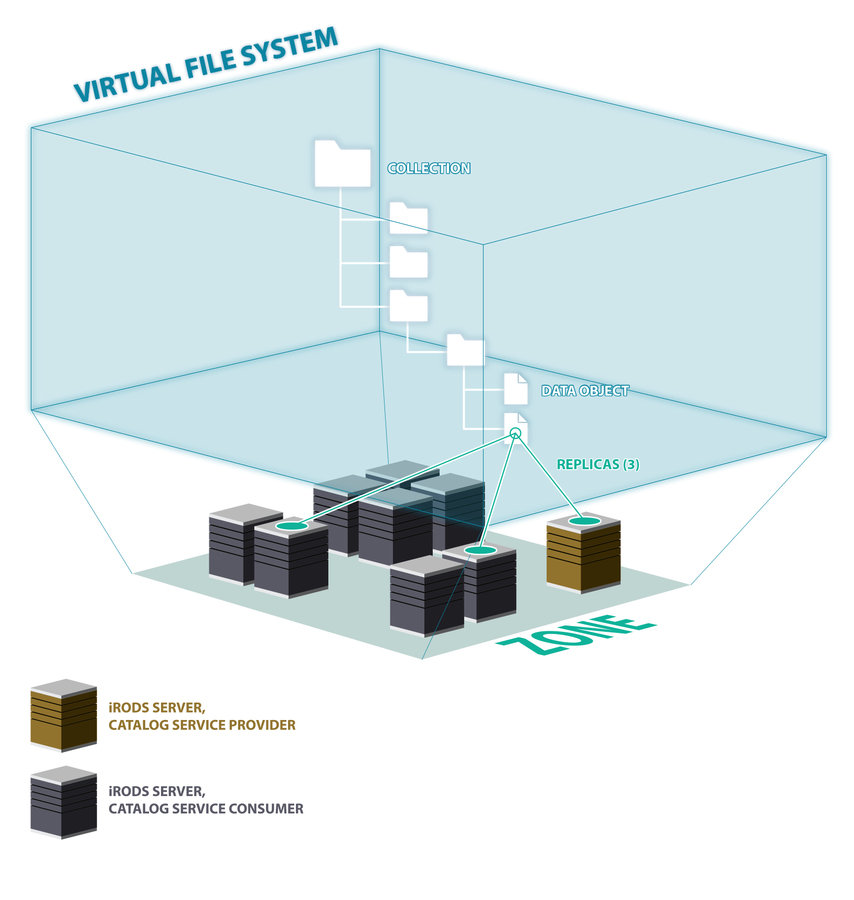
Logical Path
Physical Path(s)
Data Virtualization
| Logical Path | /tempZone/home/rods/thefile.txt |
| Physical Path(s) (replicas) |
/var/lib/irods/iRODS/Vault/home/rods/thefile.txt /tmp/u2vault/home/rods/thefile.txt /tmp/u1vault/home/rods/thefile.txt |
$ ils -L /tempZone/home/rods/thefile.txt rods 0 demoResc 29606 2016-10-05.09:05 & thefile.txt generic /var/lib/irods/iRODS/Vault/home/rods/thefile.txt rods 1 repl;u2 29606 2016-10-05.09:06 & thefile.txt generic /tmp/u2vault/home/rods/thefile.txt rods 2 repl;u1 29606 2016-10-05.09:06 & thefile.txt generic /tmp/u1vault/home/rods/thefile.txt
Data Discovery

- Metadata can be system- or user-generated.
- Users can find data using features such as description, study ID, access date.
- Metadata can be used to link processed results to raw data (i.e., tracking provenance).
- Administrators can use metadata to control policy, such as archiving and access control policies.
iRODS provides a catalog, the iCAT, that links data and metadata.
Workflow Automation

- API calls, database, resource and authentication operations
- iRODS rule engines execute PEP implementations
- PEP implementations can influence, deny or provide additional context to each operation
iRODS lets you use any operation within the system to trigger a programmatic action
Secure Collaboration
- Described as a Federation of iRODS Zones
- Users may access data in resources in other Zones anywhere
- A user from a remote zone must be granted access after federation
- A remote zone's data management policy is enforced for data accessed within that zone
iRODS lets you share data across administrative units at any time after deployment

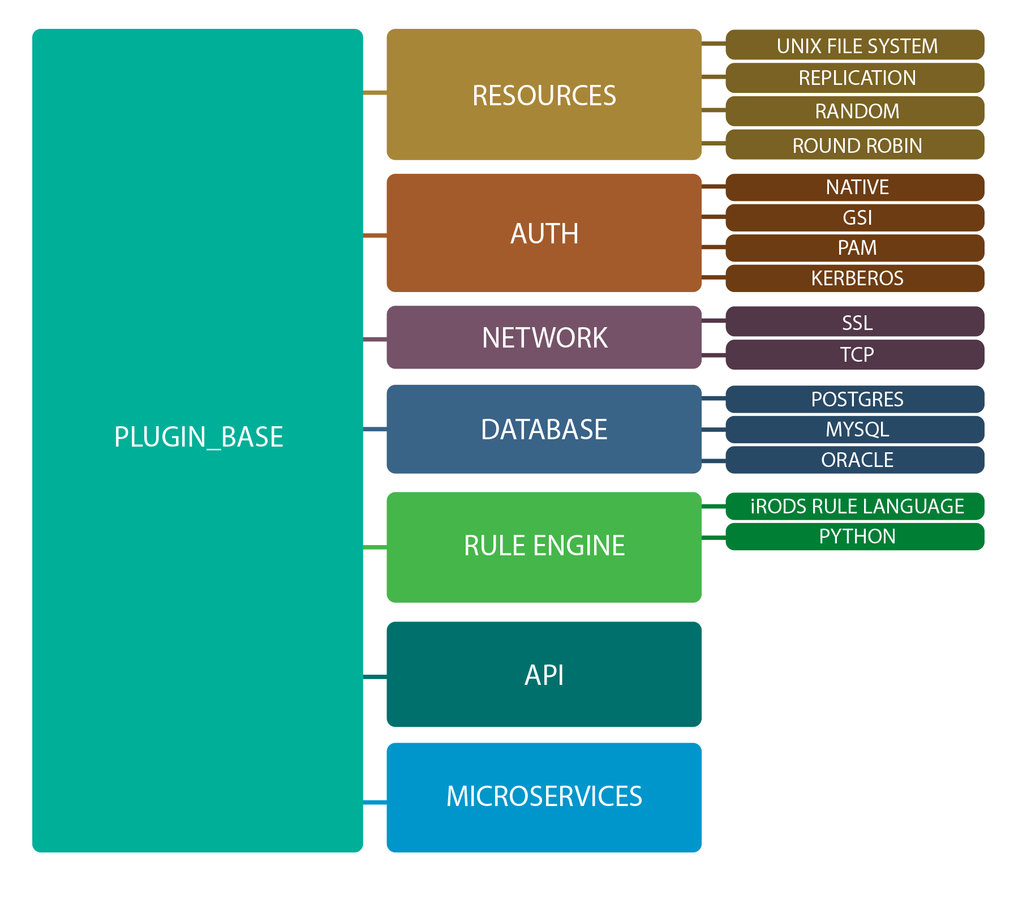
The iRODS Plugin Architecture
SC16 - Reproducible Science
By iRODS Consortium

