
















Ishanu Chattopadhyay PRO
ML Data Science Biomedicine Social Science Faculty
Ishanu Chattopadhyay
Assistant Professor of Medicine
University of Chicago
Data Governance
&
Privacy in the age of AI
Friday the 20th, October 2023
Age
of
Ai & Data
Vast databases of detailed personal information are everywhere
Data privacy and governance is crucial to protect individual rights and maintain trust.
Machine learning and AI have posed new challanges
Vast databases of detailed personal information are everywhere
Data privacy and governance is crucial to protect individual rights and maintain trust.
| name | age | occupation | address | diabetes |
|---|---|---|---|---|
| Alice | 20 | doctor | 23 maple st PA | No |
| Bob | 35 | teacher | 12 E av IL | Yes |
| Charlie | 43 | farmer | 42 oak st IL | No |
Classical Example
Truven MarketScan (IBM) Commerical Claims & Encounters Database 2003-2021
150M patients
12B transanctions
Age
of
Ai & Data
Current Example
End of Privacy?
Governace must not limit AI capabilities
Example:
Onishchenko, D., Marlowe, R.J., Ngufor, C.G. et al. Screening for idiopathic pulmonary fibrosis using comorbidity signatures in electronic health records. Nat Med 28, 2107–2116 (2022). https://doi.org/10.1038/s41591-022-02010-y
ZCoR: Zero-burden Co-morbid Risk Score
shortness of breath
dry cough
doctor can hear velcro crackles
Common Symptoms
>50 years old
more men than women
IPF
Rare disease
~5 in 10,000
Post-Dx
Survival
~4 years
At least one misdiagnosis
~55%
Two or more misdiagnoses
38%
Initially attributed to age- related symptoms:
72%
Cannot always be seen on CXR
Non-specific symptoms
PCP workflow demands
Initial midiagnoses
~ 4yrs
current
post-Dx survival ~4yrs
~ 4yrs
current clinical DX
ZCoR screening
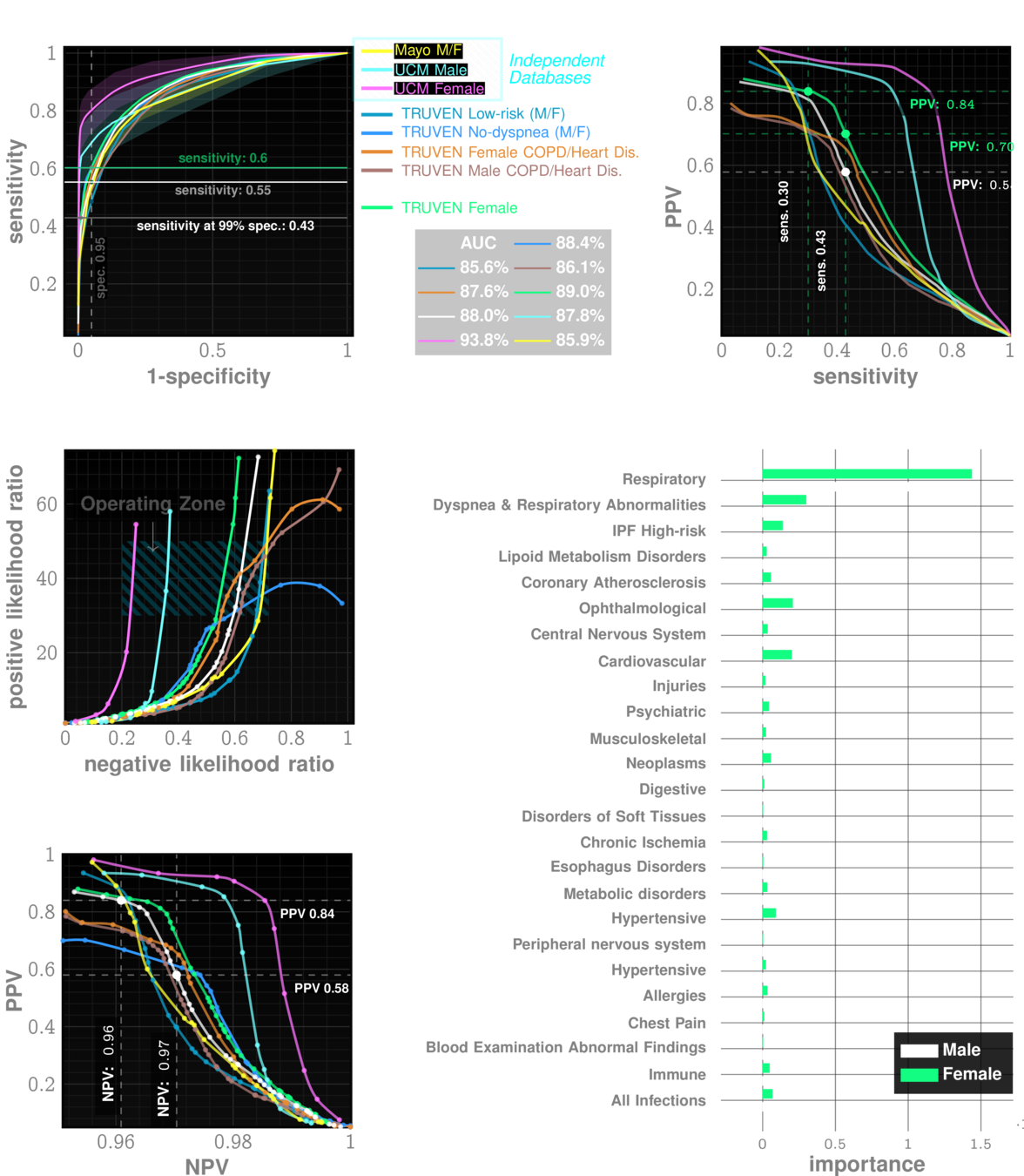
n=~3M
AUC~90%
Likelihood ratio ~30
Conventional AI/ML attempts to model the physician
AI in IPF Research
Primary Care
Reliable screening and diagnosis
ZCoR Flag
Sparse, noisy data with a priori unknown "risk factors"
Correct labels (diagnoses)
Ai
ZeD Lab: Predictive Screening from Comorbidity Footprints
Nature Medicine
JAHA
CELL Reports
Science Adv.
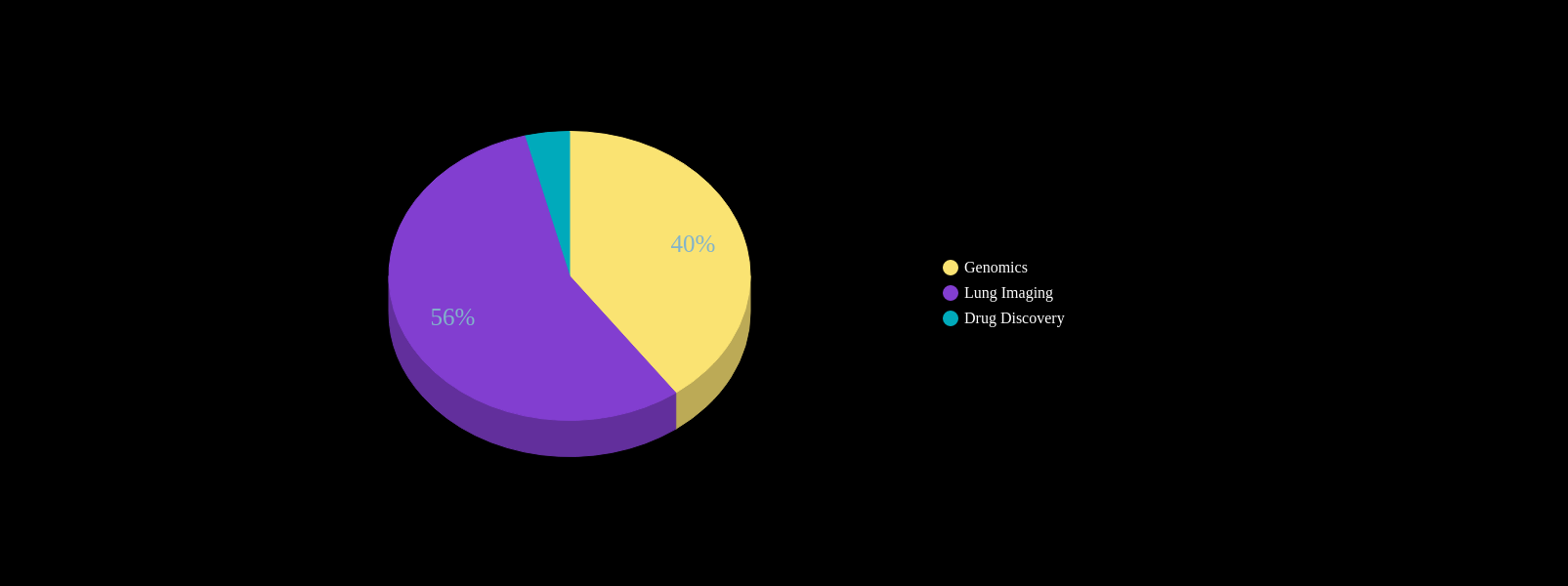
Predictive Screening from Comorbidity Footprints
| ZED performance | Competition | |
|---|---|---|
| Autism | >80% AUC at 2 yrs | Double false positives |
| Alzheimer's Disease | ~90% AUC | 60-70% AUC |
| Idiopathic Pulmonary Fibrosis | ~90% AUC | NA |
| MACE | ~80% AUC | ~70% AUC |
| Bipolar Disorder | ~85% AUC | NA |
| CKD | ~85% AUC | NA |
| Cancers | ~75% AUC | NA |
Complex systems with many variables
Cross-talk
Constrained "feasible space"
Reconstruction from noisy incomplete data
The Classical Challenge
Introduce 'noise' or alterations to the data in a way that individual records cannot be traced back, but the overall statistical patterns remain intact.
Corrupting Data
Destroying Identifiability
Mathematically, determining the right amount and type of 'noise' to add is non-trivial.
Too much alteration can render data useless, while too little can compromise privacy.
Mathematical Challenges
Mathematical framework to quantify and manage privacy risks
Differential Privacy
(Dwork 2006)
Removing or adding a single data point does not significantly impact the outcome of any analysis, thus ensuring the protection of individual privacy.
Synthetic data generation as a mode of data corruption
original data
original data
generate synthetic data
Learn generative model
has identifiable information
has no identifiable information
How do we know we did a good job?
Statistical tests
Membership Inference attcks
Qnets: A New Model for General Synthetic Data Generation
for tabular data
with mathematical guarantee of "good generator"
Differentially Private Generative Adversarial Networks (DP-GANs) combine the power of Generative Adversarial Networks (GANs) with the privacy guarantees of differential privacy.
Papernot, N., Song, S., Mironov, I., Raghunathan, A., Talwar, K., & Erlingsson, U. (2018). Differentially Private Generative Adversarial Network. arXiv preprint arXiv:1802.06739.
Existing Methods based on Adversarial Networks
discriminator
generator
Qnets: A New Model for General Synthetic Data Generation
CAD-PTSD Dataset
| PTSD1 | PTSD2 | PTSD3 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| patient1 | agree | ||||||||
| patient2 | disagree | ||||||||
| patient3 | strongly agree | ||||||||
| patient4 | neutral | ||||||||
| patient5 | |||||||||
items
respondants
example
with mathematical guarantee of "good generator"
Intrinsic Structure of Survey Responses
PTSD4
PTSD93
PTSD86
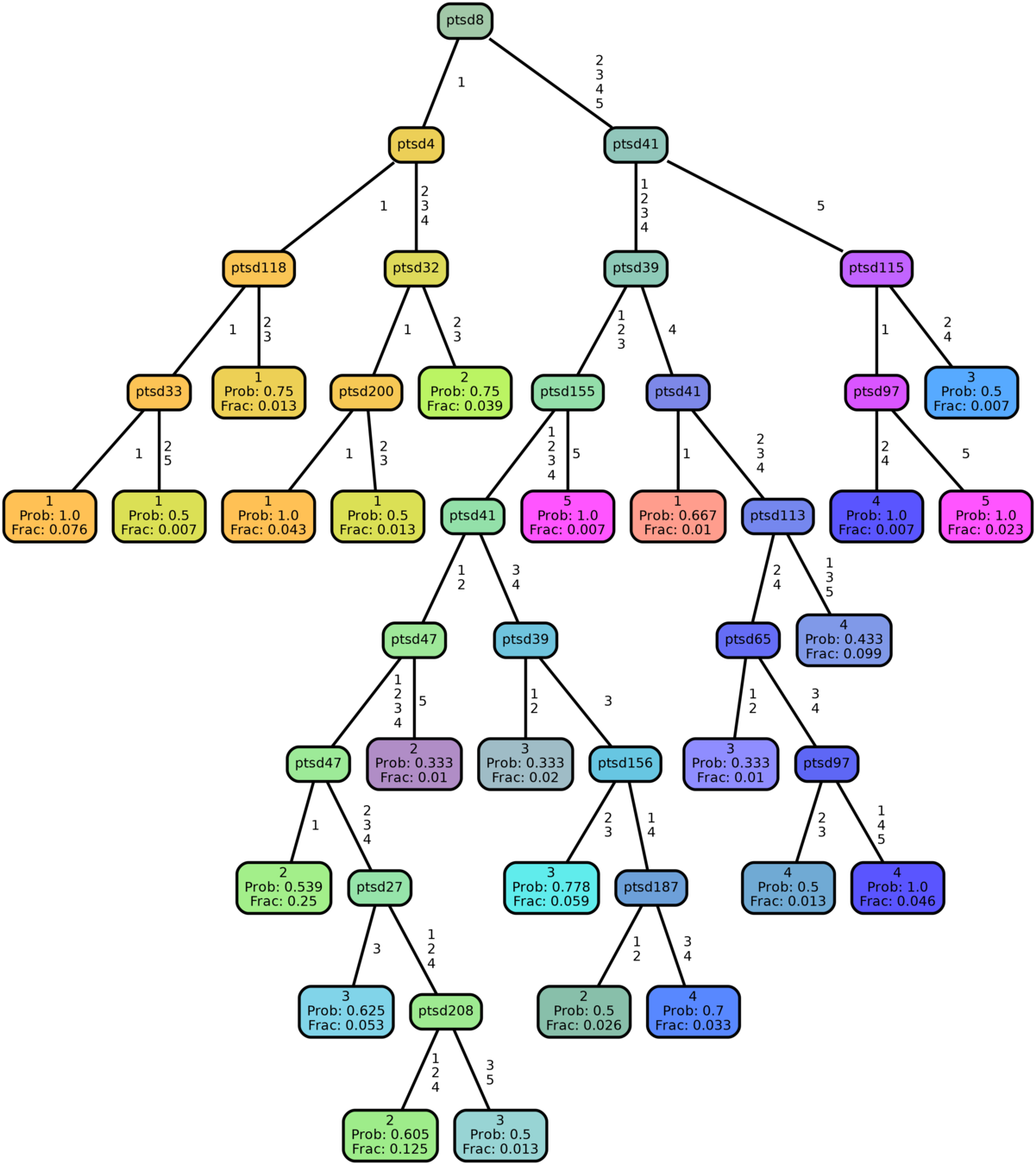
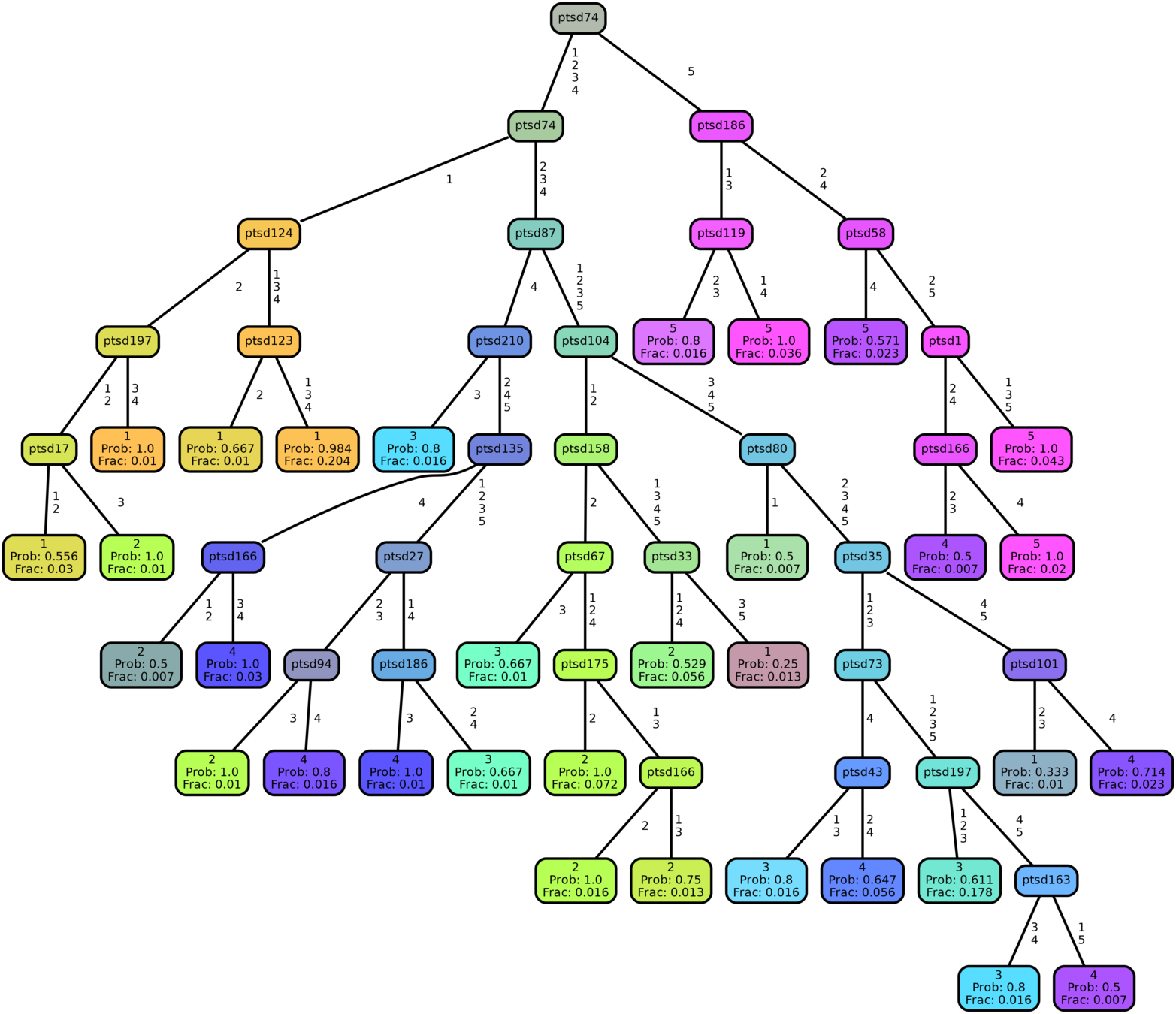
QNet Trees
(3 out of 211)
Together they form
a recursive forest
Nodes "hyperlinked" to trees: Potentially Infinite Hierarchy
The QNet Structure
Nodes Hyperlinked to Trees
click on nodes to change trees
The q-distance Metric
Collection of all such conditional inference trees is the recursive forest, answering the following question:
The q-distance Metric
The q-distance Metric: Why Is This a Natural Metric?
a
b
c
d
e
Similar opinion/response vectors can spontaneously switch:
intrinsic metric quantifies the odds of this spontaneous switch
Theorem: q-distance is "natural"
Sanov's Theorem & Pinsker's Inequality
Qnets
Q-distance
Dynamics
Q-sampling as a means of synthetic data generation
Assume that one question $$X_i$$ is unanswered.
a
b
c
d
e
Distribution of responses to this item given remaining responses
Given this distribution the probability that "b" is the answer
Follows from first principles:
Distance metric such that log-likelihood of jump scales as the distance
theorem
Q-sampling is just Gibb's sampling
"Corrupting" datasets with Qnets
q-sampled responses
Perturbation of original dataset in terms of induced metric :
Homework
Recall:
Find \(f,g\) such that
?
ishanu@uchicago.edu
By Ishanu Chattopadhyay
Predictive modeling of crime and rare phenomena using fractal nets



