Dr James Cummings
“Here to enter a dyvel wyth
thunder and fyre”
A plea for editorial infrastructure
in the digital age.
James.Cummings@newcastle.ac.uk
@jamescummings

CC+BY (press space to cycle through slides)
Overview
- About the TEI: A quick high-level refresher
- What do people do now: Creating and publishing scholarly digital editions
- Marking up abbreviations: A case study with a tiny bit of The Conversion of St Paul
- To get where we're going, we need better infrastructure
Thesis: TEI is the right format for scholarly digital editions, but we still lack mass-adopted de facto solutions for collaborative creation, annotation, publication, and analysis of scholarly digital editions.
About the TEI:
A quick high-level refresher

The TEI (The Text Encoding Initiative) is:
- An international consortium of institutions, projects and individual members
- A freely available manual of set of regularly maintained and updated recommendations: 'The Guidelines' with definitions, examples, and discussion of ~590 markup distinctions
- A mechanism for producing customized schemas for validating your project's digital texts or metadata
- A set of free and openly licensed, customizable tools and stylesheets for transformations to many formats (e.g. HTML, Word, PDF, Databases, RDF/LinkedData, Slides, ePub, etc.)
- A simple consensus-based way of organizing and structuring textual (and other) resources
- An archival, well-understood, format for long-term preservation of digital data and metadata
- Whatever you make it! It is a community of users and volunteers

- The TEI Consortium manages the development of the TEI Guidelines (and associated software)
- It is overseen by an elected Executive Board and its outputs developed by an elected Technical Council
- People don't have to be members to use the standard but this gives them a vote in elections
- The TEI Guidelines are updated about every 6 months
Markup: Why do we use italic fonts?
Think about the uses for an italic font in any form of printed publication. Why might an author/publisher put some text into italics? What are they signalling about that text?
We can usually tell these types of things apart from context. If we want to use these categories, computers need to be told these things are different.
Some common uses include:
- titles
- emphasis
- foreign phrases
- technical terms
- editorial apparatus, captions, cross references
- quotations, speaker labels in drama
- speech and thought ... and many more
About XML
<element> Text </element>
<element attribute="value">
Text or child elements here
</element>
<element attribute="value"/>
"Opening Tag"
"Closing Tag"
"Empty Element"

Overall TEI XML Structure
The TEI Guidelines

TEI Customisation
(But I don't need everything the TEI provides, or want something it doesn't give me)

Possibilities of the
TEI Framework
Project B
Project A
New Elements
What do people do now?
Creating and publishing
scholarly digital editions
Creating Scholarly Editions
(Do I have to see the XML markup?)

Creating TEI
- How do people create TEI Files?
- hand encoding
- as individuals, through a variety of editors
- through an interface
- whether various forms, tags-off views in editors, or bespoke content management systems
- up-conversion
- of materials created in other formats, such as docx, xlsx, etc., by a programmer
- hand encoding
Up-conversion
- Often people will create editions through other forms such as MS Word (docx)
- Using the docxtotei conversion that TEI-C freely provides this can be transformed to TEI
- Limited to presentational markup (based on Word formatting styles)
- If you use special word phase-level styles in the form of tei_elementName it tries to convert these to that element (e.g. tei_name to <name>)
- Second phase of conversion work can often provide more detailed markup depending on how granular the original format preserves distinctions
In the end the best method to use is that which enables you actually to create your rich digital texts
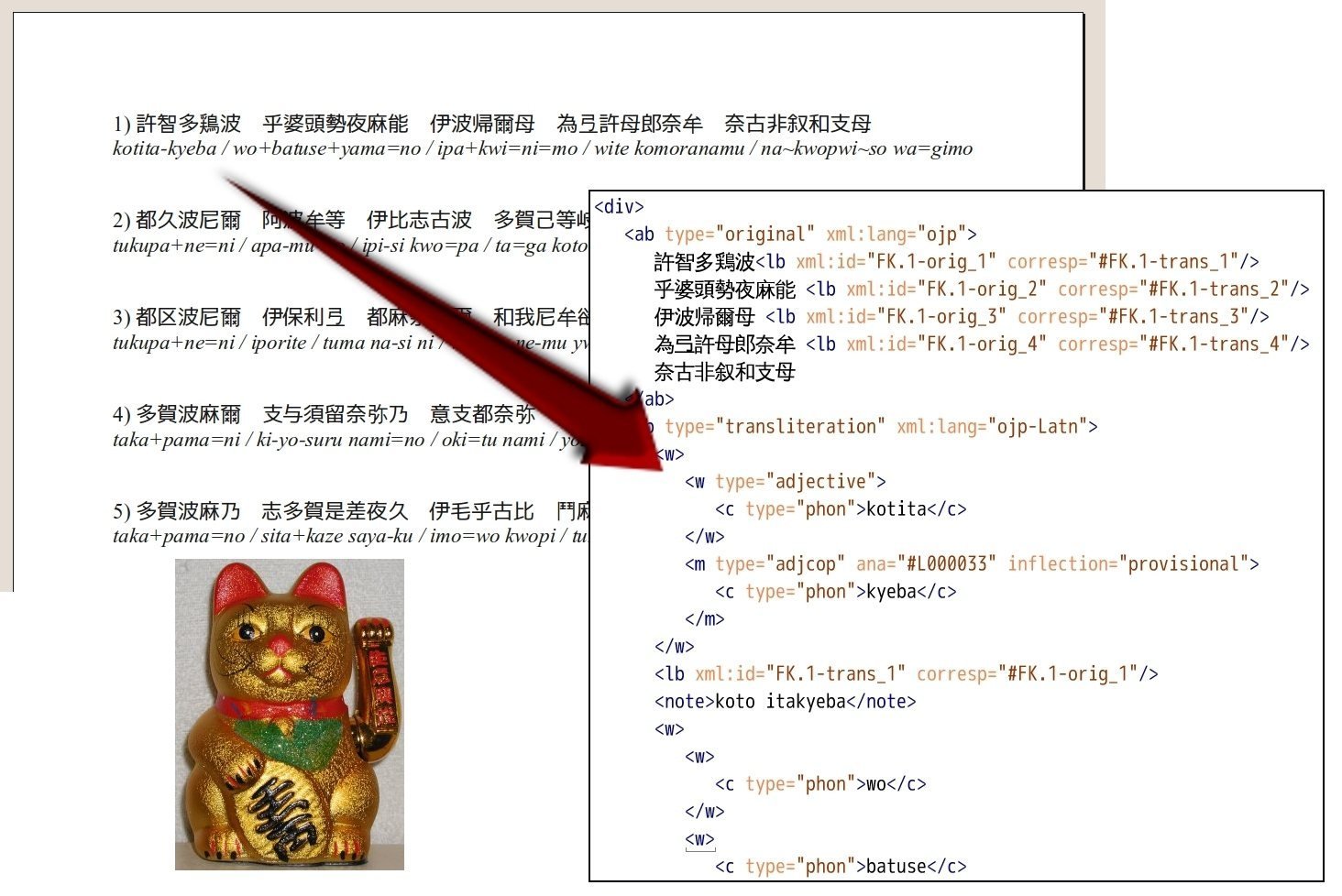
Publishing Editions
(How do people publish these TEI files?)
Publishing TEI
- There are many tools available these are only a small selection. But often projects need to create their own bespoke tools (and that is part of the problem)
- Edition Visualization Technology
- TEI Critical Edition Toolbox
- TEI-C Stylesheets
- OxGarage
- CETEIcean
- eXist-db / TEI Publisher
- TAPAS
- The tools you use may affect the features available to those reading your research. You may have more or less ability to customise.
Edition Visualization Technology
- Easy publication for multi-witness critical editions
- Critical Edition support: rich and expandable critical apparatus, variant heat map, witnesses collation and variant filtering
- Bookmark: direct reference to the current view of the web application, page and edition level, collated witnesses and selected apparatus entry
- High level of customization: the editor can customize both the user interface layout and the appearance of the graphical components
- https://visualizationtechnology.wordpress.com/

TEI Critical Apparatus Toolbox
- Based on TEI Boilerplate (a simple TEI publishing system)
- The toolbox lets you:
- Check your encoding: offers facilities to display your edition while it is still in the making, and check the consistency of your encoding
- Display parallel versions: choose the sigla of the witnesses, and the different versions of the text, following each chosen witness, will be displayed in parallel columns.
- http://teicat.huma-num.fr/


TEI-C Stylesheets
- Freely available, generalised XSLT stylesheets
- Transformations to and/or from around 40 formats such as:
- BibTeX, COCOA, CSV, DocBook, DocX (MS Word), DTD, EPub, XSL-FO, HTML, JSON, LaTeX, Markdown, NLM, ODT, PDF, RDF, RelaxNG, RNC, Schematron, Slides, TEI Lite, TEI ODD, TEI P4, TEI simplePrint, TCP, Text, Wordpress, XLSX (MS Excel), XSD
- Customisable through importing and overwriting templates; Stylesheets repository allows for local 'profiles'
- TEI-C offers services such as OxGarage which enable pipelined conversion to/from many more formats
- https://github.com/TEIC/Stylesheets



CETEIcean
- CETEIcean is a Javascript (ES6) library that enables TEI P5 XML to be displayed in a web browser without transforming them to HTML5
- Instead it registers them with the browser as Custom Elements
- Because the elements are treated as HTML, the HTML5 it produces is valid, and there are not element name collisions (like HTML <p> vs. TEI <p>)
- http://github.com/TEIC/CETEIcean



Your Edition or Web Page Template
Embedded divisions of custom HTML elements
CETEIcean
JavaScript
eXist-db TEI Publisher
- The "instant publishing toolbox" based on eXist-db XML database
- Provides easy browsing and search of TEI XML documents initially built for TEI simplePrint
- Default display is clean and sophisticated page-by-page display
- Control of element display is by editing the processing model documentation embedded in the TEI ODD (the TEI customisation format)
- http://www.teipublisher.com/


TAPAS Project
- The TAPAS project: TEI Archiving, Publishing, and Access Service hosted by Northeastern University Library's Digital Scholarship Group
- A free account can contribute to projects and collections in TAPAS to archive, publish, discover or share their TEI files
- Built in very basic XSLT transformations
- TEI Members (or paid TAPAS members) can create collections and projects
- 1GB of XML file storage for TEI files, TEI ODD Customisations
- http://tapasproject.org/

What's wrong with those?
- Nothing.
- Well, most of them don't abide by the Endings Principles for Digital Longevity
- But there is no mass adoption of a single solution
- Changing any of those systems involves significant learning curves or expense
- None of it is joined up:
- You use one system to manually create XML
- Another to publish it
- Yet another to analyse it
- If we are to build a new system, it would make sense to base it on one of these -- TEI Publisher being my favourite but even this has its downsides.
Marking up abbreviations:
A case study with
The Conversion of St Paul

- Source: Bodleian MS Digby 133, f.45r, The Conversion of St Paul
- Language: Middle English Play, late-15thC, East Anglian
- Plot: A saint's play detailing the conversion of Saint Paul, from being Saul a persecutor of Christians to Paul a disciple of Jesus
- Added fun: there is a contemporary interpolation of 3 folios containing a fun devil's scene.
- Staging: Station-based but unclear, likely that audience moved from station to station

It isn't just that we want to record the abbreviations but also at least:
- what form the abbreviations took
- if we used a different editors reading for the expansion
- that this is all inside a stage direction
- that there has just been a folio break to f. 45r
- any editorial notes we have about this being an interpolated devil's scene by a different scribe
- that just after this a speech by the character Belyall starts
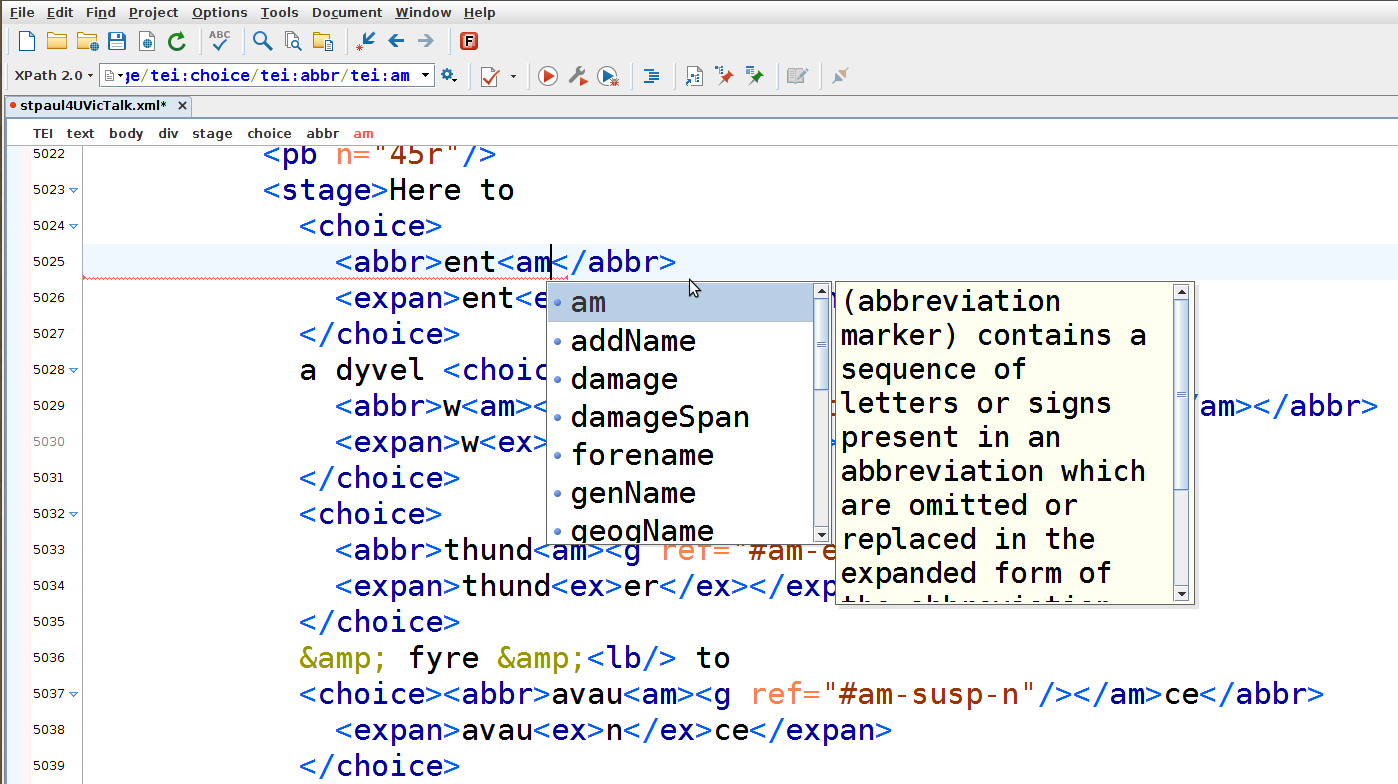
This is simplified markup using <expan> (expanded word) with <ex> (expanded text); also <stage>, <note>, <sp>, <speaker>, <l>, and & for an ampersand.

This uses a full <choice> markup with <abbr> (abbreviated word) and <am> (abbreviation marker.


(The next bit of the speech)
Why add all this markup?
- Adding sufficient markup to create a scholarly digital edition enables many presentational benefits
- Not only can readers then trace back the precise editorial process in order to form their own conclusions ("You expanded that abbreviation wrong")
- But also the markup can be used to present different views on the same edition (Diplomatic, Edited, Reading, Acting, etc.)
- Users could toggle between individual abbreviations and expansions and
- Less limited by typographical signalling (italics, parentheses, font changes) for editorial changes
- It best represents the conceptual edited object (the edition as mental construct in the mind of the editor)
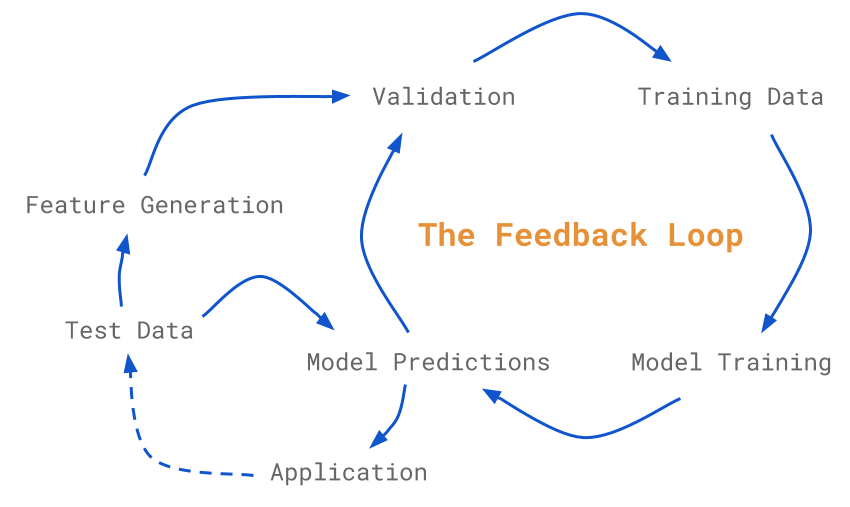
To get where we're going, we need better infrastructure:
standoff and machine learning for scholarly digital editing
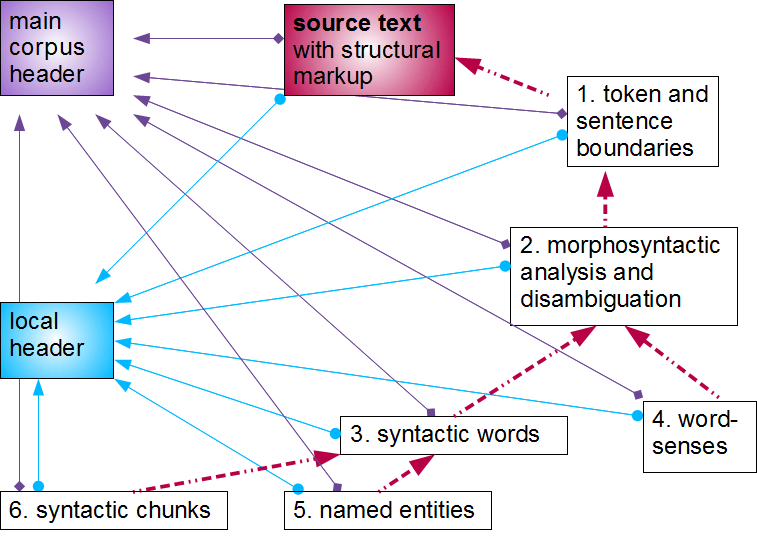
Standoff Markup and Editions
- Standoff markup keeps text separately from the markup
- Avoids overlap issues
- Modern digital editions often exploiting this, for example having a base text where each word is (automatically) marked up, and other structures stored separately and point in to the range of words they concern.
- Most generalised editing or publication software handles this out of the box.
Markup for analysis
Thinking about the markup of that St Paul play, it isn't just for presentation but analysis as well. With it one could ask questions about:
- How consistent is our editing of particular forms (do we always include the superscript 't' of a 'wyth' abbreviation as part of the abbreviation marker or the existing text.
- Word frequency or dialectical word forms of one part of the play to others (for example the interpolated devil's scene)
- use of markup over the whole text to generate aggregate reports on how we represent the text
- similar structures over multiple texts to find linguistic or stylometric patterns
But the question of why...
- In studying the markup itself we can see how something has been marked up but crucially not why.
- If we are able to get enough data (and indeed, having a large mass of data is our first stumbling blocks) then we are in the realm of data science
- An imagined future project will train machine learning algorithms to understand why editors make the decisions they do
- This would then enable AI assistants to editors, suggesting editorial interventions to them that they might want to make while editing a text
- Which could feed back into software, providing useful help to the scholarly textual editor while they work
Clippy For Scholarly Editors?

It looks like you are about to expand the Medieval Latin abbreviation 'Dni'. In 78% of cases like this editors expand this as 'Domini'. Would you like me to do that for you?
In MS A, MS B, and MS C the text has 'In spiritu humilitatis et in anima contrita suscipiamur' at this point, but is marked as missing in the textual witness you are editing. Want me to add it, marked as supplied, here?
What kind of editors?
The kind of scholarly editor I have in mind could be a vague stereotype that should work for any editor, but I also base it on people like my wonderful colleague Professor Jenny Richards down one end of a spectrum and myself down the other end.



What do we need?
- In order to build a machine learning tool for scholarly editing, of course, we need a sufficiently large corpus of reliable editorial decisions
- Some of that could be deduced from markup
- Some from retrospective conversion of highly structured print editions.
What do we need?
- But, in order to get a large corpus of editorial decisions we need lots of editors to use a single system
- Or find semi-automatic ways to deduce decisions from existing markup or printed editorial decisions.
What do we need?
- And yet, in order to get a lot of editors to use a single system it would need to be providing them with useful outputs to encourage them to use it. Outputs such as:

- Free (or very cheap) hosting
- Cater for wide range of edition types and outputs
- Collaborative annotation
- Stand-off markup
- Named entity lookups
- IIIF image hosting/display
- Export to Endings Principles compliant archival packages, etc.
- And loads of other features
What do we need?
- In order to have a popular system with useful outputs we need to make it so easy to use that editors do not mind having data tracked on how/why they make particular decisions while encoding
- Data tracking should be transparent
- And provide clear benefits back to the editor
What do we need?
- In order to have that, we need a system that is known to be stable, supported, sustainable, and future-proof. (Eeep!)
- This is, of course, impossible unless massively resourced

What should editors not learn?
For years I have said:
"It is easier to teach the subject specialist TEI than it is to teach a TEI expert another subject specialism".
This remains true, but for large scale adoption of an editing platform editors should not have to learn:
- XML (or any other particular structured data format) or editors for it: What is important is the categories of information used in a digital edition and then to have interfaces that create this for them.
- Virtual machine or server admin: Software should be hosted online (but also available in easy containerised packages for installation by local IT)
- Publication tools: Software should have easy outputs to standard formats (TEI/DOCX/HTML/PDF), modifying output should be straightforward
(Unless they want to
of course!)
What happens if we don't?
- We don't get the benefits this will provide scholarly editing.
- With the advent of HTR (Handwritten Text Recognition) set to transform all archival research on historical text over the next few decades we will be left with lots of HTR'ed text which is not truly edited.
- Digital scholarly editions will remain individual undertakings without leveraging the possibilities of large scale computational assistance for the editors.
- The digital scholarly editions will also remain unsustainable bespoke undertakings of publication without consistency of approach, markup, form of publication, and affordances for researchers across multiple editions.
- Editing as a scholarly activity may become even more sidelined in the Humanities.
The Real Question
- The Real Question though is how could we ever get there.
- The answer is not by a single academic, a single institution, a single country, or a single commercial company owning this.
- It must be a truly open, international, and cooperative endeavour.
- Sadly, the structures of many of our national institutions (funding bodies, universities, etc.) discourage these forms of cooperation
- But I hope that by starting to talk about it, we might start some interest in moving towards this future
Dr James Cummings
“Here to enter a dyvel wyth
thunder and fyre”
A plea for editorial infrastructure
in the digital age.
James.Cummings@newcastle.ac.uk
@jamescummings
CC+BY (press space to cycle through slides)
Thank you! Questions?
“Here to enter a dyvel wyth thunder and fyre” – a plea for editorial infrastructure in the digital age.
By James Cummings
“Here to enter a dyvel wyth thunder and fyre” – a plea for editorial infrastructure in the digital age.
Lansdowne Lecture at University of Victoria. January 31, 2022 at 10am Pacific time. Abstract: The editing of late-medieval plays involves making many individual decisions, but rather than making the editor’s job easier, digital technology often adds additional burdens, demanding the knowledge of encoding formats, fighting for server space, and planning for the long-term preservation of their cherished editions. Using the editing of late-medieval drama as a case study, Cummings argues that the existing infrastructure for digital textual editing fails to provide textual editors with the appropriate tools for the job of producing scholarly editions that are truly digital. A long-term proponent of standards such as the Text Encoding Initiative, he does not suggest that we do away with any of these concerns, but rather that we create standardised hosted interfaces for editorial tasks that leverage the power and expressivity of standards, while simultaneously assisting with long-term preservation. There are other potential benefits: such infrastructure could also enable data science research into editorial methods and the decisions editors make concerning any individual task, paving the way for more intelligent software in the future.




