large language models
and creating custom chat-bots that can run locally
With local-first applications, you get the speed and responsiveness of a local application, but at the same time, you get many of the desirable features from client/server systems.
Use a "production ready"
application
Make a chat-bot
Fine-tune inputs
to "base" model
Fine-tune model /
Train new model
- 😍Least technical knowledge required
- 😵Lower performance ceiling
- 🥇Can obtain peak performance
- 😢Requires knowledge, setup, infrastructure, etc...
- 😭Requires computation power
- 🥇Can obtain peak performance
- 👎Requires knowledge, setup, infrastructure, etc...
🎵 Realistically, one could pick and choose elements from each element and model selection/creation could be considered an entirely separate phase of chat-bot creation.
use a "production ready" application
- There are multiple options available that are cross platform, easy to install, and can be run locally
- Can be used to accomplish many tasks like summarization, question asking, code generation, text comprehension/generation, translation, and more.
Summary: Get up and running with Llama 3, Mistral, Gemma, and other large language models.
- Command line tool that is easy to install and use
- Available on macOS, Linux, and Windows (preview)
- Allows access to state of the art models
- Basis for ecosystem of libraries and applications, including code assistants
ollama
ollama
# Install ollama
curl -fsSL https://ollama.com/install.sh | sh
# Start ollama server
ollama serve
# Download and run a model
ollama pull llama3
ollama run llama3
# Chat with model
>>> Tell me a joke- 🤩 Once a model is downloaded, it can be used locally without an internet connection
- 🚀 Extremely fast performance on commodity hardware
- 🤓 Llama3 is Meta's newest model
Summary: Distribute and run large language models with a single file.
- Download a single file and run an LLM server
- Works on mac)S, Linux, and Windows
- Supports Lllama models and more
llamafile
Summary: Open-source large language models that run locally on your CPU and nearly any GPU
- Desktop application that is easy to install and use
- Available on macOS, Linux, and Windows
- Allows access to state of the art models
- Basis for ecosystem of libraries and applications
gpt4all
gpt4all
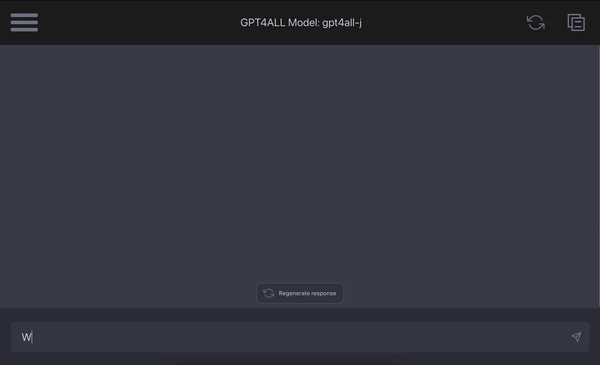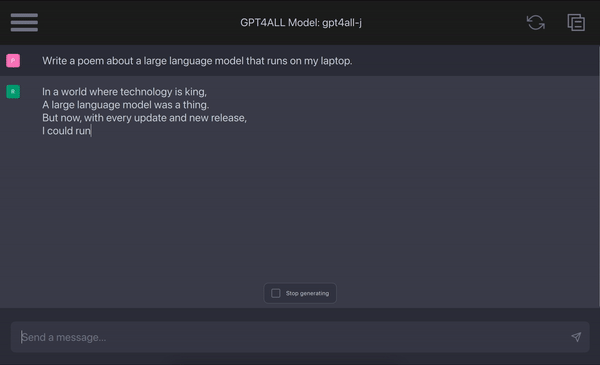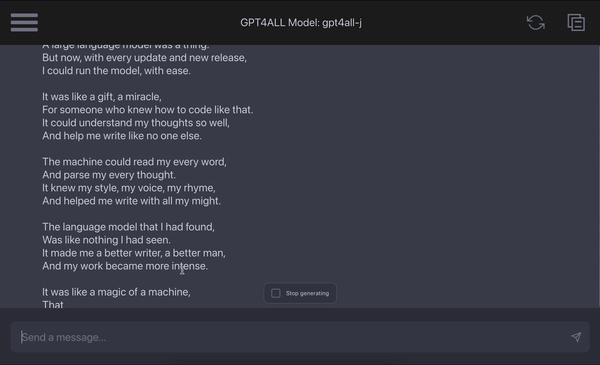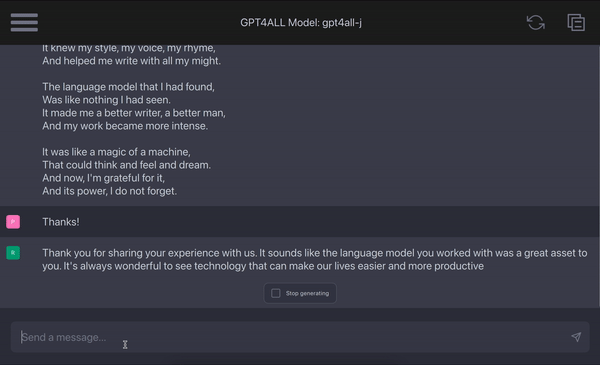
Summary: Browser that lets you install, run, and programmatically control ANY application, automatically.
- Desktop application that allows you to use many state of the art AI/ML applications such as Stable Diffusion, Parler TTS, and many more
- Available on macOS, Linux, and Windows
- User friendly interface
pinokio browser
Summary: Open source alternative to ChatGPT that runs 100% offline on your computer
- Desktop application that is easy to install and use
- Available on macOS, Linux, and Windows
- Allows access to state of the art models
- User friendly interface
jan
jan
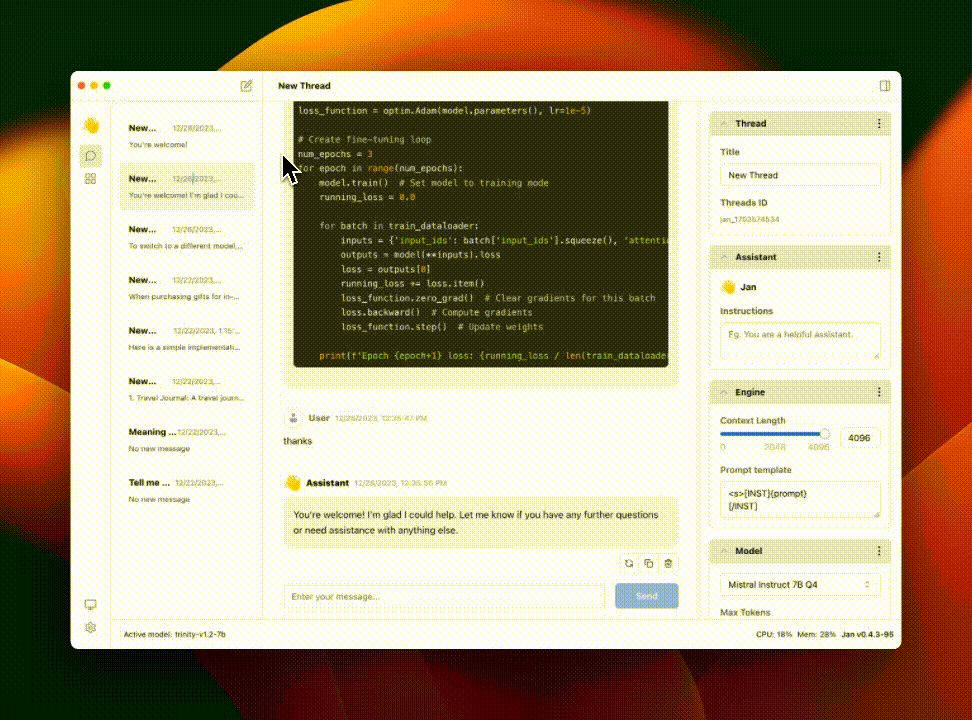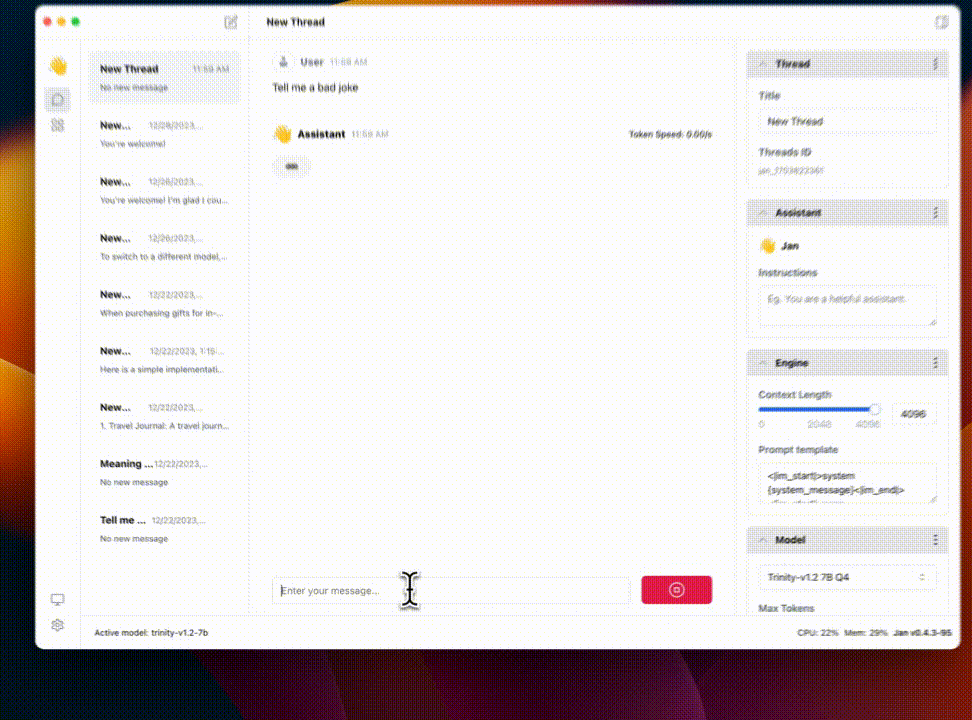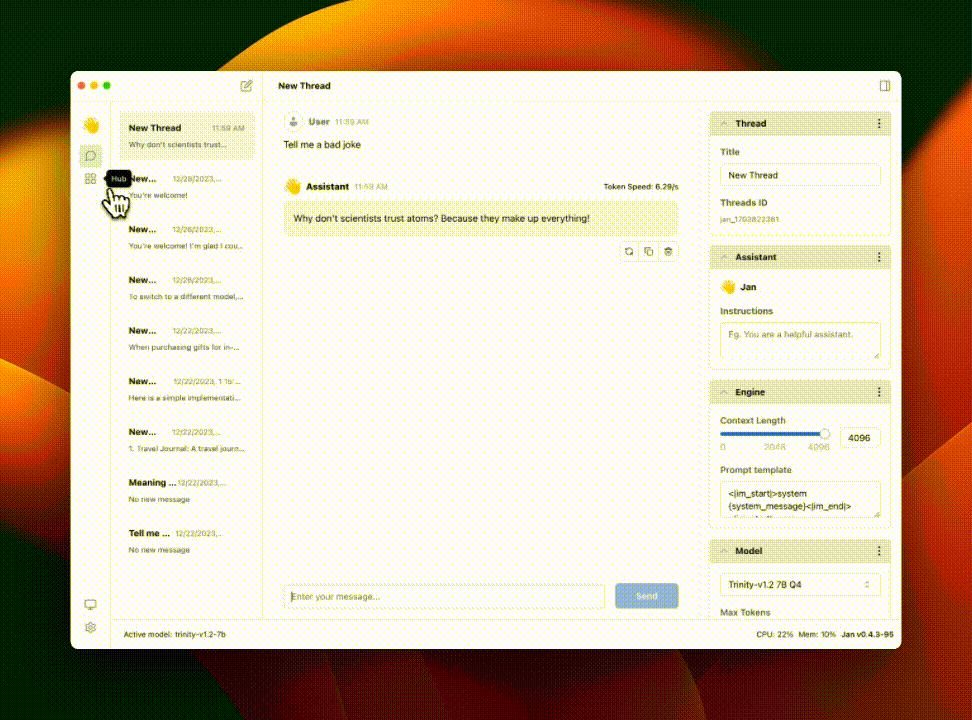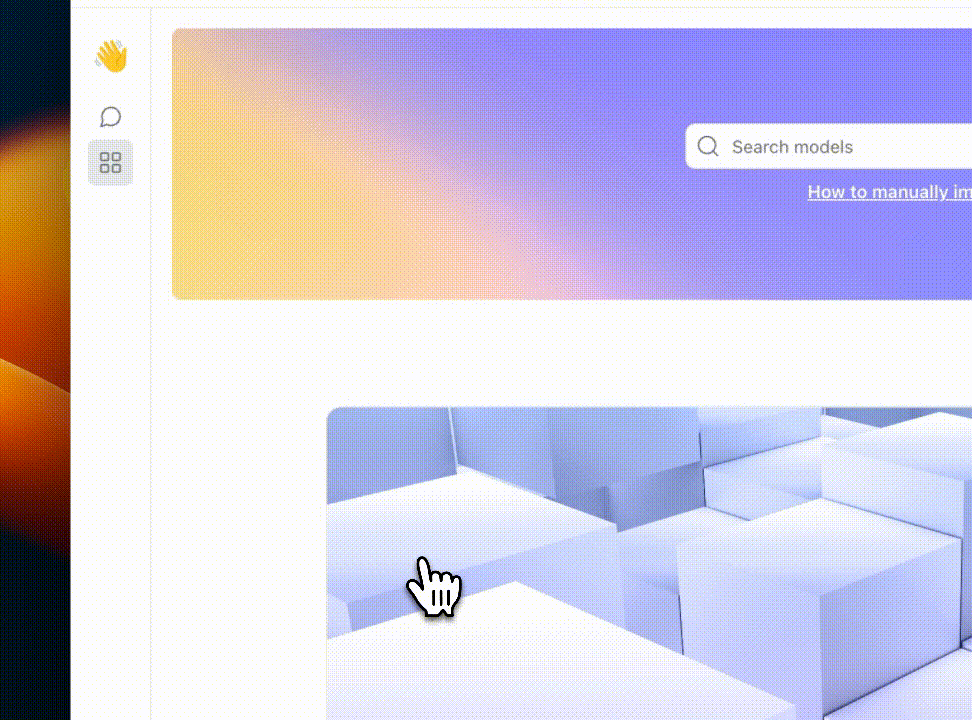
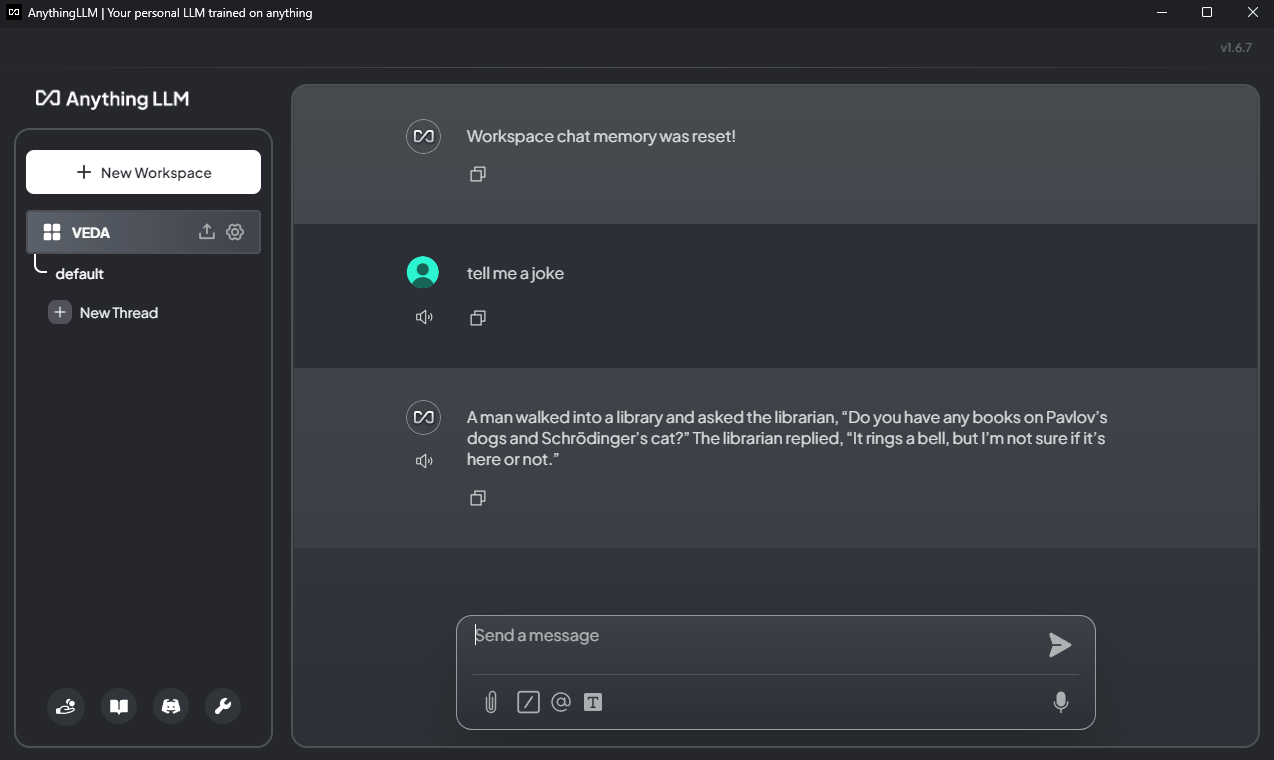
Summary: Discover, download, and run local LLMs
- Desktop application that is easy to install and use
- Provides an HTTP server for use with other applications (like AnythingLLM)
- Allows access to state of the art models
- User friendly interface
LM Studio
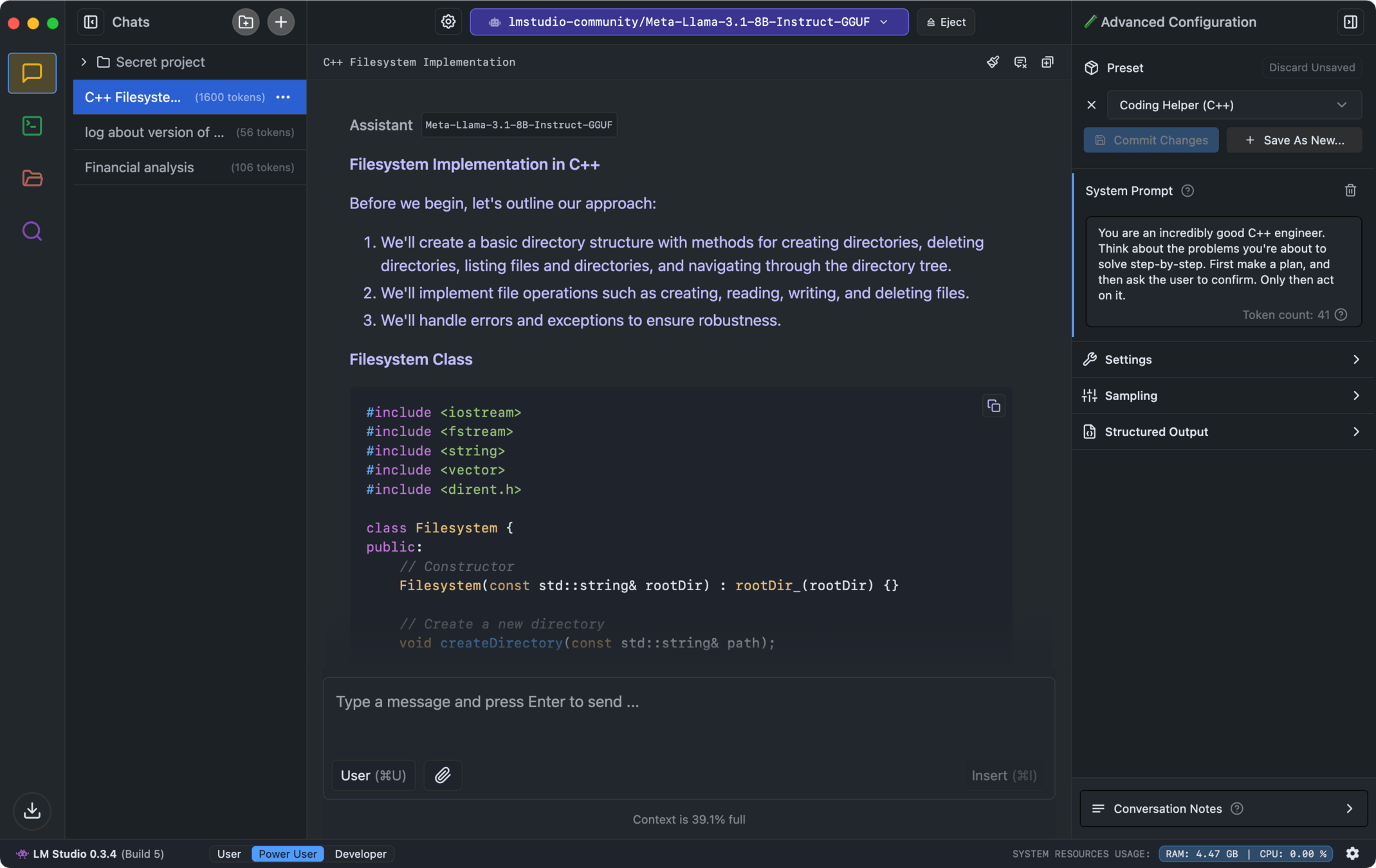
Summary: The all-in-one AI application - Any LLM, any document, any agent, fully private.
- Desktop application that is easy to install and use
- Allows access to state of the art models
- User friendly interface
- Enables RAG-like capability via "agents"
anythingllm
fine-tune inputs to a base model
- A "base model" is basically a pre-trained model, a model that is already capable to some degree
- Popular options to minimize dependence on high performance compute and technical expertise while maximizing performance are Retrieval-Augmented Generation (RAG) and Prompt Engineering
- RAG uses embedding models and vector databases to provide LLMs with enhanced context
- Prompt Engineering essentially asks better questions with techniques like question templates
fine-tune inputs to a base model
Requires
External
Context
Requires Changes to Model
RAG
Prompt
Engineering
Fine-tuning
retrieval-augmented generation
- Process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response...extends the already powerful capabilities of LLMs to specific domains or an organization's internal knowledge base, all without the need to retrain the model. It is a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts.
retrieval-augmented generation
Embedding
Model
>>> Tell me a jokeDocuments
Large Language
Model
Vector Database
Embeddings
User Prompt
Custom Data
Prompt + Context
Why don't eggs tell jokes?
(wait for it...)
Because they'd crack each other up!Popular Libraries for RAGs
- 🦙 LlamaIndex
- 🔗 LangChain
prompt engineering
<question>?Q: <Question>?
A: <Answer>
Q: <Question>?
A: <Answer>
Q: <Question>?
A:Popular prompt engineering techniques
- zero-shot prompting
- few-shot prompting
- chain-of-thought (CoT)
- instruction tuning
VS.
…around half of the improvement in language models over the past four years comes from training them on more data
Will We Run Out of Data? An Analysis of the Limits of Scaling Datasets in Machine Learning
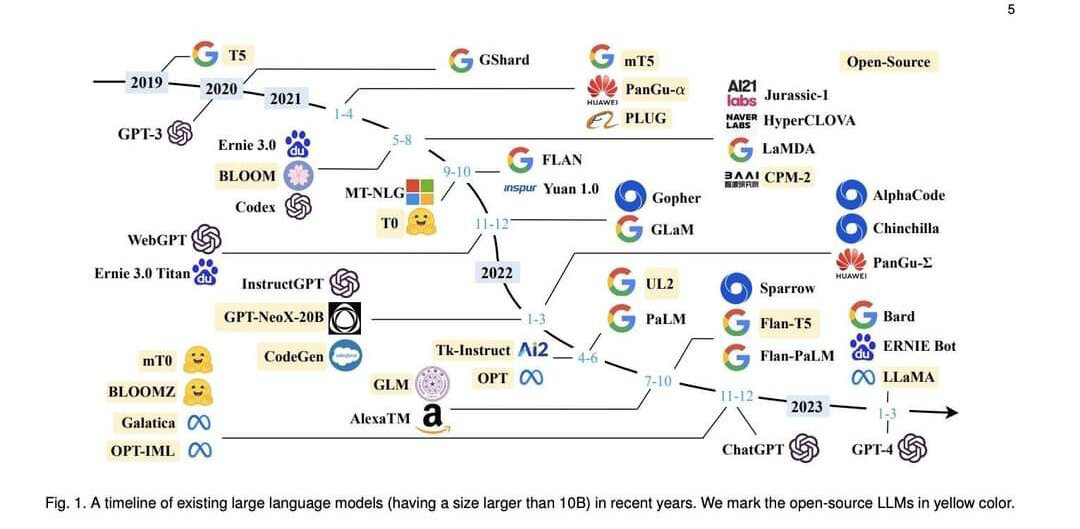
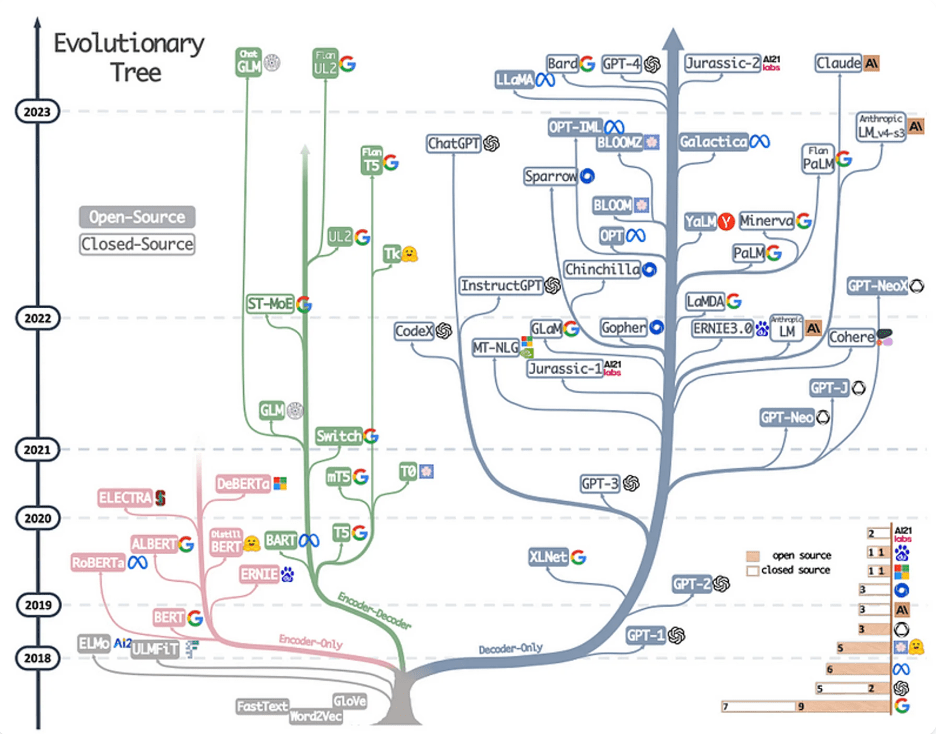
fine-tune base model / train new model
- This is an active area of research and typically only viable for organizations with access to high performance computing capabilities like Google, Meta, IBM, or ORNL
- More layers of complexity on top of fine-tuning
- You probably don't need to do this
References
- R. Tufano, A. Mastropaolo, F. Pepe, O. Dabić, M. Di Penta, and G. Bavota, “Unveiling ChatGPT’s Usage in Open Source Projects: A Mining-based Study.” arXiv, Feb. 26, 2024. Accessed: Apr. 20, 2024. [Online]. Available: http://arxiv.org/abs/2402.16480
- Y. Liu, J. Cao, C. Liu, K. Ding, and L. Jin, “Datasets for Large Language Models: A Comprehensive Survey.” arXiv, Feb. 27, 2024. Accessed: Mar. 05, 2024. [Online]. Available: http://arxiv.org/abs/2402.18041
- Z. Zhang et al., “A Survey on Language Models for Code.” arXiv, Nov. 14, 2023. doi: 10.48550/arXiv.2311.07989.
- P. Valero-Lara et al., “Comparing Llama-2 and GPT-3 LLMs for HPC kernels generation.” arXiv, Sep. 11, 2023. Accessed: Oct. 31, 2023. [Online]. Available: http://arxiv.org/abs/2309.07103
- S. Zhang et al., “Instruction Tuning for Large Language Models: A Survey.” arXiv, Aug. 21, 2023. doi: 10.48550/arXiv.2308.10792.
- J. Kaddour, J. Harris, M. Mozes, H. Bradley, R. Raileanu, and R. McHardy, “Challenges and Applications of Large Language Models.” arXiv, Jul. 19, 2023. doi: 10.48550/arXiv.2307.10169.
- J. Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” arXiv, Jan. 10, 2023. doi: 10.48550/arXiv.2201.11903.
- L. Beurer-Kellner, M. Fischer, and M. Vechev, “Prompting Is Programming: A Query Language for Large Language Models,” Proc. ACM Program. Lang., vol. 7, no. PLDI, pp. 1946–1969, Jun. 2023, doi: 10.1145/3591300.
- Y. Chang et al., “A Survey on Evaluation of Large Language Models.” arXiv, Jul. 06, 2023. doi: 10.48550/arXiv.2307.03109.
- J. D. Zamfrescu-Pereira, R. Wong, B. Hartmann, and Q. Yang, “Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts,” 2023.
- S. Zhang et al., “OPT: Open Pre-trained Transformer Language Models.” arXiv, Jun. 21, 2022. doi: 10.48550/arXiv.2205.01068.
- W. X. Zhao et al., “A Survey of Large Language Models.” arXiv, Mar. 31, 2023. Accessed: Apr. 06, 2023. [Online]. Available: http://arxiv.org/abs/2303.18223
- J. Wei et al., “Finetuned Language Models Are Zero-Shot Learners.” arXiv, Feb. 08, 2022. Accessed: Mar. 09, 2023. [Online]. Available: http://arxiv.org/abs/2109.01652
Large Language Models
By Jason Wohlgemuth




