James Sherry
Web Development Tutor and Co-Founder of { The Jump } Digital School
git log --all --decorate --oneline --graph
git log --branches=* - to see commits on all 'branches'
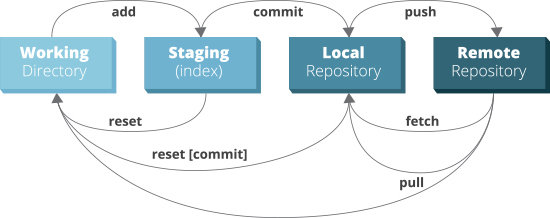
--soft: removes commit & put changes back to staging
--mixed (default): removes commit & put changes back to working dir
--hard: removes commit & reverts tracked files to the previous state (git clean to remove untracked), effectively deleting changes
This stuff works if your changing stuff locally. IF YOU'VE PUSHED, then git revert is your friend!
A branch is just a version of the codebase
git branch -M main (if you're on master)
git config --global init.defaultBranch main
<<<<<<<<<<<<<<<<< HEAD
console.log('Hello');
=================
console.log('Hello world');
>>>>>>>>>>>>>>>>> s67d8f6s7d86fs789d6AutoMerging index.html
CONFLICT (content): Merge conflict in index.html
Automatic merging failed: Fix conlicts and merge the resultConflicts (use like git conflicts)
git config --global alias.overview "log --graph --format=format:'%C(bold blue)%h%C(reset) - %C(bold green)(%ar)%C(reset) %C(white)%an%C(reset)%C(bold yellow)%d%C(reset) %C(dim white)- %s%C(reset)' --all"Better logging (credit):
git config --global alias.conflicts "diff --name-only --diff-filter=U"By James Sherry
A basic workflow introduction


