pandas
Joel Ross
IMT 511
pandas:
Series
Joel Ross
IMT 511
pandas
Python Data Analysis Library
# import the library
import pandas as pd # standard shortcut
import numpy as np # underlying frameworkSeries
Series are one-dimensional ordered collections of values (similar to a list). Values are also given indices as labels (similar to dictionary keys).
# create a Series from a list
number_series = pd.Series([1, 2, 2, 3, 5, 8])
print(number_series)
# create a Series from a dictionary
age_series = pd.Series({'sarah':42, 'amit':35, 'zhang':13})
print(age_series)
Series Operations
Basic operations on Series are applied pair-wise, matching elements with the same index label (unmatched elements give NaN).
3
1
4
1
5
1
6
1
8
0
s1 = pd.Series([3, 1, 4, 1, 5])
s2 = pd.Series([1, 6, 1, 8, 0])
s3 = s1 + s2 # Add the Series
s4 = s1 > s2 # Compare the Series
4
7
5
9
5
+
3
1
4
1
5
1
6
1
8
0
>
=
=
True
False
True
False
True
Series of booleans!
Broadcasting
If one operand is a scalar (a single value), that value is broadcast across the Series.
3
1
4
1
5
4
sample = pd.Series([3,1,4,1,5])
result = sample + 4 # add 4 to each element
print(result)7
5
8
5
9
+
3
1
4
1
5
2
True
False
True
False
True
>
=
=
Series of booleans!
Series Methods
Series provide many methods (called on the Series, with dot notation), including:

Accessing Series
Elements in a Series can be accessed via bracket notation using the index label.
number_series = pd.Series([1, 2, 2, 3, 5, 8])
age_series = pd.Series({'sarah':42, 'amit':35, 'zhang':13})
# get the 1th element from the number_series
number_series[1] # 2
# get the 'amit' element from age_series
age_series['amit'] # 35
# get the 0th element from age_series
# (Series are ordered, so can be accessed positionally)
# (when created from a dict they are ordered by key,
# which is not always in the same order as the literal)!
age_series[0] # 35, because "amit" comes before "sarah"Multiple Indices
We can also specify sequences (e.g., lists) of elements to access. This returns a new Series.
ages = pd.Series({'sarah':42, 'amit':35, 'zhang':13})
index_list = ['sarah', 'zhang']
print( ages[index_list] )
# using an anonymous variable for the index list
# (notice the brackets!)
print( ages[['sarah', 'zhang']] )
Boolean Indexing
We can use a sequence of
boolean values (True,
False). This will extract every element that corresponds with
True (or is a "truthy" value).
vowels = pd.Series[('a','e','i','o','u')]
# List of elements to extract
filter_indices = [True, False, False, True, True]
# Extract every element corresponding to True
list( vowels[filter_indices] ) # "a" "o" "u""a"
"e"
"i"
"o"
"u"
"a"
"o"
"u"
[
=
]
True
False
False
True
True
When combined with relational operators, we can use this approach to filter Series elements by a criteria!
shoe_sizes = pd.Series([(5.5, 11, 7, 8, 4])
small_sizes = shoe_sizes < 6 # True, False, False, False, True
small_shoes = shoe_sizes[small_sizes] # has values 5.5, 4
# as one line: "shoe sizes, where shoe sizes is less than 6"
small_shoes = shoe_sizes[shoe_sizes < 6]5.5
4
[
=
]
5.5
11
7
8
4
6
True
False
False
False
True
<
=
5.5
11
7
8
4
Boolean Indexing
pandas:
DataFrames
Joel Ross
IMT 511
DataFrames
DataFrames are two-dimensional collections of values, organized into rows and columns (like a table). Think of it as a dictionary of Series (each Series is a column).
column Series
row index label
column
labels
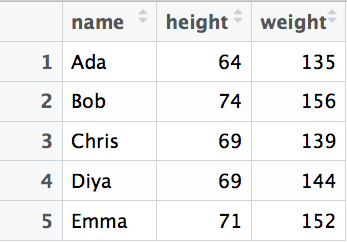
Creating DataFrames
Usually create DataFrame objects from a dictionary of columns (values can be anything that turns into a Series)
name_series = pd.Series(['Ada','Bob','Chris','Diya','Emma'])
heights = [64, 74, 69, 69, 71]
weights = [135, 156, 139, 144, 152]
people_df = pd.DataFrame({'name': name_series,
'height': heights,
'weight': weights})
print(people_df)DataFrame Operations
Basic operations on DataFrames are applied element-wise. If the other operand is a scalar, it produces a new DataFrame where each element is modified.
# data frame of test scores
test_scores = pd.DataFrame({
'math':[91, 82, 93, 100, 78, 91],
'spanish':[88, 79, 77, 99, 88, 93]
})
# Mathematical operators apply to each element in the data frame
curved_scores = test_scores * 1.02 # curve scores up by 2%
print(curved_scores)
# math spanish
# 0 92.82 89.76
# 1 83.64 80.58
# 2 94.86 78.54
# 3 102.00 100.98
# 4 79.56 89.76
# 5 92.82 94.86DataFrame Methods
DataFrames provide many of the same methods as Series

DataFrame Methods
DataFrame methods are usually applied per column:
- If a Series version of the method would return a scalar, then the DataFrame version returns a Series whose index labels are the column labels.
- If a Series version of the method would return a Series, then the DataFrame version returns a DataFrame whose columns are each of the resulting Series.
Accessing DataFrames
DataFrames are like a dictionary of columns, so can access each column by its index label using bracket notation:
df = pd.DataFrame({
'name':['Ada','Bob','Chris','Diya','Emma'],
'height':[64, 74, 69, 69, 71],
'weight':[135, 156, 139, 144, 152]
})
print( df['height'] )You can also access each column as an attribute of the object using dot notation:
print( df.height )Accessing DataFrames
It is possible to select multiple columns using a list of column labels:
# count the brackets carefully!
print( df[['name', 'height']] ) # get name and height cols
# supports boolean indexing on ROWS
print( df[ df.height > 60 ] ) # get ROWS with height > 60 DataFrame Index Lookup
DataFrames provide two attributes loc and iloc which act as "look-up tables" for individual elements. Think of them as dictionaries wth a variety of keys!

pandas:
Grouping
Joel Ross
IMT 511
groupby()
The groupby() method "separates" the rows of a DataFrame into groups. The rows in each grouping share the same value in a particular column.

Aggregation Methods
Aggregation methods (such as max(), mean(), all(), etc) are applied to each group. The result is a DataFrame whose rows are the results of each individual group.
The agg() method
You can apply multiple aggregations to specific columns by using the agg() method.
# Apply multiple aggregation functions at once
# by passing in a list of function names (as strings)
range_stats_df = by_section_groups.agg(['min', 'mean', 'max'])
# Named aggregations: apply specific aggregations to specific columns
# The argument name is what will be given to the aggregate column
# each argument is a tuple: (column_name, aggregation_function)
custom_stats_df = by_section_groups.agg(
avg_mid=('midterm', 'mean'),
avg_final=('final', 'mean'),
max_final=('final', 'max')
)
imt511-pandas
By Joel Ross



