Pandas
and other cool things
Катаев Денис
AI Center - Chatbot CTO
Кто я
4 команды, 30 человек, ищем еще
Продукты:
- Ассистент Олег
- Бот поддержки
Активности:
- Куча докладов, особенно про SQLAlchemy
- Самая большая команда в ТЦР Екб

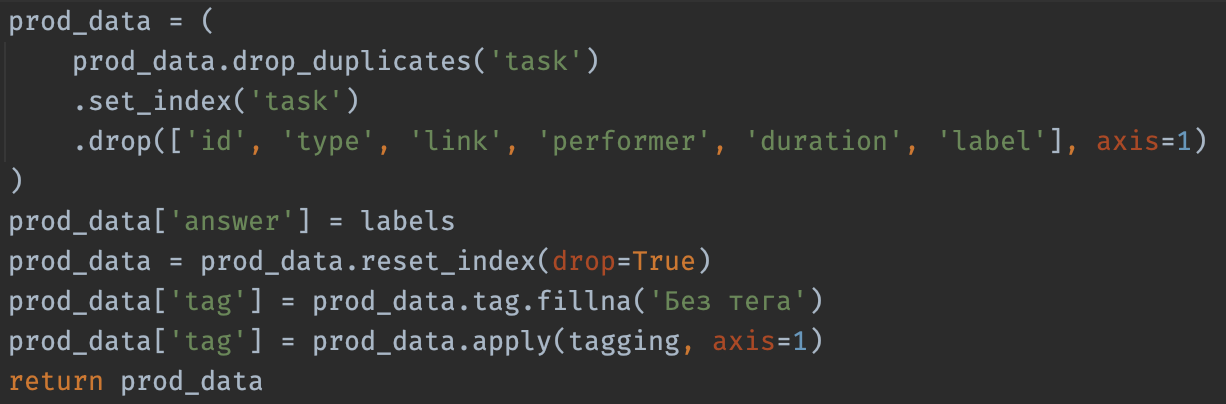
Типичный код на pandas
Нравится? Читаемо?
chaining
jQuery style lol
.pipe(func, args, kw, ...)
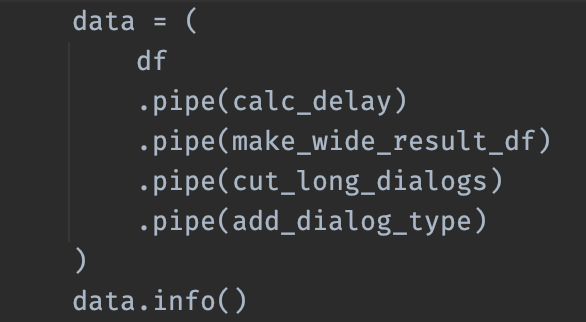
.assign(new=lambda df: ...)
- Создание колонок без warning'ов copy что-то там
- Можно chain'ить
-
Не мутирует данные!
-
Вообще мутация данных не очень
How NOT to deal with SettingWithCopyWarning in Pandas:

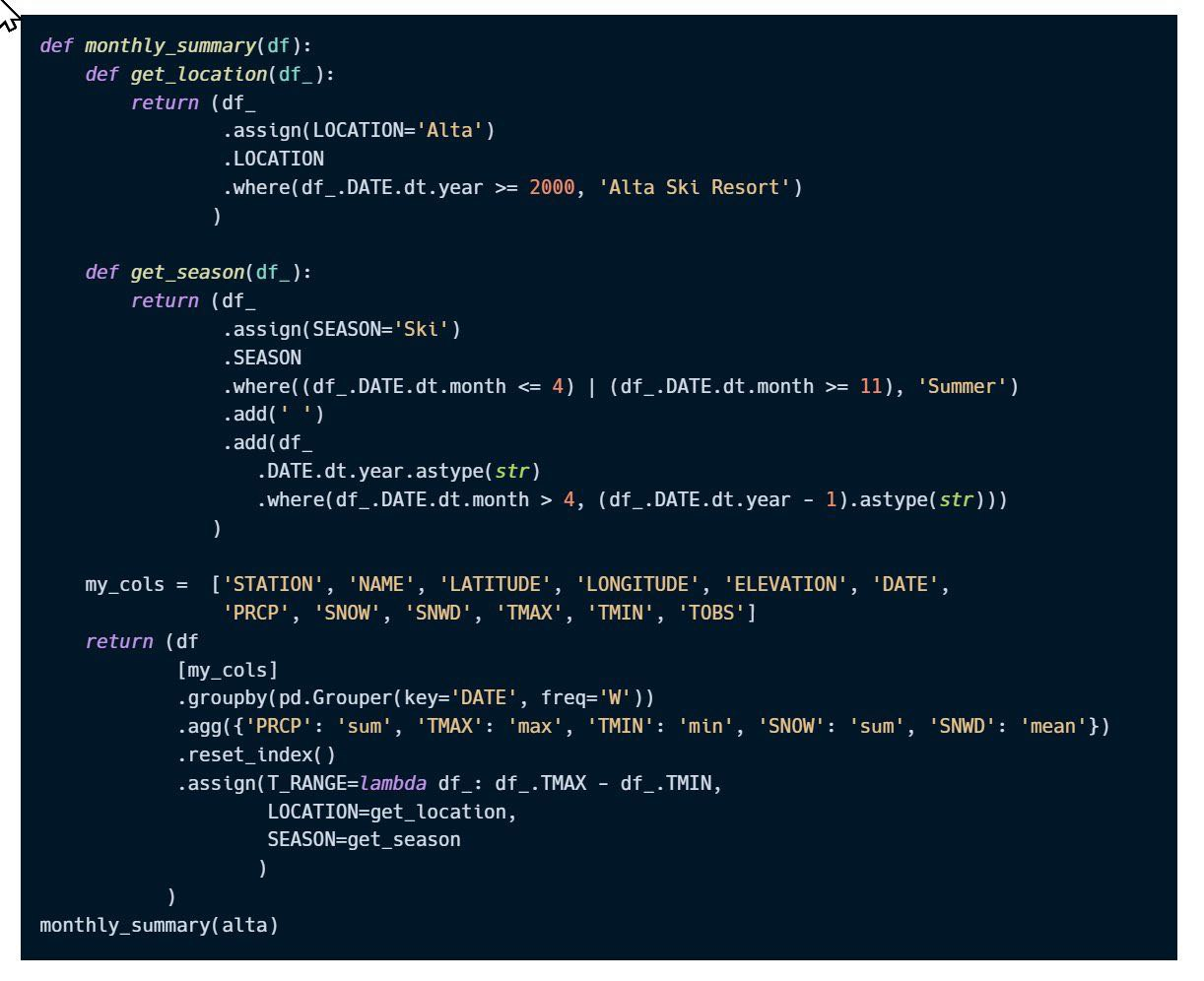

Еще больше
Я думаю у него цель в 1 строку всё сделать
Корректные типы
если в df.info() есть object, это в целом красный флаг
ну кроме что строк
Есть типы unsigned которые занимают в 2 раза меньше
Есть типы уменьшенной размерности uint8, float16 и т.д
.astype('category')
Всё просто
- Меньше типы
- меньше памяти
- быстрей операции
.query(...)
Фильтруем df по простым условиям
Порой удобно фильтровать в цепочке вызовов
Внутри есть eval

kek = "asd"
df.query("lol = @kek")
df.query("lol = 'lol'")Чуточку PHP-style правда
Синтаксис с @kek ломает читаемость, линтеры и автоматические рефакторинг
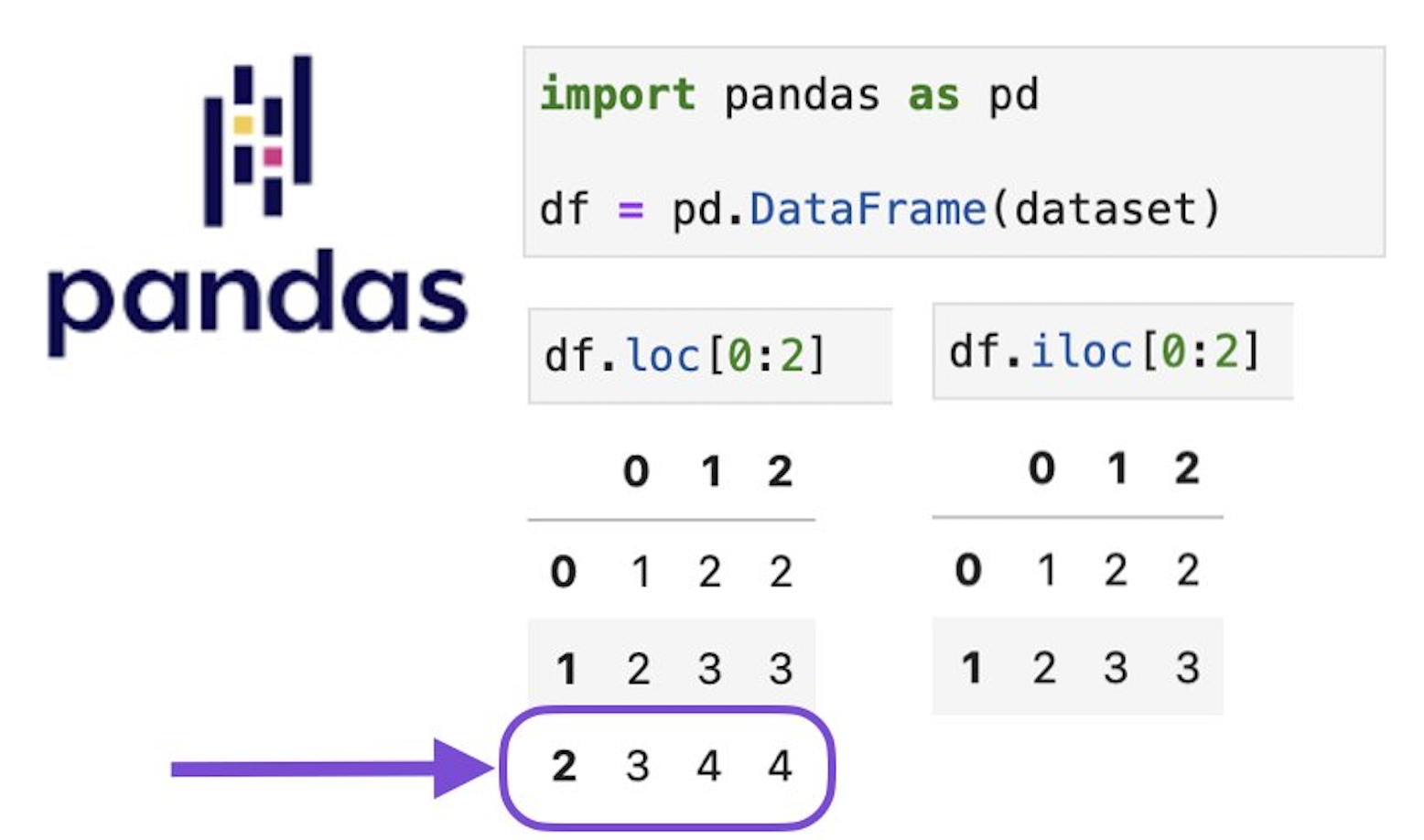
Выборка
через .loc[...]
.loc[lambda df: ...]
Минус еще один повод иметь ссылку на df{1,2,..._tmp}

Опасайтесь банкнот банка приколов
.loc[index, cols]
index? Что такое индекс?
Иерархичные индексы
MultiIndex в индексе или в колонках
Это не для новичков, но корректное использование индексов существенно ускоряет выборки
Если часто берете данные по каким-то полям,
почему бы не засунуть это в индекс?
Кандат для h.index
.loc[df.f1 == '..' & df.f2 == '@@']
.stack(...) & unstack(...)
Очень крутая штука
связанная с иерархическим индексом
.to_frame(...)
Превращает колонку в df
.to_frame(name='...')
Задаёт имя колонке в df для той серии
Пример
.groupby([...])['f1'].mean().to_frame('f1_mean')
df.join
Эффективно соединяет данные по индексу
df.merge более универсальный метод, может работать так же, но более многословен в некоторых ситуациях
pd.concat([df1, df2, ...])
Соединяет несколько df
есть аргумент axis позволяет соединять так и сяк
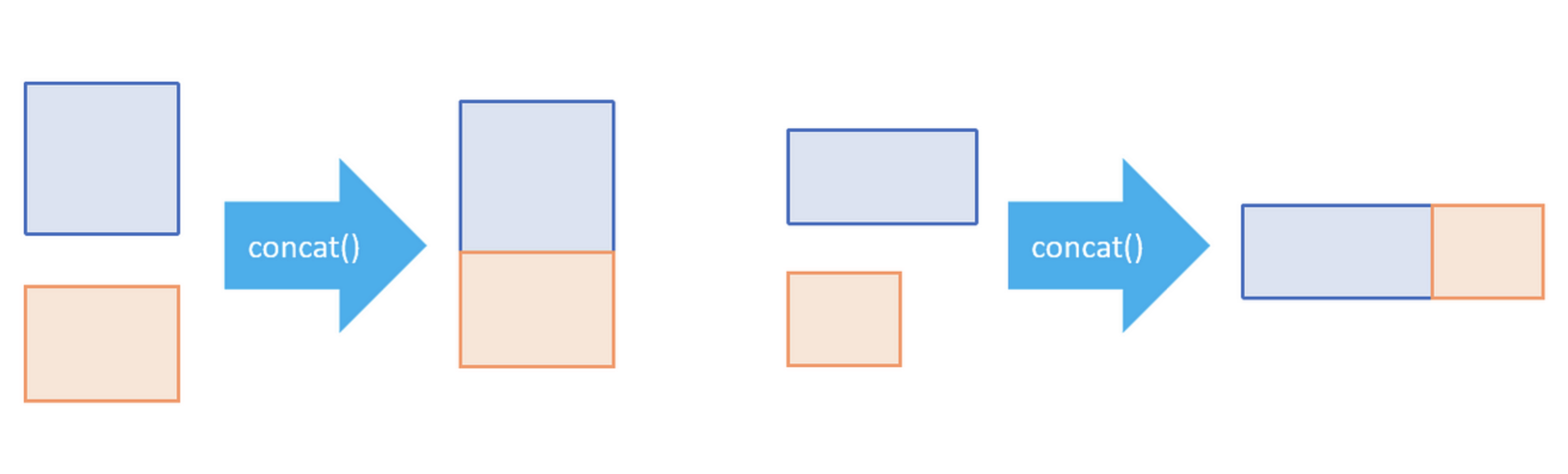

Пример где нужен pd.concat
ну и .pipe() если честно
.apply
Две большие разницы
df.apply(lambda df: ...)
df[...].apply(lambda val: ...)- В первом случае можно использовать векторизацию
- Во втором тоже, но только если np.ufunc
- lambda уже не прокатит
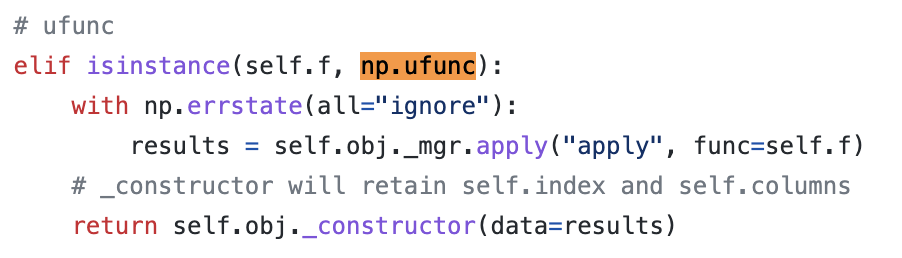
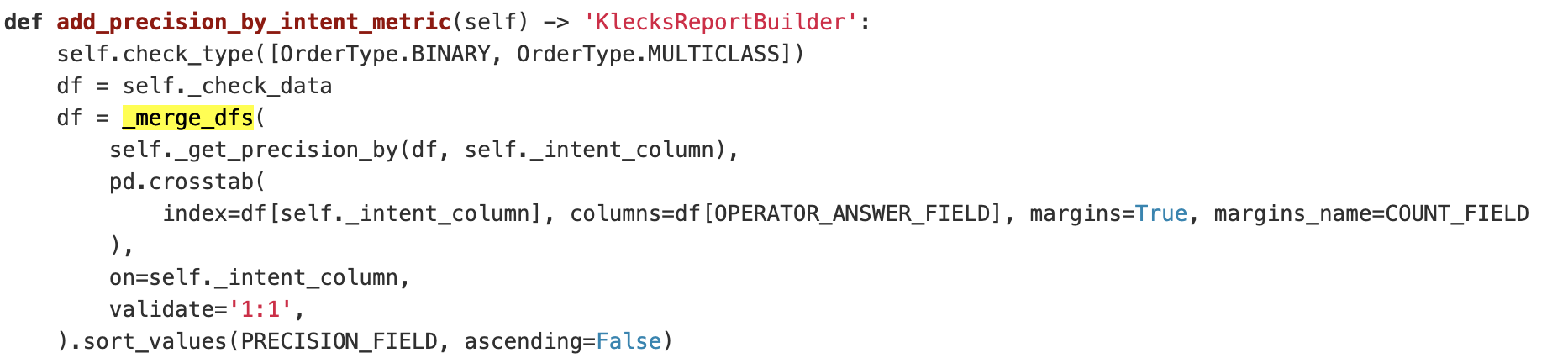
Series.apply
Пруф что используется векторизированный код

Что тут не так?
- берем колонку 'intent_id'
- заменяем значения на UNK там где 'answer' == 'yes'
- почему у колонки answer не bool тип
- Series.where(cond, other, ...)
df.assign(
true_intent_id=lambda df: df['intent_id'].where(df['asnwer'] != 'yes', UNK)
)Как то так:
Метод полностью векторизирован
.apply vs .assign
- Применяется к df и series давая разный результат
- Возвращает серию которую еще куда то надо засунуть...
- И этим разрывает channing
- Легко сломать векторизацию
- Применяется только к df
- Сам создает колонки
- Можно использовать друг за другом, объединяя последовательно разные колонки!
Vectorization
Что это вообще?!
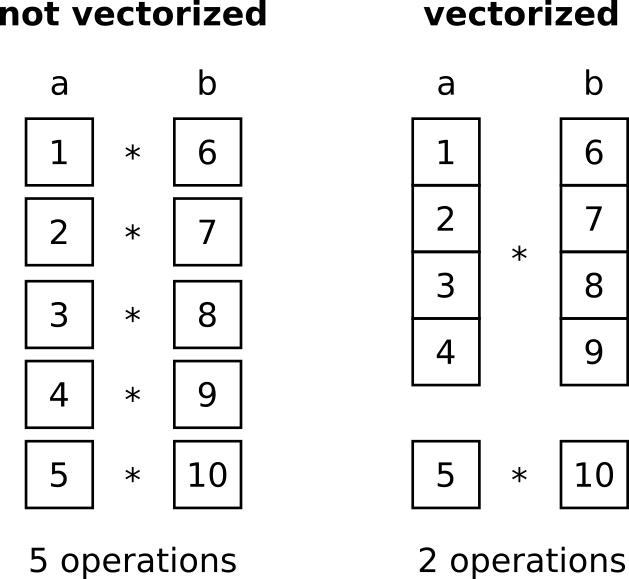
Одна из причин
почему питон медленный и почему быстрый
import pandas as pd
import numpy as np
import perfplot
def some_apply(x):
return np.log(x)
out = perfplot.bench(
setup=lambda n: pd.DataFrame(dict(kek=np.random.rand(n))),
kernels=[
lambda df: df['kek'].apply(some_apply),
lambda df: df['kek'].apply(lambda x: np.log(x)),
lambda df: df['kek'].apply(np.log),
],
labels=[
"series_apply_func",
"series_apply_lambda",
"series_apply_lambda_ufunc"
],
n_range=[2 ** k for k in range(20)],
xlabel="len(a)",
)
out.save("perf.png")
Векторизация
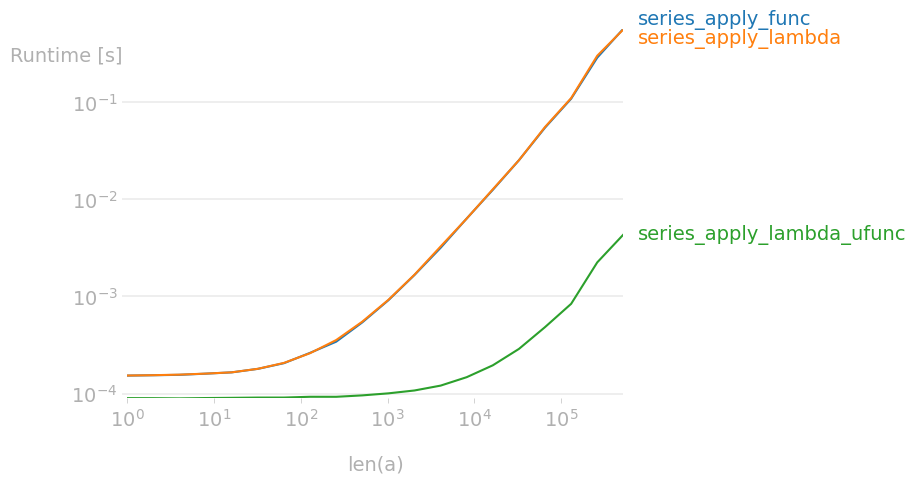
Короче говоря
- Не применяйте .apply к колонкам
- df.apply(..., axis=1) вообще superslow
- Старайтесь не итерироваться по элементам
- Когда применяете всё же .apply думайте к чему
- к df значит в lambda придет df, а не col или row
- на это вообще линтер надо написать!
- преобразования колонки с текстом таким образом не ускорить, но это не повод лепить везде .apply(lambda ...)
Series.str.{...}
Векторизованные методы
LOL
https://github.com/pandas-dev/pandas/issues/35864
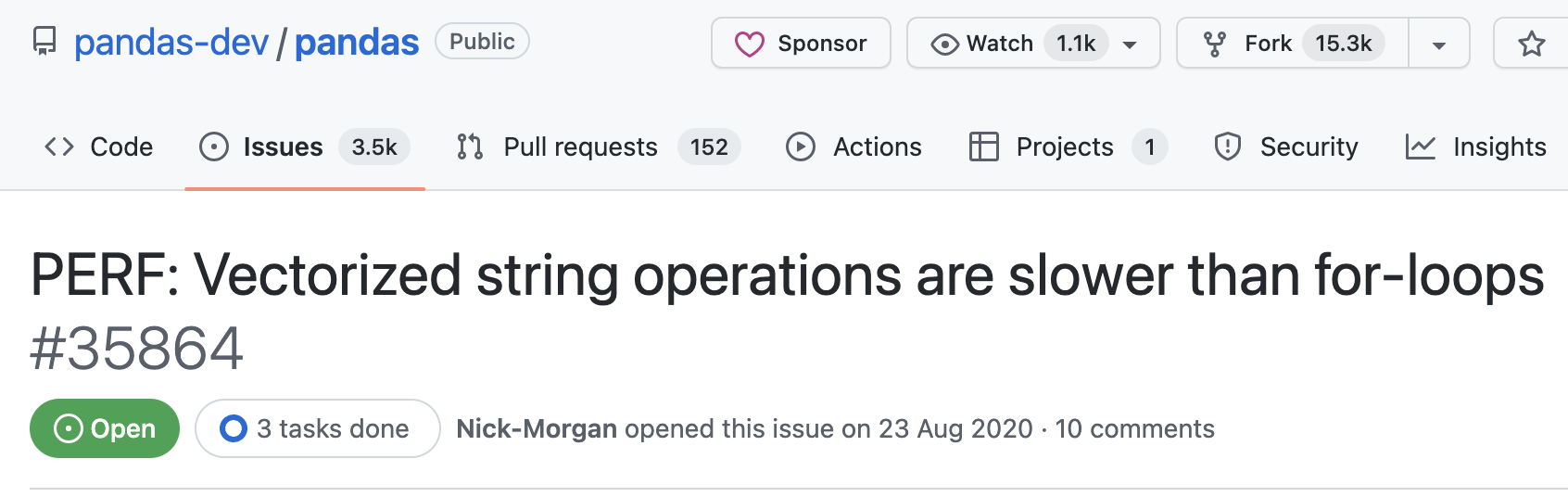
Что делать?
https://www.gresearch.co.uk/blog/article/faster-string-processing-in-pandas/
В посте разбирает скорость операций над 100 миллион строк


spaCy
spaCy’s core data structures are implemented as Cython cdef
Pandas 2.0 & Arrow

pandas.Series(['foo', 'bar', 'foobar'], dtype='string[pyarrow]')Типы вместе с pandera
pydantic для pandas
Описываем схему
И mypy даёт по жопе

Пример схемы
Схемы и типы
- на весь df
- на колонку
- самописные проверки
- hypothesis например two_sample_test

Тесты без говняка
pytest-snapshot
Почему писать тесты на ETL противно?
Сложно зафиксировать эталон, потому что он будет меняться вместе с ETL
Допустим есть код
- на вход df
- на выход df
- берем любой валидный входящий dataset
- дампим валидную часть в git в виде csv
- читаем его в тесте в pd.read_csv(...)
- применяем код
- дампим выход на диск в csv
- ...
- через дни, недели, месяцы, годы ...
- рефакторим код
- проверяем что вывод такой же!
Защита от случайного изменения поведения
Цель улучшить UX когда изменения сознательные!
pytest-snapshot
pytest --snapshot-update
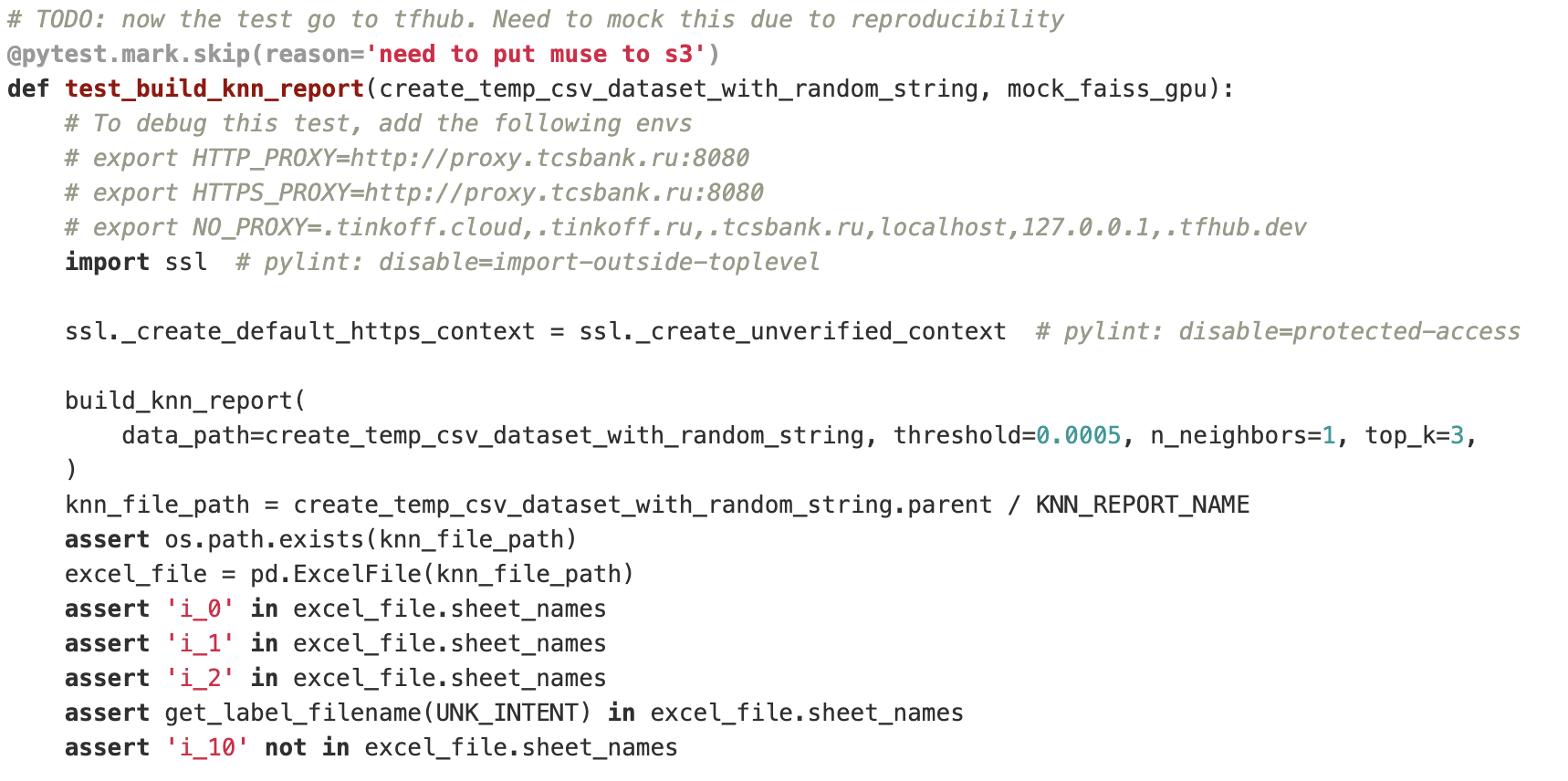
def test_knn_result(tmp_path, snapshot):
snapshot.snapshot_dir = ROOT_DIR / 'snapshots'
dataset = ROOT_DIR / 'data' / 'dataset_junior_test.csv'
df = pd.read_csv(dataset)
builder = KnnReportBuilder(df=df, ...)
assert builder.fit_knn() is None
result = builder.predict()
labels_consistency = (
builder.
calculate_consistency(result, column='label')
.to_frame('score')
)
snapshot.assert_match(
to_snapshot(labels_consistency),
'labels_consistency.jsonl'
)Путь до эталона, чтоб он мог туда записать
def to_snapshot(df: pd.DataFrame) -> str:
return (
df.reset_index()
.to_json(lines=True,
orient='records',
force_ascii=False)
)
Сравним со старым тестом
Тестирование
- фиксируем seed если надо
- пробуем несколько датасетов если надо
- воспроизводимые тесты
- легко исправляются после изменения кода
Другой пример
Генерация случайных данных, тест проходит

Прикол в функции
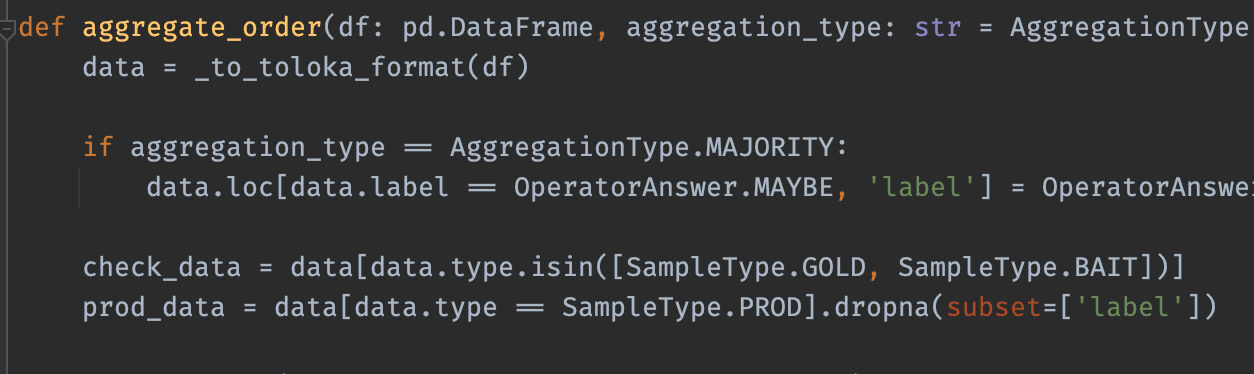
Пустой df, т.к в генерации не учли колонку type
Тест проходил
но только на 1.1.4
В 1.5 добавили проверку что нельзя вставить пустой df
А prod_data.apply(...) как раз нулевой длины
Решение?
Я удолил тест
- Можно было взять реальный пример
- Проверка схемы тоже помогла бы
Почему тесты это важно?
- Это единственный способ делать код поддерживаемым
- Сами тесты это код, т.е тесты должны быть тоже поддерживаемыми чтоб они работали
- Рефакторинг без тестов очень сложный
- Без тестов не хочется менять код, если ты его не меняешь ты умираешь
Итого
- пишем красивый и понятный код на пандас
- пишем код который несколько быстрее
- пишем типы и валидацию схемы
- пишем удобные тесты
Требуем pandas 2.0
в helicopter и zero copy между dwh и python
подписывайте петицию (её нет)
Всем спасибо
Pandas
By Denis Kataev




