智慧治理實務
永續報告書內容分析
真理大學微學分課程
智慧健康永續學分系列課程-ESG投資
關於永續報告書
Sustainability Reports
永續報告書公司治理中心

永續報告書公開資訊觀測站

永續報告書公開資訊觀測站

CSV檔內有連結

The Quality of Sustainability Report


內容分析智慧型
Content Analysis with AI
How to Analyze
資料收集
資料分析與結果呈現



資料爬蟲
資料爬蟲
資料清理
前處理

內容分析


視覺化
資料分析
內容分析任務(tasks)
資料爬蟲
資料清理

文章
哪些可能的任務?
情感分析 (Sentiment Analysis)
主題分析 (Topic Analysis/ Thematic Analysis)
新聞分類 (News Categorization)
多標籤分類(Multilabel Classification)
問答 (Question Answering)
自然語言推論 (Natural Language Inference )
自動摘要 (automatic Abstracting)
機器翻譯 (Machine Translation)
文本分析常見任務

情感分析(Sentiment Analysis)
負面評價Negative
這家店的售後服務完全不行
餐點還不錯啦,但是還有改進空間
中性評價neutral
中性評價neutral
正面評價positive
很讚喔,超喜歡你們家的產品
分類問題
情感分析
文本分析常見任務



編碼
輸入層
隱藏層
輸出層
輸出結果分類
真實
政治宣傳
惡搞
反諷
假新聞
帶風向
片面資訊
新聞分類
分類問題
文本分析常見任務

機器翻譯
迴歸問題
Transformer
輸入英文: milk drink I
輸出法文: Je bois du lait <eos>
編碼器
解碼器
編碼器輸出
解碼器輸入
<sos>: 開始符號
<eos>: 結束符號
文本分析常見任務
文本生成

輸入: 一句話
輸出: 一篇短文!
經過多個語言模型...
迴歸問題
How to Analyze scraping
圖片來源1
圖片來源2
2.1 遍訪連結
建立待訪堆疊
1. 從一個網頁開始
2.2 擷取內容
3. 輸出結果(至檔案)
取得HTML回應碼
解析超連結
解析其他HTML元素
資料輸出
資料清理
能力1: 取得HTML回應碼?了解HTTP協定

網址(http request)
瀏覽器
Web 伺服器
HTML回應碼(http response)
How to Analyze Understanding HTTP
http連線功能
➠
能力2: 解析超連結、其他HTML元素、網頁內容 ➠
HTML Parser(解析器)
How to Analyze HTML Parser
以p元素為例
找出超連結元素A,屬性href的值 ➠ 待訪網址

元素
內容
開始標籤
結束標籤
屬性名稱
屬性值
能力2: 解析超連結、其他HTML元素、網頁內容
Parser(解析器)
能力1: 取得HTML回應碼?了解HTTP協定
http連線功能
➠

圖片來源1



How to Analyze Implementation
能力3: 資料清理、資料輸出 ➠
資料處理工具
How to Analyze Data Cleaning
2.1 遍訪連結
建立待訪堆疊
1. 從一個網頁開始
2.2 擷取內容
3. 輸出結果(至檔案)
圖片來源1
圖片來源2
取得HTML回應碼
解析超連結
解析其他HTML元素
資料輸出
資料清理

網路爬蟲實作
☛ 單一頁面版:使用 Requests + BeautilfulSoup4
無限循環版:使用Scraper
Web Scraping範例(單一頁面版)
pip install requests
pip install beautifulsoup4
pip install lxml安裝Requests, BeautilfulSoup套件(使用pip 或 pip3)
parser部分使用lxml(速度快,也可解析XML檔)
若系統找不到pip,改用pip3
Web Scraping範例抓id
import requests
from bs4 import BeautifulSoup
# 假設html為你的HTML頁面內容
html = """
<html>
<head>
<title>示例頁面</title>
</head>
<body>
<div class="content">
<p>這是一個示例頁面。</p>
<div id="unique_id">
<h1>特定ID的內容</h1>
<p>這是要抓取的內容。</p>
</div>
<div class="other">
<p>其他內容。</p>
</div>
</div>
</body>
</html>
"""
# 使用BeautifulSoup解析HTML內容
soup = BeautifulSoup(html, 'html.parser')
# 找到特定ID為"unique_id"的元素
specific_element = soup.find(id='unique_id')
# 輸出特定ID為"unique_id"的元素內容
print(specific_element)
example1.py
beautifulsoup4 抓特定id
Web Scraping範例印內文
import requests
from bs4 import BeautifulSoup
# 假設html為你的HTML頁面內容
html = """
<html>
<head>
<title>示例頁面</title>
</head>
<body>
<div class="content">
<p>這是一個示例頁面。</p>
<div id="unique_id">
<h1>特定ID的內容</h1>
<p>這是要抓取的內容。</p>
</div>
<div class="other">
<p>其他內容。</p>
</div>
</div>
</body>
</html>
"""
# 使用BeautifulSoup解析HTML內容
soup = BeautifulSoup(html, 'html.parser')
# 找到特定ID為"unique_id"的元素
specific_element = soup.find(id='unique_id')
# 輸出特定ID為"unique_id"的元素內容
if specific_element:
content = specific_element.text # 或者使用 specific_element.get_text()
print(content)
else:
print("未找到特定元素")
example2.py
beautifulsoup4 抓特定id後
印出內文
Web Scraping範例抓class
import requests
from bs4 import BeautifulSoup
# 假設html為你的HTML頁面內容
html = """
<html>
<head>
<title>示例頁面</title>
</head>
<body>
<div class="content">
<p>這是一個示例頁面。</p>
<div class="specific_class">
<h1>特定Class的內容 1</h1>
<p>這是要抓取的內容 1。</p>
</div>
<div class="specific_class">
<h1>特定Class的內容 2</h1>
<p>這是要抓取的內容 2。</p>
</div>
<div class="other_class">
<p>其他內容。</p>
</div>
</div>
</body>
</html>
"""
# 使用BeautifulSoup解析HTML內容
soup = BeautifulSoup(html, 'html.parser')
# 找到具有特定class值為"specific_class"的元素
specific_elements = soup.find_all(class_='specific_class')
# 輸出符合特定class值的元素內容
for element in specific_elements:
print(element.get_text())
example3.py
beautifulsoup4 抓特定class
Web Scraping範例抓class
import requests
from bs4 import BeautifulSoup
# 假設html為你的HTML頁面內容
html = """
<html>
<head>
<title>示例頁面</title>
</head>
<body>
<div class="content">
<p>這是一個示例頁面。</p>
<a href="https://example.com/page1">連結到頁面1</a>
<a href="https://example.com/page2">連結到頁面2</a>
<a href="https://example.com/page3">連結到頁面3</a>
<div class="other">
<p>其他內容。</p>
<a href="https://example.com/page4">連結到頁面4</a>
</div>
</div>
</body>
</html>
"""
# 使用BeautifulSoup解析HTML內容
soup = BeautifulSoup(html, 'html.parser')
# 找到所有的超連結(<a>標籤)
all_links = soup.find_all('a')
# 輸出所有超連結的URL
for link in all_links:
print(link.get('href'))
example4.py
beautifulsoup4 抓所有class
Web Scraping範例抓class
import requests
from bs4 import BeautifulSoup
#所要擷取的網站網址
url = 'https://www.ptt.cc/bbs/Mobile-game/M.1700108779.A.D0A.html'
#建立回應
response = requests.get(url)
#印出網站原始碼
#print(response.text)
#將原始碼做整理
soup = BeautifulSoup(response.text, 'lxml')
# 找到具有特定class值的元素
specific_elements = soup.find_all(class_='push')
# 輸出符合特定class值的元素内容
for element in specific_elements:
print(element.get_text())ptt02.py
beautifulsoup4 抓所有class為push的元素
Web Scraping範例抓class
import requests
from bs4 import BeautifulSoup
#所要擷取的網站網址
url = 'https://www.ptt.cc/bbs/Mobile-game/index.html'
base_url = 'https://www.ptt.cc'
#建立回應
response = requests.get(url)
#將原始碼做整理
soup = BeautifulSoup(response.text, 'lxml')
# 找到所有超連結
all_links = soup.find_all('a')
# 印出超連結
for link in all_links:
href = link.get('href')
if href==None:
continue
if "http://" in href or "https://" in href:
print(href)
else:
print(base_url+href)ptt03.py
beautifulsoup4 抓所有超連結
Web Scraping範例單一頁面版
import requests
from bs4 import BeautifulSoup
# Step 1: 發出Http Request, 解析(parse)Http Response
## url: 要擷取的網址
base_url = "http://twbsball.dils.tku.edu.tw" # 網站基礎網址,補絕對網址用
url = "http://twbsball.dils.tku.edu.tw/wiki/index.php/%E5%88%86%E9%A1%9E:%E5%8F%B0%E7%81%A3%E7%90%83%E5%93%A1"
resp = requests.get(url) # 發出HTTP request
if resp.status_code == 200: # 代碼200表示連線正常
soup = BeautifulSoup(resp.content, "lxml") # parsing網頁內容
else:
exit(1) # 非200代碼,程式直接結束
### 維基百科頁面標題特徵: id="firstHeading"
title = soup.find(id="firstHeading") # 根據id值進行搜尋
print(f'頁面標題{title.text}')
### 維基百科頁面內容:假設只對包含在id="mw-pages"內的超連結感興趣
### 注意!!!每個網頁內容的id可能都不一樣!!!必須先詳細了解網頁格式
all_links = soup.find(id="mw-pages").find_all("a") # 找出所有<A>標籤
print(f"超連結數量:{len(all_links):10}")
# 走訪過濾後的<A>標籤:
#### 1. 只對此Wiki站內連結感興趣
#### 2. 只處理球員連結
num_of_link = 0
for link in all_links:
if link['href'].find("/wiki/") == -1: # 站外連結跳過不處理
continue
if link.text == '之後200': # 網頁特定內容,跳過不處理
print(f'type of link:{type(link)}')
continue
print(f"球員:{link.text} 網址:{base_url + link['href']}")
num_of_link += 1
print(f'球員總數{num_of_link:10}')webscraping-link.py
重要:必須先了解該網頁的HTML結構
重點觀察
- 屬性值(id, class),
- 特定標籤<div>, <h>系列, <SPAN>

前往目標網址後,開啟「開發人員工具」(F12)
任務 1: 爬取「球員連結」
但不是「所有超連結」都是球員

移動游標尋找目標區域
div標籤, id值 "mw-pages"
# 以'lxml' parser解析 resp.content的內容
soup = BeautifulSoup(resp.content, "lxml")
...
# 找出mw-pages段落裡面所有<A>標籤
all_links = soup.find(id="mw-pages").find_all("a") 任務 2: 擷取「頁面內容」

有興趣的段落沒有 id, class等屬性值可用
dl, dd, ul, li等標籤無法區分是否為感興趣的段落
url = "擷取的網址"
resp = requests.get(url) # (1)連線
if resp.status_code == 200: # 代碼200表示連線正常
soup = BeautifulSoup(resp.content, "lxml") # (2)分析
else:
exit(1) # 非200代碼,程式直接結束import requests
from bs4 import BeautifulSoupimport需要的模組
連線與分析(parsing)
### 維基百科頁面標題特徵: id="firstHeading"
title = soup.find(id="firstHeading") # 根據id值進行搜尋
print(f'頁面標題{title.text}')擷取任務1: 取得標題
### 維基百科頁面內容:假設只對包含在id="mw-pages"內的超連結感興趣
### 注意!!!每個網頁內容的id可能都不一樣!!!必須先詳細了解網頁格式
all_links = soup.find(id="mw-pages").find_all("a") #找出所有<A>標籤
# 走訪過濾後的<A>標籤:
for link in all_links:
if link['href'].find("/wiki/") == -1: # 站外連結跳過不處理
continue
if link.text == '之後200': # 網頁特定內容,跳過不處理
continue
print(f"球員:{link.text} 網址:{link['href']}") # 印出網址擷取任務2: 取出段落中的超連結
網路爬蟲實作
單一頁面版:使用 Requests + BeautilfulSoup4
☛ 無限循環版:使用Scrapy
Web Scraping範例安裝所需套件
安裝Scrapy, BeautilfulSoup套件(使用pip 或 pip3)
parser部分使用lxml(速度快,也可解析XML檔)
pip install scrapy
pip install beautifulsoup4
pip install lxml若系統找不到pip,改用pip3
此範例使用
效能較佳!
Web Scraping範例建立Scrapy專案
建立Scrapy專案,例如:
scrapy startproject tutorial
你的程式加在這個資料夾內
Web Scraping範例建立爬蟲主程式-手動方式
scrapy startproject mycrawler在這個資料夾內新增
twbaseball_spider.py(任何檔名皆可)

爬蟲主程式#1
資料夾內可以手動新增多隻爬蟲主程式
Web Scraping範例建立爬蟲主程式-指令
scrapy genspider CSRSpider https://cgc.twse.com.tw/生成
CSRSpider.py
CSRSpider.py
Web Scraping範例生成CSRSpider內容
import scrapy
class CsrspiderSpider(scrapy.Spider):
name = 'CSRSpider'
allowed_domains = ['cgc.twse.com.tw']
start_urls = ['https://cgc.twse.com.tw/']
def parse(self, response):
passCSRSpider.py
1. 修改start_urls
2. 加入parse()程式碼
3. 終端機中執行
Web Scraping範例簡單範例
import scrapy
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "quotes" # 2. 為spider取名
start_urls = [ # 3. 頁面擷取串列: 數量不限
'https://quotes.toscrape.com/page/1/', # 爬取網址1
'https://quotes.toscrape.com/page/2/', # 爬取網址2
]
def parse(self, response): # 4. 頁面解析
page = response.url.split("/")[-2] # 4-1 內容解析
# 4-2 資料儲存
filename = f'quotes-{page}.html' # 設定檔名
with open(filename, 'wb') as f:
f.write(response.body) # 寫入網頁<body>內容
self.log(f'Saved file {filename}')twbaseball_spider.py
爬取兩個網頁,將網頁內容寫入檔案
Web Scraping範例(1) 繼承scrapy.Spider
import scrapy
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "quotes" # 2. 為spider取名
start_urls = [ # 3. 頁面擷取串列: 數量不限
'https://quotes.toscrape.com/page/1/', # 爬取網址1
'https://quotes.toscrape.com/page/2/', # 爬取網址2
]
def parse(self, response): # 4. 頁面解析
page = response.url.split("/")[-2] # 4-1 內容解析
# 4-2 資料儲存
filename = f'quotes-{page}.html' # 設定檔名
with open(filename, 'wb') as f:
f.write(response.body) # 寫入網頁<body>內容
self.log(f'Saved file {filename}')twbaseball_spider.py
class名稱自取
Web Scraping範例(2) 為spider取名
import scrapy
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "quotes" # 2. 為spider取名
start_urls = [ # 3. 頁面擷取串列: 數量不限
'https://quotes.toscrape.com/page/1/', # 爬取網址1
'https://quotes.toscrape.com/page/2/', # 爬取網址2
]
def parse(self, response): # 4. 頁面解析
page = response.url.split("/")[-2] # 4-1 內容解析
# 4-2 資料儲存
filename = f'quotes-{page}.html' # 設定檔名
with open(filename, 'wb') as f:
f.write(response.body) # 寫入網頁<body>內容
self.log(f'Saved file {filename}')twbaseball_spider.py
為spider取名
執行程式時,會指定此名稱
Web Scraping範例(3) 設定開始爬取的網址串列
import scrapy
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "quotes" # 2. 為spider取名
start_urls = [ # 3. 頁面擷取串列: 數量不限
'https://quotes.toscrape.com/page/1/', # 爬取網址1
'https://quotes.toscrape.com/page/2/', # 爬取網址2
]
def parse(self, response): # 4. 頁面解析
page = response.url.split("/")[-2] # 4-1 內容解析
# 4-2 資料儲存
filename = f'quotes-{page}.html' # 設定檔名
with open(filename, 'wb') as f:
f.write(response.body) # 寫入網頁<body>內容
self.log(f'Saved file {filename}')twbaseball_spider.py
執行時,依序爬取網頁
但不限於只爬取串列中指定的
網頁
可遞迴呼叫「回呼函式」parse()
達成無限循環
Web Scraping範例(4) 撰寫回呼函式parse()
import scrapy
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "quotes" # 2. 為spider取名
start_urls = [ # 3. 頁面擷取串列: 數量不限
'https://quotes.toscrape.com/page/1/', # 爬取網址1
'https://quotes.toscrape.com/page/2/', # 爬取網址2
]
def parse(self, response): # 4. 頁面解析
page = response.url.split("/")[-2] # 4-1 內容解析
# 4-2 資料儲存
filename = f'quotes-{page}.html' # 設定檔名
with open(filename, 'wb') as f:
f.write(response.body) # 寫入網頁<body>內容
self.log(f'Saved file {filename}')twbaseball_spider.py
回呼函式
透過response參數解析內容
繼續跟進處理其他網址
回傳擷取的資料、儲存...
Web Scraping範例執行
cd mycrawler從「終端機」執行
1. 切換到專案資料最上層!
scrapy crawl quotesscrapy crawl twbaseball2. 執行scrapy crawl指令
spider名稱,自訂於程式碼中
import scrapy
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "quotes" # 2. 為spider取名
start_urls = [ # 3. 頁面擷取串列: 數量不限
'https://quotes.toscrape.com/page/1/', # 爬取網址1
'https://quotes.toscrape.com/page/2/', # 爬取網址2
]
def parse(self, response): # 4. 頁面解析
page = response.url.split("/")[-2] # 4-1 內容解析
# 4-2 資料儲存
filename = f'quotes-{page}.html' # 設定檔名
with open(filename, 'wb') as f:
f.write(response.body) # 寫入網頁<body>內容
self.log(f'Saved file {filename}')克服網站反爬蟲
...
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
#'sreport.middlewares.SreportDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'scrapy_user_agents.middlewares.RandomUserAgentMiddleware': 400,
}
...爬取內容時改變不同的User-Agent值(HTTP header設定)
找到專案內的settings.py
1. 開啟DOWNLOADER_MIDDLEWARES設定
2. 第5行註解掉
3. 加入6,7行
若使用相同的User-Agent值會被封鎖
pip install scrapy-user-agentsWeb Scraping範例抓id印內文-html檔
<html>
<head>
<title>示例頁面</title>
</head>
<body>
<div id="content">
<p>這是一個示例頁面。 </p>
<div id="specific_id">
<h1>特定ID的內容</h1>
<p>這是要找的內容。 </p>
</div>
<div id="other_id">
<p>其他內容。 </p>
</div>
</div>
</body>
</html>
http://example.com/example.html
範例頁面html程式碼
Web Scraping範例抓id印內文, 使用css()函式
import scrapy
class MySpider(scrapy. Spider):
name = 'my_spider'
# 抓取的網址:與上一頁url名稱相同
start_urls = ['http://example.com/example.html']
def parse(self, response):
# 使用CSS選擇器找到id為“specific_id”的元素
# '#'字號代表html id值
specific_element = response.css('#specific_id')
# 處理找到的元素
for element in specific_element:
# 輸出元素內容或其他操作
self.logger.info("Found element: %s", element.get())
# 或是
print(f'找到元素{element.get()}')
MySpider.py
抓特定id後印出內文
Web Scraping範例抓ul下的li
import scrapy
class MySpider(scrapy. Spider):
name = 'my_spider'
def parse(self, response):
# 使用 CSS 選擇器找到特定 ul 元素
# 替換為你的 <ul> 元素的 ID 或其他屬性選擇器
ul_element = response.css('ul#your_ul_id')
# 找到特定 ul 元素下的所有 li 元素
li_elements = ul_element.css('li')
# 處理找到的 li 元素
for li in li_elements:
# 在這裡進行處理
# 例如,列印 li 內容
self.logger.info("Found li: %s", li.get())
MySpider.py
Web Scraping範例抓class, 使用css()函式
import scrapy
class MySpider(scrapy.Spider):
name = 'my_spider'
start_urls = ['https://example.com'] # 你要爬取的網頁 URL
def parse(self, response):
# 使用 CSS 選擇器找到特定 class 值的元素
elements = response.css('.your_class_name')
# 處理找到的元素
for element in elements:
# 在這裡進行處理
# 例如,列印元素內容
self.logger.info("Found element: %s", element.get())
# 或者
print(f'找到元素: {element.get()}')
MySpider.py
抓特定id後印出內文
Web Scraping範例實例:永續報告書
import scrapy
class CsrspiderSpider(scrapy.Spider):
name = 'CSRSpider'
# allowed_domains = ['cgc.twse.com.tw']
start_urls = ['https://cgc.twse.com.tw/corpSocialResponsibility/chPage']
def parse(self, response):
#先找到table <table class="table-rwd">
table = response.css('table.table-rwd')
# 找每一行
rows = table.css('tr') # <tr>...</tr>
print(f'找到{len(rows)}行')
for row in rows:
cells = row.css('td, th') # tr內的所有td或th元素
# data串列:每一個td或th元素
data = [cell.css('::text').get() for cell in cells]
print(f'行:{data}')
CSRSpider.py 抓table
Web Scraping範例實例:永續報告書
import scrapy
class CsrspiderSpider(scrapy.Spider):
name = 'CSRSpider'
# allowed_domains = ['cgc.twse.com.tw']
start_urls = ['https://cgc.twse.com.tw/corpSocialResponsibility/chPage']
def parse(self, response):
#先找到table <table class="table-rwd">
table = response.css('table.table-rwd')
# 找每一行
rows = table.css('tr') # <tr>...</tr>
print(f'找到{len(rows)}行')
for row in rows:
cells = row.css('td, th') # tr內的所有td或th元素
# data串列:每一個td或th元素
data = [cell.css('::text').get() for cell in cells]
for cell in cells:
link = cell.css('a::attr(href)').get()
if not link:
continue
data.append(link)
print(f'行:{data}')
CSRSpider.py 抓table
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Listing Page</title>
</head>
<body>
<h1>Listing Page</h1>
<ul>
<li><a href="https://example.com/page1">Page 1</a></li>
<li><a href="https://example.com/page2">Page 2</a></li>
<li><a href="https://example.com/page3">Page 3</a></li>
<!-- 更多的链接 -->
</ul>
</body>
</html>
HTML頁面 https://example.com/listing
Web Scraping範例抓link後,逐一走訪
Web Scraping範例抓link後,逐一走訪
import scrapy
class LinksSpider(scrapy. Spider):
name = 'links_spider'
# 起始URL
start_urls = ['https://example.com/listing']
def parse(self, response):
# 取得目前頁面的所有連結
links = response.css('a::attr(href)').getall()
# 處理頁面的連結
for link in links:
yield scrapy.Request(
response.urljoin(link),
callback=self.parse
) LinkSpider.py
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Listing Page</title>
</head>
<body>
<h1>Listing Page</h1>
<ul class="listing">
<li><a href="https://example.com/page1">Page 1</a></li>
<li><a href="https://example.com/page2">Page 2</a></li>
<li><a href="https://example.com/page3">Page 3</a></li>
<!-- 更多的链接 -->
</ul>
<div class="pagination">
<span class="current">1</span>
<a href="https://example.com/listing?page=2">2</a>
<a href="https://example.com/listing?page=3">3</a>
<!-- 更多的分页链接 -->
</div>
</body>
</html>
分頁範例 https://example.com/listing
Web Scraping範例pagination分頁處理
Web Scraping範例抓link後,逐一走訪
import scrapy
class MySpider(scrapy.Spider):
name = 'my_spider'
def start_requests(self):
base_url = 'https://example.com/listing?page={}' # 基礎URL
total_pages = 5 # 假設總共有5頁
# 生成要訪問的每個分頁的URL
for page in range(1, total_pages + 1):
url = base_url.format(page)
yield scrapy.Request(url, self.parse)
def parse(self, response):
# 在這裡解析每個頁面的內容,如提取標題、內容等
# 你可以使用CSS選擇器或XPath來提取資料
titles = response.css('h2::text').getall()
contents = response.css('.content::text').getall()
# 處理提取的資料
for title, content in zip(titles, contents):
yield {
'Title': title,
'Content': content
}MySpider.py
Web Scraping範例完整範例-自動抓取多個頁面
<div class="article">
<h1 class=“title”>文章標題</h1>
<div class=“author”>作者:John Doe</div>
<div class=“time”>發佈時間:2023-01-01</div>
<div class="content">
<p>文章內容... </p>
</div>
<div class="comments">
<div class="comment">
<div class=“comment-author”>評論作者:Alice</div>
<div class=“comment-content”>評論內容... </div>
</div>
<!-- 更多評論 -->
</div>
</div>
article.html
Web Scraping範例完整範例-自動抓取多個頁面
import scrapy
class ArticleSpider(scrapy. Spider):
name = 'article_spider'
start_urls=['文章所在網址']
def parse_article(self, response):
# 提取文章資訊
title = response.css('h1.title::text').get()
author = response.css('div.author::text').get()
time = response.css('div.time::text').get()
content = response.css('div.content p::text').getall()
# 資料清理pandas, numpy,如果需要的話
# ...
# 提取評論資訊
comments = []
# div元素之class="comments" 或 class="comment"
comment_divs = response.css('div.comments div.comment')
for comment_div in comment_divs:
# div元素 class="comment-author"。 "::text"指 div所包內文
comment_author = comment_div.css('div.comment-author::text').get()
comment_content = comment_div.css('div.comment-content::text').get()
# 資料清理pandas, numpy,如果需要的話
# ...
# 將此輪擷取資料加入串列
comments.append({
'author': comment_author,
'content': comment_content
})
# 傳回提取的文章資訊和評論資訊
# 注意:yield類似return,但較不花系統資源
yield {
'title': title,
'author': author,
'time': time,
'content': content,
'comments': comments
}
def parse(self, response):
# 取得目前頁面的所有連結,"a::attr(屬性名稱)"讀取元素<a>的某個屬性
# get()抓取一個, getall()抓取全部
links = response.css('a::attr(href)').getall()
# 處理目前頁面的連結並解析文章內容
for link in links:
yield scrapy.Request(response.urljoin(link), callback=self.parse_article)
# 取得分頁資訊
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield scrapy.Request(response.urljoin(next_page), callback=self.parse)
ArticleSpider.py
抓特定id後印出內文
網路爬蟲實作
單一頁面版:使用 Requests + BeautilfulSoup4
☛ 無限循環版:使用Scrapy
Web Scraping範例無限循環版
import scrapy
from bs4 import BeautifulSoup
import random
import mycrawler.items as items
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "twbaseball" # 2. 為spider命名
allowed_domains = ['dils.tku.edu.tw']
start_urls = [ # 3. 頁面擷取串列
'http://twbsball.dils.tku.edu.tw/wiki/index.php/%E5%88%86%E9%A1%9E:%E5%8F%B0%E7%81%A3%E7%90%83%E5%93%A1'
]
....twbaseball_spider.py(部份)
所有spider都需要這三部份
Web Scraping範例無限循環版:部份結果
import scrapy
from bs4 import BeautifulSoup
import random
import mycrawler.items as items
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "twbaseball" # 2. 為spider命名
allowed_domains = ['dils.tku.edu.tw']
start_urls = [ # 3. 頁面擷取串列
'http://twbsball.dils.tku.edu.tw/wiki/index.php/%E5%88%86%E9%A1%9E:%E5%8F%B0%E7%81%A3%E7%90%83%E5%93%A1'
]
total_page = len(start_urls) # 分頁總數
num_of_player = 0 # 抓取的球員總數
player = items.Player() # 球員資料欄位->自行定義在items.py
sid = { # 台灣棒球維基館的section id
'簡介': '.E7.B0.A1.E4.BB.8B',
'基本資料': '.E5.9F.BA.E6.9C.AC.E8.B3.87.E6.96.99',
'經歷': '.E7.B6.93.E6.AD.B7',
'個人年表': '.E5.80.8B.E4.BA.BA.E5.B9.B4.E8.A1.A8',
'特殊事蹟': '.E7.89.B9.E6.AE.8A.E4.BA.8B.E8.B9.9F',
'職棒生涯成績': '.E8.81.B7.E6.A3.92.E7.94.9F.E6.B6.AF.E6.88.90.E7.B8.BE',
'外部連結': '.E5.A4.96.E9.83.A8.E9.80.A3.E7.B5.90'
}
def parse(self, response): # 4. 頁面解析
next200 = False # pagination link processing flag
player_links = [] # 球員超連結串列
for link in response.css('#mw-pages').css("a"):
text = link.css('a::text').get() # 超連結的文字部分
if text == '先前200': # 先前200已經處理過了
continue
if text == '之後200': # 之後200 下一頁球員
if next200: # 已經處理過了
continue
else: # 尚未處理
next200 = True # 標示為已處理
self.total_page += 1
# yield response.follow(link, self.parse) # 連續循環版
print(f"^^^current total pages:{self.total_page}")
if random.randint(1,100)<=2:
player_links.append(link)
self.num_of_player += len(player_links)
yield from response.follow_all(player_links, self.parse_player)
print(f"***current total number of players:{self.num_of_player}")
def parse_player(self, response):
player = items.Player() # 新球員資料
soup = BeautifulSoup(response.body, 'lxml')
# 0. 球員姓名
player['name'] = soup.find(id="firstHeading").text
yield {
'title': player['name'],
}
twbaseball_spider.py
items.py:可以定義「想要擷取的欄位」
Web Scraping範例items.py
# Define here the models for your scraped items
from re import S
import scrapy
class MycrawlerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class Player(scrapy.Item): # 球員資料
url = scrapy.Field() # 網址
name = scrapy.Field() # 球員姓名
nickname = scrapy.Field() # 綽號
birthday = scrapy.Field() # 生日
height = scrapy.Field() # 身高
weight = scrapy.Field() # 體重
position = scrapy.Field() # 守備位置
intro = scrapy.Field() # 簡介全文
experience = scrapy.Field() # 經歷
event = scrapy.Field() # 年表
performance = scrapy.Field() # 特殊事蹟
record = scrapy.Field() # 成績紀錄
links = scrapy.Field() # 外部連結items.py
參考這邊的寫法
Web Scraping範例無限循環版
twbaseball_spider.py(部份)
...
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
...
def parse(self, response): # 4. 頁面解析
next200 = False # pagination link processing flag
player_links = [] # 球員超連結串列
for link in response.css('#mw-pages').css("a"):
text = link.css('a::text').get() # 超連結的文字部分
if text == '先前200': # 先前200已經處理過了
continue
if text == '之後200': # 之後200 下一頁球員
if next200: # 已經處理過了
continue
else: # 尚未處理
next200 = True # 標示為已處理
self.total_page += 1
# yield response.follow(link, self.parse) # 連續循環版
print(f"^^^current total pages:{self.total_page}")
if random.randint(1,100)<=2:
player_links.append(link)
self.num_of_player += len(player_links)
yield from response.follow_all(player_links, self.parse_player)
print(f"***current total number of players:{self.num_of_player}")
...主要的回呼函式
無限循環? 透過遞迴達成!
如何辦到無限循環?特殊的遞迴呼叫(產生器):yield, yield from
...
yield from response.follow_all(player_links, self.parse_player)
.......
yield response.follow(link, self.parse) # 連續循環版
....連往下一個超連結link,並呼叫parse()回呼函式
yield: 生成器,類似return,但可節省許多記憶體
連往player_links內所有超連結,並呼叫parse_player()回呼函式
yield from:產生許多生成器
完整範例
台灣棒球維基館
twbaseball_spider.py
import random
import time
from datetime import datetime
import mycrawler.items as items # 資料欄位定義 items.xxxx
import scrapy
from bs4 import BeautifulSoup
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
#### spider 設定 ####
name = "twb_reader" # 2. 為spider命名
allowed_domains = ['dils.tku.edu.tw']
start_urls = [ # 3. 起始擷取頁面串列
# 頁面:台灣球員分類
'http://twbsball.dils.tku.edu.tw/wiki/index.php/%E5%88%86%E9%A1%9E:%E5%8F%B0%E7%81%A3%E7%90%83%E5%93%A1'
]
out_file = 'twbaseball_player.csv' # 輸出檔案
custom_settings = {
'FEEDS': { out_file: { 'format': 'csv',}}
}
#### 程式自定義屬性 ####
base_url = "http://twbsball.dils.tku.edu.tw"
total_page = 0 # 分頁總數
num_of_player = 0 # 抓取的球員總數
sections = [ # data frame的column name,共9個
'簡介', # 同義詞段落'生平簡介'
'基本資料',
'經歷',
'個人年表',
'特殊事蹟',
'職棒生涯成績',
'備註',
'註釋或參考文獻',
'外部連結',
]
sid = { # 台灣棒球維基館的section id
'基本資料': '.E5.9F.BA.E6.9C.AC.E8.B3.87.E6.96.99',
'經歷': '.E7.B6.93.E6.AD.B7',
'個人年表': '.E5.80.8B.E4.BA.BA.E5.B9.B4.E8.A1.A8',
'特殊事蹟': '.E7.89.B9.E6.AE.8A.E4.BA.8B.E8.B9.9F',
'職棒生涯成績':'.E8.81.B7.E6.A3.92.E7.94.9F.E6.B6.AF.E6.88.90.E7.B8.BE',
'備註':'.E5.82.99.E8.A8.BB',
'註釋或參考文獻': '.E8.A8.BB.E9.87.8B.E6.88.96.E5.8F.83.E8.80.83.E6.96.87.E7.8D.BB',
'外部連結': '.E5.A4.96.E9.83.A8.E9.80.A3.E7.B5.90',
'結尾': 'stub'
}
intro = {
'簡介': '.E7.B0.A1.E4.BB.8B',
'生平簡介': '.E7.94.9F.E5.B9.B3.E7.B0.A1.E4.BB.8B'
}
####
def extract_introduction(self, content, key, value):
pos = str(content).find(f'id="{value}"') # 簡介 / 生平簡介
if pos == -1:
return None
else:
next_pos = str(content).find('<span class="mw-headline" id=".E5.9F.BA.E6.9C.AC.E8.B3.87.E6.96.99">基本資料</span>')
intro_str = str(content)[pos:next_pos] # 擷取 「簡介/生平簡介」 段落
intro_str = intro_str[intro_str.find(key):] # 去掉最前面未切乾淨的html碼
intro_soup = BeautifulSoup(intro_str, 'lxml') # parsing
texts = intro_soup.find_all(text=True) # 取出所有元素的文字,不含標籤屬性
# 資料格式為串列
return u"".join(t.strip() for t in texts) # 將串列元素接在一起形單一字串,u""為unicode
####使用字串.find()和取得子字串的功能,切出每個段落大致的內容
# 參數:
# content: http response回應的內容部份
# start: 開始字串(不含),要裁切內容的開始位置
# end: 結尾字串(不含), 裁切內容的結束位置
# 回傳:
# 裁切好的子字串
def get_sub_content(self, content, start, end):
start_pos = str(content).find(f'id="{start}"')
# print(f'sp:{start_pos}')
if start_pos == -1: # 找不到start字串
return None
else: # 找到 start字串
end_pos = str(content).find(f'id="{end}"') # 尋找end字串
if end_pos == -1:
return None # 找不到end字串
else:
# print(f'ep:{end_pos}')
return str(content)[start_pos: end_pos] # 回傳裁切子字串
#### 使用BeatuifulSoup的功能,取出以<dd></dd>包起來的段落內容
# 參數:
# html_str: 要分析的段落內容字串
# 回傳:
# 段落內容串列,每一個li為一個串列元素
def extract_dlist(self, html_str):
soup = BeautifulSoup(html_str, 'lxml') # parsing
li = soup.find_all('li') # 找到<li>
li_texts = [] # 空字串, 將存入所有li的文字
for item in li:
item_text = item.find_all(text=True)
if u"".join(item_text).strip() != '':
li_texts.append(u"".join(item_text).strip())
return li_texts
def parse(self, response): # 4. 頁面解析
next200 = False # pagination link processing flag
player_links = [] # 球員超連結串列
# 走訪所有超連結:(1)處理pagination (yield版本的遞迴) (2)儲存球員超連結
for link in response.css('#mw-pages').css("a"):
text = link.css('a::text').get() # 超連結的文字部分
if text == '先前200': # 先前200已經處理過了
continue
if text == '之後200': # 之後200 下一頁球員
if next200: # 已經處理過了
continue
else: # 尚未處理
next200 = True # 標示為已處理
self.total_page += 1
yield response.follow(link, self.parse) # yield版遞迴至下一頁
print(f"^^^ 已處理總頁數 ^^^:{self.total_page}")
player_links.append(link) ## 處理全部球員
#if random.randint(1, 100) <= 2:
# player_links.append(link) # link為球員連結, 加入待處理球員連結
self.num_of_player += len(player_links)
print(f'*** 目前的球員總數 ***:{self.num_of_player}')
yield from response.follow_all(player_links, self.parse_player)
def parse_player(self, response):
if response.status == 200:
soup = BeautifulSoup(response.body, 'lxml')
else:
return
# 0. 球員姓名
player_name = soup.find(id="firstHeading").text # 棒球維基館title id
# 1. url
url = response.url
# 2. content
final_result = {} # 最後擷取的全文結果
all_content = soup.find(id="bodyContent") # 取得全部HTML內文
#### 2.1 擷取「簡介」, 如果有的話
for key, value in self.intro.items():
pp = self.extract_introduction(all_content, key, value) # 取得 簡介
if pp != None:
print(f'找到{key}')
# final_result[key] = pp # 簡介
intro = pp # 簡介內容
break
else:
intro = '' # 沒有簡介
print(f'找不到{key}')
#### 2.2 擷取後面各個段落
start_str = '' # 擷取段落用的開始字串
end_str = '' # 擷取段落用的結束字串
title = '' # 目前擷取的段落名稱:對應至sid的key
next_title = '' # 下一個擷取的段落名稱:對應至sid的key
for key, value in self.sid.items(): # 遍訪sid串列,取出定位字串
if start_str == '': # 1. 設定開始字串
start_str = value # 1.1開始字串
title = key # 1.2段落名稱
continue
else:
if end_str == '': # 2. 設定結束字串
end_str = value # 2.1 結束字串
next_title = key # 2.2 下一個段落名稱
print(title)
# 使用開始字串,結束字串取得中間的html內容
sub_content_str = self.get_sub_content(all_content, start_str, end_str)
if sub_content_str == None: # 如果擷取回來沒有內容
end_str = '' # 清除結束字串,繼續處理下一個sid項目
continue
# 處理擷取回來的段落內容
li_list = self.extract_dlist(sub_content_str) # 取出當中的li
final_result[title] = ''.join(li_list) # 紀錄起來
start_str = end_str # 設定下一段的開始字串
end_str = '' # 清除結束字串
title =next_title # 設定下一段的段落名稱
now = datetime.now().strftime("%Y/%m/%d %H:%M:%S")
player_data = items.PlayerData(
name = player_name,
url = url,
datetime = now,
intro = intro,
bio = final_result['基本資料'] if '基本資料' in final_result else '',
experience = final_result['經歷'] if '經歷' in final_result else '',
event = final_result['個人年表'] if '個人年表' in final_result else '',
performance = final_result['特殊事蹟'] if '特殊事蹟' in final_result else '',
record = final_result['職棒生涯成績'] if '職棒生涯成績' in final_result else '',
notes = final_result['備註'] if '備註' in final_result else '',
refs = final_result['註釋或參考文獻']if '註釋或參考文獻' in final_result else '',
links = final_result['外部連結']if '外部連結' in final_result else '',
)
yield player_data
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
from re import S
import scrapy
class MycrawlerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class PlayerData(scrapy.Item):
name = scrapy.Field() # 球員姓名
url = scrapy.Field() # 網址
datetime = scrapy.Field() # 擷取日期時間
intro = scrapy.Field() # 簡介全文
bio = scrapy.Field() # 基本資料
experience = scrapy.Field() # 經歷
event = scrapy.Field() # 年表
performance = scrapy.Field() # 特殊事蹟
record = scrapy.Field() # 成績紀錄
notes = scrapy.Field() # 備註
refs = scrapy.Field() # 參考文獻
links = scrapy.Field() # 外部連結
class Player(scrapy.Item):
# 球員資料
url = scrapy.Field() # 網址
name = scrapy.Field() # 球員姓名
nickname = scrapy.Field() # 綽號
birthday = scrapy.Field() # 生日
height = scrapy.Field() # 身高
weight = scrapy.Field() # 體重
position = scrapy.Field() # 守備位置
intro = scrapy.Field() # 簡介全文
experience = scrapy.Field() # 經歷
event = scrapy.Field() # 年表
performance = scrapy.Field() # 特殊事蹟
record = scrapy.Field() # 成績紀錄
links = scrapy.Field() # 外部連結
items.py
Ckip Transformers

Ckip Transformers安裝與使用

Ckip Transformers安裝與使用
使用方法ㄧ: 透過HuggingFace Transformers
圖片來源:Transformers, PyTorch, TensorFlow
pip install -U transformers❶ 安裝transformers套件
❷ 安裝深度學習套件(擇一)
pip install -U torchpip install -U tensorflow


* 後續以PyTorch為例
from ckip_transformers.nlp import CkipWordSegmenter, CkipPosTagger, CkipNerChunker
## 將斷詞結果words與 part-of-speech結果pos打包在一起
def pack_ws_pos_sentece(words, pos):
assert len(words) == len(pos), f'words{len(words)}和pos{len(pos)}長度必須一樣'
result = [] # 最終結果串列
for word, p in zip(words, pos): # zip將words,pos對應位置鏈在一起
result.append(f"{word}({p})")
return "\u3000".join(result) #\u3000是全形空白字元
# Input text
text = [
"華氏80度,氣壓30-6,整天下雨。前進到奇武荖,聆聽朗誦。然後珍珠里簡和冬瓜山,晚間在珍珠里簡的禮拜有一百五十人,拔了七十六顆牙。",
"相當涼爽舒適,與阿華出去鄉間拜訪他的一位老朋友,是一位農人。我們被看見,認出來,且受排斥。遭到兩隻大黑狗攻擊,孩童吼叫,狂暴的辱罵。 我們回家,在吃過飯之後,我們比過去更勤奮的研讀各自的功課。",
"華氏84度,陰天,氣壓30-10。上午七點離開大里簡,大部分都用走的,上午時點三十分來到頭城,拔了一些牙。十一點到打馬煙,我們剛到雨就來了。禮德醫師在路上幫一個傢伙縫手指。新漆好的禮拜堂到處都是用藍色和紅色漆,全部由他們自費花了十二元。禮德醫師拍團體照。我們照顧了十四名病人,還拔了一些牙。主持聖餐禮,聆聽十七個人背誦。大家都做得很好,我們發禮物給他們。"
]
ws_driver = CkipWordSegmenter(model="bert-base") # 載入 斷詞模型
pos_driver = CkipPosTagger(model="bert-base") # 載入 POS模型
ner_driver = CkipNerChunker(model="bert-base") # 載入 實體辨識模型
print('all loaded...')
# 執行pipeline 產生結果
ws = ws_driver(text) # 斷詞
pos = pos_driver(ws) # 詞性: 注意斷詞-詞性是依序完成
ner = ner_driver(text) # 實體辨識
##列印結果
for sentence, word, p, n in zip(text, ws, pos, ner):
print(sentence)
print(pack_ws_pos_sentece(word, p))
for token in n:
print(f"({token.idx[0]}, {token.idx[1]}, '{token.ner}', '{token.word}')")
print()華氏80度,氣壓30-6,整天下雨。前進到奇武荖,聆聽朗誦。然後珍珠里簡和冬瓜山,晚間在珍珠里簡的禮拜有一百五十人,拔了七十六顆牙。
華氏(Na) 80(Neu) 度(Nf) ,(COMMACATEGORY) 氣壓(Na) 30-6(Neu) ,(COMMACATEGORY) 整(Neqa) 天(Nf) 下雨(VA) 。(PERIODCATEGORY) 前進(VA) 到(P) 奇武荖(Nc) ,(COMMACATEGORY) 聆聽(VC) 朗誦(VC) 。(PERIODCATEGORY) 然後(D) 珍珠里簡(Na) 和(Caa) 冬瓜山(Nc) ,(COMMACATEGORY) 晚間(Nd) 在(P) 珍珠里簡(Nc) 的(DE) 禮拜(Na) 有(V_2) 一百五十(Neu) 人(Na) ,(COMMACATEGORY) 拔(VC) 了(Di) 七十六(Neu) 顆(Nf) 牙(Na) 。(PERIODCATEGORY)
(0, 5, 'QUANTITY', '華氏80度')
(8, 12, 'QUANTITY', '30-6')
(37, 40, 'LOC', '冬瓜山')
(41, 43, 'TIME', '晚間')
(52, 56, 'CARDINAL', '一百五十')
(60, 63, 'CARDINAL', '七十六')
實體辨識
11類專有名詞
7類數量詞
Part-of-Speech(POS)
61種詞性

華氏80度,氣壓30-6,整天下雨。前進到奇武荖,聆聽朗誦。然後珍珠里簡和冬瓜山,晚間在珍珠里簡的禮拜有一百五十人,拔了七十六顆牙。
華氏(Na) 80(Neu) 度(Nf) ,(COMMACATEGORY) 氣壓(Na) 30-6(Neu) ,(COMMACATEGORY) 整(Neqa) 天(Nf) 下雨(VA) 。(PERIODCATEGORY) 前進(VA) 到(P) 奇武荖(Nc) ,(COMMACATEGORY) 聆聽(VC) 朗誦(VC) 。(PERIODCATEGORY) 然後(D) 珍珠里簡(Na) 和(Caa) 冬瓜山(Nc) ,(COMMACATEGORY) 晚間(Nd) 在(P) 珍珠里簡(Nc) 的(DE) 禮拜(Na) 有(V_2) 一百五十(Neu) 人(Na) ,(COMMACATEGORY) 拔(VC) 了(Di) 七十六(Neu) 顆(Nf) 牙(Na) 。(PERIODCATEGORY)
(0, 5, 'QUANTITY', '華氏80度')
(8, 12, 'QUANTITY', '30-6')
(37, 40, 'LOC', '冬瓜山')
(41, 43, 'TIME', '晚間')
(52, 56, 'CARDINAL', '一百五十')
(60, 63, 'CARDINAL', '七十六')
只辨識出1個實體
且分類錯誤
應為GPE
3個地名,共出現四次
珍珠里簡: 不同詞性?
Na:普通名詞,Nc: 地方詞
資料清理
1. 讀寫檔案
2. 資料清理


pip install pandas
pip install numpy
Pandas安裝
Pandas範例1:寫出csv檔
from bs4 import BeautifulSoup
import requests
import pandas
....
# print(final_result) # 印出擷取的資料
fr_array = [] # 準備空白表格資料
fr_array.append(final_result) # 加入一筆資料至表格
index=[i for i in range(len(fr_array))] # data frame的索引
### 建立dataframe
# 1. fr_array: 表格資料(目前只有一筆)
# 2. index=index: 前者是參數名稱,後者是第9行建立的索引串列
# 3. columns=sections: 前者是參數名稱, 後者是先前定義的欄位串列
df = pandas.DataFrame(fr_array,index=index, columns=sections)
df.to_csv('out_file.csv') # 寫出檔案(utf-8編碼)webscraping-player.py(部份)
Pandas範例2:讀寫csv檔
...
import pandas as pd
def read_file(fn):
# 日記無header,自訂header為'date','content'
df = pd.read_csv(fn,names=['date','content'])
df['content'] = df['content'].str.strip() # 去除頭尾空白字元
print(df.info())
return df
# 步驟一: 讀取馬偕日記
data_file = './data/MackayFull-202209-utf8.csv'
out_file = './data/MackayFull-202209-Output-utf8.csv'
df = read_file(data_file)
# print(df)
...02Mackay.py(部份)
Pandas範例2:讀寫csv檔
#-*-coding:UTF-8 -*-
# 讀取馬偕日記csv檔,使用CKIP斷詞、實體辨識進行處理, 並作統計
# Import Ckip Transformers module
from ckip_transformers.nlp import CkipWordSegmenter, CkipPosTagger, CkipNerChunker
import pandas as pd
def read_file(fn):
df = pd.read_csv(fn,names=['date','content']) # 日記無header,自訂header為'date','content'
df['content'] = df['content'].str.strip() # 去除日記內容頭尾的空白字元
print(df.info())
return df
# 步驟一: 讀取馬偕日記
data_file = './data/MackayFull-202209-utf8.csv'
out_file = './data/MackayFull-202209-Output-utf8.csv'
df = read_file(data_file)
# print(df)
# 步驟二: load models
ws_driver = CkipWordSegmenter(model="bert-base")
print('word segmenter loaded...')
pos_driver = CkipPosTagger(model="bert-base")
print('Pos Tagger loaded...')
ner_driver = CkipNerChunker(model="bert-base")
df['word_segment'] = ws_driver(df['content']) # 斷詞
df['part_of_speech'] = pos_driver(df['content']) # 詞性標記
df['ner_chunker'] = ner_driver(df['content']) # 實體辨識
# 合併 斷詞 於 詞性標記 的結果
sub_df = df[['word_segment','part_of_speech']] # 取出斷詞、詞性標記
word_with_pos = list()
for index in range(sub_df.shape[0]): # 每一筆
print('處理第 %d 筆' % index)
ws = sub_df['word_segment'][index] # 斷詞結果
pos = sub_df['part_of_speech'][index] # 詞性標記結果
count = 0 # 指標 for part_of_speech
words = list()
for word in ws: # 每一筆
# print(word, pos[count], sep=' ')
words.append([word, pos[count]])
count += len(word)
word_with_pos.append(words)
df['word_with_pos'] = word_with_pos
print(df['word_with_pos'])
print(df['ner_chunker'])
'''
# 版本1: 只取部分欄位
out_field = ['date','content','word_with_pos','ner_chunker']
out_df=df[out_field]
out_df.to_csv(out_file, sep='\t', encoding='utf-8')
'''
# 版本2: 輸出所有欄位
df.to_csv(out_file, sep='\t', encoding='utf-8')
02Mackay.py
有使用BERT處理文字(需另外安裝)
pip install -U transformers➊ 用不到、不相關
➋ 資料闕漏
刪除一筆、刪除一欄、補遺
刪除欄位
➌ 資料型別錯誤
重填正確型別資料
Data Cleaning

建立資料結構

資料清理
輸出

●●●
資料庫

讀取檔案
●●●


The result Sustainability Report

永續報告書內容


大型語言模型
Large Language Model
機器學習Process
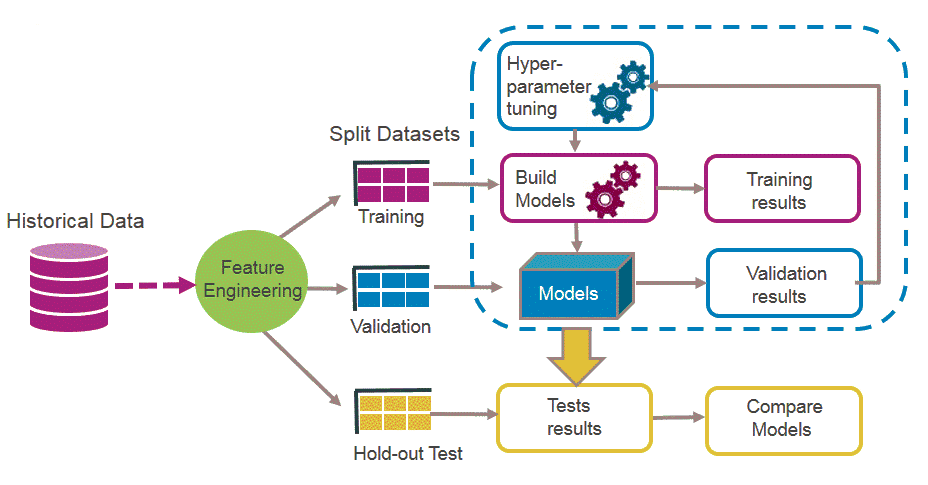
訓練資料
❶¹ 前處理
🅐 訓練集
🅑 驗證集
🅒 測試集
❷ 訓練參數
➎ 決定最終預測模型
❸ 產生預測用模型
➍ 測試模型
特徵萃取
❶² 資料集分割
遷移學習Transfer Learning
遷移學習:專注於目標領域資料集收集、訓練

機器學習傳統做法
資料集1
資料集2
資料集3
任務1
任務2
任務3
兩階段: 非監督式、監督式
不同任務、不同資料集
Transfer Learning
來源領域任務
資料集S
目標領域任務
大量
資料集T
小量
預訓練unsupervised
微調supervised


GPT
PaLM
Vaswani et al., Attention is All You Need https://arxiv.org/abs/1706.03762

Transformers模型
自注意(self-attention)機制
Encoder
Decoder
Attention Layer
Attention Layer
Attention Layer
預訓練以GPT-3為例
96個Transformer解碼器
任務之一:句子 ➠ 預測下一個字
預訓練常見任務之二:克漏字

預訓練範例BERT
任務(tasks)
資料爬蟲
資料清理
文章內容
有哪些可能的任務?
情感分析 (Sentiment Analysis)
主題分析 (Topic Analysis/ Thematic Analysis)
新聞分類 (News Categorization)
多標籤分類(Multilabel Classification)
問答 (Question Answering)
自然語言推論 (Natural Language Inference )
自動摘要 (automatic Abstracting)
機器翻譯 (Machine Translation)
Fabien, M., Villatoro-Tello, E., Motlícek, P., & Parida, S. (2020). BertAA : BERT fine-tuning for Authorship Attribution. ICON.
Fine tuning微調以Bert為例

❶ 準備Labeled Dataset
❷ 設計Network for Task
❸ Output Layer
The Quality of Sustainability Report

內容分析的參考依據
The Quality of Sustainability Report
The Quality of Sustainability Report
利害關係人議合水準分類模型
Classification Model for Stakeholder Engagement Level
利害關係人Stakeholder


利害關係人: 任何能影響或受組織目標實現影響的團體或個人

利害關係人溝通 日月光控股
直接影響
間接影響
Freeman, R. E. (1984). Strategic management: A stakeholder approach. pp.46 Boston, MA: Pitman
利害關係人議合效益Stakeholder Engagement Benefits
效益一:增加企業商業價值
效益二:呼應股東積極主義(shareholder activism)的興起
效益三:呼應ESG投資風潮的興起
利害關係人議合: 透徹蒐集各方意見,整合至公司營運策(ESG 之Governance)
促進知情與決策、避免潛在風險、擴大與開發商機;提昇品牌價值與聲譽、促進創新
較易制定問題的解決方案、避免意見爭執、培養與利害關係人的順暢關係
迎合股東和潛在投資者於分析投資決策
利害關係人議合分類模型
2016, GRI Database
119 Energy Sectors
資料集
內容分析法
標注Engagement actions:
Track
Inform
Consult
Support
Collaborate
Partner
Engagement水準分類
Level 1: Information Strategy
Level 2: Response Strategy
Level 3: Involvement Stragegy
Stocker, F., et al., (2020). Stakeholder engagement in sustainability reporting: a classification model. Corporate Social Responsibility and Environmental Management, 27(5), 2071-2080.
據此產出 議合行動的
1) Quality(Level 1~3)
2) Focus
3) Extension
Engagement Strategy Matrix
分析報告中段落:
Stakeholder Identification & Engagement

利害關係人議合分類模型

categories, coding
reference
quality: number of actions, most cited actions at each level
利害關係人議合分類模型
quality: number of actions, most cited actions at each level
focus:
- the frequency of the stakeholders for
a) each company
b) the total number of actions per level
- the most cited stakeholder groups at each level
extent of the engagement:
- the number of stakeholders cited
利害關係人議合分類模型

利害關係人議合分類模型

❶ 準備Labeled Dataset
❷ 設計Network for Task
❸ Output Layer
LLM for SR Classification
❸ Pre-train model selection
LLM for SR Classification
Network Design
Thematic Analysis + Multi-label Classification
Thematic Analysis + Aspect Based Sentiment Analysis(ABSA)

LLM for SR Classification

LLM for SR Classification
Q. Zhang, R. Lu, Q. Wang, Z. Zhu and P. Liu, "Interactive Multi-Head Attention Networks for Aspect-Level Sentiment Classification," in IEEE Access, vol. 7, pp. 160017-160028, 2019
LLM for SR Classification
Labeled dataset: 人工標記工具


1121微學分-智慧治理實務
By Leuo-Hong Wang



