






Santiago Quiñones Cuenca
Software Developer and Educator, Master in Software Engineering, Research UTPL {Loja, Ecuador} Repositories: http://github.com/lsantiago
Programación funcional y reactiva - Computación
Apuntes - Horario Tarde
Apuntes - Horario Mañana
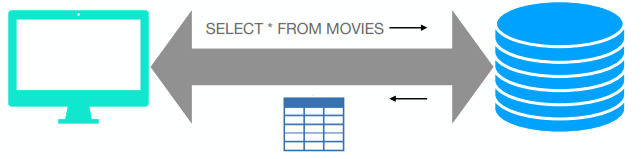
Trabajando con bases de datos relacionales
Trabajo con una base de datos
Fundamentos
Existen diferentes técnicas para trabajar con bases de datos
Pero, todas parten de un principio:
Conexión a la base
Enviar sentencias SQL que se ejecutarán
Recuperar los resultados y trabajar
Trabajo con una base de datos
Fundamentos
En programación, lo único que cambia es quien escribe el SQL
Manual
Semi-automático
Automático
Mapeo
Objeto Relación
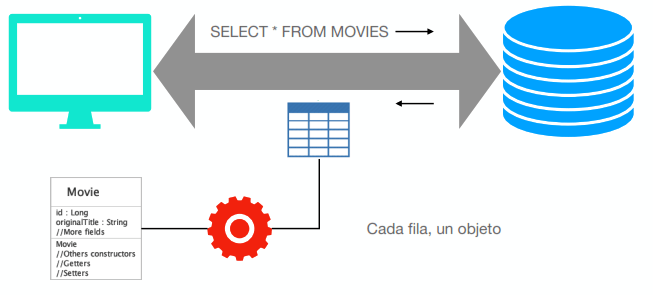
Trabajo con una base de datos
Desde el nivel más bajo
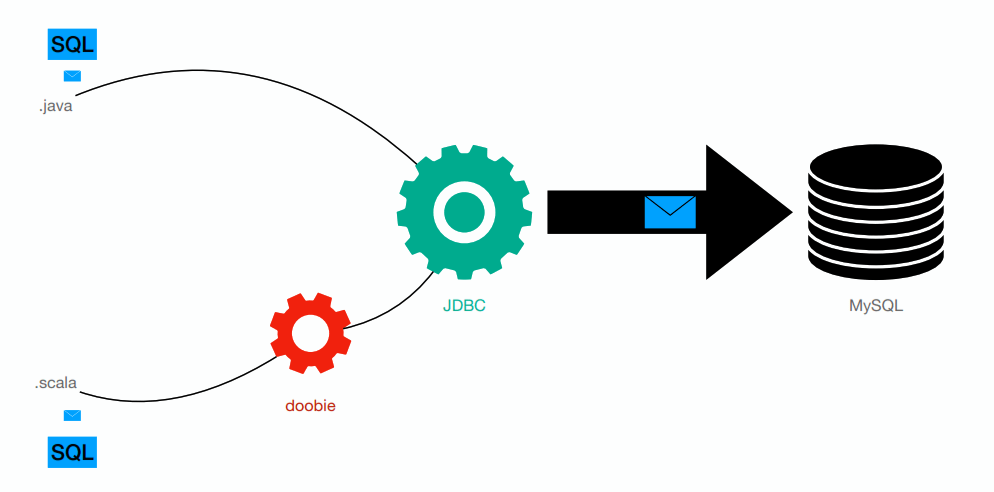
Trabajo con bases de datos relacionales
Arquitectura
BASE DE DATOS
Algunos comandos útiles
mysql -u root -p
show databases;
CREATE DATABASE my_db;
use my_db;
show tables;BASE DE DATOS - MYSQL
Scripts
CREATE TABLE MOVIE (
ID int(11) NOT NULL AUTO_INCREMENT,
ORIGINAL_TITLE varchar(1024) DEFAULT NULL,
ID_RAW_DATA int(11) DEFAULT NULL,
BUDGET double DEFAULT NULL,
REVENUE bigint(14) DEFAULT NULL,
RUNTIME int(11) DEFAULT NULL,
RELEASE_DATE date DEFAULT NULL,
PRIMARY KEY (ID)
);INSERT INTO MOVIE (ORIGINAL_TITLE, ID_RAW_DATA, BUDGET, REVENUE, RUNTIME, RELEASE_DATE)
VALUES
('Avatar', 19995, 237000000, 2787965087, 162, '2009-12-10'),
('Pirates of the Caribbean: At World''s End', 285, 300000000, 961000000, 169, '2007-05-19'),
('Spectre', 206647, 245000000, 880674609, 148, '2015-10-26'),
('The Dark Knight Rises', 49026, 250000000, 1084939099, 165, '2012-07-16'),
('John Carter', 49529, 260000000, 284139100, 132, '2012-03-07'),
('Spider-Man 3', 559, 258000000, 890871626, 139, '2007-05-01'),
('Tangled', 38757, 260000000, 591794936, 100, '2010-11-24'),
('Avengers: Age of Ultron', 99861, 280000000, 1405403694, 141, '2015-04-22'),
('Harry Potter and the Half-Blood Prince', 767, 250000000, 933959197, 153, '2009-07-07'),
('Batman v Superman: Dawn of Justice', 209112, 250000000, 873260194, 151, '2016-03-23');BASE DE DATOS - ORACLE
Scripts
CREATE TABLE MOVIE (
ID NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
ORIGINAL_TITLE VARCHAR2(1024) DEFAULT NULL,
ID_RAW_DATA NUMBER(11) DEFAULT NULL,
BUDGET BINARY_DOUBLE DEFAULT NULL,
REVENUE NUMBER(14) DEFAULT NULL,
RUNTIME NUMBER(11) DEFAULT NULL,
RELEASE_DATE DATE DEFAULT NULL
);
INSERT INTO MOVIE (ORIGINAL_TITLE, ID_RAW_DATA, BUDGET, REVENUE, RUNTIME, RELEASE_DATE)
SELECT 'Avatar', 19995, 237000000, 2787965087, 162, DATE '2009-12-10' FROM DUAL UNION ALL
SELECT 'Pirates of the Caribbean: At World''s End', 285, 300000000, 961000000, 169, DATE '2007-05-19' FROM DUAL UNION ALL
SELECT 'Spectre', 206647, 245000000, 880674609, 148, DATE '2015-10-26' FROM DUAL UNION ALL
SELECT 'The Dark Knight Rises', 49026, 250000000, 1084939099, 165, DATE '2012-07-16' FROM DUAL UNION ALL
SELECT 'John Carter', 49529, 260000000, 284139100, 132, DATE '2012-03-07' FROM DUAL UNION ALL
SELECT 'Spider-Man 3', 559, 258000000, 890871626, 139, DATE '2007-05-01' FROM DUAL UNION ALL
SELECT 'Tangled', 38757, 260000000, 591794936, 100, DATE '2010-11-24' FROM DUAL UNION ALL
SELECT 'Avengers: Age of Ultron', 99861, 280000000, 1405403694, 141, DATE '2015-04-22' FROM DUAL UNION ALL
SELECT 'Harry Potter and the Half-Blood Prince', 767, 250000000, 933959197, 153, DATE '2009-07-07' FROM DUAL UNION ALL
SELECT 'Batman v Superman: Dawn of Justice', 209112, 250000000, 873260194, 151, DATE '2016-03-23' FROM DUAL;
-- ¡No olvides el COMMIT! En Oracle los cambios no son permanentes hasta que lo ejecutas.
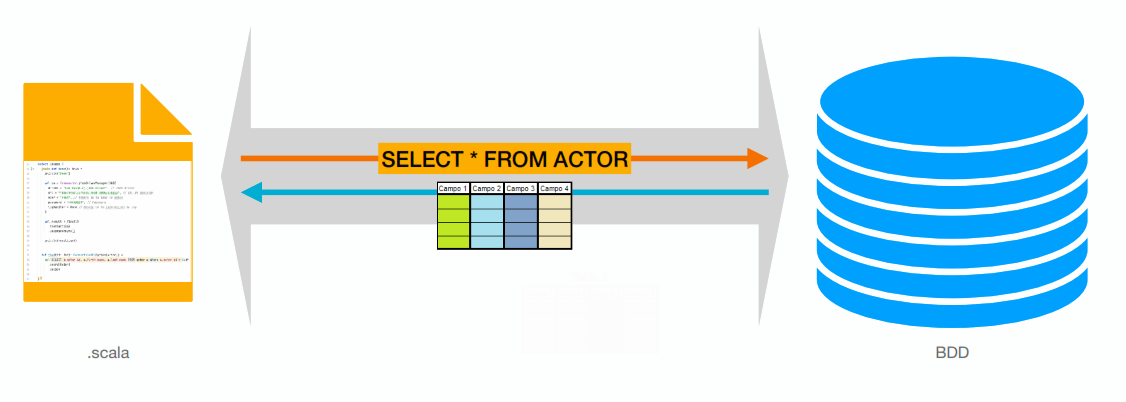
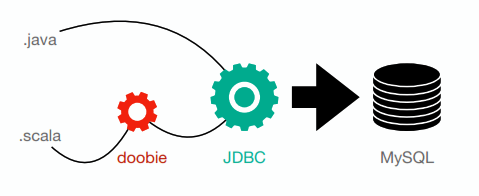
COMMIT;Scala y Base de datos relacional
doobie library
Scala y Base de datos relacional
doobie library
Scala y Base de datos relacional
doobie library - dependencias
"org.tpolecat" %% "doobie-core" % "1.0.0-RC11", // Dependencias de doobie
"org.tpolecat" %% "doobie-hikari" % "1.0.0-RC11", // Para gestión de conexiones
"com.mysql" % "mysql-connector-j" % "9.1.0", // Driver para MySQL
"com.oracle.database.jdbc" % "ojdbc8" % "21.3.0.0", // Driver para Oracle
"com.typesafe" % "config" % "1.4.2", // Para gestión de archivos de configuración
"org.slf4j" % "slf4j-simple" % "2.0.16" // Implementaciónd de loggin
Scala y Base de datos relacional
doobie library - todo el código
import doobie._
import doobie.implicits._
import cats.effect._
/**
* Objeto principal que extiende de IOApp.Simple.
* IOApp gestiona automáticamente el ciclo de vida de la aplicación y el Runtime de Cats Effect.
*/
object EjemploBase extends IOApp.Simple {
// Modelo de datos que mapea una fila de la tabla MOVIE a un objeto de Scala
case class Movie(id: Int, originalTitle: String)
}- base para trabajar con BD (Transactor, Query)
- facilita las consultas, y permite transformar resultados de consultas
- ayuda en el manejo de cálculos que pueden fallar, en la transformación de datos
- manejo de efecto secundarios de manera funcional (IO: modela E/S, Resource: manejo de recursos que necesitan ser abiertos - BD)
Scala y Base de datos relacional
doobie library - conexión
import doobie._
import doobie.implicits._
import cats.effect._
/**
* Objeto principal que extiende de IOApp.Simple.
* IOApp gestiona automáticamente el ciclo de vida de la aplicación y el Runtime de Cats Effect.
*/
object EjemploBase extends IOApp.Simple {
// Modelo de datos que mapea una fila de la tabla MOVIE a un objeto de Scala
case class Movie(id: Int, originalTitle: String)
/**
* El Transactor es el puente entre Scala y la base de Datos.
* Se encarga de:
* 1. Cargar el driver JDBC.
* 2. Gestionar la apertura y cierre de conexiones.
* 3. Envolver las operaciones en transacciones SQL.
*/
private val xa = Transactor.fromDriverManager[IO](
driver = "com.mysql.cj.jdbc.Driver",
url = "jdbc:mysql://localhost:3306/my_db",
user = "root",
password = "integrador",
logHandler = None
)
}- El Transactor se encarga de establecer y manejar la conexión con la base de datos
Scala y Base de datos relacional
doobie library - búsqueda
import doobie._
import doobie.implicits._
import cats.effect._
/**
* Objeto principal que extiende de IOApp.Simple.
* IOApp gestiona automáticamente el ciclo de vida de la aplicación y el Runtime de Cats Effect.
*/
object EjemploBase extends IOApp.Simple {
// Modelo de datos que mapea una fila de la tabla MOVIE a un objeto de Scala
case class Movie(id: Int, originalTitle: String)
/**
* El Transactor es el puente entre Scala y la base de Datos.
* Se encarga de:
* 1. Cargar el driver JDBC.
* 2. Gestionar la apertura y cierre de conexiones.
* 3. Envolver las operaciones en transacciones SQL.
*/
private val xa = Transactor.fromDriverManager[IO](
driver = "com.mysql.cj.jdbc.Driver",
url = "jdbc:mysql://localhost:3306/my_db",
user = "root",
password = "integrador",
logHandler = None
)
/**
* Busca una película por su ID.
* Devuelve un ConnectionIO[Option], lo que significa que es una descripción de una consulta
* que puede devolver una película o nada (None) si el ID no existe.
*/
private def find(id: Int): ConnectionIO[Option[Movie]] =
sql"SELECT ID, ORIGINAL_TITLE FROM MOVIE WHERE ID = $id"
.query[Movie] // Mapea el resultado a la case class Movie
.option // Devuelve Option[Movie]
/**
* Método run: Punto de entrada de la aplicación funcional.
* Aquí se "interpretan" las descripciones ConnectionIO convirtiéndolas en efectos IO
* mediante el método .transact(xa).
*/
override def run: IO[Unit] = {
for {
// Ejecuta la búsqueda y maneja el caso de que no exista el registro
res <- find(4).transact(xa)
_ <- IO.println(s"Película encontrada: ${res.map(_.originalTitle).getOrElse("No existe en la DB")}")
} yield () // El for-comprehension termina devolviendo una unidad pura dentro de IO
}
}Scala y Base de datos relacional
doobie library - búsqueda e inserción
import doobie._
import doobie.implicits._
import cats.effect._
/**
* Objeto principal que extiende de IOApp.Simple.
* IOApp gestiona automáticamente el ciclo de vida de la aplicación y el Runtime de Cats Effect.
*/
object EjemploBase extends IOApp.Simple {
// Modelo de datos que mapea una fila de la tabla MOVIE a un objeto de Scala
case class Movie(id: Int, originalTitle: String)
/**
* El Transactor es el puente entre Scala y la base de Datos.
* Se encarga de:
* 1. Cargar el driver JDBC.
* 2. Gestionar la apertura y cierre de conexiones.
* 3. Envolver las operaciones en transacciones SQL.
*/
private val xa = Transactor.fromDriverManager[IO](
driver = "com.mysql.cj.jdbc.Driver",
url = "jdbc:mysql://localhost:3306/my_db",
user = "root",
password = "integrador",
logHandler = None
)
/**
* Busca una película por su ID.
* Devuelve un ConnectionIO[Option], lo que significa que es una descripción de una consulta
* que puede devolver una película o nada (None) si el ID no existe.
*/
private def find(id: Int): ConnectionIO[Option[Movie]] =
sql"SELECT ID, ORIGINAL_TITLE FROM MOVIE WHERE ID = $id"
.query[Movie] // Mapea el resultado a la case class Movie
.option // Devuelve Option[Movie]
/**
* Recupera todos los registros de la tabla MOVIE.
* .to[List] acumula todas las filas resultantes en una lista de Scala.
*/
private def listAllMovies(): ConnectionIO[List[Movie]] =
sql"SELECT ID, ORIGINAL_TITLE FROM MOVIE"
.query[Movie]
.to[List]
/**
* Inserta un nuevo registro en la tabla MOVIE.
* .update indica que es una operación de escritura (DML).
* .run devuelve el número de filas afectadas (Int).
*/
private def insertMovie(originalTitle: String, idRawData: String, budget: String, revenue: String, runtime: String, releaseDate: String): ConnectionIO[Int] =
sql"""
INSERT INTO MOVIE (ORIGINAL_TITLE, ID_RAW_DATA, BUDGET, REVENUE, RUNTIME, RELEASE_DATE)
VALUES ($originalTitle, $idRawData, $budget, $revenue, $runtime, $releaseDate)
""".update.run
/**
* Método run: Punto de entrada de la aplicación funcional.
* Aquí se "interpretan" las descripciones ConnectionIO convirtiéndolas en efectos IO
* mediante el método .transact(xa).
*/
override def run: IO[Unit] = {
// Datos de ejemplo para la inserción
val newRow = ("Adventure Fantasy Action Science Fiction", "1452", "27000000", "39108192", "154", "2006-06-28")
for {
// Ejecuta la búsqueda y maneja el caso de que no exista el registro
res <- find(4).transact(xa)
_ <- IO.println(s"Película encontrada: ${res.map(_.originalTitle).getOrElse("No existe en la DB")}")
// Ejecuta la inserción y recupera cuántas filas se insertaron
rows <- insertMovie(newRow._1, newRow._2, newRow._3, newRow._4, newRow._5, newRow._6).transact(xa)
_ <- IO.println(s"✅ Filas insertadas: $rows")
// Recupera y recorre la lista de películas
movies <- listAllMovies().transact(xa)
_ <- IO.println("--- Listado Completo ---")
_ <- IO(movies.foreach(m => println(s"ID: ${m.id} | Título: ${m.originalTitle}")))
} yield () // El for-comprehension termina devolviendo una unidad pura dentro de IO
}
}Scala y Base de datos relacional - ORACLE
doobie library
import doobie._
import doobie.implicits._
import cats.effect._
object EjemploBaseOracle extends IOApp.Simple {
case class Movie(id: Int, originalTitle: String)
/**
* Configuración para Oracle Database 21c
* 1. Driver: oracle.jdbc.OracleDriver
* 2. URL: Formato thin para Service Name (XEPDB1)
*/
private val xa = Transactor.fromDriverManager[IO](
driver = "oracle.jdbc.OracleDriver",
url = "jdbc:oracle:thin:@//localhost:1521/XEPDB1",
user = "system",
password = "integrador",
logHandler = None
)
private def find(id: Int): ConnectionIO[Option[Movie]] =
sql"SELECT ID, ORIGINAL_TITLE FROM MOVIE WHERE ID = $id"
.query[Movie]
.option
private def listAllMovies(): ConnectionIO[List[Movie]] =
sql"SELECT ID, ORIGINAL_TITLE FROM MOVIE"
.query[Movie]
.to[List]
/**
* En Oracle, para las fechas usamos TO_DATE si pasamos Strings,
* o el literal DATE si el formato es YYYY-MM-DD.
*/
private def insertMovie(originalTitle: String, idRawData: Int, budget: Double, revenue: Long, runtime: Int, releaseDate: String): ConnectionIO[Int] =
sql"""
INSERT INTO MOVIE (ORIGINAL_TITLE, ID_RAW_DATA, BUDGET, REVENUE, RUNTIME, RELEASE_DATE)
VALUES ($originalTitle, $idRawData, $budget, $revenue, $runtime, TO_DATE($releaseDate, 'YYYY-MM-DD'))
""".update.run
override def run: IO[Unit] = {
// Definimos los datos con los tipos correctos para evitar errores de casting en Oracle
val originalTitle = "Adventure Fantasy Action Science Fiction"
val idRawData = 1452
val budget = 27000000.0
val revenue = 39108192L
val runtime = 154
val releaseDate = "2006-06-28"
for {
res <- find(4).transact(xa)
_ <- IO.println(s"Película encontrada: ${res.map(_.originalTitle).getOrElse("No existe en la DB")}")
// Pasamos los parámetros de forma individual
rows <- insertMovie(originalTitle, idRawData, budget, revenue, runtime, releaseDate).transact(xa)
_ <- IO.println(s"✅ Filas insertadas: $rows")
movies <- listAllMovies().transact(xa)
_ <- IO.println("--- Listado Completo ---")
_ <- IO(movies.foreach(m => println(s"ID: ${m.id} | Título: ${m.originalTitle}")))
} yield ()
}
}Ejecución en codespace
Conexión y creación de tablas.
# Conectar a base de datos pfr_db en MySQL
mysql -h db -u pfr_user -ppassword pfr_db
# Mostrar tablas
show tables;
# Creación de tabla
CREATE TABLE MOVIE (
ID int(11) NOT NULL AUTO_INCREMENT,
ORIGINAL_TITLE varchar(1024) DEFAULT NULL,
ID_RAW_DATA int(11) DEFAULT NULL,
BUDGET double DEFAULT NULL,
REVENUE bigint(14) DEFAULT NULL,
RUNTIME int(11) DEFAULT NULL,
RELEASE_DATE date DEFAULT NULL,
PRIMARY KEY (ID)
);
# Inserción de datos
INSERT INTO MOVIE (ORIGINAL_TITLE, ID_RAW_DATA, BUDGET, REVENUE, RUNTIME, RELEASE_DATE)
VALUES
('Avatar', 19995, 237000000, 2787965087, 162, '2009-12-10'),
('Pirates of the Caribbean: At World''s End', 285, 300000000, 961000000, 169, '2007-05-19'),
('Spectre', 206647, 245000000, 880674609, 148, '2015-10-26'),
('The Dark Knight Rises', 49026, 250000000, 1084939099, 165, '2012-07-16'),
('John Carter', 49529, 260000000, 284139100, 132, '2012-03-07'),
('Spider-Man 3', 559, 258000000, 890871626, 139, '2007-05-01'),
('Tangled', 38757, 260000000, 591794936, 100, '2010-11-24'),
('Avengers: Age of Ultron', 99861, 280000000, 1405403694, 141, '2015-04-22'),
('Harry Potter and the Half-Blood Prince', 767, 250000000, 933959197, 153, '2009-07-07'),
('Batman v Superman: Dawn of Justice', 209112, 250000000, 873260194, 151, '2016-03-23');
Ejecución en codespace
Prompt para creación de proyecto scala con IA
genera la siguiente estructura de carpetas
workspacescala/
└── db/
├── build.sbt
└── src/
└── main/
└── scala/
└── EjemploBase.scala
El archivo build.sbt contiene:
name := "ProyectoDoobie"
version := "0.1"
scalaVersion := "3.3.1" // Versión instalada en el Codespace
libraryDependencies ++= Seq(
"org.tpolecat" %% "doobie-core" % "1.0.0-RC5", // Núcleo de Doobie
"org.tpolecat" %% "doobie-hikari" % "1.0.0-RC5", // Gestión de conexiones
"com.mysql" % "mysql-connector-j" % "8.0.31", // Driver para MySQL
"org.typelevel" %% "cats-effect" % "3.5.0" // Manejo de efectos IO
)
Y el archivo de scala:
import doobie._
import doobie.implicits._
import cats.effect._
object EjemploBase extends IOApp.Simple {
case class Movie(id: Int, originalTitle: String)
// Configuración del Transactor para el entorno de Codespaces
private val xa = Transactor.fromDriverManager[IO](
driver = "com.mysql.cj.jdbc.Driver",
url = "jdbc:mysql://db:3306/pfr_db", // 'db' es el host del contenedor MySQL
user = "pfr_user", // Usuario configurado en docker-compose
password = "password", // Contraseña configurada en docker-compose
logHandler = None
)
private def find(id: Int): ConnectionIO[Option[Movie]] =
sql"SELECT ID, ORIGINAL_TITLE FROM MOVIE WHERE ID = $id"
.query[Movie]
.option
private def listAllMovies(): ConnectionIO[List[Movie]] =
sql"SELECT ID, ORIGINAL_TITLE FROM MOVIE"
.query[Movie]
.to[List]
private def insertMovie(originalTitle: String, idRawData: String, budget: String, revenue: String, runtime: String, releaseDate: String): ConnectionIO[Int] =
sql"""
INSERT INTO MOVIE (ORIGINAL_TITLE, ID_RAW_DATA, BUDGET, REVENUE, RUNTIME, RELEASE_DATE)
VALUES ($originalTitle, $idRawData, $budget, $revenue, $runtime, $releaseDate)
""".update.run
override def run: IO[Unit] = {
val newRow = ("Adventure Fantasy Action Science Fiction", "1452", "27000000", "39108192", "154", "2006-06-28")
for {
res <- find(1).transact(xa)
_ <- IO.println(s"Película encontrada: ${res.map(_.originalTitle).getOrElse("No existe en la DB")}")
rows <- insertMovie(newRow._1, newRow._2, newRow._3, newRow._4, newRow._5, newRow._6).transact(xa)
_ <- IO.println(s"✅ Filas insertadas: $rows")
movies <- listAllMovies().transact(xa)
_ <- IO.println("--- Listado Completo ---")
_ <- IO(movies.foreach(m => println(s"ID: ${m.id} | Título: ${m.originalTitle}")))
} yield ()
}
}
Ejecución en codespace
Ejecución de proyecto
cd workspacescala/db
sbt run Reto: Poblar BD de temperturas
Reto
Archivo CSV (temperaturas.csv)
dia,temp_dia,temp_tarde
1,18.5,24.3
2,17.8,25.1
3,19.2,23.8
4,16.5,26.2
5,18.9,24.5
6,17.2,25.8Reto
Organización de solución
project-root/
├── build.sbt
├── src/
│ ├── main/
│ │ ├── scala/
│ │ │ ├── config/
│ │ │ │ └── Database.scala
│ │ │ ├── models/
│ │ │ │ └── Temperatura.scala
│ │ │ ├── dao/
│ │ │ │ └── TemperaturaDAO.scala
│ │ │ ├── services/
│ │ │ │ ├── Estadistica.scala
│ │ │ │ └── DataCleaner.scala
│ │ │ └── Main.scala
│ │ └── resources/
│ │ ├── application.conf
│ │ ├── logback.xml
│ │ └── data/
│ │ └── temperaturas.csvReto
Organización de solución
Temperaturas2026/
├── src/
│ ├── main/
│ │ ├── resources/
│ │ │ ├── data/
│ │ │ │ └── temperaturas.csv # Archivo fuente con los registros climáticos
│ │ │ └── application.conf # Configuración de acceso a MySQL/MariaDB
│ │ └── scala/
│ │ ├── config/
│ │ │ └── Database.scala # Configuración del Transactor para Doobie
│ │ ├── dao/
│ │ │ └── TemperaturaDAO.scala # Consultas SQL y persistencia
│ │ ├── models/
│ │ │ └── Temperatura.scala # Case Class del modelo de datos
│ │ ├── services/
│ │ │ ├── TemperaturaService.scala # Orquestador de lógica de negocio
│ │ │ ├── Limpieza.scala # Filtrado y depuración de datos
│ │ │ └── Estadisticas.scala # Procesamiento analítico y cálculos
│ │ ├── ListBasedLoaderMain.scala # Carga de datos mediante colecciones
│ │ └── StreamingInsertMain.scala # Inserción masiva usando FS2 Streaming
└── build.sbt # Gestión de dependencias (Doobie, FS2, Circe)Reto
Creación de tabla en MYSQL
CREATE TABLE temperaturas (
id INTEGER PRIMARY KEY AUTO_INCREMENT,
dia INTEGER NOT NULL,
temperatura_manana DECIMAL(4,1),
temperatura_tarde DECIMAL(4,1)
);
Reto
Creación de tabla en ORACLE
CREATE TABLE temperaturas (
-- GENERATED AS IDENTITY es el equivalente a AUTO_INCREMENT
id INTEGER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
dia INTEGER NOT NULL,
-- DECIMAL(4,1) es válido, pero en Oracle se suele usar NUMBER
temperatura_manana NUMBER(4,1),
temperatura_tarde NUMBER(4,1)
);
Reto
Proyecto Integrador
Proyecto Integrador o bimestral
Detalles
La presentación del proyecto debe incluir:
Código cargado en GitHub (se revisará el trabajo progresivo)
Proyecto Integrador o bimestral
Detalles
La presentación del proyecto debe incluir
Formato Wiki (archivo README.md):
• Entrega del 30 al 31 de enero de 2025
Proyecto Integrador o bimestral
Recordando criterios de limpieza
# Limpieza de Datos
## Manejo de Datos Faltantes
- Examinar valores nulos en columnas numéricas (budget, revenue, runtime)
- Detectar registros sin release_date
- Evaluar campos JSON incompletos (production_companies, production_countries, spoken_languages)
## Formato de Fechas
- Convertir release_date a YYYY-MM-DD
- Identificar y corregir fechas futuras
## Validación Numérica
- Asegurar valores positivos en budget y revenue
- Verificar rango razonable de runtime
- Estandarizar decimales en vote_average
## Limpieza JSON
- Normalizar formato en campos JSON (production_companies, production_countries, spoken_languages, crew)
- Reemplazar comillas simples por dobles
- Validar estructura de arrays
- Manejar caracteres especiales
## Limpieza de Texto
- Eliminar espacios múltiples en original_title y overview
- Asegurar codificación UTF-8
- Eliminar líneas vacías y saltos innecesarios
## Validaciones de Campos
- vote_count: enteros positivos
- vote_average: rango 0-10
- popularity: valores positivos
## Control de Calidad
- Identificar registros duplicados por ID
- Verificar codificación UTF-8 del archivoProyecto Integrador o bimestral
Detalles
Se calificara los siguientes ítems:
By Santiago Quiñones Cuenca
Persistencia de datos en base de datos relacionales




