Computational approaches to opera libretti

2nd Conference for Computational Literary Studies, Würzburg, 23.06.2023

Luca Giovannini — Daniil Skorinkin
University of Potsdam, Germany
Summary
- Research question
- Corpus
- Experiments
- Findings and discussion
This presentation: plu.sh/libretti
1. Research question
Libretto
-
A new, “artificial” genre born in the early 17th century in Italy and rapidly exported across Europe
-
Traditional scholarly focus on music more than words
-
Librettology: still largely an analogic discipline
-
Few computational investigations

Some questions
-
Is it possible to consider libretti a unitary genre with its own structural features?
-
Do libretti possess a peculiar "genre signal" which sets them apart from contemporary comedies and tragedies?
-
How did the structure of libretti evolve compared to the other genres?
2. Corpus
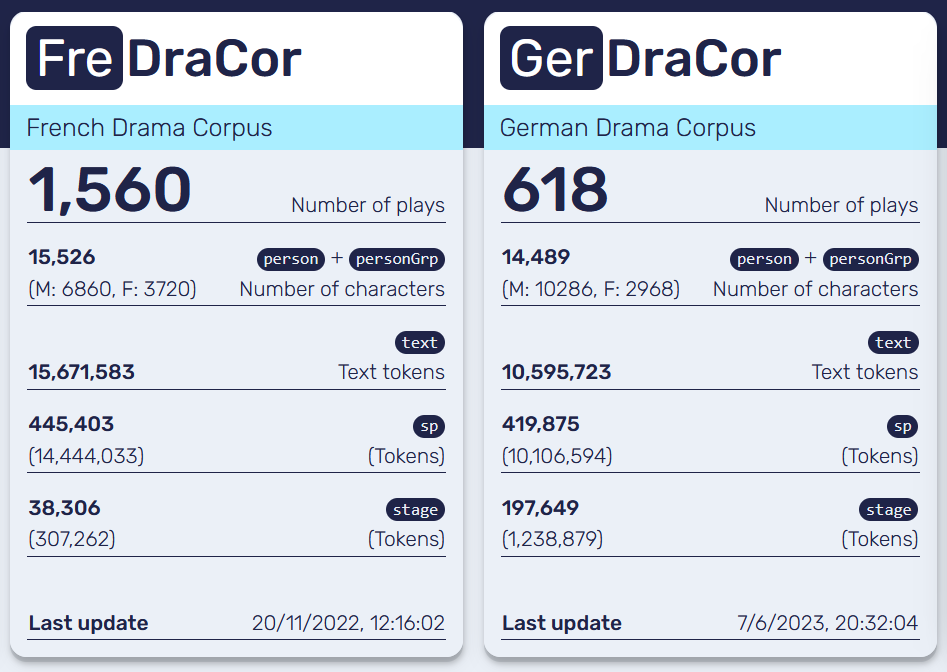
Starting point: DraCor corpora
(☞ Fischer et al. 2017, dracor.org)
Initial survey
- Get metadata from GerDraCor 🇩🇪 & FreDraCor 🇫🇷 via the Dracor API
- Investigate the '
libretto' column:- 55 libretti (as marked by DraCor) for 🇩🇪
- 58 libretti (as marked by DraCor) for 🇫🇷
- Compare '
libretto' and 'normalized_genre' columns:- For 🇩🇪 '
libretto' and 'normalized_genre' were mutually exclusive (= 0 multi-label plays) - For 🇫🇷 16 multi-label plays
- For 🇩🇪 '
Corpus preprocessing
- Normalisation of genre for the 16 multi-label 🇫🇷 plays: we preferred '
libretto' to 'normalized genre' - Initial hypothesis: the intended usage of a libretto is more distinctive than its generic alignment

Corpus enrichment
- Retrieve all items with the
'subtitle'containing one of these labels for operatic subgenres:
ballet de cour, ballet-héroïque, burlesque, comédie-ballet, divertissement, drame lyrique, entrée, grand opéra, intermède, Lehrstück, Liederspiel, Märchenoper, masque, Monodrama, opéra-ballet, opéra bouffon, opéra comique, opéra-féerie, pantomime, pastorale-héroïque, Posse, Schuldrama, Schuloper, Singspiel, Spieloper, tragédie en musique, vaudeville, Zauberoper, Zeitoper - Qualitative check, then append to 'libretti' list
Problem #1: blurred boundaries
of the concept of libretto
Corpus enrichment
- Retrieve Wikidata genres through the plays' Wikidata IDs (in the TEI markup)
- Map genres manually to one of 5 categories (Comedy, Tragedy, Tragicomedy, Libretto, None)
- Add Wikidata genre to those which had neither
normalized_genrenorlibrettofilled
Problem #2: missing
genre indicators
Enrichment results

🇩🇪
+ 51%
🇫🇷
+ 55%
3. Experiments
Exploratory data analysis as a methodological choice
- No strong hypothesis on how the structure of a libretto would have looked like
- "Let data speak by themselves"

A quite simple pipeline
Vectorisation of plays according to structural features
EDA on different textual aspects
Feature selection
- Get numeric features from the metadata table
- Drop features deemed irrelevant to play structure (e.g.
num_p,num_l,num_female_speakers) - Look for highly correlated features and remove one in each highly correlated pair
num_of_segments, num_of_speakers,
num_of_person groups, word_count_sp,
word_count_stage, average_degree, density, average_clustering, max_degree,
num_of_connected components,
diameter, average_path_length
A mixture of network measures, size statistics, and speech distribution metrics
Experiment #1
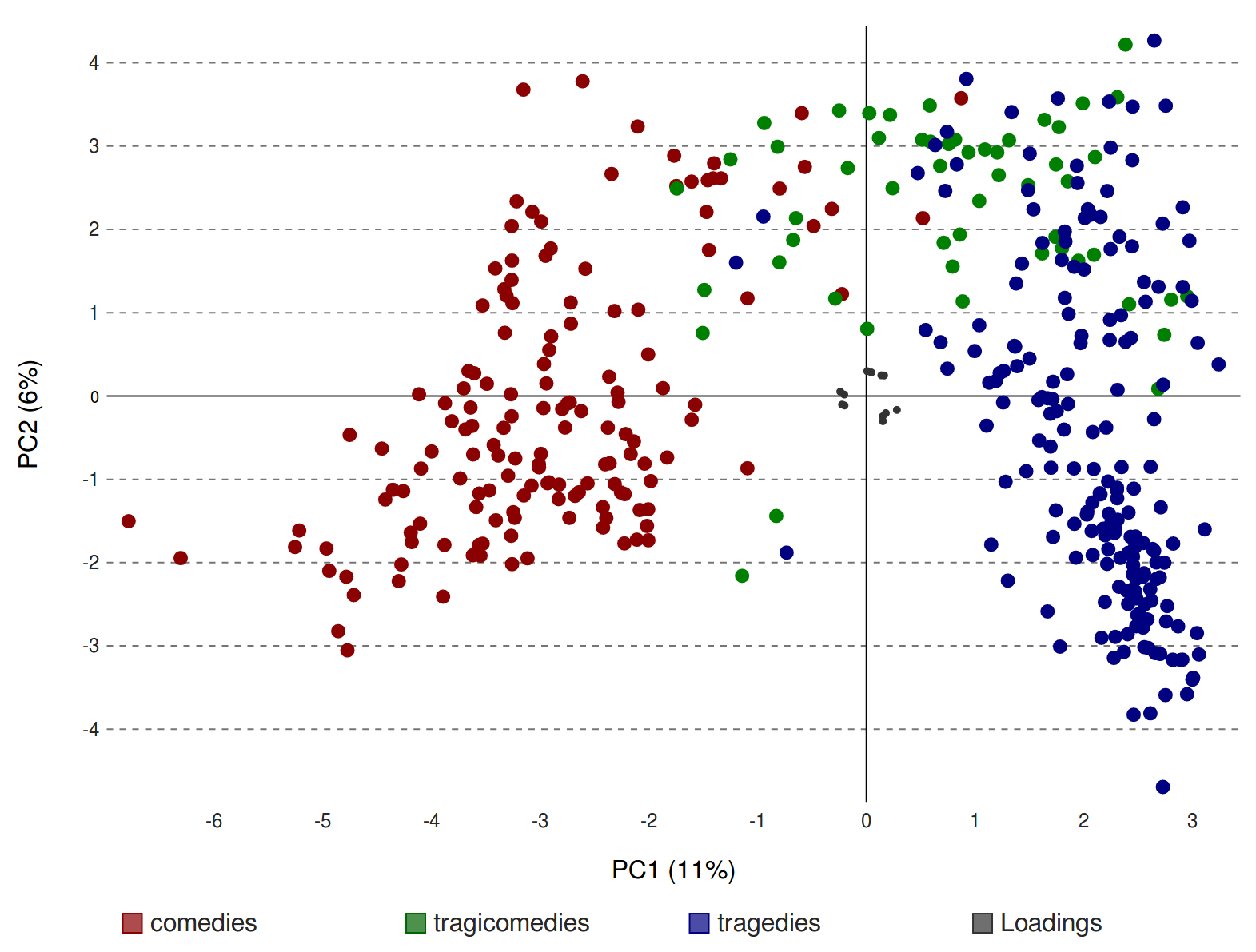
Recognising clusters
Procedure
- Split the corpora into roughly 50-year spans (3 for 🇩🇪, 5 for 🇫🇷) to follow closely the genre's evolution
- Apply dimensionality reduction methods (PCA) to the vectorised plays
-
Results were unsatisfying: no meaningful clustering, no signs of libretto being a unitary genre
Semi-automatic labelling of libretti as comic/non comic, based on their subtitles (e.g. komisches Oper → comic libretto)
Refining categories
Results: clustering still problematic BUT
significant topological patterns emerge
One interesting example:
the 🇫🇷 1670-1719 timeframe

comic space
tragic zone
non-comic libretti
Experiment #2
Measuring feature significance
1. Computing statistical significance of features variation
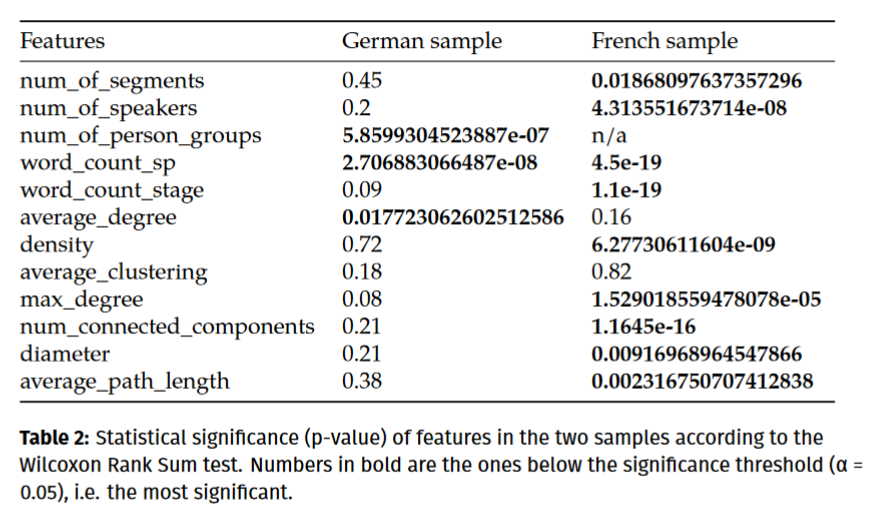
2. Training a classifier
-
Random Forest Classifier
-
5-fold cross validation on all data
-
Iterative selection of the best n estimators
parameter (10-1000) -
Removed highly correlated values (see correlation matrix)
Correlation matrix

Classifier feature importances
🇩🇪
🇫🇷
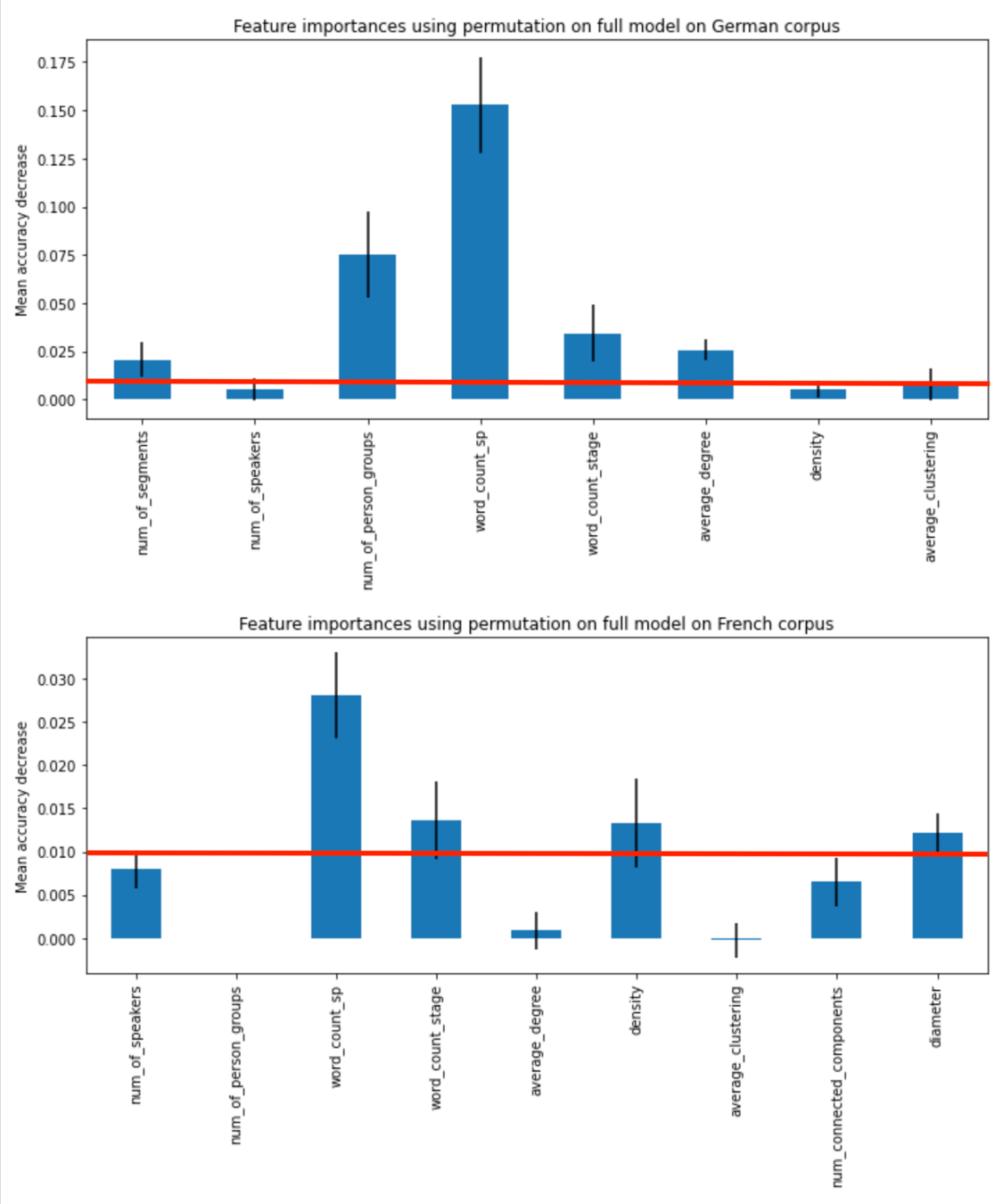
Most relevant features 🇫🇷
word_count_stageword_count_spnum_connected_componentsdensitynum_of_speakersdiameter
Most relevant features 🇩🇪
word_count_spnum_of_person_groupsaverage_degree
Experiment #3
Plotting individual features
Charting the most interpretable features as scatterplots
-
four-class implementation
-
plotting each play individually
-
LOWESS-based smoothing curves to make trends visible
4. Findings and discussion

1. Distinctive
traits of libretti
Libretti have consistently less spoken text and more stage directions
trend more prominent in French, but visible also in German
2. An interesting pattern: independence of non-comic libretti (as far as some structural features are concerned)


🇩🇪 num_groups / word_count_sp
🇫🇷: density / num_speakers
🇩🇪 4-class classifier,
confusion matrix

it is easier to confuse comedies and comic libretti
🇫🇷 4-class classifier,
confusion matrix

it is easier to confuse comedies and comic libretti
3. The French dramatic space is more formalised than the German one
- Looking at the PCA clusterings, it seems slightly easier to discriminate between different genres in 🇫🇷
- Historical reasons:

Even the two types of French libretti
are more distinct than the German ones
Limitations
- Corpora extension and markup quality
- Comparative approach: lack of 🇮🇹
- Difficulties in modelling relations between dramatic texts on the basis of formal features → could we do better?
Comparison: topic modelling (Schöch 2017)
-
Individual structural features might be useful for distinguishing libretti from non-libretti (e.g. text length), or comedies from tragedies (density)
-
However, it is generally not easy to distinguish between plays formalised as vectors of multiple features
-
Drama often seems too homogenous, in terms of structural properties, for discriminative clustering
-
Need to employ better features or rethink operationalisation patterns
In lieu of a conclusion
Thanks for listening!
#CCLS2023: Computational approaches to opera libretti
By luca-giovannini




